大家好,又见面了,我是你们的朋友全栈君。
Python期末考试知识点(史上最全)







python简介
Python是一种解释型语言
Python使用缩进对齐组织代码执行,所以没有缩进的代码,都会在载入时自动执行
数据类型:整形 int 无限大
浮点型 float 小数
复数 complex 由实数和虚数组成
Python中有6个标准的数据类型:
Number(数字)
String(字符串)
List(列表)
Tuple(元组)
Sets(集合)
Dictionart(字典)
其中不可变得数据:
Number(数字) String(字符串) Tuple(元组) Sets(集合)
可变得:
List(列表) Dictionart(字典)
我们可以用type或者isinstance来判断类型

type()不会认为子类是一种父类类型。
isinstance()会认为子类是一种父类类型
python中定义变量,不需要写变量类型,但是必须初始化。会根据我们写的数据类型,自动匹配
变量命名规则:由字母,数字,下划线组成,第一个必须字母或者下划线,对大小写敏感,不能是关键字
输入与输出
在我们需要输入中文的时候,需要包含头文件 # -*- coding: UTF-8 -*- 或者 #coding=utf-8
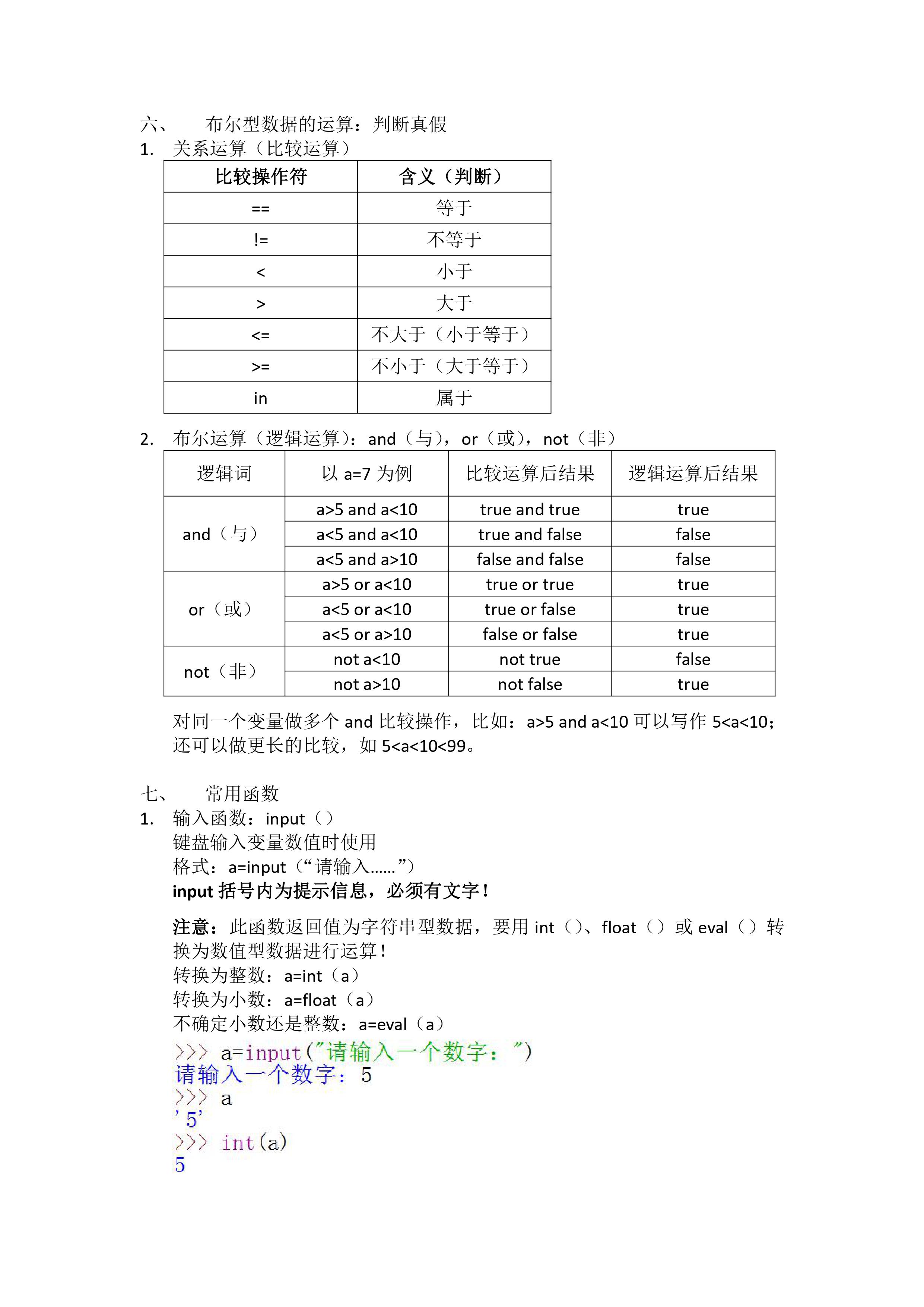
输入 a=input("请输入一个数字") 返回值为str类型
输出 print('hello world') 当然这里也可以严格按照格式控制符去输出变量值
例如:print("now a=%d,b=%d"%(a,b)) 双引号后面没有逗号
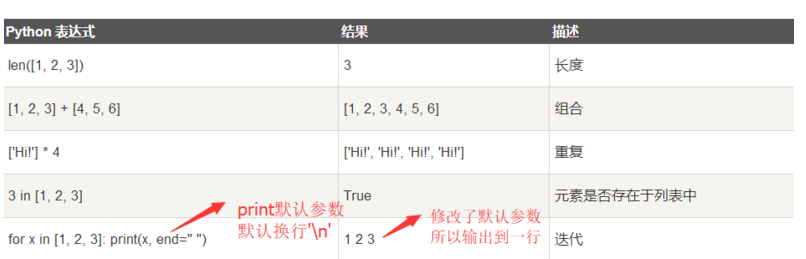
