大家好,又见面了,我是你们的朋友全栈君。
什么是数据库索引?
数据库索引是对数据库表中一列或多列进行排序的一种结构,使用索引可以快速访问数据库表中的特定信息。数据库索引就像书的目录,能加快数据库的查询速度。索引分为聚簇索引(聚集索引)和非聚簇索引(非聚集索引)。聚簇索引是按照数据存放的物理位置为顺序的,聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。索引包含从表或视图中一个或多个列生成的键,以及映射到指定数据的存储位置的指针。通过创建良好的索引以支持查询,可以显著提高数据库查询和应用程序的性能。索引可以减少为返回结果集而必须读取的数据量。索引还可以强制表中的行具有唯一性,从而确保表的数据完整性。
如果没有索引
Table Scan:
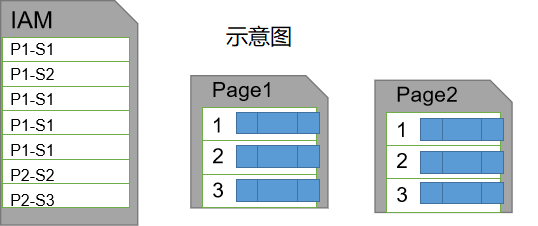
页(Page):8KB,数据库文件存储的基本单位(即使读取一行,也要加载一页)。存储表数据(有可能是多行)或索引数据,以及其他系统数据。
区(Extent):8个连续的页。以64KB为届:分配新区/页。(TRUNCATE:清空整个区)
堆(Heap):没有聚集索引的页
Index Allocation Map:索引分配映射

索引的语法
CREATE [index_type] INDEX index_name ON table_name(column_1[, column_2, ...]) DROP INDEX table_name.index_name
理解:索引和表分离。
因为SELECT中的WHERE clause可以依赖表有多个字段,所以一张表就可以建多个索引,多种索引。
而且,同一个列上也可以建多个索引(但应该尽力避免)
聚集索引
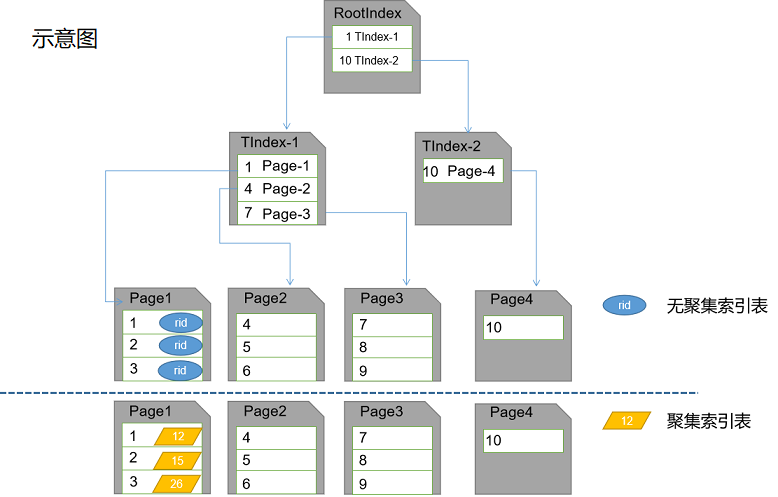
聚集索引是根据数据行的键值在表或视图中排序和存储这些数据行。索引定义中包含聚集索引列。每个表只能有一个聚集索引列。因为数据行本身只能按一个顺序排序。只有当表包行聚集索引时,表中的数据行才按排序顺序存储。如果表具有聚集索引,则该表称为聚集表。如果表没有索引,则其数据存在一个成为堆的无序结构中。
非聚集索引
非聚集索引具有独立于数据行的结构。非聚集索引包行非聚集索引键值,并且每个键值顶部都有指向包行该键值的数据行的指针。从非聚集索引中的索引行指向数据行的指针成为行定位器。行定位器的结构取决于数据页是存储在堆中还是聚集表中。对于堆,行定位器是指向行的指针。对于聚集表,行定位器是聚集索引键。
创建索引的注意事项应该创建索引的这些列具有以下特点
1、在经常需要搜索的列上。可以加快搜索的速度。
2、在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
3、在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的。
4、在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的的排序,加快排序查询的时间
5、在经常使用WHERE子句的适合
不应该创建索引的列:
1、对于那些在查询中很少使用或者参考的列不应该创建索引。既然这些这些列很少使用到,因此有索引或无索引并不能提高查询速度。相反,由于增加了索引,反而降低了系统维护速度还增大了空间需求。
2、快速开发平台对于那些只有很少数据值的列也不应该增加索引。
3、对于那些定义为text,image,和bit数据类型的不应该增加索引。因为这种列的数据量要么相当大,要么取值很少,不利于使用索引 。
4、当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的,当增加索引时,会提高检索性能,但是会降低修改性能。
文章转载自:快速开发平台– 云微平台
地址:https://www.hocode.com/
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/155102.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
