大家好,又见面了,我是你们的朋友全栈君。
Java Collection API提供了一些列的类和接口来帮助我们存储和管理对象集合。其实Java中的集合工作起来像是一个数组,不过集合的大小是可以动态改变的,而且集合也提供了更多高级功能。有了JavaCollectionAPI,我们就不需要自己编写集合类了,大部分Java集合类都位于java.util包里面,还有一些和并发相关的集合类位于java.util.concurrent包中。下面就介绍一下Java API 为我们提供的这些集合类。
一、Java 集合概览
Java中的集合有两大类,分别是:
1. Collection
2. Map
Collection类的集合可以理解为主要存放的是单个对象,而Map类的集合主要存储的是key-value类型的对象。这两大类即可理所当然的对应着两个接口,分别是Collection接口和Map接口,下面这幅图列出了这两个接口的继承树:

从上面这幅图可以看到,Collection接口又衍生了出三个分支,分别是:
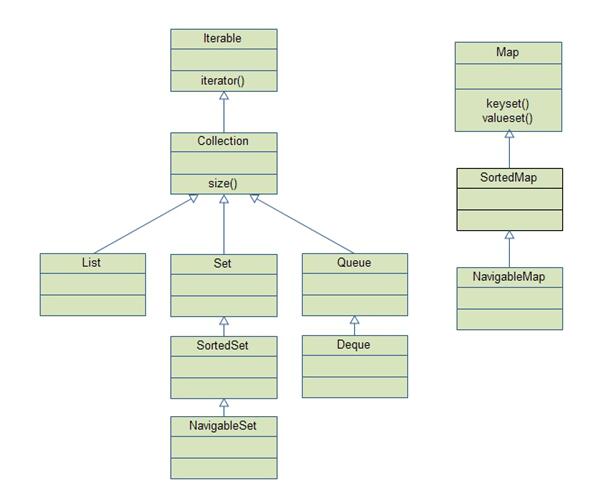
1. List
2. Set
3. Queue
而Map则相对简单,只有一个分支。下面我们就详细介绍Java Collection的每一个实现类。
注意:要把Collection、Collections区分开,Collection是集合的一个接口,而Collections是一个工具类,它提供了一些静态方法来方便我们操作集合的实例,这两个都位于java.util包中。
二、先从Collection接口介绍
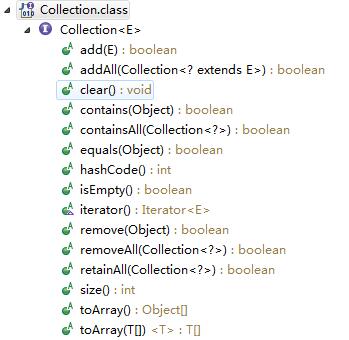
下图是Collection接口的源码截图,从接口中的抽象方法我们可以看出,它定义了一个通用集合常用的方法:
- 增加删除一个元素
- 判断元素是否存在
- 获得集合的大小
- 迭代一个集合
2.1 Collection的List接口
List接口继承自Collection接口,它的特点是其中的对象是有序的,并且每个对象都有一个唯一的index,我们可以通过这个index来搜索某个元素,并且List中的对象允许重复,这类似于一个数组。对于List接口,Java API提供了如下实现:
- java.util.ArrayList
- java.util.LinkedList
- java.util.Vector
- java.util.Stack
当然,在 java.util.concurrent包中也有一些实现,这些内容会在另一篇文章中详细介绍。
ArrayList是最常用的集合,其内部实现是一个数组,ArrayList的大小是可以动态扩充的。对于元素的随机访问效率高,其访问的时间复杂度为O(1),对于数据的插入与删除,从尾部操作效率高,时间复杂度和随机访问一样是O(1),若是从头部操作则效率会比较低,因为从头部插入或删除时需要移动后面所有元素,其时间复杂度为O(n-i)(n表示元素个数,i表示元素位置)。


LinkList:从上图可以看出,不但继承了List接口,还继承了Deque接口(后面会介绍)。LinkList是一个基于链表的数据结构,每个节点都保存了上一个和下一个节点的指针。LinkList对于随机访问效率是比较低的,因为它需要从头开始索引,所以其时间复杂度为O(i)。但是对于元素的增删,LinkList效率高,因为只需要修改前后指针即可,其时间复杂度为O(1)。
Vector:从Vector和ArrayList源码截图可以看出,它们继承的接口完全一致。所以,Vector可以看做是一个线程安全的ArrayList,它内部也是基于数组实现的,不过几乎所有的集合操作都加了synchronized关键字。


Stack:上面是Stack类源码截图,我们看到Stack类其实继承自Vector,Stack只是在Vector的基础上添加了几个方法以提供栈(Last In First Out LIFO)的特性。Stack的特点是添加时新元素会被添加到顶部,移除时顶部的元素最先被移除。这种数据结构主要用作一些特殊数据加工流程,如语言编译、XML解析等。
2.2 Collection的Set接口
Set和List接口一样也是继承自Collection接口,同样是对集合的一种实现,它们之间最大的区别是Set中的对象不允许重复。对于Set接口,Java API提供了如下实现:
- java.util.EnumSet
- java.util.HashSet
- java.util.LinkedHashSet
- java.util.TreeSet
这些类的功能稍有不同,区别主要体现在对象的迭代的顺序及插入、查找的效率上。
HashSet的实现很简单,其内部就是一个HashMap,不过它对元素的顺序没有保证。

