大家好,又见面了,我是你们的朋友全栈君。
前言
当初写这篇博客的初衷只是记录自己学习SSD的一些心得体会,纯属学习笔记,后来由于工作上的需要,需要对小伙伴进行目标检测方面的培训,后来就基于这篇博客进行了扩展,逐渐演变成了现在的样子,本文力求从一个初学者的角度去讲述目标检测和SSD(但是需要你具备CNN的基础),尽量使用通俗的语言并结合图表的方式让更多初学者更容易理解SSD这个算法,但是一个人的时间精力有限,不可能深入理解SSD的每一个细节,加上表达能力也有限,自己理解了的东西不一定在文中能够说明白,文中有什么不妥的地方,欢迎大家批评指正,也欢迎留言一起交流讨论。
ps:平时会遇到咨询关于如何使用C++加载onnx模型完成SSD或者YOLO推理的问题,可以参考这篇博客:OpenCV加载onnx模型实现SSD,YOLOV3,YOLOV5的推理
目标检测基础
在实际的工作中发现,一些小伙伴在学习检测的时候对一些基础的东西理解的还不够,这里总结了比较重要的几点。
传统目标检测的基本原理
为什么要提传统目标检测呢?因为理解传统目标检测对于理解基于深度学习的目标检测非常重要,因为学到最后你会发现,两者的本质都是一样的,都是对滑动窗口的分类。下面我们看一下传统目标检测的基本原理。
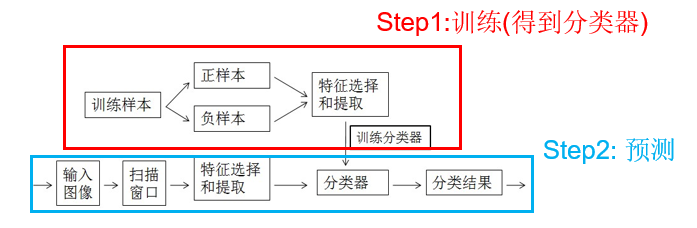

主要分为两个步骤:训练+预测,其中训练主要是用来得到分类器,比如SVM,预测就是使用训练好的分类器对图像中的滑动窗口进行特征提取然后分类,最后得到检测的结果。下面以人脸检测为例:
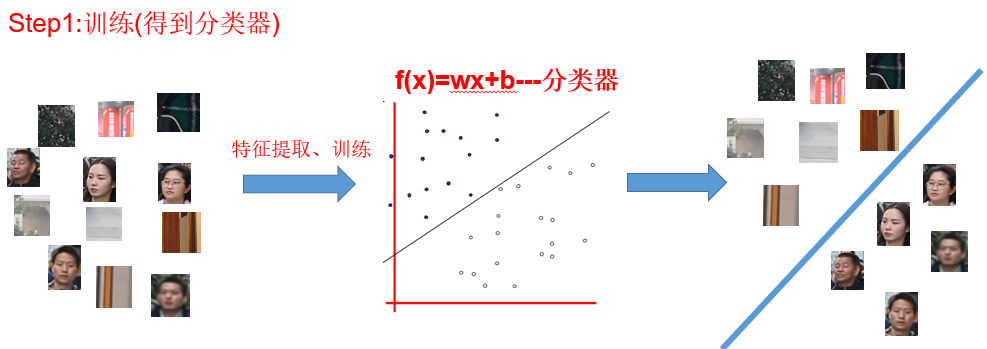
假设我们需要训练一个人脸检测器,那第一步就是训练一个人脸的分类器,这个分类器有什么作用呢?它的作用就是将上图左边的很多图像划分为两类:人脸和非人脸。分类器训练好了之后,就可以进行检测了。
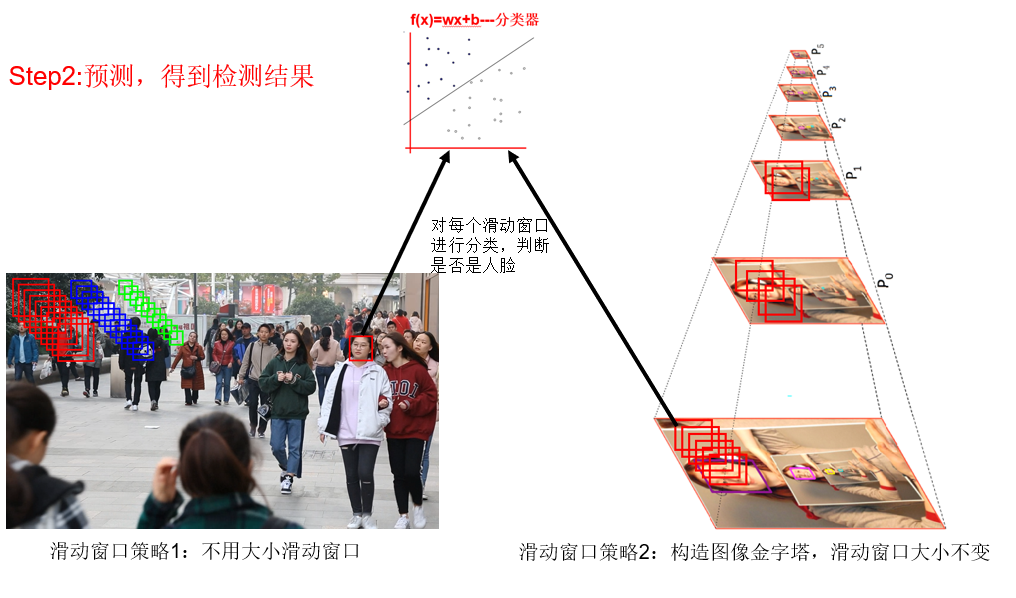
预测阶段有两种滑动窗口策略:
- 策略1:使用不同大小的滑动窗口,对每个滑动窗口提取特征并分类判断是否是人脸,最后经过NMS得到最后的检测结果,本文的SSD本质上就是这种策略,不同检测层的anchor就类似于不同大小的滑动窗口
- 策略2:构造图像金字塔,只使用一种大小的滑动窗口在所有金字塔图像上滑动,对每个滑动窗口提取特征并分类判断是否是人脸,最后经过NMS得到最后的检测结果,MTCNN就是采用了这种策略
传统目标检测的代表主要有:
- HOG+SVM的行人检测
- Haar+Adaboost的人脸检测
为什么要使用全卷积神经网络做检测
我们知道经典的深度学习目标检测算法的代表SSD,YOLOV3和FasterRCNN的RPN都使用了全卷积神经网络,那为什么要使用全卷积呢?
