大家好,又见面了,我是你们的朋友全栈君。
随机梯度下降法
欢迎关注“程序杂货铺”公众号,里面有精彩内容,欢迎大家收看^_^
算法介绍
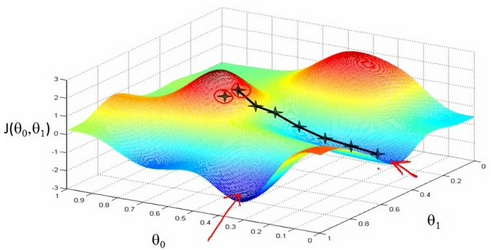

简单来说,梯度下降就是从山顶找一条最短的路走到山脚最低的地方。但是因为选择方向的原因,我们找到的的最低点可能不是真正的最低点。如图所示,黑线标注的路线所指的方向并不是真正的地方。
既然是选择一个方向下山,那么这个方向怎么选?每次该怎么走?
先说选方向,在算法中是以随机方式给出的,这也是造成有时候走不到真正最低点的原因。
如果选定了方向,以后每走一步,都是选择最陡的方向,直到最低点。
总结起来就一句话:随机选择一个方向,然后每次迈步都选择最陡的方向,直到这个方向上能达到的最低点。
在机器学习算法中,有时候需要对原始的模型构建损失函数,然后通过优化算法对损失函数进行优化,以便寻找到最优的参数,使得损失函数的值最小。而在求解机器学习参数的优化算法中,使用较多的就是基于梯度下降的优化算法(Gradient Descent, GD)。
算法优势
优点:效率。在梯度下降法的求解过程中,只需求解损失函数的一阶导数,计算的代价比较小,可以在很多大规模数据集上应用
缺点:求解的是局部最优值,即由于方向选择的问题,得到的结果不一定是全局最优。步长选择,过小使得函数收敛速度慢,过大又容易找不到最优解。
参数介绍
sklearn.linear_model.SGDRegressor(loss=’squared_loss’, *, penalty=’l2′, alpha=0.0001, l1_ratio=0.15, fit_intercept=True, max_iter=1000, tol=0.001, shuffle=True, verbose=0, epsilon=0.1, random_state=None, learning_rate=’invscaling’, eta0=0.01, power_t=0.25, early_stopping=False, validation_fraction=0.1, n_iter_no_change=5, warm_start=False, average=False)
参数:
loss:str, default=’squared_loss’,要使用的损失函数。可能的值是’squared_loss’、’huber’、’epsilon_unsensitive’或’squared_epsilon_unsensitive’普通平方表示拟合的最小平方。“huber”修改了“squared_loss”,通过从平方损失切换到超过epsilon距离的线性损失,减少了对异常值的校正。“epsilon_unsensitive”忽略小于epsilon的错误,并且是线性的;这是SVR中使用的损失函数。“squared_epsilon_unsensitive”是相同的,但在ε的公差后变为平方损失。
penalty:{‘l2’, ‘l1’, ‘elasticnet’}, default=’l2’。 要使用的惩罚(又名正则化术语)。默认为“l2”,这是线性支持向量机模型的标准正则化器。“l1”和“elasticnet”可能会给模型(特征选择)带来“l2”无法实现的稀疏性。
alpha:float, default=0.0001。乘以正则项的常数。值越大,正则化越强。当学习率设为“最优”时,也用于计算学习率。
l1_ratio:float, default=0.15。弹性网络混合参数,0<=l1<=1。l1_ratio=0对应于L2惩罚,l1_ratio=1到l1。仅当惩罚为“elasticnet”时使用。
fit_intercept:bool, default=True。是否应该估计截距。如果为False,则假定数据已经居中。
max_iter:int, default=1000。训练数据的最大传递次数(也称为epochs)。它只影响拟合方法中的行为,而不影响部分拟合方法中的行为。
tol:float, default=1e-3。停止标准。如果不是“无”,则当(损失>最佳损失-公差)更改连续的时间段时,培训将停止。
shuffle:bool, default=True。是否在每个epoch之后对训练数据进行shuffle。
verbose:int, default=0。详细程度。
epsilon:float, default=0.1。Epsilon不敏感损失函数中的Epsilon;仅当损失为“huber”、“epsilon_insensitive”或“squared_Epsilon_unsensitive”时。对于“huber”,它决定了一个阈值,在这个阈值下,准确的预测就变得不那么重要了。对于epsilon-insensitive,如果当前预测与正确标签之间的任何差异小于此阈值,则将忽略这些差异。
random_state:int, RandomState instance, default=None。当shuffle设置为True时,用于洗牌数据。为跨多个函数调用的可复制输出传递一个int。
learning_rate:string, default=’invscaling’。 学习率方法:
“constant”:eta=eta0
“optimal”:eta=1.0/(alpha*(t+t0)),其中t0由Leon Bottou提出的启发式方法选择。
“invscaling”:eta=eta0/pow(t,功率)
“adaptive”:eta=eta0,只要训练持续减少。每次n_iter_no_change连续时间未能减少tol的训练损失或未能增加tol的验证分数(如果提前停止为真),则当前学习率除以5。
eta0:double, default=0.01。“constant”、“invscaling”或“adaptive”规则的初始学习率。默认值为0.01。
power_t:double, default=0.25。逆标度学习率的指数。
early_stopping:bool, default=False。验证分数没有提高时,是否使用提前停止终止培训。如果设置为True,则当分数方法返回的验证分数没有至少提高tol时,它将自动保留一部分训练数据作为验证,并终止训练。
