大家好,又见面了,我是你们的朋友全栈君。
前言
转置卷积,学名transpose convolution,在tf和torch里都叫这个。
有时在论文里可以看到别人叫它deconvolution(反卷积),但这个名词不合适。
因为转置卷积并非direct convolution的逆运算(reverse),并不能还原出原张量,所以叫它逆卷积是错的。
只是从形状上看,其结果的形状等同于原张量的形状。
写这篇文章是因为网上介绍转置卷积的博客,
都讲不清楚,我看了半天还是云里雾里。
只能自己手动来一篇了。
一、 基本运算——错位扫描
定义 本文中,我们将平时用到的普通卷积,称为direct convolution。
transpose conv 与 direct conv最大的区别在于:
转置卷积支持错位扫描。
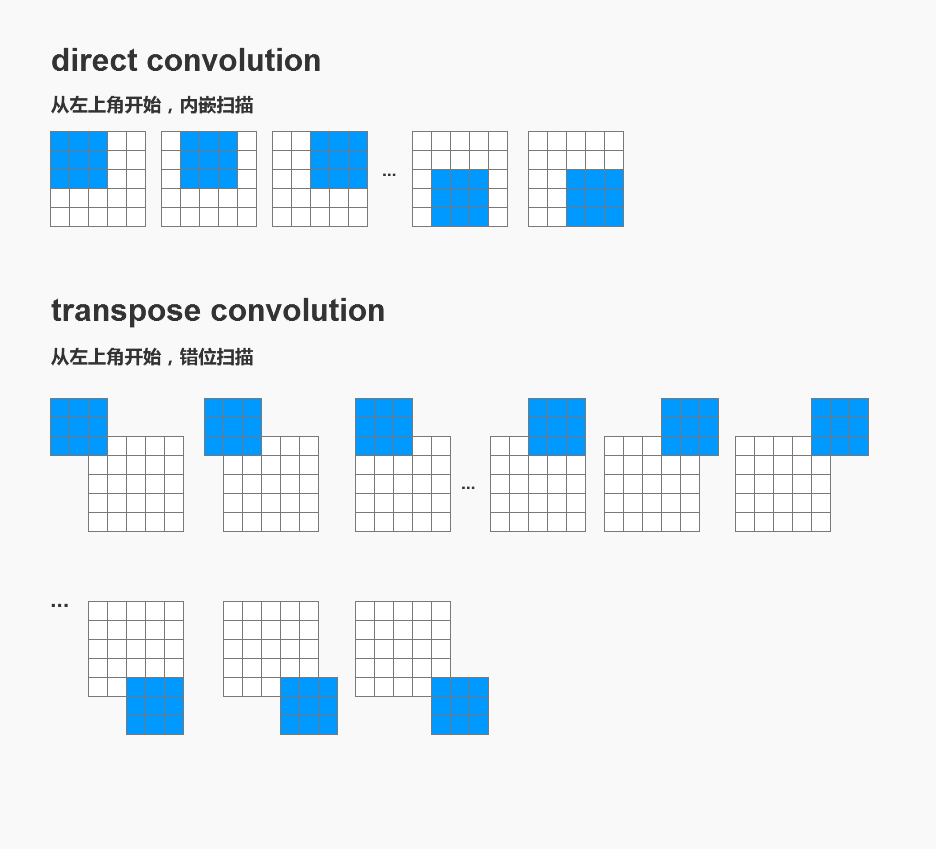

显然,错位扫描的性质使得扫描次数变多了。因此transpose conv的输出结果,shape会比输入大。
这就是转置卷积能在shape上还原input的基本原理。(当然数值上并不能还原)
二、形状公式
这篇介绍卷积的论文写得,十!分!详!尽!
