大家好,又见面了,我是你们的朋友全栈君。
文章目录
本文着重讲述经典BP神经网络的数学推导过程,并辅助一个小例子。本文不会介绍机器学习库(比如sklearn, TensorFlow等)的使用。 欲了解卷积神经网络的内容,请参见我的另一篇博客一文搞定卷积神经网络——从原理到应用。
本文难免会有叙述不合理的地方,希望读者可以在评论区反馈。我会及时吸纳大家的意见,并在之后的chat里进行说明。
本文参考了一些资料,在此一并列出。
- http://neuralnetworksanddeeplearning.com/chap2.html
- https://www.deeplearning.ai/ coursera对应课程视频讲义
- coursera华盛顿大学机器学习专项
- 周志华《机器学习》
- 李航《统计学习方法》
- 张明淳《工程矩阵理论》
0. 什么是人工神经网络?
首先给出一个经典的定义:“神经网络是由具有适应性的简单单元组成的广泛并行互连网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应”[Kohonen, 1988]。
这种说法虽然很经典,但是对于初学者并不是很友好。比如我在刚开始学习的时候就把人工神经网络想象地很高端,以至于很长一段时间都不能理解为什么神经网络能够起作用。类比最小二乘法线性回归问题,在求解数据拟合直线的时候,我们是采用某种方法让预测值和实际值的“偏差”尽可能小。同理,BP神经网络也做了类似的事情——即通过让“偏差”尽可能小,使得神经网络模型尽可能好地拟合数据集。
1. 神经网络初探
1.1 神经元模型
神经元模型是模拟生物神经元结构而被设计出来的。典型的神经元结构如下图1所示:
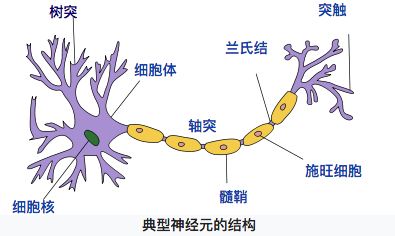

【图1 典型神经元结构 (图片来自维基百科)】
神经元大致可以分为树突、突触、细胞体和轴突。树突为神经元的输入通道,其功能是将其它神经元的动作电位传递至细胞体。其它神经元的动作电位借由位于树突分支上的多个突触传递至树突上。神经细胞可以视为有两种状态的机器,激活时为“是”,不激活时为“否”。神经细胞的状态取决于从其他神经细胞接收到的信号量,以及突触的性质(抑制或加强)。当信号量超过某个阈值时,细胞体就会被激活,产生电脉冲。电脉冲沿着轴突并通过突触传递到其它神经元。(内容来自维基百科“感知机”)
同理,我们的神经元模型就是为了模拟上述过程,典型的神经元模型如下:
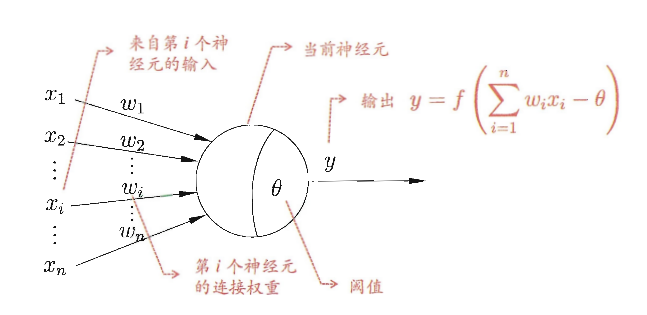
【图2 典型神经元模型结构 (摘自周志华老师《机器学习》第97页)】
这个模型中,每个神经元都接受来自其它神经元的输入信号,每个信号都通过一个带有权重的连接传递,神经元把这些信号加起来得到一个总输入值,然后将总输入值与神经元的阈值进行对比(模拟阈值电位),然后通过一个“激活函数”处理得到最终的输出(模拟细胞的激活),这个输出又会作为之后神经元的输入一层一层传递下去。
1.2 神经元激活函数
本文主要介绍2种激活函数,分别是 s i g m o i d sigmoid sigmoid和 r e l u relu relu函数,函数公式如下:
s i g m o i d ( z ) = 1 1 + e − z sigmoid(z)=\frac{1}{1+e^{-z}} sigmoid(z)=1+e−z1
r e l u ( z ) = { z z > 0 0 z ≤ 0 relu(z)= \left\{ \begin{array}{rcl} z & z>0\\ 0&z\leq0\end{array} \right. relu(z)={
z0z>0z≤0
做函数图如下:
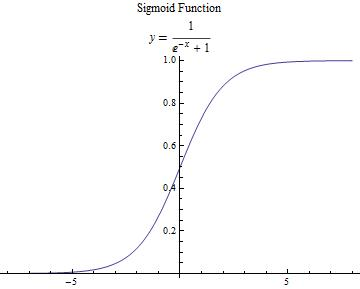
s i g m o i d ( z ) sigmoid(z) sigmoid(z)
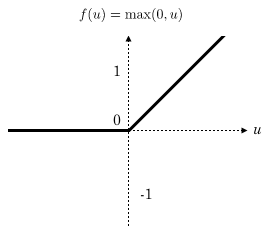
r e l u ( z ) relu(z) relu(z)
【图3 激活函数】
补充说明
【补充说明的内容建议在看完后文的反向传播部分之后再回来阅读,我只是为了文章结构的统一把这部分内容添加在了这里】引入激活函数的目的是在模型中引入非线性。如果没有激活函数,那么无论你的神经网络有多少层,最终都是一个线性映射,单纯的线性映射无法解决线性不可分问题。引入非线性可以让模型解决线性不可分问题。
一般来说,在神经网络的中间层更加建议使用 r e l u relu relu函数,两个原因:
- r e l u relu relu函数计算简单,可以加快模型速度;
- 由于反向传播过程中需要计算偏导数,通过求导可以得到 s i g m o i d sigmoid sigmoid函数导数的最大值为0.25,如果使用 s i g m o i d sigmoid sigmoid函数的话,每一层的反向传播都会使梯度最少变为原来的四分之一,当层数比较多的时候可能会造成梯度消失,从而模型无法收敛。
1.3 神经网络结构
我们使用如下神经网络结构来进行介绍,第0层是输入层(3个神经元), 第1层是隐含层(2个神经元),第2层是输出层:
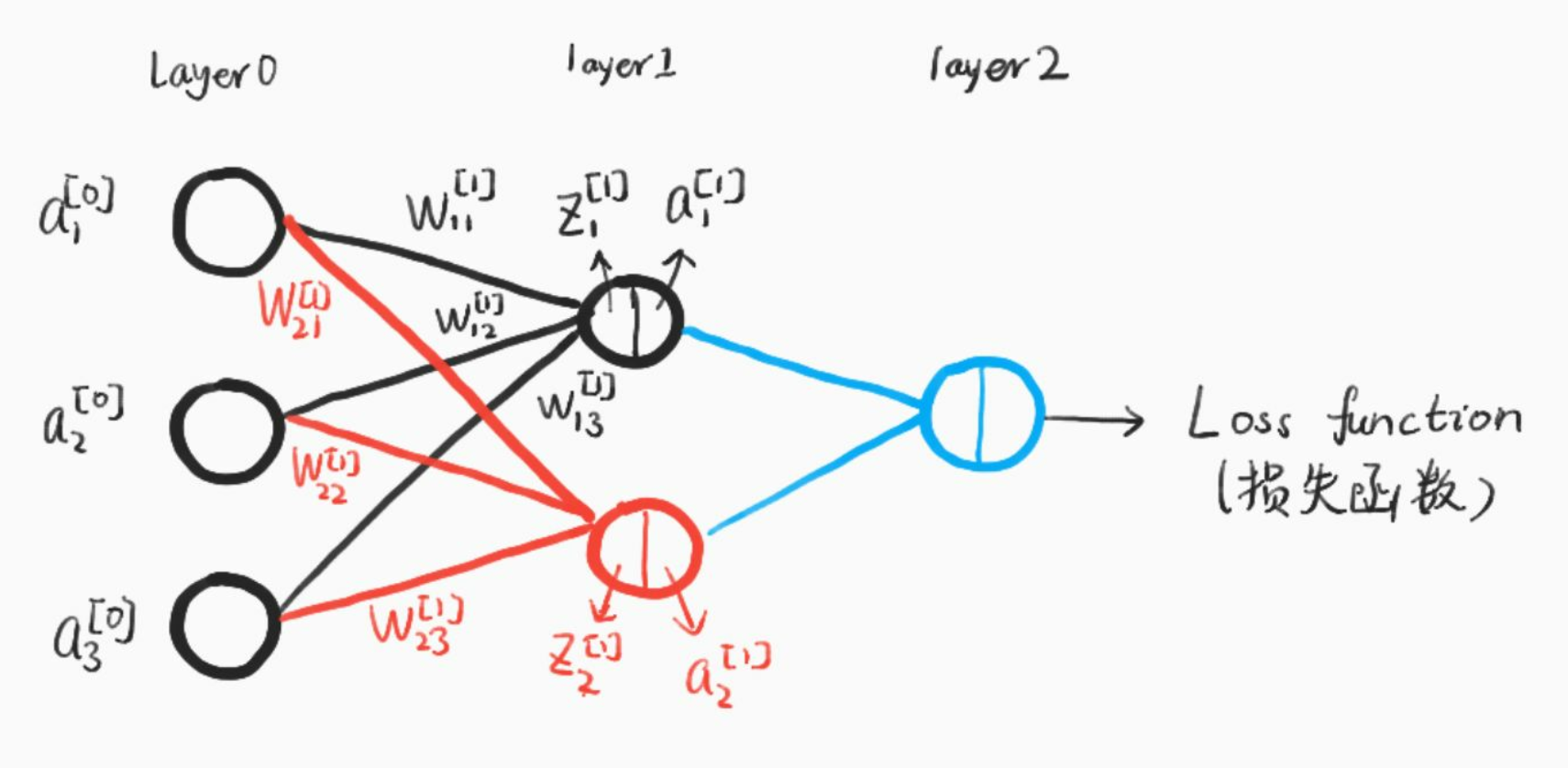
【图4 神经网络结构(手绘)】
我们使用以下符号约定, w j k [ l ] w_{jk}^{[l]} wjk[l]表示从网络第 ( l − 1 ) t h (l-1)^{th} (l−1)th中 k t h k^{th} kth个神经元指向第 l t h l^{th} lth中第 j t h j^{th} jth个神经元的连接权重,比如上图中 w 21 [ 1 ] w^{[1]}_{21} w21[1]即从第0层第1个神经元指向第1层第2个神经元的权重。同理,我们使用 b j [ l ] b^{[l]}_j bj[l]来表示第 l t h l^{th} lth层中第 j t h j^{th} jth神经元的偏差,用 z j [ l ] z^{[l]}_j zj[l]来表示第 l t h l^{th} lth层中第 j t h j^{th} jth神经元的线性结果,用 a j [ l ] a^{[l]}_j aj[l]来表示第 l t h l^{th} lth层中第 j t h j^{th} jth神经元的激活函数输出。
激活函数使用符号 σ \sigma σ表示,因此,第 l t h l^{th} lth层中第 j t h j^{th} jth神经元的激活为:
a j [ l ] = σ ( ∑ k w j k [ l ] a k [ l − 1 ] + b j [ l ] ) a^{[l]}_j=\sigma(\sum_kw^{[l]}_{jk}a^{[l-1]}_k+b^{[l]}_j) aj[l]=σ(k∑wjk[l]ak[l−1]+bj[l])
现在,我们使用矩阵形式重写这个公式:
定义 w [ l ] w^{[l]} w[l]表示权重矩阵,它的每一个元素表示一个权重,即每一行都是连接第 l l l层的权重,用上图举个例子就是:
w [ 1 ] = [ w 11 [ 1 ] w 12 [ 1 ] w 13 [ 1 ] w 21 [ 1 ] w 22 [ 1 ] w 23 [ 1 ] ] w^{[1]}=\left[ \begin{array}{cc} w_{11}^{[1]} & w_{12}^{[1]} & w_{13}^{[1]} \\ w_{21}^{[1]}& w_{22}^{[1]} & w_{23}^{[1]}\end{array}\right] w[1]=[w11[1]w21[1]w12[1]w22[1]w13[1]w23[1]]
同理,
b [ 1 ] = [ b 1 [ 1 ] b 2 [ 1 ] ] b^{[1]}=\left[ \begin{array}{cc}b^{[1]}_1 \\ b^{[1]}_2 \end{array}\right] b[1]=[b1[1]b2[1]]
z [ 1 ] = [ w 11 [ 1 ] w 12 [ 1 ] w 13 [ 1 ] w 21 [ 1 ] w 22 [ 1 ] w 23 [ 1 ] ] ⋅ [ a 1 [ 0 ] a 2 [ 0 ] a 3 [ 0 ] ] + [ b 1 [ 1 ] b 2 [ 1 ] ] = [ w 11 [ 1 ] a 1 [ 0 ] + w 12 [ 1 ] a 2 [ 0 ] + w 13 [ 1 ] a 3 [ 0 ] + b 1 [ 1 ] w 21 [ 1 ] a 1 [ 0 ] + w 22 [ 1 ] a 2 [ 0 ] + w 23 [ 1 ] a 3 [ 0 ] + b 2 [ 1 ] ] z^{[1]}=\left[ \begin{array}{cc} w_{11}^{[1]} & w_{12}^{[1]} & w_{13}^{[1]} \\ w_{21}^{[1]}& w_{22}^{[1]} & w_{23}^{[1]}\end{array}\right]\cdot \left[ \begin{array}{cc} a^{[0]}_1 \\ a^{[0]}_2 \\ a^{[0]}_3 \end{array}\right] +\left[ \begin{array}{cc}b^{[1]}_1 \\ b^{[1]}_2 \end{array}\right]=\left[ \begin{array}{cc} w_{11}^{[1]}a^{[0]}_1+w_{12}^{[1]}a^{[0]}_2+w_{13}^{[1]}a^{[0]}_3+b^{[1]}_1 \\ w^{[1]}_{21}a^{[0]}_1+w_{22}^{[1]}a^{[0]}_2+w_{23}^{[1]}a^{[0]}_3+b^{[1]}_2\end{array}\right] z[1]=[w11[1]w21[1]w12[1]w22[1]w13[1]w23[1]]⋅⎣⎢⎡a1[0]a2[0]a3[0]⎦⎥⎤+[b1[1]b2[1]]=[w11[1]a1[0]+w12[1]a2[0]+w13[1]a3[0]+b1[1]w21[1]a1[0]+w22[1]a2[0]+w23[1]a3[0]+b2[1]]
更一般地,我们可以把前向传播过程表示:
a [ l ] = σ ( w [ l ] a [ l − 1 ] + b [ l ] ) a^{[l]}=\sigma(w^{[l]}a^{[l-1]}+b^{[l]}) a[l]=σ(w[l]a[l−1]+b[l])