validation_fraction:float, default=0.1。作为早期停机验证设置的培训数据的比例。必须介于0和1之间。仅在“早停”为真时使用。
n_iter_no_change:int, default=5。在提前停止之前没有改进的迭代次数。
warm_start:bool, default=False。当设置为True时,将上一个调用的解决方案重用为fit作为初始化,否则,只需删除以前的解决方案。当warm_start为True时,反复调用fit或partial_fit会导致与一次性调用fit时不同的解决方案,这是因为数据的无序处理方式。如果使用动态学习率,学习率将根据已经看到的样本数进行调整。调用fit重置此计数器,而partial_fit将导致增加现有计数器。
average:bool or int, default=False。当设置为True时,计算所有更新的平均SGD权重,并将结果存储在coef_u属性中。如果设置为大于1的整数,则在看到的样本总数达到平均值后开始平均。所以average=10将在看到10个样本后开始平均。
属性:
coef_:ndarray of shape (n_features,)。为特征指定的权重。
intercept_:ndarray of shape (1,)。截距项。
average_coef_:ndarray of shape (n_features,)。分配给特征的平均权重。仅当average=True时可用。
average_intercept_:ndarray of shape (1,)。平均截距项。仅当average=True时可用。
n_iter_:int。达到停止条件之前的实际迭代次数。
t_:int。训练期间进行的体重更新次数。与(n_iter_u*n_示例)相同。
方法:
densify():将系数矩阵转换为密集数组格式。
fit(X, y[, coef_init, intercept_init, …]):用随机梯度下降拟合线性模型。
get_params([deep]):获取此估计器的参数。
partial_fit(X, y[, sample_weight]):对给定样本执行一个随机梯度下降的历元。
predict(X):用线性模型预测
score(X, y[, sample_weight]):返回预测的决定系数R^2。
set_params(**kwargs):设置并验证估计器的参数。
sparsify():将系数矩阵转换为稀疏格式。
调优方法
具体的损失函数可以通过 loss 参数设置。 SGDRegressor 支持以下的损失函数:
loss=”squared_loss”: Ordinary least squares(普通最小二乘法),
loss=”huber”: Huber loss for robust regression(Huber回归),
loss=”epsilon_insensitive”: linear Support Vector Regression(线性支持向量回归).
Huber 和 epsilon-insensitive 损失函数可用于 robust regression(鲁棒回归)。不敏感区域的宽度必须通过参数 epsilon 来设定。这个参数取决于目标变量的规模。
SGDRegressor 支持 ASGD(平均随机梯度下降) 作为 SGDClassifier。 均值化可以通过设置 average=True 来启用。
对于利用了 squared loss(平方损失)和 l2 penalty(l2惩罚)的回归,在 Ridge 中提供了另一个采取 averaging strategy(平均策略)的 SGD 变体,其使用了随机平均梯度 (SAG) 算法。
适用场景
随机梯度下降(SGD)是一种简单但非常有效的方法,多用用于支持向量机、逻辑回归等凸损失函数下的线性分类器的学习。并且SGD已成功应用于文本分类和自然语言处理中经常遇到的大规模和稀疏机器学习问题。
SGD既可以用于分类计算,也可以用于回归计算。
demo示例
>>> import numpy as np
>>> from sklearn.linear_model import SGDRegressor
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> n_samples, n_features = 10, 5
>>> rng = np.random.RandomState(0)
>>> y = rng.randn(n_samples)
>>> X = rng.randn(n_samples, n_features)
>>> # Always scale the input. The most convenient way is to use a pipeline.
>>> reg = make_pipeline(StandardScaler(),
... SGDRegressor(max_iter=1000, tol=1e-3))
>>> reg.fit(X, y)
Pipeline(steps=[('standardscaler', StandardScaler()),
('sgdregressor', SGDRegressor())])
>>> import numpy as np
>>> from sklearn import linear_model
>>> X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
>>> # y = 1 * x_0 + 2 * x_1 + 3
>>> y = np.dot(X, np.array([1, 2])) + 3
>>> model = linear_model.SGDRegressor(loss='huber', max_iter=1000, tol=1e-3)
>>> model.fit(X, y)欢迎关注“程序杂货铺”公众号,里面有精彩内容,欢迎大家收看^_^

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/161647.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