但是跟天书一样难懂。
A guide to convolution arithmetic for deep learning
Vincent Dumoulin, Francesco Visin
https://arxiv.org/abs/1603.07285
我尝试另外写一份自己的版本。
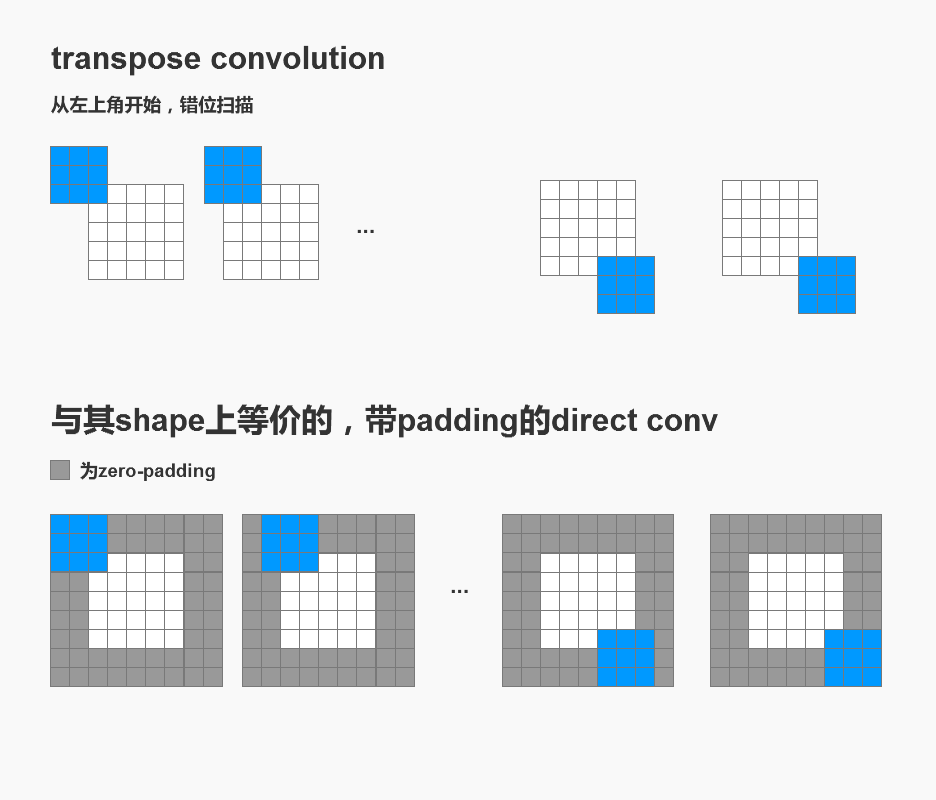
定义2.1 我们将kernel_size相同的,能还原输入shape的转置卷积,称为与direct conv相对应的 transpose conv。
例如我们输入一个(7×7),直接卷积得到(3×3)。
那么理论上存在很多个transpose conv能从(3×3)还原为(7×7),这不利于我们研究。
所以我们规定只有kernel_size相同的那个transpose conv是对应的, corresponding transpose conv。
定理2.1 每一个direct conv对应的transpose conv,又存在一个shape变换上等价的,对应的direct conv。
显然,想实现(3×3)还原为(7×7)这件事,我们也能用带padding的direct conv做到,不是吗?
其他情况也是一样的,仅仅还原形状的话,transpose conv总是可以用某个direct conv代替,我们也称呼kernel_size相同的,仅仅padding不同的那个为corresponding direct conv。
现在我们有了3个不同的概念,original direct conv, corresponding transpose conv, corresponding direct conv.