到这里,我们已经讲完了前向传播的过程,值得注意的是,这里我们只有一个输入样本,对于多个样本同时输入的情况是一样的,只不过我们的输入向量不再是一列,而是m列,每一个都表示一个输入样本。
多样本输入情况下的表示为:
Z [ l ] = w [ l ] ⋅ A [ l − 1 ] + b [ l ] Z^{[l]}=w^{[l]}\cdot A^{[l-1]}+b^{[l]} Z[l]=w[l]⋅A[l−1]+b[l]
A [ l ] = σ ( Z [ l ] ) A^{[l]}=\sigma(Z^{[l]}) A[l]=σ(Z[l])
其中,此时 A [ l − 1 ] = [ ∣ ∣ … ∣ a [ l − 1 ] ( 1 ) a [ l − 1 ] ( 2 ) … a [ l − 1 ] ( m ) ∣ ∣ … ∣ ] A^{[l-1]}=\left[ \begin{array}{cc} |&|&\ldots&| \\a^{[l-1](1)}&a^{[l-1](2)}&\ldots&a^{[l-1](m)} \\ |&|&\ldots&|\end{array}\right] A[l−1]=⎣⎡∣a[l−1](1)∣∣a[l−1](2)∣………∣a[l−1](m)∣⎦⎤
每一列都表示一个样本,从样本1到m
w [ l ] w^{[l]} w[l]的含义和原来完全一样, Z [ l ] Z^{[l]} Z[l]也会变成m列,每一列表示一个样本的计算结果。
之后我们的叙述都是先讨论单个样本的情况,再扩展到多个样本同时计算。
2. 损失函数和代价函数
说实话,**损失函数(Loss Function)和代价函数(Cost Function)**并没有一个公认的区分标准,很多论文和教材似乎把二者当成了差不多的东西。
为了后面描述的方便,我们把二者稍微做一下区分(这里的区分仅仅对本文适用,对于其它的文章或教程需要根据上下文自行判断含义):
损失函数主要指的是对于单个样本的损失或误差;代价函数表示多样本同时输入模型的时候总体的误差——每个样本误差的和然后取平均值。
举个例子,如果我们把单个样本的损失函数定义为:
L ( a , y ) = − [ y ⋅ l o g ( a ) + ( 1 − y ) ⋅ l o g ( 1 − a ) ] L(a,y)=-[y \cdot log(a)+(1-y)\cdot log(1-a)] L(a,y)=−[y⋅log(a)+(1−y)⋅log(1−a)]
那么对于m个样本,代价函数则是:
C = − 1 m ∑ i = 0 m ( y ( i ) ⋅ l o g ( a ( i ) ) + ( 1 − y ( i ) ) ⋅ l o g ( 1 − a ( i ) ) ) C=-\frac{1}{m}\sum_{i=0}^m(y^{(i)}\cdot log(a^{(i)})+(1-y^{(i)})\cdot log(1-a^{(i)})) C=−m1i=0∑m(y(i)⋅log(a(i))+(1−y(i))⋅log(1−a(i)))
3. 反向传播
反向传播的基本思想就是通过计算输出层与期望值之间的误差来调整网络参数,从而使得误差变小。
反向传播的思想很简单,然而人们认识到它的重要作用却经过了很长的时间。后向传播算法产生于1970年,但它的重要性一直到David Rumelhart,Geoffrey Hinton和Ronald Williams于1986年合著的论文发表才被重视。
事实上,人工神经网络的强大力量几乎就是建立在反向传播算法基础之上的。反向传播基于四个基础等式,数学是优美的,仅仅四个等式就可以概括神经网络的反向传播过程,然而理解这种优美可能需要付出一些脑力。事实上,反向传播如此之难,以至于相当一部分初学者很难进行独立推导。所以如果读者是初学者,希望读者可以耐心地研读本节。对于初学者,我觉得拿出1-3个小时来学习本小节是比较合适的,当然,对于熟练掌握反向传播原理的读者,你可以在十几分钟甚至几分钟之内快速浏览本节的内容。
3.1 矩阵补充知识
对于大部分理工科的研究生,以及学习过矩阵论或者工程矩阵理论相关课程的读者来说,可以跳过本节。
本节主要面向只学习过本科线性代数课程或者已经忘记矩阵论有关知识的读者。
总之,具备了本科线性代数知识的读者阅读这一小节应该不会有太大问题。本节主要在线性代数的基础上做一些扩展。(不排除少数本科线性代数课程也涉及到这些内容,如果感觉讲的简单的话,勿喷)
3.1.1 求梯度矩阵
假设函数 f : R m × n → R f:R^{m\times n}\rightarrow R f:Rm×n→R可以把输入矩阵(shape: m × n m\times n m×n)映射为一个实数。那么,函数 f f f的梯度定义为:
∇ A f ( A ) = [ ∂ f ( A ) ∂ A 11 ∂ f ( A ) ∂ A 12 … ∂ f ( A ) ∂ A 1 n ∂ f ( A ) ∂ A 21 ∂ f ( A ) ∂ A 22 … ∂ f ( A ) ∂ A 2 n ⋮ ⋮ ⋱ ⋮ ∂ f ( A ) ∂ A m 1 ∂ f ( A ) ∂ A m 2 … ∂ f ( A ) ∂ A m n ] \nabla_Af(A)=\left[ \begin{array}{cc} \frac{\partial f(A)}{\partial A_{11}}&\frac{\partial f(A)}{\partial A_{12}}&\ldots&\frac{\partial f(A)}{\partial A_{1n}} \\ \frac{\partial f(A)}{\partial A_{21}}&\frac{\partial f(A)}{\partial A_{22}}&\ldots&\frac{\partial f(A)}{\partial A_{2n}} \\\vdots &\vdots &\ddots&\vdots\\ \frac{\partial f(A)}{\partial A_{m1}}&\frac{\partial f(A)}{\partial A_{m2}}&\ldots&\frac{\partial f(A)}{\partial A_{mn}}\end{array}\right] ∇Af(A)=⎣⎢⎢⎢⎢⎡∂A11∂f(A)∂A21∂f(A)⋮∂Am1∂f(A)∂A12∂f(A)∂A22∂f(A)⋮∂Am2∂f(A)……⋱…∂A1n∂f(A)∂A2n∂f(A)⋮∂Amn∂f(A)⎦⎥⎥⎥⎥⎤
即 ( ∇ A f ( A ) ) i j = ∂ f ( A ) ∂ A i j (\nabla_Af(A))_{ij}=\frac{\partial f(A)}{\partial A_{ij}} (∇Af(A))ij=∂Aij∂f(A)
同理,一个输入是向量(向量一般指列向量,本文在没有特殊声明的情况下默认指的是列向量)的函数 f : R n × 1 → R f:R^{n\times 1}\rightarrow R f:Rn×1→R,则有:
∇ x f ( x ) = [ ∂ f ( x ) ∂ x 1 ∂ f ( x ) ∂ x 2 ⋮ ∂ f ( x ) ∂ x n ] \nabla_xf(x)=\left[ \begin{array}{cc}\frac{\partial f(x)}{\partial x_1}\\ \frac{\partial f(x)}{\partial x_2}\\ \vdots \\ \frac{\partial f(x)}{\partial x_n} \end{array}\right] ∇xf(x)=⎣⎢⎢⎢⎢⎡∂x1∂f(x)∂x2∂f(x)⋮∂xn∂f(x)⎦⎥⎥⎥⎥⎤
注意:这里涉及到的梯度求解的前提是函数 f f f 返回的是一个实数,如果函数返回的是一个矩阵或者向量,那么我们是没有办法求梯度的。比如,对函数 f ( A ) = ∑ i = 0 m ∑ j = 0 n A i j 2 f(A)=\sum_{i=0}^m\sum_{j=0}^nA_{ij}^2 f(A)=∑i=0m∑j=0nAij2,由于返回一个实数,我们可以求解梯度矩阵。如果 f ( x ) = A x ( A ∈ R m × n , x ∈ R n × 1 ) f(x)=Ax (A\in R^{m\times n}, x\in R^{n\times 1}) f(x)=Ax(A∈Rm×n,x∈Rn×1),由于函数返回一个 m m m行1列的向量,因此不能对 f f f求梯度矩阵。
根据定义,很容易得到以下性质:
∇ x ( f ( x ) + g ( x ) ) = ∇ x f ( x ) + ∇ x g ( x ) \nabla_x(f(x)+g(x))=\nabla_xf(x)+\nabla_xg(x) ∇x(f(x)+g(x))=∇xf(x)+∇xg(x)
∇ ( t f ( x ) ) = t ∇ f ( x ) , t ∈ R \nabla(tf(x))=t\nabla f(x), t\in R ∇(tf(x))=t∇f(x),t∈R
有了上述知识,我们来举个例子:
定义函数 f : R m → R , f ( z ) = z T z f:R^m\rightarrow R, f(z)=z^Tz f:Rm→R,f(z)=zTz,那么很容易得到 ∇ z f ( z ) = 2 z \nabla_zf(z)=2z ∇zf(z)=2z,具体请读者自己证明。
3.1.2 海塞矩阵
定义一个输入为 n n n维向量,输出为实数的函数 f : R n → R f:R^n\rightarrow R f:Rn→R,那么海塞矩阵(Hessian Matrix)定义为多元函数 f f f的二阶偏导数构成的方阵:
