大家好,又见面了,我是你们的朋友全栈君。
| 万叶集 |
|---|
| ? 隐约雷鸣,阴霾天空。 ? |
| ? 但盼风雨来,能留你在此。 ? |
前言:
✌ 作者简介:渴望力量的哈士奇 ✌,大家可以叫我 ?哈士奇? ,一位致力于 TFS 赋能的博主 ✌
? CSDN博客专家认证、新星计划第三季全栈赛道 top_1 、华为云享专家、阿里云专家博主 ?
? 如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步?
? 人生格言:优于别人,并不高贵,真正的高贵应该是优于过去的自己。?
? 如果感觉博主的文章还不错的话,还请?关注、点赞、收藏三连支持?一下博主哦
专栏系列(点击解锁) 学习路线指引 知识定位 ?Python全栈白皮书? 零基础入门篇 以浅显易懂的方式轻松入门,让你彻底爱上Python的魅力。 语法进阶篇 主要围绕多线程编程、正则表达式学习、含贴近实战的项目练习 。 自动化办公篇 实现日常办公软件的自动化操作,节省时间、提高办公效率。 自动化测试实战篇 从实战的角度出发,先人一步,快速转型测试开发工程师。 数据库开发实战篇 更新中 爬虫入门与实战 更新中 数据分析篇 更新中 前端入门+flask 全栈篇 更新中 django+vue全栈篇 更新中 拓展-人工智能入门 更新中 网络安全之路 踩坑篇 记录学习及演练过程中遇到的坑,便于后来居上者 网安知识扫盲篇 三天打鱼,不深入了解原理,只会让你成为脚本小子。 vulhub靶场漏洞复现 让漏洞复现变得简单,让安全研究者更加专注于漏洞原理本身。 shell编程篇 不涉及linux基础,最终案例会偏向于安全加固方向。 [待完结] WEB漏洞攻防篇 2021年9月3日停止更新,转战先知社区等安全社区及小密圈 渗透工具使用集锦 2021年9月3日停止更新,转战先知社区等安全社区及小密圈 点点点工程师 测试神器 – Charles 软件测试数据包抓包分析神器 测试神器 – Fiddler 一文学会 fiddle ,学不会倒立吃翔,稀得! 测试神器 – Jmeter 不仅是性能测试神器,更可用于搭建轻量级接口自动化测试框架。 RobotFrameWork Python实现的自动化测试利器,该篇章仅介绍UI自动化部分。 Java实现UI自动化 文档写于2016年,Java实现的UI自动化,仍有借鉴意义。 MonkeyRunner 该工具目前的应用场景已不多,文档已删,为了排版好看才留着。


在上一章节我们对正则表达式有了一个比较宏观的认识,并且知道了正则表达式的主要功能是通过匹配规则来获取或者验证字符串中的数据。要想成功的进行字符串的匹配需要使用到正则表达式模块,正则表达式匹配规则以及需要被匹配的字符串。在这三个条件中,模块与字符串都是准备好的,只有匹配规则异常的灵活,而今天这个章节就是认识一下正则表达式中的特殊字符,通过这些字符就可以针对我们想要的数据进行匹配。
? 正则表达式中的特殊字符
特殊字符 描述 \d 匹配任何十进制的数字,与[0-9]一致 \D 匹配任意非数字 \w 匹配任何字母数字下划线及unicode字符集 \W 匹配非字母数字的数据以及下划线 \s 匹配任何空格字符,与 [\n \t \r \v \f] 相同 \S 匹配任意非空字符 \A 匹配字符串的起始 \Z 匹配字符串的结束 . 匹配任何字符(除了 \n 之外);也叫做通配符
? 正则表达式的使用
接下来看一个小案例,帮助我们了解这些 特殊字符的使用方法 。
import re
test_data = "My name is Neo, I'm 30 years old." # 将一串字符串赋值给变量 test_data
result_int = re.findall('\d', test_data) # 使用 findall 函数并传入 '\d' 的匹配规则匹配 test_data(只匹配数字)
result_Space = re.findall('\s', test_data) # 使用 findall 函数并传入 '\d' 的匹配规则匹配 test_data(只匹配空格)
result_str = re.findall('\w', test_data) # 使用 findall 函数并传入 '\d' 的匹配规则匹配 test_data(匹配字符串)
result_str_start = re.findall('\AMy', test_data) # 匹配开头为 My 的字符串
result_str_start_null = re.findall('\AMya', test_data) # 匹配开头为 Mya 的字符串(不存在 mya ,返回空列表)
result_str_end = re.findall('old.\Z', test_data) # 匹配结尾为 old. 的字符串
result_str_end_null = re.findall('zold.\Z', test_data) # 匹配结尾为 zold. 的字符串(不存在 zold ,返回空列表)
result_all = re.findall('.', test_data) # 匹配除了 \n 之外的所有字符(包含空格)
print(result_int)
print(result_Space)
print(result_str) # 从结果上来看 \w 要比 \d 更高级一些,不仅匹配了 str,也匹配了 int(实际上这里的int依然是字符串)
print(result_str_start)
print(result_str_start_null)
print(result_str_end)
print(result_str_end_null)
# >>> 执行结果如下
# >>> ['3', '0']
# >>> [' ', ' ', ' ', ' ', ' ', ' ', ' ']
# >>> ['M', 'y', 'n', 'a', 'm', 'e', 'i', 's', 'N', 'e', 'o', 'I', 'm', '3', '0', 'y', 'e', 'a', 'r', 's', 'o', 'l', 'd']
