大家好,又见面了,我是你们的朋友全栈君。这是Rick Grehan发表在
TheServerSide上的一篇关于面向对象数据库–db4o的文章
,较全面地介绍了db4o的关键特性,希望对大家认识db4o能有所帮助。(2007.12.07最后更新)
db4o-针对对象的数据库-是一个完全的对象数据库;它以使对象在其生命周期中-无论是在数据库内或是在外-都保持着它们的本性这样一种方式操纵对象。不论类的复杂性如何,对象的内容,结构和关系都能够被保存。
更准确地说,db4o是一个数据库引擎,你只要将它的一个jar文件包含到你的数据库应用的类路径中就可以使用它了(至少对于Java是这样的)。所以,db4o运行在与你的应用程序相同的进程空间中,并能被直接地调用;它不需要类似于在ODBC或JDBC中使用的驱动文件。db4o存在针对Java,.NET和Mono的版本;它们在功能上都彼此相等。(事实上,使用.NET创建的db4o数据库也能由Java程序访问;反之亦然。)
db4o是开源的。可执行文件,源代码和文档可从http://www.db4objects.com/中下载。广泛的例子程序,和一个活跃的用户社区一样,也都可以从这个站点中找到。
db4o最引人的特性之一就是它在简易性与强大的功能之间的显著平衡。一方面,它的API是如此地易于掌握和方便使用,即使是初学者也能在相同的时间内创建一个功能完备的数据库对象。另一方面,这些相同的API也提供了更底层的能够深入调用数据库引擎的方法,以允许核心开发者为了得到适当的性能而能深入到该引擎的内部中去调整db4o的工具。
db4o的特性就是最好的证明–这胜过只是讨论–所以我们将通过示例这种方法去证明db4o。然而,我们必须牢记本文通篇只是展示了db4o特性中的一部分罢了。感兴趣的朋友会发现为了知晓该数据库引擎的全部功能而去查阅db4o的文档所花的时间是值得的。
db4o基础
让我们以初学者使用db4o时可能会做的事情开始:定义了一些类,然后持久化这些类的对象。我们所假定的类为同样也是假定的QA项目做一个跟踪测试的系统。我们的系统由两个类组成,首先是TestSuite类:
public class TestSuite {
private String name; // Test Suite name
private String description;
private String configuration;
private char overallScore;
private ArrayList <TestCase> cases;
private long dateExec;
… <remainder of TestSuite definition> …
}
TestSuite是TestCase对象的容器,(一个测试用例就是一个可单独执行的测试程序–相关的测试用例组合成一个测试组)。测试组使用额外的,全局的数据成员,每个数据成员的用途也是相对明显的:configuration记录被测试的指定系统;overallScore是对整个测试组一个简要的评分(‘P’代表通过,’F’代表失败,’B’代表被阻塞,等等。);dateExec是一个毫秒级的域,标识该测试组被执行时的日期与时刻。是ArrayList对象的cases含有单个的测试用例,由TestCase类定义:
public class TestCase {
private String name;
private String comment;
private char status;
private long duration;
private float result;
… <remainder of TestCase definition> …
}
每个测试用例都有一个名称,形式自由的注释字段,状态(通过或失败),持续时间和结果(例如,为了与测试-字节/秒的吞吐量-的任意数据关联)。
因为我们所关注是db4o的使用,所以我们不想在描述这些类的使用细节上停留。就让我们简单地说,我们已经执行了一个特别地测试组中所有的测试用例,将测试的结果存放在一个TestSuite对象中(与TestCase对象相关的ArrayList对象cases中),然后关闭数据库。是不是太容易了。
// Create the database
new File(“testsuites.YAP”).delete();
ObjectContainer db = Db4o.openFile(“testsuites.YAP”);
// Store the TestSuite object
db.set(testsuite);
// Close the database
db.close();
就是它。弹指一挥间,你就已经做到了。(当然,为了保持简洁,我们去掉了创建TestSuite对象和它的TestCase组件的细节)
停下来想想上述代码做了什么事情。特别要考虑你没有看到的–db4o已经做了但还未被告之的事情。
首先,我们不需要告诉db4o任何关于TestSuite类的结构的信息;不需要我们的帮助,db4o就能发现这个结构。利用Java反射机制的能力,db4o测定TestSuite类的结构,并勾勒出该类的装配方式以推导出此类对象的成员与关键数据。