∇ x 2 f ( x ) = [ ∂ 2 f ( x ) ∂ x 1 2 ∂ 2 f ( x ) ∂ x 1 ∂ x 2 … ∂ 2 f ( x ) ∂ x 1 ∂ x n ∂ 2 f ( x ) ∂ x 2 ∂ x 1 ∂ 2 f ( x ) ∂ x 2 2 … ∂ 2 f ( x ) ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ( x ) ∂ x n ∂ x 1 ∂ 2 f ( x ) ∂ x n ∂ x 2 … ∂ 2 f ( x ) ∂ x n 2 ] \nabla^2_xf(x)=\left[ \begin{array}{cc} \frac{\partial^2f(x)}{\partial x_1^2}&\frac{\partial^2f(x)}{\partial x_1\partial x_2}&\ldots &\frac{\partial^2f(x)}{\partial x_1\partial x_n}\\ \frac{\partial^2f(x)}{\partial x_2\partial x_1}&\frac{\partial^2f(x)}{\partial x_2^2}&\ldots&\frac{\partial^2f(x)}{\partial x_2\partial x_n}\\ \vdots&\vdots&\ddots&\vdots\\\frac{\partial^2f(x)}{\partial x_n\partial x_1}&\frac{\partial^2f(x)}{\partial x_n\partial x_2}&\ldots&\frac{\partial^2f(x)}{\partial x_n^2}\end{array}\right] ∇x2f(x)=⎣⎢⎢⎢⎢⎢⎡∂x12∂2f(x)∂x2∂x1∂2f(x)⋮∂xn∂x1∂2f(x)∂x1∂x2∂2f(x)∂x22∂2f(x)⋮∂xn∂x2∂2f(x)……⋱…∂x1∂xn∂2f(x)∂x2∂xn∂2f(x)⋮∂xn2∂2f(x)⎦⎥⎥⎥⎥⎥⎤
由上式可以看出,海塞矩阵总是对称阵。
注意:很多人把海塞矩阵看成 ∇ x f ( x ) \nabla _xf(x) ∇xf(x)的导数,这是不对的。只能说,海塞矩阵的每个元素都是函数 f f f二阶偏导数。那么,有什么区别呢?
首先,来看正确的解释。**海塞矩阵的每个元素是函数 f f f的二阶偏导数。**拿 ∂ 2 f ( x ) ∂ x 1 ∂ x 2 \frac{\partial^2f(x)}{\partial x_1\partial x_2} ∂x1∂x2∂2f(x)举个例子,函数 f f f对 x 1 x_1 x1求偏导得到的是一个实数,比如 ∂ 2 f ( x ) ∂ x 1 = x 2 3 x 1 \frac{\partial^2f(x)}{\partial x_1}=x_2^3x_1 ∂x1∂2f(x)=x23x1,因此继续求偏导是有意义的,继续对 x 2 x_2 x2求偏导可以得到 3 x 1 x 2 2 3x_1x_2^2 3x1x22。
然后,来看一下错误的理解。把海塞矩阵看成 ∇ x f ( x ) \nabla _xf(x) ∇xf(x)的导数,也就是说错误地以为 ∇ x 2 f ( x ) = ∇ x ( ∇ x f ( x ) ) \nabla^2_xf(x)=\nabla_x(\nabla_xf(x)) ∇x2f(x)=∇x(∇xf(x)),要知道, ∇ x f ( x ) \nabla_xf(x) ∇xf(x)是一个向量,而在上一小节我们已经重点强调过,在我们的定义里对向量求偏导是没有定义的。
但是 ∇ x ∂ f ( x ) ∂ x i \nabla_x\frac{\partial f(x)}{\partial x_i} ∇x∂xi∂f(x)是有意义的,因为 ∂ f ( x ) ∂ x i \frac{\partial f(x)}{\partial x_i} ∂xi∂f(x)是一个实数,具体地:
∇ x ∂ f ( x ) ∂ x i = [ ∂ 2 f ( x ) ∂ x i ∂ x 1 ∂ 2 f ( x ) ∂ x i ∂ x 2 ⋮ ∂ 2 f ( x ) ∂ x i ∂ x n ] \nabla_x\frac{\partial f(x)}{\partial x_i}=\left[ \begin{array}{cc} \frac{\partial^2f(x)}{\partial x_i\partial x_1}\\\frac{\partial^2f(x)}{\partial x_i\partial x_2}\\\vdots\\\frac{\partial^2f(x)}{\partial x_i\partial x_n}\end{array}\right] ∇x∂xi∂f(x)=⎣⎢⎢⎢⎢⎢⎡∂xi∂x1∂2f(x)∂xi∂x2∂2f(x)⋮∂xi∂xn∂2f(x)⎦⎥⎥⎥⎥⎥⎤
即海塞矩阵的第i行(或列)。
希望读者可以好好区分。
3.1.3 总结
根据3.1.1和3.1.2小节的内容很容易得到以下等式:
b ∈ R n , x ∈ R n , A ∈ R n × n 并 且 A 是 对 称 矩 阵 b\in R^{n}, x\in R^n, A\in R^{n\times n}并且A 是对称矩阵 b∈Rn,x∈Rn,A∈Rn×n并且A是对称矩阵
b , x b,x b,x均为列向量
那么,
∇ x b T x = b \nabla_xb^Tx=b ∇xbTx=b
∇ x x T A x = 2 A x ( A 是 对 称 阵 ) \nabla_xx^TAx=2Ax(A是对称阵) ∇xxTAx=2Ax(A是对称阵)
∇ x 2 x T A x = 2 A ( A 是 对 称 阵 ) \nabla^2_xx^TAx=2A(A是对称阵) ∇x2xTAx=2A(A是对称阵)这些公式可以根据前述定义自行推导,有兴趣的读者可以自己推导一下。
####3.2 矩阵乘积和对应元素相乘
在下一节讲解反向传播原理的时候,尤其是把公式以矩阵形式表示的时候,需要大家时刻区分什么时候需要矩阵相乘,什么时候需要对应元素相乘。
比如对于矩阵 A = [ 1 2 3 4 ] , 矩 阵 B = [ − 1 − 2 − 3 − 4 ] A=\left[ \begin{array}{cc} 1&2\\3&4\end{array}\right],矩阵B=\left[ \begin{array}{cc} -1&-2\\-3&-4\end{array}\right] A=[1324],矩阵B=[−1−3−2−4]
矩阵相乘
A B = [ 1 × − 1 + 2 × − 3 1 × − 2 + 2 × − 4 3 × − 1 + 4 × − 3 3 × − 2 + 4 × − 4 ] = [ − 7 − 10 − 15 − 22 ] AB=\left[\begin{array}{cc}1\times -1+2\times -3&1\times -2+2\times -4\\3\times -1+4\times -3&3\times -2+4\times -4\end{array}\right]=\left[\begin{array}{cc}-7&-10\\-15&-22\end{array}\right] AB=[1×−1+2×−33×−1+4×−31×−2+2×−43×−2+4×−4]=[−7−15−10−22]
对应元素相乘使用符号 ⊙ \odot ⊙表示:
A ⊙ B = [ 1 × − 1 2 × − 2 3 × − 3 4 × − 4 ] = [ − 1 − 4 − 9 − 16 ] A\odot B=\left[\begin{array}{cc}1\times -1&2\times -2 \\ 3\times -3&4\times -4\end{array}\right]=\left[\begin{array}{cc}-1&-4 \\ -9&-16\end{array}\right] A⊙B=[1×−13×−32×−24×−4]=[−1−9−4−16]
3.3 梯度下降法原理
通过之前的介绍,相信大家都可以自己求解梯度矩阵(向量)了。
那么梯度矩阵(向量)求出来的意义是什么?从几何意义讲,梯度矩阵代表了函数增加最快的方向,因此,沿着与之相反的方向就可以更快找到最小值。如图5所示:
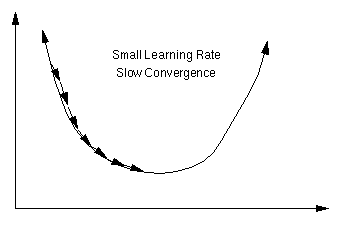
【图5 梯度下降法 图片来自百度】
反向传播的过程就是利用梯度下降法原理,慢慢的找到代价函数的最小值,从而得到最终的模型参数。梯度下降法在反向传播中的具体应用见下一小节。
3.4 反向传播原理(四个基础等式)
反向传播能够知道如何更改网络中的权重 w w w 和偏差 b b b 来改变代价函数值。最终这意味着它能够计算偏导数 ∂ L ( a [ l ] , y ) ∂ w j k [ l ] \frac{\partial L(a^{[l]},y)} {\partial w^{[l]}_{jk}} ∂wjk[l]∂L(a[l],y) 和 ∂ L ( a [ l ] , y ) ∂ b j [ l ] \frac{\partial L(a^{[l]},y)}{\partial b^{[l]}_j} ∂bj[l]∂L(a[l],y)
为了计算这些偏导数,我们首先引入一个中间变量 δ j [ l ] \delta^{[l]}_j δj[l],我们把它叫做网络中第 l t h l^{th} lth层第 j t h j^{th} jth个神经元的误差。后向传播能够计算出误差 δ j [ l ] \delta^{[l]}_j δj[l],然后再将其对应回 ∂ L ( a [ l ] , y ) ∂ w j k [ l ] \frac{\partial L(a^{[l]},y)}{\partial w^{[l]}_{jk}} ∂wjk[l]∂L(a[l],y)和 ∂ L ( a [ l ] , y ) ∂ b j [ l ] \frac{\partial L(a^{[l]},y)}{\partial b^{[l]}_j} ∂bj[l]∂L(a[l],y) 。
那么,如何定义每一层的误差呢?如果为第 l l l 层第 j j j 个神经元添加一个扰动 Δ z j [ l ] \Delta z^{[l]}_j Δzj[l],使得损失函数或者代价函数变小,那么这就是一个好的扰动。通过选择 Δ z j [ l ] \Delta z^{[l]}_j Δzj[l]与 ∂ L ( a [ l ] , y ) ∂ z j [ l ] \frac{\partial L(a^{[l]}, y)}{\partial z^{[l]}_j} ∂zj[l]∂L(a[l],y)符号相反(梯度下降法原理),就可以每次都添加一个好的扰动最终达到最优。
受此启发,我们定义网络层第 l l l 层中第 j j j 个神经元的误差为 δ j [ l ] \delta^{[l]}_j δj[l]:
δ j [ l ] = ∂ L ( a [ L ] , y ) ∂ z j [ l ] \delta^{[l]}_j=\frac{\partial L(a^{[L], y})}{\partial z^{[l]}_j} δj[l]=∂zj[l]∂L(a[L],y)
于是,每一层的误差向量可以表示为:
δ [ l ] = [ δ 1 [ l ] δ 2 [ l ] ⋮ δ n [ l ] ] \delta ^{[l]}=\left[\begin{array}{cc}\delta ^{[l]}_1\\\delta ^{[l]}_2\\ \vdots \\ \delta ^{[l]}_n\end{array} \right] δ[l]=⎣⎢⎢⎢⎢⎡δ1[l]δ2[l]⋮δn[l]⎦⎥⎥⎥⎥⎤