先约定几个符号表示,以下简称
对direct conv
input_size = i (注意,我们隐性地假设了2D输入的形状是正方形所以只需要一个字母i,而不必用2个字母wh)
output_size = o
kernel_size = k
padding = p
stride = s
对transpose conv
input_size=i’
output_size = o’
kernel_size = k’,由于我们只研究the corresponding one,所以此处k’=k
padding=p’
stride=s’
我们希望转置卷积的输出,能恢复原来的输入形状,即希望 o’=i ,
定理2.2 direct conv的形状公式
o = [ i + 2 ∗ p − ( k − 1 ) ] / s o=[i+2*p-(k-1)]/s o=[i+2∗p−(k−1)]/s
这条公式学过卷积的人都不会陌生。
定理2.3 transpose conv的形状公式
o ′ = [ i ′ + 2 ∗ p ′ + ( k ′ − 1 ) ] / s ′ o’= [i’+2*p’+(k’-1)]/s’ o′=[i′+2∗p′+(k′−1)]/s′
初学者大多数会晕在这一步,因为转置卷积悄悄地偷换了2个概念 ,s’与p’。
往下看就明白为什么说偷换了。
我先给出结论,
在现行的对应转置卷积中,s’总是等于1,p’<=0。
证明
对定理2.2进行变形,得到
i = o ∗ s + ( k − 1 ) − 2 ∗ p = o ∗ s + ( k − 1 ) + 2 ∗ ( − p ) i= o*s+(k-1) -2*p \\ =o*s +(k-1) +2*(-p) i=o∗s+(k−1)−2∗p=o∗s+(k−1)+2∗(−p)
对照定理2.3 o ′ = [ i ′ + ( k − 1 ) + 2 ∗ p ′ ] / s ′ o’= [i’+(k-1)+2*p’]/s’ o′=[i′+(k−1)+2∗p′]/s′
如果我们希望达成 o ′ = i o’=i o′=i,corresponding transpose conv就应该满足:
i ′ = o ∗ s i’=o*s i′=o∗s
p ′ = − p p’=-p p′=−p
s ′ = 1 s’=1 s′=1
虽然上述3个条件不是唯一解,但却是实践应用中最简单的一组解,所以被作为默认解。你去看torch和tf的源码,都是这么设置的。
上式表明,欲使转置卷积的输出 o ′ o’ o′完美还原直接卷积的输入形状 i i i,
需要先对 o o o做 s t r i d e stride stride处理,
然后进行步长为1的错位扫描得到(k-1)的形状增益,
最后减去 p a d d i n g padding padding。
“进行步长为1的错位扫描能得到(k-1)的形状增益”是一个不言自证的结论。
三、进阶运算,stride处理,步长1的错位扫描,与padding消融
本节对第二节中最后推导出的3个步骤进行分解说明。
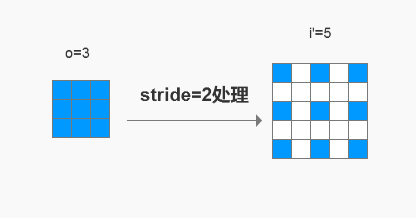
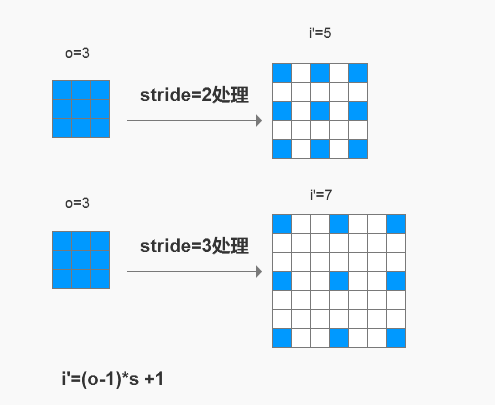
3.1 stride处理
我称之为内部zero-padding,简称内部padding。
简单的说,就是把转置卷积的输入o先放大stride倍,
填充的部分使用zero。(而不是一般图片用的插值填充)
这里肯定有人会奇怪,
按第二节给出的公式, i ′ = o ∗ s = 3 ∗ 2 = 6 i’=o*s=3*2=6 i′=o∗s=3∗2=6才对,怎么会是5。
事实上,我们在实践中真正使用的处理公式是