print默认换行,我们可以print( end=''),修改默认参数让他不换行,
也可以在print()后面加逗号 print(xxx) , 这样也可以不换行 测试发现:只适合在2.7版本
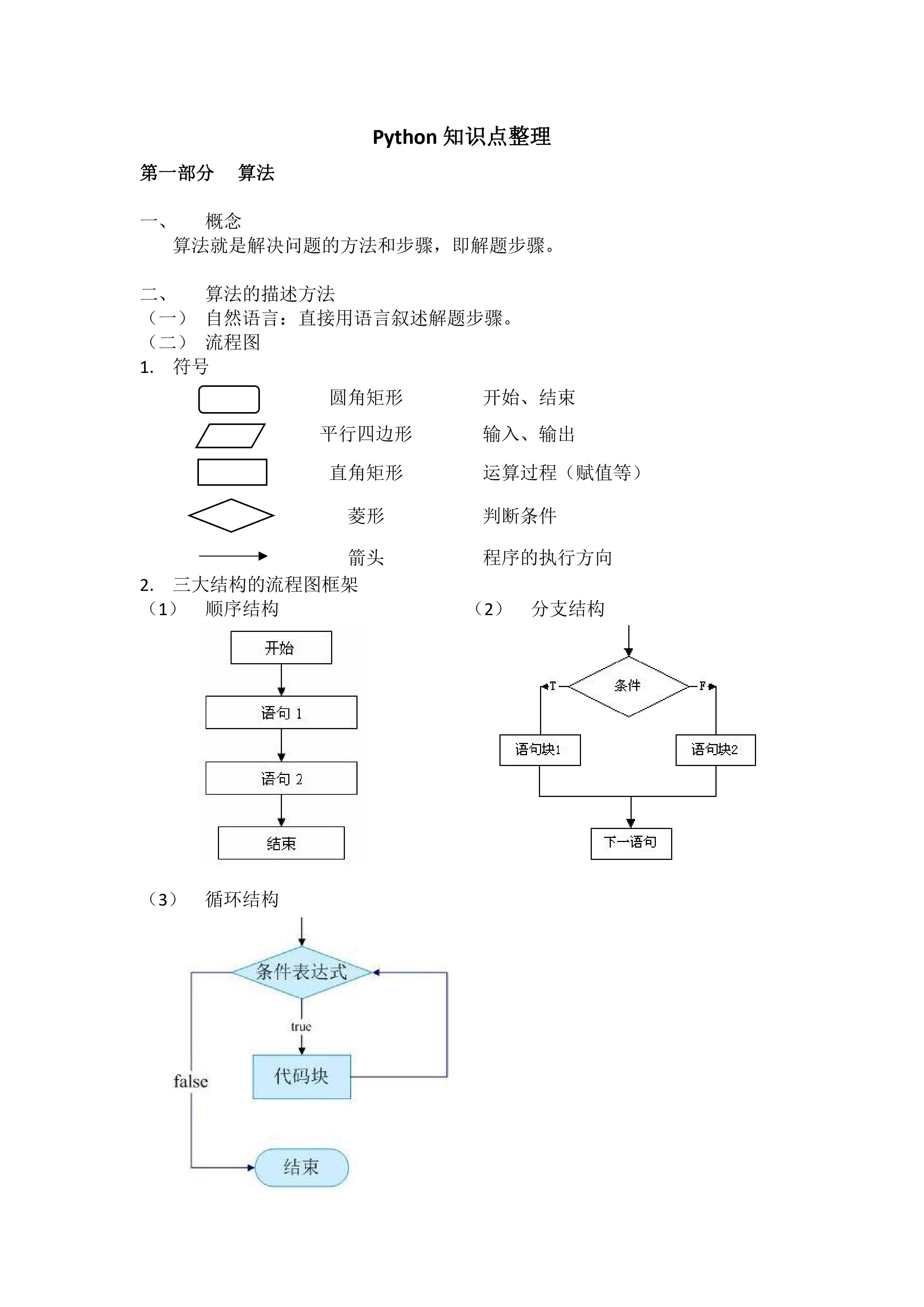
- 基础语法
运算符:
算术运算符: 多了一个**,代表 幂方 5**5 就是5的5次方 还多了一个 // 整数除法
逻辑运算符: and,or,not 与,或,非
赋值运算符: 没有++,–
身份运算符: is is not
成员关系运算符: in not in
总结:多出来了** 和 // //就是整除的意思 比如 5//3结果为 1 但是5/3结果为小数 1.6666666667
运算符优先级(下面由高到低):幂运算符最高
幂运算符 **
正负号 + -
算术运算符 *,/,//,+,-
比较运算符 <,<=,>,>=,==,!=
逻辑运算符 not,and,or (not>and>or)
选择结构
if-else
if-elif-else(这里可以不写else)
逻辑结果
python里面只要是"空”的东西都是false ""(中间有空格就为真,这里什么都不写,为假) 空元组,空列表,空字典 0 都为false
字符串
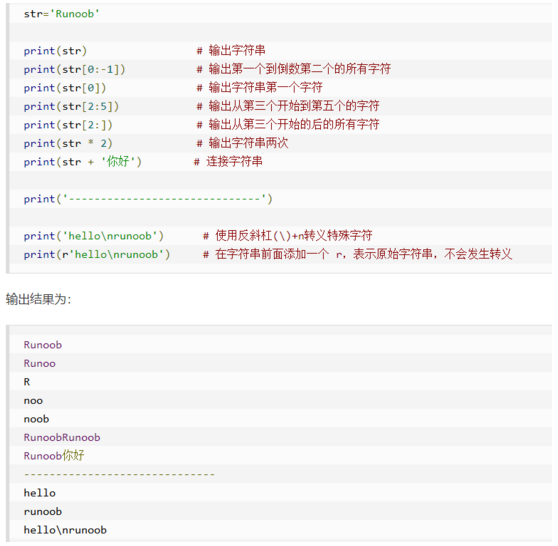
Pis:在字符串前面添加一个 r,表示原始字符串,不会发生转义
列表
list是处理一组有序项目的数据结构,用方括号定义
列表的操作:
一,通过下标去访问列表中的值 (可以用切片的方式去访问)
输出结果:这里就用了切片的方式去访问1到5
重点:这里切片的使用方法要注意,我们写的1:5实际访问的是下标为1,2,3,4.没有5!