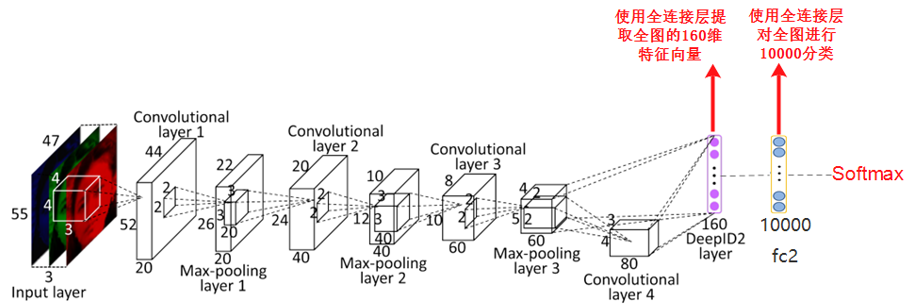
分类网络
下面是一个典型的分类网络结构:
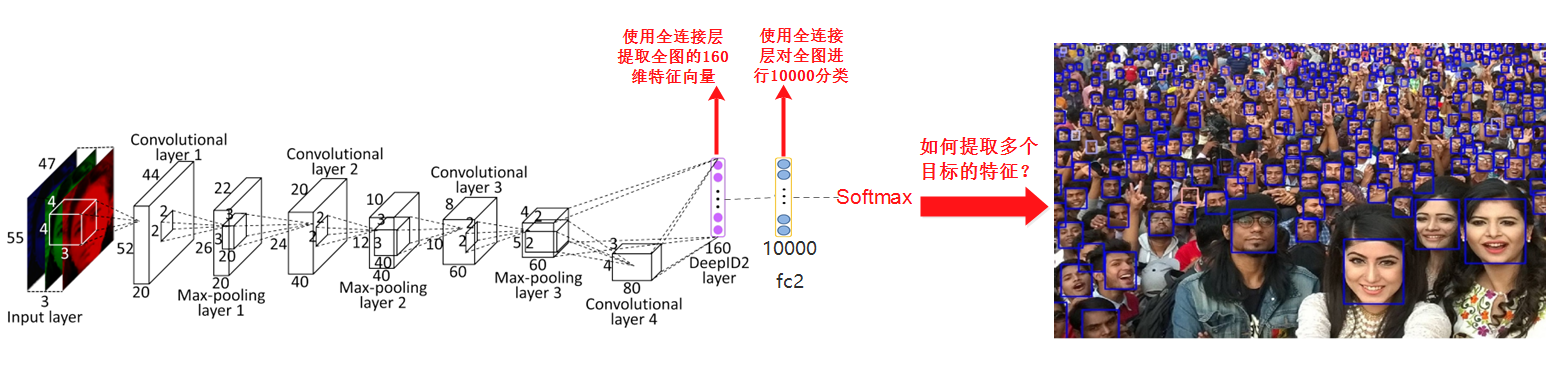
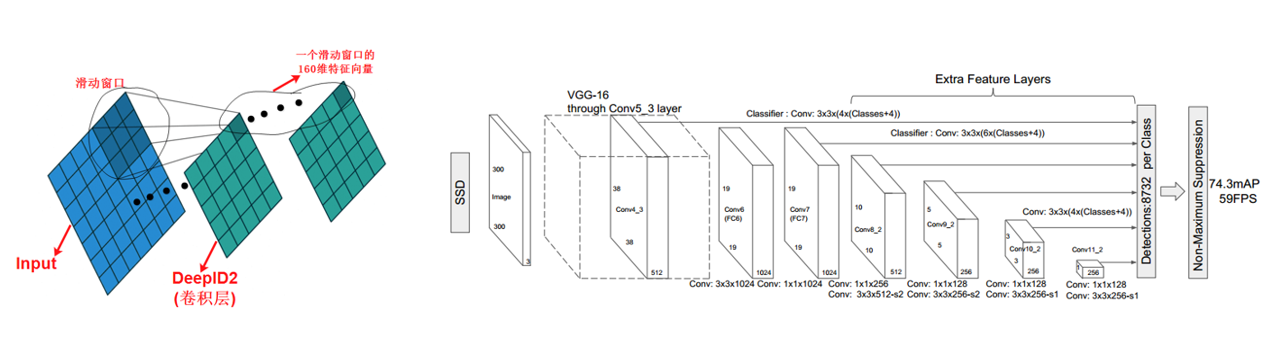
图片来自经典的人脸识别论文DeepID2:https://arxiv.org/abs/1406.4773
我们知道典型的分类网络,比如VGG,ResNet等最后都会使用全连接层提取特征,然后经过softmax计算每一类的概率。
典型的分类网络有如下特点:
- Softmax的前一层为全连接层,且输出节点数为分类的类别数,比如imagenet有1000类,则最后的全连接层有1000个输出节点,分别对应1000类的概率,VGG16中的fc8对应了这一层,上图有10000分类,所以fc2有10000个输出节点
- Softmax的倒数第二层也为全连接层,这一层一般是提取特征用的,比如VGG16中的fc7层就是用来提取特征的,上图中DeepID2层也是用来进行提取特征的
- 由于使用全连接层提取特征,所以提取的是全图的特征,所以一张图像中只能包含一个目标,如果有多个目标,提取出来的特征就不准确,影响最后的预测
- 由于全连接层的存在,网络的输入大小必须是固定的
那如何才能提取多个目标的特征呢?
