大家好,又见面了,我是你们的朋友全栈君。
生存分析(Survival Analysis)、Cox风险比例回归模型(Cox proportional hazards model)及C-index
1. 生存分析
生存分析指的是一系列用来探究所感兴趣的事件的发生的时间的统计方法。常见的有1)癌症患者生存时间分析2)工程中的失败时间分析等等。
1.1 定义
给定一个实例 i i i,我们用一个三元组来表示 ( X i , δ i , T i ) (X_i, \delta_i, T_i) (Xi,δi,Ti),其中 X i X_i Xi表示该实例的特征向量, T i T_i Ti表示该实例的事件发生时间。
如果该实例发生了我们感兴趣的事件,那么 T i T_i Ti表示的是事件发生时间点到基准时间点之间的时间,同时 δ i = 1 \delta_i = 1 δi=1。
如果该实例未发生我们感兴趣的事件,那么 T i T_i Ti表示的是事件发生时间点到观察结束时间点的时间,同时 δ i = 0 \delta_i = 0 δi=0。
生存分析的研究目标就是对一个新的实例 X j X_j Xj,来估计它所发生感兴趣事件的时间。
1.2 删失(censored)
在生存分析研究中,对于某些实例,会出现在我们的研究期间,并没有出现任何感兴趣的时间,我们将这种情况称之为删失(censored)。
出现这种情况的可能原因有:
1)实例在研究阶段就是没有出现感兴趣的事件(right-censored)
2)在研究阶段,丢失了该实例
3)该实例经历了其他的事件导致无法继续跟踪
2 生存概率(Survival probability)
生存概率也叫作生存方程 S ( t ) = P r ( T > t ) S(t) = Pr(T>t) S(t)=Pr(T>t),生存方程指的是实例出现感兴趣的事件的时间 T T T不小于给定的时间 t t t的概率。
2.1 Kaplan-Meier survival estimate
KM方法是一种无参数方法(non-parametric)来从观察的生存时间来估计生存概率的方法。
对于研究中的第 n n n个时间点 t n t_n tn,生存概率可以计算为:
S ( t n ) = S ( t n − 1 ) ( 1 − d n r n ) S(t_n) = S(t_{n-1})(1-\frac{d_n}{r_n}) S(tn)=S(tn−1)(1−rndn)
其中, S ( t n − 1 ) S(t_{n-1}) S(tn−1)指的是在 t n − 1 t_{n-1} tn−1时间点的生存概率; d n d_n dn指的是在时间点 t n t_n tn所发生的事件数; r n r_n rn指的是在快要到时间点 t n t_n tn时,还存活的人(如果在 t n − 1 t_{n-1} tn−1和 t n t_n tn之间有实例censored,那么在计算 r n r_n rn时应该将该患者剔除出去); t 0 = 0 , S ( 0 ) = 1 t_0=0, S(0)=1 t0=0,S(0)=1。


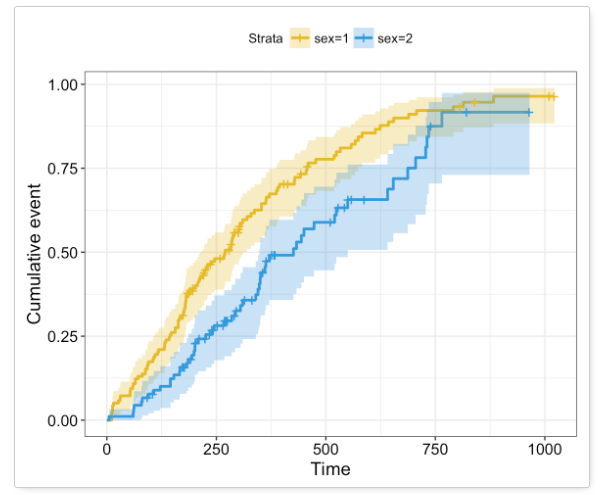
上图为构建的KM生存分析模型可视化结果。其中,
1)曲线上垂直下降的部分表明,在该时刻有感兴趣的事件发生(通过观察 S ( t n ) S(t_n) S(tn)我们能够看到,只有当 d n d_n dn不为零的时候,才会从 S ( t n − 1 ) S(t_{n-1}) S(tn−1)的值才会减小得到 S ( t n ) S(t_n) S(tn);否则,没有事件发生, S ( t n − 1 ) = S ( n ) S(t_{n-1})=S(n) S(tn−1)=S(n))
2)曲线上的垂直stick表示的是,在该时刻,有实例成为了censored,如果在 t n − 1 t_{n-1} tn−1和 t n t_n tn之间有实例censored,那么在计算 r n r_n rn时应该将该患者剔除出去
2.2 Log-Rank test 比较不同的生存曲线
在利用KM方法得到多条生存曲线后,只通过直接的观察来确定多条曲线之间是否具有显著性差异是不充分的。因此,log-rank test被广泛的用来比较两条或多条生存曲线。
1)log-rank test是一种非参数检验,因此对于生存概率的分布没有任何假设;
2)同时,log-rank test 的null hypothesis(原假设)为两个曲线代表的两个组之间,在生存率上没有显著性差异。
3)log-rank test比较的是每个组中观察到的事件数,与在原假设为真的情况下,每个组期望的事件数。
4)log-rank test统计量类似于卡方检验(Chi-square test)的统计量
