大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
前言
相比C语言,JVM虚拟机一个优势体现在对对象的垃圾回收上,JVM有一套完整的垃圾回收算法,可以对程序运行时产生的垃圾对象进行及时的回收,以便释放JVM相应区域的内存空间,确保程序稳定高效的运行,但在真正了解垃圾回收算法之前,有必要对JVM的对象的引用做一个简单的铺垫
JVM对象可达性分析算法
- Java虚拟机中的垃圾回收器采用可达性分析来探索所有存活的对象
- 扫描堆中的对象,看是否能够沿着GC Root对象为起点的引用链找到该对象,找不到表示可以被回收
想象一下,对象在什么情况下会被认为是垃圾对象呢?
- 当一个对象没有被任何引用了,就认为对象无用了(如图一)
- 当一组对象没有被任何引用了,可以认为这组对象无用了(如图二)
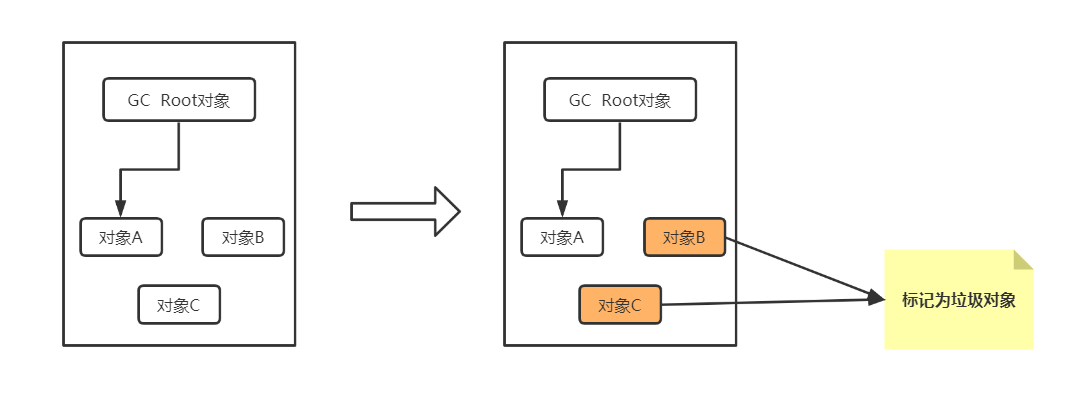

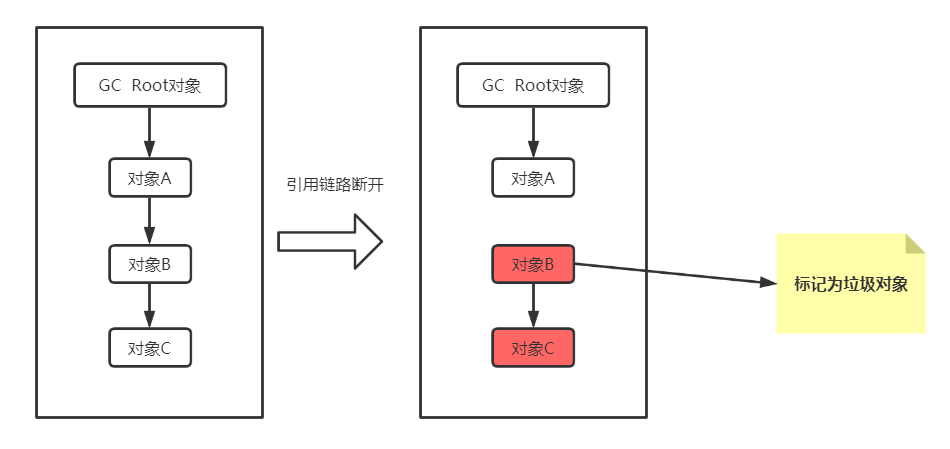
下面通过一段简单的程序代码,在不同的时刻导出dump日志,利用MAT分析工具来说明下这个问题
public static void main(String[] args) throws Exception{
List<Object> list1 = new ArrayList<>();
list1.add("aaa");