使用卷积层代替全连接层进行特征提取
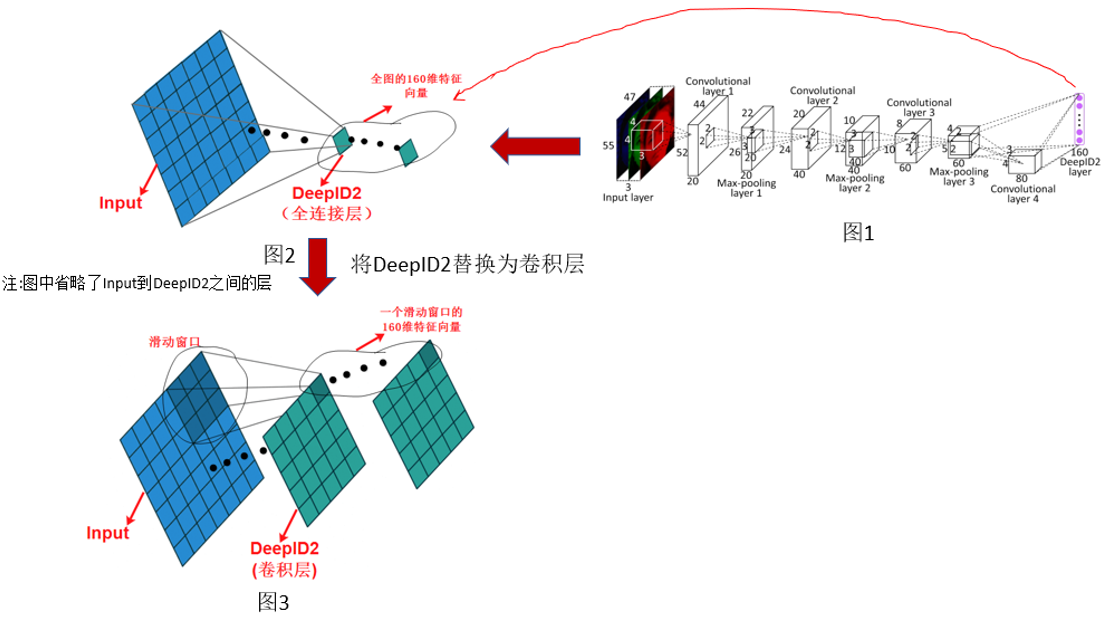
我们将图1简化为图2的表示形式,其中图2中省略了Input到DeepID2中间的层,我们看到当DeepID2是全连接层的时候,感受野对应了全图,所以提取的是全图的特征,现在我们把DeepID2替换为卷积层,其中卷积层的输出通道数为160,这是为了能够提取160维的特征向量,图3中我们可以看到当使用卷积层的时候,DeepID2的输出特征图的每个位置的感受野不是对应了全图,而是对应了原图的某一个滑动窗口,这样DeepID2这一层就可以提取原图多个滑动窗口的特征了,图3中我们可以看到一共提取出了25个滑动窗口的160维特征向量,然后我们就可以对这25个滑动窗口做分类了。这样就使得检测成为了可能。
使用卷积层代替全连接层进行分类
我们知道在分类网络中softmax的前一层使用的是全连接层,且该全连接层的输出节点数为分类数,比如上文中的DeepID2的后面的fc2层。
但是现在DeepID2这一层变成了卷积层之后,fc2层就不适合采用全连接层了。下面我们将fc2层替换为卷积层,我们采用1×1卷积(也可以使用3×3卷积),同时卷积层的输出通道数为10000,对应了10000分类。
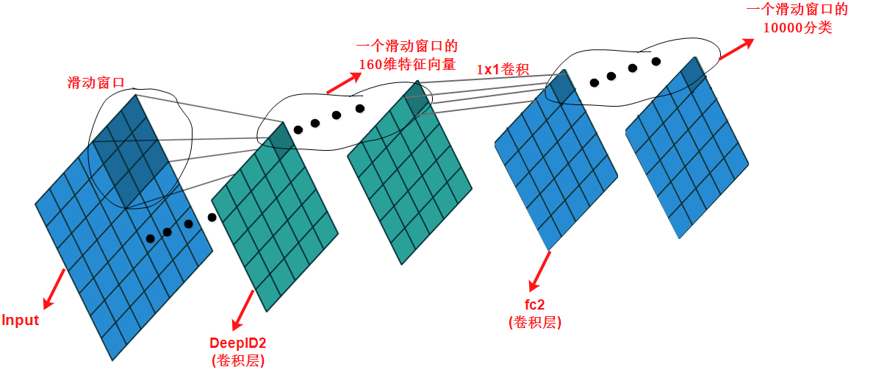
我们看到当fc2采用1×1卷积的时候,fc2层的特征图中的每个位置对应了一个滑动窗口的10000分类,这样一共得到25×10000的特征向量,表示对25个滑动窗口的10000分类。最后将这25×10000的特征向量输入softmax,就可以实现对这25个滑动窗口的分类了。
这其实就是经典的OverFeat的核心思想。
注意:这里并没有说检测网络不能使用全连接层,其实检测网络也可以使用全连接层。检测网络只是使用卷积层代替全连接层提取特征,最后对特征进行分类和回归可以使用卷积层也可以使用全连接层,YOLOV1最后就使用了全连接层对特征进行分类和回归,只是这样会有一些缺点:网络的输入大小必须是固定的,而且最后检测的效果往往没有使用卷积层做分类和回归的效果好。
确定每个滑动窗口的类别
上文中,我们将传统的分类网络一步一步的修改成了一个检测网络,知道了如何提取多个目标的特征以及使用卷积层代替全连接层进行分类,现在我们还差最后一步:要对多个目标进行分类,还需要知道他们的groundtruth,也就是他们的类别,那么如何确定类别呢?
