大家好,又见面了,我是你们的朋友全栈君。
- 这是hmily的一个核心,hmily之所以高效就是因为hmily把日志的存储维护操作及confirm,cancel的操作通过Disruptor的异步任务框架的方式执行。关于disruptor的原理如下,我没怎么研究过。后我主要分析hmily是如何使用Disruptor这个框架。
1. DisruptorProvider
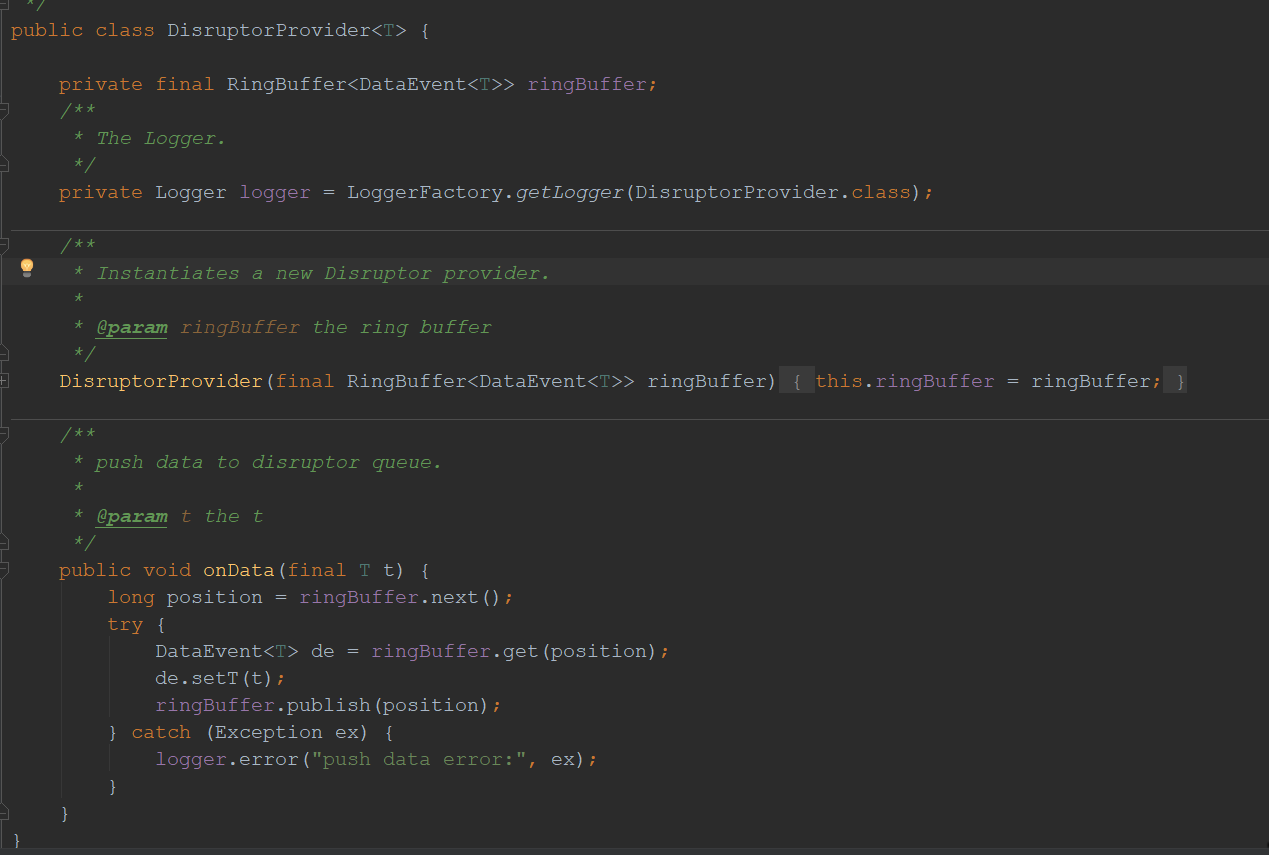
- Disruptor队列提供者。DisruptorProvider实例里面维护了一个Disruptor队列实例ringBuffer。实际上DisruptorProvider的作用就是封装了一下ringBuffer队列,并提供统一的发布入口。也就是生产者调用的入口。
- 首先新建DisruptorProvider实例的时候就传入了一个ringBuffer实例,生产者通过调用data方法将任务发布到ringBuffer上。
- 简单说一下data函数。这是Disruptor 框架发布事件的逻辑,分为三个步骤
- 先从 RingBuffer 获取下一个可以写入的事件的序号;
