大家好,又见面了,我是你们的朋友全栈君。
2019.7.17
很意外本人这篇文章受到很多人的关注,在此把源码贴出来供大家更好的理解学习。
https://download.csdn.net/download/joekepler/10590751
========================分割=====================================
本人最近研究NSGA2算法,网上有很多示例代码,但是基本没有注释,代码看起来很头疼,因此我最近把整个代码研读了一遍,并做上中文注释,希望可以帮助到一些和我一样的初学者们。贴出代码之前,首先介绍一下NSGA2遗传算法的流程图:流程图中我把每个详细的步骤用号码标出来,对应下文的代码部分。

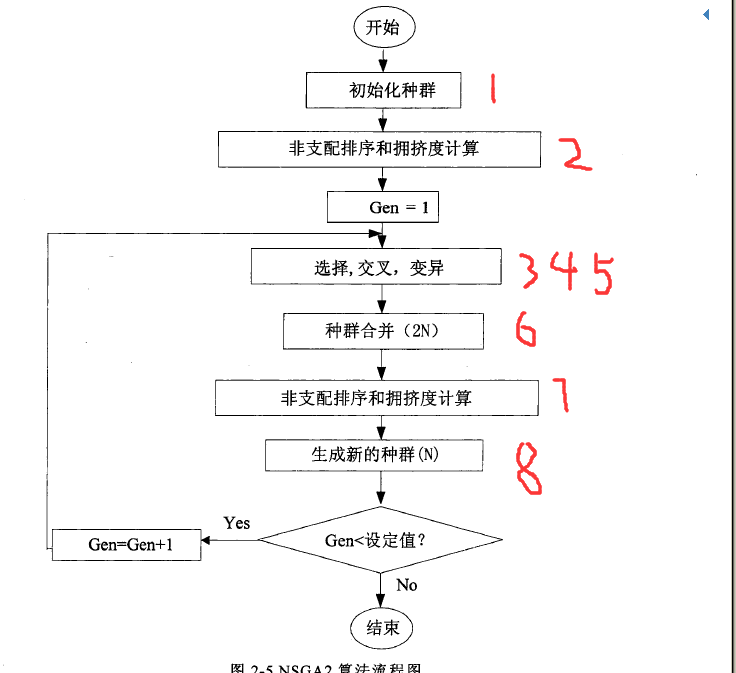
首先贴出主函数代码,对应整个流程图:
function nsga_2_optimization
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%此处可以更改
%更多机器学习内容请访问omegaxyz.com
pop = 200; %种群数量
gen = 500; %迭代次数
M = 2; %目标函数数量
V = 30; %维度(决策变量的个数)
min_range = zeros(1, V); %下界 生成1*30的个体向量 全为0
max_range = ones(1,V); %上界 生成1*30的个体向量 全为1
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
chromosome = initialize_variables(pop, M, V, min_range, max_range);%初始化种群
chromosome = non_domination_sort_mod(chromosome, M, V);%对初始化种群进行非支配快速排序和拥挤度计算
for i = 1 : gen
pool = round(pop/2);%round() 四舍五入取整 交配池大小
tour = 2;%竞标赛 参赛选手个数
parent_chromosome = tournament_selection(chromosome, pool, tour);%竞标赛选择适合繁殖的父代
mu = 20;%交叉和变异算法的分布指数
mum = 20;
offspring_chromosome = genetic_operator(parent_chromosome,M, V, mu, mum, min_range, max_range);%进行交叉变异产生子代 该代码中使用模拟二进制交叉和多项式变异 采用实数编码
[main_pop,~] = size(chromosome);%父代种群的大小
[offspring_pop,~] = size(offspring_chromosome);%子代种群的大小
clear temp
intermediate_chromosome(1:main_pop,:) = chromosome;
intermediate_chromosome(main_pop + 1 : main_pop + offspring_pop,1 : M+V) = offspring_chromosome;%合并父代种群和子代种群
intermediate_chromosome = non_domination_sort_mod(intermediate_chromosome, M, V);%对新的种群进行快速非支配排序
chromosome = replace_chromosome(intermediate_chromosome, M, V, pop);%选择合并种群中前N个优先的个体组成新种群
if ~mod(i,100)
clc;
fprintf('%d generations completed\n',i);
end
end
if M == 2
plot(chromosome(:,V + 1),chromosome(:,V + 2),'*');
xlabel('f_1'); ylabel('f_2');
title('Pareto Optimal Front');
elseif M == 3
plot3(chromosome(:,V + 1),chromosome(:,V + 2),chromosome(:,V + 3),'*');
xlabel('f_1'); ylabel('f_2'); zlabel('f_3');
title('Pareto Optimal Surface');
end
1 初始化代码
function f = initialize_variables(N, M, V, min_range, max_range)%f是一个由种群个体组成的矩阵
min = min_range;
max = max_range;
K = M + V;%%K是数组的总元素个数。为了便于计算,决策变量和目标函数串在一起形成一个数组。
%对于交叉和变异,利用目标变量对决策变量进行选择
for i = 1 : N
for j = 1 : V
f(i,j) = min(j) + (max(j) - min(j))*rand(1);%f(i j)表示的是种群中第i个个体中的第j个决策变量,
%这行代码为每个个体的所有决策变量在约束条件内随机取值
end
f(i,V + 1: K) = evaluate_objective(f(i,:), M, V); % M是目标函数数量 V是决策变量个数
%为了简化计算将对应的目标函数值储存在染色体的V + 1 到 K的位置。