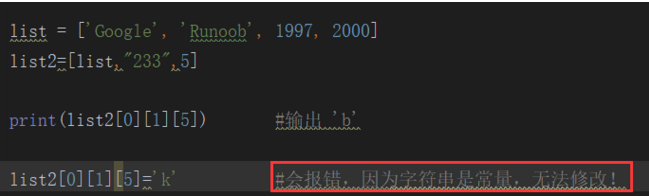
二,更新列表(列表是可以修改的)
通过下标去直接修改他的值
三,删除列表元素(del + 列表项) 删除项remove()后面说
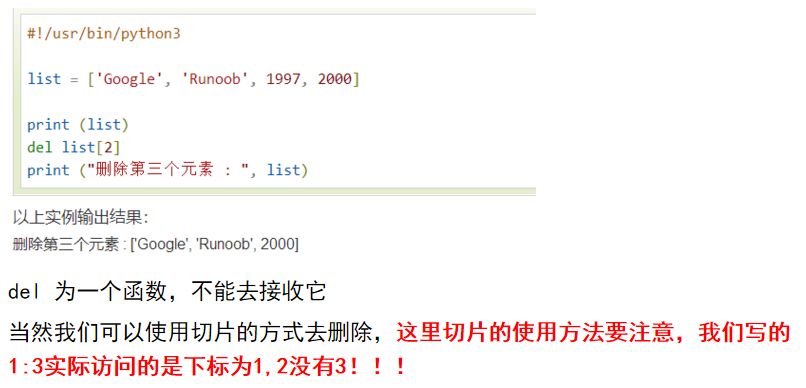
四,列表的脚本操作符
五,对于列表截取,拼接

六,list自带函数 (其中有元组转列表)
方法 功能
max(list) 返回列表元素最大值
min(list) 返回列表元素最小值
list(seq) 元组转列表
list.append(obj) 在列表末尾添加新对象
list.count(obj) 统计某个元素在列表出现的次数
list.extend(seq) 在末尾添加新列表,扩展列表
list.index(obj) 在列表中找出某个值第一个匹配性的索引位置
list.insert(index,obj) 将对象插入列表,其中的index,为插入的位置,原来该位置后面的元素包含该位置元素,都统一后移
list.pop(obj=list[-1])
有默认参数,即最后一项 删除指定位置元素并返回,他和del的区别在于del是一个关键字。而pop是内建函数,我们无法用变量去接收del删除的项 (参数可以不写,默认删除最后一项)
list.remove(obj) 移出列表中某个值第一次匹配的项
list.reverse() 反向列表中的元素(收尾互换),不代表倒序排列!
list.sort() 对列表进行排序
list.copy() 复制列表
list.clear() 清空列表
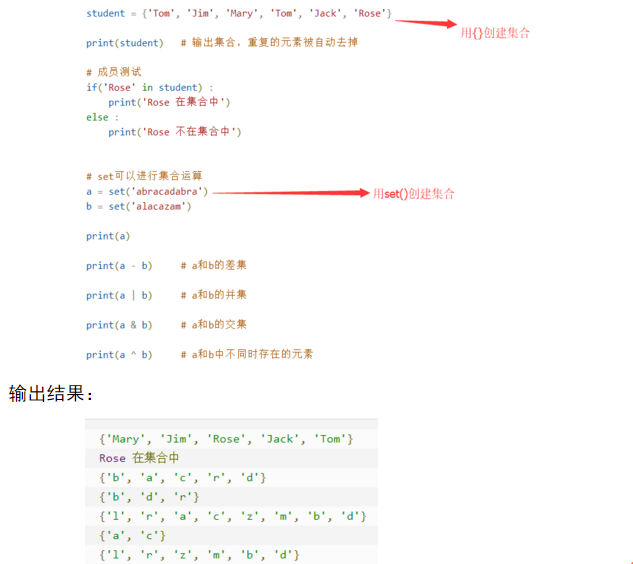
Set集合
集合是一个无序不重复元素的序列
基本功能就是进行成员关系测试,和删除重复元素 (所谓成员关系测试就是查看他们是否重复,两个集合的交集…)
可以使用 { } 或者set()函数来创建集合 但是创建一个空集合必须适用set()
编程语言的进化:机器语言、汇编语言、高级语言
机器语言:由于计算机内部只能接受二进制代码,因此,用二进制代码0或1描述的指令称为机器指令,全部机器指令的集合构成计算机的机器语言。
汇编语言:实质和机器语言是相同的,都是直接对硬件操作,只不过指令采用英文缩写的标识符,更容易识别和记忆。
高级语言:高级语言对开发人员更加友好,开发效率大大提高
高级语言所编制的程序不能直接被计算机识别,必须经过转换才能被执行。
高级语言按转换方式可分为:编译型、解释型
编译型:指在应用源程序执行之前,将程序源代码转换成目标代码,因此其目标代码可以脱离其语言环境独立执行。
编译后程序运行时不需要重新翻译,直接使用翻译的结果就行。程序执行效率高,依懒性编译器,跨平台性差。如C、C++、GO、Delphi等
解释型:应用程序源代码一边由相应语言的解释器翻译成目标代码,一边执行,因此效率比较低,不能生成可独立执行的可执行文件,应用程序不能脱离其解释器。如Python、Java、PHP、Ruby等。跨平台性好、开发效率不高。
编译型语言执行速度快,不依赖语言环境运行,跨平台差
解释型跨平台好,一份代码,到处运行。缺点是执行速度慢,依赖解释器运行。
Python创始人:Guido van Rossum(龟叔)
Python诞生在1989年
2008年12月出现Python3.0
2010年出现一个过渡版本Python2.7(最多只支持到2020年,之后不支持2.0版本)
Python解释器是用C语言写的
Python解释器种类有:CPython、IPython、PyPy、Jython、IronPython
测试安装是否成功:
windows–>运行–>输入cmd,回车,弹出cmd程序,输入Python,如果进入交互环境,代表安装成功。
print(‘hello world!’)
