大家好,又见面了,我是你们的朋友全栈君。
面试题总结
一基础部分
1.1 集合
1.1.1 fail-fast 与 fail-safe 机制有什么区别


1.1.2 说出ArrayList,Vector, LinkedList的存储性能和特性
ArrayList 采用的是数组形式来保存对象的,这种方式将对象放在连续的位置中,所以最大的缺点就是插入删除时非常麻烦
LinkedList 采用的将对象存放在独立的空间中,而且在每个空间中还保存下一个链接的索引 但是缺点就是查找非常麻烦 要丛第一个索引开始
ArrayList和Vector都是用数组方式存储数据,此数组元素数要大于实际的存储空间以便进行元素增加和插入操作,他们都允许直接用序号索引元素,但是插入数据元素涉及到元素移动等内存操作,所以索引数据快而插入数据慢.
Vector使用了sychronized方法(线程安全),所以在性能上比ArrayList要差些.
LinkedList使用双向链表方式存储数据,按序号索引数据需要前向或后向遍历数据,所以索引数据慢,是插入数据时只需要记录前后项即可,所以插入的速度快.
1.2.3 HashMap
1.2.3.1 HashMap的工作原理是什么
HashMap的底层是用hash数组和单向链表实现的 ,当调用put方法是,首先计算key的hashcode,定位到合适的数组索引,然后再在该索引上的单向链表进行循环遍历用equals比较key是否存在,如果存在则用新的value覆盖原值,如果没有则插入到链表linkedlist的头部。HashMap的两个重要属性是容量capacity和加载因子loadfactor,默认值分布为16和0.75,当容器中的元素个数大于 capacityloadfactor时,容器会进行扩容resize 为2n,在初始化Hashmap时可以对着两个值进行修改,负载因子0.75被证明为是性能比较好的取值,通常不会修改,那么只有初始容量capacity会导致频繁的扩容行为,这是非常耗费资源的操作,所以,如果事先能估算出容器所要存储的元素数量,最好在初始化时修改默认容量capacity,以防止频繁的resize操作影响性能。
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用LinkedList来解决碰撞问题,当发生碰撞了,对象将会储存在LinkedList的下一个节点中。 HashMap在每个LinkedList节点中储存键值对对象。
1.2.3.2HashMap 的 table的容量如何确定?loadFactor 是什么? 该容量如何变化?这种变化会带来什么问题?
HashMap使用的是懒加载,构造完HashMap对象后,只要不进行put 方法插入元素之前,HashMap并不会去初始化或者扩容table。
这个问题可以跟踪一下HashMap的源码就知道了,根据输入的初始化容量(门槛?)的值(先了解HashMap中容量和负载因子的概念,
其实这个和HashMap确定存储地址的算法有关),
先判断是否大于最大容量,最大容量2的30次方,1<<30 =(1073741824),
如果大于此数,初始化容量赋值为1<<30,如果小于此数,调用tableSizeFor方法 使用位运算将初始化容量修改为2的次方数,
都是向大的方向运算,比如输入13,小于2的4次方,那面计算出来桶的初始容量就是16.
1.2.3.3 HashMap 和 HashTable、ConcurrentHashMap 的区别
HashTable
底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
初始size为11,扩容:newsize = olesize2+1
计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
HashMap
底层数组+链表实现,可以存储null键和null值,线程不安全
初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)
当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀
计算index方法:index = hash & (tab.length – 1)
HashMap的初始值还要考虑加载因子:
哈希冲突:若干Key的哈希值按数组大小取模后,如果落在同一个数组下标上,将组成一条Entry链,对Key的查找需要遍历Entry链上的每个元素执行equals()比较。
加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小。
空间换时间:如果希望加快Key查找的时间,还可以进一步降低加载因子,加大初始大小,以降低哈希冲突的概率。
HashMap和Hashtable都是用hash算法来决定其元素的存储,因此HashMap和Hashtable的hash表包含如下属性:
容量(capacity):hash表中桶的数量
初始化容量(initial capacity):创建hash表时桶的数量,HashMap允许在构造器中指定初始化容量
尺寸(size):当前hash表中记录的数量
负载因子(load factor):负载因子等于“size/capacity”。负载因子为0,表示空的hash表,0.5表示半满的散列表,依此类推。轻负载的散列表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)
除此之外,hash表里还有一个“负载极限”,“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。
HashMap和Hashtable的构造器允许指定一个负载极限,HashMap和Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。
“负载极限”的默认值(0.75)是时间和空间成本上的一种折中:
较高的“负载极限”可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作(HashMap的get()与put()方法都要用到查询)
较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销
程序猿可以根据实际情况来调整“负载极限”值。
ConcurrentHashMap
底层采用分段的数组+链表实现,线程安全
通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
Hashtable和HashMap都实现了Map接口,但是Hashtable的实现是基于Dictionary抽象类的。Java5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
HashMap基于哈希思想,实现对数据的读写。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来存储值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞时,对象将会储存在链表的下一个节点中。HashMap在每个链表节点中储存键值对对象。当两个不同的键对象的hashcode相同时,它们会储存在同一个bucket位置的链表中,可通过键对象的equals()方法来找到键值对。如果链表大小超过阈值(TREEIFY_THRESHOLD,8),链表就会被改造为树形结构。
在HashMap中,null可以作为键,这样的键只有一个,但可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该key,也可以表示该key所对应的value为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个key,应该用containsKey()方法来判断。而在Hashtable中,无论是key还是value都不能为null。
Hashtable是线程安全的,它的方法是同步的,可以直接用在多线程环境中。而HashMap则不是线程安全的,在多线程环境中,需要手动实现同步机制。
Hashtable与HashMap另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。
先看一下简单的类图:
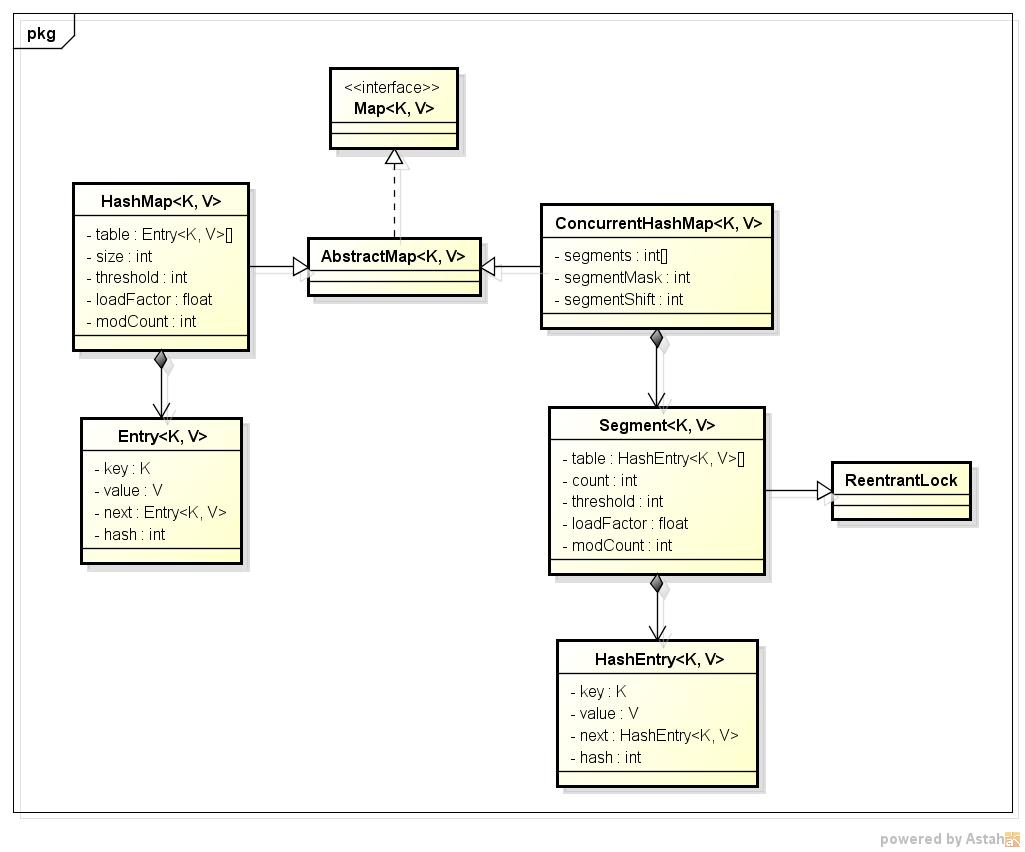
从类图中可以看出来在存储结构中ConcurrentHashMap比HashMap多出了一个类Segment,而Segment是一个可重入锁。
ConcurrentHashMap是使用了锁分段技术来保证线程安全的。
锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap提供了与Hashtable和SynchronizedMap不同的锁机制。Hashtable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的
1.2.3.4 HashMap的遍历方式及效率
1./* HashMap */
2.public static void hashMap(){
3. Map<String,String> hashMap = new HashMap<String, String>();
4.
5. for(int i=0;i<100000;i++)
6. hashMap.put(i+“”, i+“v”);
7.
8. long time = System.currentTimeMillis();
9. System.out.println(“==============方式1:通过遍历keySet()遍历HashMap的value”);
10. Iterator it = hashMap.keySet().iterator();
11. while(it.hasNext()){
12. hashMap.get(it.next());
13. //System.out.println(hashMap.get(it.next()));
14. }
15. System.out.println(“用时:”+(System.currentTimeMillis() – time));
16.
17.
18. time = System.currentTimeMillis();
19. System.out.println(“==============方式2:通过遍历values()遍历HashMap的value”);
20. Collection values = hashMap.values();
21. for(Iterator valIt = values.iterator();valIt.hasNext()?{
22. valIt.next();
23. }
24. System.out.println(“用时:”+(System.currentTimeMillis() – time));
25.
26.
27. time = System.currentTimeMillis();
28. System.out.println(“==============方式3:通过entrySet().iterator()遍历HashMap的key和映射的value”);
29. Iterator<Entry<String, String>> entryIt = hashMap.entrySet().iterator();
30. while(entryIt.hasNext()){
31. Entry<String, String> entry = entryIt.next();
32. entry.getKey();
33. entry.getValue();
34. //System.out.println(“key:”+entry.getKey()+” value:”+entry.getValue());
35. }
36. System.out.println(“用时:”+(System.currentTimeMillis() – time));
37.
38.}
以上代码运行结果如下:
==============方式1:通过遍历keySet()遍历HashMap的value
用时:61
==============方式2:通过遍历values()遍历HashMap的value
用时:7
==============方式3:通过entrySet().iterator()遍历HashMap的key和映射的value
用时:12
第一种方式是遍历key,根据key获取映射的vlaue,需要调用get()方法十万次,肯定是效率不高的。建议在数据量较大时不用此方式遍历hashMap。
第二种方式是获取集合中的values,遍历value。但是在遍历value的时候,获取不到key。建议在只需要获取集合中的value时使用此方式。
第三种方式是获取Entry<K,V>类型的Set集合,遍历这个集合,获取每一个Entry<K,V>,通过getKey()和getValue来获取key和value。Entry<K,V>是HashMap集合中的键值对。这样就就相当于遍历了一遍HashMap中的键值对 。
省去了第一种方式中get()的操作。建议多用此方式来遍历hashMap结合。
public Set keySet() 方法返回值是Map中key值的集合;public Set<Map.Entry<K,V>> entrySet()方法返回值也是返回一个Set集合,此集合的类型为Map.Entry。
Map.Entry是Map声明的一个内部接口,此接口为泛型,定义为Entry<K,V>。它表示Map中的一个实体(一个key-value对)。接口中有getKey(),getValue方法。
HashMap是这样,换成TreeMap道理也一样。
在来说一下Map.Entry接口的使用场合:
因为Map这个类没有继承Iterable接口所以不能直接通过map.iterator来遍历(list,set就是实现了这个接口,所以可以直接这样遍历),所以就只能先转化为set类型,用entrySet()方法,其中set中的每一个元素值就是map中的一个键值对,也就是Map.Entry<K,V>了,然后就可以遍历了。
基本上 就是遍历map的时候才用得着它吧。
1.2.3.5 HashMap、LinkedMap、TreeMap的区别
Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。
Hashtable与 HashMap类似,它继承自Dictionary类,不同的是:它不允许记录的键或者值为空;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了 Hashtable在写入时会比较慢。
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
一般情况下,我们用的最多的是HashMap,HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。
TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
1.2.3.6 “如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?”
当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
1.2.3.7“你了解重新调整HashMap大小存在什么问题吗?”
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在LinkedList中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在LinkedList的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。这个时候,你可以质问面试官,为什么这么奇怪,要在多线程的环境下使用HashMap呢?
1.2.3.8 WeakHashMap 是怎么工作的?
WeakHashMap当系统内存不足时,垃圾收集器会自动的清除没有在任何其他地方被引用的键值对,因此可以作为简单缓存表的解决方案。而HashMap就没有上述功能。但是,如果WeakHashMap的key在系统内持有强引用,那么WeakHashMap就退化为了HashMap,所有的表项都不会被垃圾回收器回收。但是在WeakHashMap中会删除那些已经被GC的键值对在源码中是通过调用expungeStaleEntries函数来完成的,而这个函数只在WeakHashMap的put、get、size()等方法中才进行了调用。
1.2.3.9 LinkedHashMap 和 PriorityQueue 的区别是什么
PriorityQueue 保证最高或者最低优先级的的元素总是在队列头部,但是 LinkedHashMap 维持的顺序是元素插入的顺序。当遍历一个 PriorityQueue 时,没有任何顺序保证,但是 LinkedHashMap 课保证遍历顺序是元素插入的顺序。
1.2.3.10 Hashmap底层,存储因子,hashtable区别,怎么可以变成线程安全的
Key为null总放在数组第一个位置
Hashmap底层是由数组和链表组成的,实际上是一个静态内部类entry的数组,key,value就是存储在entry中的,entry还存储了一个指向自身的next指针,当存储元素时,会计算元素的哈希值并对数组长度取模得到一个int值,这个值就是元素要存储在数组中的位置,如果不同元素计算的存储位置相同,则会将新添加进来的entry存在数组中,并将其next指向之前的entry,形成一个链表来解决hash冲突问题;当要根据key查询元素时,会根据同样方法算出索引位置,然后迭代链表,调用equals方法判断key的相等性,如果返回true返回当前entry的value,否则返回null
存储因子:0.75,元素个数超过容量的0.75倍扩容
区别:
HashTable基于Dictionary类,而HashMap是基于AbstractMap
HashMap的key和value都允许为null,而Hashtable的key和value都不允许为null
Hashtable是同步的,而HashMap是非同步的
怎么实现线程安全:
使用hashtable:hashtable的put,get方法都加了同步关键字synchronized,当一个线程在调用该put方法时,其他线程就会被阻塞,且连get方法也不能用,效率低,锁粒度大
使用ConcurrentHashMap:它包含一个segment数组,将数据分段存储,给每一段数据配一把锁(锁分段),锁粒度小,既安全又高效
创建一个类实现map接口,重写方法:在每个方法内部对有安全问题的代码块加锁
为什么线程不安全(原因解释很复杂,大概理解一下):
存在多个线程同时对map扩容时会导致最终只有一个线程扩容后的数组会赋给table,其他线程的数据可能丢失
1.2.4 HashSet
1.2.4.1 HashSet和TreeSet有什么区别
1、TreeSet 是二叉树实现的,Treeset中的数据是自动排好序的,不允许放入null值。 TreeSet是SortedSet接口的唯一实现类,向TreeSet中加入的应该是同一个类的对象。
2、HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。
3、HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的 String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例 。
1.2.4.2 HashSet 内部是如何工作的
HashSet 的实现其实非常简单,它只是封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT,它是一个静态的 Object 对象。