3 风险概率(hazard probability)
风险概率指的是在时间 t t t之前还没有发生任何事件的情况下,在时间 t t t发生感兴趣的时间的概率。
h ( t ) = lim δ ( t ) → 0 P r ( t ≤ T ≤ t + δ ( t ) ∣ T ≥ t ) δ ( t ) h(t) = \lim_{\delta(t)\rightarrow0}\frac{Pr(t\leq T\leq t+\delta(t)|T\geq t)}{\delta(t)} h(t)=δ(t)→0limδ(t)Pr(t≤T≤t+δ(t)∣T≥t)
3.1 累积风险(cummulative hazard)
在针对单因子进行生存分析时,我们已经得到了生存方程 S ( t ) S(t) S(t),那么,根据 S ( t ) S(t) S(t),累积风险为:
H ( t ) = − log ( S ( t ) ) H(t) = -\log(S(t)) H(t)=−log(S(t))
下图为上述生存方程 S ( t ) S(t) S(t)变换得到的累积风险 H ( t ) H(t) H(t)
4 Cox 比例风险回归模型
4.1 为什么要用Cox 比例风险回归
上述生存分析模型,即Kaplan-Meier survival estimate,是单变量分析(univariable analysis),在做单变量分析时,模型只描述了该单变量和生存之间的关系而忽略其他变量的影响。(为什么要考虑multi-variables?比如在比较两组病人拥有和不拥有某种基因型对生存率的影响,但是其中一组的患者年龄较大,所以生存率可能受到基因型 或/和 年龄的共同影响)
同时,Kaplan-Meier方法只能针对分类变量(治疗A vs 治疗B,男 vs 女),不能分析连续变量对生存造成的影响。
为了解决上述两种问题,Cox比例风险回归模型(Cox proportional hazards regression model)就被提了出来。
4.2 Cox 模型的定义
h ( t , X i ) = h 0 ( t ) × exp ( X i β ) h(t, X_i) = h_0(t) \times \exp(X_i \beta) h(t,Xi)=h0(t)×exp(Xiβ)
其中, h 0 ( t ) h_0(t) h0(t)是基准风险方程,可以是任意一个针对时间 t t t的非负方程; X i X_i Xi是实例 i i i的特征向量; β \beta β是参数向量,该向量是通过最大化cox部分似然得到的。
4.3 partial likelihood
实例 i i i以及其所发生事件的时间 T i T_i Ti,那么实例 i i i发生事件的概率为:
L i ( β ) = h ( T i , X i ) ∑ j : T j ≥ T i h ( T i , X j ) L_i(\beta) = \frac{h(T_i, X_i)}{\sum_{j:T_j \geq T_i}h(T_i, X_j)} Li(β)=∑j:Tj≥Tih(Ti,Xj)h(Ti,Xi)
其中,分子上的项,主要要确定实例 i i i发生事件的时间 T i T_i Ti,有了 T i T_i Ti才能为计算分母来选取实例。
根据时间 T i T_i Ti,分母中首先找到在时间 T i T_i Ti之前还没有发生事件的实例(censored应该不计入了吧,同时应该包含 h ( T i , X i ) h(T_i,X_i) h(Ti,Xi)本身),然后分别计算他们在 T i T_i Ti时刻的风险值并求和作为分母。
这样就得到了针对发生过事件的实例 i i i的发生事件概率 L i ( β ) L_i(\beta) Li(β)
L i ( β ) = h ( T i , X i ) ∑ j : T j ≥ T i h ( T i , X j ) = h 0 ( T i ) × exp ( X i β ) ∑ j : T j ≥ T i h 0 ( T i ) × exp ( X j β ) = exp ( X i β ) ∑ j : T j ≥ T i exp ( X j β ) L_i(\beta) = \frac{h(T_i, X_i)}{\sum_{j:T_j \geq T_i}h(T_i, X_j)} = \frac{h_0(T_i)\times \exp(X_i \beta)}{\sum_{j:T_j \geq T_i}h_0(T_i) \times \exp(X_j \beta)} = \frac{\exp(X_i \beta)}{\sum_{j:T_j \geq T_i} \exp(X_j \beta)} Li(β)=∑j:Tj≥Tih(Ti,Xj)h(Ti,Xi)=∑j:Tj≥Tih0(Ti)×exp(Xjβ)h0(Ti)×exp(Xiβ)=∑j:Tj≥Tiexp(Xjβ)exp(Xiβ)