end2 快速非支配排序和拥挤度计算代码
%% 对初始种群开始排序 快速非支配排序
% 使用非支配排序对种群进行排序。该函数返回每个个体对应的排序值和拥挤距离,是一个两列的矩阵。
% 并将排序值和拥挤距离添加到染色体矩阵中
function f = non_domination_sort_mod(x, M, V)
[N, ~] = size(x);% N为矩阵x的行数,也是种群的数量
clear m
front = 1;
F(front).f = [];
individual = [];
for i = 1 : N
individual(i).n = 0;%n是个体i被支配的个体数量
individual(i).p = [];%p是被个体i支配的个体集合
for j = 1 : N
dom_less = 0;
dom_equal = 0;
dom_more = 0;
for k = 1 : M %判断个体i和个体j的支配关系
if (x(i,V + k) < x(j,V + k))
dom_less = dom_less + 1;
elseif (x(i,V + k) == x(j,V + k))
dom_equal = dom_equal + 1;
else
dom_more = dom_more + 1;
end
end
if dom_less == 0 && dom_equal ~= M % 说明i受j支配,相应的n加1
individual(i).n = individual(i).n + 1;
elseif dom_more == 0 && dom_equal ~= M % 说明i支配j,把j加入i的支配合集中
individual(i).p = [individual(i).p j];
end
end
if individual(i).n == 0 %个体i非支配等级排序最高,属于当前最优解集,相应的染色体中携带代表排序数的信息
x(i,M + V + 1) = 1;
F(front).f = [F(front).f i];%等级为1的非支配解集
end
end
%上面的代码是为了找出等级最高的非支配解集
%下面的代码是为了给其他个体进行分级
while ~isempty(F(front).f)
Q = []; %存放下一个front集合
for i = 1 : length(F(front).f)%循环当前支配解集中的个体
if ~isempty(individual(F(front).f(i)).p)%个体i有自己所支配的解集
for j = 1 : length(individual(F(front).f(i)).p)%循环个体i所支配解集中的个体
individual(individual(F(front).f(i)).p(j)).n = ...%...表示的是与下一行代码是相连的, 这里表示个体j的被支配个数减1
individual(individual(F(front).f(i)).p(j)).n - 1;
if individual(individual(F(front).f(i)).p(j)).n == 0% 如果q是非支配解集,则放入集合Q中
x(individual(F(front).f(i)).p(j),M + V + 1) = ...%个体染色体中加入分级信息
front + 1;
Q = [Q individual(F(front).f(i)).p(j)];
end
end
end
end
front = front + 1;
F(front).f = Q;
end
[temp,index_of_fronts] = sort(x(:,M + V + 1));%对个体的代表排序等级的列向量进行升序排序 index_of_fronts表示排序后的值对应原来的索引
for i = 1 : length(index_of_fronts)
sorted_based_on_front(i,:) = x(index_of_fronts(i),:);%sorted_based_on_front中存放的是x矩阵按照排序等级升序排序后的矩阵
end
current_index = 0;
%% Crowding distance 计算每个个体的拥挤度
for front = 1 : (length(F) - 1)%这里减1是因为代码55行这里,F的最后一个元素为空,这样才能跳出循环。所以一共有length-1个排序等级
distance = 0;
y = [];
previous_index = current_index + 1;
for i = 1 : length(F(front).f)
y(i,:) = sorted_based_on_front(current_index + i,:);%y中存放的是排序等级为front的集合矩阵
end
current_index = current_index + i;%current_index =i
sorted_based_on_objective = [];%存放基于拥挤距离排序的矩阵
for i = 1 : M
[sorted_based_on_objective, index_of_objectives] = ...
sort(y(:,V + i));%按照目标函数值排序
sorted_based_on_objective = [];
for j = 1 : length(index_of_objectives)
sorted_based_on_objective(j,:) = y(index_of_objectives(j),:);% sorted_based_on_objective存放按照目标函数值排序后的x矩阵
end
f_max = ...