1.2.4.3 Set 里的元素是不能重复的,那么用什么方法来区分重复与否呢?是用 == 还是 equals()? 它们有何区别?
当使用HashSet时,hashCode方法就会得到调用,判断已经存储在集合中的对象的hash code值是否与增加的对象的hash code值一致:
- 如果不一致,直接加进去;
- 如果一致,再进行equals方法的比较,equals如果返回true,表示对象已经加进去了,就不会再增加新的对象;否则加进去。
1.2.4.4 TreeSet:一个已经构建好的 TreeSet,怎么完成倒排序。
A:自然排序:要在自定义类中实现Comparerable接口 ,并且重写compareTo方法
B:比较器排序:在自定义类中实现Comparetor接口,重写compare方法
1.2.4.5 EnumSet 是什么
Enumset是个虚类,我们只能通过它提供的静态方法来返回Enumset的实现类的实例。使用noneOf方法创建空的EnumSet,使用EnumSet.allOf方法创建一个拥有所有枚举类元素的EnumSet,使用EnumSet.of方法返回拥有部分元素的EnumSet,使用addAll方法,添加一个EnumSet中的所有元素到另外一个EnumSet,使用toArray方法,将EnumSet中的元素存放到数组中去
1.2.4.6 三、Set保证元素唯一底层依赖的两个方法
hashCode和equals来完成的
- 如果元素的hashCode值相同,才会判断equals是否为true
- 如果hashCode的值不同,不会调用equals方法
- 注意:对于判断元素是 否存在,以及删除等操作。依赖的方法是元素的hashCode和equals方法。
1.2.5哈希算法
1.2.5.1 Hashcode 的作用
哈希码是按照某种规则生成的int类型的数值
哈希码并不是完全唯一的。
让同一个类的对象按照自己不同的特征尽量的有不同的哈希码,但不是说不同的对象哈希码就一定不同,也有相同的情况。
hashCode方法的主要作用是为了配合基于散列的集合一起正常运行,这样的散列集合包括HashSet、HashMap以及HashTable。
为什么这么说呢?考虑一种情况,当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(注意:集合中不允许重复的元素存在)
也许大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用 equals方法去逐一比较,效率必然是一个问题。此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的 hashCode方法,得到对应的hashcode值,实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode 值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题。这样一来实际调用 equals方法的次数就大大降低了,说通俗一点:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的 字段等)映射成一个数值,这个数值称作为散列值。
put方法是用来向HashMap中添加新的元素,从put方法的具体实现可知,会先调用hashCode方法得到该元素的hashCode 值,然后查看table中是否存在该hashCode值,如果存在则调用equals方法重新确定是否存在该元素,如果存在,则更新value值,否则将 新的元素添加到HashMap中。从这里可以看出,hashCode方法的存在是为了减少equals方法的调用次数,从而提高程序效率。
如果对于hash表这个数据结构的朋友不清楚,可以参考http://www.cnblogs.com/lchzls/p/6714079.html
有些朋友误以为默认情况下,hashCode返回的就是对象的存储地址,事实上这种看法是不全面的,确实有些JVM在实现时是直接返回对象的存储地址,但是大多时候并不是这样,只能说可能存储地址有一定关联。
可以直接根据hashcode值判断两个对象是否相等吗?肯定是 不可以的,因为不同的对象可能会生成相同的hashcode值。虽然不能根据hashcode值判断两个对象是否相等,但是可以直接根据hashcode 值判断两个对象不等,如果两个对象的hashcode值不等,则必定是两个不同的对象。如果要判断两个对象是否真正相等,必须通过equals方法。
也就是说对于两个对象,
1.如果调用equals方法得到的结果为true,则两个对象的hashcode值必定相等;
2.如果equals方法得到的结果为false,则两个对象的hashcode值不一定不同;
3.如果两个对象的hashcode值不等,则equals方法得到的结果必定为false;
4.如果两个对象的hashcode值相等,则equals方法得到的结果未知。
1.2.5.2 简述一致性 Hash 算法
一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
1、平衡性(Balance)
2、单调性(Monotonicity)
3、分散性(Spread)
4、负载(Load)
普通的哈希算法(也称硬哈希)采用简单取模的方式,将机器进行散列,这在cache环境不变的情况下能取得让人满意的结果,但是当cache环境动态变化时,这种静态取模的方式显然就不满足单调性的要求(当增加或减少一台机子时,几乎所有的存储内容都要被重新散列到别的缓冲区中)。
一致性哈希算法的基本实现原理是将机器节点和key值都按照一样的hash算法映射到一个0~232的圆环上。当有一个写入缓存的请求到来时,计算Key值k对应的哈希值Hash(k),如果该值正好对应之前某个机器节点的Hash值,则直接写入该机器节点,如果没有对应的机器节点,则顺时针查找下一个节点,进行写入,如果超过232还没找到对应节点,则从0开始查找(因为是环状结构)。
1.2.5.3为什么在重写 equals 方法的时候需要重写 hashCode 方法?equals与 hashCode 的异同点在哪里
object对象中的 public boolean equals(Object obj),对于任何非空引用值 x 和 y,当且仅当 x 和 y 引用同一个对象时,此方法才返回 true;
注意:当此方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。如下:
(1)当obj1.equals(obj2)为true时,obj1.hashCode() == obj2.hashCode()必须为true
(2)当obj1.hashCode() == obj2.hashCode()为false时,obj1.equals(obj2)必须为false
如果不重写equals,那么比较的将是对象的引用是否指向同一块内存地址,重写之后目的是为了比较两个对象的value值是否相等。特别指出利用equals比较八大包装对象
(如int,float等)和String类(因为该类已重写了equals和hashcode方法)对象时,默认比较的是值,在比较其它自定义对象时都是比较的引用地址
hashcode是用于散列数据的快速存取,如利用HashSet/HashMap/Hashtable类来存储数据时,都是根据存储对象的hashcode值来进行判断是否相同的。
这样如果我们对一个对象重写了euqals,意思是只要对象的成员变量值都相等那么euqals就等于true,但不重写hashcode,那么我们再new一个新的对象,
当原对象.equals(新对象)等于true时,两者的hashcode却是不一样的,由此将产生了理解的不一致,如在存储散列集合时(如Set类),将会存储了两个值一样的对象,
导致混淆,因此,就也需要重写hashcode()
1.2.5.4 a.hashCode() 有什么用?与 a.equals(b) 有什么关系
1、hashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,hashCode是用来在散列存储结构中确定对象的存储地址的;
2、如果两个对象相同,就是适用于equals(Java.lang.Object) 方法,那么这两个对象的hashCode一定要相同;
3、如果对象的equals方法被重写,那么对象的hashCode也尽量重写,并且产生hashCode使用的对象,一定要和equals方法中使用的一致,否则就会违反上面提到的第2点;
4、两个对象的hashCode相同,并不一定表示两个对象就相同,也就是不一定适用于equals(java.lang.Object) 方法,只能够说明这两个对象在散列存储结构中,如Hashtable,他们“存放在同一个篮子里”。
再归纳一下就是hashCode是用于查找使用的,而equals是用于比较两个对象的是否相等的。
1.2.5.4 hashCode() 和 equals() 方法的重要性体现在什么地方
Java中的HashMap使用hashCode()和equals()方法来确定键值对的索引,当根据键获取值的时候也会用到这两个方法。
如果没有正确的实现这两个方法,两个不同的键可能会有相同的hash值,因此可能会被集合认为是相等的。
而且,这两个方法也用来发现重复元素,所以这两个方法的实现对HashMap的精确性和正确性是至关重要的。
HashMap的很多函数要基于hashCode()方法和equals()方法,hashCode()用来定位要存放的位置,equals()用来判断是否相等。
相等的概念是什么?
Object的equals()只是简单地判断是不是同一个实例,但是有时候我们想要的是逻辑上的相等。比如一个学生类Student,有一个成员变量studentID,只要StudentID相等,不是同一个实例我们也认为是同一个学生。当我们认为判定equals的相等应该是逻辑上的相等而不是只判断是不是内存中的同一个东西的时候,我们就应该重写equals()。而涉及到HashMap的时候,重写了equals()就要重写hashCode()。
总结:
同一个对象(没有发生过修改)无论何时调用hashCode(),得到的返回值必须一样。
hashCode()返回值相等,对象不一定相等,通过hashCode()和equals()必须能唯一确定一个对象。
一旦重写了equals(),就必须重写hashCode()。而且hashCode()生成哈希值的依据应该是equals()中用来比较是否相等的字段。如果两个由equals()规定相等的对象生成的hashCode不等,对于HashMap来说,他们可能分别映射到不同位置,没有调用equals()比较是否相等的机会,两个实际上相等的对象可能被插入到不同位置,出现错误。其他一些基于哈希方法的集合类可能也会有这个问题。
1.2.5.5 如何在父类中为子类自动完成所有的 hashcode 和 equals 实现?这么做有何优劣。
同时复写hashcode和equals方法,优势可以添加自定义逻辑,且不必调用超类的实现。
参照:http://java-min.iteye.com/blog/1416727
1.2.5.6 Object:Object有哪些公用方法?Object类hashcode,equals 设计原则? sun为什么这么设计?Object类的概述
答案:clone,getClass, toString, finalize, equal, hashCode,wait,notify, notifyAll
Object类是所有Java类的祖先。每个类都使用 Object 作为超类。所有对象(包括数组)都实现这个类的方法。
1.2.5.7 可以在 hashcode() 中使用随机数字吗?
不可以。Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。
1.2.5.8
1.2.6 List
1.2.6.1 List, Set, Map三个接口,存取元素时各有什么特点
List与Set都是单列元素的集合,它们有一个功共同的父接口Collection。
Set里面不允许有重复的元素,
存元素:add方法有一个boolean的返回值,当集合中没有某个元素,此时add方法可成功加入该元素时,则返回true;当集合含有与某个元素equals相等的元素时,此时add方法无法加入该元素,返回结果为false。
取元素:没法说取第几个,只能以Iterator接口取得所有的元素,再逐一遍历各个元素。
List表示有先后顺序的集合,
存元素:多次调用add(Object)方法时,每次加入的对象按先来后到的顺序排序,也可以插队,即调用add(int index,Object)方法,就可以指定当前对象在集合中的存放位置。
取元素:方法1:Iterator接口取得所有,逐一遍历各个元素
方法2:调用get(index i)来明确说明取第几个。
Map是双列的集合,存放用put方法:put(obj key,obj value),每次存储时,要存储一对key/value,不能存储重复的key,这个重复的规则也是按equals比较相等。
取元素:用get(Object key)方法根据key获得相应的value。
也可以获得所有的key的集合,还可以获得所有的value的集合,
还可以获得key和value组合成的Map.Entry对象的集合。
List以特定次序来持有元素,可有重复元素。Set 无法拥有重复元素,内部排序。Map 保存key-value值,value可多值。
1.2.6.2 遍历一个 List 有哪些不同的方式
- package com.suwu.listtest;
2.import java.util.List;
3.import java.util.ArrayList;
4.import java.util.Iterator;
5.public class ListTest
6.{
- public static void main(String[] args )
- {
-
List<Integer> list=new ArrayList<Integer>(); -
list.add(new Integer(100)); -
list.add(new Integer(200)); -
list.add(new Integer(54)); -
list.add(new Integer(10242)); -
//遍历方式1---while(it.hasNext()) -
System.out.println("遍历方式1--while(it.hasNext())"); -
Iterator<Integer> it=list.iterator(); -
while(it.hasNext()) -
{ -
System.out.println(it.next()); -
} -
//遍历方式2--get(i) -
System.out.println("遍历方式2--get(i)"); -
for(int i=0;i<list.size();i++) -
{ -
System.out.println(list.get(i)); -
} -
//遍历方式3--Object o -
System.out.println("遍历方式3--Object o"); -
for(Object o:list) -
{ -
System.out.println(o); -
} - }
34.}
1.2.6.3 LinkedList 是单向链表还是双向链表
Linkedlist,双向链表,优点,增加删除,用时间很短,但是因为没有索引,对索引的操作,比较麻烦,只能循环遍历,但是每次循环的时候,都会先判断一下,这个索引位于链表的前部分还是后部分,每次都会遍历链表的一半 ,而不是全部遍历。
双向链表,都有一个previous和next, 链表最开始的部分都有一个fiest和last 指向第一个元素,和最后一个元素。增加和删除的时候,只需要更改一个previous和next,就可以实现增加和删除,所以说,LinkedList对于数据的删除和增加相当的方便。
1.2.6.4 插入数据时,ArrayList, LinkedList, Vector谁速度较快?
ArrayList 和Vector他们底层的实现都是一样的,都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢。
Vector中的方法由于添加了synchronized修饰,因此Vector是线程安全的容器,但性能上较ArrayList差,因此已经是Java中的遗留容器。
LinkedList使用双向链表实现存储(将内存中零散的内存单元通过附加的引用关联起来,形成一个可以按序号索引的线性结构,这种链式存储方式与数组的连续存储方式相比,内存的利用率更高),按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
Vector属于遗留容器(Java早期的版本中提供的容器,除此之外,Hashtable、Dictionary、BitSet、Stack、Properties都是遗留容器),已经不推荐使用,但是由于ArrayList和LinkedListed都是非线程安全的,如果遇到多个线程操作同一个容器的场景,则可以通过工具类Collections中的synchronizedList方法将其转换成线程安全的容器后再使用(这是对装潢模式的应用,将已有对象传入另一个类的构造器中创建新的对象来增强实现)。
1.2.6.5ArrayList 和 HashMap 的默认大小是多数
答案:hashMap为16,ArrayList为10. 但是ArrayList比较特殊,只是初始化了10个空的数组
1.2.6.6 ArrayList 和 LinkedList 的区别,什么时候用 ArrayList?
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
ArrayList是实现了基于动态数组的数据结构
ArrayList它是由数组后推得到的;而LindedLsit是由常规的双向链表实现的,每个元素都包含了数据和指向前后元素的句柄。正是由于这个原因,假如想在一个列表中进行大量的插入和删除操作,那么LindedList无疑是最恰当的选择,如果是想频繁的遍历链表,那么ArrayList的速度要快上很多。所以根据具体使用场合,选择恰当的数据结构能大大提高程序的效率。
1.2.6.7ArrayList如何实现扩容
在JDK1.7中,如果通过无参构造的话,初始数组容量为0,当真正对数组进行添加时,才真正分配容量。
每次按照1.5倍(位运算)的比率通过copeOf的方式扩容。
在JKD1.6中,如果通过无参构造的话,初始数组容量为10.每次通过copeOf的方式扩容后容量为原来的1.5倍加1.以上就是动态扩容的原理。
1.2.6.8 Array 和 ArrayList 有何区别?什么时候更适合用Array
存储内容比较:
Array数组可以包含基本类型和对象类型,
ArrayList却只能包含对象类型。
但是需要注意的是:Array数组在存放的时候一定是同种类型的元素。ArrayList就不一定了,因为ArrayList可以存储Object。
空间大小比较:
它的空间大小是固定的,空间不够时也不能再次申请,所以需要事前确定合适的空间大小。
ArrayList的空间是动态增长的,如果空间不够,它会创建一个空间比原空间大一倍的新数组,然后将所有元素复制到新数组中,接着抛弃旧数组。而且,每次添加新的元素的时候都会检查内部数组的空间是否足够。(比较麻烦的地方)。
方法上的比较:
ArrayList作为Array的增强版,当然是在方法上比Array更多样化,比如添加全部addAll()、删除全部removeAll()、返回迭代器iterator()等。
适用场景:
如果想要保存一些在整个程序运行期间都会存在而且不变的数据,我们可以将它们放进一个全局数组里,但是如果我们单纯只是想要以数组的形式保存数据,而不对数据进行增加等操作,只是方便我们进行查找的话,那么,我们就选择ArrayList。而且还有一个地方是必须知道的,就是如果我们需要对元素进行频繁的移动或删除,或者是处理的是超大量的数据,那么,使用ArrayList就真的不是一个好的选择,因为它的效率很低,使用数组进行这样的动作就很麻烦,那么,我们可以考虑选择LinkedList。
1.2.6.9 一句代码实现list元素去重
List out= new ArrayList(new HashSet(in));
1.2.6.10
1.2.7 Map
1.2.7.1 Map 接口提供了哪些不同的集合视图
Map接口在Java集合中提供三个集合视图:
(1)Set keyset():返回map中包含的所有key的一个Set视图。集合是受map支持的,map的变化会在集合中反映出来,反之亦然。当一个迭代器正在 遍历一个集合时,若map被修改了(除迭代器自身的移除操作以外),迭代器的结果会变为未定义。
(2)Collection values():返回一个map中包含的所有value的一个Collection视图。这个collection受map支持的,map的变化会在 collection中反映出来,反之亦然。当一个迭代器正在遍历一个collection时,若map被修改了(除迭代器自身的移除操作以外),迭代器 的结果会变为未定义。
(3)Set<Map.Entry<K,V>> entrySet():返回一个map钟包含的所有映射的一个集合视图。这个集合受map支持的,map的变化会在collection中反映出来,反之 亦然。当一个迭代器正在遍历一个集合时,若map被修改了(除迭代器自身的移除操作,以及对迭代器返回的entry进行setValue外),迭代器的结 果会变为未定义。
以上集合都支持通过Iterator的Remove、Set.remove、removeAll、retainAll和clear操作进行元素 移除,从map中移除对应的映射。它不支持add和addAll操作。
1.2.7.2为什么 Map 接口不继承 Collection 接口
尽管Map接口和它的实现也是集合框架的一部分,但Map不是集合,集合也不是Map。因此,Map继承Collection毫无意义,反之亦然。
如果Map继承Collection接口,那么元素去哪儿?Map包含key-value对,它提供抽取key或value列表集合的方法,但是它不适合“一组对象”规范。
1.2.7.3Hashmap和hashtable的区别,hashmap的底层以及怎么变成线程安全
区别比较:

HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
1.2.8 Conllections
而Collections则是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。
Collections是个java.util下的类,它包含有各种有关集合操作的静态方法。
collections 此类完全由在 collection 上进行操作或返回 collection 的静态方法组成。它包含在 collection 上操作的多态算法,即“包装器”,包装器返回由指定 collection 支持的新 collection,以及少数其他内容。 如果为此类的方法所提供的 collection 或类对象为 null,则这些方法都会抛出 NullPointerException。
1.2.9为什么集合类没有实现Cloneable和Serializable接口?
为什么集合类没有实现Cloneable和Serializable接口?
答:克隆(cloning)或者序列化(serialization)的语义和含义是跟具体的实现相关的。因此应该由集合类的具体实现类来决定如何被克隆或者序列化
一些解释:
(1)什么是克隆?
克隆是把一个对象里面的属性值,复制给另一个对象。而不是对象引用的复制
(2)实现Serializable序列化的作用
1.将对象的状态保存在存储媒体中一边可以在以后重写创建出完全相同的副本
2.按值将对象从一个应用程序域法相另一个应用程序域
实现Serializable接口的作用就是可以把对象存到字节流,然后可以恢复。所以你想你的对象没有序列化,怎么才能在网络传输呢?要网络传输就得转为字节流,所以在分布式应用中,你就得实现序列化。如果你不需要分布式应用,那就没必要实现序列化
1.2.10 集合扩容长度
ArrayList、Vector 默认初始容量为10
Vector加载因子1(元素个数超过容量长度),扩容增量为:原容量的1倍;10—>20—>40
ArrayList原容量的0.5倍+1,10—>16
HashSet,HashMap默认初始容量为16,加载因子0.75(元素长度超过容量长度的0.75倍),扩容增量1倍;16—>32
补充:
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便,其中一种实现链表的数组
哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置
1.2 线程
1.2.1 Thread 常用的方法
答案

1.2.2 volatile与synchronized的区别,底层实现
首先两者都是用来确保数据的一致性的,volatile它能够使变量在值发生改变时尽快让其他线程知道,为什么要这么做呢?编译器为了加快程序运行速度,对一些变量的写操作会现在寄存器或者是cpu缓存上进行,最后才写入内存,这个过程,变量的新值对其他线程是不可见的,而volatile的作用就是使它修饰的变量的读写操作都必须在内存中进行
区别:
Volatile本质是告诉jvm当前变量在寄存器中的值是不安全的需要从内存中读取,sychronized则是锁定当前变量,只有当前线程可以访问到该变量其他线程被阻塞
Volatile只能作用于变量,synchronized则是可以使用在变量和方法上
Volatile仅能实现变量的修改可见性,但不具备原子特性,而synchronized则可以保证变量的修改可见性和原子性
volatile不会造成线程的阻塞,而synchronized可能会造成线程的阻塞
volatile标记的变量不会被编译器优化,而synchronized标记的变量可以被编译器优化
补充:
因此,在使用volatile关键字时要慎重,并不是只要简单类型变量使用volatile修饰,对这个变量的所有操作都是原来操作,当变量的值由自身的上一个决定时,如n=n+1、n++ 等,volatile关键字将失效,只有当变量的值和自身上一个值无关时对该变量的操作才是原子级别的,如n = m + 1,这个就是原级别的。所以在使用volatile关键时一定要谨慎,如果自己没有把握,可以使用synchronized来代替volatile
1.2.2 竞态条件,临界区
当两个线程竞争同一资源时,如果对资源的访问顺序敏感,就称存在竞态条件。导致竞态条件发生的代码区称作临界区。
1.2.3你是如何调用 wait()方法的?使用 if 块还是循环?为什么?
wait() 方法应该在循环调用,因为当线程获取到 CPU 开始执行的时候,其他条件可能还没有满足,所以在处理前,循环检测条件是否满足会更好。下面是一段标准的使用 wait 和 notify 方法的代码:
// The standard idiom for using the wait method
synchronized (obj) {
while (condition does not hold)
obj.wait(); // (Releases lock, and reacquires on wakeup)
… // Perform action appropriate to condition
}
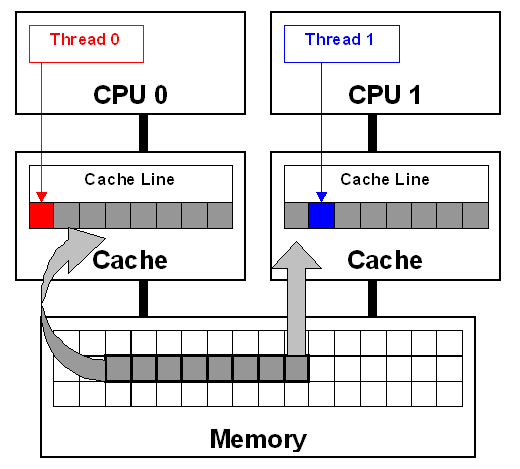
1.2.4 多綫程环境下的伪共享
伪共享是多线程系统(每个处理器有自己的局部缓存)中一个众所周知的性能问题。伪共享发生在不同处理器的上的线程对变量的修改依赖于相同的缓存行,
如下图所示:
1.2.5 什么是 Busy spin?我们为什么要使用它?
Busy spin 是一种在不释放 CPU 的基础上等待事件的技术。它经常用于避免丢失 CPU 缓存中的数据(如果线程先暂停,之后在其他CPU上运行就会丢失)。所以,如果你的工作要求低延迟,并且你的线程目前没有任何顺序,这样你就可以通过循环检测队列中的新消息来代替调用 sleep() 或 wait() 方法。它唯一的好处就是你只需等待很短的时间,如几微秒或几纳秒。LMAX 分布式框架是一个高性能线程间通信的库,该库有一个 BusySpinWaitStrategy 类就是基于这个概念实现的,使用 busy spin 循环 EventProcessors 等待屏障。
1.2.6 什么是线程局部变量?