下面开始正式介绍四个基础等式【确切的说是四组等式】
**注意:**这里我们的输入为单个样本(所以我们在下面的公式中使用的是损失函数而不是代价函数)。多个样本输入的公式会在介绍完单个样本后再介绍。
- 等式1 :输出层误差
δ j [ L ] = ∂ L ∂ a j [ L ] σ ′ ( z j [ L ] ) \delta^{[L]}_j=\frac{\partial L}{\partial a^{[L]}_j}\sigma^{'}(z^{[L]}_j) δj[L]=∂aj[L]∂Lσ′(zj[L])
其中, L L L表示输出层层数。以下用 ∂ L \partial L ∂L 表示 ∂ L ( a [ L ] , y ) \partial L(a^{[L]}, y) ∂L(a[L],y)
写成矩阵形式是:
δ [ L ] = ∇ a L ⊙ σ ′ ( z [ L ] ) \delta^{[L]}=\nabla _aL\odot \sigma^{'}(z^{[L]}) δ[L]=∇aL⊙σ′(z[L])
【注意是对应元素相乘,想想为什么?】
说明
根据本小节开始时的叙述,我们期望找到 ∂ L / ∂ z j [ l ] \partial L \ /\partial z^{[l]}_j ∂L /∂zj[l],然后朝着方向相反的方向更新网络参数,并定义误差为:
δ j [ L ] = ∂ L ∂ z j [ L ] \delta^{[L]}_j=\frac{\partial L}{\partial z^{[L]}_j} δj[L]=∂zj[L]∂L
根据链式法则,
δ j [ L ] = ∑ k ∂ L ∂ a k [ L ] ∂ a k [ L ] ∂ z j [ L ] \delta^{[L]}_j = \sum_k \frac{\partial L}{\partial a^{[L]}_k} \frac{\partial a^{[L]}_k}{\partial z^{[L]}_j} δj[L]=k∑∂ak[L]∂L∂zj[L]∂ak[L]
当 k ≠ j k\neq j k̸=j时, ∂ a k [ L ] / ∂ z j [ L ] \partial a^{[L]}_k / \partial z^{[L]}_j ∂ak[L]/∂zj[L]就为零。结果我们可以简化之前的等式为
δ j [ L ] = ∂ L ∂ a j [ L ] ∂ a j [ L ] ∂ z j [ L ] \delta^{[L]}_j = \frac{\partial L}{\partial a^{[L]}_j} \frac{\partial a^{[L]}_j}{\partial z^{[L]}_j} δj[L]=∂aj[L]∂L∂zj[L]∂aj[L]
重新拿出定义: a j [ L ] = σ ( z j [ L ] ) a^{[L]}_j = \sigma(z^{[L]}_j) aj[L]=σ(zj[L]),就可以得到:
δ j [ L ] = ∂ L ∂ a j [ L ] σ ′ ( z j [ L ] ) \delta^{[L]}_j = \frac{\partial L}{\partial a^{[L]}_j} \sigma'(z^{[L]}_j) δj[L]=∂aj[L]∂Lσ′(zj[L])
再”堆砌”成向量形式就得到了我们的矩阵表示式(这也是为什么使用矩阵形式表示需要 对应元素相乘 的原因)。
- 等式2: 隐含层误差
δ j [ l ] = ∑ k w k j [ l + 1 ] δ k [ l + 1 ] σ ′ ( z j [ l ] ) \delta^{[l]}_j = \sum_k w^{[l+1]}_{kj} \delta^{[l+1]}_k \sigma'(z^{[l]}_j) δj[l]=k∑wkj[l+1]δk[l+1]σ′(zj[l])
写成矩阵形式:
δ [ l ] = [ w [ l + 1 ] T δ [ l + 1 ] ] ⊙ σ ′ ( z [ l ] ) \delta^{[l]}=[w^{[l+1]T}\delta^{[l+1]}]\odot \sigma ^{'}(z^{[l]}) δ[l]=[w[l+1]Tδ[l+1]]⊙σ′(z[l])
说明:
z k [ l + 1 ] = ∑ j w k j [ l + 1 ] a j [ l ] + b k [ l + 1 ] = ∑ j w k j [ l + 1 ] σ ( z j [ l ] ) + b k [ l + 1 ] z^{[l+1]}_k=\sum_jw^{[l+1]}_{kj}a^{[l]}_j+b^{[l+1]}_k=\sum_jw^{[l+1]}_{kj}\sigma(z^{[l]}_j)+b^{[l+1]}_k zk[l+1]=j∑wkj[l+1]aj[l]+bk[l+1]=j∑wkj[l+1]σ(zj[l])+bk[l+1]
进行偏导可以获得:
∂ z k [ l + 1 ] ∂ z j [ l ] = w k j [ l + 1 ] σ ′ ( z j [ l ] ) \frac{\partial z^{[l+1]}_k}{\partial z^{[l]}_j} = w^{[l+1]}_{kj} \sigma'(z^{[l]}_j) ∂zj[l]∂zk[l+1]=wkj[l+1]σ′(zj[l])
代入得到:
δ j [ l ] = ∑ k w k j [ l + 1 ] δ k [ l + 1 ] σ ′ ( z j [ l ] ) \delta^{[l]}_j = \sum_k w^{[l+1]}_{kj} \delta^{[l+1]}_k \sigma'(z^{[l]}_j) δj[l]=k∑wkj[l+1]δk[l+1]σ′(zj[l])
- 等式3:参数变化率
∂ L ∂ b j [ l ] = δ j [ l ] \frac{\partial L}{\partial b^{[l]}_j}=\delta^{[l]}_j ∂bj[l]∂L=δj[l]
∂ L ∂ w j k [ l ] = a k [ l − 1 ] δ j [ l ] \frac{\partial L}{\partial w^{[l]}_{jk}}=a^{[l-1]}_k\delta^{[l]}_j ∂wjk[l]∂L=ak[l−1]δj[l]
写成矩阵形式:
∂ L ∂ b [ l ] = δ [ l ] \frac{\partial L}{\partial b^{[l]}}=\delta^{[l]} ∂b[l]∂L=δ[l] ∂ L ∂ w [ l ] = δ [ l ] a [ l − 1 ] T \frac{\partial L}{\partial w^{[l]}}=\delta^{[l]}a^{[l-1]T} ∂w[l]∂L=δ[l]a[l−1]T
说明:
根据链式法则推导。
由于
z j [ l ] = ∑ k w j k [ l ] a k [ l ] + b k [ l ] z^{[l]}_j=\sum_kw^{[l]}_{jk}a^{[l]}_k+b^{[l]}_k zj[l]=k∑wjk[l]ak[l]+bk[l]
对 b j [ l ] b^{[l]}_j bj[l]求偏导得到:
∂ L ∂ b j [ l ] = ∂ L ∂ z j [ l ] ∂ z j [ l ] b j [ l ] = δ j [ l ] \frac{\partial L}{\partial b^{[l]}_j}=\frac{\partial L}{\partial z^{[l]}_j}\frac{\partial z^{[l]}_j}{b^{[l]}_j}=\delta^{[l]}_j ∂bj[l]∂L=∂zj[l]∂Lbj[l]∂zj[l]=δj[l]
对 w j k [ l ] w^{[l]}_{jk} wjk[l]求偏导得到:
∂ L ∂ w j k [ l ] = ∂ L ∂ z j [ l ] ∂ z j [ l ] w j k [ l ] = a k [ l − 1 ] δ j [ l ] \frac{\partial L}{\partial w^{[l]}_{jk}}=\frac{\partial L}{\partial z^{[l]}_j}\frac{\partial z^{[l]}_j}{w^{[l]}_{jk}}=a^{[l-1]}_k\delta^{[l]}_j ∂wjk[l]∂L=∂zj[l]∂Lwjk[l]∂zj[l]=ak[l−1]δj[l]
最后再变成矩阵形式就好了。对矩阵形式来说,需要特别注意维度的匹配。强烈建议读者在自己编写程序之前,先列出这些等式,然后仔细检查维度是否匹配。
很容易看出 ∂ L ∂ w [ l ] \frac{\partial L}{\partial w^{[l]}} ∂w[l]∂L是一个 d i m ( δ [ l ] ) dim(\delta^{[l]}) dim(δ[l])行 d i m ( a [ l − 1 ] ) dim(a^{[l-1]}) dim(a[l−1])列的矩阵,和 w [ l ] w^{[l]} w[l]的维度一致; ∂ L ∂ b [ l ] \frac{\partial L}{\partial b^{[l]}} ∂b[l]∂L是一个维度为 d i m ( δ [ l ] ) dim(\delta^{[l]}) dim(δ[l])的列向量
- 等式4:参数更新规则
这应该是这四组公式里最简单的一组了,根据梯度下降法原理,朝着梯度的反方向更新参数:
b j [ l ] ← b j [ l ] − α ∂ L ∂ b j [ l ] b^{[l]}_j\leftarrow b^{[l]}_j-\alpha \frac{\partial L}{\partial b^{[l]}_j} bj[l]←bj[l]−α∂bj[l]∂L
w j k [ l ] ← w j k [ l ] − α ∂ L ∂ w j k [ l ] w^{[l]}_{jk}\leftarrow w^{[l]}_{jk}-\alpha\frac{\partial L}{\partial w^{[l]}_{jk}} wjk[l]←wjk[l]−α∂wjk[l]∂L
写成矩阵形式:
b [ l ] ← b [ l ] − α ∂ L ∂ b [ l ] b^{[l]}\leftarrow b^{[l]}-\alpha\frac{\partial L}{\partial b^{[l]}} b[l]←b[l]−α∂b[l]∂L