sorted_based_on_objective(length(index_of_objectives), V + i);%fmax为目标函数最大值 fmin为目标函数最小值
f_min = sorted_based_on_objective(1, V + i);
y(index_of_objectives(length(index_of_objectives)),M + V + 1 + i)...%对排序后的第一个个体和最后一个个体的距离设为无穷大
= Inf;
y(index_of_objectives(1),M + V + 1 + i) = Inf;
for j = 2 : length(index_of_objectives) - 1%循环集合中除了第一个和最后一个的个体
next_obj = sorted_based_on_objective(j + 1,V + i);
previous_obj = sorted_based_on_objective(j - 1,V + i);
if (f_max - f_min == 0)
y(index_of_objectives(j),M + V + 1 + i) = Inf;
else
y(index_of_objectives(j),M + V + 1 + i) = ...
(next_obj - previous_obj)/(f_max - f_min);
end
end
end
distance = [];
distance(:,1) = zeros(length(F(front).f),1);
for i = 1 : M
distance(:,1) = distance(:,1) + y(:,M + V + 1 + i);
end
y(:,M + V + 2) = distance;
y = y(:,1 : M + V + 2);
z(previous_index:current_index,:) = y;
end
f = z();%得到的是已经包含等级和拥挤度的种群矩阵 并且已经按等级排序排序
3 竞标赛选择代码
function f = tournament_selection(chromosome, pool_size, tour_size)
[pop, variables] = size(chromosome);%获得种群的个体数量和决策变量数量
rank = variables - 1;%个体向量中排序值所在位置
distance = variables;%个体向量中拥挤度所在位置
%竞标赛选择法,每次随机选择两个个体,优先选择排序等级高的个体,如果排序等级一样,优选选择拥挤度大的个体
for i = 1 : pool_size
for j = 1 : tour_size
candidate(j) = round(pop*rand(1));%随机选择参赛个体
if candidate(j) == 0
candidate(j) = 1;
end
if j > 1
while ~isempty(find(candidate(1 : j - 1) == candidate(j)))%防止两个参赛个体是同一个
candidate(j) = round(pop*rand(1));
if candidate(j) == 0
candidate(j) = 1;
end
end
end
end
for j = 1 : tour_size% 记录每个参赛者的排序等级 拥挤度
c_obj_rank(j) = chromosome(candidate(j),rank);
c_obj_distance(j) = chromosome(candidate(j),distance);
end
min_candidate = ...
find(c_obj_rank == min(c_obj_rank));%选择排序等级较小的参赛者,find返回该参赛者的索引
if length(min_candidate) ~= 1%如果两个参赛者的排序等级相等 则继续比较拥挤度 优先选择拥挤度大的个体
max_candidate = ...
find(c_obj_distance(min_candidate) == max(c_obj_distance(min_candidate)));
if length(max_candidate) ~= 1
max_candidate = max_candidate(1);
end
f(i,:) = chromosome(candidate(min_candidate(max_candidate)),:);
else
f(i,:) = chromosome(candidate(min_candidate(1)),:);
end
end
4、5 交叉 变异代码
function f = genetic_operator(parent_chromosome, M, V, mu, mum, l_limit, u_limit)
[N,m] = size(parent_chromosome);%N是交配池中的个体数量
clear m
p = 1;
was_crossover = 0;%是否交叉标志位
was_mutation = 0;%是否变异标志位
for i = 1 : N%这里虽然循环N次,但是每次循环都会有概率产生2个或者1个子代,所以最终产生的子代个体数量大约是2N个
if rand(1) < 0.9%交叉概率0.9
child_1 = [];
child_2 = [];
parent_1 = round(N*rand(1));
if parent_1 < 1
parent_1 = 1;
end
parent_2 = round(N*rand(1));
if parent_2 < 1
parent_2 = 1;
end
while isequal(parent_chromosome(parent_1,:),parent_chromosome(parent_2,:))
parent_2 = round(N*rand(1));
if parent_2 < 1
parent_2 = 1;
end
end
parent_1 = parent_chromosome(parent_1,:);
parent_2 = parent_chromosome(parent_2,:);
for j = 1 : V
u(j) = rand(1);
if u(j) <= 0.5
bq(j) = (2*u(j))^(1/(mu+1));
else
bq(j) = (1/(2*(1 - u(j))))^(1/(mu+1));
end
child_1(j) = ...
0.5*(((1 + bq(j))*parent_1(j)) + (1 - bq(j))*parent_2(j));
child_2(j) = ...