保存为helloworld.py,注意.py后缀名的作用:命名约束规范,方便程序员识别代码。
进入cmd命令行,执行Python helloworld.py,看结果。
注意文件名前面加python的原因是要把代码交给python解释器去解释执行
内存和磁盘的关系:内存存取速度快,断电就丢失;磁盘存取速度慢,永久保存。
Python交互器是主要用来对代码进行调试用的
变量:先定义后使用
变量作用:存数据,占内存,存储程序运行的中间结果,可以被后面的代码调用。
声明变量:变量名=变量的值
变量的命名规则:
1.变量名只能是数字、字母或下划线的任意组合
2.变量名的第一个字符不能是数字
3.以下关键字不能声明为变量名[‘and’,‘as’,‘assert’,‘break’,‘class’,‘continue’,‘def’,‘elif’,‘else’,‘except’,‘exec’,‘finally’,‘for’,‘from’,‘global’,‘if’,‘import’,‘in’,‘is’,‘lambda’,‘not’,‘or’,‘pass’,‘print’,‘raise’,‘return’,‘try’,‘while’,‘with’,‘yield’]
常量:程序在执行过程中不能改变的量
在Python中没有一个专门的语法代表常量,程序员约定俗成的变量名全部大写代表常量。
读取用户输入
name = input(“what’s your name:”)print(“hello”+name)
输入用户姓名和密码
username= input(“username:”)
password= input(“password:”)print(username,password)
注释:解释说明,帮助阅读代码。
单行注释:#
多行注释:’’’…’’’
数据类型
数据类型-数字类型
int(整型):32位机器上:-231 —— 231-1 64位同样的道理
long(长整型):Python的长整型没有指定位宽。(Python3里不再有long类型)
float(浮点型):
数据类型-字符串类型
字符串:在Python中,加了引号的字符都被认为是字符串!
注意:单双引号是没有任何区别的;多行字符串必须用多引号。
布尔类型:
只有两个值True、False ,主要用来做逻辑判断
格式化输出:(%s 以一个字符替换 %d以一个整数替换 %f以一个浮点数替换)都是一个占位符 %是一个连接符
运算符
算术运算符(+,-,*,/,%,**,//),
比较运算符(==,!=,<>,>,<,>=,<=),
逻辑运算符(and,or,not),
赋值运算符(=,+=,*=,/=,%=,**=,//=),
成员运算符(in,not in),
身份运算符(is , is not),
位运算(>>,<<)
流程控制
单分支:
if 条件:
满足条件后要执行的代码块
多分支:
if 条件:
满足条件后要执行的代码块
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
else:
上面的条件不满足就走这个
while循环
while 条件:
执行代码…
Dead Loop
count=0
while True:
print(“你个基佬!!!”,count)
count+=1
循环终止语句:break语句或continue语句
break语句:用于完全结束一个循环,跳出循环体执行后面的语句
continue语句:只终止本次循环,接着执行后面的循环
while…else用法
当while循环正常执行完,中间没有被break终止的话,就会执行else后面的语句。
二进制运算、字符编码、数据类型
二进制(0,1)、八进制(0-7)、十进制(0-9)、十六(0-9,A-F)进制的转换
四位二进制表示一位十六进制
oct() 八进制 hex()十六进制
char(num)将ASCII值得数字转换成ASCII字符,范围只能是0-255
ord(char)接受一个ASCII值字符,返回相应的ASCII值
每一位0或1所占的空间单位为bit(比特),这是计算机中最小的表示单位
8bits = 1Bytes字节,最小的存储单位,1bytes缩写为1B
1024Bytes = 1KB = 1KB
1024KB = 1MB
1024MB =1GB
1024GB = 1TB
1024TB = 1PB
ASCII 256,每一个字符占8位
Unicode编码(统一码、万国码):规定了所有的字符和符号最少由16位表示
UTF-8:ascii码中的内容用1个字节保存,欧洲的字符用2个字节保存,东亚的字符用3个字节保存…
winsows系统中文版默认编码是GBK
Mac OS\Linux系统默认编码是UTF-8
UTF是为unicode编码 设计的一种在存储和传输时节省空间的编码方案。
无论以什么编码在内存里显示字符,存到硬盘上都是二进制。不同编码的二进制是不一样的
存到硬盘上以何种编码存的,那么读的时候还得以同样的编码读,否则就乱码了。
python2.x默认编码是ASCII;默认不支持中文,支持中文需要加:#* coding:utf-8 * 或者 #!encoding:utf-8
Python3.x默认编码是UTF-8,默认支持中文
Python数据类型
字符串 str
数字:整型(int)长整型(long) 浮点型(float) 布尔(bool) 复数(complex)
列表 list
元组 tuple
字典 dictionary
集合:可变集合(set) 不可变集合(frozenset)
不可变类型:数字,字符串,元组
可变类型:列表,字典,集合
899590-20180512120213031-26929447.png
字符串
特点:有序、不可变
字符串的常用方法:isdigit,replace,find,count,index,strip,split,format,join,center
ContractedBlock.gif
ExpandedBlockStart.gif
1 s = “abcd”
2 print(s.swapcase()) #都变成大写字母
3
4 print(s.capitalize()) #都变成首字母大写
5
6 print(s.center(50,”“)) #打印变量s的字符串 指定长度为50,字符串长度不够的用号补齐
7
8 print(s.count(“a”,0,5)) #统计字符串a在变量里有几个;0,5代表统计范围是下标从0-5的范围
9
10 print(s.endswith(“!”)) #是否是以什么结尾的。
11
12 print(s.startswith(“a”)) #判断以什么开始
13
14
15 s = “a b”
16 print(s.expandtabs(20)) #相当于在a和b中间的tab长度变成了20个字符,交互模式可看出效果
17
18 s.find(“a”,0,5) #查找字符串,并返回索引
19
20 s.format() #字符串格式化
21 s1 = “my name is {0},i am {1} years old”
22 print(s1)23 print(s1.format(“aaa”,22)) #分别把{0}替换成aaa {1}替换成22
24 #也可以写成如下
25 s1 = “my name is {name},i am {age} years old”