list1.add("bbb");
System.out.println(1);
System.in.read();
list1 = null;
System.out.println(1);
System.in.read();
System.out.println("end");
}
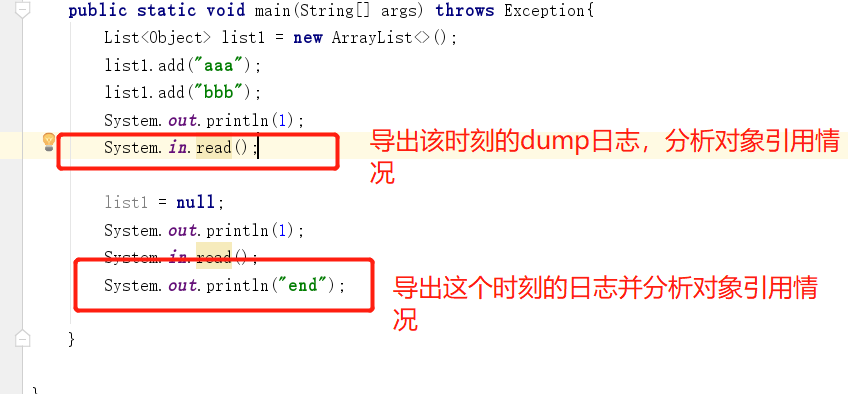
运行程序,利用下面的命令导出两个时刻的dump文件
map -dump:format=b,live,file=a.dump 17356

分析第一个文件,在第一个时刻,此时由于list1集合中放了2个元素,因此该对象存在引用关系
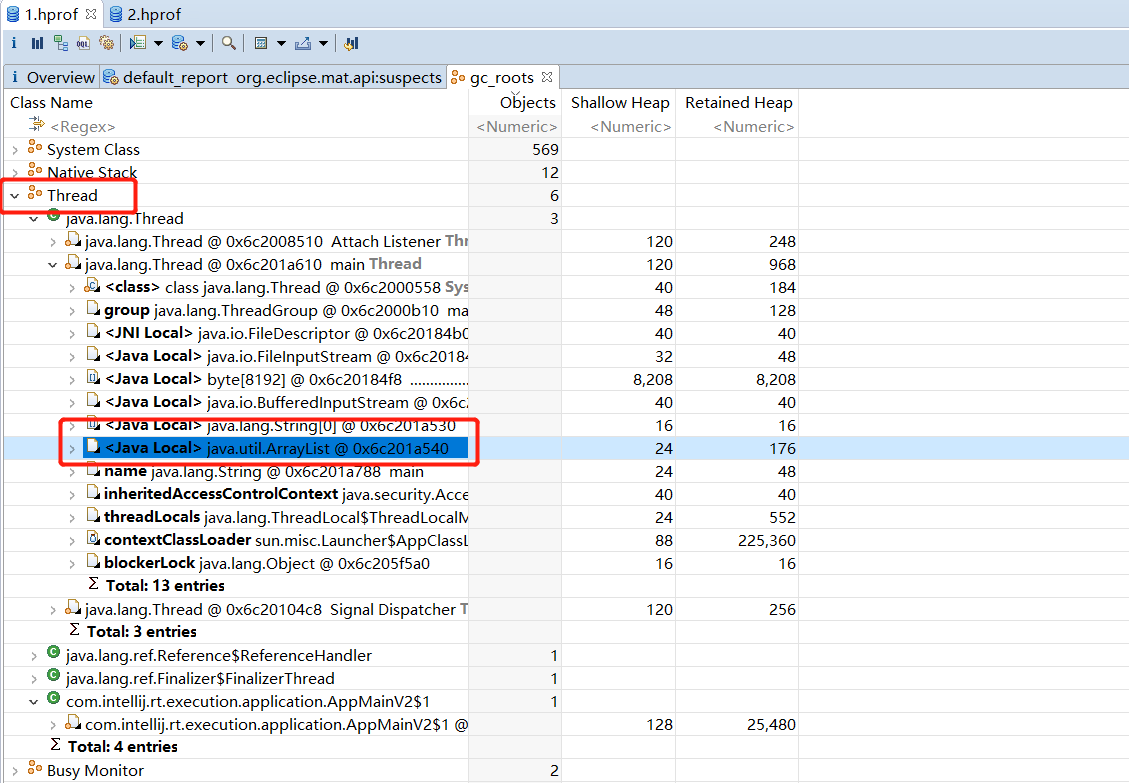
再分析第二个文件,在第二个时刻,此时由于list1置为null,因此该对象没有被引用的地方了,在gc root中找不到list1对象了
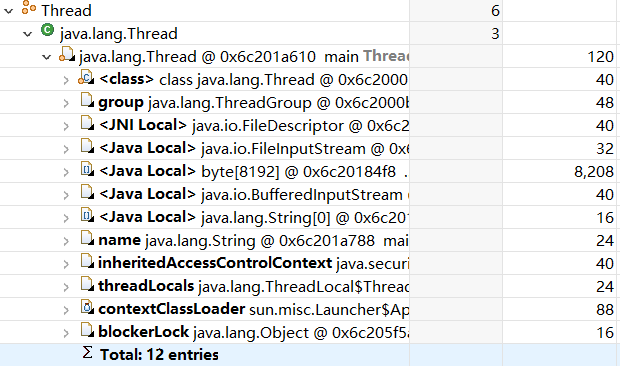
通过上面简单的案例演示和说明,我们再次明确,对象被标为垃圾的前提是该对象从GC Root出发进行搜索时,找不到对该对象的引用,即为不可达对象
几种常用的垃圾回收算法
1、引用计数法
引用计数法在JVM的早期版本中有用到,引用计数是指采用计数器说明引用对象的个数,即为某个对象设置一个引用对象数量的计数器,如果该对象被引用了,计数器的数量加1,否则减一,当计数器的数值为0的时候,垃圾回收器将该对象进行回收