LinkedHashSet的实现也很简单,其内部用的是一个LinkedHashMap。因为LinkedHashMap内部维护了一个双向链表以保持顺序,所以LinkedHashSet的特点是它当中的元素是有序的,元素迭代的顺序就是其插入的顺序,元素的再次插入不会影响原有元素的顺序。


TreeSet:从上图的继承关系可以看出,想要了解TreeSet就要先了解NavigableSet和SortedSet接口。
SortedSet接口
public interface SortedSet<E> extends Set<E> {
Comparator<? super E> comparator();
SortedSet<E> subSet(E fromElement, E toElement);
SortedSet<E> headSet(E toElement);
SortedSet<E> tailSet(E fromElement);
E first();
}
从上面接口定义看,SortedSet接口是Set的一个子接口,它除了有一般Set的特性之外它元素在内部是有序的。它内部元素的顺序取决于元素的排序规则,即元素顺序取决于元素对comparable接口的实现或者一个comparator比较器,关于comparable和comparator的区别,可以参考:http://www.cnblogs.com/sunflower627/p/3158042.html
NavigableSet接口
public interface NavigableSet<E> extends SortedSet<E> {
NavigableSet<E> descendingSet();
Iterator<E> descendingIterator();
SortedSet<E> headSet(E toElement);
SortedSet<E> tailSet(E fromElement);
SortedSet<E> subSet(E fromElement, E toElement);
ceiling(), floor(), higher(), and lower()
...
}
从NavigableSet接口定义可以看到,它是SortedSet的一个子接口,并且提供了一些导航方法,至于这些导航方法的含义大家可以查看Java Doc。
所以,TreeSet的特点就是内部元素有序,并且有很多导航方法的实现。从第一部分Java集合类概览中我们知道,Set有一个子接口SortedSet,而SortedSet又有一个子接口NavigableSet接口,Java API对SortedSet、NavigableSet接口的实现只有一个,就是TreeSet。
2.3 Collection的Queue接口
Queue接口继承自Collection接口,它也代表了一个有序的队列,不过这个队列最大的特点就是新插入的元素位于队列的尾部,移除的对象位于队列的头部,这类似于超市中结账的队列。
我们通过第一节的Java集合概览已经知道,Queue接口还有一个子接口Deque,下面我们分别看一下JavaAPI对这两个接口的定义:
Queue接口:
public interface Queue<E> extends Collection<E> {
boolean add(E e);
boolean offer(E e);
E remove();
E poll();
E peek();
}
Deque接口:
public interface Deque<E> extends Queue<E> {
void addFirst(E e);
void addLast(E e);
E removeFirst();
E removeFirst();
}
从这两个接口的定义我想大家已经看出些端倪,Queue接口定义了一般队列的操作方式,而Deque则是一个双端队列。
对于Queue接口,Java API提供了两个实现:
- java.util.LinkedList(也实现了Deque接口)
- java.util.PriorityQueue
LinkedList:前面的List章节已经提到,它是一个标准队列。
PriorityQueue:队列中的顺序类似于TreeSet,取决于元素的排序规则,即元素对comparable接口的实现或者一个comparator比较器。
对于Deque接口,出了LinkList类之外还有一个实现:
- java.util.ArrayDeque
ArrayDeque:从名称可以看出,其内部实现是一个数组。
三、Java 集合之 Map
从第一部分Java集合类概览中我们知道,Map不是继承自Collection接口,而是和Collection接口出于并列的位置。所以,Map的行为和上面介绍的Collection的行为由很大不同。Map的主要特点是它存放的元素为key-value对,我们看一下Map接口的定义:
public interface Map<K,V> {
V put(K key, V value);
boolean containsKey(Object key);
Set<Map.Entry<K, V>> entrySet();
int hashCode(); V get(Object key);
Set<K> keySet();
... ...
}
对于Map接口,Java API提供了如下实现:
- java.util.HashMap
- java.util.Hashtable
- java.util.EnumMap
- java.util.IdentityHashMap
- java.util.LinkedHashMap
- java.util.Properties
- java.util.TreeMap
- java.util.WeakHashMap
其中,我们最常用到的是HashMap和TreeMap。
HashMap中的key、value都是无序的。HashMap的内部实现非常值得研究,具体请参考HashMap内部实现
HashTable可以看做是HashMap的重量级实现,其中的大部分方法都加了synchronized关键字,是线程安全的。HashTable与HashMap的另一个区别是HashMap的key-value都允许为null,而HashTable不可以。
LinkedHashMap也是一个HashMap,只是内部维护了一个双向链表以保持顺序,LinkedHashSet内部实现就是用的LinkedHashMap。
TreeMap中的key、value不但可以保持顺序,类似于TreeSet和PriorityQueue,TreeMap中key、value的迭代顺序取决于它们各自的排序规则。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/160477.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