第二,我们不必建议db4o去关注ArrayList。不仅我们不必将ArrayList的大小告诉db4o,而且我们也不必把它里面的内容告诉db4o。正如db4o在它刚接触testsuite对象时就能够发现它所需要的一切,db4o也能知道它所需要的关于(在ArrayList中的)TestCase对象的所有信息。
结果就是,如果我们把testsuite作为一个任意宠大而复杂的对象树的根,db4o能找到并存储整个树而不需要我们的任何协助。所以,存储这个处于根部的对象testsuite也就是存储了整个ArrayList对象。
最后,我们也没有必须要求db4o以事务的保护性方式去调用set方法。任何会修改ObjectContainer(表示数据库的db4o对象)的调用都会自动地开启一个事务,除非已经有一个活跃的事务了。此外还会调用close方法去终止这个事务,所以上述代码等价于:
db.startTransaction();
db.set(testsuite);
db.commitTransaction();
db.close();
此处的startTransaction和commitTransaction方法是为了证明我们的观点而虚构的。db4o也确实有显示地提交或中止事务的方法,但为了使原先的代码足够的简洁我们没有使用这些方法。db4o隐式的事务使得数据库能够一直处于一致的状态;一旦commit方法已经执行了,数据库的完整性就能够得到保证,甚至是发生了灾难性失败也能如此。
查询I – QBE
有了已经存于数据库中的对象,下一步我们想要展示的操作将肯定就是查询和恢复。db4o提供了三种查询API:有一种简单,有一种优雅,还有一种则复杂。每一种API都有其所长,并适用于不同的查询条件。以db4o的眼光来看,你选择哪一种API并没有关系:它们都是可兼容的。
我们以简单的API开始:query by exampel(QBE)。
使用QBE是如此的容易:为你的查询目标构建一个’模板’对象,然后把它传入ObjectContainer的query方法。实际上,你就是告诉db4o’去拿到所有与这个对象看起来一样的对象’。(这与JavaSpaces查询API非常相似;为了清楚地了解如何处理基本数据类型,可以看下面的内容,db4o的处理方式与JavaSpaces不同。也要注意,JavaSpace Entry对象期望使用public字段,db4o则没有这种要求。)
假设一个测试组名为”Network Throughput”,我们想取出这个测试组执行的所有测试以便我们能确定失败了的测试所占的百分比(基于TestSuite的overalScore值)。使用QBE,完成该工作的代码如下:
// Open the database
ObjectContainer db = Db4o.openFile(“testsuites.YAP”);
// Instantiate the template object, filling in
// only the name field
testTemplate = new TestSuite(“Network Throughput”);
// Execute the query
ObjectSet result = db.get(testTemplate);
fails = 0.0f;
total = 0.0f;
// Step through results,
while(result.hasNext())
{
testsuite = (TestSuite)result.next();
if(testsuite.getOverallScore()==’F’)
fails += 1.0f;
total += 1.0f;
}
if(total == 0.0f)
System.out.println(“No tests of that type found.”);
else
{
System.out.println(“Percent failed: ” + (fails/total * 100.0f) + “%”);
System.out.println(“Total executed: ” + total);
}
db.close();
在上面的代码中,testTemplate是QBE的模板对象。注意,只有它的name字段有真实的值;所有其它的成员变量不是为null就是为0。Null或0字段不参与QBE查询;因此,调用db.get方法就会返回在该数据库中name字段匹配”Network Throughput”的所有TestSuite对象。匹配的TestSuite对象将返回在一个ObjectSet结果对象中。上述代码遍历该结果,取出对象,然后计算结果并展示出来。
QBE明显的优点就是它的简易性。不需要掌握其它单独的查询语言。另外,QBE也是类型安全的:你不需要创建一个类似于SQL的查询语句
SELECT TestSuite.overallScore FROM TestSuite WHERE TestSuite.name = 200.0
另一方面,由于该查询是由Java代码创建的,编译器不会允许你把一个浮点值赋给一个String字段;反之亦然。
QBE明显的缺点就是它只能执行”等于”查询。另外,QBE使用null值去确定不参与查询的String或对象引用成员变量,使用0值去指定不参与查询的数字字段。所以,例如,我不能发明一个QBE查询去获得所有result字段的值为0的TestCase对象。