这里就要用到anchor这项技术。
anchor就是用来确定类别的。
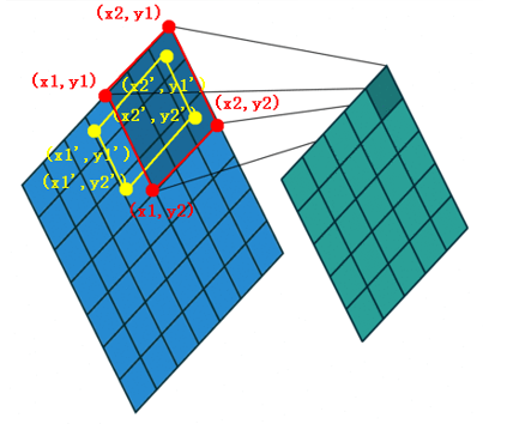
我们知道anchor的参数是可以手动设置的,上图中
anchor的大小被设置为 [x1,y1,x2,y2],这个anchor就是上文中提到的滑动窗口
groundtruth对应 [x1’,y1’,x2’,y2’]
然后通过计算anchor和groundtruth之间的IOU就可以确定这个滑动窗口的类别了(比如IOU>0.5的为正样本,IOU<0.3的为负样本)。关于anchor在下文中会有详细讨论。
到这里,SSD的整体框架已经基本搭建好了。其实SSD的多个检测层就等价于多个DeepID2层,不同检测层有不同大小的滑动窗口,能够检测到不同大小的目标。每个检测层后面会接2路3×3卷积用来做分类和回归,对应了fc2层。
理解了上面的内容之后,其实就很容易理解SSD了。
SSD效果为什么这么好
虽然SSD这个算法出来已经两年了,但是至今依旧是目标检测中应用最广泛的算法,虽然后面有很多基于SSD改进的算法,但依旧没有哪一种可以完全超越SSD。那么为什么SSD效果这么好?SSD效果好主要有三点原因:
- 多尺度
- 设置了多种宽高比的anchor
- 数据增强
注:
- anchor,default box,prior box表示的是同一个意思,本文统一使用更加常用的anchor来表示。实际上,anchor技术的鼻祖是DeepMultiBox(2014年CVPR:Scalable Object Detection using Deep Neural Networks),这篇论文里首次提出使用prior(先验框),并且提出使用prior做匹配。后面的众多工作,比如RCNN系列,YOLO系列都使用了anchor这个术语,而在SSD中anchor又叫default box,本质上都是表示的同一个东西。
原因1:多尺度
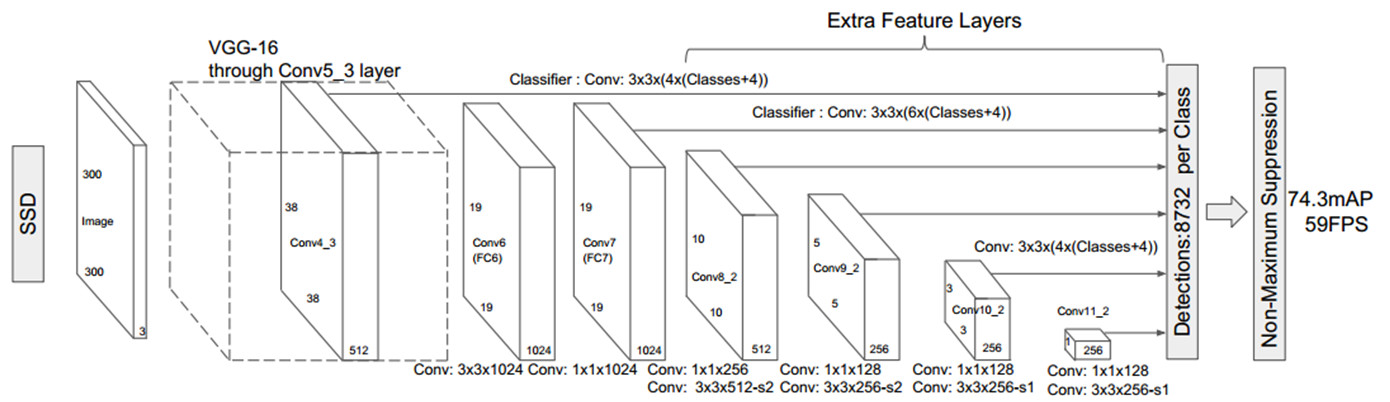
由SSD的网络结构可以看出,SSD使用6个不同特征图检测不同尺度的目标。低层预测小目标,高层预测大目标。
通过前面的学习,其实就很容易理解SSD中的多尺度检测,这6个检测层都是卷积层,对应了上文中的6个DeepID2层,每个DeepID2层对应了不同大小的滑动窗口(低层滑动窗口较小,高层滑动窗口较大),这样就可以检测到不同尺度的目标了。

作者在论文中通过实验验证了,采用多个特征图做检测能够大大提高检测精度,从上面的表格可以看出,采用6个特征图检测的时候,mAP为74.3%,如果只采用conv7做检测,mAP只有62.4%。
原因2:设置了多种宽高比的anchor
在特征图的每个像素点处,生成不同宽高比的anchor,论文中设置的宽高比为{1,2,3,1/2,1/3}。假设每个像素点有k个anchor,需要对每个anchor进行分类和回归,其中用于分类的卷积核个数为ck(c表示类别数),回归的卷积核个数为4k。
SSD300中anchor的数量:(38384 + 19196 + 10106 + 556 + 334 + 114)= 8732
对于初学者一定有以下几个问题:
- 为什么要设置anchor?
- 为什么同一个检测层可以设置不同大小的anchor?
- 为什么一个检测层可以设置多个anchor?
- 为什么要设置多种宽高比的anchor?