如下图所示,某一时刻,对象A,B,C各自持有对对象P的引用,到另一时刻A,B,C不再对P对象进行引用了,计数器的值归为0,此时垃圾回收器就对P对象进行垃圾回收
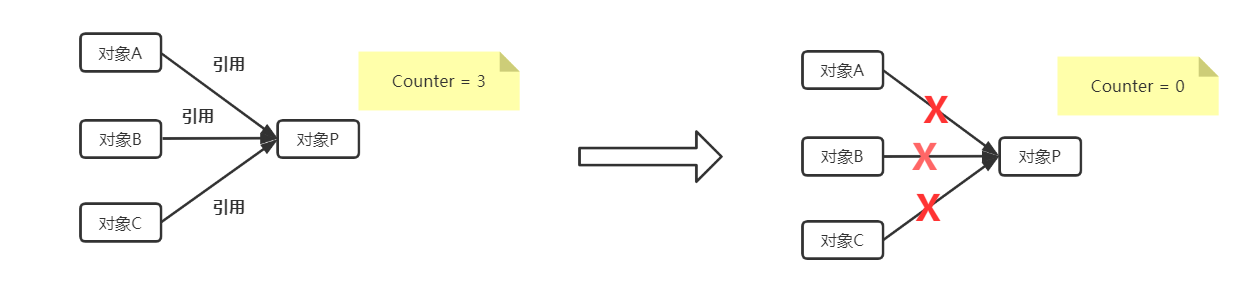
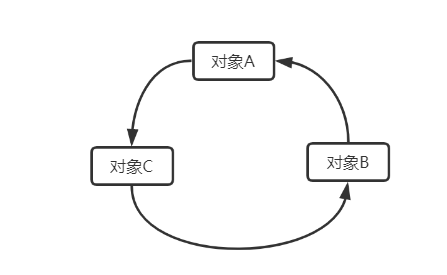
引用计数法在JVM垃圾回收算法中逐渐被废弃,很简单,如果存在对象之间的循环引用,则计数器的count值永远不会清0,如此对象将会一直存在内存中得不到释放
2、根搜索算法
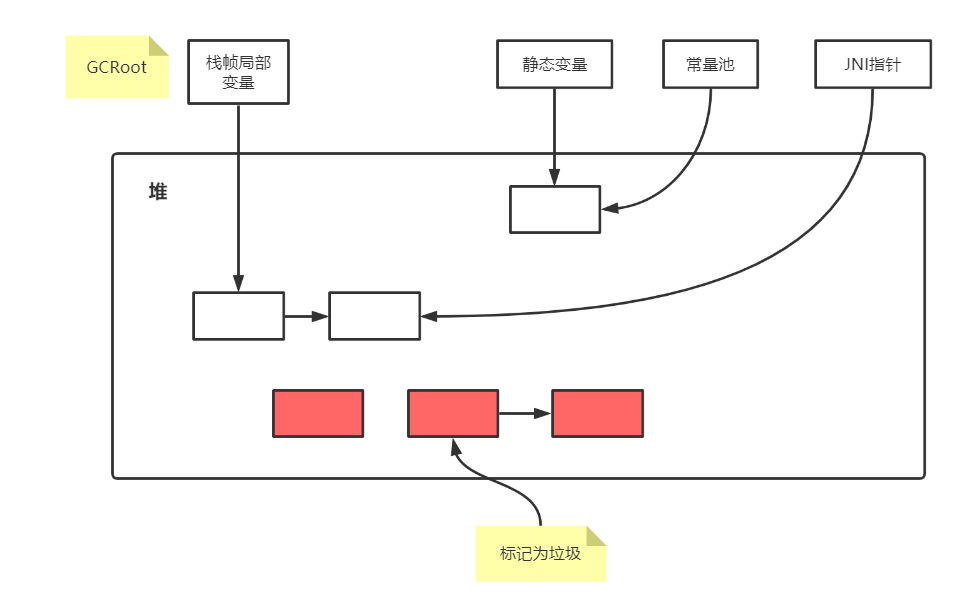
根搜索算法是JVM的默认垃圾回收算法,也叫做“可达性分析算法”,即从GCRoot出发,有引用的对象都是不可回收的,其他的可以进行标记后再回收
如下图所示,对某个线程栈来说,里面有局部变量,有静态变量,常量池,或对本地native方法的调用,假设从某个栈帧的局部变量出发,可认为是GCRoot的搜索起点,以此为起点,搜索整个引用链条上的所有引用对象,在这个链条上的对象认为是GCRoot可达的对象,否则将会被设为可回收对象被垃圾回收器回收
3、标记清除法(Mark-Sweep)
标记清除算法主要经历标记和清除2个步骤,通过根搜索算法中的可达性分析之后,那些被标记为垃圾对象的内存空间,通过该算法直接清除
