大家好,又见面了,我是你们的朋友全栈君。
几种常见的距离计算公式
在学习分类、聚类、预测、推荐算法的过程中常常会遇到比较两个或多个对象的相似性,而相似性的度量可以通过计算距离来实现。我们常用的距离计算公式是欧几里得距离公式,但是有时候这种计算方式会存在一些缺陷,那么就需要另外的计算方法去加以补充,本文将介绍几种在机器学习中常用的计算距离。
在做很多研究问题时常常需要估算不同样本之间的相似性度量(Similarity Measurement),这时通常采用的方法就是计算样本间的“距离”(Distance)。采用什么样的方法计算距离是很讲究,甚至关系到分类的正确与否。
1. 欧氏距离
欧式距离就是“两点”之间的直线距离。
(1)二维平面上两点 a ( x 1 , y 1 ) a(x_1,y_1) a(x1,y1)与 b ( x 2 , y 2 ) b(x_2,y_2) b(x2,y2)间的欧氏距离:


(2)两个n维向量 a ( x 11 , x 12 , … , x 1 n ) a(x_{11},x_{12},…,x_{1n}) a(x11,x12,…,x1n)与 b ( x 21 , x 22 , … , x 2 n ) b(x_{21},x_{22},…,x_{2n}) b(x21,x22,…,x2n)间的欧氏距离:

2. 曼哈顿距离
曼哈顿距离又称城市街区距离,不是直线距离。
(1)二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离

(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离

3. 切比雪夫距离
(1)二维平面两点a(x1,y1)与b(x2,y2)间的切比雪夫距离

(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的切比雪夫距离

4. 闵氏距离
两个n维变量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:

其中p是一个变参数。
闵氏距离定义的是一组距离公式,它包括欧式距离、曼哈顿距离和切比雪夫距离
当p=1时,是曼哈顿距离
当p=2时,是欧氏距离
当p→∞时,是切比雪夫距离
总结:闵氏距离存在明显的缺点。
举个例子:二维样本(身高,体重),其中身高范围是150190,体重范围是5060,有三个样 本:a(180,50),b(190,50),c(180,60)。那么a与b之间的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c之 间的闵氏距离,但是身高的10cm真的等价于体重的10kg么?因此用闵氏距离来衡量这些样本间的相似度很有问题。
闵氏距离的缺点主要有两个:(1)将各个分量的量纲(scale),也就是“单位”当作相同的看待了。(2)没有考虑各个分量的分布(期望,方差等)可能是不同的。
5. 标准化欧氏距离
针对原始的欧式距离的不足,提出了标准化欧氏距离公式,两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的标准化欧氏距离的公式:

假设样本集X的均值(mean)为m,标准差(standard deviation)为s,那么X的“标准化变量”表示为:

标准化后的值 = ( 标准化前的值 - 分量的均值 ) /分量的标准差
其中,一组数的标准差 S N S_N SN可以表示为:

平均值为:

贝赛尔修正
在上面的标准差公式中,存在一个值为N的分母,其作用为将计算得到的累积偏差进行平均,从而消除数据集大小对计算数据离散程度所产生的影响。不过,使用N所计算得到的方差及标准差只能用来表示该数据集本身(population)的离散程度;如果数据集是某个更大的研究对象的样本(sample),也就说数据是取样出来的,那么在计算该研究对象的离散程度时,就需要对上述方差公式和标准差公式进行贝塞尔修正,将N替换为N-1:

是否使用贝塞尔修正,是由数据集的性质来决定的:如果只想计算数据集本身的离散程度(population),那么就使用未经修正的公式;如果数据集是一个样本(sample),而想要计算的则是样本所表达对象的离散程度,那么就使用贝塞尔修正后的公式。在特殊情况下,如果该数据集相较总体而言是一个极大的样本 (比如一分钟内采集了十万次的IO数据) — 在这种情况下,该样本数据集不可能错过任何的异常值(outlier),此时可以使用未经修正的公式来计算总体数据的离散程度。
6. 余弦相似度
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫”余弦相似性”。下面看一下余弦函数的图像:


余弦相似性推导公式如下:

(1)在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:

(2) 两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦

即:

欧氏距离和余弦相似度的联系:
假设二维空间两个点,

然后归一化为单位向量,

那么余弦相似度就是:

(分母是1,省略了)
欧式距离就是:

化简后就是:

总结:夹角余弦取值范围为[-1,1]。夹角余弦越大表示两个向量的夹角越小,夹角余弦越小表示两向量的夹角越大。当两个向量的方向重合时夹角余弦取最大值1,当两个向量的方向完全相反夹角余弦取最小值-1。根据欧氏距离(或曼哈顿距离、切比雪夫距离、闵氏距离等)和余弦相似度各自的计算方式和衡量特征,分别适用于不同的数据分析模型:
欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异;而余弦相似度更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分用户兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦相似度对绝对数值不敏感)。
7. 马氏距离
马氏距离(Mahalanobis Distance)是一种距离的度量,可以看作是欧氏距离的一种修正,修正了欧式距离中各个维度尺度不一致且相关的问题。马氏距离(Mahalanobis Distance)是度量学习中一种常用的距离指标,同欧氏距离、曼哈顿距离、汉明距离等一样被用作评定数据之间的相似度指标。但却可以应对高维线性分布的数据中各维度间非独立同分布的问题。
有M个样本向量X1~Xm,协方差矩阵记为S,均值记为向量μ(一个特征或一个维度上计算均值,等于维度的个数),则其中样本向量X到u的马氏距离表示为:

而其中向量Xi与Xj之间的马氏距离定义为:


协方差矩阵S的介绍:
(1)协方差,在概率论和统计学中,协方差用于衡量两个变量(就是两个特征或者维度)的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。期望值分别为E[X]与E[Y]的两个实随机变量X与Y之间的协方差Cov(X,Y)定义为:


如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值时另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值;如果两个变量的变化趋势相反,即其中一个变量大于自身的期望值时另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。如果X与Y是统计独立的,那么二者之间的协方差就是0,因为两个独立的随机变量满足E[XY]=E[X]E[Y]。但是,反过来并不成立。即如果X与Y的协方差为0,二者并不一定是统计独立的。协方差Cov(X,Y)的度量单位是X的协方差乘以Y的协方差。而取决于协方差的相关性,是一个衡量线性独立的无量纲的数。协方差为0的两个随机变量称为是不相关的。
当X,Y是同一个随机变量时,X与其自身的协方差就是X的方差,可以说方差是协方差的一个特例。

或

(2)对多个维度(特征) X = [ X 1 , X 2 , X 3 , . . . , X n ] T \textbf X=[X_1, X_2, X_3, …, X_n]^T X=[X1,X2,X3,...,Xn]T,需要计算各维度两两维度(特征)之间的协方差,这样各协方差组成了一个 n ∗ n n*n n∗n的矩阵,称为协方差矩阵。协方差矩阵是个对称矩阵,对角线上的元素是各维度上随机变量的方差。我们定义协方差矩阵为S。矩阵内的元素 S i j S_{ij} Sij为:
S i j = cov ( X i , X j ) = E [ ( X i − E [ X i ] ) ( X j − E [ X j ] ) ] \ S_{ij}=\operatorname{cov}(X_i,X_j)=\operatorname{E}\big[(X_i-\operatorname{E}[X_i])(X_j-\operatorname{E}[X_j])\big] Sij=cov(Xi,Xj)=E[(Xi−E[Xi])(Xj−E[Xj])]
这样,这个矩阵为:
S = E [ ( X − E [ X ] ) ( X − E [ X ] ) T ] \ S=\operatorname{E}\big[(\textbf X-\operatorname{E}[\textbf X]\big)(\textbf X-\operatorname{E}[\textbf X])^T] S=E[(X−E[X])(X−E[X])T](仅代表n个维度而已)

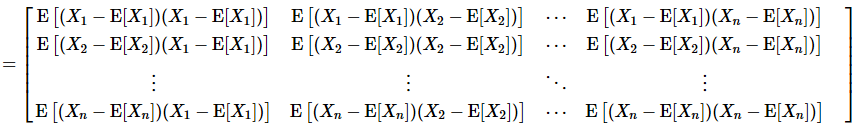
若协方差矩阵是单位矩阵(各个样本向量之间独立同分布),则公式就成了:

