大家好,又见面了,我是你们的朋友全栈君。
Hadoop 是什么


Hadoop 是一个提供分布式存储和计算的开源软件框架,它具有无共享、高可用(HA)、弹性可扩展的特点,非常适合处理海量数量。
- Hadoop 是一个开源软件框架
- Hadoop 适合处理大规模数据
- Hadoop 被部署在一个可扩展的集群服务器上
Hadoop 三大核心组件
- HDFS(分布式文件系统) -—— 实现将文件分布式存储在集群服务器上
- MAPREDUCE(分布式运算编程框架) —— 实现在集群服务器上分布式并行运算
- YARN(分布式资源调度系统) —— 帮用户调度大量的 MapReduce 程序,并合理分配运算资源(CPU和内存)
Hadoop 优点
-
高可靠性
Hadoop 维护存储多个数据副本,增加数据冗余,避免数据丢失
-
高扩展性
Hadoop 集群可以方便地扩展更多的集群节点
-
高效性
Hadoop 能够在集群节点之间动态地移动数据,并保证各个节点数据的动态平衡,以并行的方式工作,处理速度非常快
-
高容错性
Hadoop 维护存储多个数据副本,并且能够自动将失败的任务重新分配
-
低成本
Hadoop 是开源框架,项目的软件成本会大大降低。 Hadoop 使用 Java 语言编写,可以跨平台运行
Hadoop 生态圈
Hadoop 生态圈是指围绕 Hadoop 软件框架为核心而出现的越来越多的相关软件框架,这些软件框架和 Hadoop 框架一起构成了一个生机勃勃的 Hadoop 生态圈。在特定场景下,Hadoop 有时也指代 Hadoop 生态圈。
Hadoop 生态圈的架构图
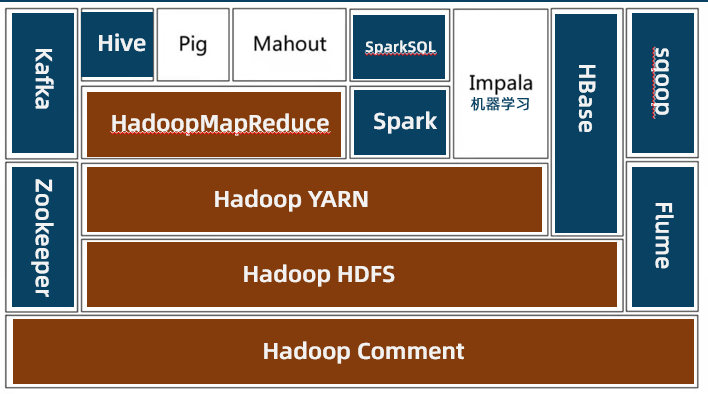
- Hadoop Common:Hadoop 体系最底层的一个模块,是其他模块的基础设施
- HDFS:Hadoop 分布式文件系统,是 Hadoop 的基石
- YARN:另一种资源协调器,是统一资源管理和调度平台
- MapReduce:是一种编程模型,非常适合进行分布式计算
- Spark:新一代计算框架,和 MapReduce 相比性能大幅度提升
- HBase:是一个分布式的、面向列族的数据库(底层依赖 HDFS)
- Hive:是一个基于 Hadoop 的数据仓库工具(SQL 语句)
- Pig:与Hive 类似,也是对大型数据集进行分析和评估的工具
