大家好,又见面了,我是你们的朋友全栈君。
01:源码安装Python3
一、源码安装
- 安装依赖软件包
[root@qfedu.com ~]# yum groupinstall "Development Tools"
[root@qfedu.com ~]# yum -y install zlib-devel bzip2-devel openssl-devel sqlite-devel readline-devel libffi-devel
- 下载源码包
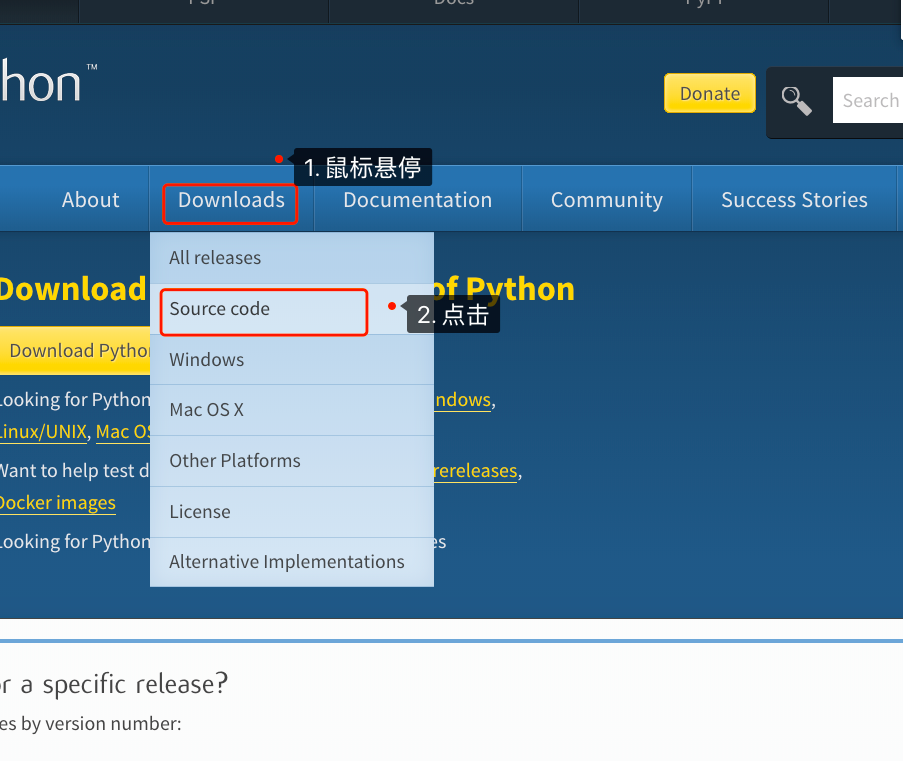
![Python#Typora-Python笔记[通俗易懂]](https://img-blog.csdnimg.cn/img_convert/4912e268fa6b760bbd74ee61f86ff41a.png)
可以直接点击下载,也可以右键 选择复制链接地址。
[root@qfedu.com ~]# wget https://www.python.org/ftp/python/3.7.6/Python-3.7.6.tar.xz
- 解压安装
[root@qfedu.com ~]# tar -xf Python-3.7.6.tar.xz
[root@qfedu.com ~]# cd Python-3.7.6
- 修改配置信息
可以选择如下两种方式之一
4.1 方式一:直接使用 vi 修改
修改文件 Python-3.7.6/Modules/Setup.dist, 去掉如下几行的注释 :
readline readline.c -lreadline -ltermcap
SSL=/usr/local/ssl
_ssl _ssl.c \
-DUSE_SSL -I$(SSL)/include -I$(SSL)/include/openssl \
-L$(SSL)/lib -lssl -lcrypto
4.2 方式二:在 shell 命令提示符下执行如下命令:
sed -ri 's/^#readline/readline/' Modules/Setup.dist
sed -ri 's/^#(SSL=)//' Modules/Setup.dist
sed -ri 's/^#(_ssl)//' Modules/Setup.dist
sed -ri 's/^#([\t]*-DUSE)//' Modules/Setup.dist
sed -ri 's/^#([\t]*-L$\(SSL\))//' Modules/Setup.dist
- 开始编译安装
[root@qfedu.com ~]# ./configure --enable-shared
[root@qfedu.com ~]# make -j 2 && make install
# -j 当前主机的 cpu 核心数
–enable-shared 指定安装共享库,共享库在使用其他需调用python的软件时会用到,比如使用
mod_wgsi连接Apache与python时需要。
二、 配置环境
执行如下命令
[root@qfedu.com ~]# cmd1='export LD_LIBRARY_PATH='
[root@qfedu.com ~]# cmd2='$LD_LIBRARY_PATH:/usr/local/lib'
[root@qfedu.com ~]# file="/etc/profile.d/python3_lib.sh"
[root@qfedu.com ~]# echo "${cmd1}${cmd2}" >$file
[root@qfedu.com ~]# path="l"
[root@qfedu.com ~]# file2="/etc/ld.so.conf.d/python3.conf"
[root@qfedu.com ~]# echo ${path} > $file2
接下来,执行如下命令使配置好的环境信息生效
[root@qfedu.com ~]# ldconfig
[root@qfedu.com ~]# source /etc/profile
三、 测试安装
- 测试 python3
[root@qfedu.com ~]# python3 -V
Python 3.7.6
[root@qfedu.com ~]#
假如上面显示的含有 Python3.7.6 就没问题了
- 测试 pip3
[root@qfedu.com ~]# pip3 -V
pip 20.0.2 from /usr/local/lib/python3.7/site-packages/pip (python 3.7)
输出的信息中的目录
/usr/local/lib/python3.7/site-packages/
是用于存放 安装的第三方模块的
四、 配置使用本地的源安装第三方模块
- 在当前用户的家目录下创建一个隐藏的目录
.pip
[root@qfedu.com ~]# mkdir ~/.pip
- 执行如下命令,以便写入国内的源:
[root@qfedu.com ~]# echo '[global]' >> ~/.pip/pip.conf
[root@qfedu.com ~]# c1="index-url=https://"
[root@qfedu.com ~]# c2="mirrors.aliyun.com/pypi/simple"
[root@qfedu.com ~]# echo "${c1}${c2}" >> ~/.pip/pip.conf
豆瓣源:
https://pypi.douban.com/simple/
阿里源:https://mirrors.aliyun.com/pypi/simple
- 测试配置正确行
可以安装一个增强版的解释器 ipython 用于测试后面也会用的这个模块
[root@qfedu.com ~]# pip3 install ipython
python 不支持执行系统命令
ipython 增强版本,支持执行系统命令
02:ipython的基本使用
一、安装
[root@qfedu.com ~]# pip3 install ipython
二、 基本使用
- 启动 Ipython
[root@qfedu.com ~]# ipython
- 特点
支持 Tab 键补全
连续按下两次 Tab 键即可

可以查看函数的源码
方法:??函数名
In [5]: ??open # 按下回车即可查看 open 函数的源码,输入 q 退出源码
可以执行系统命令
方法: !命令
In [6]: !vi hello.py
输入如下内容,并保存退出
执行脚本程序
In [8]: %run hello.py
hello
In [9]:
03:猜数游戏开始学习基本语法
一、 需求
假设目前需要写一个小的程序,程序的功能非常简单,就叫猜数游戏吧。
- 给用户一个提示信息,让其输入一个数字
- 接着拿用户输入的数字和 18 进行比较大小
- 等于 18 , 就输出 “相等”
- 小于 18,就输出 “小了”
- 大于 18,就输出 “大了”
二、 需求分析和分解技术点
- 程序和用户交互
思考一下,如何实现?
我们可以分析一下
给提示信息,让其输入一个数字
这里会用的和用户的交互,就是程序和用户的交互。
python 中 使用 input 函数实现
input("这里写提示信息, 必须使用引号引起来")
- 变量
那用户的输入可以使用一个变量接收
输入的都是字符类型是字符串
n = input("请输入一个数字")
2.1 变量命名潜规则:
- 不要以单下划线和双下划线开头;如:_user或 __user
- 变量命名要易读;如:user_name,而不是username
- 不用使用标准库中(内置)的模块名或者第三方的模块名
- 不要用这些 Python 内置的关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
2.2 如何理解 python 的变量赋值
在 python 中究竟该如何正确理解变量的赋值过程呢?
s = 'hello'
以上的变量赋值,应该说成把变量名 s 分配给 hello 这个对象更合理。
hello 这个对象会在内存中先被创建,之后再把变量名 s 分配给这个对象。
所以要理解 Python 中的变量赋值,应该始终先看等号右边。
对象是在右边先被创建或者被获取,在此之后左边的变量名才会被绑定到对象上,这就像是为对象贴上了一个标签。
一个对象可以有多个标签或者名字。
比如: 我们自己就有很多名字,身份证上的名字,网络昵称等。
请看下面的代码示例:
a = 1
b = a
a = 2
print(b) # b 会是 ?
a = 1 时如下图:
b = a 时如下图:
a = 2 时如下图:
上面的 b = a 我们称它为 传递引用,此时对象会拥有两个名称(标签) ,分别是 a 和 b
2.3 多元赋值
字符串、列表、元组的多元赋值统称为元祖解包
字符串以及后面讲的列表、元组都支持这种操作,也叫元组解包
规范写法是等号两边和逗号后面都有空格
In [9]: n1, n2 = 1, 2
In [10]: n1
Out[10]: 1
字符串的解包是按照字符分割的
In [11]: n2
Out[11]: 2
In [75]: s1, s2 = '12'
In [76]: s1
Out[76]: '1'
In [77]: s2
Out[77]: '2'
列表的解包是按照元素分割的
In [78]: num, s = [10, 'hello'] # 这个是列表, 后面会讲到
In [79]: num
Out[79]: 10
In [80]: s
Out[80]: 'hello'
好,至此,我们解决了使用变量来接收用户的输入,接下来就要解决判断的问题了。
那 python 中如何进行判断呢?