# >>> ['My']
# >>> []
# >>> ['old.']
# >>> []
# >>> ['M', 'y', ' ', 'n', 'a', 'm', 'e', ' ', 'i', 's', ' ', 'N', 'e', 'o', ',', ' ', 'I', "'", 'm', ' ', '3', '0', ' ', 'y', 'e', 'a', 'r', 's', ' ', 'o', 'l', 'd', '.']
? 正则小案例 – 1
1、定义一个函数,判断传入参数是否包含有数字。
2、定义一个函数,判断传入参数是否含有数字,如果有则移除。
import re
def have_number(data): # 定义一个判断是否存在数字的函数
result = re.findall('\d', data) # 利用 re 模块的 findall 函数的 \d 规则判断传入的 data 是否存在数字
print(result)
for i in result: # 利用 for 循环 判断 result 的结果,如果存在返回 True ;反之返回 False
return True
return False
def remove_number(data):
result = re.findall('\D', data)
print(result)
return ' '.join(result)
if __name__ == '__main__':
test_data_1 = "My name is Neo, I'm 30 year's old."
test_data_2 = "it's a beautiful day to be with you"
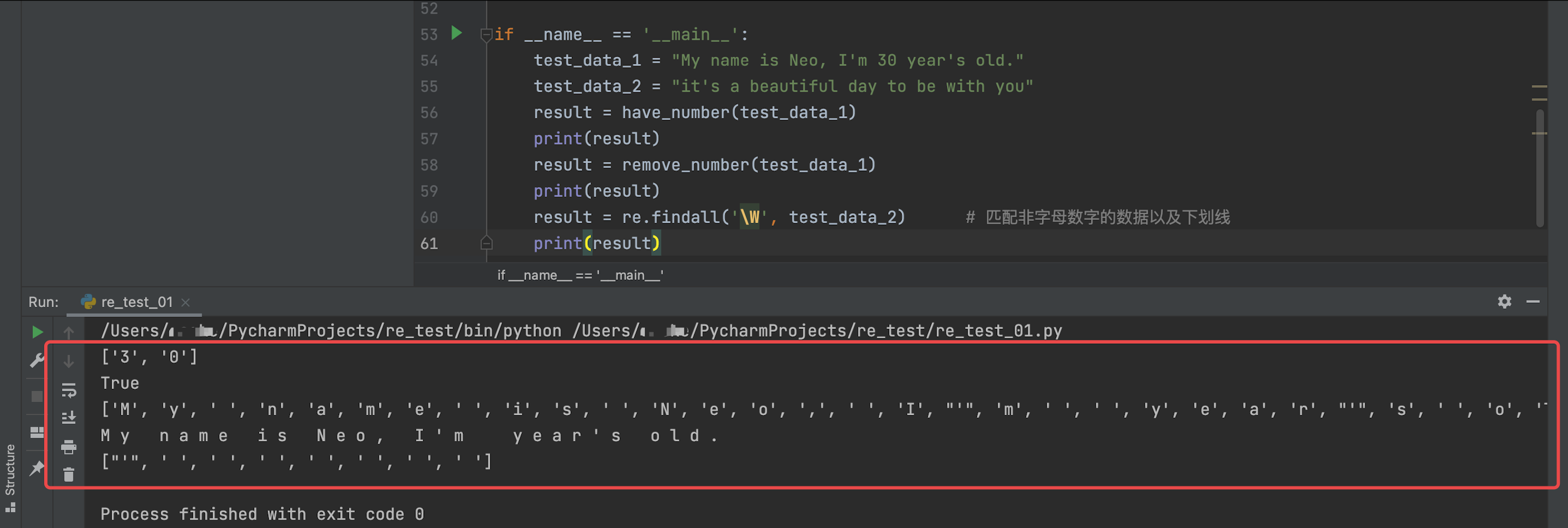
result = have_number(test_data_1)
print(result)
result = remove_number(test_data_1)
print(result)