26 s1.format(name=“aaa”,age = 22) #字典形式赋值
27
28 #s.format_map() #后续补充
29
30
31 print(s.index(“a”)) #返回索引值
32
33 print(s.isalnum()) #查看是否是一个阿拉伯字符 包含数字和字母
34
35 print(s.isalpha()) #查看是否是一个阿拉伯数字 不包含字母
36
37 print(s.isdecimal()) #判断是否是一个整数
38
39 print(s.isdigit()) #判断是否是一个整数
40
41 print(s.isidentifier()) #判断字符串是否是一个可用的合法的变量名
42
43 print(s.islower()) #判断是否是小写字母
44
45 print(s.isnumeric()) #判断只有数字在里边
46
47 print(s.isprintable()) #判断是否可以被打印,linux的驱动不能被打印
48
49 print(s.isspace()) #判断是否是一个空格
50
51 print(s.istitle()) #判断是否是一个标题 每个字符串的首字母大写 Hello Worlld
52
53 print(s.isupper()) #判断是否都是大写
54
55 #s.join()
56 name = [“a”,“b”,“1”,“2”]57 name2 = “”.join(name) #列表转成字符串,把列表里边的元素都join到字符串中
58 print(name2) #得出ab12
59
60 #s.ljust
61 s = “Hello World”
62 print(s.ljust(50,”-“)) #给字符串从左往右设置长度为50,字符串长度不够用 – 补充
63
64 print(s.lower()) #字符串都变成小写
65
66 print(s.upper()) #变大写
67
68 print(s.strip()) #脱掉括号里边的,可以是空格 换行 tab …
69
70 s.lstrip() #只脱掉左边的空格
71 s.rstrip() #只拖点右边的空格
72
73 #s.maketrans() #
74 str_in = “abcdef” #必须是一一对应
75 str_out = “!@#$%^” #必须是一一对应
76 tt = str.maketrans(str_in,str_out) #生成对应表,就像密码表一样
77 print(tt)78 #结果:{97: 33, 98: 64, 99: 35, 100: 36, 101: 37, 102: 94}
79
80 print(s.translate(tt)) #s.translate方法调用 加密方法tt 给 s的字符串加密
81 #结果:H%llo Worl$
82
83 #s.partition()
84 s = “Hello World”
85 print(s.partition(“o”)) #把字符串用 从左到右第一个o把 字符串分成两半
86 #结果:(‘Hell’, ‘o’, ’ World’)
87
88 s.replace(“原字符”,“新字符”,2) #字符串替换,也可以写换几次 默认全换,可以设置count次数
89
90 s.rfind(“o”) #查找最右边的字符,也有开始和结束
91
92 print(s.rindex(“o”) ) #查找最右边的字符的索引值
93
94 s.rpartition(“o”) #从最右边的字符开始 把字符串分成两半
95
96 s.split() #已括号里边的把字符串分成列表,括号里可以是空格、等字符来分成列表
97
98 s.rsplit() #从最右边以 某字符 来分开字符串
99
100 s.splitlines() #设置以换行的形式 把字符串分成列表
101
102 print(s.swapcase()) #字母换成相反的大小写,大的变成小,小的变成大
103 #结果“:hELLO wORLD
104 #原来的“hello World”
105
106 s.title() #把字符串变成title格式 Hello World
107
108 s.zfill(40) #把字符串变成40,字符串不够,从左往右用0 补齐
109
110
111 #“a\tb” 字符串中间的\t 被认为是tab 是4个或者8个空格
112 #整体意思是:a 有一个tab 然后 又有一个b
View Code
列表
列表的常用方法:创建、查询、切片、增加、修改、删除、循环、排序、反转、拼接、clear、copy
列表的特点:可以重复;列表是有序的
ContractedBlock.gif
ExpandedBlockStart.gif
1 1、创建2 方法一:list1 = [“a”, “b”] #常用
3 方法二:list2 = list () #一般不用这种方法
4
5 2、查询6 列表的索引 (也称下标):7 列表从左到右下标是从0开始0、1、2、3…8 列表从右到左下标是从 – 1开始 -1 -2 -3…9
10 查询索引值:11 list1.index (a) #index查询找到第一个a程序就不走了,
12 list1[0] #通过a的索引 得出a
13 list1[-1] #通过b的下标 得出b
14
15 当list1 = [1, 2, 3, 4, 4, 4, 4, 4, 4]16 列表里出现元素相同时,统计相同次数17 list1.count (4) #统计得出:6 代表列表有6个4
18
19 3、切片20 切片:通过索引 (或下标)21 截取列表中一段数据出来。22 list1 = [1, 2, 3, 4, 4, 4, 4, 4, 4]23 list1[0:2] #得出 [1,2] ,列表切片顾头不顾尾,也可成list1[:2]
24 list1[-5:] #得出[4,4,4,4,4],取最后5个元素,只能从左往右取
25 按步长取元素:26 list1 = [1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5]27 list1[:6:2] #得出:[1, 3, 5] :2 代表步长 ,每隔两步取一个元素
28 list1[::2] #得出:[1, 3, 5, 1, 3, 5] 在列表所有元素中,每隔2步取一个数
29
30 4、增加31 list1 = [“a”, “b”, “c”]32 list1.append (“d”) #追加d到列表list1的最后 结果:[‘a’, ‘b’, ‘c’, ‘d’]
33 list1.insert (1, “aa”) #插入aa到列表下标为1的之前 得出结果:[‘a’, ‘aa’, ‘b’, ‘c’, ‘d’]
34
35 5、修改36 list1[1] = “bb” #直接给对应位置赋值,即是修改 结果:[‘a’, ‘bb’, ‘b’, ‘c’, ‘d’]
37 批量修改38 把[‘a’, ‘bb’, ‘b’, ‘c’, ‘d’]里的前两个元素替换掉39 list1[0:2] = “boy” #结果:[‘b’, ‘o’, ‘y’, ‘b’, ‘c’, ‘d’]
40