标记清除算法简单粗暴,效率很高,因为不涉及到其他的步骤,但是从下面的图示也可以看到,标记清除算法产生了不连续的内存碎片(产生了内存间隙)导致其内存使用率比较低,如果程序中需要为某个大对象分配一大块连续的内存空间,则很难通过这种算法腾出这样的内存空间,因此该算法在JVM中并没有使用到(作为一种垃圾回收算法的思想值得借鉴)
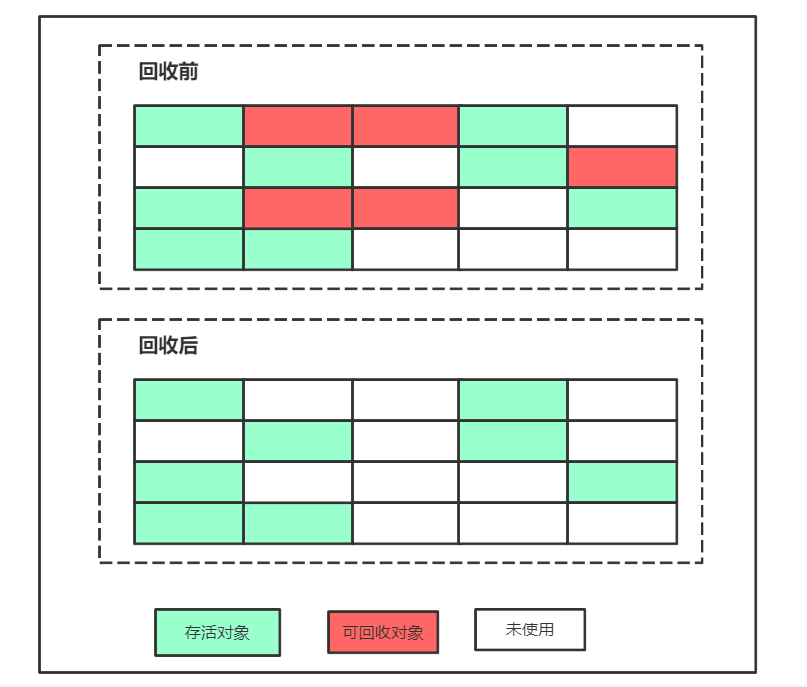
4、复制交换算法(Mark-Sweep)
为解决Mark-Sweep算法的缺陷,Copying算法就被提了出来。它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当某一块内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用的内存空间一次清理掉,这样一来就不容易出现内存碎片的问题
在堆的年轻代进行GC的时候使用的就是复制算法,还记得新生代的区域划分吗?S0和S1两个区域的内存在实际使用时,总是其中一块在使用,当达到了minor gc的条件时,就按照复制算法,将这块空间中存活的对象转移到另一块,再清理当前这块空间的垃圾对象
总结来说,复制算法速度快,无内存碎片,但缺点也比较明显,就是浪费空间,在年轻代的 Minor Gc中使用
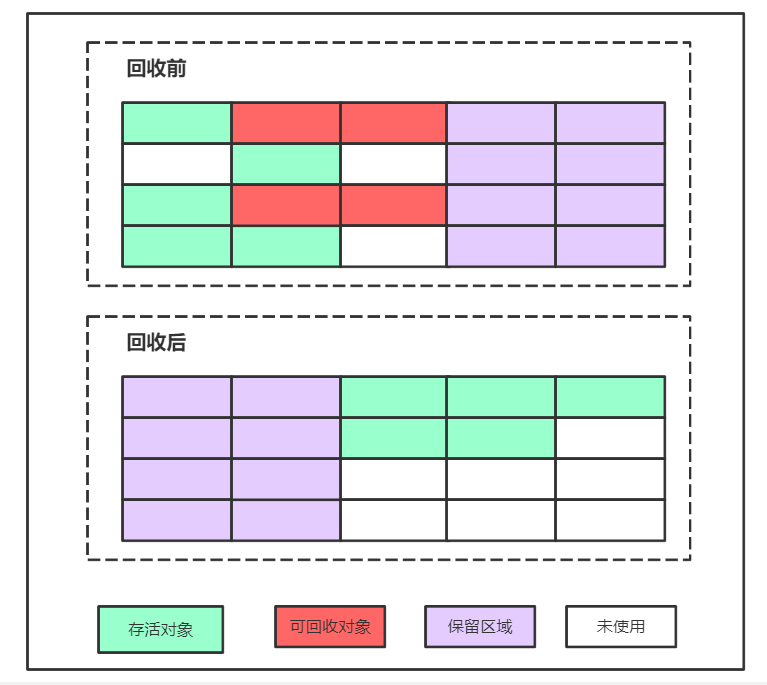