要判断需要使用判断条件
- python 中的判断条件
>>> n = 10
>>> n == 10 # 等于
True # 条件为真,则返回 True
>>> n != 10 # 不等于
False # 条件为假,则返回 False
>>> n > 10 # 大于
False
>>> n < 10 # 小于
False
>>> n >= 10 # 大于等于
True
>>> n <= 10 # 小于等于
True
>>>
那接下来,在 Ipython 中来实际操作一下
In [1]: n = input("请输入一个数字>>:")
请输入一个数字>>:10
In [2]: n == 10
Out[2]: False
In [3]:
会发现返回 False
在编程语言中 ,数据是有类型之分的。
input()接收到的任何数据都会成为 字符串类型(str),就是普通的字符串
而 我们等号 右边的10是整型(int)
- 数据类型
4.1 查看数据的类型,使用 type
In [3]: type(n) # 查看 input 接收到的数据类型
Out[3]: str
In [4]: type(10)
Out[4]: int
In [5]:
4.2 基本的数据类型
记住:整型、浮点型、字符串、布尔型、二进制
- 整型(int)
In [11]: type(0)
Out[11]: int
In [12]: type(-1)
Out[12]: int
In [13]: type(1)
Out[13]: int
- 浮点型(带小数点的小数)
In [17]: type(1.1)
Out[17]: float
In [18]: type(-0.1)
Out[18]: float
- 布尔型
In [19]: type(True)
Out[19]: bool
In [20]: type(False)
Out[20]: bool
- 字符串(str)
In [14]: type('10')
Out[14]: str
In [15]: type('hello')
Out[15]: str
In [16]: type('-1.1')
Out[16]: str
In [17]:
-
二进制(bytes)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fEfWkWZ2-1600591396517)(/root/Bilder/2020-09-20 14-11-32 的屏幕截图.png)]
In [18]: type(b'hello')
Out[18]: bytes
我们来验证一下 input 接收的数据的类型
In [36]: n = input("请输入一个数字>>:")
请输入一个数字>>:10
In [37]: n
Out[37]: '10'
In [38]: type(n)
Out[38]: str
要想把用户的输入(str)和整型(int)进行正确的比较大小,就需要把 字符串类型的数据转换整型。
这种把一个数据从一个类型转换为另外一个类型的操作叫类型装换
- 类型转换
- 转换为 int
In [21]: int('10')
Out[21]: 10
In [22]: int('-10')
Out[22]: -10
In [23]: int(1.9)
Out[23]: 1
- 转换为 float
In [25]: float(1)
Out[25]: 1.0
In [26]: float(-1)
Out[26]: -1.0
In [27]: float('1.1')
Out[27]: 1.1
- 转换为 str
In [28]: str(111)
Out[28]: '111'
In [29]: str(-111)
Out[29]: '-111'
In [30]: str(-11.1)
Out[30]: '-11.1'
In [31]: str(b'hello', encoding='utf-8')
Out[31]: 'hello'
注意:'utf-8' 用引号引起来
二进制转换字符串的时候,需要指定字符编码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SZ8t1E6A-1600591396520)(/root/Bilder/2020-09-20 14-24-56 的屏幕截图.png)]
- 转换为二进制
In [32]: bytes('千锋', encoding='utf-8')
Out[32]: b'\xe5\x8d\x83\xe9\x94\x8b'
In [58]: b = bytes('千锋', encoding='utf-8')
In [59]: b
Out[59]: b'\xe5\x8d\x83\xe9\x94\x8b'
In [60]: str(b, encoding='utf-8')
Out[60]: '千锋'
In [61]: s= str(b, encoding='utf-8')
In [62]: s
Out[62]: '千锋'
In [63]: type(s)
Out[63]: str
注意字符串转二进制,二进制转字符串,需要指定字符编码
- if 判断语句
python中,所有结构语句用:号开头
通过字符缩进判断结束
判断条件可以用在 if 判断语句中
语法结构是这样的:
- 语法一:
if 判断条件: # 冒号必须的
如果判断条件为真,执行这里的代码,这里的代码必须缩进4个空格
并且每一行代码的缩进要一致
示例:
In [39]: n = input("请输入一个数字>>:")
请输入一个数字>>:18
注意输入的是字符串类型,判断大小需要转换成整型
In [40]: n = int(n)
In [41]: if n == 18:
...: print("相等")
...:
相等
- 语法二:
if 判断条件:
如果判断条件为真,执行这里的代码
else: # 这里的冒号也是必须的
如果判断条件为假,执行这里的代码,这里的代码必须缩进4个空格
并且每一行代码的缩进都要一致
示例:
In [44]: if n == 10:
...: print("相等")
...: else:
...: print("不相等")
...:
不相等
- 语法三:
if 判断条件:
如果判断条件添加为真,执行这里的代码,这里的代码必须缩进4个空格
并且每一行代码的缩进要一致
elif 判断条件: # 这里同样需要加条件
如果判断条件添加为真,执行这里的代码,这里的代码必须缩进4个空格
并且每一行代码的缩进要一致
else: # 这里的冒号也是必须的
如果判断条件为假,执行这里的代码,这里的代码必须缩进4个空格
并且每一行代码的缩进都要一致
elif根据需求可以出现多个
示例:
In [51]: n = 20
In [52]: if n == 10:
...: print("相等")
...: elif n > 10:
...: print("大了")
...: else:
...: print("小了")
...:
大了
做实验,特结论
下面的代码会打印出几次 'ok'
一个,执行第一个就不往后执行了
if 1 == 1:
print("ok")
elif 2 == 2:
print("ok")
elif 3 == 3:
print("ok")
三、Python 程序
在生产中,通常我们会把程序的代码写的一个文件种,这个文件就成为 Python 的一个程序文件,文件名一般都是以 .py 为结尾,有时候也成为 一个 python 的程序。
使用 vi 编辑器,来把我们这个猜数游戏的小程序写一下吧
#!/usr/bin/env python3
# file name hello.py
print("猜数游戏开始")
n = input("请输入一个数字")
n = int(n)
if n == 18:
print("猜对了")
elif n > 18:
print("大了")
else:
print("小了")
第一行不是注释,和 shell 脚本一样,是在声明这个脚本默认使用的解释器
执行 python 程序
[root@qfedu.com ~]# ./hello.py
猜数游戏开始
请输入一个数字8
小了
四、 while 循环
语法:
while 条件表达式:
条件表达示为真,就执行这里的代码,必须缩进 4 个空格
多行代码保持缩进一致
条件表达式可以是:
True# 布尔值的 True1 < 10# 凡是在 if 语句中使用的判断表达示,这里都可以使用
猜数游戏优化版本
#!/usr/bin/env python3
print("猜数游戏开始")
while True:
n = input("请输入一个数字")
# 如果输入空,就重新开始新一轮的循环
if not n:
continue
# 如果输入 q 就是跳出循环
if n == 'q':
break
n = int(n)
if n == 18:
print("猜对了")
elif n > 18:
print("大了")
else:
print("小了")
# 退出循环后,程序继续运行下面的代码
exit("退出程序..")
[root@sun mnt]# python3 sun.py
>>:q
退出程序
python3编译可以exit
ipython里面不支持
五、函数的定义和调用
- 函数的定义
def 函数名():
"""函数的说明,主要是说明一下函数的主要功能,这是可选的"""
函数体,就是代码
缩进 4 个空格,多行缩进保持一致
函数名的规则和变量名的命名规则一致
- 函数的调用
调用方式:
函数名()
python 属于解释性语言,就是代码需要读一行,解释器解释一行。
因此,函数就像是 定义一个变量,必须先定义函数,才能调用函数。
- 示例
def foo():
print("我是函数体,只有在调用函数时,这里的代码才会被执行")
foo()
执行后会输出:
我是函数体,只有在调用函数时,这里的代码才会被执行
那我们现在可以把之前写的猜数游戏,编写函数
#!/usr/bin/env python3
def guess_number():
"""输入一个数字,和18 比较大小"""
print("猜数游戏开始")
while True:
n = input("请输入一个数字")
# 如果输入空,就重新开始新一轮的循环
if not n:
continue
# 如果输入 q 就是跳出循环
if n == 'q':
break
n = int(n)
if n == 18:
print("猜对了")
elif n > 18:
print("大了")
else:
print("小了")
# 调用函数
guess_number()
exit("退出程序..")
六、今日作业:
编写一个小程序,实现如下效果
用户输入一个数字,返回对应的服务名称,加上没有对应的服务,就返回未知的服务。
输入q 退出
python的两个条件同时满足用 and 连接
python的两个条件满足一个用 or 连接
其他写法不支持
[root@qfedu.com ~]# python3 search_server.py
常用端口-->查询程序
请输入一个常用的服务默认端口号:80
HTTP 服务
请输入一个常用的服务默认端口号:22
SSHD 服务
请输入一个常用的服务默认端口号:21
FTP 服务
请输入一个常用的服务默认端口号:3306
Mysql 服务
请输入一个常用的服务默认端口号:9080
未知服务
请输入一个常用的服务默认端口号:
常见服务的端口号:
ftp 20、21
ssh 22
Telnet 23
DNS 53
HTTP、Niginx 80
NTP 123/udp
HTTPS 443
rsyslog 514
NFS 2049/tcp
mysql 3306
redis 6379
Weblogic 7001
tomcat 8080(8005、8009)
php 9000
zabbix 10050 10051
while True:
n = input("请输入要查询的端口号>>:")
if not n:
continue
if n == 'q':
break
n = int(n)
if n == 20 or n == 21:
print("ftp服务")
elif n == 22:
print("ssh服务")
elif n == 23:
print("telnet服务")
elif n == 53:
print("DNS服务")
elif n == 80:
print("HTTP、Niginx服务")
elif n == 443:
print("HTTPS服务")
elif n == 514:
print("rsyslog服务")
elif n == 2049:
print("NFS服务")
elif n == 3306:
print("Mysql服务")
elif n == 6379:
print("Redis服务")
elif n == 7001:
print("weblogc服务")
elif n == 8080 or n == 8005 or n == 8009:
print("tomcat服务")
elif n == 9000:
print("php服务")
elif n == 10050 or n == 10051:
print("zabbix服务")
else:
print("未知服务")
04:VSCode的部署和使用
一、下载安装
- 打开浏览器
- 输入百度的网址并搜索
vscode
- 打开官网
- 点击
- 按照提示安装即可
也可以右键 打开终端,输入如下命令进行安装
[root@qfedu.com ~] sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
[root@qfedu.com ~]# sh -c 'echo -e "[code]\nname=Visual Studio Code\nbaseurl=https://packages.microsoft.com\
/yumrepos/vscode\nenabled=1\ngpgcheck=1\ngpgkey=\
https://packages.microsoft.com/keys/microsoft.asc" > /etc/yum.repos.d/vscode.repo'
[root@qfedu.com ~]# yum check-update
[root@qfedu.com ~]# yum install code
- 添加桌面快捷方式
在终端中输入如下命令
[root@qfedu.com ~]# cp /usr/share/applications/code.desktop ~/桌面/
或者
[root@qfedu.com ~]# cp /usr/share/applications/code.desktop ~/Desktop/
- 接下来双击桌面快捷方式,再点击
标记为信任
- 完成
二、安装插件
-
双击桌面图标打开软件
-
打开商店,安装中文简体插件
- 重启软件生效
汉化完成
- 安装文档图标
- 接下来会自动提示设置图标主题
三、基本设置
打开配置文件方式
添加如下内容到 settings.json 配置文件中,并按下 Control + s 保存
{
"editor.fontSize": 30,
"debug.console.fontSize": 30,
"markdown.preview.fontSize": 26,
"terminal.integrated.fontSize": 30,
// 编辑的文件 每 1 秒自动保存一次
"files.autoSave": "afterDelay"
}
完成后的样子
鼠标悬停到某一行,会自动显示当前配置项的意义
四、创建一个 python 文件
创建的文件需要有对应的扩展名,有了对应的扩展名,VSCode 就会自动识别,并提示安装对应的插件进行支持。
比如下面创建一个 python 的文件的步骤
- 可以在当前用户的家目录下,创建一个文件夹
python_code
[root@qfedu.com ~]# mkdir python_code
- 接下来在 VSCode 中打开这个文件夹
目前打开的这个目录就是一个项目的主目录,项目所有的代码都应该放到这个目录下,可以在这个目录下再创建其他目录(稍后介绍)。
重要:在VSCode 看来,这个目录就是
当前的工作目录,假设在 vscode 中执行的代码的相对路径,就是相对于这个目录的,而不会是这个目录下面的其他目录。
- 在项目目录中创建目录和文件
鼠标点击项目目录会出现创建文档的图标
- 点击创建的目录,选择创建文件
- 安装对应的插件
VSCode 会自动提示安装对应的插件
- 配置默认的 python 解释器
vscode 默认选择的python 解释器是 python2.7 ,我们需要的是 python3
- 接下来会提示安装用于 python 语法检测的插件
pylint
这个插件会突出显示了Python源代码中的语法和风格问题,通常可以帮助您识别和纠正细微的编程错误或可能导致错误的非常规编码实践。
例如,检测未使用或未定义的变量的使用,对未定义函数的调用,缺少括号以及甚至更细微的问题,
例如尝试重新定义内置类型或函数。
因此,与Formatting不同,因为这个插件分析代码的运行方式并检测错误,而Formatting仅重组代码的显示方式。
五、编辑代码并运行
运行的输出结果
六、 安装 Code Runner
刚刚的执行方式有点小缺点,当你重复执行这个文件的时候,之前的输出在终端中不能清除,这可能会影响观看。使用 code runner 插件可以解决,并且它支持多重语言。
- 安装 Code Runner
- 配置 Run Code
再次打开配置文件 settings.json 文件添加如下内容,并按下 Control + s 保存
"code-runner.clearPreviousOutput": true,