w [ l ] ← w [ l ] − α ∂ L ∂ w [ l ] w^{[l]}\leftarrow w^{[l]}-\alpha\frac{\partial L}{\partial w^{[l]}} w[l]←w[l]−α∂w[l]∂L
这里的 α \alpha α指的是学习率。学习率指定了反向传播过程中梯度下降的步长。
3.5 反向传播总结
我们可以得到如下最终公式:
3.5.1 单样本输入公式表
| 说明 | 公式 | 备注 |
|---|---|---|
| 输出层误差 | δ [ L ] = ∇ a L ⊙ σ ′ ( z [ L ] ) \delta^{[L]}=\nabla _aL\odot \sigma^{'}(z^{[L]}) δ[L]=∇aL⊙σ′(z[L]) | |
| 隐含层误差 | δ [ l ] = [ w [ l + 1 ] T δ [ l + 1 ] ] ⊙ σ ′ ( z [ l ] ) \delta^{[l]}=[w^{[l+1]T}\delta^{[l+1]}]\odot \sigma ^{'}(z^{[l]}) δ[l]=[w[l+1]Tδ[l+1]]⊙σ′(z[l]) | |
| 参数变化率 | ∂ L ∂ b [ l ] = δ [ l ] \frac{\partial L}{\partial b^{[l]}}=\delta^{[l]} ∂b[l]∂L=δ[l] ∂ L ∂ w [ l ] = δ [ l ] a [ l − 1 ] T \frac{\partial L}{\partial w^{[l]}}=\delta^{[l]}a^{[l-1]T} ∂w[l]∂L=δ[l]a[l−1]T | 注意维度匹配 |
| 参数更新 | b [ l ] ← b [ l ] − α ∂ L ∂ b [ l ] b^{[l]}\leftarrow b^{[l]}-\alpha\frac{\partial L}{\partial b^{[l]}} b[l]←b[l]−α∂b[l]∂L w [ l ] ← w [ l ] − α ∂ L ∂ w [ l ] w^{[l]}\leftarrow w^{[l]}-\alpha\frac{\partial L}{\partial w^{[l]}} w[l]←w[l]−α∂w[l]∂L | α \alpha α是学习率 |
3.5.2 多样本输入公式表
多样本:需要使用代价函数,如果有m个样本,那么由于代价函数有一个 1 m \frac{1}{m} m1的常数项,因此所有的参数更新规则都需要有一个 1 m \frac{1}{m} m1的前缀。
多样本同时输入的时候需要格外注意维度匹配,一开始可能觉得有点混乱,但是不断加深理解就会豁然开朗。
| 说明 | 公式 | 备注 |
|---|---|---|
| 输出层误差 | d Z [ L ] = ∇ A C ⊙ σ ′ ( Z [ L ] ) dZ^{[L]}=\nabla _AC\odot \sigma^{'}(Z^{[L]}) dZ[L]=∇AC⊙σ′(Z[L]) | 此时 d Z [ l ] dZ^{[l]} dZ[l]不再是一个列向量,变成了一个 m m m列的矩阵,每一列都对应一个样本的向量 |
| 隐含层误差 | d Z [ l ] = [ w [ l + 1 ] T d Z [ l + 1 ] ] ⊙ σ ′ ( Z [ l ] ) dZ^{[l]}=[w^{[l+1]T}dZ^{[l+1]}]\odot \sigma ^{'}(Z^{[l]}) dZ[l]=[w[l+1]TdZ[l+1]]⊙σ′(Z[l]) | 此时 d Z [ l ] dZ^{[l]} dZ[l]的维度是 n × m n\times m n×m, n n n表示第l层神经元的个数,m表示样本数 |
| 参数变化率 | d b [ l ] = ∂ C ∂ b [ l ] = 1 m m e a n O f E a c h R o w ( d Z [ l ] ) d w [ l ] = ∂ C ∂ w [ l ] = 1 m d Z [ l ] A [ l − 1 ] T db^{[l]}=\frac{\partial C}{\partial b^{[l]}}=\frac{1}{m}meanOfEachRow(dZ^{[l]})\\dw^{[l]}=\frac{\partial C}{\partial w^{[l]}}=\frac{1}{m}dZ^{[l]}A^{[l-1]T} db[l]=∂b[l]∂C=m1meanOfEachRow(dZ[l])dw[l]=∂w[l]∂C=m1dZ[l]A[l−1]T | 更新 b [ l ] b^{[l]} b[l]的时候需要对每行求均值; 注意维度匹配; m m m是样本个数 |
| 参数更新 | b [ l ] ← b [ l ] − α ∂ C ∂ b [ l ] b^{[l]}\leftarrow b^{[l]}-\alpha\frac{\partial C}{\partial b^{[l]}} b[l]←b[l]−α∂b[l]∂C w [ l ] ← w [ l ] − α ∂ C ∂ w [ l ] w^{[l]}\leftarrow w^{[l]}-\alpha\frac{\partial C}{\partial w^{[l]}} w[l]←w[l]−α∂w[l]∂C | α \alpha α是学习率 |
3.5.3 关于超参数
通过前面的介绍,相信读者可以发现BP神经网络模型有一些参数是需要设计者给出的,也有一些参数是模型自己求解的。
那么,哪些参数是需要模型设计者确定的呢?
比如,学习率 α \alpha α,隐含层的层数,每个隐含层的神经元个数,激活函数的选取,损失函数(代价函数)的选取等等,这些参数被称之为超参数。
其它的参数,比如权重矩阵 w w w和偏置系数 b b b在确定了超参数之后是可以通过模型的计算来得到的,这些参数称之为普通参数,简称参数。
超参数的确定其实是很困难的。因为你很难知道什么样的超参数会让模型表现得更好。比如,学习率太小可能造成模型收敛速度过慢,学习率太大又可能造成模型不收敛;再比如,损失函数的设计,如果损失函数设计不好的话,可能会造成模型无法收敛;再比如,层数过多的时候,如何设计网络结构以避免梯度消失和梯度爆炸……
神经网络的程序比一般程序的调试难度大得多,因为它并不会显式报错,它只是无法得到你期望的结果,作为新手也很难确定到底哪里出了问题(对于自己设计的网络,这种现象尤甚,我目前也基本是新手,所以这些问题也在困扰着我)。当然,使用别人训练好的模型来微调看起来是一个捷径……
总之,神经网络至少在目前来看感觉还是黑箱的成分居多,希望通过大家的努力慢慢探索吧。
4. 是不是猫?
本小节主要使用上述公式来完成一个小例子,这个小小的神经网络可以告诉我们一张图片是不是猫。本例程参考了coursera的作业,有改动。
在实现代码之前,先把用到的公式列一个表格吧,这样对照着看大家更清晰一点(如果你没有2个显示器建议先把这些公式抄写到纸上,以便和代码对照):
| 编号 | 公式 | 备注 |
|---|---|---|
| 1 | Z [ l ] = w [ l ] A [ l − 1 ] + b [ l ] Z^{[l]}=w^{[l]}A^{[l-1]}+b^{[l]} Z[l]=w[l]A[l−1]+b[l] | |
| 2 | A [ l ] = σ ( Z [ l ] ) A^{[l]}=\sigma(Z^{[l]}) A[l]=σ(Z[l]) | |
| 3 | d Z [ L ] = ∇ A C ⊙ σ ′ ( Z [ L ] ) dZ^{[L]}=\nabla_AC\odot\sigma^{'}(Z^{[L]}) dZ[L]=∇AC⊙σ′(Z[L]) | |
| 4 | d Z [ l ] = [ w [ l + 1 ] T d Z [ l + 1 ] ] ⊙ σ ′ ( Z [ l ] ) dZ^{[l]}=[w^{[l+1]T}dZ^{[l+1]}]\odot \sigma ^{'}(Z^{[l]}) dZ[l]=[w[l+1]TdZ[l+1]]⊙σ′(Z[l]) | |
| 5 | d b [ l ] = ∂ C ∂ b [ l ] = 1 m m e a n O f E a c h R o w ( d Z [ l ] ) db^{[l]}=\frac{\partial C}{\partial b^{[l]}}=\frac{1}{m}meanOfEachRow(dZ^{[l]}) db[l]=∂b[l]∂C=m1meanOfEachRow(dZ[l]) | |
| 6 | d w [ l ] = ∂ C ∂ w [ l ] = 1 m d Z [ l ] A [ l − 1 ] T dw^{[l]}=\frac{\partial C}{\partial w^{[l]}}=\frac{1}{m}dZ^{[l]}A^{[l-1]T} dw[l]=∂w[l]∂C=m1dZ[l]A[l−1]T | |
| 7 | b [ l ] ← b [ l ] − α ⋅ d b [ l ] b^{[l]}\leftarrow b^{[l]}-\alpha \cdot db^{[l]} b[l]←b[l]−α⋅db[l] | |
| 8 | w [ l ] ← w [ l ] − α ⋅ d w [ l ] w^{[l]}\leftarrow w^{[l]}-\alpha\cdot dw^{[l]} w[l]←w[l]−α⋅dw[l] | |
| 9 | d A [ l ] = w [ l ] T ⊙ d Z [ l ] dA^{[l]}=w^{[l]T}\odot dZ^{[l]} dA[l]=w[l]T⊙dZ[l] | |
准备工作做的差不多了,让我们开始吧?等等,好像我们还没有定义代价函数是什么?OMG!好吧,看来我们得先把这个做好再继续了。
那先看结果吧,我们的代价函数是:
C = − 1 m ∑ i = 1 m ( y ( i ) l o g ( a [ L ] ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − a [ L ] ( i ) ) ) C =-\frac{1}{m} \sum^{m}_{i=1}(y^{(i)}log(a^{[L](i)})+(1-y^{(i)})log(1-a^{[L](i)})) C=−m1i=1∑m(y(i)log(a[L](i))+(1−y(i))log(1−a[L](i)))
其中, m m m是样本数量;
下面简单介绍一下这个代价函数是怎么来的(作者非数学专业,不严谨的地方望海涵)。
.