理论感受野和有效感受野
NIPS 2016论文Understanding the Effective Receptive Field in Deep Convolutional Neural Networks[1]提出了有效感受野(Effective Receptive Field, ERF)理论。有效感受野的理解对于理解anchor非常重要。
影响某个神经元输出的输入区域就是理论感受野,也就是我们平时说的感受野,但该输入区域的每个像素点对输出的重要性不同,越靠近中心的像素点影响越大,呈高斯分布,也就是说只有中间的一小部分区域对最后的输出有重要的影响,这个中间的一小部分区域就是有效感受野。
有效感受野在训练过程中是会发生变化的,影响有效感受野的因素:
- 数据集
- 层的类型(下采样,扩张卷积,跳层连接,非线性激活函数)
- 卷积层参数初始化方式(Uniform(参数全部设置为1), Random)
- 卷积层的个数
下图展示了不同因素对有效感受野的影响

卷积层层数,权值初始化方式以及非线性激活对ERF的影响

下采样和扩张卷积可以增大感受野

不同数据集对感受野的影响
为什么要设置anchor?
通过前面的学习,我们知道,在分类/识别问题中,通常整张图就包含一个目标,所以只需要对一个目标直接分类就好了,所以最后直接使用全连接层提取整幅图像的特征就可以了(全连接层理论感受野大小就是输入大小)。但是检测问题中,输入图像会包含有很多个目标,所以需要对多个目标进行特征提取,这个时候就不能使用全连接层了,只能使用卷积层,卷积层的输出特征图上每个位置对应原图的一个理论感受野,该位置提取的就是这个理论感受野区域的特征,然后我们只需要对这个特征进行分类和回归就可以实现检测了。在实际训练训练过程中,要想对这个特征进行分类,我们就需要知道这个特征提取的是什么目标的特征,所以我们需要知道两个东西:
- 这个特征对应了原图什么区域?
- 这个区域的label是什么?
但是在实际训练过程中,我们并不知道这个理论感受野的大小,这个时候就出现了anchor技术。
anchor作用:通过anchor设置每一层实际响应的区域,使得某一层对特定大小的目标响应。这样检测层提取的就是anchor对应区域的特征了。通过anchor我们就可以知道上面两个问题的答案了。
论文中也提到:
Feature maps from different levels within a network are known to have different (empirical) receptive field sizes. Fortunately,
within the SSD framework, the default boxes do not necessary need to correspond to the actual receptive fields of each layer. We design the tiling of default boxes so that specific feature maps learn to be responsive to particular scales of the objects.
通过设计anchor的平铺可以使得特定的特征图对特定大小的目标进行响应。
下图可以更加形象的表示anchor的作用

图a中黑色虚线区域对应图b中的理论感受野,红色实线框是手动设置的anchor大小
图b是使用图a中的anchor参数训练出来的模型,其中整个黑色区域就是理论感受野(TRF),对应a图的黑色虚线区域,中间呈高斯分布的白色点云区域就是由于设置了anchor而实际发生响应的区域,这个区域就是有效感受野(ERF),我们用anchor等价表示这个区域。
我们可以看到通过在图a中设置anchor可以设置该层实际响应的区域,使得对特定大小的目标响应。
这里还有几个问题需要说明一下。
-
为什么anchor可以设置实际响应的区域?
这就是CNN的神奇之处,这个问题目前我还不知道如何解释,就像目前的深度学习依然是不可解释的一样,这点就当作一个结论记住就可以了。 -
为什么同一个检测层可以设置不同大小的anchor
我们知道可以通过anchor设置每一层实际响应的区域,使得某一层对特定大小的目标响应。
是否每一层只能对理论感受野响应呢?有效感受野理论表明,每一层实际响应的区域其实是有效感受野区域,而且这个有效感受野区域在训练过程中会发生变化(比如不同数据集的影响等),正是由于有效感受野有这个特性,所以我们可以在同一个检测层设置不同大小的anchor,也就是说你既可以设置anchor大小为理论感受野大小,也可以将anchor大小设置为其他大小,最后训练出来的网络会根据你的设置对特定大小的区域响应。 -
为什么在同一个特征图上可以设置多个anchor检测到不同尺度的目标
刚开始学SSD的朋友一定有这样的疑惑,同一层的感受野是一样的,为什么在同一层可以设置多个anchor,然后在分类和回归两个分支上只需要使用不同通道的3×3卷积核就可以实现对不同anchor的检测?虽然分类和回归使用的是同一个特征图,但是不同通道的3×3卷积核会学习到那块区域的不同的特征,所以不同通道对应的anchor可以检测到不同尺度的目标。 -
anchor本身不参与网络的实际训练,anchor影响的是classification和regression分支如何进行encode box(训练阶段)和decode box(测试阶段)。测试的时候,anchor就像滑动窗口一样,在图像中滑动,对每个anchor做分类和回归得到最终的结果。
-
关于anchor的进一步探讨,见另一篇博客:深入理解anchor,欢迎大家畅所欲言
anchor与滑动窗口
上文中提到了两个概念:滑动窗口和anchor,每个检测层对应了不同大小的滑动窗口,也对应着不同大小的anchor,那这两个概念有什么区别呢?
这里我们不严格区分这两个概念,我们可以认为这两个表示的是同一个东西。
这里有一点要注意:由于anchor是可以手动设置的,所以某一个检测层的滑动窗口大小是会随着anchor的大小发生变化的,这就是anchor的神奇之处!