"code-runner.runInTerminal": true,
// 每次运行文件之前,保存当前文件
"code-runner.saveFileBeforeRun": true,
// 默认的语言
"code-runner.defaultLanguage": "python",
// 每次运行文件前 保存所有的文件
"code-runner.saveAllFilesBeforeRun": true,
// 设置 phthon3 解释器路径
"code-runner.executorMap": {
"python": "/usr/local/bin/python3"
}
七、最终的配置文件
{
"workbench.iconTheme": "vscode-icons",
"editor.fontSize": 30,
"debug.console.fontSize": 30,
"markdown.preview.fontSize": 26,
"terminal.integrated.fontSize": 30,
// 编辑的文件 每 1 秒自动保存一次
"files.autoSave": "afterDelay",
"code-runner.clearPreviousOutput": true,
"code-runner.runInTerminal": true,
"code-runner.saveFileBeforeRun": true,
"code-runner.defaultLanguage": "python",
"code-runner.saveAllFilesBeforeRun": true,
// set python path
"code-runner.executorMap": {
"python": "/usr/local/bin/python3"
}
}
八、部分快捷键
快速添加注释
鼠标点击某一行 ,同时按下
Ctrl和?/, 重复按下取消注释
快速复制一行
通用鼠标选中需要复制的行,之后先按住
Ctrl和Shift不放,再按下方向键,会向下自动复制被选中的内容。
05:字符串和数据的切片
两行代码下载网站数据
一、 创建
s1 = 'lenovo'
s2 = "QF"
s3 = """hello lenovo"""
s4 = '''hello 千锋云计算'''
s5 = """hello shark """
s6 = '''hello world'''
二、简单使用
\转义符
testimony = 'This shirt doesn\'t fit me'
words = 'hello \nshark'
+拼接
In [1]: file_name= "成功的21个信念"
In [2]: suffix = '.txt'
In [3]: file_name = file_name + suffix
In [4]: file_name
Out[4]: '成功的21个信念.txt'
拼接只能是 字符串和字符串进行操作,不可以用 字符串和 一个非字符串类型的对象相加
In [5]: '西瓜甜' + 1 ## 这会报错的
*复制
python中支持字符串的乘法复制
In [6]: "-" * 10
Out[6]: '----------'
In [7]: print('*' * 10)
**********
三、取值和切片
- 字符串 是 Python 中的一个 序列类型 的数据结构
- 存放的数据,在其内是有序的。
s1 = "shark"
序列类型的特点
-
序列里的每个数据被称为序列的一个元素
-
元素在序列里都是有个自己的位置的,这个位置被称为索引或
者叫偏移量,也有叫下标的, 从
0开始,从左到右依次递增 -
序列中的每一个元素可以通过这个元素的索引来获取到
-
获取到序列类型数据中的多个元素需要用切片的操作来获取
- 通过索引取值,获取单个元素
In [10]: s1 = "shark"
In [11]: s1[0]
Out[11]: 's'
In [12]: s1[-1]
Out[12]: 'k'
In [13]: s1[3]
Out[13]: 'r'
- 切片,获取多个元素
str[从索引号开始取:到第几个结束:每隔n-1个取一次]
3.1 一般操作
# 使用切片获取多个元素
In [15]: s1[0:3]
Out[15]: 'sha'
# 起始和结尾的索引号可以省略
In [16]: s1[:3]
Out[16]: 'sha'
In [17]: s1[1:]
Out[17]: 'hark'
# 索引可以使用 负数
In [18]: s1[2:-1]
Out[18]: 'ar'
In [19]:
去掉最后一个字符
In [13]: s1[:-1]
Out[13]: 'shar'
去掉第一个字符
In [14]: s1[1:]
Out[14]: 'hark'
下面这样的操作,臣妾做不到
>>> s1[-1:-3]
''
>>>
因为默认的切片是从左向右开始操作, 索引号
-1的右边没有任何索引号了
-3在-1的左边
3.2 使用步长
- 步长就是每数几个取一个的意思
- 步长是正数时,是从左向右开始操作
- 步长是负数时,是从右向左操作
In [19]: s2 = 'abcdefg'
In [20]: s2[::2]
Out[20]: 'aceg'
In [21]: s2[::-1]
Out[21]: 'gfedcba'
In [22]: s2[::-2]
Out[22]: 'geca'
四、字符串方法
- 统计序列数据的长度
就是获取一个序列数据的元素个数,这个适用于所有的序列类型的数据,比如 字符串、列表、元组。
# 获取字符串的长度,包含空格和换行符
In [25]: s3 = "a \n\t"
In [26]: len(s3)
Out[26]: 4
\n是一个换行符
\t是一个 Tab 键
- in 成员判断
In [39]: line = 'Size: 8192 MB'
In [40]: if 'Size' in line:
...: print(line)
...:
Size: 8192 MB
注意: 空的字符串总是被视为任何其他字符串的子串,因此
"" in "abc"将返回True。
- strip() 去除字符串两端的空白字符(空格、
\t、\n)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qvJHFtpc-1600602992531)(/root/Bilder/2020-09-16 11-45-03 的屏幕截图.png)]
Out[41]: line = ' Size: 8192 MB'
In [42]: line.strip()
Out[42]: 'Size: 8192 MB'
字符串两边的任意都可以擦除(传递要擦除的参数)
In [31]: s = "sun"
In [33]: s.strip('n')
Out[33]: 'su'
In [34]: s.strip('sn')
Out[34]: 'u'
In [35]: s.strip('un')
Out[35]: 's'
- split() 分割
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0U5Vkgbv-1600602992535)(/root/Bilder/2020-09-16 11-46-10 的屏幕截图.png)]
默认使用空白字符作为分隔符(空格、
\t、\n)
和 shell 中的 awk 一样道理
In [47]: line
Out[47]: ' Size: 8192 MB'
In [48]: line.split()
Out[48]: ['Size:', '8192', 'MB']
In [49]: s
Out[49]: '\tab\n'
In [50]: s.split()
Out[50]: ['ab']
可以指定分隔符
In [51]: line.split(':')
Out[51]: [' Size', ' 8192 MB']
指定多个分割符号,空格放在后面
In [52]: line.split(': ')
Out[52]: [' Size', '8192 MB']
strip()返回的是字符串,所以可以连续操作
In [73]: line.strip().split(': ')
Out[73]: ['Size', '8192 MB']
In [74]: line
Out[74]: ' Size: 8192 MB'
In [75]: k, v = line.strip().split(': ')
In [76]: k
Out[76]: 'Size'
In [77]: v
Out[77]: '8192 MB'
- replace() 替换
In [65]: line = ' <strong>10、命运在自己手里,而不是在别人的嘴里</strong></p>'
In [66]: line.strip() ## 先去除两端空白字符
Out[66]: '<strong>10、命运在自己手里,而不是在别人的嘴里</strong></p>'
In [67]: line.strip().replace('strong>', '') ## 将字符串 strong> 替换为空
Out[67]: '<10、命运在自己手里,而不是在别人的嘴里</</p>'
In [68]: line.strip().replace('strong>', '')[1:-6]
Out[68]: '10、命运在自己手里,而不是在别人的嘴里'
In [36]: s
Out[36]: 'sun'
In [37]: s.replace('s','ji')
Out[37]: 'jiu
字符串.replace('查找的内容','替换的内容')
- startswith() 判断字符串以什么为开头
In [85]: line = 'Locator: DIMM_A2'
In [86]: line.startswith("Locator:")
Out[86]: True
- endswith() 判断字符串以什么为结尾
In [87]: line = 'Size: 8192 MB'
In [88]: line.endswith('MB')
Out[88]: True
五、 字符串的判断(扩展自修)
In [1]: s = '123'
In [2]: s.isdigit() # 判断是否是纯数字
Out[2]: True
In [3]: s1 = '123adb'
In [4]: s1.isalnum() # 判断是否是数字和字母
Out[4]: True
In [5]: s2 = 'adb'
In [6]: s2.isalpha() # 判断是否是纯字母
Out[6]: True
In [7]: s2.encode() # 转换为二进制 bytes 类型
Out[7]: b'adb'
In [8]: s4 = "云计算"
In [9]: s4.encode() # 转换为二进制 bytes 类型,默认编码 utf-8
Out[9]: b'\xe4\xba\x91\xe8\xae\xa1\xe7\xae\x97'
In [16]: b = s4.encode()
In [17]: b.hex() # bytes 转换成 16 进制
Out[17]: 'e4ba91e8aea1e7ae97'
In [18]: b.decode() # bytes 转换成 str,默认编码 utf-8
Out[18]: '云计算'
06:列表、元组
两行代码下载网站数据
一、列表
- 列表的特性介绍
列表和字符串一样也是序列类型的数据
列表内的元素直接用英文的逗号隔开,元素是可变的,所以列表是可变的数据类型,而字符串不是。
列表中的元素可以是 Python 中的任何类型的数据对象
如:字符串、列表、元组、字典、集合、函数
- 列表中的具有相同值的元素允许出现多次
[1, 2, 1, 1, 1, 1, 3, 3, 2]
- 创建列表
- 嵌套的列表
列表中可包含 python 中任何类型的元素(对象),当然也可以包括一个或多个列表
li = [['one', 'two', 'three'], [1, 2, 3]]
- 列表的基本操作
4.1 取值和就地修改
没有嵌套的列表取值
In [90]: l2 = ['insert', 'append', 'remove', 'pop', 'sort']
In [91]: l2[0]
Out[91]: 'insert'
In [92]: l2[-1]
Out[92]: 'sort'
4.2 嵌套的列表取值
In [93]: l3 = [['one', 'two', 'three'], [1, 2, 3]]
In [94]: l3[0]
Out[94]: ['one', 'two', 'three']
In [95]: ll = l3[0]
In [96]: ll[1]
Out[96]: 'two'
In [97]: l3[0][1]
Out[97]: 'two'
4.3 就地修改
可以通过索引直接修改索引对应位置的数据
In [113]: li
Out[113]: ['qfedu.com', 1314, '521']
In [114]: li[0] = '千锋教育'
In [115]: li
Out[115]: ['千锋教育', 1314, '521']
In [79]: li[1:]
Out[79]: [1314, '521']
In [80]: li[1:] = ['jiji']
列表重新赋值,是列表格式
li[1:] = ''
删除列表的值
4.3 切片
同字符串的切片一样,详情参考字符串教程中的切片
几点简单示例
In [100]: line = 'Size: 8192 MB\n'
In [66]: line.split('\n')[0].split(': ')
Out[66]: ['Size', '8192 MB']
可以指定连续的多个分隔符
In [101]: line.split('\n')
Out[101]: ['Size: 8192 MB', '']
In [102]: l5 = line.split('\n')
In [103]: l5[:-1]
Out[103]: ['Size: 8192 MB']
In [104]: line.split('\n')[:-1] # 可以直接连续操作
Out[104]: ['Size: 8192 MB']
去掉最后一个
4.4 必会方法
len() 适合字符串、列表、元组
方法是一个内置函数,可以统计序列类型的数据结构的长度。
In [108]: li = ['qfedu.com', 1314, '521']
In [109]: len(li)
Out[109]: 3
in
判断元素是否存在于列表中。
适合字符串、列表、元组
In [3]: li = ['qfedu.com', 1314, '521']
In [4]: '521' in li
Out[4]: True
In [5]: 1314 in li
Out[5]: True
In [6]: if 'qfedu.com' in li:
...: print('ok')
...:
ok
In [7]:
append() 真正可以改变列表
每次只能在列表最后插入一个元素
没有返回值,不能被变量接收
向列表的最后位置,添加一个元素,只接收一个参数。
In [7]: li.append(521)
In [8]: li
Out[8]: ['qfedu.com', 1314, '521', 521]
insert()
向原列表的指定位置插入一个元素,接收两个参数,
第一个是索引号,第二个是要插入的元素。
没有返回值,不能被变量接收
In [9]: li.insert(0, 521)
In [10]: li
Out[10]: [521, 'qfedu.com', 1314, '521', 521]
remove()
移除列表中某个指定的元素,,并且假如有多个相同值的元素存在,每次只会移除排在最前面的那个元素
没有返回值,不能被变量接收
In [14]: li.remove(521)
In [15]: li
Out[15]: ['qfedu.com', 1314, '521', 521, 'qf', 'yangge']
pop()
默认删除最后一个
从原列表中删除一个元素,并且把这个元素返回,有返回,就可以用变量接收
接收零个或一个参数,参数是偏移量,int 类型。
# 删除列表中的最后一个元素
In [16]: name = li.pop()
In [17]: name
Out[17]: 'yangge'
In [18]: li
Out[18]: ['qfedu.com', 1314, '521', 521, 'qf']
# 删除列表中第二个索引号对应的元素,并且返回这个元素,用变量名`n` 接收。
In [19]: n = li.pop(-2)
In [20]: n
Out[20]: 521
In [21]: li
Out[21]: ['qfedu.com', 1314, '521', 'qf']
- 循环列表
5.1 for 循环语法
for 变量 in 可迭代对象:
循环体的代码,必须缩进 4 个空格
多行代码缩进要一致
可迭代对象 可以理解为可以被 for 循环的数据。
比如: 字符串、列表、元组、文件对象(后面讲)等。
for-list.py 文件内容如下:
li = ['qfedu.com', 1314, '521', 'qf']
for item in li:
print(item)
执行
python3 for-list.py
输出结果
qfedu.com
1314
521
qf
二、元组
- 元组特点
- 元组和列表一样,也是一种序列类型的数据。
- 唯一的不同是,元组是相对不可变的。
- 高效创建元组
t1 = () # 创建 空 元素的元组
单一元素元组怎么搞?