线程局部变量是局限于线程内部的变量,属于线程自身所有,不在多个线程间共享。Java 提供 ThreadLocal 类来支持线程局部变量,是一种实现线程安全的方式。但是在管理环境下(如 web 服务器)使用线程局部变量的时候要特别小心,在这种情况下,工作线程的生命周期比任何应用变量的生命周期都要长。任何线程局部变量一旦在工作完成后没有释放,Java 应用就存在内存泄露的风险。
1.2.7 Java 中 sleep 方法和 wait 方法的区别?
虽然两者都是用来暂停当前运行的线程,但是 sleep() 实际上只是短暂停顿,因为它不会释放锁,而 wait() 意味着条件等待,这就是为什么该方法要释放锁,因为只有这样,其他等待的线程才能在满足条件时获取到该锁。
1.2.8 什么是线程
线程,有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的相互制约,致使线程在运行中呈现出间断性。线程也有就绪、阻塞和运行三种基本状态。就绪状态是指线程具备运行的所有条件,逻辑上可以运行,在等待处理机;运行状态是指线程占有处理机正在运行;阻塞状态是指线程在等待一个事件(如某个信号量),逻辑上不可执行。每一个程序都至少有一个线程,若程序只有一个线程,那就是程序本身。
线程是程序中一个单一的顺序控制流程。进程内有一个相对独立的、可调度的执行单元,是系统独立调度和分派CPU的基本单位指令运行时的程序的调度单位。在单个程序中同时运行多个线程完成不同的工作,称为多线程。
1.2.9 多线程的优点 缺点
为了解决负载均衡问题,充分利用CPU资源.为了提高CPU的使用率,采用多线程的方式去同时完成几件事情而不互相干扰.为了处理大量的IO操作时或处理的情况需要花费大量的时间等等,比如:读写文件,视频图像的采集,处理,显示,保存等
多线程的好处:
1.使用线程可以把占据时间长的程序中的任务放到后台去处理
2.用户界面更加吸引人,这样比如用户点击了一个按钮去触发某件事件的处理,可以弹出一个进度条来显示处理的进度
3.程序的运行效率可能会提高
4.在一些等待的任务实现上如用户输入,文件读取和网络收发数据等,线程就比较有用了.
多线程的缺点:
1.如果有大量的线程,会影响性能,因为操作系统需要在它们之间切换.
2.更多的线程需要更多的内存空间
3.线程中止需要考虑对程序运行的影响.
4.通常块模型数据是在多个线程间共享的,需要防止线程死锁情况的发生
1.2.10 多线程的实现方式
https://blog.csdn.net/king_kgh/article/details/78213576 这是4种实现方式的介绍
1.继承Thread类,重写run方法
2.实现Runnable接口,重写run方法,实现Runnable接口的实现类的实例对象作为Thread构造函数的target
3.通过Callable和FutureTask创建线程
4.通过线程池创建线程
前面两种可以归结为一类:无返回值,原因很简单,通过重写run方法,run方式的返回值是void,所以没有办法返回结果
后面两种可以归结成一类:有返回值,通过Callable接口,就要实现call方法,这个方法的返回值是Object,所以返回的结果可以放在Object对象中
1.2.11 线程安全
线程安全是多线程编程时的计算机程序代码中的一个概念。在拥有共享数据的多条线程并行执行的程序中,线程安全的代码会通过同步机制保证各个线程都可以正常且正确的执行,不会出现数据污染等意外情况。
1.2.12 多线程中的忙循换
忙循环就是程序员用循环让一个线程等待,不像传统方法wait(), sleep() 或 yield() 它们都放弃了CPU控制,而忙循环不会放弃CPU,它就是在运行一个空循环。这么做的目的是为了保留CPU缓存,在多核系统中,一个等待线程醒来的时候可能会在另一个内核运行,这样会重建缓存。为了避免重建缓存和减少等待重建的时间就可以使用它了。
1.2.13理解ThreadLocal(线程局部变量)
ThreadLocal是什么呢?其实ThreadLocal并非是一个线程的本地实现版本,它并不是一个Thread,而是threadlocalvariable(线程局部变量)。也许把它命名为ThreadLocalVar更加合适。线程局部变量(ThreadLocal)其实的功用非常简单,就是为每一个使用该变量的线程都提供一个变量值的副本,是Java中一种较为特殊的线程绑定机制,是每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突。
从线程的角度看,每个线程都保持一个对其线程局部变量副本的隐式引用,只要线程是活动的并且 ThreadLocal 实例是可访问的;在线程消失之后,其线程局部实例的所有副本都会被垃圾回收(除非存在对这些副本的其他引用)。
通过ThreadLocal存取的数据,总是与当前线程相关,也就是说,JVM 为每个运行的线程,绑定了私有的本地实例存取空间,从而为多线程环境常出现的并发访问问题提供了一种隔离机制。
ThreadLocal是如何做到为每一个线程维护变量的副本的呢?其实实现的思路很简单,在ThreadLocal类中有一个Map,用于存储每一个线程的变量的副本。
概括起来说,对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
API:
ThreadLocal() 创建一个线程本地变量。
T get() 返回此线程局部变量的当前线程副本中的值,如果这是线程第一次调用该方法,则创建并初始化此副本。
protected T initialValue() 返回此线程局部变量的当前线程的初始值。最多在每次访问线程来获得每个线程局部变量时调用此方法一次,即线程第一次使用 get() 方法访问变量的时候。如果线程先于 get 方法调用 set(T) 方法,则不会在线程中再调用 initialValue 方法。
若该实现只返回 null;如果程序员希望将线程局部变量初始化为 null 以外的某个值,则必须为 ThreadLocal 创建子类,并重写此方法。通常,将使用匿名内部类。initialValue 的典型实现将调用一个适当的构造方法,并返回新构造的对象。
void remove() 移除此线程局部变量的值。这可能有助于减少线程局部变量的存储需求。如果再次访问此线程局部变量,那么在默认情况下它将拥有其 initialValue。
void set(T value) 将此线程局部变量的当前线程副本中的值设置为指定值。许多应用程序不需要这项功能,它们只依赖于 initialValue() 方法来设置线程局部变量的值。程序中一般都重写initialValue方法,以给定一个特定的初始值。
ThreadLocal使用场合主要解决多线程中数据数据因并发产生不一致问题。ThreadLocal为每个线程的中并发访问的数据提供一个副本,通过访问副本来运行业务,这样的结果是耗费了内存,单大大减少了线程同步所带来性能消耗,也减少了线程并发控制的复杂度。
ThreadLocal不能使用原子类型,只能使用Object类型。ThreadLocal的使用比synchronized要简单得多。
ThreadLocal和Synchonized都用于解决多线程并发访问。但是ThreadLocal与synchronized有本质的区别。synchronized是利用锁的机制,使变量或代码块在某一时该只能被一个线程访问。而ThreadLocal为每一个线程都提供了变量的副本,使得每个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享。而Synchronized却正好相反,它用于在多个线程间通信时能够获得数据共享。
Synchronized用于线程间的数据共享,而ThreadLocal则用于线程间的数据隔离。
当然ThreadLocal并不能替代synchronized,它们处理不同的问题域。Synchronized用于实现同步机制,比ThreadLocal更加复杂。
ThreadLocal使用的一般步骤
1、在多线程的类(如ThreadDemo类)中,创建一个ThreadLocal对象threadXxx,用来保存线程间需要隔离处理的对象xxx。
2、在ThreadDemo类中,创建一个获取要隔离访问的数据的方法getXxx(),在方法中判断,若ThreadLocal对象为null时候,应该new()一个隔离访问类型的对象,并强制转换为要应用的类型。
3、在ThreadDemo类的run()方法中,通过getXxx()方法获取要操作的数据,这样可以保证每个线程对应一个数据对象,在任何时刻都操作的是这个对象。
1.2.14 线程通信与进程通信的区别
每个进程有自己的地址空间。两个进程中的地址即使值相同,实际指向的位置也不同。进程间通信一般通过操作系统的公共区进行。
同一进程中的线程因属同一地址空间,可直接通信。
不仅是系统内部独立运行的实体,而且是独立竞争资源的实体。
线程也被称为轻权进程,同一进程的线程共享全局变量和内存,使得线程之间共享数据很容易也很方便,但会带来某些共享数据的互斥问题。
许对程序为了提高效率也都是用了线程来编写。
父子进程的派生是非常昂贵的,而且父子进程的通讯需要ipc或者其他方法来实现,比较麻烦。而线程的创建就花费少得多,并且同一进程内的线程共享全局存储区,所以通讯方便。
线程的缺点也是由它的优点造成的,主要是同步,异步和互斥的问题,值得在使用的时候小心设计。
只有进程间需要通信,同一进程的线程share地址空间,没有通信的必要,但要做好同步/互斥mutex,保护共享的全局变量。线程拥有自己的栈。同步/互斥是原语primitives.
而进程间通信无论是信号,管道pipe还是共享内存都是由操作系统保证的,是系统调用.
线程间通信:由于多线程共享地址空间和数据空间,所以多个线程间的通信是一个线程的数据可以直接提供给其他线程使用,而不必通过操作系统(也就是内核的调度)。
进程间的通信则不同,它的数据空间的独立性决定了它的通信相对比较复杂,需要通过操作系统。以前进程间的通信只能是单机版的,现在操作系统都继承了基于套接字(socket)的进程间的通信机制。这样进程间的通信就不局限于单台计算机了,实现了网络通信。
一、进程间的通信方式
管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
有名管道 (namedpipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
信号量(semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
消息队列( messagequeue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
信号 (sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
共享内存(shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
套接字(socket ) : 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
二、线程间的通信方式
锁机制:包括互斥锁、条件变量、读写锁
*互斥锁提供了以排他方式防止数据结构被并发修改的方法。
*读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
*条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
信号量机制(Semaphore):包括无名线程信号量和命名线程信号量
信号机制(Signal):类似进程间的信号处理
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
1.2.15什么是多线程环境下的伪共享(false sharing)?
伪共享是多线程系统(每个处理器有自己的局部缓存)中一个众所周知的性能问题。伪共享发生在不同处理器上的线程对变量的修改依赖于相同的缓存行
小知识点:
1.共享就是一个内存区域的数据被多个处理器访问,伪共享就是不是真的共享。
这里的共享这个概念是基于逻辑层面的。实际上伪共享与共享在cache line 上实际都是共享的。
2.CPU访问的数据都是从cache line 中读取的。如果cpu 在cache 中找不到需要的变量,则称缓存未命中。
未命中时,需要通过总线从内存中读取进cache 中。每次读取的内存大小就是一个cache line 的大小。
3.如果多个CPU访问的不同内存变量被装载到了同一个cache line 中,则从程序逻辑层上讲,并没有共享变量,
但实际上在cache line 上他们是共享访问的,这个就是典型的伪共享。
4.伪共享与共享 在 cache line 的层面上必须都是共享的。多个CPU对共享内存的访问安全通过缓存一致性来保证。
5.伪共享问题很难被发现,因为线程可能访问完全不同的全局变量,内存中却碰巧在很相近的位置上。如其他诸多的并发问题,避免伪共享的最基本方式是仔细审查代码,根据缓存行来调整你的数据结构。
1.2.16 同步和异步有何异同,在什么情况下分别使用他们?举例说明
如果数据将在线程间共享。例如正在写的数据以后可能被另一个线程读到,或者正在读的数据可能已经被另一个线程写过了,那么这些数据就是共享数据,必须进行同步存取。
当应用程序在对象上调用了一个需要花费很长时间来执行的方法,并且不希望让程序等待方法的返回时,就应该使用异步编程,在很多情况下采用异步途径往往更有效率。
Java中交互方式分为同步和异步两种:
同步交互:指发送一个请求,需要等待返回,然后才能够发送下一个请求,有个等待过程;
异步交互:指发送一个请求,不需要等待返回,随时可以再发送下一个请求,即不需要等待。
区别:一个需要等待,一个不需要等待,在部分情况下,我们的项目开发中都会优先选择不需要等待的异步交互方式。
哪些情况建议使用同步交互呢?比如银行的转账系统,对数据库的保存操作等等,都会使用同步交互操作,其余情况都优先使用异步交互
1.2.17在线程中你怎么处理不可捕捉异常
为了保证主线程不被阻塞,线程之间基本相互隔离,所以线程之间不论是异常还是通信都不共享。当然,因为你抓异常是主线程,而异常是在子线程出现,可以用thread.setUncaughtExceptionHandler()去处理线程的异常。在Thread中,Java提供了一个setUncaughtExceptionHandler的方法来设置线程的异常处理函数,你可以把异常处理函数传进去,当发生线程的未捕获异常的时候,由JVM来回调执行。类似的功能就可以组成线程池自己的异常处理机制,正常来说,你想在主线程异步执行子线程的代码并得知是否执行成功,可以直接使用Promise模式,即Java中线程池返回的Future对象。
1.2.18什么是Java线程转储(Thread Dump),如何得到它
线程转储是一个JVM活动线程的列表,它对于分析系统瓶颈和死锁非常有用。有很多方法可以获取线程转储——使用Profiler,Kill-3命令,jstack工具等等。有的更喜欢jstack工具,因为它容易使用并且是JDK自带的。由于它是一个基于终端的工具,所以可以编写一些脚本去定时的产生线程转储以待分析。
1.2.19请说出与线程同步以及线程调度相关的方法
-wait():使一个线程处于等待(阻塞)状态,并且释放所持有的对象的锁;
-sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要处理InterruptedException异常;
-notify():唤醒一个处于等待状态的线程,当然在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且与优先级无关;
-notityAll():唤醒所有处于等待状态的线程,该方法并不是将对象的锁给所有线程,而是让它们竞争,只有获得锁的线程才能进入就绪状态;
1.2.20Executors类是什么? Executor和Executors的区别
Executor 和 ExecutorService 这两个接口主要的区别是:ExecutorService 接口继承了 Executor 接口,是 Executor 的子接口
Executor 和 ExecutorService 第二个区别是:Executor 接口定义了 execute()方法用来接收一个Runnable接口的对象,而 ExecutorService 接口中的 submit()方法可以接受Runnable和Callable接口的对象。
Executor 和 ExecutorService 接口第三个区别是 Executor 中的 execute() 方法不返回任何结果,而 ExecutorService 中的 submit()方法可以通过一个 Future 对象返回运算结果。
Executor 和 ExecutorService 接口第四个区别是除了允许客户端提交一个任务,ExecutorService 还提供用来控制线程池的方法。比如:调用 shutDown() 方法终止线程池。可以通过 《Java Concurrency in Practice》 一书了解更多关于关闭线程池和如何处理 pending 的任务的知识。
Executors 类提供工厂方法用来创建不同类型的线程池。比如: newSingleThreadExecutor() 创建一个只有一个线程的线程池,newFixedThreadPool(int numOfThreads)来创建固定线程数的线程池,newCachedThreadPool()可以根据需要创建新的线程,但如果已有线程是空闲的会重用已有线程。
1.2.21 java holdsLock()方法检测一个线程是否拥有锁
阅读数:3129
java.lang.Thread中有一个方法叫holdsLock(),它返回true如果当且仅当当前线程拥有某个具体对象的锁
.
Object o = new Object();
.
.
@Test
.
.
public void test1() throws Exception {
new Thread(new Runnable() {
@Override
public void run() {
synchronized(o) {
System.out.println(“child thread: holdLock: ” +
Thread.holdsLock(o));
}
}
}).start();
System.out.println(“main thread: holdLock: ” + Thread.holdsLock(o));
Thread.sleep(2000);
}
1.2.22死锁与活锁的区别,死锁与饥饿的区别
答案:死锁:是指两个或两个以上的进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。死锁发生的四个条件
产生死锁的原因:(1)竞争系统资源 (2)进程的推进顺序不当
1、互斥条件:线程对资源的访问是排他性的,如果一个线程对占用了某资源,那么其他线程必须处于等待状态,直到资源被释放。
2、请求和保持条件:线程T1至少已经保持了一个资源R1占用,但又提出对另一个资源R2请求,而此时,资源R2被其他线程T2占用,于是该线程T1也必须等待,但又对自己保持的资源R1不释放。
3、不剥夺条件:线程已获得的资源,在未使用完之前,不能被其他线程剥夺,只能在使用完以后由自己释放。
4、环路等待条件:在死锁发生时,必然存在一个“进程-资源环形链”,即:{p0,p1,p2,…pn},进程p0(或线程)等待p1占用的资源,p1等待p2占用的资源,pn等待p0占用的资源。(最直观的理解是,p0等待p1占用的资源,而p1而在等待p0占用的资源,于是两个进程就相互等待)
活锁:是指线程1可以使用资源,但它很礼貌,让其他线程先使用资源,线程2也可以使用资源,但它很绅士,也让其他线程先使用资源。这样你让我,我让你,最后两个线程都无法使用资源。
饥饿:是指如果线程T1占用了资源R,线程T2又请求封锁R,于是T2等待。T3也请求资源R,当T1释放了R上的封锁后,系统首先批准了T3的请求,T2仍然等待。然后T4又请求封锁R,当T3释放了R上的封锁之后,系统又批准了T4的请求…,T2可能永远等待。
1.2.23 简述锁的等级方法锁、对象锁、类锁
对象锁(方法锁),是针对一个对象的,它只在该对象的某个内存位置声明一个标识该对象是否拥有锁,所有它只会锁住当前的对象,一般一个对象锁是对一个非静态成员变量进行synchronized修饰,或者对一个非静态成员方法进行synchronized进行修饰,对于对象锁,不同对象访问同一个被synchronized修饰的方法的时候不会阻塞
java的内置锁:每个java对象都可以用做一个实现同步的锁,这些锁成为内置锁。线程进入同步代码块或方法的时候会自动获得该锁,在退出同步代码块或方法时会释放该锁。获得内置锁的唯一途径就是进入这个锁的保护的同步代码块或方法。
java内置锁是一个互斥锁,这就是意味着最多只有一个线程能够获得该锁,当线程A尝试去获得线程B持有的内置锁时,线程A必须等待或者阻塞,知道线程B释放这个锁,如果B线程不释放这个锁,那么A线程将永远等待下去。
java的对象锁和类锁:java的对象锁和类锁在锁的概念上基本上和内置锁是一致的,但是,两个锁实际是有很大的区别的,对象锁是用于对象实例方法,或者一个对象实例上的,类锁是用于类的静态方法或者一个类的class对象上的。我们知道,类的对象实例可以有很多个,但是每个类只有一个class对象,所以不同对象实例的对象锁是互不干扰的,但是每个类只有一个类锁。但是有一点必须注意的是,其实类锁只是一个概念上的东西,并不是真实存在的,它只是用来帮助我们理解锁定实例方法和静态方法的区别的
上面已经对锁的一些概念有了一点了解,下面探讨synchronized关键字的用法。
synchronized的用法:synchronized修饰方法和synchronized修饰代码块。
其实,类锁修饰方法和代码块的效果和对象锁是一样的,因为类锁只是一个抽象出来的概念,只是为了区别静态方法的特点,因为静态方法是所有对象实例共用的,所以对应着synchronized修饰的静态方法的锁也是唯一的,所以抽象出来个类锁。其实这里的重点在下面这块代码,synchronized同时修饰静态和非静态方法
synchronized的缺陷:当某个线程进入同步方法获得对象锁,那么其他线程访问这里对象的同步方法时,必须等待或者阻塞,这对高并发的系统是致命的,这很容易导致系统的崩溃。如果某个线程在同步方法里面发生了死循环,那么它就永远不会释放这个对象锁,那么其他线程就要永远的等待。这是一个致命的问题。
一个类的对象锁和另一个类的对象锁是没有关联的,当一个线程获得A类的对象锁时,它同时也可以获得B类的对象锁。
1.2.24 启动一个线程是调用 run() 还是 start() 方法?start() 和 run() 方法有什么区别
一、区别
Java中启动线程有两种方法,继承Thread类和实现Runnable接口,由于Java无法实现多重继承,所以一般通过实现Runnable接口来创建线程。但是无论哪种方法都可以通过start()和run()方法来启动线程,下面就来介绍一下他们的区别。
start方法:
通过该方法启动线程的同时也创建了一个线程,真正实现了多线程。无需等待run()方法中的代码执行完毕,就可以接着执行下面的代码。此时start()的这个线程处于就绪状态,当得到CPU的时间片后就会执行其中的run()方法。这个run()方法包含了要执行的这个线程的内容,run()方法运行结束,此线程也就终止了。
run方法:
通过run方法启动线程其实就是调用一个类中的方法,当作普通的方法的方式调用。并没有创建一个线程,程序中依旧只有一个主线程,必须等到run()方法里面的代码执行完毕,才会继续执行下面的代码,这样就没有达到写线程的目的。
下面我们通过一个很经典的题目来理解一下:
public class Test {
public static void main(String[] args) {
Thread t = new Thread(){
public void run() {
pong();
}
};
t.run();
System.out.println(“ping”);
}
static void pong() {
System.out.println("pong");
}
}
代码如图所示,那么运行程序,输出的应该是什么呢?没错,输出的是”pong ping”。因为t.run()实际上就是等待执行new Thread里面的run()方法调用pong()完毕后,再继续打印”ping”。它不是真正的线程。
而如果我们将t.run();修改为t.start();那么,结果很明显就是”ping pong”,因为当执行到此处,创建了一个新的线程t并处于就绪状态,代码继续执行,打印出”ping”。此时,执行完毕。线程t得到CPU的时间片,开始执行,调用pong()方法打印出”pong”。
如果感兴趣,还可以多加几条语句自己看看效果。
二、源码
那么他们本质上的区别在哪里,我们来看一下源码:
/*java
* Causes this thread to begin execution; the Java Virtual Machine
* calls the run method of this thread.
