大家好,又见面了,我是你们的朋友全栈君。
自动编码器简介
自动编码器(一下简称AE)属于生成模型的一种,目前主流的生成模型有AE及其变种和生成对抗网络(GANs)及其变种。随着深度学习的出现,AE可以通过网络层堆叠形成深度自动编码器来实现数据降维。通过编码过程减少隐藏层中的单元数量,可以以分层的方式实现降维,在更深的隐藏层中获得更高级的特征,从而在解码过程中更好的重建数据。
自动编码器原理
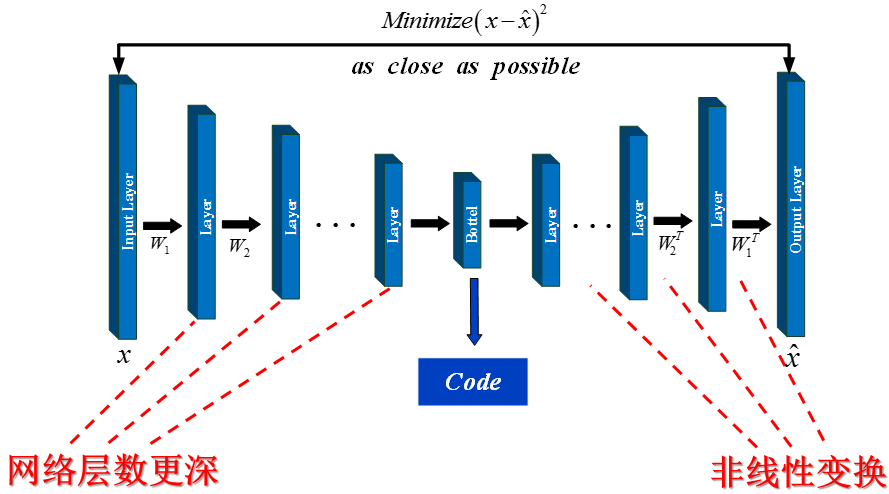
自动编码器是通过无监督学习训练的神经网络,实际上是一个将数据的高维特征进行压缩降维编码,再经过相反的解码过程还原原始数据的一种学习方法。学习过程中通过解码得到的最终结果与原数据进行比较,通过修正权重偏置参数降低损失函数,不断提高对原数据的复原能力。自动编码器学习的前半段的编码过程得到的结果即可代表原数据的低维“特征值”。通过学习得到的自编码器模型可以实现将高维数据压缩至所期望的维度,原理与PCA相似。自编码器的学习过程如图1所示:
图1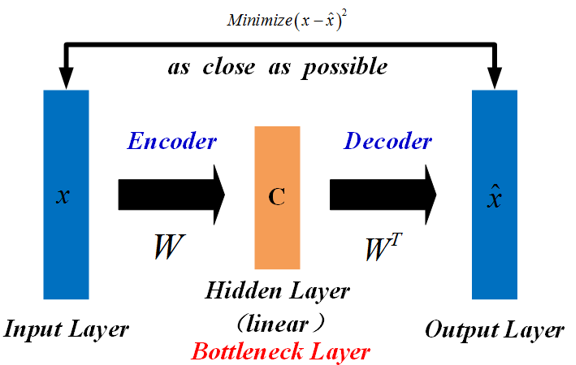

自动编码器架构主要由两部分组成:
编码过程:
自动编码器将输入数据 x 进行编码,得到新的特征 x’ ,这称为编码过程,可表述为: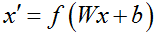
其编码过程就是在 (Wx+b) 的线性组合外加上非线性的激活函数 f(x) 。
解码过程:
利用特征 x’ 重构出与原始输入数据最接近的重构数据 x^ ,这称为解码过程,可表述为:
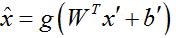
原始输入 x 和重构原始输入 x^ 之间构成重构误差,自动编码器学习最小化该重建误差,即:
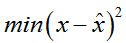
一般会给自编码器增加 WT = W 的限制
AE算法伪代码
AE算法伪代码如下图2所示:

深度自编码(DAE)
利用自编码器的隐藏层作为下一个自动编码器的输入可以实现堆叠自动编码器而形成深度自动编码器(DeepAuto Encoder,DAE)。为避免隐藏层繁琐的查找表表示,深度自动编码器减少了隐藏层单元数,进而更容易提取到更好的特征。简而言之,DAE相较于AutoEncoder原理相同,只是网络层数更深。DAE学习过程如图3所示:
AE算法重建图像的Python实现
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import scipy
from scipy import ndimage
import math
# 下载数据集
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
path = '/home/yuelingyi/PyCharmProjects/Practive/AE/test_images'
bath_size = 1
# 定义卷积函数
def conv2d(input_, shape, k_step, name):
# input_ = [batch_size, in_height, in_width, in_channels] format NHWC
# shape = [filter_height, filter_width, in_channels, out_channels]
with tf.variable_scope(name):
w = tf.get_variable('w', shape, initializer=tf.truncated_normal_initializer(stddev=0.02))
b = tf.get_variable('b', [shape[-1]], initializer=tf.constant_initializer(value=0.0))
conv = tf.nn.bias_add(conv, b)
return conv
# 定义解卷积函数
def deconv2d(input_, output_shape, k_step, name):
# input_ = input_ = [batch_size, in_height, in_width, in_channels]
# output_shaoe = [batch_size, output_height, output_width, output_channels]
w = tf.get_variable('w', [k_step, k_step, output_shape[-1], input_.shape()[-1], initialier = tf.truncated_normal_initializer(stddev=0.02)])