有元素的元组实际上是使用英文的逗号创建的
In [168]: n = (3)
In [169]: t = 3,
In [170]: type(n)
Out[170]: int
In [171]: type(t)
Out[171]: tuple
创建非空元素的元组是用
逗号,而不是用小括号
- 转换
tuple()
可以对其他序列类型的数据转换为元组。
In [173]: s1 = 'car'
In [174]: li = [1,2,3]
In [175]: tuple(s1)
Out[175]: ('c', 'a', 'r')
In [176]: tuple(li)
Out[176]: (1, 2, 3)
In [177]: dl = [1,2,3,['a','b']]
In [178]: tuple(dl)
Out[178]: (1, 2, 3, ['a', 'b'])
- 元组的取值
元组也是序列类型的数据,取值和切片和列表的操作一样
In [33]: t1 = (1, 2, 3, ['a', 'b'])
In [34]: t1[3][0]=0
In [35]: t1
Out[35]: (1, 2, 3, [0, 'b'])
- 元组的方法
- count() 统计一个元素在元组内出现的次数
- index()返回一个元素在元组内的索引
In [117]: t1 = (1,'hello', ['a', 'b'])
In [4]: t1.count(1)
Out[4]: 1
In [5]: t1.index('hello')
Out[5]: 1
In [118]: t1. # 按 Tab 键
count index # 可以看出没有可以改变其自身的方法
- 元组的相对不可变
元组本身是不可变的,就是元组内的元素是不可变的,一旦创建一个元组,这个元组内的元素个数和数据都是固定的了
相对不可变的意思是,元组内的元素自身是可变的数据对象,就可以通过修改这个可变元素,来间接改变元组的样子。
说下面的示例之前,先说一个内置函数 id(), 这个函数可以返回python 中一个对象的内存地址(id 号)
In [119]: id('hello')
Out[119]: 4478905344
In [120]: id(t1)
Out[120]: 4479260568
In [121]: id(t1[-1])
Out[121]: 4478661192
接下来就来验证元组是相对不可变的
假设我想把上个示例中的元组 t1 中的最后一个元素,修改为 ['a']
In [122]: t1[-1]
Out[122]: ['a', 'b']
In [123]: t1[-1] = ['a']
-----------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-123-9d326d207854> in <module>
----> 1 t1[-1] = ['a']
TypeError: 'tuple' object does not support item assignment
可以看到,我们不能通过元组的索引就地复制为 ['a']
但是,元组中的最后一个元素是列表,列表中的元素是可以改变的,所以可以直接操作列表本身就行
In [129]: t1 = (1,'hello', ['a', 'b'])
In [130]: t1[-1]
Out[130]: ['a', 'b']
In [131]: id(t1[-1]) # 改变前的 id
Out[131]: 4473983368
In [132]: t1[-1].pop()
Out[132]: 'b'
In [133]: t1
Out[133]: (1, 'hello', ['a'])
In [134]: id(t1[-1]) # 改变后的 id
Out[134]: 4473983368
- for 循环元组
for-tuple.py 文件内容
t = ('qfedu.com', 1314, 521)
for item in t:
print(item)
执行
python3 for-tuple.py
输出结果
qfedu.com
1314
521
- 元组的优点
给我一个理由
- 占用内存空间小
- 元组内的值不会被意外的修改
- 可作为字典的键
- 函数的参数是以元组形式传递的
07:获取服务器信息
获取 CPU 信息
先看这个: https://www.jianshu.com/p/150c13ec54d4
二、Python 代码
1 获取 CPU 信息
获取物理CPU型号
grep 'model name' /proc/cpuinfo |sort| uniq |wc -l
In [1]: import subprocess
In [2]: cmd_cpu_name = "grep 'model name' /proc/cpuinfo | uniq"
In [3]: subprocess.getoutput(cmd_cpu_name)
Out[3]: 'model name\t: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz'
In [4]: cpu_name = subprocess.getoutput(cmd_cpu_name).split(": ")[1]
In [5]: cpu_name
Out[5]: 'Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz'
查看物理CPU颗数
grep 'physical id' /proc/cpuinfo | sort -u | wc -l
In [8]: cmd_cpu_pyc = "grep 'physical id' /proc/cpuinfo | sort -u | wc -l"
In [9]: subprocess.getoutput(cmd_cpu_pyc)
Out[9]: '1'
In [10]: cpu_pyc = subprocess.getoutput(cmd_cpu_pyc)
In [11]: cpu_pyc = int(cpu_pyc)
查看每颗物理 CPU 的核心数
grep 'cpu cores' /proc/cpuinfo | uniq # 每颗 CPU 的核心数,不是总核心数
In [13]: subprocess.getoutput("grep 'cpu cores' /proc/cpuinfo | uniq")
Out[13]: 'cpu cores\t: 1'
In [14]: cpu_cores_each = subprocess.getoutput("grep 'cpu cores' /proc/cpuinfo | uniq")
In [15]: cpu_cores_each = cpu_cores_each.split(": ")[1]
In [16]: cpu_cores_each = int(cpu_cores_each)
In [17]: cpu_cores_each
Out[17]: 1
2 获取 IP 地址信息
In [2]: from subprocess import getoutput
In [3]: ret = getoutput("ip a")
In [4]: ips = []
...: for line in ret.splitlines():
...: if 'inet ' in line and '127.0.0.1' not in line:
...: _,ip,*_,net_name = line.split()
...: ips.append([net_name, ip])
...:
In [7]: ips
Out[7]: [['ens33', '10.11.59.169/24'], ['ens37', '192.168.8.128/24']]
3 获取硬盘信息
In [8]: from subprocess import getoutput
In [9]: ret = getoutput("lsblk")
In [10]: print(ret)
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 30G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 29G 0 part
├─centos-root 253:0 0 27G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 5G 0 disk
sr0 11:0 1 4.3G 0 rom
In [11]: disks = []
...: for line in ret.splitlines():
...: if 'disk' in line:
...: dev_name, *_, size = line.split()
...: disks.append([dev_name, size])
...:
In [12]: disks
Out[12]: [['sda', 'disk'], ['sdb', 'disk']]
08:字典、集合
第3天服务器信息清洗
一、 字典
- 字典特性介绍
字典在 Python 中极为重要,是属于映射类型的数据结构。
字典有一对儿大括号组成{},
字典内的元素都是成对儿出现的{"a": 1}, 他们用英文的冒号(:)隔开, 左边叫做键(key),右边的叫值(value), 通常叫做键值对儿。
每个元素用英文的逗号 (,) 隔开{"a": 1, "b": 2}
- 创建字典
创建字典可以使用一对儿大括号, 也可以使用
dict()dict (序列元素:列表、元组) 创建字典
列表和元组里面只能
序列类型元素成对出现
>>> d1 = {
}
>>> type(d1)
<class 'dict'>
>>> d2 = dict()
>>> type(d2)
<class 'dict'>
>>> d3 = {
"size": 8096}
>>>
d3 = {
"size": 8096, "name": "sunlizhen"}
字典的规范写法,冒号和逗号后面加空格
- 字典的 key 和 value
3.1 字典的 key
在一个字典中,key 不允许有重复
>>> {
"a": 1, "a": 10}
{
'a': 10}
并且必须是 python 中不可变的数据类型
如:
整型 浮点型 布尔值 字符串 元组
>>> {
1: "整型", 1.1: "浮点型", False: "布尔值", "abc": "字符串", (1,2): "元组" }
{
1: '整型', 1.1: '浮点型', False: '布尔值', 'abc': '字符串', (1, 2): '元组'}
>>>
最常用的是字符串,因为比较容易有语意,易读
>>> {
"user": "shark", "age": 18}
{
'user': 'shark', 'age': 18}
>>>
小扩展
注意: python 中认为 1 和 True, 0 和 False 的值是相等的
但不是一个对象,因为它们的 id 不同
>>> 1 == True
True
>>> False == 0
True
>>> 1 is True
False
>>> id(1);id(True)
4551162464
4550779216
>>> 0 is False
False
这种在ipython中打不出来
所以你会看到如下的现象
>>> {
1: "整型", True: "布尔型"}
{
1: '布尔型'}
>>> {
True: "布尔型", 1: "整型"}
{
True: '整型'}
>>>
3.2 字典中的 value
字典中的 value 可以是 Python 中任意的一个数据对象:
- 整型、浮点型、布尔值、字符串、列表、元组、字典
>>> {
'port': 3306, "height": 1.81, 'stat': True, "name": "dbserver"}
{
'port': 3306, 'height': 1.81, 'stat': True, 'name': 'dbserver'}
>>> {
"mysql-01": {
... "cpu": 4,
... "memroy": [4096,4096]
... }
... }
{
'mysql-01': {
'cpu': 4, 'memroy': [4096, 4096]}}
>>>
- 函数对象等
>>> def foo():
... print("hello")
...