*
* The result is that two threads are running concurrently: the
* current thread (which returns from the call to the
* start method) and the other thread (which executes its
* run method).
*
* It is never legal to start a thread more than once.
* In particular, a thread may not be restarted once it has completed
* execution.
*
* @exception IllegalThreadStateException if the thread was already
* started.
* @see #run()
* @see #stop()
/
public synchronized void start() {
/
* This method is not invoked for the main method thread or “system”
* group threads created/set up by the VM. Any new functionality added
* to this method in the future may have to also be added to the VM.
*
* A zero status value corresponds to state “NEW”.
*/
if (threadStatus != 0)
throw new IllegalThreadStateException();
/* Notify the group that this thread is about to be started
* so that it can be added to the group's list of threads
* and the group's unstarted count can be decremented. */
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
}
}
}
private native void start0();
可以看到,当一个线程启动的时候,它的状态(threadStatus)被设置为0,如果不为0,则抛出IllegalThreadStateException异常。正常的话,将该线程加入线程组,最后尝试调用start0方法,而start0方法是私有的native方法(Native Method是一个java调用非java代码的接口)。
我猜测这里是用C实现的,看来调用系统底层还是要通过C语言。这也就是为什么start()方法可以实现多线程。而调用run()方法,其实只是调用runnable里面自己实现的run()方法。
我们再看看Thread里run()的源码:
@Override
public void run() {
if (target != null) {
target.run();
}
}
如果target不为空,则调用target的run()方法,那么target是什么:
/* What will be run. */
private Runnable target;
1
2
其实就是一个Runnable接口,正如上面代码中new Thread的部分,其实我们就是在实现它的run()方法。所以如果直接调用run,就和一个普通的方法没什么区别,是不会创建新的线程的,因为压根就没执行start0方法。
三、实现
前面说了,继承Thread类和实现Runnable接口都可以定义一个线程,那么他们又有什么区别呢?
在《Java核心技术卷1 第9版》第627页提到。可以通过一下代码构建Thread的子类定义一个线程:
class MyThread extends Thread {
public void run() {
//do Something
}
}
然后,实例化一个对象,调用其start方法。不过这个方法不推荐。应该减少需要并行运行的任务数量。如果任务很多,要为每个任务创建一个独立的线程所付出的代价太多,当然可以用线程池来解决。
实现Runnable接口所具有的优势:
1、避免Java单继承的问题
2、适合多线程处理同一资源
3、代码可以被多线程共享,数据独立,很容易实现资源共享
1.2.25 调用start()方法时会执行run()方法,为什么不能直接调用run()方法
为什么我们调用start()方法时会执行run()方法?
因为类Thread中的start方法中,调用了Thread中的run方法。顺便说下,类A继承了Tread类,在A中写run方法,就会覆盖掉Thread中的run方法,所以此时调用start方法后,实现的是自己的run方法体里面的代码。
为什么我们不能直接调用run()方法?
如果我们直接调用子线程的run()方法,其方法还是运行在主线程中,代码在程序中是顺序执行的,所以不会有解决耗时操作的问题。所以不能直接调用线程的run()方法,只有子线程开始了,才会有异步的效果。当thread.start()方法执行了以后,子线程才会执行run()方法,这样的效果和在主线程中直接调用run()方法的效果是截然不同的。
start( )与run( )之间有什么区别?
run()方法:在本线程内调用该Runnable对象的run()方法,可以重复多次调用;
start()方法:启动一个线程,调用该Runnable对象的run()方法,不能多次启动一个线程;
1.2.26sleep() 方法和对象的 wait() 方法都可以让线程暂停执行,它们有什么区别
sleep()方法(休眠)是线程类(Thread)的静态方法,调用此方法会让当前线程暂停执行指定的时间,
将执行机会(CPU)让给其他线程,但是对象的锁依然保持,因此休眠时间结束后会自动恢复(线程回到就绪状态,请参考第66题中的线程状态转换图)。
wait()是Object类的方法,调用对象的wait()方法导致当前线程放弃对象的锁(线程暂停执行),进入对象的等待池(wait pool),只有调用对象的notify()方法(或notifyAll()方法)时才能唤醒等待池中的线程进入等锁池(lockpool),如果线程重新获得对象的锁就可以进入就绪状态
可能不少人对什么是进程,什么是线程还比较模糊,对于为什么需要多线程编程也不是特别理解。
简单的说:
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是操作系统进行资源分配和调度的一个独立单位;
线程是进程的一个实体,是CPU调度和分派的基本单位,是比进程更小的能独立运行的基本单位。线程的划分尺度小于进程,这使得多线程程序的并发性高;进程在执行时通常拥有独立的内存单元,而线程之间可以共享内存。
1.2.27 yield方法有什么作用?sleep() 方法和 yield() 方法有什么区别
① sleep()方法给其他线程运行机会时不考虑线程的优先级,因此会给低优先级的线程以运行的机会;yield()方法只会给相同优先级或更高优先级的线程以运行的机会;
② 线程执行sleep()方法后转入阻塞(blocked)状态,而执行yield()方法后转入就绪(ready)状态;
③ sleep()方法声明抛出InterruptedException,而yield()方法没有声明任何异常;
④ sleep()方法比yield()方法(跟操作系统CPU调度相关)具有更好的可移植性.
1.2.28 Java 中如何停止一个线程
停止一个线程意味着在任务处理完任务之前停掉正在做的操作,也就是放弃当前的操作。停止一个线程可以用Thread.stop()方法,但最好不要用它。虽然它确实可以停止一个正在运行的线程,但是这个方法是不安全的,而且是已被废弃的方法。
在java中有以下3种方法可以终止正在运行的线程:
1.使用退出标志,使线程正常退出,也就是当run方法完成后线程终止。
2.使用stop方法强行终止,但是不推荐这个方法,因为stop和suspend及resume一样都是过期作废的方法。
3.使用interrupt方法中断线程。
-
停止不了的线程
interrupt()方法的使用效果并不像for+break语句那样,马上就停止循环。调用interrupt方法是在当前线程中打了一个停止标志,并不是真的停止线程。
public class MyThread extends Thread {
public void run(){
super.run();
for(int i=0; i<500000; i++){
System.out.println(“i=”+(i+1));
}
}
}
public class Run {
public static void main(String args[]){
Thread thread = new MyThread();
thread.start();
try {
Thread.sleep(2000);
thread.interrupt();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
输出结果:
…
i=499994
i=499995
i=499996
i=499997
i=499998
i=499999
i=500000 -
判断线程是否停止状态
Thread.java类中提供了两种方法:
1.this.interrupted(): 测试当前线程是否已经中断;
2.this.isInterrupted(): 测试线程是否已经中断;
那么这两个方法有什么图区别呢?
我们先来看看this.interrupted()方法的解释:测试当前线程是否已经中断,当前线程是指运行this.interrupted()方法的线程。
public class MyThread extends Thread {
public void run(){
super.run();
for(int i=0; i<500000; i++){
i++;// System.out.println(“i=”+(i+1));
}
}
}
public class Run {
public static void main(String args[]){
Thread thread = new MyThread();
thread.start();
try {
Thread.sleep(2000);
thread.interrupt();System.out.println("stop 1??" + thread.interrupted()); System.out.println("stop 2??" + thread.interrupted()); } catch (InterruptedException e) { e.printStackTrace(); }}
}
运行结果:
stop 1??falsestop 2??false
类Run.java中虽然是在thread对象上调用以下代码:thread.interrupt(), 后面又使用
System.out.println(“stop 1??” + thread.interrupted());System.out.println(“stop 2??” + thread.interrupted());
来判断thread对象所代表的线程是否停止,但从控制台打印的结果来看,线程并未停止,这也证明了interrupted()方法的解释,测试当前线程是否已经中断。这个当前线程是main,它从未中断过,所以打印的结果是两个false.
如何使main线程产生中断效果呢?
public class Run2 {
public static void main(String args[]){
Thread.currentThread().interrupt();
System.out.println(“stop 1??” + Thread.interrupted());
System.out.println(“stop 2??” + Thread.interrupted());System.out.println("End");}
}
运行效果为:
stop 1??truestop 2??falseEnd
方法interrupted()的确判断出当前线程是否是停止状态。但为什么第2个布尔值是false呢? 官方帮助文档中对interrupted方法的解释:
测试当前线程是否已经中断。线程的中断状态由该方法清除。 换句话说,如果连续两次调用该方法,则第二次调用返回false。
下面来看一下inInterrupted()方法。
public class Run3 {
public static void main(String args[]){
Thread thread = new MyThread();
thread.start();
thread.interrupt();
System.out.println(“stop 1??” + thread.isInterrupted());
System.out.println(“stop 2??” + thread.isInterrupted());
}
}
运行结果:
stop 1??truestop 2??true
isInterrupted()并为清除状态,所以打印了两个true。 -
能停止的线程–异常法
有了前面学习过的知识点,就可以在线程中用for语句来判断一下线程是否是停止状态,如果是停止状态,则后面的代码不再运行即可:
public class MyThread extends Thread {
public void run(){
super.run();
for(int i=0; i<500000; i++){
if(this.interrupted()) {
System.out.println(“线程已经终止, for循环不再执行”);
break;
}
System.out.println(“i=”+(i+1));
}
}
}
public class Run {
public static void main(String args[]){
Thread thread = new MyThread();
thread.start();
try {
Thread.sleep(2000);
thread.interrupt();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
运行结果:
…i=202053i=202054i=202055i=202056
线程已经终止, for循环不再执行
上面的示例虽然停止了线程,但如果for语句下面还有语句,还是会继续运行的。看下面的例子:
public class MyThread extends Thread {
public void run(){
super.run();
for(int i=0; i<500000; i++){
if(this.interrupted()) {
System.out.println(“线程已经终止, for循环不再执行”);
break;
}
System.out.println(“i=”+(i+1));
}System.out.println("这是for循环外面的语句,也会被执行");}
}
使用Run.java执行的结果是:
…i=180136i=180137i=180138i=180139
线程已经终止, for循环不再执行
这是for循环外面的语句,也会被执行
如何解决语句继续运行的问题呢? 看一下更新后的代码:
public class MyThread extends Thread {
public void run(){
super.run();
try {
for(int i=0; i<500000; i++){
if(this.interrupted()) {
System.out.println(“线程已经终止, for循环不再执行”);
throw new InterruptedException();
}
System.out.println(“i=”+(i+1));
}System.out.println("这是for循环外面的语句,也会被执行"); } catch (InterruptedException e) { System.out.println("进入MyThread.java类中的catch了。。。"); e.printStackTrace(); }}
}
使用Run.java运行的结果如下:
…i=203798i=203799i=203800
线程已经终止, for循环不再执行
进入MyThread.java类中的catch了。。。
java.lang.InterruptedException
at thread.MyThread.run(MyThread.java:13) -
在沉睡中停止
如果线程在sleep()状态下停止线程,会是什么效果呢?
public class MyThread extends Thread {
public void run(){
super.run();try { System.out.println("线程开始。。。"); Thread.sleep(200000); System.out.println("线程结束。"); } catch (InterruptedException e) { System.out.println("在沉睡中被停止, 进入catch, 调用isInterrupted()方法的结果是:" + this.isInterrupted()); e.printStackTrace(); }}
}
使用Run.java运行的结果是:
线程开始。。。
在沉睡中被停止, 进入catch, 调用isInterrupted()方法的结果是:falsejava.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at thread.MyThread.run(MyThread.java:12)
从打印的结果来看, 如果在sleep状态下停止某一线程,会进入catch语句,并且清除停止状态值,使之变为false。
前一个实验是先sleep然后再用interrupt()停止,与之相反的操作在学习过程中也要注意:
public class MyThread extends Thread {
public void run(){
super.run();
try {
System.out.println(“线程开始。。。”);
for(int i=0; i<10000; i++){
System.out.println(“i=” + i);
}
Thread.sleep(200000);
System.out.println(“线程结束。”);
} catch (InterruptedException e) {
System.out.println(“先停止,再遇到sleep,进入catch异常”);
e.printStackTrace();
}}
}
public class Run {
public static void main(String args[]){
Thread thread = new MyThread();
thread.start();
thread.interrupt();
}
}
运行结果:
i=9998i=9999
先停止,再遇到sleep,进入catch异常
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at thread.MyThread.run(MyThread.java:15) -
能停止的线程—暴力停止
使用stop()方法停止线程则是非常暴力的。
public class MyThread extends Thread {
private int i = 0;
public void run(){
super.run();
try {
while (true){
System.out.println(“i=” + i);
i++;
Thread.sleep(200);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public class Run {
public static void main(String args[]) throws InterruptedException {
Thread thread = new MyThread();
thread.start();
Thread.sleep(2000);
thread.stop();
}
}
运行结果:
i=0
i=1
i=2
i=3
i=4
i=5
i=6
i=7
i=8
i=9
Process finished with exit code 0
6.方法stop()与java.lang.ThreadDeath异常
调用stop()方法时会抛出java.lang.ThreadDeath异常,但是通常情况下,此异常不需要显示地捕捉。
public class MyThread extends Thread {
private int i = 0;
public void run(){
super.run();
try {
this.stop();
} catch (ThreadDeath e) {
System.out.println(“进入异常catch”);
e.printStackTrace();
}
}
}
public class Run {
public static void main(String args[]) throws InterruptedException {
Thread thread = new MyThread();
thread.start();
}
}
stop()方法以及作废,因为如果强制让线程停止有可能使一些清理性的工作得不到完成。另外一个情况就是对锁定的对象进行了解锁,导致数据得不到同步的处理,出现数据不一致的问题。
7. 释放锁的不良后果
使用stop()释放锁将会给数据造成不一致性的结果。如果出现这样的情况,程序处理的数据就有可能遭到破坏,最终导致程序执行的流程错误,一定要特别注意:
public class SynchronizedObject {
private String name = “a”;
private String password = “aa”;
public synchronized void printString(String name, String password){
try {
this.name = name;
Thread.sleep(100000);
this.password = password;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
public class MyThread extends Thread {
private SynchronizedObject synchronizedObject;
public MyThread(SynchronizedObject synchronizedObject){
this.synchronizedObject = synchronizedObject;
}
public void run(){
synchronizedObject.printString("b", "bb");
}
}
public class Run {
public static void main(String args[]) throws InterruptedException {
SynchronizedObject synchronizedObject = new SynchronizedObject();
Thread thread = new MyThread(synchronizedObject);
thread.start();
Thread.sleep(500);
thread.stop();
System.out.println(synchronizedObject.getName() + ” ” + synchronizedObject.getPassword());
}
}
输出结果:
b aa
由于stop()方法以及在JDK中被标明为“过期/作废”的方法,显然它在功能上具有缺陷,所以不建议在程序张使用stop()方法。
8. 使用return停止线程
将方法interrupt()与return结合使用也能实现停止线程的效果:
public class MyThread extends Thread {
public void run(){
while (true){
if(this.isInterrupted()){
System.out.println(“线程被停止了!”);
return;
}
System.out.println(“Time: ” + System.currentTimeMillis());
}
}
}
public class Run {
public static void main(String args[]) throws InterruptedException {
Thread thread = new MyThread();
thread.start();
Thread.sleep(2000);
thread.interrupt();
}
}
输出结果:
…Time: 1467072288503Time: 1467072288503Time: 1467072288503
线程被停止了!