anchor的匹配
前面我们知道了SSD提取的是anchor对应区域的特征,实际训练的时候还需要知道每个anchor的分类和回归的label,如何确定呢?SSD通过anchor与groundtruth匹配来确定label。
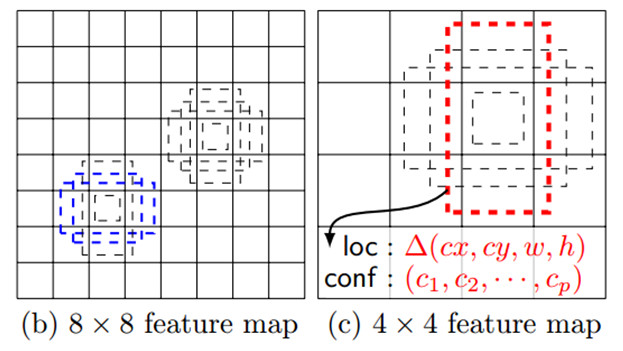
在训练阶段,SSD会先寻找与每个anchor的IOU最大的那个ground truth(大于IOU阈值0.5),这个过程叫做匹配。如果一个anchor找到了匹配的ground truth,则该anchor就是正样本,该anchor的类别就是该ground truth的类别,如果没有找到,该anchor就是负样本。图1(b)中8×8特征图中的两个蓝色的anchor匹配到了猫,该anchor的类别为猫,图1©中4×4特征图中的一个红色的anchor匹配到了狗,该anchor的类别为狗。图2显示了实际的匹配过程,两个红色的anchor分别匹配到了猫和狗,左上角的anchor没有匹配,即为负样本。
图1
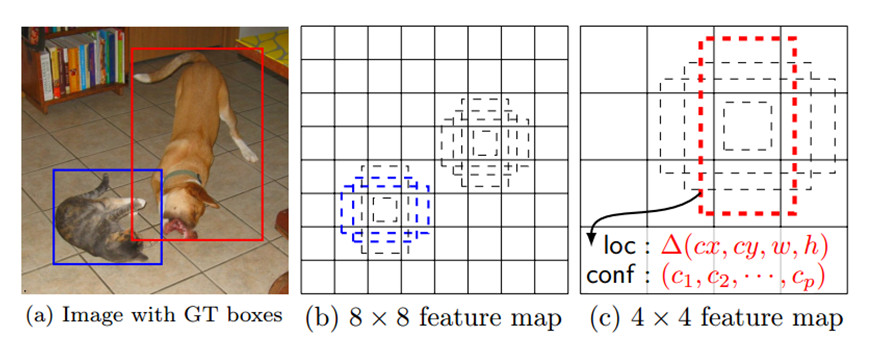
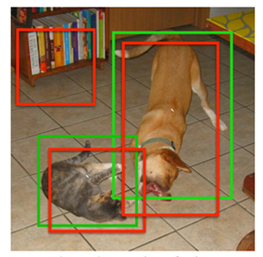
图 2(图中红色框表示anchor,绿色框表示groundtruth)
关于匹配更多的细节,参考Caffe源码multibox_loss_layer.cpp中的FindMatches()函数,前面的博客:SSD源码解读3-MultiBoxLossLayer中也讲到了该函数。
为什么要设置多种宽高比的anchor?
由于现实中的目标会有各种宽高比(比如行人),设置多个宽高比可以检测到不同宽高比的目标。

作者实验结果表明,增加宽高比为1/2,2,1/3,3的default box,mAP从71.6%提高到了74.3%。
如何选择anchor的scale和aspect ratio?
假设我们用m个feature maps做预测,那么对于每个featuer map而言其anchor的scale是按以下公式计算的。
S k = S m i n + S m a x − S m i n m − 1 ( k − 1 ) S_k=S_{min}+{
{S_{max}-S_{min}} \over {m-1}}(k-1) Sk=Smin+m−1Smax−Smin(k−1)
这里 S m i n S_{min} Smin是0.2,表示最低层的scale是0.2, S m a x S_{max} Smax是0.9,表示最高层的scale是0.9。宽高比 α r = 1 , 2 , 3 , 1 / 2 , 1 / 3 {\alpha}_r={1,2,3,1/2,1/3} αr=1,2,3,1/2,1/3,因此每个anchor的宽 w k α = S k α r w^{\alpha}_{k}=S_k \sqrt{
{\alpha}_r} wkα=Skαr,高 h k α = S k / α r h^{\alpha}_{k}={S_k / \sqrt{
{\alpha}_r}} hkα=Sk/αr,当aspect ratio为1时,作者还增加一种scale的anchor: S k ′ = S k S k + 1 S^{‘}_k= \sqrt{S_kS_k+1} Sk′=SkSk+1,因此,对于每个feature map cell而言,一共有6种anchor。
示例:
假设m=6,即使用6个特征图做预测, 则每一层的scale:0.2,0.34,0.48,0.62,0.76,0.9
对于第一层,scale=0.2,对应的6个anchor为:
| 宽高比 | 宽 | 高 |
|---|---|---|
| 1 | 0.200000 | 0.200000 |
| 2 | 0.282843 | 0.141421 |
| 3 | 0.346410 | 0.115470 |
| 1/2 | 0.141421 | 0.282843 |
| 1/3 | 0.115412 | 0.346583 |
| 最后增加的default box | 0.260768 | 0.260768 |
注:表格中每个宽高比的anchor的实际宽和高需要乘以输入图像的大小,如SSD300,则需要使用上面的数值乘以300得到anchor实际大小。
Caffe源码中anchor的宽高比以及scale的设置参考prior_box_layer.cpp,前面的博客:SSD源码解读2-PriorBoxLayer也对该层进行过解读。
原因3:数据增强
SSD中使用了两种数据增强的方式
1. 放大操作: 随机crop,patch与任意一个目标的IOU为0.1,0.3,0.5,0.7,0.9,每个patch的大小为原图大小的[0.1,1],宽高比在1/2到2之间。能够生成更多的尺度较大的目标
2. 缩小操作: 首先创建16倍原图大小的画布,然后将原图放置其中,然后随机crop,能够生成更多尺度较小的目标
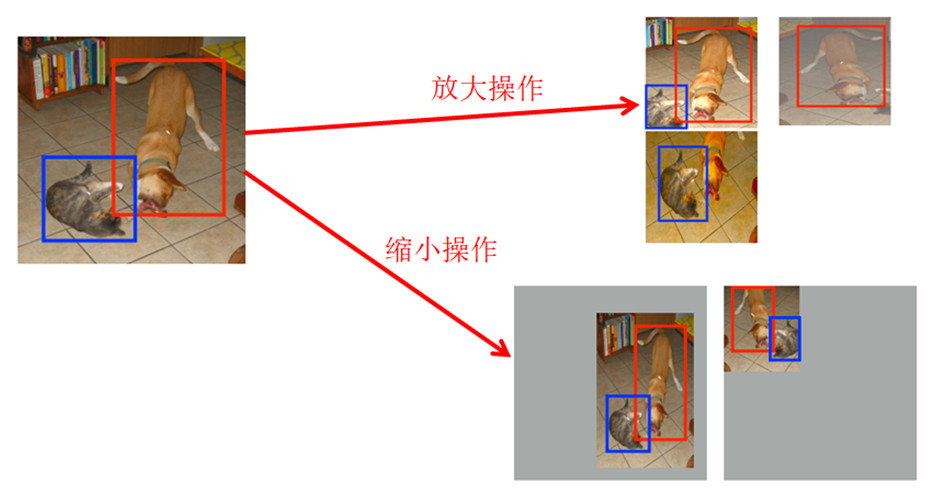

作者实验表明,增加了数据增强后,mAP从65.5提高到了74.3!