41 6、删除42 list1 = [‘b’, ‘o’, ‘y’, ‘b’, ‘c’, ‘d’]43 list1.pop () #默认删除最后一个元素 d
44 list1.remove (“o”) #删除元素O remove只能一个一个删除
45 list1.remove (0) #删除下标为0的元素 b
46 del list1[0] #删除下标为0的元素 del是一个全局删的方法
47 del list1[0:2] #del可以批量删除
48
49 7、for循环列表50 list1 = [1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5]51 for i in list1: #使用for循环循环列表list1里边的元素
52 range (10) #生成0到10 的数字
53
54 8、排序55 list1 = [“1”, “5”, “3”, “a”, “b”, “f”, “c”, “d”, “A”, “C”, “B”]56 list1.sort () #结果:[‘1’, ‘3’, ‘5’, ‘A’, ‘B’, ‘C’, ‘a’, ‘b’, ‘c’, ‘d’, ‘f’]
57
58 排序是按照ASCII码对应排序。59 反转60 list1.reverse () #结果:[‘f’, ‘d’, ‘c’, ‘b’, ‘a’, ‘C’, ‘B’, ‘A’, ‘5’, ‘3’, ‘1’]
61
62 9、两个列表拼一块63 #方法一
64 list1 = [1, 2, 3, 4, 5]65 list2 = [6, 7, 8, 9]66 list1 + list2 #结果:[1, 2, 3, 4, 5, 6, 7, 8, 9]
67 #方法二
68 list1.extend (list2) #把列表2扩展到list1中
69 结果:[1, 2, 3, 4, 5, 6, 7, 8, 9]70
71 10、clear72 #清空列表
73 list2.clear () #清空list2
74
75 11、copy76 浅copy77 复制列表78 list2 =list1.copy ()79 当列表只有一层数据,没有列表嵌套列表的情况下,复制后的列表和原来的列表是完全独立的。80 当列表有多层嵌套的时候,列表嵌套里边的列表的内容是和原有列表是共享的。81 list1.copy () #所以这个叫做:浅copy
82
83 深copy:需要借助python模块84 importcopy85 list2 =copy.deepcopy (list1)86 深copy后,新的列表和旧的列表,不管有没有列表嵌套列表,都是完全独立的个体。87 可以通过查看列表名对应的内存地址分辨两个列表是否独立88 查看python解释器里边的内存地址:id (变量名)
View Code
元组
特点:有序的,不可变的列表
常用功能:index,count,切片
使用场景:显示的告知别人,此处数据不可修改;数据库连接配置信息等
hash函数
hash,一般翻译为“散列”,也有直接翻译为“哈希”的,就是把任意长度的输入,通过散列算法,变成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不通的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值,简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
特征:hash值的计算过程是依据这个值的一些特征计算的,这就要求被hash的值必须固定,因此被hash的值必须是不可变的。(不能保证输出的数据唯一的,容易造成冲突)
用途:文件签名;md5加密;密码验证
ContractedBlock.gif
ExpandedBlockStart.gif
1 >>> hash(“abc”)2 -6784760005049606976
3 >>> hash((1,2,3))4 2528502973977326415
View Code
字典
语法:info={}
特点:1.key-value结构,key必须是可hash、必须是不可变数据类型、必须唯一
2.每一个key必须对应一个value值,value可以存放任意多个值,可修改,可以不唯一
3.字典是无序的
字典的查找速度快是因为字典可以把每个key通过hash变成一个数字(数字是按照ASCII码表进行排序的)
字典的方法:增删改查 多级嵌套 等
ContractedBlock.gif
ExpandedBlockStart.gif
1 #字典方法
2 info ={3 “student01”:“aaa”,4 “student02”:“bbb”,5 “student03”:“ccc”
6 }7
8 #增加
9 info[“student04”] = “ddd”
10 info[“student05”] = “eee”
11 info[“student06”] = “fff”
12
13 #查询
14 #判断student01在不在info字典里
15 print(“student01” in info ) #返回True
16 print(info.get(“student01”)) #返回aaa,没有返回None
17 info[“student01”] #获取对应的value ,如果没有这个key 就报错,所以一般用get
18
19 #删除
20 print(info.pop(“student01”)) #删除key
21 print(info.popitem()) #随机删除一个key
22 del info[“student02”] #删除的key ,如果没有删除的key 就报错 KeyError: ‘student01’
23
24 info.clear() #清空字典
25
26 #多级字典嵌套
27 dic1 = {“aaa”: {“aa”: 11}, “bbb”: {“bb”: 22}}28
29 #其他方法
30 info ={31 “name1”: [22, “it”],32 “name2”: [24, “hr”],33 “name3”: 33
34 }35
36 info2 ={37 “name1”: 44,38 “name4”: 33,39 1: 2
40 }41 info.keys() #打印所有的key
42 info.values() #打印所有的value
43 info.items() #把字典转成一个列表
44 info.update(info2) #把两个字典合成一个,如果有重复的key ,info2里边的重复key会覆盖info里边的key
45 info.setdefault(“student07”,“abcdef”) #设置一个默认的key:value ,
46 #如果info字典里没有key student07 ,那么info字典里有添加 student07:abcdef
47 #如果info字典里已经手动添加了student07的key value,那么这里的student07:abcdef 就不起作用
48 print(info.fromkeys([“name1”,“name2”],“aaa”) ) #从一个可迭代的对象中批量生成key和相同的value
49
50 #字典的循环:高效循环
51 for k ininfo:52 print(k,info[k]) #打印key value