不过还是建议使用“抛异常”的方法来实现线程的停止,因为在catch块中还可以将异常向上抛,使线程停止事件得以传播。
1.2.29 stop() 和 suspend() 方法为何不推荐使用
反对使用stop(),是因为它不安全。它会解除由线程获取的所有锁定,当在一个线程对象上调用stop()方法时,这个线程对象所运行的线程就会立即停止,假如一个线程正在执行:synchronized void { x = 3; y = 4;} 由于方法是同步的,多个线程访问时总能保证x,y被同时赋值,而如果一个线程正在执行到x = 3;时,被调用了 stop()方法,即使在同步块中,它也干脆地stop了,这样就产生了不完整的残废数据。而多线程编程中最最基础的条件要保证数据的完整性,所以请忘记线程的stop方法,以后我们再也不要说“停止线程”了。而且如果对象处于一种不连贯状态,那么其他线程能在那种状态下检查和修改它们。结果很难检查出真正的问题所在。
suspend()方法容易发生死锁。调用suspend()的时候,目标线程会停下来,但却仍然持有在这之前获得的锁定。此时,其他任何线程都不能访问锁定的资源,除非被”挂起”的线程恢复运行。对任何线程来说,如果它们想恢复目标线程,同时又试图使用任何一个锁定的资源,就会造成死锁。所以不应该使用suspend(),而应在自己的Thread类中置入一个标志,指出线程应该活动还是挂起。若标志指出线程应该挂起,便用 wait()命其进入等待状态。若标志指出线程应当恢复,则用一个notify()重新启动线程。
1.2.30多线程共享数据的方式:
1,如果每个线程执行的代码相同,可以使用同一个Runnable对象,这个Runnable对象中有那个共享数据,例如,卖票系统就可以这么做。
2,如果每个线程执行的代码不同,这时候需要用不同的Runnable对象,例如,设计4个线程。其中两个线程每次对j增加1,另外两个线程对j每次减1,银行存取款
有两种方法来解决此类问题:
将共享数据封装成另外一个对象,然后将这个对象逐一传递给各个Runnable对象,每个线程对共享数据的操作方法也分配到那个对象身上完成,这样容易实现针对数据进行各个操作的互斥和通信
将Runnable对象作为一个类的内部类,共享数据作为这个类的成员变量,每个线程对共享数据的操作方法也封装在外部类,以便实现对数据的各个操作的同步和互斥,作为内部类的各个Runnable对象调用外部类的这些方法。
下面逐一介绍
每个线程执行的代码相同,可以使用同一个Runnable对象
卖票系统demo:
package com.tgb.hjy;
/**
- 多线程共享数据-卖票系统
- @author hejingyuan
/
public class SellTicket {
/*
* @param args
/
public static void main(String[] args) {
Ticket t = new Ticket();
new Thread(t).start();
new Thread(t).start();
}
}
class Ticket implements Runnable{
private int ticket = 10;
public void run() {
while(ticket>0){
ticket–;
System.out.println(“当前票数为:”+ticket);
}
}
}
简单的多线程间数据共享,每个线程执行的代码不同,用不同的Runnable对象
设计4个线程。
其中两个线程每次对j增加1,另外两个线程对j每次减1
package com.tgb.hjy;
public class TestThread {
/*
* @param args
*/
public static void main(String[] args) {
final MyData data = new MyData();
for(int i=0;i<2;i++){
new Thread(new Runnable(){
public void run() {
data.add();
}
}).start();
new Thread(new Runnable(){
public void run() {
data.dec();
}
}).start();
}
}
}
class MyData {
private int j=0;
public synchronized void add(){
j++;
System.out.println(“线程”+Thread.currentThread().getName()+“j为:”+j);
}
public synchronized void dec(){
j–;
System.out.println(“线程”+Thread.currentThread().getName()+“j为:”+j);
}
}
银行存取款实例:
package com.tgb.hjy;
public class Acount {
private int money;
public Acount(int money){
this.money=money;
}
public synchronized void getMoney(int money){
//注意这个地方必须用while循环,因为即便再存入钱也有可能比取的要少
while(this.money<money){
System.out.println(“取款:”+money+” 余额:“+this.money+” 余额不足,正在等待存款…“);
try{ wait();} catch(Exception e){}
}
this.money=this.money-money;
System.out.println(“取出:”+money+” 还剩余:“+this.money);
}
public synchronized void setMoney(int money){
try{ Thread.sleep(10);}catch(Exception e){}
this.money=this.money+money;
System.out.println(“新存入:”+money+” 共计:”+this.money);
notify();
}
public static void main(String args[]){
Acount Acount=new Acount(0);
Bank b=new Bank(Acount);
Consumer c=new Consumer(Acount);
new Thread(b).start();
new Thread©.start();
}
}
//存款类
class Bank implements Runnable {
Acount Acount;
public Bank(Acount Acount){
this.Acount=Acount;
}
public void run(){
while(true){
int temp=(int)(Math.random()*1000);
Acount.setMoney(temp);
}
}
}
//取款类
class Consumer implements Runnable {
Acount Acount;
public Consumer(Acount Acount){
this.Acount=Acount;
}
public void run(){
while(true){
int temp=(int)(Math.random()*1000);
Acount.getMoney(temp);
}
}
}
总结:
其实多线程间的共享数据最主要的还是互斥,多个线程共享一个变量,针对变量的操作实现原子性即可。
1.2.31 如何强制启动一个线程
在线程操作中,可以使用join()方法让一个线程强制运行,线程强制运行期间,只有该线程拥有CPU的执行权,其他线程无法运行,必须等待此线程完成之后才可以继续执行。
运行的主方法
运行结果
1.2.32 如何让正在运行的线程暂停一段时间
1 可以使用Thread类的Sleep()方法让线程暂停一段时间。需要注意的是,这并不会让线程终止,一旦从休眠中唤醒线程,线程的状态将会被改变为Runnable,并且根据线程调度,它将得到执行。
2可以使用thread.wait()方法来让线程暂停一段时间,wait方法里面填写的是暂停的时间的长度,一毫秒为单位,
1.2.33 什么是线程组,为什么在Java中不推荐使用
在Java中每一个线程都归属于某个线程组管理的一员,例如在主函数main()主工作流程中产生一个线程,则产生的线程属于main这个线程组管理的一员。简单地说,线程组就是由线程组成的管理线程的类,这个类是java.lang.ThreadGroup类。
定义一个线程组,通过以下代码可以实现。
ThreadGroup group=new ThreadGroup(“group”);
Thread thread=new Thread(group,“the first thread of group”);
ThreadGroup类中的某些方法,可以对线程组中的线程产生作用。例如,setMaxPriority()方法可以设定线程组中的所有线程拥有最大的优先权。
所有线程都隶属于一个线程组。那可以是一个默认线程组,亦可是一个创建线程时明确指定的组。在创建之初,线程被限制到一个组里,而且不能改变到一个不同的组。每个应用都至少有一个线程从属于系统线程组。若创建多个线程而不指定一个组,它们就会自动归属于系统线程组。
线程组也必须从属于其他线程组。必须在构建器里指定新线程组从属于哪个线程组。若在创建一个线程组的时候没有指定它的归属,则同样会自动成为系统线程组的一名属下。因此,一个应用程序中的所有线程组最终都会将系统线程组作为自己的“父”
之所以要提出“线程组”的概念,一般认为,是由于“安全”或者“保密”方面的理由。根据Arnold和Gosling的说法:“线程组中的线程可以修改组内的其他线程,包括那些位于分层结构最深处的。一个线程不能修改位于自己所在组或者下属组之外的任何线程”(注释①)
虽然线程组看上去很有用处,实际上现在的程序开发中已经不推荐使用它了,主要有两个原因:
1.线程组ThreadGroup对象中比较有用的方法是stop、resume、suspend等方法,由于这几个方法会导致线程的安全问题(主要是死锁问题),已经被官方废弃掉了,所以线程组本身的应用价值就大打折扣了。
2.线程组ThreadGroup不是线程安全的,这在使用过程中获取的信息并不全是及时有效的,这就降低了它的统计使用价值。
虽然线程组现在已经不被推荐使用了,但是它在线程的异常处理方面还是做出了一定的贡献。当线程运行过程中出现异常情况时,在某些情况下JVM会把线程的控制权交到线程关联的线程组对象上来进行处理。所以对线程组的了解还是有一定必要的。
来自
https://baijiahao.baidu.com/s?id=1587096758782864253&wfr=spider&for=pc
1.2.34 你是如何调用 wait(方法的)?使用 if 块还是循环?为什么
在多线程的编程实践中,wait()的使用方法如下:
synchronized (monitor) {
// 判断条件谓词是否得到满足
while(!locked) {
// 等待唤醒
monitor.wait();
}
// 处理其他的业务逻辑
}
那为什么非要while判断,而不采用if判断呢?如下:
synchronized (monitor) {
// 判断条件谓词是否得到满足
if(!locked) {
// 等待唤醒
monitor.wait();
}
// 处理其他的业务逻辑
}
这是因为,如果采用if判断,当线程从wait中唤醒时,那么将直接执行处理其他业务逻辑的代码,但这时候可能出现另外一种可能,条件谓词已经不满足处理业务逻辑的条件了,从而出现错误的结果,于是有必要进行再一次判断,如下:
synchronized (monitor) {
// 判断条件谓词是否得到满足
if(!locked) {
// 等待唤醒
monitor.wait();
if(locked) {
// 处理其他的业务逻辑
} else {
// 跳转到monitor.wait();
}
}
}
而循环则是对上述写法的简化,唤醒后再次进入while条件判断,避免条件谓词发生改变而继续处理业务逻辑
1.2.35 线程的生命周期
1.线程的生命周期
线程是一个动态执行的过程,它也有一个从产生到死亡的过程。
(1)生命周期的五种状态
新建(new Thread)
当创建Thread类的一个实例(对象)时,此线程进入新建状态(未被启动)。
例如:Thread t1=new Thread();
就绪(runnable)
线程已经被启动,正在等待被分配给CPU时间片,也就是说此时线程正在就绪队列中排队等候得到CPU资源。例如:t1.start();
运行(running)
线程获得CPU资源正在执行任务(run()方法),此时除非此线程自动放弃CPU资源或者有优先级更高的线程进入,线程将一直运行到结束。
死亡(dead)
当线程执行完毕或被其它线程杀死,线程就进入死亡状态,这时线程不可能再进入就绪状态等待执行。
自然终止:正常运行run()方法后终止
异常终止:调用stop()方法让一个线程终止运行
堵塞(blocked)
由于某种原因导致正在运行的线程让出CPU并暂停自己的执行,即进入堵塞状态。
正在睡眠:用sleep(long t) 方法可使线程进入睡眠方式。一个睡眠着的线程在指定的时间过去可进入就绪状态。
正在等待:调用wait()方法。(调用motify()方法回到就绪状态)
被另一个线程所阻塞:调用suspend()方法。(调用resume()方法恢复)
2.常用方法
void run() 创建该类的子类时必须实现的方法
void start() 开启线程的方法
static void sleep(long t) 释放CPU的执行权,不释放锁
static void sleep(long millis,int nanos)
final void wait()释放CPU的执行权,释放锁
final void notify()
static void yied()可以对当前线程进行临时暂停(让线程将资源释放出来)
3.(1)结束线程原理:就是让run方法结束。而run方法中通常会定义循环结构,所以只要控制住循环即可
(2)方法—-可以boolean标记的形式完成,只要在某一情况下将标记改变,让循环停止即可让线程结束
(3)public final void join()//让线程加入执行,执行某一线程join方法的线程会被冻结,等待某一线程执行结束,该线程才会恢复到可运行状态
4. 临界资源:多个线程间共享的数据称为临界资源
(1)互斥锁
a.每个对象都对应于一个可称为“互斥锁”的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
b.Java对象默认是可以被多个线程共用的,只是在需要时才启动“互斥锁”机制,成为专用对象。
c.关键字synchronized用来与对象的互斥锁联系
d.当某个对象用synchronized修饰时,表明该对象已启动“互斥锁”机制,在任一时刻只能由一个线程访问,即使该线程出现堵塞,该对象的被锁定状态也不会解除,其他线程任不能访问该对象。
1.2.36 线程状态,BLOCKED 和 WAITING 有什么区别
BLOCKED状态
线程处于BLOCKED状态的场景。
当前线程在等待一个monitor lock,比如等待执行synchronized代码块或者使用synchronized标记的方法。
在synchronized块中循环调用Object类型的wait方法,如下是样例
synchronized(this)
{
while (flag)
{
obj.wait();
}
// some other code
}
WAITING状态
线程处于WAITING状态的场景。
调用Object对象的wait方法,但没有指定超时值。
调用Thread对象的join方法,但没有指定超时值。
调用LockSupport对象的park方法。
提到WAITING状态,顺便提一下TIMED_WAITING状态的场景。
TIMED_WAITING状态
线程处于TIMED_WAITING状态的场景。
调用Thread.sleep方法。
调用Object对象的wait方法,指定超时值。
调用Thread对象的join方法,指定超时值。
调用LockSupport对象的parkNanos方法。
调用LockSupport对象的parkUntil方法。
1.2.37 ThreadLocal 用途是什么,原理是什么,用的时候要注意什么
ThreadLocal不是用来解决对象共享访问问题的,而主要是提供了保持对象的方法和避免参数传递的方便的对象访问方式。
1。每个线程中都有一个自己的ThreadLocalMap类对象,可以将线程自己的对象保持到其中,各管各的,线程可以正确的访问到自己的对象。
2。将一个共用的ThreadLocal静态实例作为key,将不同对象的引用保存到不同线程的ThreadLocalMap中,然后在线程执行的各处通过这个静态ThreadLocal实例的get()方法取得自己线程保存的那个对象,避免了将这个对象作为参数传递的麻烦
一、用法
ThreadLocal用于保存某个线程共享变量:对于同一个static ThreadLocal,不同线程只能从中get,set,remove自己的变量,而不会影响其他线程的变量。
1、ThreadLocal.get: 获取ThreadLocal中当前线程共享变量的值。
2、ThreadLocal.set: 设置ThreadLocal中当前线程共享变量的值。
3、ThreadLocal.remove: 移除ThreadLocal中当前线程共享变量的值。
4、ThreadLocal.initialValue: ThreadLocal没有被当前线程赋值时或当前线程刚调用remove方法后调用get方法,返回此方法值。
二、原理
线程共享变量缓存如下:
Thread.ThreadLocalMap<ThreadLocal, Object>;
1、Thread: 当前线程,可以通过Thread.currentThread()获取。
2、ThreadLocal:我们的static ThreadLocal变量。
3、Object: 当前线程共享变量。
我们调用ThreadLocal.get方法时,实际上是从当前线程中获取ThreadLocalMap<ThreadLocal, Object>,然后根据当前ThreadLocal获取当前线程共享变量Object。
ThreadLocal.set,ThreadLocal.remove实际上是同样的道理。
这种存储结构的好处:
1、线程死去的时候,线程共享变量ThreadLocalMap则销毁。
2、ThreadLocalMap<ThreadLocal,Object>键值对数量为ThreadLocal的数量,一般来说ThreadLocal数量很少,相比在ThreadLocal中用Map<Thread, Object>键值对存储线程共享变量(Thread数量一般来说比ThreadLocal数量多),性能提高很多。
关于ThreadLocalMap<ThreadLocal, Object>弱引用问题:
当线程没有结束,但是ThreadLocal已经被回收,则可能导致线程中存在ThreadLocalMap<null, Object>的键值对,造成内存泄露。(ThreadLocal被回收,ThreadLocal关联的线程共享变量还存在)。
虽然ThreadLocal的get,set方法可以清除ThreadLocalMap中key为null的value,但是get,set方法在内存泄露后并不会必然调用,所以为了防止此类情况的出现,我们有两种手段。
1、使用完线程共享变量后,显示调用ThreadLocalMap.remove方法清除线程共享变量;
2、JDK建议ThreadLocal定义为private static,这样ThreadLocal的弱引用问题则不存在了。
1.2.38 线程池
1.2.38.1 什么是线程池
java.util.concurrent.Executors提供了一个 java.util.concurrent.Executor接口的实现用于创建线程池
多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力。
假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中执行任务的时间,T3 销毁线程时间。
如果:T1 + T3 远大于 T2,则可以采用线程池,以提高服务器性能。
一个线程池包括以下四个基本组成部分:
1、线程池管理器(ThreadPool):用于创建并管理线程池,包括 创建线程池,销毁线程池,添加新任务;
2、工作线程(PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;
3、任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
4、任务队列(taskQueue):用于存放没有处理的任务。提供一种缓冲机制。
线程池技术正是关注如何缩短或调整T1,T3时间的技术,从而提高服务器程序性能的。它把T1,T3分别安排在服务器程序的启动和结束的时间段或者一些空闲的时间段,这样在服务器程序处理客户请求时,不会有T1,T3的开销了。
线程池不仅调整T1,T3产生的时间段,而且它还显著减少了创建线程的数目,看一个例子:
假设一个服务器一天要处理50000个请求,并且每个请求需要一个单独的线程完成。在线程池中,线程数一般是固定的,所以产生线程总数不会超过线程池中线程的数目,而如果服务器不利用线程池来处理这些请求则线程总数为50000。一般线程池大小是远小于50000。所以利用线程池的服务器程序不会为了创建50000而在处理请求时浪费时间,从而提高效率。
首先看一下java中作为线程池Executor底层实现类的ThredPoolExecutor的构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
…
}
corePoolSize- 池中所保存的线程数,包括空闲线程。需要注意的是在初创建线程池时线程不会立即启动,直到有任务提交才开始启动线程并逐渐时线程数目达到corePoolSize。若想一开始就创建所有核心线程需调用prestartAllCoreThreads方法。
maximumPoolSize-池中允许的最大线程数。需要注意的是当核心线程满且阻塞队列也满时才会判断当前线程数是否小于最大线程数,并决定是否创建新线程。
keepAliveTime – 当线程数大于核心时,多于的空闲线程最多存活时间
unit – keepAliveTime 参数的时间单位。
workQueue – 当线程数目超过核心线程数时用于保存任务的队列。主要有3种类型的BlockingQueue可供选择:无界队列,有界队列和同步移交。将在下文中详细阐述。从参数中可以看到,此队列仅保存实现Runnable接口的任务。
threadFactory – 执行程序创建新线程时使用的工厂。
handler – 阻塞队列已满且线程数达到最大值时所采取的饱和策略。java默认提供了4种饱和策略的实现方式:中止、抛弃、抛弃最旧的、调用者运行。将在下文中详细阐述。
1.2.38.2 常见的线程池
①newSingleThreadExecutor
单个线程的线程池,即线程池中每次只有一个线程工作,单线程串行执行任务
②newFixedThreadExecutor(n)
固定数量的线程池,没提交一个任务就是一个线程,直到达到线程池的最大数量,然后后面进入等待队列直到前面的任务完成才继续执行
③newCacheThreadExecutor(推荐使用)
可缓存线程池,当线程池大小超过了处理任务所需的线程,那么就会回收部分空闲(一般是60秒无执行)的线程,当有任务来时,又智能的添加新线程来执行。
④newScheduleThreadExecutor
大小无限制的线程池,支持定时和周期性的执行线程
java提供的线程池更加强大,相信理解线程池的工作原理,看类库中的线程池就不会感到陌生了。
1.2.38.3线程池的作用
线程池作用就是限制系统中执行线程的数量。
根据系统的环境情况,可以自动或手动设置线程数量,达到运行的最佳效果;少了浪费了系统资源,多了造成系统拥挤效率不高。用线程池控制线程数量,其他线程排队等候。一个任务执行完毕,再从队列的中取最前面的任务开始执行。若队列中没有等待进程,线程池的这一资源处于等待。当一个新任务需要运行时,如果线程池中有等待的工作线程,就可以开始运行了;否则进入等待队列。
1.2.38.4 为什么要用线程池
1.减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
2.可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内存,而把服务器累趴下(每个线程需要大约1MB内存,线程开的越多,消耗的内存也就越大,最后死机)。
我们知道使用线程池可以大大的提高系统的性能,提高程序任务的执行效率,
节约了系统的内存空间。在线程池中,每一个工作线程都可以被重复利用,可执行多个任务,
减少了创建和销毁线程的次数。能够根据系统的承受能力,调整其线程数目,以便使系统达到运行的最佳效果。
Java里面线程池的顶级接口是Executor,但是严格意义上讲Executor并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是ExecutorService。
比较重要的几个类:
ExecutorService 真正的线程池接口。
ScheduledExecutorService 能和Timer/TimerTask类似,解决那些需要任务重复执行的问题。
ThreadPoolExecutor ExecutorService的默认实现。
ScheduledThreadPoolExecutor 继承ThreadPoolExecutor的ScheduledExecutorService接口实现,周期性任务调度的类实现。
要配置一个线程池是比较复杂的,尤其是对于线程池的原理不是很清楚的情况下,很有可能配置的线程池不是较优的,因此在Executors类里面提供了一些静态工厂,生成一些常用的线程池。
- newSingleThreadExecutor
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
2.newFixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。 - newCachedThreadPool
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,
那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
4.newScheduledThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
1.2.38.5 线程池原理:
一个线程池中有多个处于可运行状态的线程,当向线程池中添加Runnable或Callable接口对象时,
就会有一个线程来执行run()方法或call()方法。如果方法执行完毕,则该线程并不终止,
而是继续在池中处于可运行状态,以运行新的任务。
1.2.38.6 创建线程池的四种方式
Java通过Executors提供四种线程池,分别为:
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newSchednewFixedThreadPool uledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
1 newCachedThreadPool
public static void main(String[] args) {
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int index = i;
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
cachedThreadPool.execute(new Runnable() {
public void run() {
System.out.println(index);
}
});
}
}
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
这里的线程池是无限大的,当一个线程完成任务之后,这个线程可以接下来完成将要分配的任务,而不是创建一个新的线程,
java api 1.7 will reuse previously constructed threads when they are available.