数据增强是SSD中最大的trick,已经成为了后面众多检测算法的标配了。
数据增强对应Caffe源码annotated_data_layer.cpp,前面的博客:SSD源码解读1-数据层AnnotatedDataLayer也对该层进行过解读。
SSD的缺点及改进
1. SSD主要缺点:SSD对小目标的检测效果一般,作者认为小目标在高层没有足够的信息。
论文原文:
This is not surprising because those small objects may not even have any information at the very top layers. Increasing the input size (e.g. from 300× 300 to 512× 512) can help improve detecting small objects, but there is still a lot of room to improve.
对小目标检测的改进可以从下面几个方面考虑:
1. 增大输入尺寸
2. 使用更低的特征图做检测(比如S3FD中使用更低的conv3_3检测)
3. FPN(已经是检测网络的标配了)
2. 关于anchor的设置的优化
An alternative way of improving SSD is to design a better tiling of default boxes so that its position and scale are better aligned with the receptive field of each position on a feature map. We leave this for future work. P12
论文中提到的anchor设置没有对齐感受野,通常几个像素的中心位置偏移,对大目标来说IOU变化不会很大,但对小目标IOU变化剧烈,尤其感受野不够大的时候,anchor很可能偏移出感受野区域,影响性能。
关于anchor的设计,作者还提到了
In practice, one can also design a distribution of default boxes to best fit a specific dataset. How to design the optimal tiling is an open question as well
论文提到根据特定数据集设计default box,在YOLOV2中使用聚类的方式初始化anchor,能够更好的匹配到ground truth,帮助网络更好的训练
SSD中的Mining机制
在视觉任务中经常遇到两个问题:
1. 类别不均衡
2. 简单样本和困难样本不均衡 (easy sample overwhelming)。easy sample如果太多,可能会将有效梯度稀释掉。
为了解决上述问题,研究人员提出了一些解决方案:
1. Online Hard Example Mining, OHEM(2016)。将所有sample根据当前loss排序,选出loss最大的N个,其余的抛弃。这个方法就只处理了easy sample的问题。
2. Focal Loss(2017), 最近提出来的。不会像OHEM那样抛弃一部分样本,focal loss考虑了每个样本, 不同的是难易样本上的loss权重是根据样本难度计算出来的。
SSD中采用了一种新的Mining机制,OHNM(Online Hard Negative Mining),在Focal Loss里代号为OHEM 1:3,是对OHEM的一种改进。OHNM在计算loss时, 使用所有的positive anchor, 使用OHEM选择3倍于positive anchor的negative anchor。同时考虑了类间平衡与easy sample。通过OHNM让训练更快收敛同时也更加稳定。
注意,SSD中mining具体实现的时候,MultiBoxLoss层的 mining_type可以选择MAX_NEGATIVE或者HARD_EXAMPL
- MAX_NEGATIVE对应OHNM, 只计算分类loss,不计算定位loss,只针对负样本选择loss最大的3倍于正样本数量的负样本
- HARD_EXAMPL对应OHEM ,会同时计算分类和定位loss,选择出loss最大的前topN个样本
具体实现参考MineHardExamples()函数。
SSD与MTCNN
这里为什么会提到MTCNN[2]呢?如果你了解过MTCNN这个算法,一定对PNet这个网络不陌生,仔细比较SSD与PNet,你就会发现SSD与PNet之间有着千丝万缕的联系。
其实我对SSD的理解就是源于MTCNN中的PNet,实际上SSD可以看成是由6个不同的PNet组合而成。
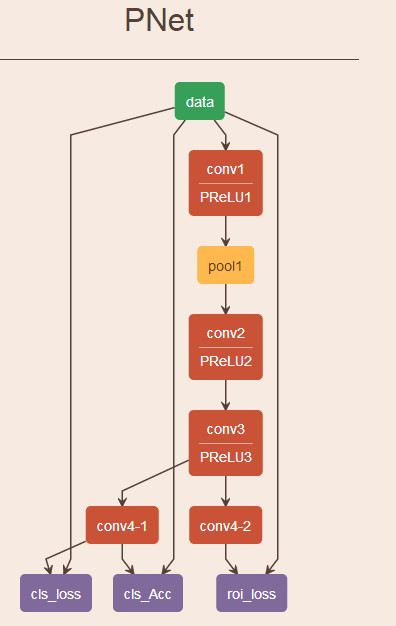
这里用原论文中的SSD300的结构与MTCNN作比较
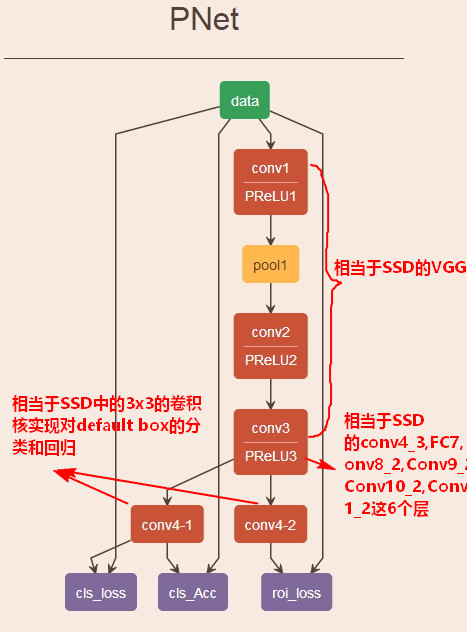
SSD与MTCNN的不同
- 生成训练数据的方式不同
MTCNN需要事先手动将所有的训练样本生成好,然后输入到网络中训练, 而SSD不需要,SSD在训练过程中自动生成所有训练样本。SSD中实际的训练样本就是所有anchor,每个anchor的label由anchor与ground truth匹配来确定。SSD实现了真正意义上端到端的训练。 - MTCNN和SSD采用了两种不同的多尺度检测策略