代价函数的确定用到了统计学中的**“极大似然法”**,既然这样,那就不可避免地要介绍一下“极大似然法”了。极大似然法简单来说就是“在模型已定,参数未知的情况下,根据结果估计模型中参数的一种方法“,换句话说,极大似然法提供了一种给定观察数据来评估模型参数的方法。
举个例子(本例参考了知乎相关回答),一个不透明的罐子里有黑白两种球(球仅仅颜色不同,大小重量等参数都一样)。有放回地随机拿出一个小球,记录颜色。重复10次之后发现7次是黑球,3次是白球。问你罐子里白球的比例?
相信很多人可以一口回答“30%”,那么,为什么呢?背后的原理是什么呢?
这里我们把每次取出一个球叫做一次抽样,把“抽样10次,7次黑球,3次白球”这个事件发生的概率记为 P ( 事 件 结 果 ∣ M o d e l ) P(事件结果|Model) P(事件结果∣Model),我们的Model需要一个参数 p p p表示白球的比例。那么 P ( 事 件 结 果 ∣ M o d e l ) = p 3 ( 1 − p ) 7 P(事件结果|Model)=p^3(1-p)^7 P(事件结果∣Model)=p3(1−p)7。
好了,现在我们已经有事件结果的概率公式了,接下来求解模型参数 p p p,根据极大似然法的思想,既然这个事件发生了,那么为什么不让这个事件(抽样10次,7次黑球,3次白球)发生的概率最大呢?因为显然概率大的事件发生才是合理的。于是就变成了求解 p 3 ( 1 − p ) 7 p^3(1-p)^7 p3(1−p)7取最大值的 p p p,即导数为0,经过求导:
d ( p 3 ( 1 − p ) 7 ) = 3 p 2 ( 1 − p ) 7 − 7 p 3 ( 1 − p ) 6 = p 2 ( 1 − p ) 6 ( 3 − 10 p ) = 0 d(p^3(1-p)^7)=3p^2(1-p)^7-7p^3(1-p)^6=p^2(1-p)^6(3-10p)=0 d(p3(1−p)7)=3p2(1−p)7−7p3(1−p)6=p2(1−p)6(3−10p)=0
求解可得 p = 0.3 p=0.3 p=0.3
极大似然法有一个重要的假设:
假设所有样本独立同分布!!!
好了,现在来看看我们的神经网络模型。
最后一层我们用sigmoid函数求出一个激活输出a,如果a大于0.5,就表示这个图片是猫( y = 1 y=1 y=1),否则就不是猫( y = 0 y=0 y=0)。因此:
P ( y = 1 ∣ x ; θ ) = a P(y=1|x;\theta)=a P(y=1∣x;θ)=a
P ( y = 0 ∣ x ; θ ) = 1 − a P(y=0|x;\theta)=1-a P(y=0∣x;θ)=1−a
公式解释:
上述第一个公式表示,给定模型参数 θ \theta θ和输入 x x x,是猫的概率是 P ( y = 1 ∣ x ; θ ) = a P(y=1|x;\theta)=a P(y=1∣x;θ)=a
把两个公式合并成一个公式,即
p ( y ∣ x ; θ ) = a y ( 1 − a ) ( 1 − y ) p(y|x;\theta)=a^y(1-a)^{(1-y)} p(y∣x;θ)=ay(1−a)(1−y)
这里的 θ \theta θ指的就是我们神经网络的权值参数和偏置参数。
那么似然函数
L ( θ ) = p ( Y ∣ X ; θ ) = ∏ i = 1 m p ( y ( i ) ∣ x ( i ) ; θ ) = ∏ i = 1 m ( a [ L ] ( i ) ) y ( i ) ( 1 − a [ L ] ( i ) ) ( 1 − y ( i ) ) L(\theta)=p(Y|X;\theta)=\prod^m_{i=1}p(y^{(i)}|x^{(i)};\theta)=\prod^m_{i=1}(a^{[L](i)})^{y^{(i)}}(1-a^{[L](i)})^{(1-y^{(i)})} L(θ)=p(Y∣X;θ)=i=1∏mp(y(i)∣x(i);θ)=i=1∏m(a[L](i))y(i)(1−a[L](i))(1−y(i))
变成对数形式:
l o g ( L ( θ ) ) = ∑ i = 1 m ( y ( i ) l o g ( a [ L ] ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − a [ L ] ( i ) ) ) log(L(\theta))=\sum^m_{i=1}(y^{(i)}log(a^{[L](i)})+(1-y^{(i)})log(1-a^{[L](i)})) log(L(θ))=i=1∑m(y(i)log(a[L](i))+(1−y(i))log(1−a[L](i)))
所以我们的目标就是最大化这个对数似然函数,也就是最小化我们的代价函数:
C = − 1 m ∑ i = 1 m ( y ( i ) l o g ( a [ L ] ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − a [ L ] ( i ) ) ) C =-\frac{1}{m} \sum^{m}_{i=1}(y^{(i)}log(a^{[L](i)})+(1-y^{(i)})log(1-a^{[L](i)})) C=−m1i=1∑m(y(i)log(a[L](i))+(1−y(i))log(1−a[L](i)))
其中, m m m是样本数量;
好了,终于可以开始写代码了,码字手都有点酸了,不得不说公式真的好难打。
由于代码比较简单就没有上传github。本文代码和数据文件可以在这里下载: https://pan.baidu.com/s/1q_PzaCSXOhRLOJVF5-vy2Q,密码: d7vx
其他下载源:
https://drive.google.com/file/d/0B6exrzrSxlh3TmhSV0ZNeHhYUmM/view?usp=sharing
4.1 辅助函数
辅助函数主要包括激活函数以及激活函数的反向传播过程函数:
其中,激活函数反向传播代码对应公式4和9.
def sigmoid(z):
""" 使用numpy实现sigmoid函数 参数: Z numpy array 输出: A 激活值(维数和Z完全相同) """
return 1/(1 + np.exp(-z))
def relu(z):
""" 线性修正函数relu 参数: z numpy array 输出: A 激活值(维数和Z完全相同) """
return np.array(z>0)*z
def sigmoidBackward(dA, cacheA):
""" sigmoid的反向传播 参数: dA 同层激活值 cacheA 同层线性输出 输出: dZ 梯度 """
s = sigmoid(cacheA)
diff = s*(1 - s)
dZ = dA * diff
return dZ
def reluBackward(dA, cacheA):
""" relu的反向传播 参数: dA 同层激活值 cacheA 同层线性输出 输出: dZ 梯度 """
Z = cacheA
dZ = np.array(dA, copy=True)
dZ[Z <= 0] = 0
return dZ
另外一个重要的辅助函数是数据读取函数和参数初始化函数:
def loadData(dataDir):
""" 导入数据 参数: dataDir 数据集路径 输出: 训练集,测试集以及标签 """
train_dataset = h5py.File(dataDir+'/train.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File(dataDir+'/test.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
def iniPara(laydims):
""" 随机初始化网络参数 参数: laydims 一个python list 输出: parameters 随机初始化的参数字典(”W1“,”b1“,”W2“,”b2“, ...) """
np.random.seed(1)
parameters = {
}
for i in range(1, len(laydims)):
parameters['W'+str(i)] = np.random.randn(laydims[i], laydims[i-1])/ np.sqrt(laydims[i-1])
parameters['b'+str(i)] = np.zeros((laydims[i], 1))
return parameters
4.2 前向传播过程
对应公式1和2.