2 newFixedThreadPool
public static void main(String[] args) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
final int index = i;
fixedThreadPool.execute(new Runnable() {
public void run() {
try {
System.out.println(index);
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
3创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待
定长线程池的大小最好根据系统资源进行设置。如Runtime.getRuntime().availableProcessors()
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
for (int i = 0; i < 10; i++) {
scheduledThreadPool.schedule(new Runnable() {
public void run() {
System.out.println(“delay 3 seconds”);
}
}, 3, TimeUnit.SECONDS);
}
}
4 newSingleThreadExecutor
public static void main(String[] args) {
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int index = i;
singleThreadExecutor.execute(new Runnable() {
public void run() {
/* System.out.println(index);*/
try {
System.out.println(index);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
.
按顺序来执行线程任务 但是不同于单线程,这个线程池只是只能存在一个线程,这个线程死后另外一个线程会补上
1.2.38.6 我们可以通过ThreadPoolExecutor来创建一个线程池。
new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, milliseconds,runnableTaskQueue, handler);
创建一个线程池需要输入几个参数:
corePoolSize(线程池的基本大小):当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads方法,线程池会提前创建并启动所有基本线程。
runnableTaskQueue(任务队列):用于保存等待执行的任务的阻塞队列。 可以选择以下几个阻塞队列。
ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
maximumPoolSize(线程池最大大小):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是如果使用了无界的任务队列这个参数就没什么效果。
ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。
RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。以下是JDK1.5提供的四种策略。
AbortPolicy:直接抛出异常。
CallerRunsPolicy:只用调用者所在线程来运行任务。
DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
DiscardPolicy:不处理,丢弃掉。
当然也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化不能处理的任务。
keepAliveTime(线程活动保持时间):线程池的工作线程空闲后,保持存活的时间。所以如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。
TimeUnit(线程活动保持时间的单位):可选的单位有天(DAYS),小时(HOURS),分钟(MINUTES),毫秒(MILLISECONDS),微秒(MICROSECONDS, 千分之一毫秒)和毫微秒(NANOSECONDS, 千分之一微秒)。
1.2.38.7 线程池的实现策略
JDK主要提供了4种饱和策略供选择。4种策略都做为静态内部类在ThreadPoolExcutor中进行实现。
3.1 AbortPolicy中止策略
该策略是默认饱和策略。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException(“Task ” + r.toString() +
” rejected from ” +
e.toString());
}
使用该策略时在饱和时会抛出RejectedExecutionException(继承自RuntimeException),调用者可捕获该异常自行处理。
3.2 DiscardPolicy抛弃策略
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
如代码所示,不做任何处理直接抛弃任务
3.3 DiscardOldestPolicy抛弃旧任务策略
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute®;
}
}
如代码,先将阻塞队列中的头元素出队抛弃,再尝试提交任务。如果此时阻塞队列使用PriorityBlockingQueue优先级队列,将会导致优先级最高的任务被抛弃,因此不建议将该种策略配合优先级队列使用。
3.4 CallerRunsPolicy调用者运行
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
既不抛弃任务也不抛出异常,直接运行任务的run方法,换言之将任务回退给调用者来直接运行。使用该策略时线程池饱和后将由调用线程池的主线程自己来执行任务,因此在执行任务的这段时间里主线程无法再提交新任务,从而使线程池中工作线程有时间将正在处理的任务处理完成。
1.2.38.8 线程池的关闭
Java提供的对ExecutorService的关闭方式有两种,一种是调用其shutdown()方法,另一种是调用shutdownNow()方法。这两者是有区别的。
shutdown:
1.调用之后不允许继续往线程池内继续添加线程;
2.线程池的状态变为SHUTDOWN状态;
3.所有在调用shutdown()方法之前提交到ExecutorSrvice的任务都会执行;
4.一旦所有线程结束执行当前任务,ExecutorService才会真正关闭。
shutdownNow():
1.该方法返回尚未执行的 task 的 List;
2.线程池的状态变为STOP状态;
3.阻止所有正在等待启动的任务, 并且停止当前正在执行的任务;
简单点来说,就是:
shutdown()调用后,不可以再 submit 新的 task,已经 submit 的将继续执行
shutdownNow()调用后,试图停止当前正在执行的 task,并返回尚未执行的 task 的 list
作者:zjhch123
链接:https://hacpai.com/article/1488023925829
来源:黑客派
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1.2.38.9 线程池中submit() 和 execute()方法有什么区别?
线程池中的execute方法大家都不陌生,即开启线程执行池中的任务。还有一个方法submit也可以做到,它的功能是提交指定的任务去执行并且返回Future对象,即执行的结果。下面简要介绍一下两者的三个区别:
1、接收的参数不一样
2、submit有返回值,而execute没有
用到返回值的例子,比如说我有很多个做validation的task,我希望所有的task执行完,然后每个task告诉我它的执行结果,是成功还是失败,如果是失败,原因是什么。
然后我就可以把所有失败的原因综合起来发给调用者。
个人觉得cancel execution这个用处不大,很少有需要去取消执行的。
而最大的用处应该是第二点。
3、submit方便Exception处理
意思就是如果你在你的task里会抛出checked或者unchecked exception,
而你又希望外面的调用者能够感知这些exception并做出及时的处理,那么就需要用到submit,通过捕获Future.get抛出的异常。
下面一个小程序演示一下submit方法
public class RunnableTestMain {
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(2);
/**
* execute(Runnable x) 没有返回值。可以执行任务,但无法判断任务是否成功完成。
*/
pool.execute(new RunnableTest("Task1"));
/**
* submit(Runnable x) 返回一个future。可以用这个future来判断任务是否成功完成。请看下面:
*/
Future future = pool.submit(new RunnableTest("Task2"));
try {
if(future.get()==null){//如果Future's get返回null,任务完成
System.out.println("任务完成");
}
} catch (InterruptedException e) {
} catch (ExecutionException e) {
//否则我们可以看看任务失败的原因是什么
System.out.println(e.getCause().getMessage());
}
}
}
public class RunnableTest implements Runnable {
private String taskName;
public RunnableTest(final String taskName) {
this.taskName = taskName;
}
@Override
public void run() {
System.out.println("Inside "+taskName);
throw new RuntimeException("RuntimeException from inside " + taskName);
}
}
1.2.39 Java中用到的线程调度算法是什么
操作系统的核心,它实际就是一个常驻内存的程序,不断地对线程队列进行扫描,利用特定的算法(时间片轮转法、优先级调度法、多级反馈队列调度法等)找出比当前占有CPU的线程更有CPU使用权的线程,并从之前的线程中收回处理器,再使待运行的线程占用处理器。
1.2.40 什么是多线程中的上下文切换
什么是上下文切换
即使是单核CPU也支持多线程执行代码,CPU通过给每个线程分配CPU时间片来实现这个机制。时间片是CPU分配给各个线程的时间,因为时间片非常短,所以CPU通过不停地切换线程执行,让我们感觉多个线程时同时执行的,时间片一般是几十毫秒(ms)。
CPU通过时间片分配算法来循环执行任务,当前任务执行一个时间片后会切换到下一个任务。但是,在切换前会保存上一个任务的状态,以便下次切换回这个任务时,可以再次加载这个任务的状态,从任务保存到再加载的过程就是一次上下文切换。
这就像我们同时读两本书,当我们在读一本英文的技术书籍时,发现某个单词不认识, 于是便打开中英文词典,但是在放下英文书籍之前,大脑必须先记住这本书读到了多少页的第多少行,等查完单词之后,能够继续读这本书。这样的切换是会影响读 书效率的,同样上下文切换也会影响多线程的执行速度。
如何减少上下文切换
既然上下文切换会导致额外的开销,因此减少上下文切换次数便可以提高多线程程序的运行效率。减少上下文切换的方法有无锁并发编程、CAS算法、使用最少线程和使用协程。
无锁并发编程。多线程竞争时,会引起上下文切换,所以多线程处理数据时,可以用一些办法来避免使用锁,如将数据的ID按照Hash取模分段,不同的线程处理不同段的数据
CAS算法。Java的Atomic包使用CAS算法来更新数据,而不需要加锁
使用最少线程。避免创建不需要的线程,比如任务很少,但是创建了很多线程来处理,这样会造成大量线程都处于等待状态
协程。在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换
1.2.41.线程优先级
现代操作系统基本采用时分的形式调度运行的线程,线程分配得到的时间片的多少决定了线程使用处理器资源的多少,也对应了线程优先级这个概念。在JAVA线程中,通过一个int priority来控制优先级,范围为1-10,其中10最高,默认值为5。下面是源码(基于1.8)中关于priority的一些量和方法。
private int priority;
/**
* Changes the priority of this thread.
* <p>
* First the <code>checkAccess</code> method of this thread is called
* with no arguments. This may result in throwing a
* <code>SecurityException</code>.
* <p>
* Otherwise, the priority of this thread is set to the smaller of
* the specified <code>newPriority</code> and the maximum permitted
* priority of the thread's thread group.
*
* @param newPriority priority to set this thread to
* @exception IllegalArgumentException If the priority is not in the
* range <code>MIN_PRIORITY</code> to
* <code>MAX_PRIORITY</code>.
* @exception SecurityException if the current thread cannot modify
* this thread.
* @see #getPriority
* @see #checkAccess()
* @see #getThreadGroup()
* @see #MAX_PRIORITY
* @see #MIN_PRIORITY
* @see ThreadGroup#getMaxPriority()
*/
public final void setPriority(int newPriority) {
ThreadGroup g;
checkAccess();
if (newPriority > MAX_PRIORITY || newPriority < MIN_PRIORITY) {
throw new IllegalArgumentException();
}
if((g = getThreadGroup()) != null) {
if (newPriority > g.getMaxPriority()) {
newPriority = g.getMaxPriority();
}
setPriority0(priority = newPriority);
}
}
/**
* Returns this thread's priority.
*
* @return this thread's priority.
* @see #setPriority
*/
public final int getPriority() {
return priority;
}
显然,对于需要较多CPU时间的线程需要设置较低的优先级,这样可以确保处理器不会被独占。
另外:
线程优先级不能作为程序正确性的依赖,因为操作系统可以完全不用理会JAVA线程对于优先级的设定。——->《JAVA并发编程基础》
下面是一个关于线程优先级的程序:
package com.xidian.sortthird;
import java.util.ArrayList;import java.util.List;import java.util.concurrent.TimeUnit;
public class TestPriority
{
private static volatile boolean notStart=true;
private static volatile boolean notEnd=true;
public static void main(String[] args) throws Exception
{
List<Job> jobs = new ArrayList<>();
for(int i = 0;i<10;i++)
{
int priority = i<5?Thread.MIN_PRIORITY:Thread.MAX_PRIORITY;
Job job=new Job(priority);
jobs.add(job);
Thread thread=new Thread(job, "Thread:"+i);
thread.setPriority(priority);
thread.start();
}//使用这个循环启动了10个线程
notStart=false;
TimeUnit.SECONDS.sleep(10);//main线程沉睡10s,使得10个小线程执行结束
notEnd=false;
for(Job job:jobs)
{
System.out.println("JOB priority:"+job.priority+","+job.jobCount);
}
}
static class Job implements Runnable
{
private int priority;
private long jobCount;
public Job(int priority)
{
this.priority=priority;
}
public void run()
{
while(notStart)
{
Thread.yield();//这里确保main线程将10个小线程启动成功
}
while(notEnd)
{
Thread.yield();//这里让出CPU资源,使得10个线程自由竞争。
jobCount++;//记录竞争状态,反映线程的优先级。
}
}
}
}
下面是运行结果,不过这个结果有很大的迷惑性:
JOB priority:1,1099494JOB priority:1,1097710JOB priority:1,1099911JOB priority:1,1100411JOB priority:1,1099721JOB priority:10,5208263JOB priority:10,5198474JOB priority:10,5213148JOB priority:10,5184842JOB priority:10,5172312
可以看出,的确是优先级高的得到的时间片较多,但是这个结果是具有迷惑性的,让我们看一下LINUX环境下的运行结果:
JOB priority:1,3075988
JOB priority:1,2899121
JOB priority:1,2843459
JOB priority:1,2780645
JOB priority:1,2910943
JOB priority:10,3243229
JOB priority:10,12090519
JOB priority:10,3027128
JOB priority:10,6275521
从上面这个结果可以看出,操作系统并没有理会我们设置的线程优先级。
1.2.42 什么是线程调度器(Thread Scheduler)和时间分片(Time Slicing)?
线程调度器是一个操作系统服务,它负责为Runnable状态的线程分配CPU时间。一旦我们创建一个线程并启动它,它的执行便依赖于线程调度器的实现。时间分片是指将可用的CPU时间分配给可用的Runnable线程的过程。分配CPU时间可以基于线程优先级或者线程等待的时间。线程调度并不受到Java虚拟机控制,所以由应用程序来控制它是更好的选择(也就是说不要让你的程序依赖于线程的优先级)。
1.2.43 请说出你所知的线程同步的方法
答:(1).同步代码块
synchronized(object){ 代码段 }
(2)同步函数
public synchronized void sale(){
//…
}
1.2.44 判断代码是线程安全的
如果你的代码在多线程下执行和在单线程下执行永远都能获得一样的结果,那么你的代码就是线程安全的。
1.2.45 解决线程安全
死锁和脏数据就是典型的线程安全问题。
解决线程安全通常做法:访问状态变量时使用同步。 synchronized和Lock都可以实现同步。简单点说,就是在你修改或访问可变状态时加锁,独占对象,让其他线程进不来。达到线程隔离,保证线程安全
1.2.46 wait和sleep的区别
1,这两个方法来自不同的类分别是Thread和Object
2,最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
3,wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
4,sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
1.3 String
1.3.1 String不可变的好处
String是不可变的、final的。Java在运行时也保存了一个字符串池(String pool),这使得String成为了一个特别的类。
好处:
1, 便于实现String常量池
只有当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同 一个字符串。但如果字符串是可变的,那么String interning将不能实现(译者注:String interning是指对不同的字符串仅仅只保存一个,即不会保存多个相同的字符串。),因为这样的话,如果变量改变了它的值,那么其它指向这个值的变量的值也会一起改变。
2, 避免网络安全问题
如果字符串是可变的,那么会引起很严重的安全问题。譬如,数据库的用户名、密码都是以字符串的形式传入来获得数据库的连接,或者在socket编程中,主机名和端口都是以字符串的形式传入。因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变字符串指向的对象的值,造成安全漏洞。
3, 使多线程安全:
因为字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。
4, 避免本地安全性问题
类加载器要用到字符串,不可变性提供了安全性,以便正确的类被加载。譬如你想加载java.sql.Connection类,而这个值被改成了myhacked.Connection,那么会对你的数据库造成不可知的破坏。
5,加快字符串处理速度
因为字符串是不可变的,所以在它创建的时候hashcode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
1.3.2 string,stringbuilder,stringbufferr
答案: 三者在执行速度方面的比较:StringBuilder > StringBuffer > String
StringBuilder:线程非安全的
StringBuffer:线程安全的
区别在于
StringBufferd支持并发操作,线性安全的,适 合多线程中使用。
StringBuilder不支持并发操作,线性不安全的,不适合多线程中使用。
StringBuilder类不是线程安全的,但其在单线程中的性能比StringBuffer高。
对于三者使用的总结: 1.如果要操作少量的数据用 = String
2.单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
3.多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
string 的长度是不可变的;好处:字符串可以共享
StringBuffer的长度是可变的,如果你对字符串中的内容经常进行操作,特别是内容要修改时,那么使用 StringBuffer,如果最后需要转换为String,那么使用 StringBuffer 的 toString() 方法;线程安全;
StringBuilder 是从 JDK 5 开始,为StringBuffer该类补充了一个单个线程使用的等价类;通常应该优先使用 StringBuilder 类,因为它支持所有相同的操作,但由于它不执行同步,所以速度更快。
使用字符串的时候要特别小心,如果对一个字符串要经常改变的话,就一定不要用String,否则会创建许多无用的对象出来
1.3.3 String的api
1.3.4 StringBuffer
String和StringBuffer他们都可以存储和操作字符串,即包含多个字符的字符串数据。
String类是字符串常量,是不可更改的常量。而StringBuffer是字符串变量,它的对象是可以扩充和修改的。
StringBuffer类的构造函数
public StringBuffer()
创建一个空的StringBuffer类的对象。
public StringBuffer( int length )
创建一个长度为 参数length 的StringBuffer类的对象。
注意:如果参数length小于0,将触发NegativeArraySizeException异常。
public StringBuffer( String str )
用一个已存在的字符串常量来创建StringBuffer类的对象。
1.3.5 两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对
不对,如果两个对象x和y满足x.equals(y) == true,它们的哈希码(hash code)应当相同。Java对于eqauls方法和hashCode方法是这样规定的:(1)如果两个对象相同(equals方法返回true),那么它们的hashCode值一定要相同;(2)如果两个对象的hashCode相同,它们并不一定相同。当然,你未必要按照要求去做,但是如果你违背了上述原则就会发现在使用容器时,相同的对象可以出现在Set集合中,同时增加新元素的效率会大大下降(对于使用哈希存储的系统,如果哈希码频繁的冲突将会造成存取性能急剧下降)。
1.3.6 为什么java中的String是不可变的
String是Java中的一个不可变类。所谓不可变,简单来说就是其对象不能被修改。实例中的所有信息在初始化的时候就已经具备,并且不能被修改(老外好啰嗦…)。不可变类有很多优点。这篇文章简要说明了为什么String被设计为不可变类。关于其好的回答应该建立在对内存模型、同步和数据结构等的理解之上。
- 字符串池的需求
字符串池是一个位于方法区的特殊区域。当一个字符串被创建的时候,如果该字符串已经存在于字符串池中,那么直接返回该字符串的引用,而不是创建一个新的字符串。
下边的代码将只会创建一个字符串对象:
String s1 = “abcd”;String s2 = “abcd”;
就不上图了,这块的内容前一篇翻译的文章已经解释过了。也就是s1和s2都指向同一个字符串对象。
如果String不是不可变的,那么修改s1的字符串对象同样也会导致s2的内容发生变化。 - 缓存Hashcode
字符串的hashcode在Java中经常被用到。例如,在一个HashMap中。其不可变性保证了hashcode(哈希值)总是保持不变,从而不用担心因hashcode变化导致的缓存问题。那就意味着,不用每次在其使用的时候计算其hashcode,从而更加高效。
在String类中,有如下代码:
private int hash; //用来缓存hash code - 简化其他对象的使用
为了理解这一点,请看下边的代码:
HashSet set = new HashSet();
set.add(new String(“a”));
set.add(new String(“b”));
set.add(new String(“c”));for (String a : set)
a.value = “a”;
这个例子中,如果String是可变的,也就是说set中的值是可变的,这会影响到set的设计(set包含不重复的元素)。当然这个例子是有问题的,在String类中是不存在value这个属性的。
4.安全性
字符串在许多的java类中都用作参数,例如网络连接,打开文件等等。如果字符串是可变的,一个连接或文件就会被修改从而导致严重的错误。可变的字符串也会导致在使用反射时导致严重的问题,因为参数是字符串形式的。
举例如下:
boolean connect(String s) {
if (!isSecure(s)) {
throw new SecurityException();
}
// 如果s内的值被修改,则会导致出现问题
doSomethind(s);
}
(虽然略牵强,但是也有一定道理) - 不可变的对象本身就是线程安全的
不可变的对象,可以在多个线程间自由共享。从而免除了进行同步的麻烦。
总之, String被设计为不可变的类,是出于性能和安全性的考虑,这也是其他所有不可变类应用的初衷
1.3.7 如何判断一个字符串是空值或者空字符串
StringUtils isBlank();
补充:
1.类型:
null表示的是一个对象的值,而并不是一个字符串。例如声明一个对象的引用,String a = null ;
““表示的是一个空字符串,也就是说它的长度为0。例如声明一个字符串String str = “” ;
2、内存分配
String str = null ; 表示声明一个字符串对象的引用,但指向为null,也就是说还没有指向任何的内存空间;
String str = “”; 表示声明一个字符串类型的引用,其值为””空字符串,这个str引用指向的是空字符串的内存空间;
在java中变量和引用变量是存在栈中(stack),而对象(new产生的)都是存放在堆中(heap):
1.3.8 分割字符串有几种方式?