MTCNN:首先构建图像金字塔,然后使用固定大小的滑动窗口在金字塔每一级滑动,对每个滑动窗口分类回归。
SSD: 在原图中设置了不同大小的滑动窗口,对不同大小的滑动窗口进行分类和回归。
不管是MTCNN,还是SSD,本质上是对所有滑动窗口的分类。这与传统的目标检测方法本质上是一样的。 - Mining的方式不同
MTCNN需要手动做mining,而SSD采用了OHNM训练过程中自动完成负样本的mining,解决了简单样本的问题和类别不平衡问题。 - 其实MTCNN中也是有anchor的, MTCNN中的anchor就是PNet的滑动窗口
MTCNN的训练样本就是滑动窗口图像,而生成训练样本的时候使用滑动窗口与groundtruth进行匹配,得到分类和回归的label,所以anchor就是PNet的滑动窗口。不过与SSD的区别在于这个匹配过程不是训练过程中自动完成的,而是事先手动完成。
判断什么是anchor的方法:使用什么匹配groundtruth的,那个就是anchor
SSD与YOLOV3
YOLOV3和SSD在很多地方都非常相似,连YOLOV3的作者都说了,YOLOV3只是借鉴了其他人的一些思想(So here’s the deal with YOLOv3: We mostly took goodideas from other people.),看完YOLOV3,我甚至都觉得YOLOV3就是抄的SSD。但是不管怎么样,目前工业界用的最多的目标检测算法就是SSD和YOLO。YOLOV3和SSD都使用了anchor技术+多尺度检测+FPN。但是在诸多细节上稍有不同。
SSD与YOLOV3的不同
- 训练数据格式不同:SSD的训练数据坐标顺序为label x1 y1 x2 y2,而YOLOV3为 label x y w h(x,y表示中心点)
- 网络结构方面,对坐标偏移和类别预测的结构不同:SSD在每个检测层使用了两个分支分别做分类和回归,但是YOLOV3在每个检测层只使用了一个分支,也就是说只用了一个tensor预测了3部分内容:坐标偏移+目标置信度+分类置信度(通道数为4+1+classNum)。
- 坐标偏移量的编码形式不同。
SSD和FasterRCNN使用了相同的编码方式
而YOLOV3使用了如下的编码方式
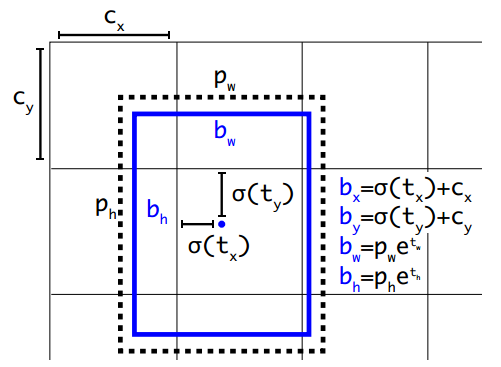
SSD的坐标偏移很好理解,就是ground truth和anchor之间的偏移,但是YOLOV3中的偏移有点不同,YOLOV3的代码中,cx和cy表示的是检测层特征图每个像素点的坐标(实际计算的时候,做了归一化处理),其实也就是anchor的中心点,所以第1,2个公式表示的就是预测框和anchor中心点的偏移,第3,4个公式和SSD的是一样的 - 训练中anchor的匹配策略不同。SSD中,如果一个anchor匹配到groundtruth了,就是正样本,否则为负样本,一个groundtruth可以有多个anchor匹配到,但是YOLOV3中,一个groundtruth只能有一个anchor匹配到,这个anchor负责预测这个groundtruth,而且YOLOV3用了双阈值处理,YOLOV3会忽略掉一部分样本。但是我在阅读作者源码的时候发现,源码和论文有点出入,训练的时候,并不是只有最佳匹配的anchor参与训练,只要IOU大于阈值的都会参与训练,但是在YOLOV2中,只有最佳匹配的anchor会参与训练。
- SSD使用了单阈值匹配,YOLOV3使用了双阈值匹配。前面也提到了这一点,SSD在区分正负anchor的时候,只用了一个阈值,但是YOLOV3使用了两个阈值。
- loss的形式不同。
如果还有不同点没有列出的,欢迎留言补充。
SSD和YOLOV3在众多细节上有所不同,但是孰优孰劣,目前还没有定论。只要用的好,这两个算法的性能都是非常不错的,能够熟练掌握其中的一种就够用了。
与传统目标检测的关系
基于深度学习的检测算法,不管是SSD,YOLOV3,FasterRCNN还是MTCNN,本质上都是一样的,都是对滑动窗口的分类。
结束语
博客最初写于2018-08-27, 2019-11-10和2020-6-9分别对原博客做了两次重大修改,随着对SSD一遍又一遍的学习和思考,每一次都能够发现以前有些地方理解还是有点问题的,现在越来越能体会到,为什么经典需要反复阅读反复思考,每次都会有新的理解,每次都能发现不一样的东西。
最后希望这篇文章能够帮助到你。
2018-8-27 08:08:36
Last Updated: 2020-6-9 14:11:48
参考文献
[1] [2016 NIPS] Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
[2] [2016 ISPL] Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
[3] [2014 NIPS] Deep Learning Face Representation by Joint Identification-Verification
非常感谢您的阅读,如果您觉得这篇文章对您有帮助,欢迎扫码进行赞赏。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139057.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