因此,该概率和时间无关,并不需要来对 h 0 ( t ) h_0(t) h0(t)进行建模,所以称之为partial likelihood。
在得到针对单个实例的事件发生概率之后,为了估计使得所有样本出现我们数据中这样的样本的概率最大,我们需要使用极大似然估计来估计参数。假设每个实例的是独立同分布的,那么我们可以得到针对我们样本的似然概率:
L ( β ) = ∏ i : δ i = 1 exp ( X i β ) ∑ j : T j ≥ T i exp ( X j β ) L(\beta) =\prod_{i:\delta_i=1} \frac{\exp(X_i \beta)}{\sum_{j:T_j \geq T_i} \exp(X_j \beta)} L(β)=i:δi=1∏∑j:Tj≥Tiexp(Xjβ)exp(Xiβ)
该公式的意思为,需要将所有出现过感兴趣事件的实例的概率相乘,即 ∏ i : δ i = 1 \prod_{i:\delta_i = 1} ∏i:δi=1。
得到上述似然概率,我们只需要选择使得 L ( β ) L(\beta) L(β)得到最大值的 β \beta β值即可,即:
arg max β { L ( β ) } \arg\max_\beta\{ L(\beta)\} argβmax{
L(β)}
R语言实现Cox比例风险回归模型
Cox比例风险回归模型wiki
5 C-index
英文全称为concordance index。对于存在censored实例的生存数据,一些标准的评估方法是不合适的,比如均方误差等等。
5.1 计算方法
1)将所有样本两两配对,共组成 N × ( N − 1 ) / 2 N \times (N-1)/2 N×(N−1)/2对
2)排除其中无法判断出谁先出现感兴趣事件的配对。比如配对中两个实例都没有出现感兴趣的事件;配对中的两个实例A、B,如果A是censored(非right-censored),时间为 T A T_A TA,B是发生事件的,其发生时间为 T B T_B TB,并且 T A < T B T_A < T_B TA<TB。排除无法判断谁先出现事件的配对后,得到总的可比较对数为 M M M
3)在剩下的 M M M对中,预测结果和实际结果相一致的配对数为 K K K,即我预测的生存率 S ( X A ) < S ( X B ) S(X_A) < S(X_B) S(XA)<S(XB),实际的 T A < T B T_A < T_B TA<TB,即为相一致。
4)则 c − i n d e x = K M c-index = \frac{K}{M} c−index=MK
C-index的计算可由下列公式描述:
1 M ∑ i : δ i = 1 ∑ j : T i < T j I [ S ( T i , X i ) < S ( T j , X j ) ] \frac{1}{M}\sum_{i:\delta_i=1}\sum_{j:T_i < T_j} I[S(T_i, X_i) < S(T_j, X_j)] M1i:δi=1∑j:Ti<Tj∑I[S(Ti,Xi)<S(Tj,Xj)]
其中,函数 I [ C ] I[C] I[C]指的是如果 C C C为真,则 I [ C ] = 1 I[C] = 1 I[C]=1,否则 I [ C ] = 0 I[C] = 0 I[C]=0;
第一个求和函数 ∑ i : δ i = 1 \sum_{i:\delta_i = 1} ∑i:δi=1表示配对中至少要有一个实例发生了事件;
第二个求和函数 ∑ j : T i < T j \sum_{j:T_i < T_j} ∑j:Ti<Tj表示配对中,另一个的记录时间 T j T_j Tj必须长于第一个实例事件发生时间;两个求和函数选择出了能够用于比较的所有配对组合。
5.2 bootstrap 重抽样
为了得到更加robust的评估结果,希望通过多次重复采样的方法来计算多组评估结果,从而得到更为有说服力的结果。
1)从原始样本中允许重复抽取的抽取一定数量的样本
2)根据抽取得到的新样本,计算统计量 T T T,这里为C-index
3)重复上述N次(一般大于1000),得到N个统计量 T T T
4)计算上述N个统计量 T T T的样本方差
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/146493.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