result = re.findall('\W', test_data_2) # 匹配非字母数字的数据以及下划线
print(result)
运行结果如下图:
? 正则小案例 – 2
1、定义一个 startwith 函数 判断传入数据是否是字符串的开头
2、定义一个 endwith 函数 判断传入数据是否是字符串的结尾
import re
def startswith(sub, data):
_sub = '\A{}'.format(sub)
result = re.findall(_sub, data)
for i in result:
return True
return False
def endswith(sub, data):
_sub = '{}\Z'.format(sub)
result = re.findall(_sub, data)
if len(result) == 0:
return False
else:
return True
if __name__ == '__main__':
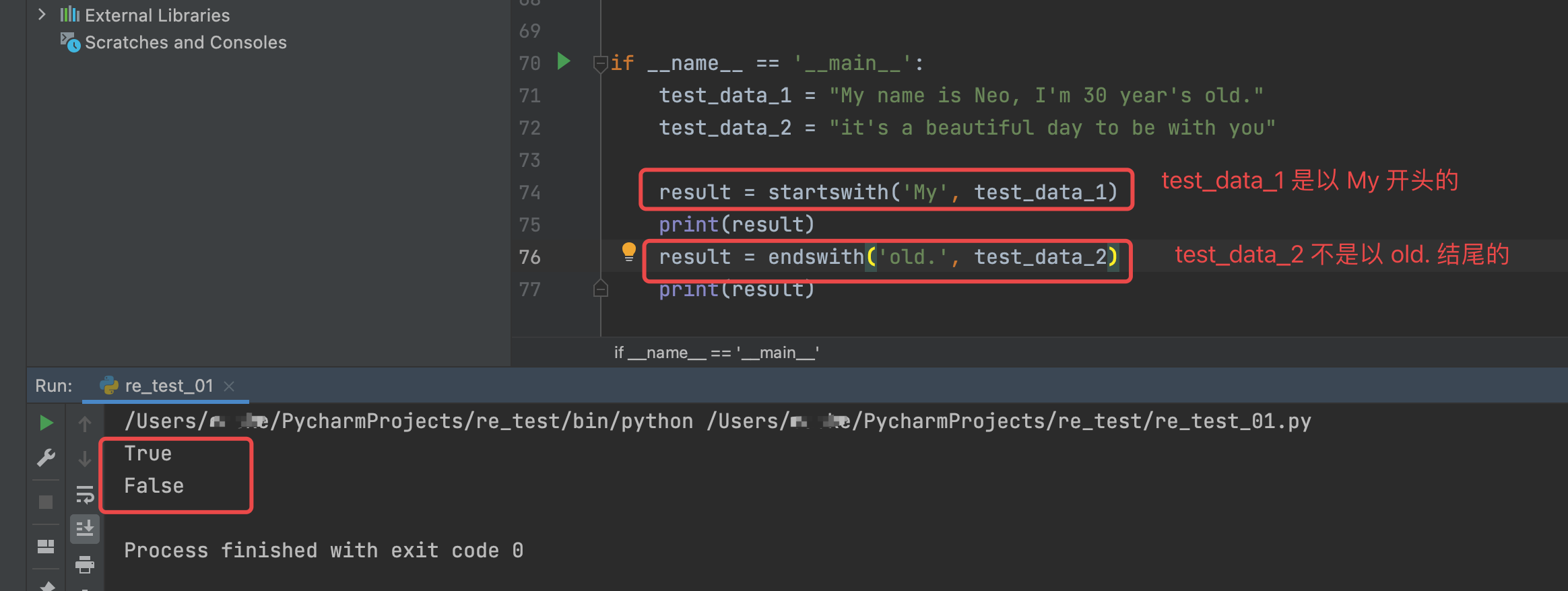
result = startswith('My', test_data_1)
print(result)
result = endswith('old.', test_data_2)
print(result)
执行结果如下:
? 正则小案例 – 3
1、python 内置函数 len() 是可以获取到字符串的长度的,但是当字符串中存在着空格符号的时候也会计算在长度内。
2、利用正则的知识,定义一个计算字符串真实长度的函数
import re
def real_len(data):
result = re.findall('\S', data)
return len(result)
if __name__ == '__main__':
test_data_1 = "My name is Neo, I'm 30 year's old."