>>> {
"1": foo}
{
'1': <function foo at 0x10f5b9e18>}
- 获取字典中 key 和 value
4.1 检查字典中是否存在某个 key
可以使用
in关键字
In [39]: dic_map = {
...: "Manufacturer": "manufacturer",
...: "Product Name": "pod_name",
...: "Serial Number": "sn"
...: }
In [40]: line = '\tManufacturer: Alibaba Cloud'
In [41]: line = line.strip()
In [42]: k, v = line.split(": ")
In [43]: k
Out[43]: 'Manufacturer'
In [44]: k in dic_map
Out[44]: True
In [45]:
4.2 使用 [] 获取指定 key 的 value
In [48]: dic_map['Manufacturer']
Out[48]: 'manufacturer
这种方式是非常的高效做法,推荐使用。
但是有个问题,假设获取字典中不存在的 key 的值,会报错的
4.3 使用字典的 get() 方法
>>> dic = {
'a': 1, 'b': 2}
>>> dic.get('a') # 获取到 'a' 对应的值(value)
1
>>>
>>> dic.get('c') # key 不存在字典中,则返回 None
>>>
>>> v = dic.get('c')
>>> type(v)
<class 'NoneType'>
>>> dic.get('c', '5') # key 不存在,返回指定的值
'5'
>>>
4.4 循环字典的 key 和 value
字典对象的
items()方法会获取到字典的 key 和 value, 它是一个可迭代对象
In [49]: dic_map.values()
Out[49]: dict_values(['manufacturer', 'pod_name', 'sn'])
for i in dic_map
In [50]: for k, v in dic_map.items():
...: print(k, v)
Manufacturer manufacturer
Product Name pod_name
Serial Number sn
In [51]:
4.5 向字典中添加键值对
[]方式
>>> info = {
}
>>> info["cpu"] = 4
>>> info["memory"] = [4096, 4096]
>>> info
{
'cpu': 4, 'memory': [4096, 4096]}
>>>
生产示例:
字段映射
In [51]: dic_map
Out[51]:
{
'Manufacturer': 'manufacturer',
'Product Name': 'pod_name',
'Serial Number': 'sn'}
In [52]: li = ['Manufacturer: Alibaba Cloud',
...: 'Product Name: Alibaba Cloud ECS',
...: 'Version: pc-i440fx-2.1',
...: 'Serial Number: 0f7e3d86-7742-4612-9f93-e3a9e4754157']
In [53]: prod_info = {
}
In [54]: for line in li:
...: k, v = line.split(": ")
...: if k in dic_map:
...: prod_info[dic_map[k]] = v # 获取的一个字典的值作为另一个字典的键
...:
In [55]: prod_info
Out[55]:
{
'manufacturer': 'Alibaba Cloud',
'pod_name': 'Alibaba Cloud ECS',
'sn': '0f7e3d86-7742-4612-9f93-e3a9e4754157'}
update方式
>>> disk = {
"disk": [10240]}
>>> info.update(disk)
>>> info
{
'cpu': 4, 'memory': [4096, 4096], 'disk': [10240]}
>>>
4.6 字典的编程之道:用字典实现 case 语句
程序源码
data = {
"0": "zero",
"1": "one",
"2": "two",
}
while True:
arg = input(">>:")
v = data.get(arg, "nothing")
print(v)
执行程序
$ python3 hello.py
>>:0
zero
>>:1
one
>>:9
nothing
>>:
思考题,如何给上例添加 输入 ‘q’ 退出
while True:
…: su = input(“>>:”)
…: v = data.get(su, “love”)
…: if su == ‘q’:
…: break
…: else:
…: print(v)
二、 集合
1 集合特性介绍
在 python 中集合看起来像是只有 key 的字典
{
'disk','cpu','memory','motherboard'}
在 python 解释器中表现为 set
集合内的元素不允许重复
- 高效创建集合和转换
set()
>>> s1 = set()
>>> type(s1)
<class 'set'>
>>>
转换
In [99]: set('disk')
Out[99]: {
'd', 'i', 'k', 's'}
In [100]:
Out[100]: {
'cpu', 'disk', 'memory'}
In [101]: set(('disk','cpu','memory'))
Out[101]: {
'cpu', 'disk', 'memory'}
In [102]: set({
'disk': '560G','cpu': '4'})
Out[102]: {
'cpu', 'disk'}
- 集合运算
&交集
获取两个集合都有的元素
In [55]: s1 = {
"192.168.1.51", "192.168.1.45"}
In [56]: s2 = {
"192.168.1.51", "192.168.1.78"}
In [57]: s1 & s2
Out[57]: {
'192.168.1.51'}
|并集
把两个集合的元素合并在一起,产生一个新的集合
In [60]: s1 | s2
Out[60]: {
'192.168.1.45', '192.168.1.51', '192.168.1.78'}
-差集
返回第一个集合中独有的元素。
就是只保留在第一个集合中出现并且不在第二个集合中出现的元素。
In [55]: s1 = {
"192.168.1.51", "192.168.1.45"}
In [56]: s2 = {
"192.168.1.55", "192.168.1.51"}
In [61]: s1 - s2
Out[61]: {
'192.168.1.45'}
In [62]: s2 - s1
Out[62]: {
'192.168.1.78'}
-
^异或运算获取两个集合的分别独有的元素,组合为一个新的集合对象。
In [55]: s1 = {
"192.168.1.51", "192.168.1.45"}
In [56]: s2 = {
"192.168.1.55", "192.168.1.51"}
In [63]: s1 ^ s2
Out[63]: {
'192.168.1.45', '192.168.1.78'}
09:函数、模块、包
第3天服务器信息清洗
一、 有参函数
python 中,函数的参数是在小括号中定义和传递的
>>> def foo(x, y): # 定义参数
... print("x 的值是:",x)
... print("y 的值是:", y)
...
>>> foo(2,3) # 传递参数,简称传参
x 的值是: 2
y 的值是: 3
>>>
形参是定义函数的时候的概念:
包括位置参数和默认参数
在定义参数的时候,还可以给它定义一个默认的值,默认值的参数我们叫它默认参数
默认参数在调用函数传参时候,可以不传,使用的是定义的默认值, 也可以传,传了,就使用传递的值
变量之间的逗号只是用与隔离变量和变量,变量和字符串,输出的时候不会显示
>>> def conn_mysql(user,port=3306):
... print(user, port)
...
>>> conn_mysql("root")
root 3306
>>> conn_mysql("root", 3307)
root 3307
>>>
当然在调用函数的时候,我们还可以指定某个值给具体的某个参数
定义函数的时候可以在给变量设定默认值
调用函数的时候也可以给变量制定参数
>>> conn_mysql(port=3308, user="sahrk")
sahrk 3308
>>>
二、 函数的返回值
函数中处理的数据,只有使用
return关键字进行返回,函数外的代码才能使用这个数据
函数可以返回任意数量的任意 Python 的数据对象
- 返回单个值
>>> def foo():
... n = 3 + 7
... return n # 10
...
>>> n = foo() # n = 10
>>> n
10
>>>
- 返回多个值和多种数据类型
>>> def func():
... return 1, "hello", [1,2], {
"a":1}
...
>>> t = func() # 函数的返回值用一个变量接收
>>> t
函数的返回值返回一个元组,可以元组解包
(1, 'hello', [1, 2], {
'a': 1})
>>> n, s, li, dic = func()
>>> print(n, s, li, dic)
1 hello [1, 2] {
'a': 1}
>>>
用变量接收函数的多个返回值之后,变量应该是一个元组
一、模块化编程
- 简介
Python 有时候称为胶水语言,就是因为它有强大的可扩展性,这个扩展性就是用模块实现的。
模块其实就是一个以 .py 结尾的 Python 文件,这个文件中可以包含变量、函数、类等。
这个模块可以包含实现了一个或者多个功能的代码。
模块可以在其他 Python 文件中使用,可以通过网络进行传播。
这样的话,如果想在你的程序中实现某些功能,其实网络的其他程序猿已经给你写好了,下载下来,安装到自己的环境下,就可以使用了。
模块化编程
模块化编程是指将大型,笨拙的编程任务分解为单独的,更小的,更易于管理的子任务或模块的过程。然后可以像构建块一样拼凑单个模块以创建更大的应用程序。
在大型应用程序中模块化代码有几个优点:
- **简单性:**模块通常只关注问题的一小部分,而不是关注当前的整个问题。如果您正在处理单个模块,那么您的头脑中要思考的将有一个较小的问题范围。这使得开发更容易,更不容易出错。
- **可维护性:**模块通常设计为能够在不同的问题域之间实施逻辑边界。如果以最小化相互依赖性的方式编写模块,则对单个模块的修改将对程序的其他部分产生影响的可能性降低。(您甚至可以在不了解该模块之外的应用程序的情况下对模块进行更改。)这使得许多程序员团队在大型应用程序上协同工作更加可行。
- **可重用性:**单个模块中定义的功能可以通过应用程序的其他部分轻松地重用。这消除了重新创建重复代码的需要。
- 范围:模块通常定义一个单独的命名空间,这有助于避免程序的不同区域中的变量名之间的冲突。
二、 模块分类
- 实现方式分类
实际上有两种不同的方法可以在Python中定义模块:
- 模块可以用Python本身编写。
- 模块可以用C编写并在运行时动态加载,就像
re(正则表达式)模块一样。 - 一个内置的模块,本质上已经包含在了 Python 解释器中,像
itertools模块
。
以上情况下,模块的内容都以相同的方式访问:使用import语句
在这里,重点将主要放在用Python编写的模块上。用Python编写的模块的妙处在于它们的构建极其简单。您需要做的就是创建一个包含合法Python代码的文件,然后为该文件命名并带有 .py 扩展名即可。
- 归属分类
模块还可以分为
- 内置模块 ,就是 python 解释器中自带的. 如:
osreitertools - 第三方模块, 这些模块需要自己安装,就像是在 Linux 系统中安装软件一样。
- 自定义模块, 这个就是自己编写的模块。
- 模块的安装
3.1 安装方法
3.1.1 pip3 工具安装
例如下面的示例是安装用于执行远程主机命令的模块 paramiko
注意: pip3 是 bash 环境下的命令
$ pip3 install paramiko
python2.x 使用
pip
python3.x 使用pip3
当然这也不是固定的,比如你给pip3定义了一个别名pip
3.1.2 源码安装
源码安装就是,从网络上下载没有封装的 python 文件的源码,之后在本地执行其源码中的 setup.py 文件进行安装。
模块的源码一般都有一个主目录,主目录中包含了一个到多个子目录和文件。
但是主目录下一定有一个 setup.py 的文件,这个是源码安装的入口文件,就是需要执行这个文件并且传入一个 install 参数进行源码安装。
示例:
a. 下载源码包
wget https://files.pythonhosted.org/packages/4a/1b/9b40393630954b54a4182ca65a9cf80b41803108fcae435ffd6af57af5ae/redis-3.0.1.tar.gz
b. 解压源码包
tar -xf redis-3.0.1.tar.gz
c. 进入模块源码的主目录,并安装源码包
![]()
![]()
上面表示安装成功
- 自定义模块
有的情况下,是需要自己编写一些模块的,这种就是自定义模块了。
示例:
some_mod.py
x = 10
li = ['shark', 18]
def foo():
return 30
class Person():
def __init__(self, name, age):
self.name = name
self.age = age
- 模块的使用
使用模块需要先导入模块名。
模块名就是把 .py 去掉后的文件名。比如 some_mod.py 的模块名就是 some_mod
5.1 导入模块
import some_mod
5.2 使用模块中的对象
要想使用模块中的变量名或者函数名等,只需要使用 模块名.变量名 的方式即可。
例如,下面是使用的了 some_mod 模块中的 foo 函数。
import some_mod
some_mod.foo()
5.3 更多模块导入的方式
a. 从模块中导入其中的一个对象
from some_mod import x
b. 从模块中导入多个对象
from some_mod import x, foo
c. 从模块中导入全部的对象, 不建议这么做, 应该视使用模块中的对象的情况而定
from some_mod import *
import后面的才是可以直接引用的
导入模块时模块的代码会自动被执行一次,在一个程序中多次导入同一个模块,此模块的代码仅会运行一次。
[root@kube-master py3]# cat some_mod.py
print("hello shark")
[root@kube-master py3]# cat t.py
import some_mod
import some_mod
[root@kube-master py3]# python t.py
hello shark
- 模块的内置变量
__name__
每个 .py 文件都有一个变量名 __name__, 这个变量名的值会根据这个文件的用途不同而随之变化。
- 当文件作为模块被其他文件使用时,
__name__的值是这个文件的模块名 - 当文件作为脚本(就是作为可执行文件)使用时,
__name__的值是字符串类型的'__main__'
通常你会看到一些 Python 脚本中会有类似下面的代码:
some_script.py
def foo():
pass
def func():
pass
def main():
foo()
func()
if __name__ == '__main__':
main()
使用这个脚本
python3 some_script.py
这样执行这个脚本的话,其内置的
__name__变量的值就是字符串的'__main__'。
这样的话,if的判断添加就会达成,从而其语句下面的代码就会执行,main()函数就会被调用 。
三、包
包就是包含了一个 __init__.py 文件的文件夹,这个文件夹下可以有更多的目录或文件。就是说,包里可以用子包或单个 .py 的文件。
其实包也是模块,就是说包和单一的 .py 文件统称为模块。
- 包的目录结构
![]()
- 文件
__init__.py
__init__.py 文件,在 Python3.x 中可以没有,但是在 Python2.x 中必须有。
文件中可以有代码,也可以是个空文件,但是文件名不能是其他的。
到导入包的时候,此文件假如存在,会以此文件去创建包的名称空间。
也就是说,导入如包的时候,只要在 __init__.py 文件中的名称才可以生效。否则,即使是一个模块在包目录下面也不会被导入到内存中,也就不会生效。
- 使用包
示例包目录机构
![]()
千锋云计算杨哥团队@shark
使用包也需要导入
a. 单独导入包
import package # 注意这样不会导入其下面的模块和子包
b. 从包中导入下面的模块
from package import t
c. 从包中导入下面的子包,注意这不会导入子包下面的任何模块
from package import subpkg
d. 从包的子包中导入子包的模块
from package.subpkg import som_mod
e. 从包或子包的模块中导入具体的对象
from package.t import foo
from package.subpkg.som_mod import x
from package.t import x as y # 把 x 导入后起个别名 y
记住一点:不论是导入包还是模块,从左向右的顺序来说,最后一个点儿的左边一定是一个包名,而不能是一个模块名
下面是错误的
import package.t.foo
from package.subpkg import som_mod.x
四、模块名包名的搜索路径(扩展)
这个就像是在 Linux 系统中,当执行一个命令时候,系统会查找这个命令的二进制文件一样。Linux 系统是从环境变量 PATH 中查找。
查找顺序
当你导入模块或者包的时候, 查找模块或包的顺序:
- 系统会从内存中查找,看是否之前已经导入过此模块。
- 假如第一次导入,内存中就不会存在,这时再从当前目录下查找。
- 最再从
sys.path输出的值中的路径里查找模块名或者包名。
都找不到,就会报错,并且整个程序会退出
In [1]: import sys
In [2]: sys.path
Out[2]:
['/usr/local/bin',
'/usr/local/lib/python37.zip',
'/usr/local/lib/python3.7',
'/usr/local/lib/python3.7/lib-dynload',
'',
'/usr/local/lib/python3.7/site-packages',
'/usr/local/lib/python3.7/site-packages/unicodecsv-0.14.1-py3.7.egg',
'/usr/local/lib/python3.7/site-packages/IPython/extensions',
'/root/.ipython']
sys.path 输出的值是一个 Python 的列表,这个列表我们可以对其修改的。
10:字典类型,主机信息
第3天服务器信息清洗
一、 subprocess 执行本机命令
subprocess的getoutput()方法可以接收一个字符串的参数,这个参数会被认为是当前操作系统的命令去执行,并返回字符串类型的命令执行结果,假设命令出错,会返回相应的错误信息。
比如我们执行一条命令,来获取的厂商机器信息
目标是得到这些信息
- 厂商 就是
Manufacturer对应的值 比如 Del- 服务器型号(名字) 就是
Product Name对应的值 比如 Del R710- 服务器序列号 就是
Serial Number对应的值
(img-
-q –不显示表头,简洁输出
-t –type type只显示给定类型的条目
dmidecode系统厂商信息
dmidecode -qt 1
dmidecode查看主板信息
dmidecode -qt 2
dmidecode查询物理内存信息
dmidecode -qt 16
查看内存条数
dmidecode -qt 17
查看CPU信息
dmidecode -qt 4
我的是虚拟机
我们也可以用cat /proc/cpuinfo命令查看CPU信息。
[root@qfedu.com ~]# rpm -qa dmidecode