第一种方法:
可能一下子就会想到使用split()方法,用split()方法实现是最方便的,但是它的效率比较低
第二种方法:
使用效率较高的StringTokenizer类分割字符串,StringTokenizer类是JDK中提供的专门用来处理字符串分割子串的工具类
第三种方法:
使用String的两个方法—indexOf()和subString(),subString()是采用了时间换取空间技术,因此它的执行效率相对会很快,只要处理好内存溢出问题,但可大胆使用。而indexOf()函数是一个执行速度非常快的方法,
1.4 JVM
1.4.1 jvm加载class文件
JVM加载Class包括3个阶段:类加载,链接,初始化
1.类加载
JVM通过类的全限定名(包命+类名)找到类的.class文件。然后把这个.class文件加载进来,这个过程需要通过ClassLoader来实现。
ClassLoader包括
Boostrap ClassLoader,
Extendsion ClassLoader
System ClassLoader。
Boostrap ClassLoader:启动类加载器,它用来加载一些jdk的核心类,主要负责JAVA_HOME
/jre/lib下的类的加载,可以通过参数-Xbootclasspath制定需要装入的jar包。 它本身不是用java实现的,所以肯定不是ClassLoader的子类了。
Extendsion ClassLoader:扩展类加载器,用来加载一些扩展类,主要负责JAVA_HOME
/jre/lib/ext下类的加载。此类是ClassLoader的一个子类。
System ClassLoader:系统类加载器 也叫Application ClassLoader。是离我们最近的ClassLoader了,它负责加载CLASSPATH里指定的那些类。我们要实现自己的ClassLoader也是继承自该类。SystemClassLoader的父类是Extension ClassLoader。
类的加载过程分两步:第一步:从下往上查找类是否已经加载,如果找到,直接返回已加载的类,如果没找着接着往上找。第二步:如果到Bootstrap ClassLoader还没找到,这时Bootstrap ClassLoader会尝试加载该类,如果成功加载,直接返回加载后的类,如果无法加载,交由Extension ClassLoader去加载,依次类推。如果最后仍然没找到,程序会抛出ClassNotFoundException。
2 链接:
当一个class文件被成功加载后,接下来就要做链接了。链接就是要把二进制的.class文件转换成可以被jvm执行的Class对象的过程。这个过程又分为:检验、准备、解析。
检验:就是检查.class的结构是否正确,是否符合Java虚拟机的语义要求。
准备:包括创建类或接口的静态域以及把这些静态域初始化为标准的缺省值。注意此处的初始化不同于后面的的初始化步骤。如有一个static的String 变量str,我们知道,在JAVA中String变量默认的初始值是null,此处的初始化就是将null赋值给str。
解析:将类中对另一个类或接口的符合引号转化成全限定名引用,将对他们的方法、字段的符合引用转化成直接引用。
3 初始化:执行类或接口中的静态初始化函数(块),将静态变量初始化。这就是我们平时理解的对静态变量赋值。
至此,一个类才加载完成,可以调用类的类变量了(静态变量)和对类进行实例化了。
1.4.2 对象的创建过程
JVM会先去方法区下找有没有所创建对象的类存在,有就可以创建对象了,没有则把该类加载到方法区
在创建类的对象时,首先会先去堆内存中分配空间
当空间分配完后,加载对象中所有的非静态成员变量到该空间下
所有的非静态成员变量加载完成之后,对所有的非静态成员进行默认初始化
所有的非静态成员默认初始化完成之后,调用相应的构造方法到栈中
在栈中执行构造函数时,先执行隐式,再执行构造方法中书写的代码
执行顺序:静态代码库,构造代码块,构造方法
当整个构造方法全部执行完,此对象创建完成,并把堆内存中分配的空间地址赋给对象名(此时对象名就指向了该空间)
1.4.3 Jvm虚拟机内存主要分为以下几个区
程序计数器:可以看作是当前线程所执行的字节码文件(class)的行号指示器,它会记录执行痕迹,是每个线程私有的;
栈:栈是运行时创建的,是线程私有的,生命周期与线程相同,存储声明的变量的
本地方法栈:为native方法服务,native方法是一种由非java语言实现的java方法,为什么使用这种方法呢,与java环境外交互, 或者与操作系统交互
堆:堆是所有线程共享的一块内存,是在java虚拟机启动时创建的,几乎所有对象实例都在此创建,所以经常发生垃圾回收操作;
方法区:主要存储已被虚拟机加载的类的信息,常量,静态变量和即时编译器编译后的代码等数据,该区域是被线程共享的,很少发生垃圾回收
1.4.4 方法区堆栈溢出
jdk1.7之前字符串常量池是方法区的一部分,方法区叫做“永久代”,在1.7之前无限的创建对象就会造成内存溢出
用jdk1.7之后,开始逐步去永久代,就不会产生内存溢出
1.4.5 jvm参数的含义
Xms:初始堆大小
-Xmx:堆最大内存
-Xss:栈内存
-XX:PermSize 初始永久带内存
-XX:MaxPermSize 最大永久带内存
-server:服务器模式
-Xms512m :初始堆空间
-Xmx512m:最大堆空间
-Xss1024K :栈空间
-XX:PermSize=256m :初始永久带空间
-XX:MaxPermSize=512m :最大永久带空间
-XX:MaxTenuringThreshold=20 :对象的生命周期
XX:CMSInitiatingOccupancyFraction=80 :老年代的内存在使用到70%的时候,就开始启动CMS了
-XX:+UseCMSInitiatingOccupancyOnly:它就只会按照你设置的比率来启动CMS GC了
-XX:+UseCompressedOops 有什么作用 当你将你的应用从 32 位的 JVM 迁移到 64 位的 JVM 时,由于对象的指针从 32 位增加到了 64 位,因此堆内存会突然增加,差不多要翻倍。这也会对 CPU 缓存(容量比内存小很多)的数据产生不利的影响。因为,迁移到 64 位的 JVM 主要动机在于可以指定最大堆大小,通过压缩 OOP 可以节省一定的内存。通过 -XX:+UseCompressedOops 选项,JVM 会使用 32 位的 OOP,而不是 64 位的 OOP。
1.4.6 当出现了内存溢出,你怎么排错。
1.首先控制台查看错误日志
2.然后使用jdk自带的jvisualvm工具查看系统的堆栈日志
3.定位出内存溢出的空间:堆,栈还是永久代(jdk8以后不会出现永久代的内存溢出)。
4.如果是堆内存溢出,看是否创建了超大的对象
5.如果是栈内存溢出,看是否创建了超大的对象,或者产生了死循环。
1.4.7. JVM内存模型的相关知识了解多少,比如重排序,内存屏障,happen-before,主内存,工作内存等。
重排序:jvm虚拟机允许在不影响代码最终结果的情况下,可以乱序执行。
内存屏障:可以阻挡编译器的优化,也可以阻挡处理器的优化
happens-before原则:
1:一个线程的A操作总是在B之前,那多线程的A操作肯定实在B之前。
2:monitor 再加锁的情况下,持有锁的肯定先执行。
3:volatile修饰的情况下,写先于读发生
4:线程启动在一起之前 strat
5:线程死亡在一切之后 end
6:线程操作在一切线程中断之前
7:一个对象构造函数的结束都该对象的finalizer的开始之前
8:传递性,如果A肯定在B之前,B肯定在C之前,那A肯定是在C之前。
主内存:所有线程共享的内存空间
工作内存:每个线程特有的内存空间
1.4.8 JVM如何加载字节码文件
1、通过一个类的全限定名(包名与类名)来获取定义此类的二进制字节流(Class文件)。而获取的方式,可以通过jar包、war包、网络中获取、JSP文件生成等方式。
2、将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。这里只是转化了数据结构,并未合并数据。(方法区就是用来存放已被加载的类信息,常量,静态变量,编译后的代码的运行时内存区域)
3、在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。这个Class对象并没有规定是在Java堆内存中,它比较特殊,虽为对象,但存放在方法区中。
1.4.9 类加载器分类
从Java虚拟机的角度来讲,只存在两种不同的类加载器:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器是虚拟机的一部分;另一种就是所有其他的类加载器,这些类加载器都由Java语言实现,独立于虚拟机,并且全部继承自java.lang.ClassLoader。细分来看,类加载器还可以分为如下几类:
1.启动类加载器:Bootstrap ClassLoader,负责加载存放在JDK\jre\lib(JDK代表JDK的安装目录,下同)下,或被-Xbootclasspath参数指定的路径中的,并且能被虚拟机识别的类库。(用来加载java核心类库,无法被java程序直接引用。)
2.扩展类加载器:Extension ClassLoader,该加载器由sun.misc.LauncherKaTeX parse error: Undefined control sequence: \jre at position 25: …oader实现,它负责加载DK\̲j̲r̲e̲\lib\ext目录中,或者由…JAVA_HOME中jre/lib/.jar或-Djava.ext.dirs指定目录下的jar包)
3.应用程序类加载器:Application ClassLoader,该类加载器由sun.misc.Launcher$AppClassLoader来实现,它负责加载用户类路径(ClassPath)所指定的类,开发者可以直接使用该类加载器
4.Custom ClassLoader/用户自定义类加载器(通过继承 java.lang.ClassLoader类的方式实现。)
属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader
1 Bootstrap ClassLoader
Bootstrap ClassLoader被称为根类加载器,它负责加载Java的核心类。根类加载器并不是java.lang.ClassLoader的子类,而是由JVM自身实现的。在Sun的JVM中,当执行java.exe命令时,使用-Xbootclasspath选择或使用-D选项指定sun.boot.class.path系统属性值可以指定加载附加的类。
通过如下程序查看根类加载器加载的类的路径:
.
public class LoaderTest {
public static void main(String[] args) throws IOException {
// 获取根类加载器所加载的全部URL数组
URL[] urls = Launcher.getBootstrapClassPath().getURLs();
// 遍历、输出根类加载器加载的全部URL
System.out.println(“根类加载器加载的全部URL***”);
for (URL url : urls) {
System.out.println(url.toExternalForm());
}
}
}
输出结果:
.
根类加载器加载的全部URL****
file:/D:/Java/jdk1.7.0_80/jre/lib/resources.jar
file:/D:/Java/jdk1.7.0_80/jre/lib/rt.jar
file:/D:/Java/jdk1.7.0_80/jre/lib/sunrsasign.jar
file:/D:/Java/jdk1.7.0_80/jre/lib/jsse.jar
file:/D:/Java/jdk1.7.0_80/jre/lib/jce.jar
file:/D:/Java/jdk1.7.0_80/jre/lib/charsets.jar
file:/D:/Java/jdk1.7.0_80/jre/lib/jfr.jar
file:/D:/Java/jdk1.7.0_80/jre/classes
.
2 Extension ClassLoader
Extension ClassLoader是扩展类加载器,它负责加载JRE的扩展目录中JAR包的类,或者被java.ext.dirs系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器。
3 Application ClassLoader
Application ClassLoader是应用程序类加载器,由sun.misc.Launcher$AppClassLoader实现,可以通过ClassLoader.getSystemClassLoader()方法获取,因此也被称为系统类加载器。它负责加载用户类路径(ClassPath)上指定的类库,开发者可以直接使用这个类加载器,如果应用程序没有自定义类加载器,一般情况下这个就是程序中默认的类加载器。
4 自定义类加载器器
为了实现类加载的个性化定制,我们可以通过扩展java.lang.ClassLoader类来实现自定义类加载器,详细的实现随后描述。
我们的应用程序一般都是由这几种类加载器相互配合进行加载的,类加载器之间的关系如图:
类加载器之间的关系并非是类继承性质的父子关系,而是一种组合关系。
1.4.10 内存溢出的原因是什么?
内存溢出是由于没被引用的对象(垃圾)过多造成JVM没有及时回收,造成的内存溢出。如果出现这种现象可行代码排查:
一)是否App中的类中和引用变量过多使用了Static修饰 如public staitc Student s;在类中的属性中使用 static修饰的最好只用基本类型或字符串。如public static int i = 0; //public static String str;
二)是否App中使用了大量的递归或无限递归(递归中用到了大量的建新的对象)
三)是否App中使用了大量循环或死循环(循环中用到了大量的新建的对象)
四)检查App中是否使用了向数据库查询所有记录的方法。即一次性全部查询的方法,如果数据量超过10万多条了,就可能会造成内存溢出。所以在查询时应采用“分页查询”。
五)检查是否有数组,List,Map中存放的是对象的引用而不是对象,因为这些引用会让对应的对象不能被释放。会大量存储在内存中。
六)检查是否使用了“非字面量字符串进行+”的操作。因为String类的内容是不可变的,每次运行”+“就会产生新的对象,如果过多会造成新String对象过多,从而导致JVM没有及时回收而出现内存溢出。
如String s1 = “My name”;
String s2 = “is”;
String s3 = “xuwei”;
String str = s1 + s2 + s3 +…;这是会容易造成内存溢出的
但是String str = “My name” + ” is ” + ” xuwei” + ” nice ” + ” to ” + ” meet you”; //但是这种就不会造成内存溢出。因为这是”字面量字符串“,在运行”+“时就会在编译期间运行好。不会按照JVM来执行的。
在使用String,StringBuffer,StringBuilder时,如果是字面量字符串进行”+“时,应选用String性能更好;如果是String类进行”+”时,在不考虑线程安全时,应选用StringBuilder性能更好。
1.public class Test {
2.
3. public void testHeap(){
4. for(;?{ //死循环一直创建对象,堆溢出
5. ArrayList list = new ArrayList (2000);
6. }
7. }
8. int num=1;
9. public void testStack(){ //无出口的递归调用,栈溢出
10. num++;
11. this.testStack();
12. }
13.
14. public static void main(String[] args){
15. Test t = new Test ();
16. t.testHeap();
17. t.testStack();
18. }
19.}
七)使用 DDMS工具进行查找内存溢出的大概位置
1.4.11栈溢出的原因
一)、是否有递归调用
二)、是否有大量循环或死循环
三)、全局变量是否过多
四)、 数组、List、map数据是否过大
五)使用DDMS工具进行查找大概出现栈溢出的位置
1.4.12JVM内存分为哪几部分,这些部分分别都存储哪些数据?
按照Java虚拟机规范的规定,JVM自动管理的内存将会包括以下几个运行时数据区域。
1.4.13一个对象从创建到销毁都是怎么在这些部分里存活和转移的?
Student stu = new Student(“zhangsan”);
stu.add();
stu=null;
1、用户创建了一个Student对象,运行时JVM首先会去方法区寻找该对象的类型信息,没有则使用类加载器classloader将Student.class字节码文件加载至内存中的方法区,并将Student类的类型信息存放至方法区。
2、接着JVM在堆中为新的Student实例分配内存空间,这个实例持有着指向方法区的Student类型信息的引用,引用指的是类型信息在方法区中的内存地址。
3、在此运行的JVM进程中,会首先起一个线程跑该用户程序,而创建线程的同时也创建了一个虚拟机栈,虚拟机栈用来跟踪线程运行中的一系列方法调用的过程,每调用一个方法就会创建并往栈中压入一个栈帧,栈帧用来存储方法的参数,局部变量和运算过程的临时数据。上面程序中的stu是对Student的引用,就存放于栈中,并持有指向堆中Student实例的内存地址。
4、JVM根据stu引用持有的堆中对象的内存地址,定位到堆中的Student实例,由于堆中实例持有指向方法区的Student类型信息的引用,从而获得add()方法的字节码信息,接着执行add()方法包含的指令。
5、将stu指向null
6、JVM GC
1.4.14解释内存中的栈(stack)、堆(heap)和方法区(method area)的用法
栈的使用:通常我们定义一个基本数据类型的变量,一个对象的引用,还有就是函数调用的现场保存都使用JVM中的栈空间。
队的使用:通过new关键字和构造器创建的对象则放在堆空间,堆是垃圾收集器管理的主要区域。
方法区的使用:方法区和堆都是各个线程共享的内存区域,用于存储已经被JVM加载的类信息、常量、静态变量、JIT编译器编译后的代码等数据;程序中的字面量(literal)如直接书写的100、”hello”和常量都是放在常量池中,常量池是方法区的一部分。
栈空间操作起来最快但是栈很小,通常大量的对象都是放在堆空间,栈和堆的大小都可以通过JVM的启动参数来进行调整,栈空间用光了会引发StackOverflowError,而堆和常量池空间不足则会引发OutOfMemoryError。
例子:
String str = new String(“hello”);
上面的语句中变量str放在栈上,用new创建出来的字符串对象放在堆上,而”hello”这个字面量是放在方法区的。
1.4.15简述内存分配与回收策略
对象优先在 Eden 分配
大对象直接进入老年代
长期存活对象进入老年代
动态对象年龄判定
空间分配担保
Java技术体系提倡的自动内存管理,最终,可以归结为自动化解决两个问题
给对象分配内存
回收分配给对象的内存
给对象分配内存,大方向上,是在堆上分配,但也可能经过JIT编译后,被拆散为标量类型,并间接地栈上分配
对象主要分配在新生代的Eden区域,如果启动了本地线程分配缓冲,将按线程,优先在Thread Local Allocation Buffer上分配。少数情况下,可能会直接分配到老年代。
具体取决于使用哪种垃圾收集器组合,还有配置参数
对象优先在 Eden 分配
大多数情况下,对象在新生代Eden区中分配,当Eden区没有足够空间分配时,虚拟机发生一次Minor GC
大对象直接进入老年代
-XX:PretenureSizeThreshold
长期存活对象进入老年代
-XX:MaxTenuringThreshold
Age计数器,如果Eden出生并经过第一次Minor GC 后存活,且能被Survior空间容纳,对象移动到Survivor,年龄+1
加到一定程度,默认是15,晋升到老年代
动态对象年龄判定
当Survivor中,相同年齡的对象大小,超过了Survivor空间的一半,这些年龄大于或等于这个年龄的对象,可以直接进入老年代
空间分配担保
新生代使用复制算法,当新生代出现大对象时,为保证能分配到空间,需要老年代的空间做担保,以便让大对象可以在新生代空间不足的情况下进入老年代,否则就只能Full GC
在Minor GC前,JVM 先检查老年代最大可用的连续空间是否大于 新生代所有对象的总和,
-如果大于,Minor GC可以确保安全
-如果小于,JVM会看HandlePromotionFailure设置值是否允許担保失败,
–如果允许,检查老年代最大可用连续空间是否大于历次晋升到老年代对象的平均大小
—如果大于,尝试Minor GC
—如果小于,Full GC
–如果不允许,Full GC
1.4.16 Java中存在内存泄漏问题吗?请举例说明
在Java语言中,判断一个内存空间是否符合垃圾回的标准有两个:
第一:给对象赋予了空值null,以后再没有被使用过;
第二:给对象赋予了新值,重新分配了内存空间。
一般来讲,内存泄漏主要有两种情况:
一是在堆中申请了空间没有被释放;
二是对象已不再被使用,但还仍然在内存中保留着。
垃圾回收机制的引入可以有效地解决第一种情况;而对于第二种情况,垃圾回收机制则无法保证不再使用的对象会被释放。因此Java语言中的内存泄漏主要指的第二种情况。
Java语言中,容易引起内存泄漏的原因有很多,主要有以下几个方面的内容:
(1)静态集合类,例如HashMap和Vector。如果这些容器为静态的,由于它们的声明周期与程序一致,那么容器中的对象在程序结束之前将不能被释放,从而造成内存泄漏。
(2)各种连接,例如数据库的连接、网络连接以及IO连接等。
(3)监听器。在Java语言中,往往会使用到监听器。通常一个应用中会用到多个监听器,但在释放对象的同时往往没有相应的删除监听器,这也可能导致内存泄漏。
(4)变量不合理的作用域。一般而言,如果一个变量定义的作用域大于其使用范围,很有可能会造成内存泄漏,另一方面如果没有及时地把对象设置为Null,很有可能会导致内存泄漏的放生,如下:
class Server{
private String msg;
public void receiveMsg(){
readFromNet();//从网络接收数据保存在msg中
saveDB()//把msg保存到数据库中
}
从上面的代码中,通过readFromNet()方法接收的消息保存在变量msg中,然后调用saveDB()方法把msg的内容保存到数据库中,此时msg已经没用了,但是由于msg的声明周期与对象的声明周期相同,此时msg还不能被回收,因此造成了内存泄漏。对于这个问题,有如下两种解决方案:第一种方法,由于msg的作用范围只在receiveMsg()方法内,因此可以把msg定义为这个方法的局部变量,当方法结束后,msg的声明周期就会结束,此时垃圾回收器就会可以回收msg的内容了;第二种方法,在使用完msg后就设置为null,这样垃圾回收器也会自动回收msg内容所占用的内存空间。