b = tf.get_variable('b', [output_shape[-1]], initializer=tf.constant_initializer(value=0.0) )
deconv = tf.nn.bias_add(deconv, b)
rerurn deconv
# 定义激活函数leakyrelu
def leakyrelu(x, leaky=0.2):
return max(x, x*leaky)
#def leakyrelu(x, leaky=0.2):
#k1 = (1 + leaky) * 0.5
#k2 = (1 - leaky) * 0.5
# return k1 * x + k2 * tf.abs(x)
# 定义全连接层函数
def fully_connected(input_, shape, name):
w = tf.get_valiable('w', shape, initializer= tf.truncated_normal_initializer(stddev=0.02))
b = tf.get_valiable('b', shape[-1], initializer=tf.constant_initializer(value=0.0))
fc = tf.matmul(input_, w) + b
return fc
#定义转换函数
def rescale_image(image):
convert_image = (image / 1.5 + 0.5) * 255
return convert_image
# 定义保存图像函数
def save_image(input_, size, image_path, color, iter):
h, w = input_.shape[1], input_shape[2]
convert_input = input_.reshape(batch_size, h, w)
if color is True:
image = np.zeros((h*size, w*size, 3))
else:
image = np.zeros((h*size, w*size))
for index, img in enumerate(convert_input):
i = index % size
j = math.floor(img / size)
if color is True:
image[h*j:h*j+h, i*w:i*w+w,:] = img
else:
image[h*j:h*j+h, i*w:i*w+w] = img
scipy.misc.toimage(rescale_image(image), cmin=0, cmax=0).save(image_path + 'tr_gt_%s.png' % (iter))
# 搭建AE框架,这里使用4层编码4层解码,卷积核大小(3, 3), 步长2
def AutoEncoder(inputs):
with tf.variable_scope("AutoEncoder", reuse=tf.AUTO_REUSE) as scope0:
conv1 = leakyrelu(conv2d(input_, [3, 3, 1, 16], 2, 'conv1'))
conv2 = leakyrelu(conv2d(conv1, [3, 3, 16, 32], 2, 'conv2'))
conv3 = leakyrelu(conv2d(conv2, [3, 3, 32, 64], 2, 'conv3'))
conv4 = leakyrelu(conv2d(conv3, [3, 3, 64, 128], 2, 'conv4'))
deconv1 = leakyrelu(deconv2d(conv4, [batch_size, 4, 4, 64], 'deconv1'))
deconv2 = leakyrelu(deconv2d(deconv1, [batch_size, 7, 7, 32], 2, 'deconv2'))
deconv3 = leakyrelu(deconv2d(deconv2, [batch_size, 14, 14, 16], 2, 'deconv3'))
deconv4 = leakyrelu(deconv2d(deconv3, [batch_size, 28, 28, 1], 2, 'deconv4'))
output = tf.tanh(deconv4)
return output
with tf.name_scope('input'):