dmidecode-3.1-2.el7.x86_64
[root@qfedu.com ~]# dmidecode -q -t 1 2>/dev/null
System Information
Manufacturer: Alibaba Cloud
Product Name: Alibaba Cloud ECS
Version: pc-i440fx-2.1
Serial Number: 0f7e3d86-7742-4612-9f93-e3a9e4754157
UUID: 0f7e3d86-7742-4612-9f93-e3a9e4754157
Wake-up Type: Power Switch
SKU Number: Not Specified
Family: Not Specified
在 python 中可以这样做
In [1]: import subprocess
In [2]: prod_info = "dmidecode -q -t 1 2>/dev/null"
In [3]: prod_info
Out[3]: 'dmidecode -q -t 1 2>/dev/null'
In [4]: subprocess.getoutput(prod_info)
Out[4]: 'System Information\n\tManufacturer: Alibaba Cloud\n\tProduct Name: Alibaba Cloud ECS\n\tVersion: pc-i440fx-2.1\n\tSerial Number: 0f7e3d86-7742-4612-9f93-e3a9e4754157\n\tUUID: 0f7e3d86-7742-4612-9f93-e3a9e4754157\n\tWake-up Type: Power Switch\n\tSKU Number: Not Specified\n\tFamily: Not Specified\n'
In [5]:
可以看到输出结果是一个整体的字符串,和 shell 中输出的少有不同,就是这里每一行后面都有一个换行符 ‘\n’
那我们要想对每一行进行处理,可以使用 split('\n') 进行分割,当然我们这里使用另一个方法 splitlines(), 它默认使用的分隔符就是换行符
In [5]: ret = subprocess.getoutput(prod_info)
In [6]: ret.splitlines()
Out[6]:
['System Information',
'\tManufacturer: Alibaba Cloud',
'\tProduct Name: Alibaba Cloud ECS',
'\tVersion: pc-i440fx-2.1',
'\tSerial Number: 0f7e3d86-7742-4612-9f93-e3a9e4754157',
'\tUUID: 0f7e3d86-7742-4612-9f93-e3a9e4754157',
'\tWake-up Type: Power Switch',
'\tSKU Number: Not Specified',
'\tFamily: Not Specified']
In [7]:
那接着我们即可以循环列表中的每个元素(也就是每行),在循环中处理每行内容,得到我们想要的数据
In [7]: for line in ret.splitlines():
...: print(line)
...:
System Information
Manufacturer: Alibaba Cloud
Product Name: Alibaba Cloud ECS
Version: pc-i440fx-2.1
Serial Number: 0f7e3d86-7742-4612-9f93-e3a9e4754157
UUID: 0f7e3d86-7742-4612-9f93-e3a9e4754157
Wake-up Type: Power Switch
SKU Number: Not Specified
Family: Not Specified
In [8]: for line in ret.splitlines():
...: if 'Manufacturer:' in line:
...: print(line)
...:
Manufacturer: Alibaba Cloud
字典用循环列表创建,不要直接
可以看到我们拿到了我们需要的第一个数据,并且可以进行进一步的处理,比如转换成一个字典,其他可以如法炮制。
In [52]: info_dict = {}
…: for line in n:
…: k, v = line.split(’:’)
…: info_dict[k] = v
循环得到的每一行是字符串,用split(’:’)将字符串分割成列表,进行元组解包
In [12]: prod_dic = {
}
...: for line in ret.splitlines():
...: k = ''
...: line = line.strip()
...: print(line)
...: if ': ' in line:
...: k, v = line.split(': ')
...: print(k)
...: if k == 'Manufacturer':
...: prod_dic[k.lower()] = v
...: elif k == 'Product Name':
...: prod_dic[k.lower()] = v
...: elif k == 'Serial Number':
...: prod_dic[k.lower()] = v
...:
In [13]: prod_dic
Out[13]:
{
'serial_number': '0f7e3d86-7742-4612-9f93-e3a9e4754157',
'manufacturer': 'Alibaba Cloud',
'product_name': 'Alibaba Cloud ECS'}
和我们的目标越来接近了,但你会发现有问题
- 多个判断语句导致代码臃肿
- 并且 if 语句中存在重复的代码
那继续优化,思路是可以提前定义一个映射的字典
#!/usr/bin/env python3
import subprocess
prod_info = 'dmidecode -q -t 1 2>/dev/null'
# 执行系统命令并返回结果
ret = subprocess.getoutput(prod_info)
prod_dic = {
}
# 定义映射字典
map_dic = {
"Manufacturer": "manufacturer",
"Product Name": "pod_name",
"Serial Number": "sn"
}
for line in ret.splitlines():
line = line.strip()
try: # 异常处理语句
k, v = line.split(": ")
if k in map_dic:
# k = map_dic.get(k)
prod_dic[map_dic.get(k)] = v
except ValueError as e:
print(e)
# print('....>>>')
print(prod_dic)
# 输出信息
{
'manufacturer': 'VMware, Inc.', 'pod_name': 'VMware7,1', 'sn': 'VMware-56 4d 2b 4b 91 1e 48 15-5b d2 73 9c ec 98 da 22'}
异常处理
try…except… else…finally…
1)普通的异常处理:
import time
try:
# 如果你觉得代码可能出现问题, 那么放在try语句中, 只执行一次;
print(s) #可能NameError
except NameError as e: # 对于异常进行一个重命名;记录了异常的详细信息;
# 可能执行一次, 也可能不执行;
print('名称错误')
with open('except.log','w') as f: #把异常内容写入except.log文件
f.write('名称错误')
finally:
# 无论是否出现异常, 肯定会执行一次
print('处理结束')
123456789101112
输出:
名称错误
处理结束
12
并且会得到一个except.log文件
当没有错误时,except不执行
可以调整except.log文件记录格式显示时间错误内容等
import time
try:
# print(s)
print('hello') # 没有错误,except不执行
except NameError as e:
print('名称错误')
with open('except.log','w') as f:
f.write(time.ctime()+' ') #打印时间
f.write(str(e)) # 打印错误详情
finally:
print('处理结束')
try语句中一旦出现问题, 后面的语句(try里面的)不执行,并且except.log文件什么都不记录。
import time
try:
# 如果你觉得代码可能出现问题, 那么放在try语句中, 只执行一次;
print('hello')
with open('/etc/aa') as f: # try语句中一旦出现问题, 后面的语句(try里面的)不执行
print(f.read()[:5])
print("文件读取结束")
li = [1, 2, 3, 4]
print(li[5])
print(s)
print("hello")
except (NameError, IndexError) as e: # 对于异常进行一个重命名;记录了异常的详细信息;
# 可能执行一次, 也可能不执行;
# print("名称错误")
with open("except.log", 'a+') as f:
f.write(time.ctime() + ' ' + str(e) + '\n')
finally:
# 无论是否出现异常, 肯定会执行一次,
print("处理结束")
二、 获取服务器的硬件基础信息
- 基础信息
# 主机名
cmd_machine = 'uname -n'
# 内核版本
cmd_kernel = 'uname -r'
# 操作系统
cmd_os_version = "cat /etc/redhat-release"
# cpu信息
cmd_cpu = "cat /proc/cpuinfo"
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z7rR8Scb-1600949334074)(/root/Bilder/2020-09-21 21-24-04 的屏幕截图.png)]
- 厂家和产品信息
[root@qfedu.com]# dmidecode -q -t 1 2>/dev/null
System Information
Manufacturer: Alibaba Cloud # 厂商
Product Name: Alibaba Cloud ECS # 机器型号
Version: pc-i440fx-2.1
Serial Number: 0f7e3d86-7742-4612-9f93-e3a9e4754157
UUID: 0f7e3d86-7742-4612-9f93-e3a9e4754157
Wake-up Type: Power Switch
SKU Number: Not Specified
Family: Not Specified
- CPU 信息
3.1 查看物理CPU型号
grep 'model name' /proc/cpuinfo | uniq
In [1]: import subprocess
In [2]: cmd_cpu_name = "grep 'model name' /proc/cpuinfo | uniq"
In [3]: subprocess.getoutput(cmd_cpu_name)
Out[3]: 'model name\t: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz'
In [4]: cpu_name = subprocess.getoutput(cmd_cpu_name).split(": ")[1]
In [5]: cpu_name
Out[5]: 'Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz'
In [6]: cpu = {
"cpu_name": cpu_name}
In [7]: cpu
Out[7]: {
'cpu_name': 'Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz'}
In [8]:
3.2 查看物理CPU颗数
grep 'physical id' /proc/cpuinfo | sort -u | wc -l
In [8]: cmd_cpu_pyc = "grep 'physical id' /proc/cpuinfo | sort -u | wc -l"
In [9]: subprocess.getoutput(cmd_cpu_pyc)
Out[9]: '1'
In [10]: cpu["pyc"] = int(subprocess.getoutput(cmd_cpu_pyc))
In [11]: cpu
Out[11]: {
'cpu_name': 'Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz', 'cpu_pyc': 1}
In [12]:
3.3 查看每颗物理 CPU 的核心数
grep 'cpu cores' /proc/cpuinfo | uniq # 每颗 CPU 的核心数,不是总核心数
In [13]: subprocess.getoutput("grep 'cpu cores' /proc/cpuinfo | uniq")
Out[13]: 'cpu cores\t: 1'
In [14]: cpu_cores_each = subprocess.getoutput("grep 'cpu cores' /proc/cpuinfo | uniq")
In [15]: cpu_cores_each = int(cpu_cores_each.split(": ")[1])
In [16]: cpu_cores_each
Out[16]: 1
In [17]: cpu["cores_each"] = cpu_cores_each
In [18]: cpu
Out[18]:
{
'cpu_name': 'Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz',
'cpu_num': 1,
'cpu_cores_each': 1}
In [19]:
- 内存信息
- 阿里云虚拟主机
[root@qfedu.com]# dmidecode -q -t 17 2>/dev/null
Memory Device
Total Width: Unknown
Data Width: Unknown
Size: 4096 MB # 容量
Form Factor: DIMM
Set: None
Locator: DIMM 0 # 插槽号
Bank Locator: Not Specified
Type: RAM # 类型 物理的有 DDR3 DDR4
Type Detail: Other
Speed: Unknown # 速率 物理的有 1333 等
Manufacturer: Alibaba Cloud # 厂商
Serial Number: Not Specified # 序列号
Asset Tag: Not Specified
Part Number: Not Specified
Rank: Unknown
Configured Clock Speed: Unknown
Minimum Voltage: Unknown
Maximum Voltage: Unknown
Configured Voltage: Unknown
- 物理 R710 服务器
Memory Device
Total Width: 72 bits
Data Width: 64 bits
Size: 8192 MB
Form Factor: DIMM
Set: 6
Locator: DIMM_B2
Bank Locator: Not Specified
Type: DDR3
Type Detail: Synchronous Registered (Buffered)
Speed: 1333 MT/s
Manufacturer: 00CE00B380CE
Serial Number: 82B79F71
Asset Tag: 02120363
Part Number: M393B1K70DH0-YH9
Rank: 2
Memory Device
Total Width: 72 bits
Data Width: 64 bits
Size: 8192 MB
Form Factor: DIMM
Set: 6
Locator: DIMM_B3
Bank Locator: Not Specified
Type: DDR3
Type Detail: Synchronous Registered (Buffered)
Speed: 1333 MT/s
Manufacturer: 00CE00B380CE
Serial Number: 32CDDE81
Asset Tag: 02120361
Part Number: M393B1K70CH0-YH9
Rank: 2
Memory Device
Total Width: 72 bits
Data Width: 64 bits
Size: No Module Installed
Form Factor: DIMM
Set: 4
Locator: DIMM_B4
Bank Locator: Not Specified
Type: DDR3
Type Detail: Synchronous
Speed: Unknown
Manufacturer:
Serial Number:
Asset Tag:
Part Number:
Rank: Unknown
Memory Device
Total Width: 72 bits
Data Width: 64 bits
Size: 8192 MB
Form Factor: DIMM
Set: 5
Locator: DIMM_B5
Bank Locator: Not Specified
Type: DDR3
Type Detail: Synchronous Registered (Buffered)
Speed: 1333 MT/s
Manufacturer: 00CE04B380CE
Serial Number: 85966B82
Asset Tag: 02113621
Part Number: M393B1K70DH0-YH9
Rank: 2
Memory Device
Total Width: 72 bits
Data Width: 64 bits
Size: 8192 MB
Form Factor: DIMM
Set: 6
Locator: DIMM_B6
Bank Locator: Not Specified
Type: DDR3
Type Detail: Synchronous Registered (Buffered)
Speed: 1333 MT/s
Manufacturer: 000000B380CE
Serial Number: 00000000
Asset Tag: 02121563
Part Number:
Rank: 2
作业
请使用以上信息,编写一个脚本,输出如下信息
{
"base_info": {
"host_name": "db_server",
"kernel": "3.10.0-957.21.3.el7.x86_64",
"os": "CentOS Linux release 7.6.1810 (Core)",
'manufacturer': 'Alibaba Cloud',
'pod_name': 'Alibaba Cloud ECS',
'sn': '0f7e3d86-7742-4612-9f93-e3a9e4754157'
},
"cpu": {
'name': 'Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz',
'num': 1,
'cores_each': 1
},
"mem": [
{
'capacity': '8192 MB',
'slot': 'DIMM_A3',
'model': 'DDR3',
'speed': '1333 MT/s',
'manufacturer': '00CE04B380CE',
'sn': '8362A2F8'
},
{
'capacity': 'No Module Installed',
'slot': 'DIMM_A4',
'model': 'DDR3',
'speed': 'Unknown'
}
...........略............