- 获取对应的事件对象,将业务信息写入事件对象;事件对象Disruptor 要我们自定义,如下hmily定义了一个DataEvent类作为事件对象。事件对象只是一个载体,在生产者生成任务与消费者消费任务时,并不新增与销毁事件对象。事件对象内存储的才是真实被生产(/消费)的业务信息。
- 将事件提交到 RingBuffer;后面消费者就会读取到该position,处理该业务信息。

2. DisruptorProviderManage
-
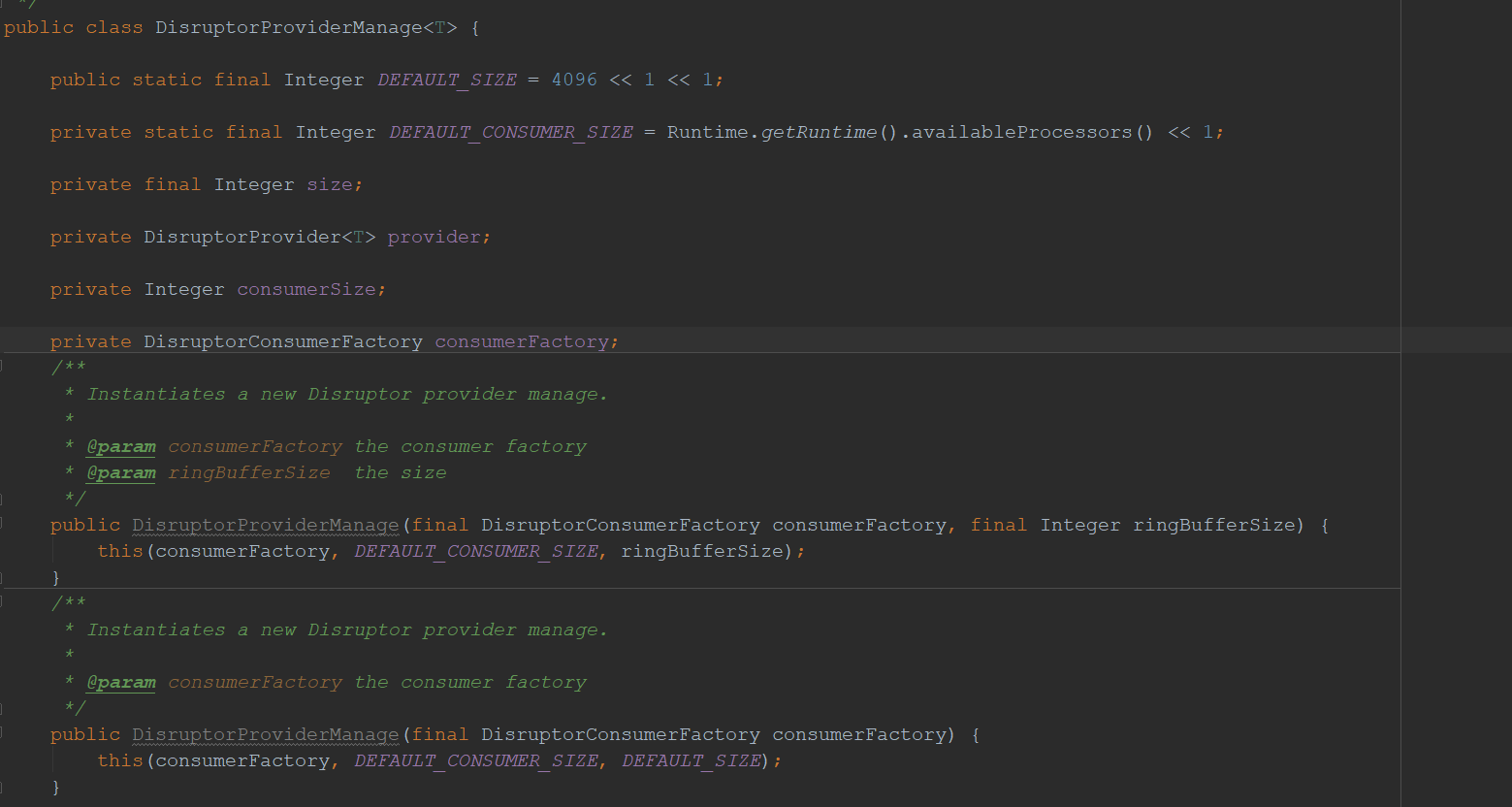
队列管理者。该类负责创建DisruptorProvider实例,也就是Disruptor队列,并提供与维护该队列。可以说如果有一个DisruptorProviderManage实例创建,那么就会有一个Disruptor任务队列。
-
DisruptorProviderManage也是泛型的,它的泛型同DisruptorProvider的泛型一致,是指向被生成与消费业务信息类。
-