i ′ = ( o − 1 ) ∗ s + 1 i’=(o-1)*s+1 i′=(o−1)∗s+1
我将在第五节补充讨论这个问题。
3.2 步长1的错位扫描
这个在第一节已经介绍过了。
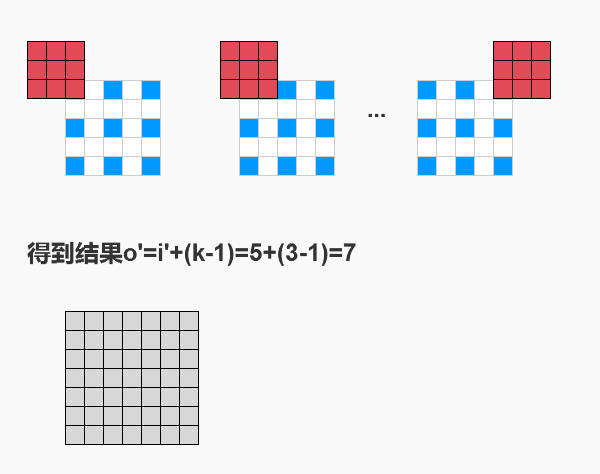
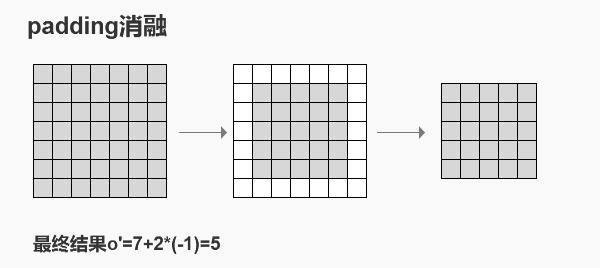
3.3 padding消融
上节说过 p ′ = − p p’=-p p′=−p,这意味着我们在转置卷积中,做的不是加边,而是消边。
以p=1为例,那么p’=-1,我们需要在四周消去1条边。
最终o’=7+2*(-1)=5
四、代码验证3步骤的正确性
注意!torch中的weight会被reverse。
本节通用头文件
import torch
import torch.nn.functional as F
4.1 一个基本的1d转置卷积
算2d很累的,看看1d弄明白就行了。
代码参考
inputs = torch.Tensor([[1,2,3],[4,5,6]]).unsqueeze(0) #(1,2,3)
weights = torch.Tensor([1.1,2.2,3.3]).view(1,1,-1).repeat(2,1,1) #(2,5,k=3)
print(inputs.shape)
print(weights.shape)
o =F.conv_transpose1d(inputs, weights,padding=0,stride=1)
print(o.shape)
print(o)
打印结果
torch.Size([1, 2, 3])
torch.Size([2, 1, 3])
torch.Size([1, 1, 5])
tensor([[[ 5.5000, 18.7000, 41.8000, 42.9000, 29.7000]]])
对上述运算进行基本说明。
inputs形状为[batch_size,C_in,L_in]=[1,2,3]
weights的形状为[C_in,C_out,kernel_size] = [2,1,3]
输出的形状为[batch_size,C_out,L_out] = [1,1,5]
本例中,我们设置
batch_size=1,
C_in=2,
L_in=3,即直接卷积的输出o=3
C_out=1,
k=3
p=0
s=1
其中C_out本质上是输出特征图的数量,我们令为1,所以结果只需要输出一张特征图。
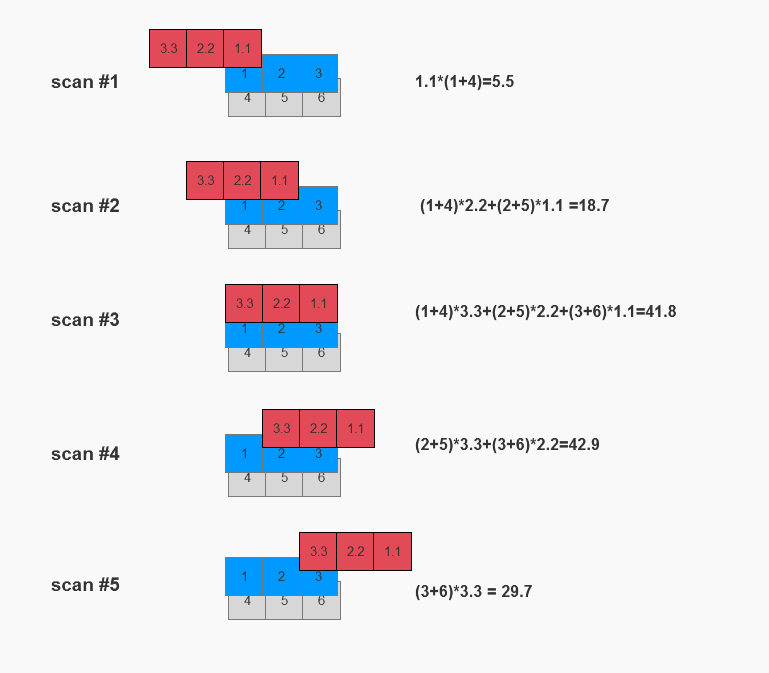
对结果进行分析不难发现
o = tensor([[[ 5.5000, 18.7000, 41.8000, 42.9000, 29.7000]]])
5.5 = (1+4)*1.1
18.7= (2+5)*1.1+(1+4)*2.2
41.8= (3+6)*1.1+(2+5)*2.2+(1+4)*3.3
42.9= (3+6)*2.2+(2+5)*3.3
29.7= (3+6)*3.3
对应扫描方式为
这就是很奇怪的一点了,
weights我们定义是 [ 1.1 , 2.2 , 3.3 ] [1.1,2.2,3.3] [1.1,2.2,3.3],
进去运算时,它里面就reverse了变成 [ 3.3 , 2.2 , 1.1 ] [3.3,2.2,1.1] [3.3,2.2,1.1]
当然平时我们用的转置卷积,大多数是随机初始化参数自己去学习的,这个reverse也不影响。
但若是固定weights,自己手动控制转置卷积时,这个reverse就非常值得注意了。
在使用torch时务必当心。
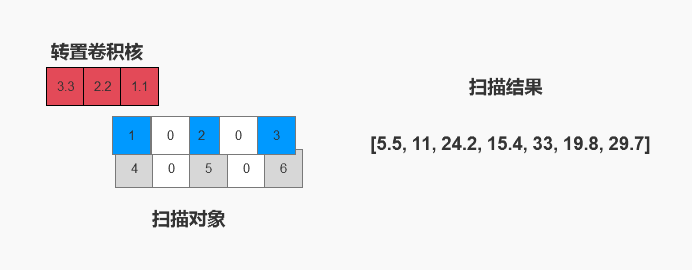
4.2 stride处理的正确性验证
