大家好,又见面了,我是你们的朋友全栈君。
事务模型描述
1、step之间事务独立
2、step划分成多个chunk执行,chunk事务彼此独立,互不影响;chunk开始开启一个事务,正常结束提交
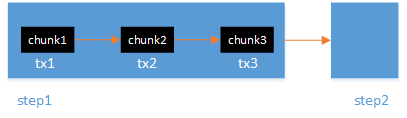

图-job
总体事务
总体事务
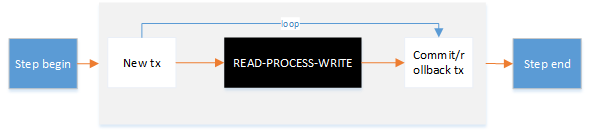 图-step内部事务
图-step内部事务
3、chunk定义:默认设置commitInterval=N,即读取N条数据为一个chunk(采用默认SimpleCompletionPolicy),或者reader里面所读取的item==null,或者
满足自定义完成策略
满足自定义完成策略
事务提交&回滚
1、事务提交条件:chunk执行正常,未抛RuntimeExecption
2、默认情况下,Reader、Processor、Writer抛出未捕获RuntimeException,当前chunk事务回滚,step失败,job失败
3、通过以下配置,保证出现异常时,事务不回滚,事务继续提交:
<batch:tasklet><batch:chunk /><batch:no-rollback-exception-classes><batch:include class="com.xx.batch.DefRuntimeException"/></batch:no-rollback-exception-classes></batch:tasklet>
4、事务配置.通过以下配置,改变事务行为
<batch:tasklet>
<batch:transaction-attributes isolation="READ_COMMITTED" propagation="REQUIRES_NEW" timeout="300"/>
<batch:chunk reader="defItemReader" processor="defItemProcessor" writer="defItemWriter" commit-interval="10"/>
</batch:tasklet>
默认配置:
DEFAULT+REQUIRED
DEFAULT+REQUIRED
参数配置影响
1、
任务恢复
任务恢复
<batch:job id="jobId" restartable="true">
</batch:job>
通过配置job的restartable=true,保证任务失败后能够进行恢复。比如:文件处理时,chunkSize=10,在line=35时处理失败,文件修复后,job将从31行开始重新处理(因为1-10,11-20,21-30进行事务提交,Spring Batch将ExecutionContext中的count持久化到系统表,恢复时读取)
FlatFileItemReader继承
AbstractItemCountingItemStreamItemReader类,所以
默认具备读取恢复能力
AbstractItemCountingItemStreamItemReader类,所以
默认具备读取恢复能力
2、跳过
<batch:chunk skip-limit="20"><batch:skippable-exception-classes><batch:include class="com.xx.batch.ExceptionClass" /></batch:skippable-exception-classes></batch:chunk>
或者
<batch:chunk skip-policy="defSkipPolicy">
</batch:chunk>
跳过数据量或者跳过策略不满足时候,step失败,job失败
a、ItemProcessor处理中跳过
事务回滚,失败条目在缓存标志为跳过,并重新开启一个事务处理缓存中的条目,并提交。这个时候会重复process,
如果存在业务逻辑,注意幂等性问题
如果存在业务逻辑,注意幂等性问题
b、ItemWriter处理中跳过
事务回滚,失败条目在缓存标志为跳过,因为是批量提交,需要找出问题条目,所以针对每个条目开启一个事务循环处理process&write并提交,如果存在业务逻辑,注意幂等性问题
3、重试
<batch:chunk retry-limit="20">
<batch:retryable-exception-classes>
<batch:include class="com.xx.batch.ExceptionClass" />
</batch:retryable-exception-classes>
</batch:chunk>
或者
<batch:chunk retry-policy="defRetryPolicy">
</batch:chunk>
重试次数达到或者重试策略不满足时,step失败,job失败
4、reader-transactional-queue&processor-transactional
a、reader-transactional-queue,默认false,设置为true代表read资源具备事务特性,chunk事务回滚时,资源回滚。出现异常导致重复读取并处理,注意幂等性问题
b、processor-transactional,默认true,即writer失败时,processor重复执行,需要注意幂等性问题;设置false,即writer失败时,processor不再执行
处理组件事务
Spring Batch提供了很多监听器等组件,在处理事务相关的问题时,参考下图进行事务考虑:
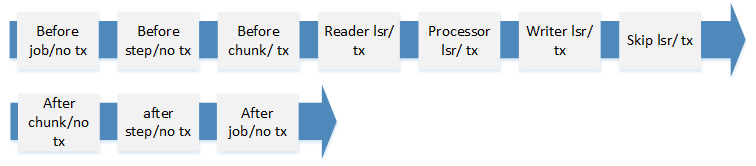
图-job执行阶段轨迹&事务
注意:ItemReadeListener、ItemProcessListener、ItemWriteListener所有监听方法均在chunk事务当中执行,所以,如果在这些监听方法里面要处理好业务事务与chunk事务的关系,最好将业务事务设置为独立REQUIRE_NEW特性,
避免相互影响
关于onXXError监听方法:改监听方法在事务回滚之前执行,或者事务提交之前执行(如果有no-rollback-exception配置)
一点点建议
在使用Spring Batch的时候需要注意它要解决的问题域,它本身的关注点应该是提供一个批量处理的能力,即对文件或数据库的批量读取、写入和协议数据的转换,以及对整个过程的控制。
因此,如果在批量处理过程中需要做些业务逻辑,那么业务逻辑的实现需要与它彼此独立,尽量不要在batch的处理过程中耦合业务逻辑,原因如下:
a、Spring Batch的使用目的更加清晰
b、避免Spring Batch事务与业务逻辑事务的交叉耦合所带来的偶发复杂性,应用已于理解
其次,Spring Batch的系统表最好和业务数据表处于同一物理库,保证事务的一致性
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/146269.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
