大家好,又见面了,我是你们的朋友全栈君。
我没学过python,通过网上和一些图书资料,自学并且记下笔记。
很多细节留作以后自己做项目时再研究,这样能更高效一些。
python基础自学笔记
一、基本输入和输出
pthon3.0用input提示用户输入,用print提示用户输出,格式为print(“…”)
如果格式化输出,那么格式为print(“%d” %(变量名)), %d可以替换为%s等其他格式符,
以后用到什么格式自己查,这样学起来高效。
简单的例子:
#-*-coding:utf-8-*- name = input("What's your name ? >") age = input("How old are you ? >") print ("your name is %s, your age is %d" %(name, int(age))) print ("你的名字是 %s, 你的年龄是 %d" %(name,int(age)))
运行结果:


二、基本数据结构
1 列表
列表和C++里边的list差不多
插入方式为: list.insert(1,‘小草’);
1为要插入元素放在下标为1的位置,‘小草’为要插入的元素
移除元素的方式为:list.pop(3);
指定取出下标为3的元素
list中元素是按照从下标为0开始计算的。
如果要计算列表中元素个数可以通过len(list)计算。
下面是个小例子:
animals = ["大象","猴子","蚂蚁","豪猪"] print ("动物园有这些动物:", animals) lion = "狮子" print ("新来了", lion) animals.insert(1,lion) print ("动物园有这些动物:", animals) animals.pop(3) print ("蚂蚁灭绝了") print ("动物园有这些动物:", animals) print ("老虎和狮子交配生了两个小宝宝") babies = ["小宝宝1号", "小宝宝2号"] animals.insert(2,babies); print ("动物园有这些动物:", animals) print("饲养员给两个小宝宝取了名字") animals[2][0]="小毛" animals[2][1]="大毛" print ("动物园有这些动物:",animals) print("列表中有%d个元素" %len(animals)) print("第三个元素包含%d个元素" %len(animals[2]))
试着用python 运行上面这个程序
2 tuple(元组)
tuple定义之后不可修改,理解为不可修改的列表就行了
试着运行下面这个程序,看看结果:
#-*-coding:utf-8-*- nums = (0,1) print("nums are", nums) another = (0,1,[3,4]) print("nums are", another) another[2][0] = 5 print("nums are", another);
为什么another能被修改?因为another[2]指向的是list,接着将list的第一个元素,
下表为0的元素赋值为5,这是允许的。
3 dict(字典)
字典和C++map很相似,但是不完全相同,字典dict可以包含不同类型的key和value
字典的插入方式很简单d[‘韩梅梅’]=23
d为字典定义的变量名,key为‘韩梅梅’, value为23
当字典d中没有‘韩梅梅’这个key,那么就会将key和value插入d
如果调用d[‘韩梅梅’]=22,那么‘韩梅梅’对应的value就为22了
如果字典d中没有‘李磊’这个key,那么调用print(d[‘李磊’])就会提示出错。
所以取元素的时候要记得判断字典中是否有该key对应的value
可以通过get和in判断,下边代码有使用方法。
字典同样调用pop移除元素
d.pop(‘韩梅梅’)
下面这段代码综合了dict使用方式
infos = {"李明":23, "豆豆":22,"老李":55}
print("李明的年龄为%d" %(infos["李明"]))
infos["王立冬"]=32
print (infos)
#print (infos["梁田"])
if not ("梁田" in infos):
print("梁田不在记录")
print(infos.get("梁田"))
print(infos.get("梁田","梁田不在记录"))
infos.pop("王立冬")
print (infos)
用python调用上边代码,看看效果。
4 set(集合)
集合中允许存在多个重复的值
集合添加元素用add,删除用remove操作
下边的代码为集合操作
numset = set([1,3,5,7,9]) print(numset) numset.add(4) print(numset) numset.add(4) print(numset) numset.remove(3) print(numset) numset2 = set([2,4,6,8,10]) print(numset&numset2) print(numset|numset2)
三、循环和控制
这部分和C++差不多,就是基本写法不一样
nums = (0,100,34,50,179,130,27,22) print("nums are:", nums) bigernums =[] smallnums = [] for num in nums: if num > 50: bigernums.append(num) print("大于50的数字有:", bigernums) for num in nums: if num < 50: smallnums.append(num) print("小于50的数字有:", smallnums) print(range(5)) print(list(range(5))) #1~10数字求和 sum = 0 for num in list(range(11)): sum += num print("1到10数字求和结果为:%d" %sum) #错误输出 #print("1到10数字求和结果为:%d", sum) #换一种方式求和,while循环注意别写成死循环 i = 0 sum = 0 while i < 11: sum += i i=i+1#i++不行,习惯了C++ print("1到10数字求和结果为:%d" %sum)
python通过缩进和:控制模块。
四、函数
1 定义函数
#函数的定义 def judgeint(x): if not isinstance(x,(int)): raise TypeError('类型不匹配') else: return x
是通过def 函数名(参数):方式来定义函数。上面这个函数定义在func.py文件中,
我再写一个文件使用这个函数
from func import judgeint numlist = [1,3,5] strlist =['1','2','3'] for i in numlist: print(judgeint(i)) for j in strlist: print(strlist(j))
结果为:

可见strlist中字符串类型被函数识别并终止程序运行了。
想用到某个.py文件的函数可以用
from 文件名(不包含.py) import 函数名
如果想用文件中所有的接口
from 文件名(不包含.py) import *
其他的引用方式我也不会,以后遇到了再去查。
也可以去写一个空函数
#空函数 def emptyfun(x): pass
pass表示什么都不做。
当然函数可以返回许多值,这些值其实是通过tuple返回的
定义函数
#多个返回值 def getposition(x,y): return x, y
调用这个函数
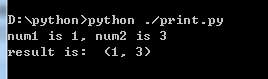
from func import * num1 = 0; num2 = 0 num1, num2 = getposition(1,3) print('num1 is %d, num2 is %d' %(num1,num2)) print('result is: ', getposition(1,3) )
结果为:
2 函数参数分类和使用
1 位置参数
位置参数是普通的参数
如下:
def power(x): return x*x
2 默认参数
默认参数提供了参数的默认赋值
#默认参数 def power(x,n = 2): imul =1 while(n > 0): imul = x*imul n = n-1 return imul
值得注意的是默认参数要指向不可变对象,否则函数重复调用默认参数会被修改
def getList(L=[]): L.append("end") return L
重复调用看看结果如何:
#-*-coding:utf-8-*- from func import * L=[] print(getList(L)) print(getList(L))
结果

可以看出默认参数随着函数调用被修改了,所以尽量不要让默认参数指向可变对象,
list就是可变对象。
3 可变参数
可变参数使用和定义都非常方便
定义:
def calsum(*nums): sum = 0 for i in nums: sum = sum+ i return sum
使用:
#-*-coding:utf-8-*- from func import * L=[1,3,5,7,9] print(calsum(*L)) print(calsum(*range(0,101)))
定义可变参数前边加*,使用时可以传入list,tuple等,实参前也加*即可。
4 关键字参数
其实和可变参数类似,关键字参数可以直接传入字典
定义:
def getinfo2(name, age, **info): print("姓名:", name, "年龄:", age, "其他信息:", info) def getinfo3(name,age,**info): if 'city' in info: print("有城市信息") if 'job' in info: print("有工作记录") print("姓名:", name, "年龄:", age, "其他信息:", info)
定义关键字参数在形参前边加**
使用:在实参前加**表示取出字典中所有内容依次传递给函数
from func import * info ={'性别':'女','job':'学生','city':'上海'} info2 ={'性别':'男','job':'工人','city':'北京'} getinfo2('韩梅梅', 23, **info) getinfo3('李雷',25,**info2)
结果

5 命名关键字参数
命名关键字参数就是传入命名的关键字,如指定传入的关键字参数的key为‘city’,‘type’等等。
举例:
def getinfo8(name, age, *,city, job): print("姓名:", name, "年龄:", age, "城市:", city, "工作:", job) def getinfo7(name, age, *infolist, city, job): print("姓名:", name, "年龄:", age, "城市:", city, "工作:", job, "其他信息:", infolist)
可以看出命名关键字参数格式为(*,指定名称1,指定名称2…)的格式
当明明关键字参数之前的参数为可变参数时,那么不需要*,只需指明指定的几个名成即可
格式为:(*可变参数,指定名称1,指定名称2…)
试着写个代码用一下:
from func import * info ={'性别':'女','job':'学生','city':'上海'} info2 ={'性别':'男','job':'工人','city':'北京'} getinfo2('韩梅梅', 23, **info) getinfo3('李雷',25,**info2) getinfo8('王麻子',70, city ='南京', job = '裁缝') infolist = ['有犯罪记录','酗酒'] getinfo7('张三',50,*infolist,city ='翰林',job ='无业游民')
读者自己打印下,看看结果

当然命名关键字参数可以提供默认值
def getinfo4(name, age,*,city='沈阳',job): print("姓名:", name, "年龄:", age, "城市:", city, "工作:", job)
6 参数混合使用
当参数列表包含位置参数,默认参数,可变参数,关键字参数和明明关键字参数时,
从左到右的顺序为
位置参数,默认参数,可变参数,命名关键字参数,关键字参数
读者可以自己考虑下为什么这么规定
下面定义两个函数:
def getinfo5(name,age,city='沈阳',**info): print("姓名:", name, "年龄:", age, "城市:", city, "其他信息:", info) def getinfo6(name,age,city='沈阳',*infolist ,health = '良好', job,**otherinfo): print("姓名:", name, "年龄:", age, "城市:", city, '工作信息:',job,'\n', "身体状况", health, "个人备注",infolist,'\n', "其他信息:", otherinfo)
使用这一系列定义的函数
info5 ={'性别':'男','job':'工人','兴趣':'修自行车'}
baselist=('Linkn',28,'上海','喜欢喝冰啤酒','爱打麻将')
getinfo6(*baselist,**info5)
getinfo5('Linkn',28,'上海',**info5);
函数调用传入实参都可以通过*arg,**dict格式,提高了开发效率
7 递归函数
递归函数和C++一样,先实现一个阶乘的函数
#递归计算阶乘函数 def imul2(num=1): if num ==1: return num else: return num * imul2(num-1)
print(imul2(3)) 看看结果
同样去实现汉诺塔
编写move(n, a, b, c)函数,它接收参数n,表示3个柱子A、B、C中第1个柱子A的盘子数量,
然后打印出把所有盘子从A借助B移动到C的方法,计算n==3时,移动方法

读者试着自己完成,我是这样实现的
def move(n,A,B,C): if n==1: print("%s --> %s" %(A,C)) return else: move(n-1,A,C,B) move(1,A,B,C) move(n-1,B,A,C)
调用
move(3,’A’,’B’,’C’)
结果为

用递归很简单实现了复杂的逻辑,但是递归有一个问题就是当递归次数过大容易造成栈溢出。
基础先记到这里,下一篇会记录python的特性和函数编程。
我的公众号,谢谢关注:

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/156057.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