def forwardLinear(W, b, A_prev):
""" 前向传播 """
Z = np.dot(W, A_prev) + b
cache = (W, A_prev, b)
return Z, cache
def forwardLinearActivation(W, b, A_prev, activation):
""" 带激活函数的前向传播 """
Z, cacheL = forwardLinear(W, b, A_prev)
cacheA = Z
if activation == 'sigmoid':
A = sigmoid(Z)
if activation == 'relu':
A = relu(Z)
cache = (cacheL, cacheA)
return A, cache
def forwardModel(X, parameters):
""" 完整的前向传播过程 """
layerdim = len(parameters)//2
caches = []
A_prev = X
for i in range(1, layerdim):
A_prev, cache = forwardLinearActivation(parameters['W'+str(i)], parameters['b'+str(i)], A_prev, 'relu')
caches.append(cache)
AL, cache = forwardLinearActivation(parameters['W'+str(layerdim)], parameters['b'+str(layerdim)], A_prev, 'sigmoid')
caches.append(cache)
return AL, caches
4.3 反向传播过程
线性部分反向传播对应公式5和6。
def linearBackward(dZ, cache):
""" 线性部分的反向传播 参数: dZ 当前层误差 cache (W, A_prev, b)元组 输出: dA_prev 上一层激活的梯度 dW 当前层W的梯度 db 当前层b的梯度 """
W, A_prev, b = cache
m = A_prev.shape[1]
dW = 1/m*np.dot(dZ, A_prev.T)
db = 1/m*np.sum(dZ, axis = 1, keepdims=True)
dA_prev = np.dot(W.T, dZ)
return dA_prev, dW, db
非线性部分对应公式3、4、5和6 。
def linearActivationBackward(dA, cache, activation):
""" 非线性部分的反向传播 参数: dA 当前层激活输出的梯度 cache (W, A_prev, b)元组 activation 激活函数类型 输出: dA_prev 上一层激活的梯度 dW 当前层W的梯度 db 当前层b的梯度 """
cacheL, cacheA = cache
if activation == 'relu':
dZ = reluBackward(dA, cacheA)
dA_prev, dW, db = linearBackward(dZ, cacheL)
elif activation == 'sigmoid':
dZ = sigmoidBackward(dA, cacheA)
dA_prev, dW, db = linearBackward(dZ, cacheL)
return dA_prev, dW, db
完整反向传播模型:
def backwardModel(AL, Y, caches):
""" 完整的反向传播过程 参数: AL 输出层结果 Y 标签值 caches 【cacheL, cacheA】 输出: diffs 梯度字典 """
layerdim = len(caches)
Y = Y.reshape(AL.shape)
L = layerdim
diffs = {
}
dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL))
currentCache = caches[L-1]
dA_prev, dW, db = linearActivationBackward(dAL, currentCache, 'sigmoid')
diffs['dA' + str(L)], diffs['dW'+str(L)], diffs['db'+str(L)] = dA_prev, dW, db
for l in reversed(range(L-1)):
currentCache = caches[l]
dA_prev, dW, db = linearActivationBackward(dA_prev, currentCache, 'relu')
diffs['dA' + str(l+1)], diffs['dW'+str(l+1)], diffs['db'+str(l+1)] = dA_prev, dW, db
return diffs
4.4 测试结果
打开你的jupyter notebook,运行我们的BP.ipynb文件,首先导入依赖库和数据集,然后使用一个循环来确定最佳的迭代次数大约为2000:
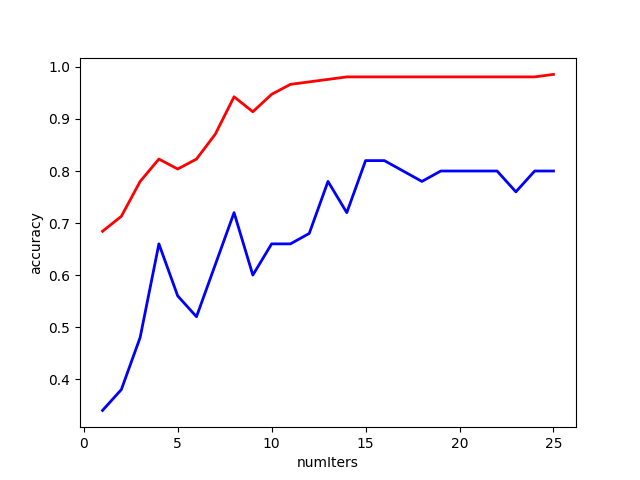
【图6】
最后用一个例子来看一下模型的效果——判断一张图片是不是猫:
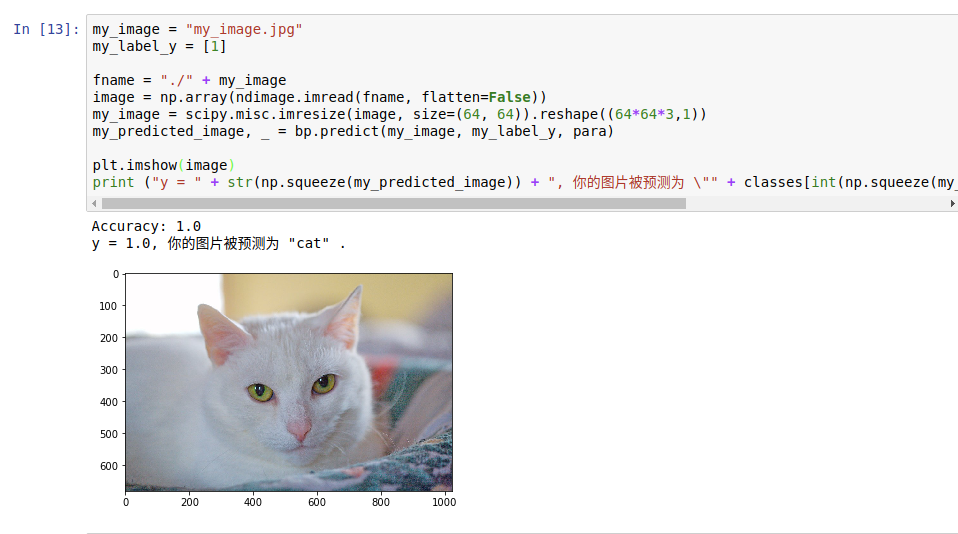
【图7】
好了,测试到此结束。你也可以自己尝试其它的神经网络结构和测试其它图片。
5. 本文小结
本文主要叙述了经典的全连接神经网络结构以及前向传播和反向传播的过程。通过本文的学习,读者应该可以独立推导全连接神经网络的传播过程,对算法的细节烂熟于心。另外,由于本文里的公式大部分是我自己推导的,瑕疵之处,希望读者不吝赐教。
虽然这篇文章实现的例子并没有什么实际应用场景,但是自己推导一下这些数学公式并用代码实现对理解神经网络内部的原理很有帮助,继这篇博客之后,我还计划写一个如何自己推导并实现卷积神经网络的教程,如果有人感兴趣,请继续关注我!
本次内容就到这里,谢谢大家。
订正与答疑:
前向传播过程比较简单,我就不再赘述了。
这里主要针对反向传播过程中可能会出现的问题做一个总结:
1. 具体解释一下公式1里面的“堆砌”是什么意思?
δ j [ L ] = ∑ k ∂ L ∂ a k [ L ] ∂ a k [ L ] ∂ z j [ L ] \delta^{[L]}_j = \sum_k \frac{\partial L}{\partial a^{[L]}_k} \frac{\partial a^{[L]}_k}{\partial z^{[L]}_j} δj[L]=k∑∂ak[L]∂L∂zj[L]∂ak[L]
有读者对这里不太理解,这其实是因为,我们的输出层不一定是只有一个神经元,可能有好多个神经元,因此损失函数是每个输出神经元“误差”之和,因此才会出现这种 ∑ \sum ∑的形式,然后每个输出神经元的误差函数与其它神经元没有关系,所以只有 k = j k=j k=j的时候值不是0.
另外,这里说的“堆砌”指的就是:
δ [ l ] = [ ∂ L ∂ a 1 [ L ] ∂ L ∂ a 2 [ L ] ⋮ ] ⊙ [ σ ′ ( z 1 [ L ] ) σ ′ ( z 2 [ L ] ) ⋮ ] \delta^{[l]}=\left[ \begin{array}{cc} \frac{\partial L}{\partial a^{[L]}_1} \\ \frac{\partial L}{\partial a^{[L]}_2} \\\vdots \end{array}\right]\odot\left[\begin{array}{cc}\sigma^{'}(z^{[L]}_1) \\\sigma^{'}(z^{[L]}_2)\\\vdots\end{array}\right] δ[l]=⎣⎢⎢⎡∂a1[L]∂L∂a2[L]∂L⋮⎦⎥⎥⎤⊙⎣⎢⎢⎡σ′(z1[L])σ′(z2[L])⋮⎦⎥⎥⎤
2. 公式2写成矩阵形式为什么系数矩阵会有转置?自己没搞懂。
这里可能有一点绕,有的读者感觉我的推导不是很明白,所以有必要详细说明一下。
很多读者不明白,写成矩阵形式的时候
δ [ l ] = [ w [ l + 1 ] T δ [ l + 1 ] ] ⊙ σ ′ ( z [ l ] ) \delta^{[l]}=[w^{[l+1]T}\delta^{[l+1]}]\odot \sigma ^{'}(z^{[l]}) δ[l]=[w[l+1]Tδ[l+1]]⊙σ′(z[l])
里面的“系数矩阵转置”是怎么来的。这里就主要说明一下:
相信大家都已经理解了下面这个前向传播公式:
z k [ l + 1 ] = ∑ j w k j [ l + 1 ] a j [ l ] + b k [ l + 1 ] = ∑ j w k j [ l + 1 ] σ ( z j [ l ] ) + b k [ l + 1 ] z^{[l+1]}_k=\sum_jw^{[l+1]}_{kj}a^{[l]}_j+b^{[l+1]}_k=\sum_jw^{[l+1]}_{kj}\sigma(z^{[l]}_j)+b^{[l+1]}_k zk[l+1]=j∑wkj[l+1]aj[l]+bk[l+1]=j∑wkj[l+1]σ(zj[l])+bk[l+1]
求偏导这里在原文中有一点错误,应该是:
∂ z k [ l + 1 ] ∂ z j [ l ] = ∑ k w k j [ l + 1 ] σ ′ ( z j [ l ] ) \frac{\partial z^{[l+1]}_k}{\partial z^{[l]}_j} =\sum_k w^{[l+1]}_{kj} \sigma'(z^{[l]}_j) ∂zj[l]∂zk[l+1]=k∑wkj[l+1]σ′(zj[l])
为了大家有一个直观的感受,来一个具体的例子:
第 1 层的系数矩阵比方是:
w [ 2 = [ w 11 [ 2 ] w 12 [ 2 ] w 13 [ 2 ] w 21 [ 2 ] w 22 [ 2 ] w 23 [ 2 ] ] w^{[2}=\left[ \begin{array}{cc} w_{11}^{[2]} & w_{12}^{[2]} & w_{13}^{[2]} \\ w_{21}^{[2]}& w_{22}^{[2]} & w_{23}^{[2]}\end{array}\right] w[2=[w11[2]w21[2]w12[2]w22[2]w13[2]w23[2]]
b [ 2 ] = [ b 1 [ 2 ] b 2 [ 2 ] b^{[2]}=\left[ \begin{array}{cc}b^{[2]}_1 \\ b^{[2}_2 \end{array}\right] b[2]=[b1[2]b2[2]