0.5*(((1 - bq(j))*parent_1(j)) + (1 + bq(j))*parent_2(j));
if child_1(j) > u_limit(j)
child_1(j) = u_limit(j);
elseif child_1(j) < l_limit(j)
child_1(j) = l_limit(j);
end
if child_2(j) > u_limit(j)
child_2(j) = u_limit(j);
elseif child_2(j) < l_limit(j)
child_2(j) = l_limit(j);
end
end
child_1(:,V + 1: M + V) = evaluate_objective(child_1, M, V);
child_2(:,V + 1: M + V) = evaluate_objective(child_2, M, V);
was_crossover = 1;
was_mutation = 0;
else%if >0.9
parent_3 = round(N*rand(1));
if parent_3 < 1
parent_3 = 1;
end
child_3 = parent_chromosome(parent_3,:);
for j = 1 : V
r(j) = rand(1);
if r(j) < 0.5
delta(j) = (2*r(j))^(1/(mum+1)) - 1;
else
delta(j) = 1 - (2*(1 - r(j)))^(1/(mum+1));
end
child_3(j) = child_3(j) + delta(j);
if child_3(j) > u_limit(j) % 条件约束
child_3(j) = u_limit(j);
elseif child_3(j) < l_limit(j)
child_3(j) = l_limit(j);
end
end
child_3(:,V + 1: M + V) = evaluate_objective(child_3, M, V);
was_mutation = 1;
was_crossover = 0;
end% if <0.9
if was_crossover
child(p,:) = child_1;
child(p+1,:) = child_2;
was_cossover = 0;
p = p + 2;
elseif was_mutation
child(p,:) = child_3(1,1 : M + V);
was_mutation = 0;
p = p + 1;
end
end
f = child;交叉算法选择的是模拟二进制交叉,变异算法选择的是多项式变异, 算法的具体过程大家可以在网上查阅一下
8 生成新的种群(精英策略)
function f = replace_chromosome(intermediate_chromosome, M, V,pop)%精英选择策略
[N, m] = size(intermediate_chromosome);
[temp,index] = sort(intermediate_chromosome(:,M + V + 1));
clear temp m
for i = 1 : N
sorted_chromosome(i,:) = intermediate_chromosome(index(i),:);
end
max_rank = max(intermediate_chromosome(:,M + V + 1));
previous_index = 0;
for i = 1 : max_rank
current_index = max(find(sorted_chromosome(:,M + V + 1) == i));
if current_index > pop
remaining = pop - previous_index;
temp_pop = ...
sorted_chromosome(previous_index + 1 : current_index, :);
[temp_sort,temp_sort_index] = ...
sort(temp_pop(:, M + V + 2),'descend');
for j = 1 : remaining
f(previous_index + j,:) = temp_pop(temp_sort_index(j),:);
end
return;
elseif current_index < pop
f(previous_index + 1 : current_index, :) = ...
sorted_chromosome(previous_index + 1 : current_index, :);
else
f(previous_index + 1 : current_index, :) = ...
sorted_chromosome(previous_index + 1 : current_index, :);
return;
end
previous_index = current_index;
end
本例子选择的测试函数是ZDT1, 目标评价函数如下:
function f = evaluate_objective(x, M, V)%%计算每个个体的M个目标函数值
f = [];
f(1) = x(1);
g = 1;
sum = 0;
for i = 2:V
sum = sum + x(i);
end
sum = 9*(sum / (V-1));
g = g + sum;
f(2) = g * (1 - sqrt(x(1) / g));
end
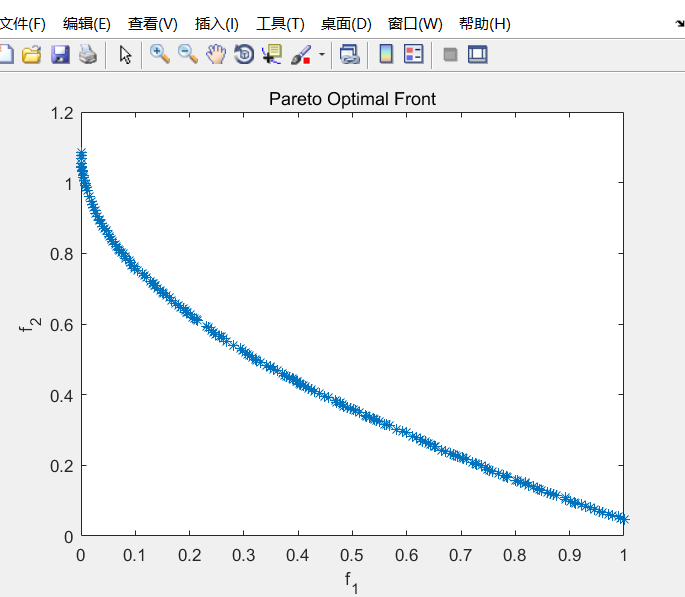
经历500次迭代后的pareto最优解集:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144187.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