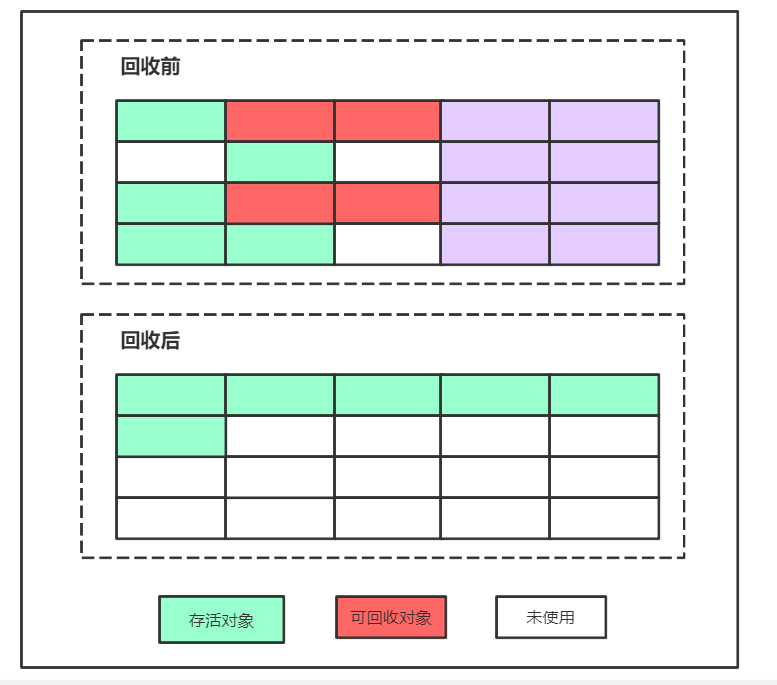
5、标记压缩算法(Mark-Compact)
为解决Copying算法的缺陷,充分利用内存空间,提出了Mark-Compact算法。该算法标记阶段和Mark-Sweep一样,但是在完成标记之后,它不是直接清理可回收对象,而是将存活对象都向一端移动,然后清理掉端边界以外的内存
标记压缩算法整个垃圾回收的过程包括,标记 -> 压缩 -> 整理 ->清除,通过下图展示也不难发现,标记压缩进行垃圾回收之后,整个内存区域的分布比较连续(无内存碎片),但是很明显这种算法的中间操作步骤相对上面两种算法要复杂,因此在进行GC过程中比较耗时效率较低,在老年代的Full Gc时使用的就是标记压缩算法
JVM 分代收集算法
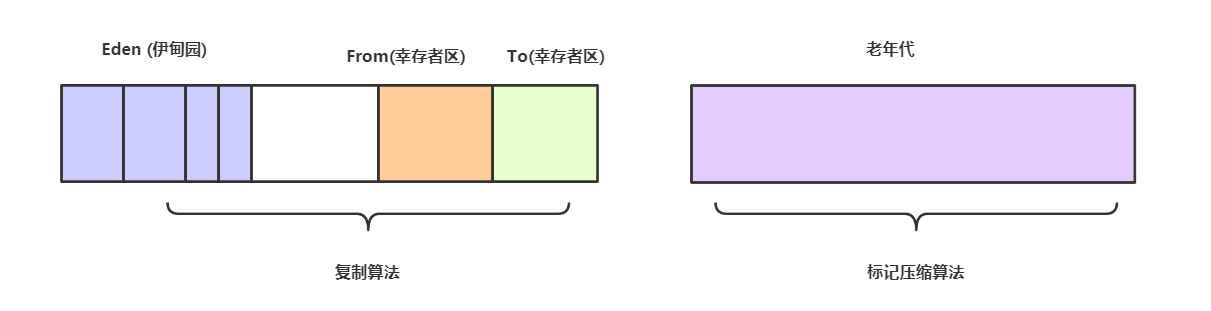
在JVM的内存结构中,按照堆内存的结构划分,大的方面可以分为年轻代和老年代,堆内存是JVM中进行垃圾回收的主要区域
但是各个区域在使用过程中的作用,对象生成规则,对象生命周期的不同又可以细分为各个逻辑上的结构,比如在新生代区域,可以划分为 Eden区和Survivor区,而Survivor再细分为from(s0)区和to(s1)区,通过区域的划分,各个区域的职责更加明确