z [ 2 ] = [ w 11 [ 2 ] w 12 [ 2 ] w 13 [ 2 ] w 21 [ 2 ] w 22 [ 2 ] w 23 [ 2 ] ] ⋅ [ a 1 [ 1 ] a 2 [ 1 ] a 3 [ 1 ] ] + [ b 1 [ 2 ] b 2 [ 2 ] ] = [ w 11 [ 2 ] a 1 [ 1 ] + w 12 [ 2 ] a 2 [ 1 ] + w 13 [ 2 ] a 3 [ 1 ] + b 1 [ 2 ] w 21 [ 2 ] a 1 [ 1 ] + w 22 [ 2 ] a 2 [ 1 ] + w 23 [ 2 ] a 3 [ 1 ] + b 2 [ 2 ] ] z^{[2]}=\left[ \begin{array}{cc} w_{11}^{[2]} & w_{12}^{[2]} & w_{13}^{[2]} \\ w_{21}^{[2]}& w_{22}^{[2]} & w_{23}^{[2]}\end{array}\right]\cdot \left[ \begin{array}{cc} a^{[1]}_1 \\ a^{[1]}_2 \\ a^{[1]}_3 \end{array}\right] +\left[ \begin{array}{cc}b^{[2]}_1 \\ b^{[2]}_2 \end{array}\right]=\left[ \begin{array}{cc} w_{11}^{[2]}a^{[1]}_1+w_{12}^{[2]}a^{[1]}_2+w_{13}^{[2]}a^{[1]}_3+b^{[2]}_1 \\ w^{[2]}_{21}a^{[1]}_1+w_{22}^{[2]}a^{[1]}_2+w_{23}^{[2]}a^{[1]}_3+b^{[2]}_2\end{array}\right] z[2]=[w11[2]w21[2]w12[2]w22[2]w13[2]w23[2]]⋅⎣⎢⎡a1[1]a2[1]a3[1]⎦⎥⎤+[b1[2]b2[2]]=[w11[2]a1[1]+w12[2]a2[1]+w13[2]a3[1]+b1[2]w21[2]a1[1]+w22[2]a2[1]+w23[2]a3[1]+b2[2]]
那么,
∂ z 1 [ 2 ] ∂ a 1 [ 1 ] = ∂ ( w 11 [ 2 ] a 1 [ 1 ] + w 12 [ 2 ] a 2 [ 1 ] + w 13 [ 2 ] a 3 [ 1 ] + b 1 [ 2 ] ) ∂ a 1 [ 1 ] = w 11 [ 2 ] \frac{\partial z^{[2]}_1}{\partial a^{[1]}_1}=\frac{\partial(w_{11}^{[2]}a^{[1]}_1+w_{12}^{[2]}a^{[1]}_2+w_{13}^{[2]}a^{[1]}_3+b^{[2]}_1)}{\partial a^{[1]}_1}=w^{[2]}_{11} ∂a1[1]∂z1[2]=∂a1[1]∂(w11[2]a1[1]+w12[2]a2[1]+w13[2]a3[1]+b1[2])=w11[2]
那么,根据之前介绍的求解梯度向量的定义:
∂ z 1 [ 2 ] ∂ a [ 1 ] = [ ∂ z 1 [ 2 ] ∂ a 1 [ 1 ] ∂ z 1 [ 2 ] ∂ a 2 [ 1 ] ∂ z 1 [ 2 ] ∂ a 3 [ 1 ] ] = [ w 11 [ 2 ] w 12 [ 2 ] w 13 [ 2 ] ] \frac{\partial z^{[2]}_1}{\partial a^{[1]}}=\left[ \begin{array}{cc}\frac{\partial z^{[2]}_1}{\partial a^{[1]}_1}\\\frac{\partial z^{[2]}_1}{\partial a^{[1]}_2}\\\frac{\partial z^{[2]}_1}{\partial a^{[1]}_3}\end{array}\right]=\left[\begin{array}{cc}w^{[2]}_{11}\\w^{[2]}_{12}\\w^{[2]}_{13}\end{array}\right] ∂a[1]∂z1[2]=⎣⎢⎢⎢⎢⎡∂a1[1]∂z1[2]∂a2[1]∂z1[2]∂a3[1]∂z1[2]⎦⎥⎥⎥⎥⎤=⎣⎢⎡w11[2]w12[2]w13[2]⎦⎥⎤
∂ z 2 [ 2 ] ∂ a [ 1 ] = [ ∂ z 2 [ 2 ] ∂ a 1 [ 1 ] ∂ z 2 [ 2 ] ∂ a 2 [ 1 ] ∂ z 2 [ 2 ] ∂ a 3 [ 1 ] ] = [ w 21 [ 2 ] w 22 [ 2 ] w 23 [ 2 ] ] \frac{\partial z^{[2]}_2}{\partial a^{[1]}}=\left[ \begin{array}{cc}\frac{\partial z^{[2]}_2}{\partial a^{[1]}_1}\\\frac{\partial z^{[2]}_2}{\partial a^{[1]}_2}\\\frac{\partial z^{[2]}_2}{\partial a^{[1]}_3}\end{array}\right]=\left[\begin{array}{cc}w^{[2]}_{21}\\w^{[2]}_{22}\\w^{[2]}_{23}\end{array}\right] ∂a[1]∂z2[2]=⎣⎢⎢⎢⎢⎡∂a1[1]∂z2[2]∂a2[1]∂z2[2]∂a3[1]∂z2[2]⎦⎥⎥⎥⎥⎤=⎣⎢⎡w21[2]w22[2]w23[2]⎦⎥⎤
这就解释了,为什么会出现转置了。
然后排布成矩阵形式:
[ w 11 [ 2 ] w 21 [ 2 ] w 12 [ 2 ] w 22 [ 2 ] w 13 [ 2 ] w 23 [ 2 ] ] \left[\begin{array}{cc}w^{[2]}_{11}&w^{[2]}_{21}\\w^{[2]}_{12}&w^{[2]}_{22}\\w^{[2]}_{13}&w^{[2]}_{23}\end{array}\right] ⎣⎢⎡w11[2]w12[2]w13[2]w21[2]w22[2]w23[2]⎦⎥⎤
或者,根据推到得到的公式: δ j [ l ] = ∑ k w k j [ l + 1 ] δ k [ l + 1 ] σ ′ ( z j [ l ] ) \delta^{[l]}_j = \sum_k w^{[l+1]}_{kj} \delta^{[l+1]}_k \sigma'(z^{[l]}_j) δj[l]=∑kwkj[l+1]δk[l+1]σ′(zj[l]) 写成矩阵形式:
[ δ 1 [ 1 ] δ 2 [ 1 ] δ 3 [ 1 ] ] = [ w 11 [ 2 ] w 21 [ 2 ] w 12 [ 2 ] w 22 [ 2 ] w 13 [ 2 ] w 23 [ 2 ] ] [ δ 1 [ 2 ] δ 2 [ 2 ] ] ⊙ [ σ ′ ( z 1 [ 1 ] ) σ ′ ( z 2 [ 1 ] ) σ ′ ( z 3 [ 1 ] ) ] \left[\begin{array}{cc}\delta^{[1]}_1\\\delta^{[1]}_2\\\delta^{[1]}_3\end{array}\right]=\left[\begin{array}{cc}w^{[2]}_{11}&w^{[2]}_{21}\\w^{[2]}_{12}&w^{[2]}_{22}\\w^{[2]}_{13}&w^{[2]}_{23}\end{array}\right]\left[\begin{array}{cc}\delta^{[2]}_1\\\delta^{[2]}_2\end{array}\right]\odot\left[\begin{array}{cc}\sigma^{'}(z^{[1]}_1)\\\sigma^{'}(z^{[1]}_2)\\\sigma^{'}(z^{[1]}_3)\end{array}\right] ⎣⎢⎡δ1[1]δ2[1]δ3[1]⎦⎥⎤=⎣⎢⎡w11[2]w12[2]w13[2]w21[2]w22[2]w23[2]⎦⎥⎤[δ1[2]δ2[2]]⊙⎣⎢⎡σ′(z1[1])σ′(z2[1])σ′(z3[1])⎦⎥⎤
也可以解释为什那么会变成转置。
写成矩阵形式,注意检查一下维度匹配的问题。
3. 公式3能具体讲一下矩阵形式是怎么来的吗?
这里有一点小错误,说明部分的第一个公式应该是:
z j [ l ] = ∑ k w j k [ l ] a k [ l − 1 ] + b k [ l ] z^{[l]}_j=\sum_kw^{[l]}_{jk}a^{[l-1]}_k+b^{[l]}_k zj[l]=k∑wjk[l]ak[l−1]+bk[l]
对 b b b求偏导的过程比较简单,这里就不再赘述。
主要详细解释一下对 w w w 的求导过程:
对系数矩阵单个系数元素的推导原文已经说得比较明白了 ∂ L ∂ w j k [ l ] = ∂ L ∂ z j [ l ] ∂ z j [ l ] w j k [ l ] = a k [ l − 1 ] δ j [ l ] \frac{\partial L}{\partial w^{[l]}_{jk}}=\frac{\partial L}{\partial z^{[l]}_j}\frac{\partial z^{[l]}_j}{w^{[l]}_{jk}}=a^{[l-1]}_k\delta^{[l]}_j ∂wjk[l]∂L=∂zj[l]∂Lwjk[l]∂zj[l]=ak[l−1]δj[l],有些读者可能还是不清楚如何把单个元素的公式对应为矩阵形式的公式:
单个元素公式 ∂ L ∂ w j k [ l ] = ∂ L ∂ z j [ l ] ∂ z j [ l ] w j k [ l ] = a k [ l − 1 ] δ j [ l ] \frac{\partial L}{\partial w^{[l]}_{jk}}=\frac{\partial L}{\partial z^{[l]}_j}\frac{\partial z^{[l]}_j}{w^{[l]}_{jk}}=a^{[l-1]}_k\delta^{[l]}_j ∂wjk[l]∂L=∂zj[l]∂Lwjk[l]∂zj[l]=ak[l−1]δj[l]说明系数矩阵 w [ l ] w^{[l]} w[l]的第 j t h j^{th} jth行 k t h k^{th} kth列的值为 a k [ l − 1 ] δ j [ l ] a^{[l-1]}_k\delta^{[l]}_j ak[l−1]δj[l],所以 δ j [ l ] \delta^{[l]}_j δj[l]对应行, a k [ l − 1 ] a^{[l-1]}_k ak[l−1]对应列,就得到了我们的矩阵形式。这也解释了为什么会出现转置。
4. 为什么会损失函数不用最小二乘法?
有的读者问,为什么使用极大似然估计,而不用最小二乘法?
其实在线性回归模型中,损失函数也是使用极大似然法来估计的,http://www.jianshu.com/p/0d25be8901c9,只不过线性回归模型中,我们假设残差是高斯分布,因此最终使用极大似然法和最小二乘法的结果是一样的。
如果你直接使用误差平方和最小的话,也不是不可以,但是效果可能会比较差。因为他是非凸的,可能会收敛到局部最优解。
而使用对数似然函数作为损失函数,是凸函数。
5. 能不能顺便介绍一下Python环境的管理?
一般我用anaconda管理Python环境,另外IDE推荐spyder,因为你可以像使用MATLAB的workspace一样直接观察中间变量,对初学者检查自己的程序的正确性很有帮助。
6. 为什么w的初始化使用随机初始化,而b参数的初始化全部初始化为0?
首先,b参数也可以用随机初始化。
为什么不把w全部初始化为0呢?因为这样的话,每次学习所有的隐含神经元学到的东西都一样,最终会导致,和层一个神经元没有区别,所以我们需要随机初始化开打破这种局面,让每个神经元都更好地“学习“。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/162079.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