更为精细的查询要求一个能力更强的查询机制,而db4o恰恰就有这样一种机制。
查询方式II – 原生查询(Native Query)
db4o的原生查询系统应该是能想像得到的最具弹性的查询机制。不像使用数据库查询语言去构建查询,你是使用”无格式的普通Java语句”去构造原生查询。原生查询用两种手段去实现这件不可思意的工作:一个是Predicate类;另一个是QueryComparator接口。这个类包含一个可重载的(overrideable)回调方法,该方法将指定如何从数据库中选择对象(如果你愿意,你将会看到查询语句的主体….)。这个接口只声明了一个方法,该方法用于指明如何对查询结果进行排序。
作为一个例子,我们假设想找到在给定的一周内执行过了的总得分为”failed”,但与之关联的测试用例中有超过一半的被评为”passed”的测试组。这不是一个简单的”等于”查询,所以它不能使用QBE构建。
然而,db4o的原生查询可以直接地生成该查询。首先,我们继承db4o的Predicate类:
// Predicate class sub-class for native query example
public class NativeQueryQuery extends Predicate<TestSuite>
{
ObjectContainer db;
private long startdate;
private long enddate;
// 构造器要在本地获得ObjectContainer对象和日期范围
public NativeQueryQuery(ObjectContainer _db,
long _start, long _end)
{
db = _db;
startdate = _start;
enddate = _end;
}
// 这就是查询的主体
public boolean match(TestSuite testsuite)
{
float passed;
float total;
TestCase testcase;
// 判断testsuite是否在指定的日期范围内
if(testsuite.getDateExec()<startdate ||
testsuite.getDateExec()>enddate) return false;
// 如果该测试组对象中没有测试用例对象,则拒绝将该测试组对象放入查询结果中
if(testsuite.getNumberOfCases()==0)
return false;
// 检查该测试组对象中的测试用例的通过率是否超过50%
passed = 0.0f;
total = 0.0f;
for(int i=0; i<testsuite.getNumberOfCases(); i++)
{
testcase = testsuite.getTestCase(i);
if(testcase.getStatus()==’P’)
passed+=1.0f;
total+=1.0f;
}
if((passed/total)<.5) return false;
return true;
}
}
注意在这个类的使用中使用了Java泛型语义,这就是告诉db4o只去取TestSuite对象。当查询执行时,TestSuite对象就会传入match方法(我们之前提到过的回调方法),如果传入的TestSuite对象符合查询规范该方法就返回true,否则就返回false。
match方法中的代码首先确定侯选对象是否是在一周的日期范围内。如果是,则循环该对象中的成员变量测试用例的对象,计算出所有通过了的测试用例的总数。如果,得到的通过率小于50%,该测试组就被拒绝;否则,就让它通过。
我们可以使用如下的代码准确地展示该查询程序:
. . .
TestSuite testsuite;
NativeQueryQuery nqqClass;
Date now;
// Open the database
ObjectContainer db = Db4o.openFile(“testsuites.YAP”);
// Instantiate a NativeQueryQuery object,
// setting the start and end dates for
// any test in the past week
// 604800000 = milliseconds in a week
now = new Date();
nqqClass = new NativeQueryQuery(db,
now.getTime()-604800000L,
now.getTime());
// Execute the query and display the
// results
System.out.println(“Results:”);
ObjectSet results = db.query(nqqClass);
if(results.isEmpty())
System.out.println(” NOTHING TO DISPLAY”);
while(results.hasNext())
{
testsuite = (TestSuite)(results.next());
System.out.println(testsuite.toString());
}
db.close();
. . .