test_data_2 = "it's a beautiful day to be with you"
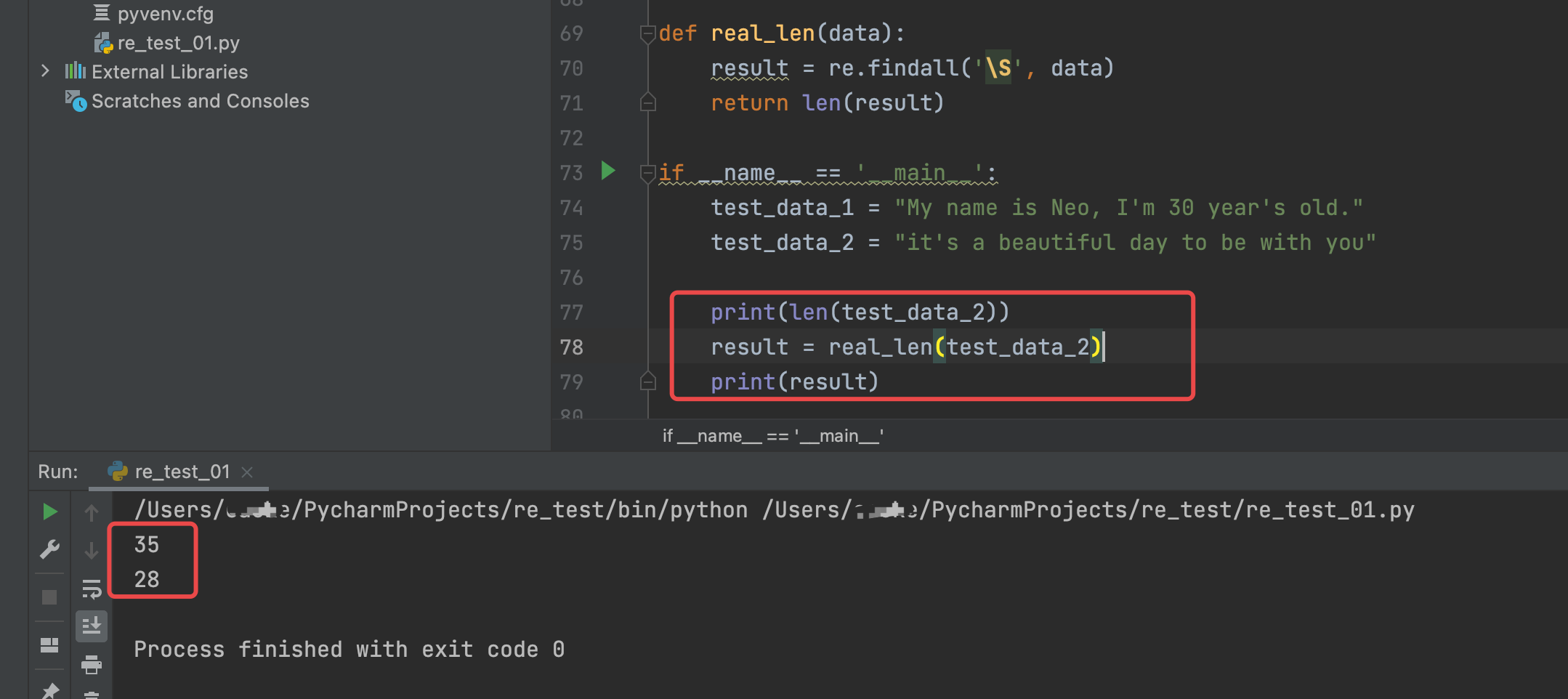
print(len(test_data_2))
result = real_len(test_data_2)
print(result)
运行结果如下:
思考:大家可以看出上述的示例中,原本是单词的一部分没经过正则匹配输出之后,变成了一个个单独的字符串,有没有什么办法让它仍按照原本的单词进行输出呢?这就是我们下一章节的内容了,这里就先卖个关子吧。???
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/159364.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