这里可以先说一下,每一个加入himly框架的微服务,在启动后都会创建两个DisruptorProviderManage实例,对应的两个业务信息类分别是处理事务日志异步维护及confirm,cancel的异步执行。具体后面再说。
-
我们先来分析一下DisruptorProviderManage内的属性
- DEFAULT_SIZE 队列的默认的大小, 使用时不设定ringbuffer的size默认为该值。另外说一下RingBuffer 大小,得是 2 的 N 次方;个数是2的N次方更有利于基于二进制的计算机进行计算,这涉及到ringbuffer性能。
- DEFAULT_CONSUMER_SIZE 消费者默认个数,这里是设定为JVM可以使用的处理器数量*2。这里的设定我不太理解,为什么要乘以2?
- size 队列大小
- consumerSize 消费者个数
- provide Disruptor队列提供者。创建后提供给外部使用生产任务到ringbuffer队列中。
- factory 消费者工厂类,用于创建消费者去执行任务的。这里的消费处理hmily设计的比较复杂,先按下不表,后面再述。
-
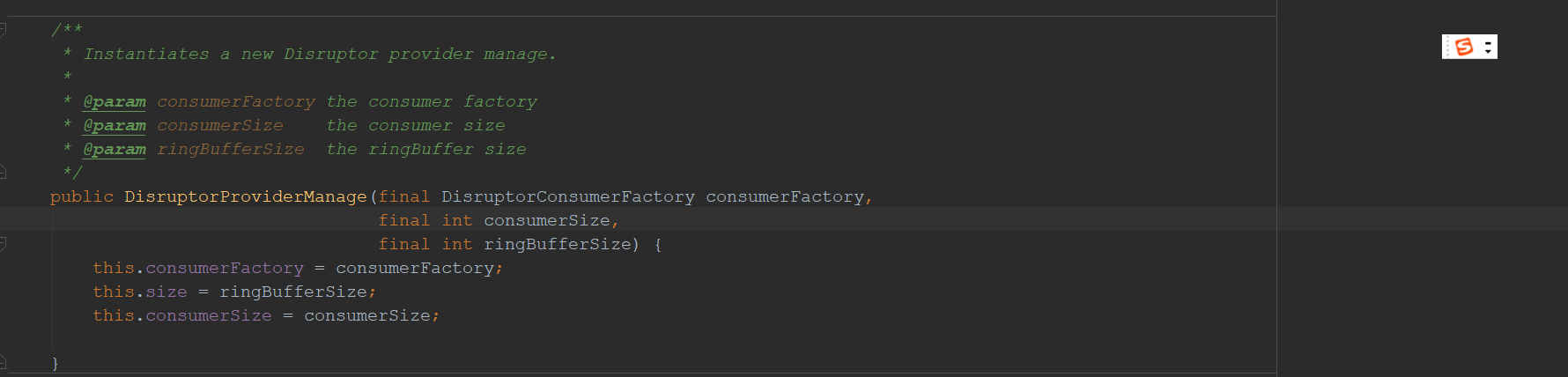