可以把原生查询想像成这样:目标类的对象一个接一个从数据库中取出,然后把它们传入match方法中。只有那些被match方法返回true的对象才会置于查询结果ObjectSet对象中。基本上可以说,如果你会知道如何写Java代码,那么你就知道如何写原生查询。
那么排序呢?如果想按日期的升序排列查询结果,我们就要实现QueryComparator接口,如下所示:
public class NativeQuerySort implements QueryComparator<TestSuite>{
public int compare(TestSuite t1, TestSuite t2)
{
if (t1.getDateExec() < t2.getDateExec()) return -1;
if (t1.getDateExec() > t2.getDateExec()) return 1;
return 0;
}
}
compare方法的作用十分明显。那些在查询中得以胜出的对象会成对的传入compare方法,如果第一个对象会排在第二个对象之前,相同或之后的位置,该方法就会分别返回一个小于,等于或大于0的值。为了准确地说明对查询结果的排序,我们实例化NativeQuerySort,并把对query方法的调用修改成如下:
. . .
// Instantiate the sort class
nqsClass = new NativeQuerySort();
. . .
ObjectSet results = db.query(nqqClass, nqsClass);
. . .
其它的代码仍然与原先的保持一致。
好怀疑的读者可能会抱怨道,原生查询只是一种编程上的小伎俩–相比较于直接去拿到所有的TestSuite对象然后再排除其中不符合条件的对象这样的程序,原生查询并不快。
是的,但并不十分准确。原生能够被优化。你所需要做的只是把两个jar文件–db4o-xxx-nqopt.jar(xxx表示db4o的版本)和bloat.jar–置于CLASSPATH环境变量中。在查询执行的时候,这些类库中的代码会对(在match方法中)例如基本数据类型比较,算术和布尔表达式,简单的对象成员访问,以及更多方面的结构进行优化。这个被支持的优化的列表在不停的增长,因为db4o引擎还在扩展优化的范围。
查询方式III – S.O.D.A.
db4o独一无二的能力之一就是它的API被分层了。开发者能够选择通过高层次–赋予数据库引擎相当大的自由度,让它决定如何去实现它的操作–或者开发者也可以使用一种更直接地方式去访问db4o。后一种选择为程序员平添了更多的负担,程序员必须更加小心地引导数据库引擎的内部工作。但回报就是得到一个更快,能力更强的数据库应用。
db4o的S.O.D.A.(Simple Object Data Access)查询机制就是该层次API的一个完美的例子。S.O.D.A.就是db4o的内部查询系统–QBE和原生查询都被翻译成了S.O.D.A.。然而,应用程序也能直接地调用S.O.D.A.。
假设我们想找到所有名为”Network Throughput”,且至少拥有一个其result字段–我们使用这个参数作为字节/秒的量度–不小于指定值(比方说,100)的测试用例的测试组。为该请求而做的S.O.D.A.查询可能就像这样:
. . .
TestSuite testsuite;
// Open the database
ObjectContainer db = Db4o.openFile(“testsuites.YAP”);
// Construct the query
Query query = db.query();
query.constrain(TestSuite.class);
Constraint nameConst = query.descend(“name”).
constrain(“Network Throughput”);
query.descend(“cases”).descend(“result”).
constrain(100.0f).smaller().and(nameConst);
System.out.println(“Results:”);
// Execute the query
ObjectSet result = query.execute();
if(result.isEmpty())
System.out.println(“NOTHING TO DISPLAY”);
while(result.hasNext())
{
testsuite = (TestSuite)(result.next());
System.out.println(testsuite.toString());
}
db.close();
. . .