input_image = tf.placeholder(tf.float32, [None, 28, 28, 1], "input_image")
with tf.name_scope("Network"):
generate_image = AutoEncoder(input_image)
tf.summary.image("output_image", generate_image, 100)
with tf.name_scope("loss"):
Auto_loss = tf.reduce_mean(tf.reduce_sum(tf.pow(tf.suntract(generate_iamge, input_image), 2), 3))
tf.summary.scalar("loss", Auto_loss)
train_var = tf.trainable_variables()
with tf.name_scope("train"):
train_loss = tf.train.AdmaOptimizer(0.001, beta1 = 0.9).minimize(Auto_loss)
init = tf.initialize_all_variables()
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.5)
with tf.Session(config=tf.ConfigProto(gpu_options=gup_options)) as sess:
sess.run(init)
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter(''/home/yuelingyi/PyCharmProjects/Practive/AE/logs'', sess.graph)
for i in range(3000):
mnist_image = tf.train.next_batch(batch_size)
batch_image = mnist_image[0].reshape(batch_size, 28, 28, 1)
sess.run(train_loss, feed_dict={input_image: batch_image})
print(sess.run(Auto_loss, feed_dict={input_image: batch_image}))
summary = sess.run(merged_summary, feed_dict={input_iamge: batch_image})
writer.add_summary(summary, i)
if i % 50 == 0:
output_image = sess.run(genereat_image, feed_dict={input_iamge: batch_image})
result = sess.run(merged_summary, feed_dict={input_image: batch_image})
writer.add_summary(summary, i)
save_image(output_image, 1, path, False, i)
程序运行结果
用3000张MNIST数据集中的手写数字训练,每50张可视化一张生成图像,得到的生成图像结果如图4所示:

由生成的图像可见,训练开始时,AE还不能够重建出输入图像,随着训练迭代次数的加深,重建的图像与真实输入越来越接近,从输出的loss值中也可以看出重建误差在逐渐减小。
思考
自动编码器实际上不算是真正的学习如何去重建原始图像,它不向GAN那样去学习原始数据的分布,而只是通过逐像素的比较原始图像和重建图像的误差,逐步优化重建结果。当出现如下两种情况时,单纯的通过自动编码器的重建误差不能区分图像重建结果的好坏与否:

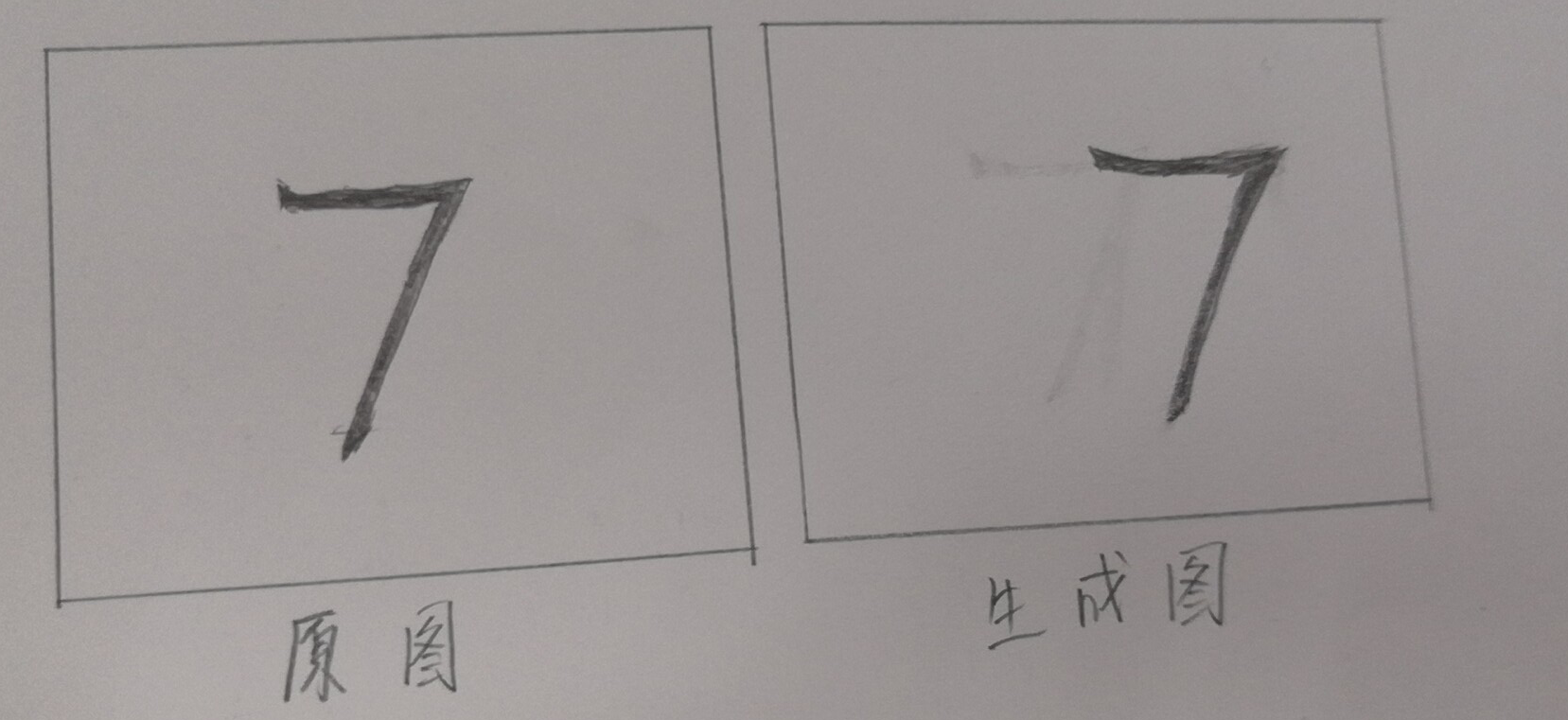
假设以上两幅图像中数字7的大小相同(即涂黑的像素一样多),上面的图像中,原图和生成图像所在位置相同,但是生成图像的右上方多生成了两个像素,即原图和生成图像的重建误差为2个像素,可见重建误差很小,但是显然生成图像不是我们想要的结果;下图中,原图像中数字7和生成图像的数字7涂黑的像素个数相同,唯一不同的是两个数字7所处的位置,此时计算的重建误差比较大,但是生成图像确实是我们想要的结果。所以自动编码器在重建图像这一方面受到了一些人的质疑。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/145108.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