inputs = torch.Tensor([[1,2,3],[4,5,6]]).unsqueeze(0) #(1,2,3)
weights = torch.Tensor([1.1,2.2,3.3]).view(1,1,-1).repeat(2,1,1) #(2,5,k=3)
print(inputs.shape)
print(weights.shape)
o =F.conv_transpose1d(inputs, weights,padding=0,stride=2)
print(o.shape)
print(o)
输出
torch.Size([1, 2, 3])
torch.Size([2, 1, 3])
torch.Size([1, 1, 7])
tensor([[[ 5.5000, 11.0000, 24.2000, 15.4000, 33.0000, 19.8000, 29.7000]]])
本例我们设置p=0,s=2.
如同我们在3.2中猜想的那样,输入的o=3,先被stride=2处理变成i’=5,然后进行k=3、步长为1的错位扫描,最后输出的形状o’=7。
数值上也显然可以验证是正确的。
“由于篇幅限制,这里写不下。”
请读者自行验证。
、
4.3 padding消融的正确性验证
在4.2的代码基础上,把padding改成1即可。
oinputs = torch.Tensor([[1,2,3],[4,5,6]]).unsqueeze(0) #(1,2,3)
weights = torch.Tensor([1.1,2.2,3.3]).view(1,1,-1).repeat(2,1,1)
print(inputs.shape)
print(weights.shape)
o =F.conv_transpose1d(inputs, weights,padding=1,stride=2)
print(o.shape)
print(o)
输出
torch.Size([1, 2, 3])
torch.Size([2, 1, 3])
torch.Size([1, 1, 5])
tensor([[[11.0000, 24.2000, 15.4000, 33.0000, 19.8000]]])
注意到,
4.2中的输出是 [ 5.5 , 11 , 24.2 , 15.4 , 33 , 19.8 , 29.7 ] [5.5, 11, 24.2, 15.4, 33, 19.8, 29.7] [5.5,11,24.2,15.4,33,19.8,29.7],共7个。
4.3中的输出是 [ 11 , 24.2 , 15.4 , 33 , 19.8 ] [11, 24.2, 15.4, 33, 19.8] [11,24.2,15.4,33,19.8],共5个。
我们设p=1之后,输出结果在4.2的基础上,两头各消去1个值,得到o’=5。
至此,我们完美验证了第三节的所有猜想。
草(一种植物)
我突然发现,这个卷积核的英文名叫transpose conv filter。
这东西的断句可能不是(transpose conv) filter,即 filter of transpose conv,
而是transpose (conv filter),即conv filter in transpose form?
难道因为这样,所以weights进去必须被transpose???
所以1.1,2.2,3.3逆转了。
玄学。。。
五、对stride处理的补充
我们回来讨论第三节中遗留的问题,
为什么o=3,s=2,k=3,p=1时,i’=5,而不是6。
再次回顾转置卷积的背景意义,我们希望在shape上还原直接卷积的input。
不妨思考,i=多少时,经过k=3,p=1,s=2的直接卷积,能得到o=3?