在由Illustration 1所示图表的帮助下,这些有点儿神秘的代码就变得不那么神秘了。该程序所构建的归总起来就是一个用于指导底层数据库引擎的查询图(Query Graph)。descend方法创建了该图的一个分支,该分支向下步入对象的结构中。每个descend方法就在这个树中构建一个结点,可以在这些结点上再附上一个约束(使用constrain方法)。用SQL的话来说,约束指定了查询的”WHERE”子句部分。多个约束可以在与(and)或或(or)方法的协助下结合起来。在上面的查询中我们已经使用了and方法去关联这些约束。
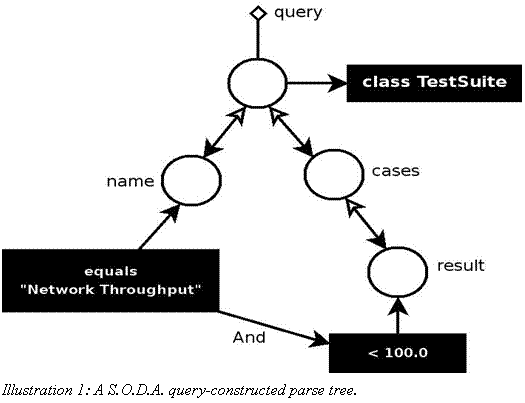

与其它的查询方式一样,查询结果返回到ObjectSet对象中,通过遍历该对象就可取出那些拿到的对象。
注意,由于S.O.D.A.是一种低层次的访问方法,没有智能的指示,它就没有默认的行为。访问cases对象的成员变量result字段的代码很简单
query.descend(“cases”).descend(“result”). …
我们并没有告诉S.O.D.A.”cases”是一个集合对象。所以当查询执行时,它会不被察觉地检测ArrayList对象cases中所有元素(TestCase对象)的result字段,然后会正确地返回那些拥有符合搜索规范的测试用例的测试组。
db4o性能调优
我们已经展示了db4o的基本操作(但无关紧要的删除操作除外,下面将会提到它)。但,正如我们在本文通篇所提到的,db4o发布(expose)了一个API层次结构,以允许开发者能够选择以何种层次的API去控制建立在该数据库引擎之上的应用程序。从另一方面看,如果你所想做的只是向数据库存入,及从数据库取出对象,那么你就已经看到了你所需要的一切。然而,如果你的应用的需求超出了添加,更新,查询和删除,可能还有一个db4o的特性可解决你的问题。
db4o的ObjectContainer实际上发布(expose)了两个API。第一个API非常的简单,由十个方法组成。这些方法处理数据库的打开与关闭;添加,更新,查询和删除对象;及提交或中止事务。短言之,该API为你提供了在操纵数据库时所需要所有功能。然而,该API中的一个方法–ext()–是进入”被扩展的”ObjectContainer的一个入口。该被扩展的ObjectContainer为深入控制db4o的内部发布(expose)了更多方法。例如,你可以获得并改变数据库的配置上下文,使用它你能够修改该引擎的行为。
例如,假设你已经从数据库中拿到了一个TestSuite对象,发现该对象中的数据是错误的,并决定该对象应该被删除。此外,你还决定你必须删除的不仅是该TestSuite对象,而且还有所有与之关联的TestCase对象(在ArrayList对象cases中)。
你是可以冗长而乏味地遍历这个ArrayList对象,一个接一个地删除每一个TestCase对象,然后再删除TestSuite对象本身。可能一种更好的解决方案是为这个TestSuite对象启用db4o的”级联删除”特性。
. . .
// Fetch the database’s configuration context
Configuration config = db.ext().configure();
// Get the ObjectClass for TestSuite
ObjectClass oc = config.objectClass(“testsuites.TestSuite”);
// Turn on cascaded delete
oc.cascadeOnDelete(true);
… …
db.delete(ts1);
. . .