- Impala:与 Hive 类似,可以对存储在 HDFS、HBase的海量数据提交交互式 SQL 查询的工具
- Mahout:是一个机器学习和数据挖掘库,可以实现经典的机器学习算法
- Flume:是一个高可用、高可靠、分布式的海量日志采集框架
- Sqoop:是一个关系型数据库与 Hadoop 之间进行数据相互转换的工具
- Kafka:是一种高吞吐量的分布式发布/订阅消息系统
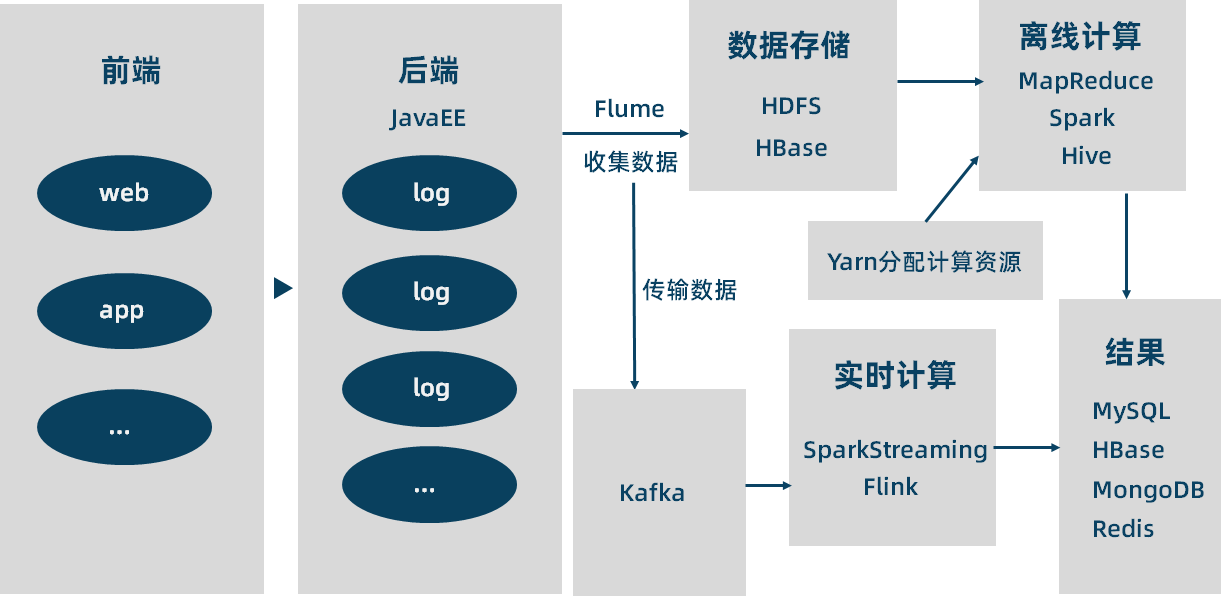
大数据处理平台及核心技术
Hadoop 与云计算
什么是云计算
云计算是一种可以通过网络方便地接入共享资源池、按需获取计算资源(如网络、服务器、存储、应用、服务等)的服务模型。
之所以称之为”云“,是因为云计算在某些地方和现实中的云非常符合,云的规模可以动态伸缩,边界模糊,飘忽不定,无法确定具体位置,但它确实存在于某处。
云计算的特点
- 按需提供服务(如租用云服务器,用户可以按需申请配置,如CPU 核数、内存大小等)
- 宽带网络访问(用户可以利用各种终端设备随时随地通过互联网访问云计算服务)
- 资源池化(资源以共享资源池的方式统一管理,利用虚拟化技术将资源分享给不同用户)
- 高可伸缩性(服务的规模可快速伸缩,如云盘扩容)
- 可量化的服务(可以通过监控软件监控用户的使用情况,根据资源的使用情况对服务计费,如云盘的流量)
- 大规模(如 google 云计算中心具有 100 多万台服务器)
云计算的类型
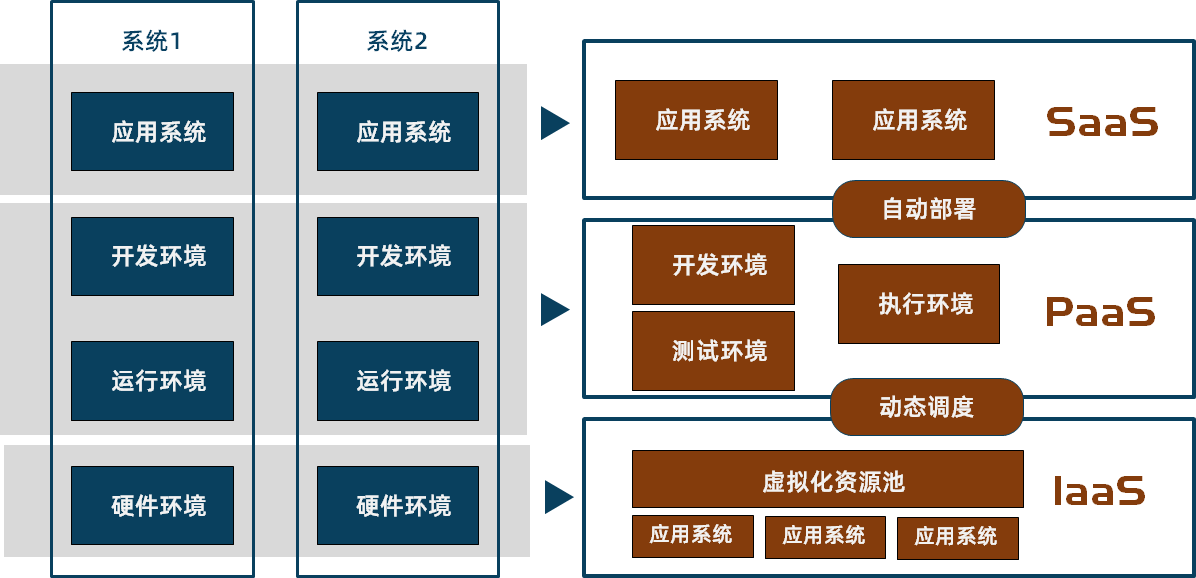
云计算按照服务类型大致分为3类
-
基础设施即服务(IaaS):提供用户硬件设备(云服务器)
-
平台即服务(PaaS):提供用户应用程序的应用环境(不需要维护服务器,只需上传应用程序即可)
-
软件即服务(SaaS):提供用户应用程序(云盘、云笔记)
国内云计算技术走在前列的有华为公司、阿里巴巴集团、百度等,主要以互联网企业巨头和系统集成提供商为主
Hadoop 仅是云计算技术的一种实现,但云计算的概念则更为广阔,并不局限于某种技术。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/155441.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