构造器方法就不讲了,就是为了传递如上的参数进来。
-
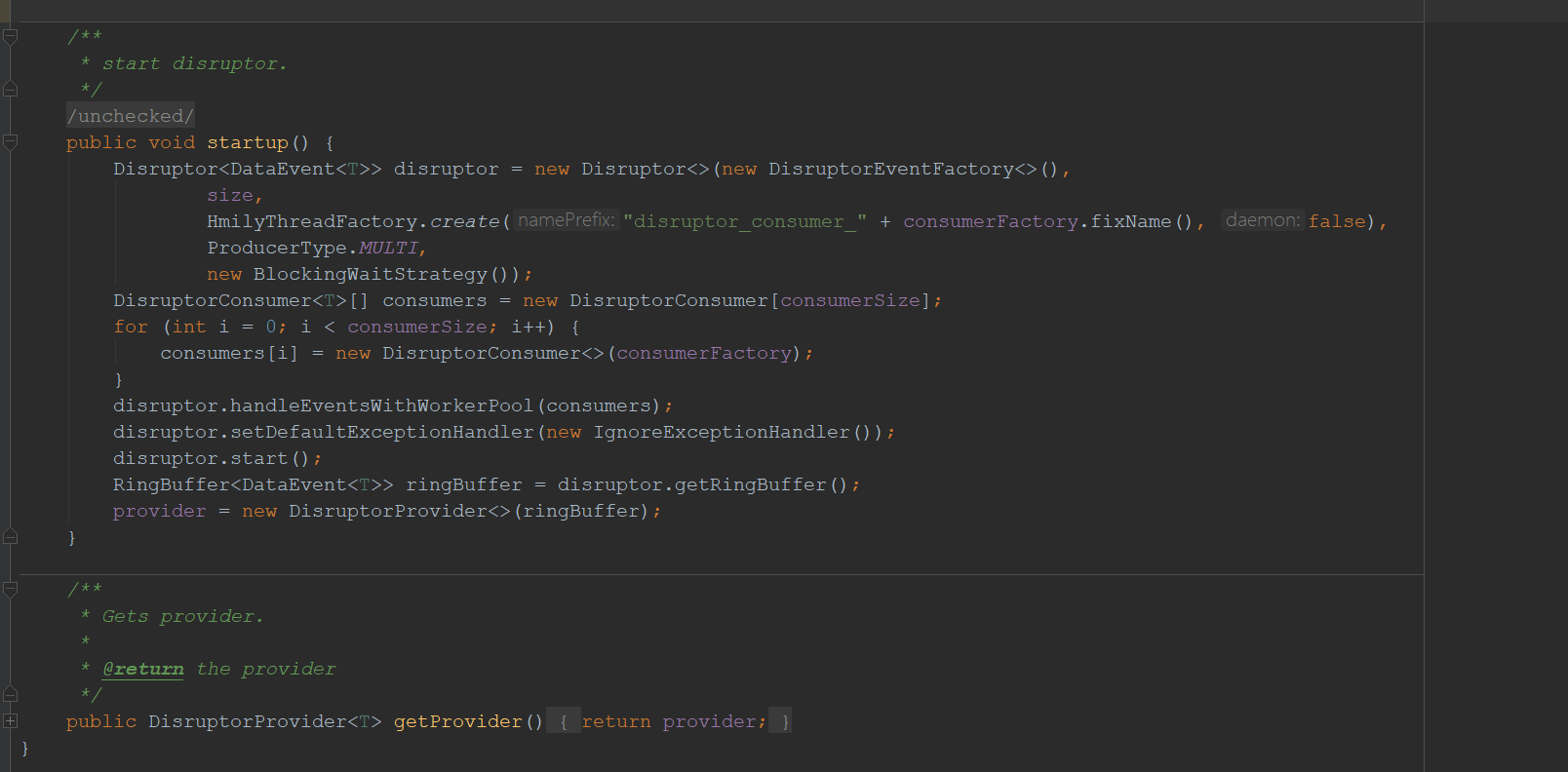
在调用者在创建DisruptorProviderManage实例后,就会调用DisruptorProviderManage的start方法,创建ringbuffer队列。创建ringbuffer的过程下面简单介绍一下。
- 第一步创建disruptor实例,我们看到Disruptor的泛型就是事件对象。我们来看一下Disruptor类的构造器都传入什么参数做了什么。
- 第一个参数是EventFactory(事件对象工厂),负责为disruptor在初始化时提供事件对象(DataEvent)实例
- 第二个参数是ringbuffer的size,这个队列的容量。
- 第三个参数是ThreadFactory,是用于事件处理的线程池,也就是调用消费者处理任务的线程。通过HmilyThreadFactory类生成,关于HmilyThreadFactory类先按下不表。
- 第四个参数是ProducerType.MULTI?不清楚什么意思,允许生产者并发新增任务?