在上述代码中,我们实例化了一个ObjectClass对象,该对象使我们能够访问到TestSuite对象的db4o内部表现形式。我们打开cascadeOnDelete标记,以便当执行db4o.delete(ts1)时,不仅ts1对象会被删除,而且所有由ts1引用的TestCase对象也会被删除。(由于显而易见的原因,默认情况下,级联删除是被关闭的)
作为另一个例子,假设你想为数据库预分配存储空间,以至于要最小化磁盘驱动器的头移动(head movement)。(最好是在硬盘碎片整理之后,并新创建一个数据库时这样做。)并且假设以ObjectContainer对象db作为打开了的数据库:
// Fetch the database’s configuration context
// 获得数据库的配置上下文
Configuration config = db.ext().configure();
// Pre-allocate 200,000 bytes
// 预分配200000000字节
config.reserveStorageSpace(200000000L);
把数据库文件预扩展到200000000字节(略小于200兆字节)。假设该磁盘已经做碎片整理了,那么被分配的块就是连续的,这可显著提升数据库的访问。
db4o高级应用
完全可以说,db4o在它不大的空间(约500K)内已装入了足够多的特性,相比较于db4o在运行过程中所做的众多事情,我们不能花费更多的笔墨去解释它们了。但是有两个特性十分突出,以至于肯定要提到它们。
db4o的对象复制实现了被总称为面向对象版的数据库同步。使用复制所提供的功能,你能为一个数据库中的一个对象做一个副本,并将该副本放入另一个数据库中。使用这样的方法,副本对象就无形中和原始对象关联在了一起。对任一对象–原始对象或副本对象–的改变都会被跟踪到,以便在之后的某个时候,数据库能够被重组,并且这两个数据库中对象的不同之处可被分解(例如,可同步这两个数据库)。
它工作起来就像这样:为使一个数据库可被复制,与事务计数器一样,该数据库中被创建的任何一个对象都用一个唯一全局标识符(UUID)进行了标记。当你从原始数据库中”复制”一个对象到另一个数据库中,副本对象会带着与它的原始对象相同的UUID和事务计数器。副本数据库现在就可以从它的原始数据库那儿弄走了。修改副本对象的内容将会导致对象的事务计数器被修改。所以,当这两个数据库重新连接起来,db4o内建的同步处理机制就能一个对象一个对象地进行正确的匹配(使用UUID),并确定原始或副本对象是否已经改变了。db4o甚至能追踪到每个对象发生最后一次修改时的时间,以便用户写的冲突解决代码能确定哪个对象是最近更新的。
从操作行为来看,db4o的同步处理机制与原生查询十分相似。回想一下,当实现了一个原生查询类时,我们要定义一个match方法,该方法确定哪些对象符合(或不符合)查询规范。使用同步复制,我们要定义一个ReplicationProcess对象,我们会把冲突处理对象传入该方法中。这些Java代码可能像这样:
. . .
ReplicationProcess replication = db1.ext().
replicationBegin(db2, new ReplicationConflictHandler()
{
public Object resolveConflict(
ReplicationProcess rprocess, Object a, Object b)
{
. . . …
return winning_object;
}
)
};
在上述代码中,Object a是来自于数据库db1的对象,Object b则来自于数据库db2。默认情况下,同步是双向的。同步处理保证胜出的对象(由resolveConflict方法返回的对象)能存入这两个数据库中。所以当复制完成时,这两个数据库中被复制的对象就同步了。
最后,db4o最强大的特性之一就是它能毫不费力地容忍类结构的演变。假设,在向数据库内加入数百个TestSuite对象之后,我们决定这个类必须要被修改。就是说,我们已经被告之,该系统必须能追踪到每个TestSuite的执行QA工程师,所以必须加入如下字段
private int engineerID;
到TestSuite类的定义中。
现在我们就遇到了两个相关联的问题。第一个问题不是很糟糕:已存在于数据库中的用于表示测试的TestSuite对象,并没有为它们记录QA工程师的ID,所以我们将不得不将一个虚拟的值赋给这些对象的engineerID字段;该值会指出”未记录QA工程师的ID”。第二个问题就更难应付了:我们必须不知原因地把已有的TestSuite对象移植到”新的”类结构中。我们必须为数据库中所有已存在的TestSuite对象加上一个engineerID字段。除了把旧数据库中的对象复制到一个中间性的文件,然后重新创建一个数据库这种方法之外,我们还能怎么做呢?