]
}
内存源数据使用上面 R710 的,映射字典使用下面这个
key_map = {
'Size': 'capacity',
'Locator': 'slot',
'Type': 'model',
'Speed': 'speed',
'Manufacturer': 'manufacturer',
'Serial Number': 'sn',
}
内存处理参考代码
def parse(data):
key_map = {
'Size': 'capacity',
'Locator': 'slot',
'Type': 'model',
'Speed': 'speed',
'Manufacturer': 'manufacturer',
'Serial Number': 'sn'
}
info_mem = []
# 首先把服务器上的所有插槽分开,并发到一个列表中
# 这个语法叫列表生成式, 表示循环中的元素为真时候,将 mem 添加到列表中
memory_list = [ mem for mem in data.split('Memory Device') if mem]
for item in memory_list:
# 把每个插槽的信息放到一个字典中
single_slot = {
}
for line in item.splitlines():
line = line.strip()
if len(line.split(': ')) == 2:
key, val = line.split(': ')
if key in key_map:
# 获取到映射字典的 value 作为新字典的 key
single_slot[key_map[key]] = val
# 含有插槽信息的字典:
# {'capacity': '8192 MB', 'slot': 'DIMM_A3', 'model': 'DDR3', 'speed': '1333 MT/s', 'manufacturer': '00CE04B380CE', 'sn': '8362A2F8'}
# 由于存在多个内存插槽,每个插槽的号码是不一样的
# 所以可以把当前内存的插槽号作为总体内存字典中的一个 key,值就是当前含有插槽信息的字典
info_mem.append = single_slot
return info_mem
11:格式化输出
第3天服务器信息清洗
一、 简单介绍
字符串的格式化输出目前有三种方式
%方式(陈旧) python2.x及以上 都支持str.format()方式(新式,官方推荐) python2.7及以上都支持f-string方式 (Python3.6 及以上推荐使用)
二、常用操作
- % 百分号方式
把字符串和变量合起来输出,比字符串的拼接简单
%s 是字符串类型的占位符
% 用来传递参数
% 后面的参数按照顺序传递,多个参数用()括起来,中间用逗号隔开
>>> tpl = "i am %s"
>>> msg = tpl % "yangge"
>>> msg
'i am yangge'
>>>
>>> tpl = "i am %s, %s"
>>> msg = tpl % ("yangge", 18)
>>> msg
'i am yangge, 18
- str.format() 方式
{}为占位符
str.format() 括号里面传递参数,多个参数用逗号隔开
str.format()和列表list结合使用
用列表进行传递参数
占位符数量要和列表元素数量一样
str.format(*li) 导入列表
>>> msg = "I am {}"
>>> msg.format("yangge")
'I am yangge'
>>>
>>> msg = "I am {}, {}"
>>> msg.format("yangge", 18)
'I am yangge, 18'
In [75]: li = ["yangge", 18]
>>> msg.format(*li)
'I am yangge, 18'
>>>
msg = “I am {name}, {age}”,可以把变量定义在中括号里面,赋值的时候可以不用按照顺序,但要对应
str.format()与字典dict连用,
用字典进行参数赋值
字典的key要先定义在占位符{}里面
str.format(**info) 导入字典
>>> msg = "I am {name}, {age}"
>>> msg.format(age=18, name="shark")
'I am shark, 18'
>>>
>>> info = {
"name": "shark", "age": 18}
>>> msg.format(**info)
'I am shark, 18'
>>>
- f-strings 方式
f-strings方法用来操作数据库很方便,在外面定义变量,f”{变量}”
>>> ip="192.168.1.100"
>>> user="admin"
>>> pwd="QFedu123!"
>>> conn_mysql = f"mysql -u{user} -p{pwd} -h {ip}"
>>> conn_mysql
'mysql -uadmin -pQFedu123! -h 192.168.1.100'
Python print()输出颜色设置
12:python爬虫
一、获取数据
参考数据源: 斗图:https://www.doutula.com/photo/list/
- 打开浏览器的调试模式
首先,在打开网页后右键,点击 检查
- 查找图片地址
-
首先,点击调试窗口的左上角的箭头
-
之后,将鼠标点击某一张图片上,在下方的红框中就会看到图片的链接地址,实际是
img标签的一个属性:data-original的值 -
获取图片
双击 data-original 属性,之后用鼠标选定地址,再右键
http://tva2.sinaimg.cn/bmiddle/9150e4e5gy1gct8nwvd5yj205i05bjr9.jpg
- 开始下载
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9VFLhXms-1600949389143)(/root/Bilder/2020-09-24 19-30-36 的屏幕截图.png)]
复制好地址后就可以使用 requests 模块的的 get() 方法来请求这个数据了
图片、视频等非普通问题的文件,返回的数据都是二进制的,所以要保存到本地就需要使用文件的 wb 的方式写。
import requests,io
io 模块中的 open 函数和 open 函数使用方法一样
io.open 适用 python2 和 python3 ,比较通用
url = 'http://tva2.sinaimg.cn/bmiddle/9150e4e5gy1gct8nwvd5yj205i05bjr9.jpg'
获取响应对象
res = requests.get(url=url)
打印出文件内容
print(res.content)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YkRvwlPY-1600949389146)(/root/Bilder/2020-09-24 19-37-09 的屏幕截图.png)]
- 保存数据
1 文件操作
在 python3 中使用 open() 函数
语法格式:
f = open('文件路径', '文件打开模式', encoding='字符编码')
-
f 是打开的文件对象
-
文件路径: 可以是相对路径或者绝对路径
-
字符编码: 一般是 utf-8
-
文件打开模式:
-
普通文本文件的打开模式有:
r只读,不能写,这也是默认模式
-
-
w只写, 不能读,文件不存在,会自动创建,但是不会自动创建目录,覆盖-
a在原来文件内容的基础上追加的写,通常用于写日志。文件不存在也会自动创建。 -
图片、视频、音频等非普通文本文件使用二进制的方式打开,打开时不能传递
encoding参数。 -
rb读wb写
-
重要: 使用 open 函数打开文件,无论读写,都需要执行文件对象的 close() 方法进行关闭。
读文件示例演示
In [1]: file='/etc/hosts'
In [2]: f = open(file, 'r', encoding='utf-8')
In [3]: content = f.read() # 读取文件的全部内容
In [4]: f.close() # 关闭文件对象
In [5]: content
Out[5]: '127.0.0.1 VM-0-11-centos VM-0-11-centos\n127.0.0.1 localhost.localdomain localhost\n127.0.0.1 localhost4.localdomain4 localhost4\n\n::1 VM-0-11-centos VM-0-11-centos\n::1 localhost.localdomain localhost\n::1 localhost6.localdomain6 localhost6\n\n'
In [7]: print(content)
127.0.0.1 VM-0-11-centos VM-0-11-centos
127.0.0.1 localhost.localdomain localhost
127.0.0.1 localhost4.localdomain4 localhost4
::1 VM-0-11-centos VM-0-11-centos
::1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
In [8]:
循环文件对象
上面是把文件一次性读取到内存了,假如文件比较大,不适合。可以使用 for 对文件对象循环解决此问题,这样的话,每次读入到内存中的只有当前被循环的一行内容而已。
In [8]: file='/etc/hosts'
In [9]: f = open(file, 'r', encoding='utf-8')
In [10]: for line in f:
...: print(line)
...:
127.0.0.1 VM-0-11-centos VM-0-11-centos
127.0.0.1 localhost.localdomain localhost
127.0.0.1 localhost4.localdomain4 localhost4
::1 VM-0-11-centos VM-0-11-centos
::1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
写文件示例
In [11]: f = open("a.txt", "w", encoding='utf-8') # 写模式打开文件
In [12]: f.write("hello\n") # 写入第一行内容,需要自己写换行符才能换行
Out[12]: 6
In [13]: f.write("world\n")
Out[13]: 6
返回字符个数
In [14]: f.close() # 写完内容后,关闭文件对象
In [15]: !cat a.txt # 查看刚才写好的文件内容
hello
world
In [16]:
2 上下文管理器 with
相信你从上面已经感受到了,每次打开文件都需要自己写代码关闭文件对象,这样很麻烦,并且总会出现忘记编写关闭文件对象的代码。现在使用上下文管理器 with 就可以让 Python 为我们自动关闭文件对象,它的语法格式是这样的:
with open('文件路径', '文件打开模式', encoding='字符编码') as f:
# 缩进后进行文件的操作,只要
# 只要代码出了 with 语句代码块,文件就会自动关闭,程序退出文件也会自动关闭。
print("此时文件会自动关闭")
示例演示
with open('/etc/hosts', 'r', encoding='utf-8') as f:
for line in f:
print(line)
3 保存图片到本地
import requests,io
# io 模块中的 open 函数和 #open 函数使用方法一样
io.open 适用 python2 和 python3 ,比较通用
url = 'http://tva2.sinaimg.cn/bmiddle/9150e4e5gy1gct8nwvd5yj205i05bjr9.jpg'
# 获取响应对象
res = requests.get(url=url)
with open("test.jpg",'wb') as f:
f.write(res.content)
13:python发送邮件和钉钉消息
第4天
一、 邮件发送
- 开通邮箱SMTP服务,并获取 授权码
这个账户是你要使用此邮箱发送邮件的账户,密码不是平时登录邮箱的密码,而是开通 POP3/SMTP 功能后设置的客户端授权密码。
这里以 126 邮箱为例:
2。安装
GDIKCHPAPVKZQROZ
pip3 install yagmail
- 基本用法
import yagmail
yag = yagmail.SMTP(
user='自己的账号',
password='账号的授权码',
host='smtp.qq.com', # 邮局的 smtp 地址
port='端口号', # 邮局的 smtp 端口
smtp_ssl=False)
yag.send(to='收件箱账号',
subject='邮件主题',
contents='邮件内容')
- 实例
下面是以我的 126 邮箱为例, 使用系统密钥环的方式,向我的 163邮箱发送了一封邮件。
import yagmail
# 这个要刚才已经成功开通 SMTP 的邮箱账号
email_user = 'shark@126.com'
# 这个必须是客户端授权码,不是登录密码
email_pwd = 'yourpassword'
# 这个可以从邮件服务提供商获取
email_host = 'smtp.126.com'
邮件正文
email_content = """你不是我喜欢的那种人 却慢慢变成 我喜欢的那个人"""