我们知道,新生代和老年代一个很大的区别在于,新生代是对象频繁产生的区域,也是Minor Gc很频繁的区域,而老年代中的对象大多则是比较稳定的对象,从这个角度上说,各个区域在进行垃圾回收时策略自然不相同
分代收集算法是目前大部分JVM的垃圾收集器采用的算法,新生代对象朝生夕死,生命周期短,内存空间需要频繁的进行清理以应对快速而来的新对象,因此需要更高效的垃圾回收算法
新生代
目前大部分垃圾收集器对新生代都采取Copying算法,因为新生代中每次垃圾回收都要回收大部分对象,也就是说需要复制的操作次数较少,但实际中并不是按照1:1的比例来划分新生代的空间的,一般来说是将新生代划分为一块较大的Eden空间和两块较小的Survivor空间(一般为8:1:1),每次使用Eden空间和其中的一块Survivor空间,当进行回收时,将Eden和Survivor中还存活的对象复制到另一块Survivor空间中,然后清理掉Eden和刚才使用过的Survivor空间
老年代
老年代内存空间相对较大,可以存放更多的对象,通常情况下每次发生Full Gc的间隔时间也较长,而且在老年代中经常需要存放一些大对象,需要连续的内存空间,基于这些特点,在目前主流的JVM垃圾回收器中对于老年代采用压缩算法
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/210188.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