- 第五个参数是WaitStrategy,等待处理策略。就是当ringbuffer的size被存储满了之后,仍然有生产者添加新的任务时应该如何处理。这里采用BlockingWaitStrategy (阻塞策略,没有空间了线程就阻塞着)。BlockingWaitStrategy 是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现。
- 第二步disruptor实例设置消费者集合。关于DisruptorConsumer我们也先按下不表。
- 第三步设置默认异常处理方案为不处理(for why?)。
- 第四步,启动disruptor。
- 第五步获取ringBuffer实例并根据ringBuffer实例创建DisruptorProvider实例。后面的生产者就是通过调用DisruptorProvider实例来新增异步任务的。
- 第一步创建disruptor实例,我们看到Disruptor的泛型就是事件对象。我们来看一下Disruptor类的构造器都传入什么参数做了什么。
-
getProvider方法,返回DisruptorProvider实例供生产者添加异步任务。
-
前面介绍了说有两个DisruptorProviderManage实例,我们来看一下它们是如何发布任务的把。
-
执行confirm,cancel命令的队列
- 定义

- 定义
-
初始化

-
HmilyTransactionHandlerAlbum (真实的业务信息——接口),run方法的实现由生产者来定义,后面消费者会执行这个run方法来实现消费这个业务信息,这是后话了。
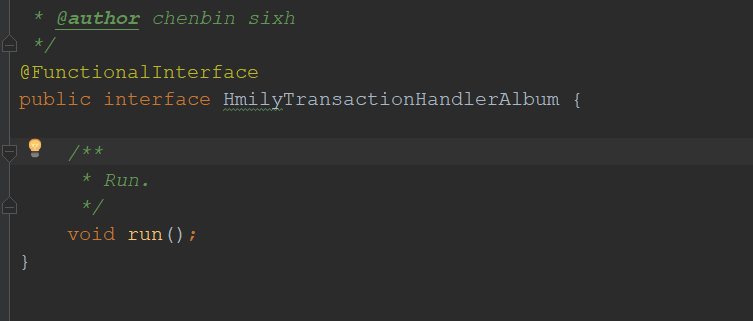
-
生产者发布,如下获取provide,发布这个(java8提供的语法,会自动继承HmilyTransactionHandlerAlbum ,并实现run方法),后面消费者最终调用的也就是run方法(内的 hmilyTransactionExecutor.confirm语句),从而实现异步执行。

-
异步执行日志维护
- 定义

- 初始化
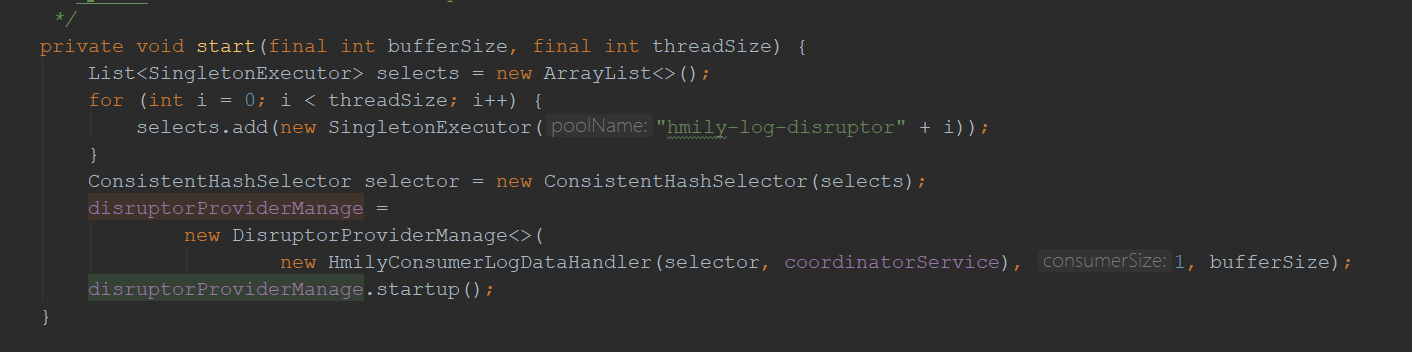
- HmilyTransactionEvent 业务信息载体(事务日志及操作状态——更新,新增或删除)
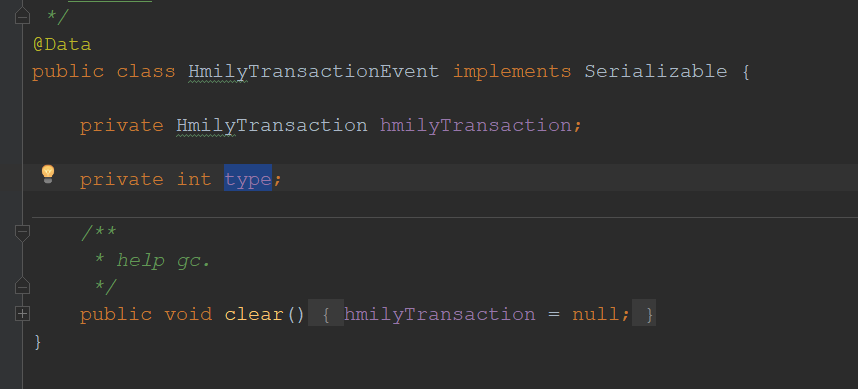
- 生产者使用,这里由封装了一层,但无关大雅。至于消费者是如何使用这个信息的我们后面再说。

- 定义
关于消费者
- 关于消费者,hmily用了一个挺复杂的框架(用到的类很多),但我觉得是挺必要的,我在消费者的搭建这块也学到了挺多的。不过记录起来是挺麻烦的,下面我一一道来。
3. DisruptorConsumer