53
54 #另外一种方法 低效
55 for k,v in info.items(): #先把字典转成列表,在循环,所以低效
56 print(k,v)
View Code
集合
集合是一个无序的、不重复的数据组合
作用:1.去重
2.关系测试,测试两组数据之间的交集、差集、并集等关系
语法:
s = {} #如果为空,就是字典
s = {1,2,3,4} #就成了集合 set
s = {1,2,3,4,1,2} #有重复数据,显示结果就直接去重{1, 2, 3, 4}
列表转成给一个字典
l = [1,2,3,4,1,2]
l2 = set(l)
集合的方法
ContractedBlock.gif
ExpandedBlockStart.gif
1 #集合方法
2 s = {1,2,3,4,5} #定义一个集合
3
4 #增加
5 s.add(6)6 print(s) #{1, 2, 3, 4, 5, 6}
7
8 #删除
9 #随机删除
10 s.pop()11 print(s) #{2, 3, 4, 5, 6}
12 #指定删除,如果不存在,就报错
13 s.remove(6)14 print(s) #{2, 3, 4, 5}
15 #指定删除,如果不存在,不报错
16 s.discard(6)17 print(s)18
19 #联合其他集合,可以添加多个值
20 s.update([7,8,9])21 print(s) #{2, 3, 4, 5, 7, 8, 9}
22
23 #清空集合
24 s.clear()25
26
27 #集合的关系测试
28 iphone7 = {“alex”,“rain”,“jack”,“old_driver”}29 iphone8 = {“alex”,“shanshan”,“jack”,“old_boy”}30
31 #交集
32 print(iphone7.intersection(iphone8))33 print(iphone7 &iphone8)34 #输出:
35 {‘jack’, ‘alex’}36 {‘jack’, ‘alex’}37
38 #差集
39 print(iphone7.difference(iphone8))40 print(iphone7 -iphone8)41 #输出:
42 {‘rain’, ‘old_driver’}43 {‘rain’, ‘old_driver’}44
45 #并集 把两个列表加起来
46 print(iphone7.union(iphone8))47 print(iphone7 |iphone8)48 #输出:
49 {‘rain’, ‘jack’, ‘old_driver’, ‘alex’, ‘shanshan’, ‘old_boy’}50 {‘rain’, ‘jack’, ‘old_driver’, ‘alex’, ‘shanshan’, ‘old_boy’}51
52 #对称差集 把不交集的取出来
53 print(iphone7.symmetric_difference(iphone8))54 #输出:
55 {‘rain’, ‘old_driver’, ‘shanshan’, ‘old_boy’}56
57 s = {1,2,3,4}58 s2 = {1,2,3,4,5,6,}59 #超集 谁是谁的父集
60 print(s2.issuperset(s)) #s2是s的父集
61 print(s2 >=s)62 #输出:
63 True64 True65
66 #子集
67 print(s.issubset(s2)) #s是s2的子集
68 print(s <=s2)69 #输出:
70 True71 True72
73 #判断两个集合是否不相交
74 print(s.isdisjoint(s2))75 #输出:
76 False #代表两个集合是相交的
77
78 s = {1,2,3,-1,-2}79 s2 = {1,2,3,4,5,6}80 s.difference_update(s2) #求出s和s2 的差集,并把差集 覆盖给 s
81 print(s) #结果:{-2, -1}
82
83 s.intersection_update(s2) #求出s和s2的交集,并把交集 覆盖给 s
84 print(s)85 print(s2)86 #结果:
87 {1, 2, 3}88 {1, 2, 3, 4, 5, 6}
View Code
字符编码
python3
文件编码默认 :utf-8
字符串编码:unicode
python2
文件编码默认:ascii
字符串编码默认:ascii
如果文件头声明了utf-8,那字符串的编码是utf-8
unicode是一个单独的类型
python3的内存里:全部是unicode
python3执行代码的过程:
1、解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
2、把代码字符串按照python语法规则进行解释
3、所有的变量字符都会以unicode编码声明
在python2里边,默认编码是ASCII编码,那么文件头声明是utf-8的代码,在windows中将显示乱码
如何在windows上显示正常呢?(windows的默认编码是gbk)
1、字符串以gbk格式显示
2、字符串以unicode编码
修改方法:
1.UTF-8 – >decode解码 –> Unicode
2.Unicode – > encode编码 – > GBK / UTF-8
ContractedBlock.gif
ExpandedBlockStart.gif
1 s=“路飞学城”
2 print(“decode before:”,s)3 s2=s.decode(“utf-8”)4 print(“decode after:”,s2)5 print(type(s2))6 s3=s2.encoded(“gbk”)7 print(s3)8 print(type(s3))
View Code
python中bytes类型
二进制的组合转换成16进制来表示就称之为bytes类型,即字节类型,它把8个二进制组成一个bytes,用16进制来表示。
在python2里,bytes类型和字符串是本质上时没有区分的。
str = bytes
python2 以utf-8编码的字符串,在windows上不能显示,乱码。
如何在python2下实现一种,写一个软件,在全球各国电脑上 可以直接看?
以unicode编码写软件。
s = you_str.decode(“utf-8”)
s2= u”路飞”
unicode类型 也算字符串
文件头:
python2:以utf-8 or gbk 编码的代码,代码内容加载到内存,并不会被转成unicode,编码依然是utf-8 或 gbk。
python3:以utf-8 or gbk编码的代码,代码内容加到在内存,会被自动转成unicode。
在python3里,bytes类型主要来存储图片、视频等二进制格式的数据
str = unicode
默认就支持了全球的语言编码
常见编码错误的原因有:
1、python解释器的默认编码
2、python源文件文件编码
3、终端使用的编码(windows/linux/os)
4、操作系统的语言设置
一、模块、包
1、什么是模块?