在第四节的代码已经能看到,我们最终还原出来的o’=5。
显然可以验证,如果i=5,k=3,p=1,s=2,我们是能得到o=3的。
关键在于直接卷积有一个隐性操作,
若 [ i + 2 ∗ p − ( k − 1 ) ] % s ! = 0 [ i+2*p-(k-1) ]\%s !=0 [i+2∗p−(k−1)]%s!=0
直接卷积,会额外做padding操作。
本例中,i=5,k=3,p=1,s=2,计算得到 i + 2 ∗ p − ( k − 1 ) = 5 + 2 ∗ 1 − ( 3 − 1 ) = 5 i+2*p-(k-1)=5+2*1-(3-1)=5 i+2∗p−(k−1)=5+2∗1−(3−1)=5,不能被 s = 2 s=2 s=2整除。
于是5又额外pad一次,得到6,然后 o = 6 / 2 = 3 o=6/2=3 o=6/2=3。
同理,如果i=6,k=3,p=1,s=2,也能得到o=3。
也就是说,在满足我们给定的背景意义“希望转置卷积还原直接卷积的输入shape”的基础上, {o=3,k=3,p=1,s=2}这组条件,有2个解,i=5 or i=6。
但计算机中,我们不可能让transpose_conv_layer输出2个解,我们只能求一个确定解,这样才有计算可行性。
因此这种“内部pad”的stride处理方式,本质上是一种人为规定。
虽然给定条件可能对应多个解,但我们总是取最小的那个解。
而且,这种stride处理方式,看起来很优美不是吗。
六、corresponding direct conv
我们回顾第二节中获得的公式
i = o ∗ s + ( k − 1 ) − 2 ∗ p = o ∗ s + ( k − 1 ) + 2 ∗ ( − p ) i= o*s+(k-1) -2*p \\ =o*s +(k-1) +2*(-p) i=o∗s+(k−1)−2∗p=o∗s+(k−1)+2∗(−p)
继续变形得到
i = o ∗ s + 2 ∗ ( k − 1 ) − ( k − 1 ) + 2 ∗ ( − p ) = o ∗ s + 2 ∗ ( k − 1 − p ) − ( k − 1 ) i =o*s+2*(k-1)-(k-1)+2*(-p)\\ =o*s+2*(k-1-p) – (k-1) i=o∗s+2∗(k−1)−(k−1)+2∗(−p)=o∗s+2∗(k−1−p)−(k−1)
对照定理2.2的式子
o ′ ′ = [ i ′ ′ + 2 ∗ p ′ ′ − ( k ′ ′ − 1 ) ] / s ′ ′ o”=[i”+2*p”-(k”-1)]/s” o′′=[i′′+2∗p′′−(k′′−1)]/s′′
不难得出,corresponding direct conv若想让输出完美还原输入,
需要令
i ′ ′ = o ∗ s i”=o*s i′′=o∗s
k ′ ′ = k k”=k k′′=k
s ′ ′ = 1 s”=1 s′′=1
p ′ ′ = k − 1 − p p”=k-1-p p′′=k−1−p
才能得到 o ′ ′ = = i o”==i o′′==i
当然,我们也会遇到第四节中讨论的多解问题。
因此同样的,我们也对 i ′ ′ = o ∗ s i”=o*s i′′=o∗s进行微调,
改为采用 i ′ ′ = ( o − 1 ) ∗ s + 1 i”=(o-1)*s+1 i′′=(o−1)∗s+1,这样总是能得到多个解中的最小值。
这一节有什么意义呢?
我也不知道。
但是第二节中那篇论文的作者很热衷于讨论这个东西。(摊手)
他有一个字面意思上有趣的结论。
我们先约定s=1。
如果p=0,就能得到
p ′ ′ = k − 1 p”=k-1 p′′=k−1,那个作者称这个 p ′ ′ p” p′′为fully-padding。
于是我们可以这样说。
non-padding的direct conv,对应的corresponding direct conv是fully-padding的。
相反地,如果想让 p ′ ′ = 0 p”=0 p′′=0,就需要 p = k − 1 p=k-1 p=k−1
于是可以说
fully-padding的direct conv,对应的corresponding direct conv是non-padding的。
大概就是这么个用处吧。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/151942.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