幸运地是,使用db4o,我们确实什么都不用做。为了能操纵新的engineerID字段,以完成业务逻辑上所要求的变化,如果就只是向(我们的应用程序中的)TestSuite类添加一个engineerID字段,我们完全不必触动db4o API的任何调用。当db4o使用”新的”TestSuite类结构去读取”旧的”TestSuite对象,db4o将认为这些对象中的engineerID字段消失了,并且会优雅地把该字段的值设为0。如果我们把0当作”未记录QA工程师的ID”,那么我们所做的移植就完成了。写入到数据库中的新TestSuite对象将会包括新字段。(事实上,对旧的TestSuite对象本身进行重写,会使db4o不被察觉地为这些对象加上新字段。)所以,通过发布一个包含新的TestSuite定义的更新应用,我们完全可以不被察觉地从旧的TestSuite对象移植到新的…正如前述应用所做的那样。
全方位数据库
通过适当地应用,db4o就能成为数据库中的”瑞士军刀”。它占用足够小的内存空间,使它能够被包含在一个不需要消耗大量资源的项目中。同样地,一个数据库只在磁盘上占用一个文件的事实可能会使人们在第一眼看到它时,不能认识到它丰富的功能。将数据库从一个地方移到另一个地方就是一个简单的文件拷贝;你不必担心分离的索引文件,数据文件,数据库结构文件等等这些文件的位置。对于快速部署和零管理的数据库应用,db4o很能胜任。
另外,根据我们已多次描述过的,db4o在简单性和优雅之间达到了适度的平衡。db4o的QBE既如此的简单,又如此的功能强大,对于一组令人惊奇的应用,它经常是我们唯一需要的查询API。如果你主要是通过指针导航而不是查询去访问数据库,QBE就特别有吸引力。在这种情况下,QBE经常能高效地拿到一个对象网络(Object Network)的根对象。然后,你就能使用db4o的激活(activation)功能从根部向下进行对象引用导航,如果这些对象都完全在内存中的话,你就更可以这么做了。
而在使用QBE并不高效的时候,原生查询和S.O.D.A.就能派上用场了,并且它们伴随着一堆特性和低层次的API。我们还没有展示db4o的加密功能,插入式文件I/O(例如,它允许你添加”写后读(read-after-write)”验证),信号量,客户端/服务器端模式,以及其它难以计数的功能。我们结论性的建议很简单:当你的下一个Java应用需要一个数据库,在最终开始编码之前,你可以去访问一下http://www.db4objects.com/。这是很值得的。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/162578.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...

评论
#
re: 深入db4o(译) 2007-12-05 12:43
Sha Jiang
回复
更多评论
re: 深入db4o(译) 2007-12-05 12:46
sitinspring
回复
更多评论
re: 深入db4o(译) 2007-12-06 08:32
sitinspring
另外DB4O没有工具去查询已有数据库的对象是个遗憾.
回复
更多评论
re: 深入db4o(译) 2007-12-06 09:05
Sha Jiang
不明白何为”predicate式查询” :-)
不过,db4o的原生查询API中有一个类名为”Predicate”,不知是否为你所期望的。
详见”查询方式II – 原生查询(Native Query)”一节。
> 另外DB4O没有工具去查询已有数据库的对象是个遗憾.
ObjectManager,可以到如下链接中下载,
http://developer.db4o.com/files/folders/objectmanager_64/default.aspx
回复
更多评论
re: 深入db4o(译) 2007-12-06 16:46
sitinspring
好,再去看看.
回复
更多评论
re: 深入db4o(译) 2007-12-07 07:57
结下梁子
回复
更多评论
re: 深入db4o(译) 2007-12-07 08:53
Sha Jiang
下面的链接中有db4o的部分成功案例,
http://www.db4o.com/about/customers/success/
回复
更多评论
re: 深入db4o(译)
2011-07-14 09:03
tom.cat
怎么没人,有ECLIPSE插件
回复
更多评论