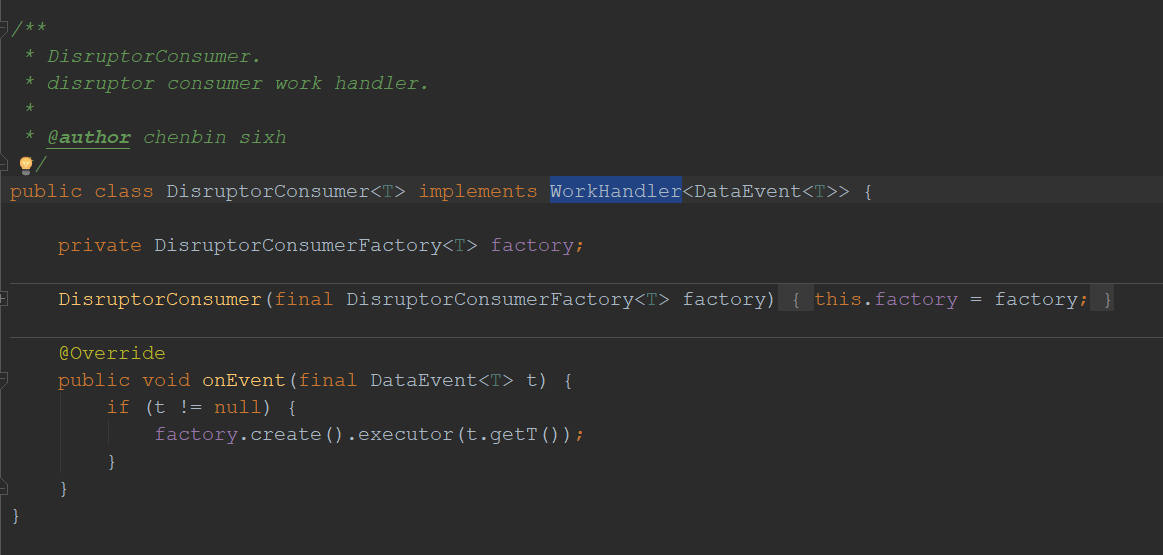
- 如上,Disruptor提供的消费者接口是WorkHandler。hmily在此的实现就是DisruptorConsumer 类。
- 如下,DisruptorConsumer 下并没有直接去执行业务数据,而是又封装了一层DisruptorConsumerFactory (消费者工厂)。这一层封装的作用我以为是为了和泛型T对应。不同的T会有不同的DisruptorConsumer实例及传入对应DisruptorConsumerFactory实现良好的扩展。
4. DisruptorConsumerFactory
- DisruptorConsumerFactory也是一个接口,而且这里又封装了一层AbstractDisruptorConsumerExecutor去真正执行业务信息,这我就不是很理解了。明明在DisruptorConsumer 里直接传入AbstractDisruptorConsumerExecutor不就行了么?或者这是什么设计模式么,存疑待学习

5. AbstractDisruptorConsumerExecutor
- 关于这个抽象类里面不仅定义了executor方法,还定义了一个subscribers集合,看起来这就是在消费者这边做了两层扩展的原因吧,但是作者暂时没使用到这个集合,它的企图我们这边暂时不得而知。
