大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
什么是路由懒加载
官方的解释:
- 当打包构建应用时,
JavaScript包会变得非常大,影响页面加载。 - 如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应组件,这样就更加高效了。
官方想表达的意思
- 首先,我们知道路由中通常会定义很多不同的页面
- 这个页面最后会被打包到哪里呢?一般情况下是会放在一个js文件中
- 但是页面这么多,所有文件都放到一个
js文件中,必然会造成这个页面会非常的大 - 如果我们一次性从服务器中请求下来这个页面,可能需要花费一定的时间,甚至用户的电脑上会出现短暂空白的情况
- 如何避免这种情况?使用路由懒加载即可
路由懒加载做了什么
- 路由懒加载的主要作用是将路由对应的组件打包成一个个js代码块
- 只要在这个路由被访问到的时候,才加载对应的组件
路由懒加载的使用
在使用之前,我们先来看看原先代码是如何加载路由的
import Vue from "vue";
import VueRouter from "vue-router";
import Home from "@/views/Home";
import About from "@/views/About";
import User from "@/views/User";
Vue.use(VueRouter);
const routes = [
{
path: "/",
name: "Home",
component: Home,
},
{
path: "/about",
name: "About",
component: About
},
{
path: "/user/:userId",
name: "User",
component: User
}
];
我们看到从一开始我们就导入了路由对应的组件,如果需要的导入的组件非常多,那么加载页面就会相对较慢,我们来看下这种方式打包出来的文件
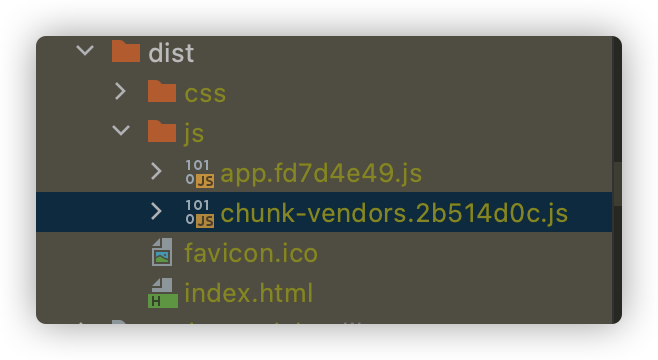

我们看到这种方式打包出来的文件只有2个js文件,之后我们加载页面的时候,需要把这2个文件全部加载完,页面才会展示,如果代码量过多,那么页面响应就比较慢,给用户体验非常不好
接下来我们使用路由懒加载
import Vue from "vue";
import VueRouter from "vue-router";
Vue.use(VueRouter);
// 新增路由懒加载代码
const Home = () => import('../views/Home')
const About = () => import('../views/About')
const User = () => import('../views/User')
const routes = [
{
path: "/",
name: "Home",
component: Home,
},
{
path: "/about",
name: "About",
component: About
},
{
path: "/user/:userId",
name: "User",
component: User
}
];
我们看到,在路由配置中什么都不需要改变,只需要像往常一样使即可,只是在这之前声明了一个变量,变量中使用箭头函数来导入对应的组件,使用起来非常简单。
使用路由懒加载的方式打包出来的文件结构如下:
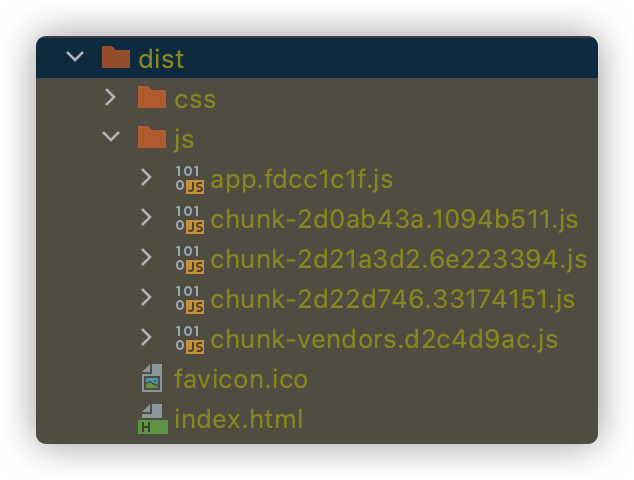
我们可以看到比原来的方式多出了3个js文件,这是因为我们上面代码3个组件使用了路由懒加载,这3个js文件只有路由被访问到了才会去加载,能省下不少的加载时间
所以我们更推荐使用路由懒加载的方式去加载路由
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/164839.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