yag = yagmail.SMTP(user=email_user,
password=email_pwd,
host=email_host,
port=25,
smtp_ssl=False)
yag.send(to='docker@163.com',
subject='告白气球',
contents=email_content)
这样就愉快的发送了一封测试邮件到 docker@163.com 的邮箱。
- 群发附件并且给邮件内容加密
给多个人发送是,只需要把关键字参数 to 的值改成列表即可,列表中放入需要通知的人的邮箱地址。
email_users=["user1@163.com", "user2@126.com"]
to=email_users
希望加密邮件内容,也很简单。
大部分运营上提供的加密邮件接收的端口是 465,把端口改成 465
其实 smtp_ssl=True 这个参数不传也行,因为默认的就是 True
实例图片
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zReHgqCf-1600952298084)(/root/sunlizhen/4aca8c294b6b575ff147df8b346b35f0.jpg)]
保存上面的图片到本地,作为测试之用。
这里保存的名称是 告白气球.jpg
发送附件可以使用 attachments 关键字参数,它的值可以是一个具体的有效路径,也可以是包含有效路径的列表。
代码
import yagmail
email_user = 'shark@126.com'
email_pwd ='yourpassword'
email_host = 'smtp.126.com'
email_content = """你不讲真心话 我却在大冒险"""
email_image = "./拥抱.jgp"
yag = yagmail.SMTP(user=email_user,
password=email_pwd,
host=email_host,
port=465,
smtp_ssl=True)
yag.send(to='docker@163.com',
subject='告白气球',
contents=email_content,
attachments=email_image
)
邮件收到显示:
有的时候,发送的邮件会被识别为垃圾邮件
^_^
最简单的还是放在 contents 中。比如:
contents=[email_content, email_image]
在这个列表中,假如是有效的路径,就会作为附件发送,假如不是有效路径,就会作为普通文字发送。
二、发送钉钉消息
- 自定义机器人
- 发送给群内所有人
郑重警告⚠️
每个机器人每分钟只可以发送
20条信息,多了,会被禁止使用10分钟.
import requests
content = {
"msgtype": "text",
"text": {
"content": "出发!"
},
"at": {
# 发送给群里的所有人
"isAtAll": True
}
}
headers = {
"Content-Type": "application/json;charset=utf-8"}
# 机器人助手地址
url = "https://oapi.dingtalk.com/robot/send?access_token=你自己的 token"
r = requests.post(url=url,headers=headers,json=content)
print(r.content.decode())
- 发给指定的人
需要知道他们的注册钉钉时候使用的手机号
import requests
content = {
"msgtype": "text",
"text": {
"content": "出发!"
},
"at": {
"atMobiles": [
# 单独 @ 某个人,使用绑定的手机号,
# 多个人用户英文逗号隔开
"131xxxxxx811",
"137xxxxxxxxx"
]
}
}
headers = {
"Content-Type": "application/json;charset=utf-8"}
url = "https://oapi.dingtalk.com/robot/send?access_token=你自己的 token"
r = requests.post(url=url,headers=headers,json=content)
print(r.content.decode(encoding="utf-8")) # 指定字符编码
14:python的正则表达式
第4天-发送消息和正则表达式
一、预备知识正则
- 正则介绍
Python 中的正则,本质上是嵌入在Python中的一种微小的、高度专业化的编程语言,可通过
re这个内置模块获得。
正则表达式模式几乎和 shell 中的一样,更接近grep -P的效果,因为 Python 中的re模块提供的是类似 Perl 语言中的正则表达式。
正则表达式模式会被编译成一系列字节码,然后由用 C 编写的匹配引擎执行。
- 陷阱
友情提示:
正则表达式语言相对较小且受限制,因此并非所有可能的字符串处理任务都可以使用正则表达式完成。
还有一些任务 可以 用正则表达式完成,但表达式变得非常复杂。 在这些情况下,你最好编写 Python 代码来进行处理;虽然 Python 代码比精心设计的正则表达式慢,但它也可能更容易理解。
- 特殊的字符
在 Python 中有一些特殊的字符,在正则表达式模式中的作用和 shell 和 grep -P 时候有一些细微的差别
正则特殊字符 匹配内容 \w匹配单个字母、数字、汉字(shell中没有)或下划线 类似于 [a-zA-Z0-9_]\d匹配单个数字 类似于 [0-9]\s匹配单个任意的空白符,这等价于 [ \t\n\r\f\v]\S匹配任何非空白字符, [^ \t\n\r\f\v]
二、 re 模块的方法
其实,前面在 shell 中我们已经学习正则,这里我们主要学习的是 Python 中如何使用正则的,就是
re模块中都有哪些方法。
接下来我们就学习几个常间的方法,更多请移步正则扩展知识完整版
1 常用方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KkF0Pm7r-1600952333224)(/root/Bilder/2020-09-24 20-23-55 的屏幕截图.png)]
match() 就看开头有没有
只在整个字符串的起始位置进行匹配
示例字符串
s = "isinstance yangge enumerate www.qfedu.com 1997"
示例演示:
import re
In [4]: r = re.match("is\w+", s)
用变量接收
In [8]: r.group() # 获取匹配成功的结果
Out[8]: 'isinstance'
s = “isinstance yangge enumerate www.qfedu.com 1997”
search() 只查到第一个匹配的
从整个字符串的开头找到最后,当第一个匹配成功后,就不再继续匹配。
In [9]: r = re.search("a\w+", s)
In [10]: r.group()
Out[10]: 'ance'
找不到返回null
不用group的都是直接返回数据的
findall() 查到所有
搜索整个字符串,找到所有匹配成功的字符串,比把这些字符串放在一个列表中返回。
In [16]: r = re.findall("a\w+", s)
Python中单引号和双引号没什么区别
findall返回一个列表,不许有group
In [17]: r
Out[17]: ['ance', 'angge', 'ate']
findall找不到返回空列表
sub() 替换
把匹配成功的字符串,进行替换。
# 语法:
""" ("a\w+", "100", s, 2) 匹配规则,替换成的新内容, 被搜索的对象, 有相同的话替换的次数 """
In [24]: r = re.sub("a\w+", "100", s, 2)
In [25]: r
Out[25]: 'isinst100 y100 enumerate www.qfedu.com 1997'
# 模式不匹配时,返回原来的值
split() 分割
和 awk -F '[d]' 一样效果,以匹配到的字符进行分割,返回分割后的列表
In [26]: s
Out[26]: 'isinstance yangge enumerate www.qfedu.com 1997'
In [27]: r = re.split("a", s, 1)
数字代表分割次数
使用多个界定符分割字符串
>>> line = 'asdf fjdk; afed, fjek,asdf, foo'
>>> import re
>>> re.split('[;,\s]\s*', line)
['asdf', 'fjdk', 'afed', 'fjek', 'asdf', 'foo']
- 正则分组
match:只找开头
search:只找一个
findall:全部找到,直接返回
就是从已经成功匹配的内容中,再去把想要的取出来,
# match
In [64]: s
Out[64]: 'isinstance yangge enumerate www.qfedu.com 1997'
In [65]: r = re.match("is(\w+)", s)
In [66]: r.group()
Out[66]: 'isinstance'
In [67]: r.groups()
Out[67]: ('instance',)
不命名分组,返回数据放在元组里面
命名之后放在字典里面
# search
# 命名分组 P<name>
isinstance yangge enumerate www.qfedu.com 1997
In [87]: r = re.search("is\w+\s(?P<name>y\w+e)", s)
In [88]: r.group()
Out[88]: 'isinstance yangge'
In [89]: r.groups()
Out[89]: ('yangge',)
In [90]: r.groupdict()
Out[90]: {
'name': 'yangge'}
# findall
In [98]: s
Out[98]: 'isinstance yangge enumerate www.qfedu.com 1997'
In [99]: r = re.findall("a(\w+)", s)
findall只输出了分组之后的内容
In [100]: r
Out[100]: ['nce', 'ngge', 'ny', 'te']
15:海量数据爬虫思路
第4 天正则爬去海量图片
一、获取数据
参考数据源: 斗图:https://www.doutula.com/photo/list/
- 打开浏览器的调试模式
首先,在打开网页后右键,点击 检查
- 查找图片地址
-
首先,点击调试窗口的左上角的箭头
-
之后,将鼠标点击某一张图片上,在下方的红框中就会看到图片的链接地址,实际是
img标签的一个属性:data-original的值 -
获取图片
双击 data-original 属性,之后用鼠标选定地址,再右键
http://tva2.sinaimg.cn/bmiddle/9150e4e5gy1gct8nwvd5yj205i05bjr9.jpg
- 开始下载
复制好地址后就可以使用 requests 模的的 get() 方法来请求这个数据了
图片、视频等非普通问题的文件,返回的数据都是二进制的,所以要保存到本地就需要使用文件的 wb 的方式写。
import requests,io
io 模块中的 open 函数和 #open 函数使用方法一样
io.open 适用 python2 和 python3 ,比较通用
url = 'http://tva2.sinaimg.cn/bmiddle/9150e4e5gy1gct8nwvd5yj205i05bjr9.jpg'
方法的源码: def get(url, params=None, **kwargs):
获取响应对象
res = requests.get(url=url)
file_name = "反应" + '.jpg'
二进制方式打开文件,不需要传递字符编码参数:encoding
with io.open(file_name, 'wb') as bf:
bf.write(res.content)
二、批量下载
- 思路分析
上面的方式只是想让大家对爬虫爬取图片数据的流程有个简单的认识
可以看出来步骤非常的繁琐,且效率很低
实际上,图片的地址都是通过代码获取到的
思路就是把所有需要下载的图片地址放到一个列表中,之后循环这个列表一个一个的下载,或者分批下载。
2 获取整个页面内容
首先我们需要把整个页面的内容获取到,我们知道获取到的网页数据实际上是普通文本,之前我们也操作过。
那我们只需要利用字符串的方法或者利用正则的方式,把需要的地址找出来并放到一个列表中就可以了。
参考数据源: 斗图:https://www.doutula.com/photo/list/
import requests
# 发送请求
res = requests.get('https://www.doutula.com/photo/list/')
# 获取到普通文本内容,需要指定字符编码
# 字符编码一般从页面中的 meta 标签中获取,请看下面的图片
html = str(res.content,encoding='utf-8')
# 打印出内容后,在内容中搜索关键字 data-original
print(html)
- 清理数据
根据我们找到 img 标签在整个页面上的特点清理数据,获取到图片的地址
- 保存数据
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144715.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...