6. HmilyConsumerLogDataHandler
- 是异步维护日志信息时的实现类。继承了AbstractDisruptorConsumerExecutor类及实现了DisruptorConsumerFactory接口。
- 所以在DisruptorConsumer 里面的两层扩展都是这一个类的实例?我觉得可能是这样的,作者有一些企图需要做两层的扩展实现某些需求,但是真的实现只需要一个实现类就可以。这样似乎更清晰?有一种说不上来觉得这种写法挺好的感觉,值得学习一下。定义分层,实现归一
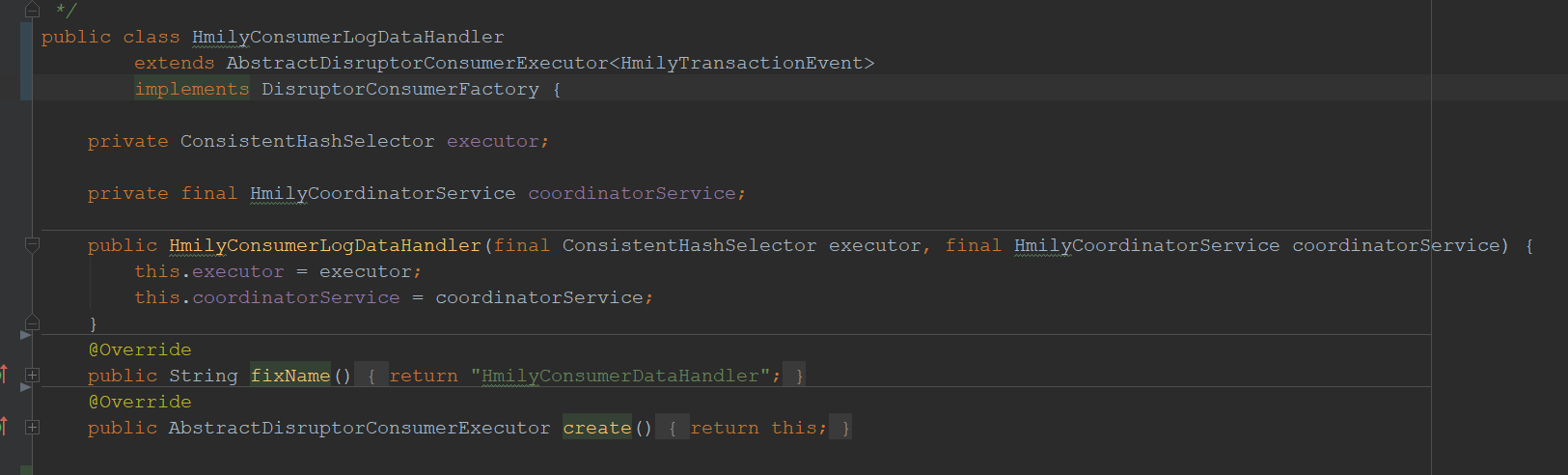
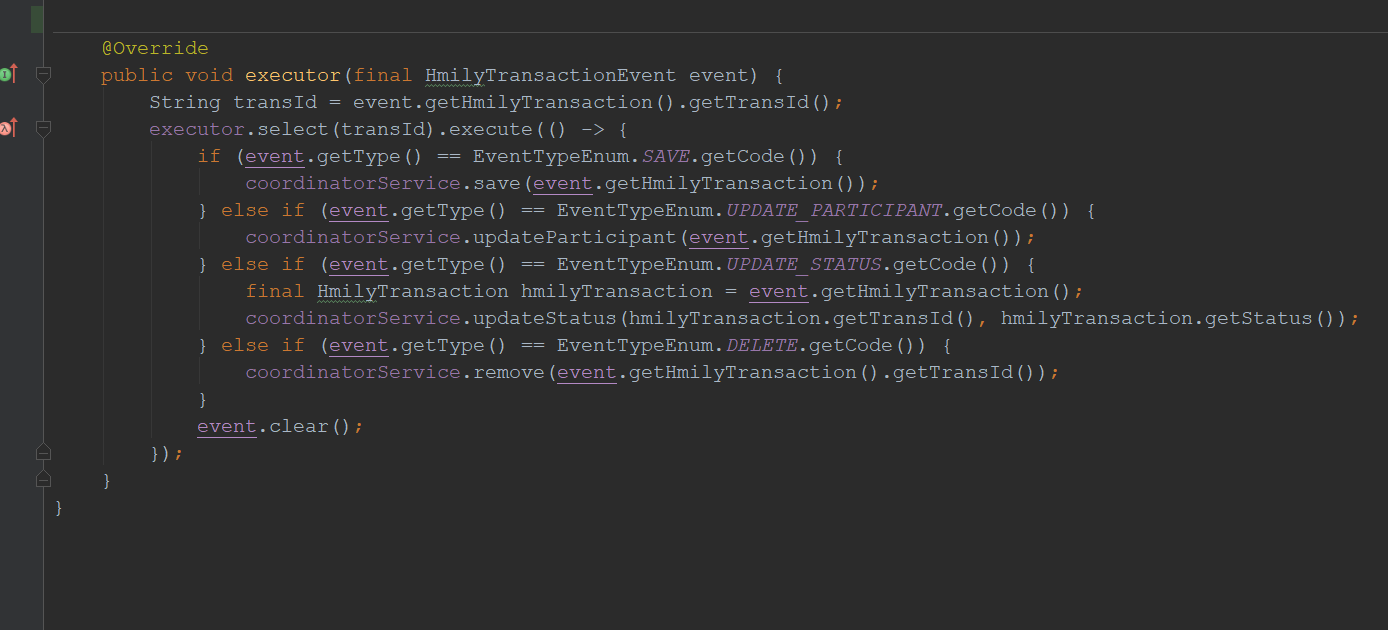
- executor方法里面就是处理业务信息的逻辑了,再往下我们就不深入了,与消费者的框架无关了。
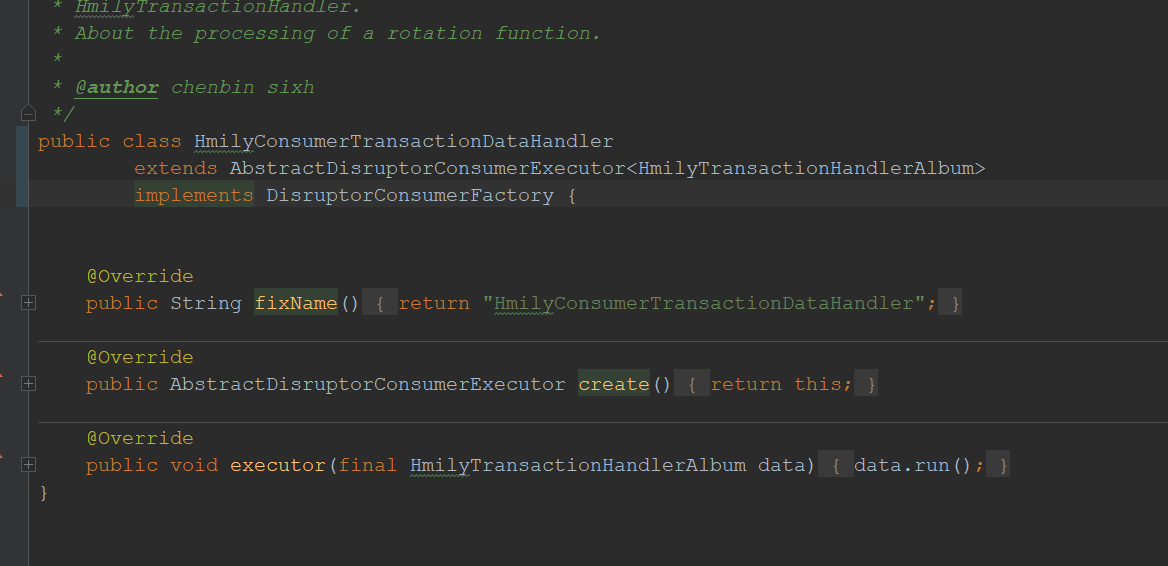
7. HmilyConsumerTransactionDataHandler
- 是异步执行cofrm,cancel的实现类。原理同6
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/143593.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