1、把相同功的函数放在一个py文件里,称为模块。
2、一个PY文件就称为一个模块。
3、模块有什么好处:
1、容易维护。
2、减少变量和函数名冲突。
4、模块种类:
1、第三方模块——别人写的模块
2、内置模块——编译器自带模块(如:os、sys、等)
3、自定义模块——自己编写的模块
5、模块怎么导入:
通过import命令导入,eg:import os(模块名)
2、什么是包?
1、把多个模块放在同一个文件夹内,这个文件夹称为包。
2、文件夹称为包还有一个条件——文件夹里要有__init__.py模块。
3、模块与包有什么区别
1、模块——一个py文件就称一个模块
2、包——一个包含有__init__.py的文件夹称为一个包;一个包里可以有多个py模块。
json、pickle
1、什么是序列化?
1、把内存数据转换成字符串。
1、把内存数据保存到硬盘。
2、把内存数据传输给他人(由于网络传输是通过二进制传输,所以需要进行转换)。
2、序列化的模块有两个,json和pickle
2、json、pickle有什么优点和缺点?
1、json——把json所支持的数据转换成字符串
优点:体积小、跨平台。
缺点:只支持int、str、list、dict、tuple等类型。
2、pickle——把python所支持的所有类型转换成字符串
优点:支持python 全部数据类型
缺点:只能在python平台使用,占用空间大。
3、json和pickle有4个方法
load 、loads 、dump 、dumps
load:通过open函数的read文件方法,把内存数据转成字符串
loads:把内存数据转成字符串
dump:通过open函数的write文件方法,把字符串转换成相应的数据类型。
dumps:把字符串数据转成相应的数据类型。
shelve
1、什么是shelve?
1、shelve是一种key,value 形式的文件序列化模块;序列化后的数据是列表形式。
2、底层封装了pickle模块,支持pickle模块所支持的数据类型。
3、可以进行多次反序列化操作。
hashlib
1、什么是hashlib?
hashlib 模块——也称‘哈希’模块。
通过哈希算法,可以将一组不定长度的数据,生成一组固定长度的数据散列。
特点:
1、固定性——输入一串不定长度的数据,生成固定长度的数字散列。
2、唯一性——不同的输入所得出的数据不一样。
2、md5
输入一串不定长度的数据,生成128位固定长度的数据。
特点:
1、数字指纹——输入一串不定长度的数据,生成128位固定长度的数据(数字指纹)。
2、运算简单——通过简单的运算就可以得出。
3、放篡改——改动很少,得出的值都会不一样。
4、强碰撞——已知MD5值,想找到相同的MD5值很难。
函数
1、什么是函数?
把代码的集合通过函数名进行封装,调用时只需要调用其函数名即可。
有什么好处:
1、可扩展
2、减少重复代码
3、容易维护
2、函数的参数?
函数可以带参数:
形参:
1、在函数定义是指定。
2、函数调用时分配内存空间,函数运行结束,释放内存空间。
实参:
1、形式可以是常量、变量、表达式、函数等形式。
2、无论是何种形式,都必须要有明确的值,以便把数据传递给形参。
默认参数:
1、函数定义时可以指定默认参数(eg: def func(a,b=1))
2、传参时指定了默认参数,就使用传参时的值,没有指定,则使用默认参数的值。
关键参数:
1、函数传参时需按顺序传参,如果不按顺序传参可以使用关键参数传参。
非固定参数:
1、当不确定参数的数量时可以使用非固定参数。
2、非固定参数有两种:1.*args——(传入的参数以元组表示)。2.**kwargs——(传入的阐述用字典表示)
3、函数的返回值
1、函数可以把运算的结果返回。
2、函数可以有返回值,也可以没有返回值。
有返回值——通过return返回。
没有返回值——返回值为None
3、函数遇到return,代表函数运行结束。
4、函数的种类
嵌套函数——一个函数包含了另一个函数。
高阶函数——一个函数的参数引用了另一个函数,一个函数的返回值是另一个函数。
匿名函数——不用显式指定函数名的函数(lambrda),常和map和filter配合使用。
递归函数
1、函数内部引用了函数自身
2、函数里有一个明确的结束条件。
递归函数的特性:
1、有一个明确的结束条件
2、每次递归的规模都应有所减少
3、递归函数的效率不高。
作用域
1、名称空间
名称空间就是存放变量名和变量值(eg:x=1)绑定关系的地方。
1、名称空间种类:
local:函数内部,包括形参和局部变量。
global:函数所在模块的名字空间。
buildin:内置函数的名字空间。
2、变量名的作用域范围的不同,是由这个变量名所在的名称空间所决定的。
全局范围:全局存活,全局有效。
局部范围:局部存活,局部有效。
2、作用域查找顺序
作用域查找顺序:
local——》enclosing function——》global——》builtin
local:函数内部,包括形参、局部参数。
enclosing function:内嵌函数。
global:函数所在模块。
builtin:内置函数。
闭包
1、什么是闭包
1、一个嵌套函数,分别有内函数,外函数。
2、内函数使用了外函数的变量。
3、外函数返回了内函数的应用地址。
4、那么这个嵌套函数就称为闭包。
2、闭包有什么意义
1、闭包返回的对象不仅仅是一个对象,而且还返回了这个函数的外层包裹的作用域。
2、无论这个函数在何处被调用,都优先使用其外层作用域。
装饰器
1、什么是装饰器
1、装饰器本质上就是一个闭包函数。
2、装饰器的作用是,在不改变原有函数的调用方式下,增加代码的功能。
不喜勿喷,喜欢的点个赞呗!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/146257.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