即欧氏距离。若协方差矩阵是对角矩阵,公式变成了标准化欧氏距离。
总结
优点:(1)它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关。(它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度);(2)马氏距离还可以排除变量之间的相关性的干扰。
缺点:(1)夸大了变化微小的变量的作用。(2)受协方差矩阵不稳定的影响,马氏距离并不总是能顺利计算出。即计算马氏距离过程中,要求总体样本数大于样本的维数,否则得到的总体样本协方差矩阵逆矩阵不存在。(3)如果样本的维数非常大,那么计算它的协方差矩阵是十分耗时的
8. 汉明距离
在信息理论中,Hamming Distance 表示两个等长字符串在对应位置上不同字符的数目,我们以d(x, y)表示字符串x和y之间的汉明距离。从另外一个方面看,汉明距离度量了通过替换字符的方式将字符串x变成y所需要的最小的替换次数。如:
1011101 与 1001001 之间的汉明距离是 2。
2143896 与 2233796 之间的汉明距离是 3。
“toned” 与 “roses” 之间的汉明距离是 3。
9. 巴氏距离
在统计中,Bhattacharyya距离测量两个离散或连续概率分布的相似性。它与衡量两个统计样品或种群之间的重叠量的Bhattacharyya系数密切相关。Bhattacharyya距离和Bhattacharyya系数以20世纪30年代曾在印度统计研究所工作的一个统计学家A. Bhattacharya命名。同时,Bhattacharyya系数可以被用来确定两个样本被认为相对接近的,它是用来测量中的类分类的可分离性。
(1)巴氏距离的定义对于离散概率分布 p和q在同一域 X,它被定义为:

其中:

是Bhattacharyya系数。对于连续概率分布,Bhattacharyya系数被定义为:

在 这两种情况下,巴氏距离并没有服从三角不等式.(值得一提的是,Hellinger距离不服从三角不等式)。
这两种情况下,巴氏距离并没有服从三角不等式.(值得一提的是,Hellinger距离不服从三角不等式)。
对于多变量的高斯分布


和是手段和协方差的分布

需要注意的是,在这种情况下,第一项中的Bhattacharyya距离与马氏距离有关联。
(2)Bhattacharyya系数是两个统计样本之间的重叠量的近似测量,可以被用于确定被考虑的两个样本的相对接近。计算Bhattacharyya系数涉及集成的基本形式的两个样本的重叠的时间间隔的值的两个样本被分裂成一个选定的分区数,并且在每个分区中的每个样品的成员的数量,在下面的公式中使用

考虑样品a 和 b ,n是的分区数,并且 被一个 和 b i的日分区中的样本数量的成员。
被一个 和 b i的日分区中的样本数量的成员。
10. 杰卡德相似系数(Jaccard similarity coefficient)
(1) 杰卡德相似系数
两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。

杰卡德相似系数是衡量两个集合的相似度一种指标。
(2) 杰卡德距离
与杰卡德相似系数相反的概念是杰卡德距离(Jaccard distance)。杰卡德距离可用如下公式表示:

杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。
(3) 杰卡德相似系数与杰卡德距离的应用
可将杰卡德相似系数用在衡量样本的相似度上。
本A与样本B是两个n维向量,而且所有维度的取值都是0或1。例如:A(0111)和B(1011)。我们将样本看成是一个集合,1表示集合包含该元素,0表示集合不包含该元素。
p :样本A与B都是1的维度的个数
q :样本A是1,样本B是0的维度的个数
r :样本A是0,样本B是1的维度的个数
s :样本A与B都是0的维度的个数
那么样本A与B的杰卡德相似系数可以表示为:
这里p+q+r可理解为A与B的并集的元素个数,而p是A与B的交集的元素个数。
而样本A与B的杰卡德距离表示为:

11. 相关系数 ( Correlation coefficient )与相关距离(Correlation distance)
相关距离:

其中, ρ X Y ρ_{XY} ρXY是相关系数:

相关系数是衡量随机变量X与Y相关程度的一种方法,相关系数的取值范围是[-1,1]。相关系数的绝对值越大,则表明X与Y相关度越高。当X与Y线性相关时,相关系数取值为1(正线性相关)或-1(负线性相关)。协方差公式请见马氏距离的介绍或者博客马氏距离-协方差矩阵
12. 信息熵(Information Entropy)
信息熵是衡量分布的混乱程度或分散程度的一种度量。分布越分散(或者说分布越平均),信息熵就越大。分布越有序(或者说分布越集中),信息熵就越小。
计算给定的样本集X的信息熵的公式:

参数的含义:
n:样本集X的分类数
p i p_i pi:X中第i类元素出现的概率
信息熵越大表明样本集X分类越分散,信息熵越小则表明样本集X分类越集中。当X中n个分类出现的概率一样大时(都是1/n),信息熵取最大值log2(n)。当X只有一个分类时,信息熵取最小值0。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150917.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