(5)单例模式可能会造成内存泄漏
1.4.17 JVM自身会维护缓存吗,是不是在堆中进行对象分配,操作系统的堆还是JVM自己管理的堆?为什么?
答案:是的,JVM自身会管理缓存,它在堆中创建对象,然后在栈中引用这些对象。
1.4.18 类加载过程
Jvm先去方法区下找类是否存在,如果不存在,则把类加载到方法区下
先加载非静态内容到方法区下的非静态区域内
再加载静态内容到方法区下的静态区域内,并对所有的静态成员变量进行默认初始化,再对所有的静态成员变量显式初始化
JVM自动执行静态代码块(静态代码块在栈中执行)[如果有多个静态代码,执行的顺序是按照代码书写的先后顺序执行]
所有的静态代码块执行完成之后,此时类的加载完成
1.4.19
1.4.20
1.5 设计模式
1.5.1 单例模式在项目中的应用
日志,数据库连接池,网站技术,多线程线程池
单例模式有以下特点:
1、单例类只能有一个实例。
2、单例类必须自己创建自己的唯一实例。
3、单例类必须给所有其他对象提供这一实例。
单例模式确保某个类只有一个实例,而且自行实例化并向整个系统提供这个实例。
1.5.2 常见的设计模式
工厂模式:一个抽象接口的实现,多个抽象接口的实现类,spring的beanFactory就是工厂模式
单例模式:spring配置文件中配置的bean默认为单例模式
装饰者模式:对一个类进行装饰,增强其方法行为,如Java中的IO流就使用了装饰者模式
代理模式:比如动态代理
适配器模式:io流,通过继承实现将一个接口适配到另一个接口,InputStreamReader类继承Reader接口,但要创建它们必须在构造函数中传入一个InputStream的实例,InputStreamReader的作用也就是将InputStream适配到Reader
装饰器模式关注于在一个对象上动态的添加方法,然而代理模式关注于控制对对象的访问
1.5.3 单例模式的实现
饿汉式:
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
private Singleton1() {}
private static final Singleton1 single = new Singleton1();
//静态工厂方法
public static Singleton1 getInstance() {
return single;
}
}
懒汉式:
//懒汉式单例类.在第一次调用的时候实例化自己
public class Singleton {
private Singleton() {}
private static Singleton single=null;
//静态工厂方法
public static Singleton getInstance() {
if (single == null) {
single = new Singleton();
}
return single;
}
}
饿汉式就是类一旦加载,就把单例初始化完成,保证getInstance()的时候,单例就已经存在
懒汉式比较懒,只有当调用getInstance的时候,才会去初始化这个单例
区别:
饿汉式是线程安全的,懒汉式是线程不安全的(即一个进程内有多个线程在在同时使用时可能会产生多个实例,可创建个静态内部类,产生一个单例对象,通过静态内部类返回获取这个对象)
public class Singleton {
private Singleton (){};
private static class LazyHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static final Singleton getInstance() {
return LazyHolder.INSTANCE;
}
}
资源加载和性能问题:饿汉式在类创建的同时就实例化一个静态对象出来,所以会占据一定的内存,但是相应的,在第一次调用时速度也会更快,因为其资源已经初始化完成,
而懒汉式顾名思义,会延迟加载,在第一次使用该单例的时候才会实例化对象出来,第一次调用时要做初始化,如果要做的工作比较多,性能上会有些延迟,之后就和饿汉式一样了
1.5.4什么是设计模式(Design Patterns)?你用过哪种设计模式?用在什么场合
什么是设计模式
一套被反复使用、多数人知晓的、经过分类编目的、代码 设计经验 的总结;
使用设计模式是为了 可重用 代码、让代码 更容易 被他人理解、保证代码 可靠性;
设计模式使代码编制 真正工程化;
设计模式使软件工程的 基石脉络, 如同大厦的结构一样;
并不直接用来完成代码的编写,而是 描述 在各种不同情况下,要怎么解决问题的一种方案;
能使不稳定依赖于相对稳定、具体依赖于相对抽象,避免引起麻烦的紧耦合,以增强软件设计面对并适应变化的能力。
设计模式的由来
建筑师 克里斯托佛·亚历山大 在1977-1979年编制了一本汇集设计模式的书
肯特· 贝克 和 沃德·坎宁安 在 1987年,利用克里斯托佛·亚历山大 在建筑设计领域里的思想开发了 设计模式 并把此思想 应用在Smalltalk 中的图形用户接口的生成中
1988年,Erich Gamma 在他的苏黎世大学博士毕业论文中开始尝试把这种思想 改写为适用于软件开发
与此同时 James Coplien 在 1989年至1991 年 也在利用相同的思想致力于C++ 的 开发,而后与1991 年 发表了他的著作 Advanced C++ Idioms。
1995年,Richard Helm,Ralph Johnson,John Vlissides(Gof)合作出版了 Design Patterns – Elements of Reusable Object-Oriented Software 一书,在此书中收录了23 个设计模式。
1.5.5哪些设计模式可以增加系统的可扩展性
可扩展性:
工厂模式
抽象工厂模式
观察者模式:很方便增加观察者,方便系统扩展
模板方法模式:很方便的实现不稳定的扩展点,完成功能的重用
适配器模式:可以很方便地对适配其他接口
代理模式:可以很方便在原来功能的基础上增加功能或者逻辑
责任链模式:可以很方便得增加拦截器/过滤器实现对数据的处理,比如struts2的责任链
策略模式:通过新增策略从而改变原来的执行策略
1.5.6 单例模式有五种写法:懒汉、饿汉、双重检验锁、静态内部类、枚举。
单例模式算是设计模式中最容易理解,也是最容易手写代码的模式了吧。但是其中的坑却不少,所以也常作为面试题来考。本文主要对几种单例写法的整理,并分析其优缺点。很多都是一些老生常谈的问题,但如果你不知道如何创建一个线程安全的单例,不知道什么是双检锁,那这篇文章可能会帮助到你。
懒汉式,线程不安全
当被问到要实现一个单例模式时,很多人的第一反应是写出如下的代码,包括教科书上也是这样教我们的。
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
这段代码简单明了,而且使用了懒加载模式,但是却存在致命的问题。当有多个线程并行调用 getInstance() 的时候,就会创建多个实例。也就是说在多线程下不能正常工作。
懒汉式,线程安全
为了解决上面的问题,最简单的方法是将整个 getInstance() 方法设为同步(synchronized)。
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
虽然做到了线程安全,并且解决了多实例的问题,但是它并不高效。因为在任何时候只能有一个线程调用 getInstance() 方法。但是同步操作只需要在第一次调用时才被需要,即第一次创建单例实例对象时。这就引出了双重检验锁。
双重检验锁
双重检验锁模式(double checked locking pattern),是一种使用同步块加锁的方法。程序员称其为双重检查锁,因为会有两次检查 instance == null,一次是在同步块外,一次是在同步块内。为什么在同步块内还要再检验一次?因为可能会有多个线程一起进入同步块外的 if,如果在同步块内不进行二次检验的话就会生成多个实例了。
public static Singleton getSingleton() {
if (instance == null) { //Single Checked
synchronized (Singleton.class) {
if (instance == null) { //Double Checked
instance = new Singleton();
}
}
}
return instance ;
}
这段代码看起来很完美,很可惜,它是有问题。主要在于instance = new Singleton()这句,这并非是一个原子操作,事实上在 JVM 中这句话大概做了下面 3 件事情。
给 instance 分配内存
调用 Singleton 的构造函数来初始化成员变量
将instance对象指向分配的内存空间(执行完这步 instance 就为非 null 了)
但是在 JVM 的即时编译器中存在指令重排序的优化。也就是说上面的第二步和第三步的顺序是不能保证的,最终的执行顺序可能是 1-2-3 也可能是 1-3-2。如果是后者,则在 3 执行完毕、2 未执行之前,被线程二抢占了,这时 instance 已经是非 null 了(但却没有初始化),所以线程二会直接返回 instance,然后使用,然后顺理成章地报错。
我们只需要将 instance 变量声明成 volatile 就可以了。
public class Singleton {
private volatile static Singleton instance; //声明成 volatile
private Singleton (){}
public static Singleton getSingleton() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
有些人认为使用 volatile 的原因是可见性,也就是可以保证线程在本地不会存有 instance 的副本,每次都是去主内存中读取。但其实是不对的。使用 volatile 的主要原因是其另一个特性:禁止指令重排序优化。也就是说,在 volatile 变量的赋值操作后面会有一个内存屏障(生成的汇编代码上),读操作不会被重排序到内存屏障之前。比如上面的例子,取操作必须在执行完 1-2-3 之后或者 1-3-2 之后,不存在执行到 1-3 然后取到值的情况。从「先行发生原则」的角度理解的话,就是对于一个 volatile 变量的写操作都先行发生于后面对这个变量的读操作(这里的“后面”是时间上的先后顺序)。
但是特别注意在 Java 5 以前的版本使用了 volatile 的双检锁还是有问题的。其原因是 Java 5 以前的 JMM (Java 内存模型)是存在缺陷的,即时将变量声明成 volatile 也不能完全避免重排序,主要是 volatile 变量前后的代码仍然存在重排序问题。这个 volatile 屏蔽重排序的问题在 Java 5 中才得以修复,所以在这之后才可以放心使用 volatile。
相信你不会喜欢这种复杂又隐含问题的方式,当然我们有更好的实现线程安全的单例模式的办法。
饿汉式 static final field
这种方法非常简单,因为单例的实例被声明成 static 和 final 变量了,在第一次加载类到内存中时就会初始化,所以创建实例本身是线程安全的。
public class Singleton{
//类加载时就初始化
private static final Singleton instance = new Singleton();
private Singleton(){}
public static Singleton getInstance(){
return instance;
}
}
这种写法如果完美的话,就没必要在啰嗦那么多双检锁的问题了。缺点是它不是一种懒加载模式(lazy initialization),单例会在加载类后一开始就被初始化,即使客户端没有调用 getInstance()方法。饿汉式的创建方式在一些场景中将无法使用:譬如 Singleton 实例的创建是依赖参数或者配置文件的,在 getInstance() 之前必须调用某个方法设置参数给它,那样这种单例写法就无法使用了。
静态内部类 static nested class
我比较倾向于使用静态内部类的方法,这种方法也是《Effective Java》上所推荐的。
public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
这种写法仍然使用JVM本身机制保证了线程安全问题;由于 SingletonHolder 是私有的,除了 getInstance() 之外没有办法访问它,因此它是懒汉式的;同时读取实例的时候不会进行同步,没有性能缺陷;也不依赖 JDK 版本。
枚举 Enum
用枚举写单例实在太简单了!这也是它最大的优点。下面这段代码就是声明枚举实例的通常做法。
public enum EasySingleton{
INSTANCE;
}
我们可以通过EasySingleton.INSTANCE来访问实例,这比调用getInstance()方法简单多了。创建枚举默认就是线程安全的,所以不需要担心double checked locking,而且还能防止反序列化导致重新创建新的对象。但是还是很少看到有人这样写,可能是因为不太熟悉吧。
总结
一般来说,单例模式有五种写法:懒汉、饿汉、双重检验锁、静态内部类、枚举。上述所说都是线程安全的实现,文章开头给出的第一种方法不算正确的写法。
就我个人而言,一般情况下直接使用饿汉式就好了,如果明确要求要懒加载(lazy initialization)会倾向于使用静态内部类,如果涉及到反序列化创建对象时会试着使用枚举的方式来实现单例。
1.5.7适配器模式是什么?什么时候使用
适配器模式将某个类的接口转换成客户端期望的另一个接口表示,主的目的是兼容性,让原本因接口不匹配不能一起工作的两个类可以协同工作。其别名为包装器(Wrapper)。
属于结构型模式
主要分为三类:类适配器模式、对象的适配器模式、接口的适配器模式。
使用场景:
1 系统需要使用现有的类,而这些类的接口不符合系统的需要。
2 想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作。
3 需要一个统一的输出接口,而输入端的类型不可预知。
二 类适配器模式:
一句话描述:Adapter类,通过继承 src类,实现 dst 类接口,完成src->dst的适配。
别的文章都用生活中充电器的例子来讲解适配器,的确,这是个极佳的举例,本文也不能免俗:
充电器本身相当于Adapter,220V交流电相当于src,我们的目dst标是5V直流电。
我们现有的src类:
/**
- 介绍:src类: 我们有的220V电压
- 作者:zhangxutong
- 邮箱:zhangxutong@imcoming.com
- 时间: 2016/10/18.
*/
public class Voltage220 {
public int output220V() {
int src = 220;
System.out.println(“我是” + src + “V”);
return src;
}
}
我们想要的dst接口:
/**
- 介绍:dst接口:客户需要的5V电压
- 作者:zhangxutong
- 邮箱:zhangxutong@imcoming.com
- 时间: 2016/10/18.
*/
public interface Voltage5 {
int output5V();
}
适配器类:
/**
- 介绍:Adapter类:完成220V-5V的转变
- 通过继承src类,实现 dst 类接口,完成src->dst的适配。
- 作者:zhangxutong
- 邮箱:zhangxutong@imcoming.com
- 时间: 2016/10/18.
*/
public class VoltageAdapter extends Voltage220 implements Voltage5 {
@Override
public int output5V() {
int src = output220V();
System.out.println(“适配器工作开始适配电压”);
int dst = src / 44;
System.out.println(“适配完成后输出电压:” + dst);
return dst;
}
}
Client类:
/**
- 介绍:Client类:手机 .需要5V电压
- 作者:zhangxutong
- 邮箱:zhangxutong@imcoming.com
- 时间: 2016/10/18.
*/
public class Mobile {
/**
* 充电方法
*
* @param voltage5
*/
public void charging(Voltage5 voltage5) {
if (voltage5.output5V() == 5) {
System.out.println(“电压刚刚好5V,开始充电”);
} else if (voltage5.output5V() > 5) {
System.out.println(“电压超过5V,都闪开 我要变成note7了”);
}
}
}
测试代码:
System.out.println(“=类适配器”);
Mobile mobile = new Mobile();
mobile.charging(new VoltageAdapter());
输出:
=类适配器
我是220V
适配器工作开始适配电压
适配完成后输出电压:5
电压刚刚好5V,开始充电
类图如下:
小结:
Java这种单继承的机制,所有需要继承的我个人都不太喜欢。
所以类适配器需要继承src类这一点算是一个缺点,
因为这要求dst必须是接口,有一定局限性;
且src类的方法在Adapter中都会暴露出来,也增加了使用的成本。
但同样由于其继承了src类,所以它可以根据需求重写src类的方法,使得Adapter的灵活性增强了。
三 对象适配器模式(常用):
基本思路和类的适配器模式相同,只是将Adapter类作修改,这次不继承src类,而是持有src类的实例,以解决兼容性的问题。
即:持有 src类,实现 dst 类接口,完成src->dst的适配。
(根据“合成复用原则”,在系统中尽量使用关联关系来替代继承关系,因此大部分结构型模式都是对象结构型模式。)
Adapter类如下:
/**
- 介绍:对象适配器模式:
- 持有 src类,实现 dst 类接口,完成src->dst的适配。 。以达到解决兼容性的问题。
- 作者:zhangxutong
- 邮箱:zhangxutong@imcoming.com
- 时间: 2016/10/18.
*/
public class VoltageAdapter2 implements Voltage5 {
private Voltage220 mVoltage220;
public VoltageAdapter2(Voltage220 voltage220) {
mVoltage220 = voltage220;
}
@Override
public int output5V() {
int dst = 0;
if (null != mVoltage220) {
int src = mVoltage220.output220V();
System.out.println("对象适配器工作,开始适配电压");
dst = src / 44;
System.out.println("适配完成后输出电压:" + dst);
}
return dst;
}
}
测试代码:
System.out.println(“\n=对象适配器”);
VoltageAdapter2 voltageAdapter2 = new VoltageAdapter2(new Voltage220());
Mobile mobile2 = new Mobile();
mobile2.charging(voltageAdapter2);
输出:
=对象适配器
我是220V
对象适配器工作,开始适配电压
适配完成后输出电压:5
电压刚刚好5V,开始充电
类图:
小结:
对象适配器和类适配器其实算是同一种思想,只不过实现方式不同。
根据合成复用原则,组合大于继承,
所以它解决了类适配器必须继承src的局限性问题,也不再强求dst必须是接口。
同样的它使用成本更低,更灵活。
(和装饰者模式初学时可能会弄混,这里要搞清,装饰者是对src的装饰,使用者毫无察觉到src已经被装饰了(使用者用法不变)。 这里对象适配以后,使用者的用法还是变的。
即,装饰者用法: setSrc->setSrc,对象适配器用法:setSrc->setAdapter.)
四 接口适配器模式
也有文献称之为认适配器模式(Default Adapter Pattern)或缺省适配器模式。
定义:
当不需要全部实现接口提供的方法时,可先设计一个抽象类实现接口,并为该接口中每个方法提供一个默认实现(空方法),那么该抽象类的子类可有选择地覆盖父类的某些方法来实现需求,它适用于一个接口不想使用其所有的方法的情况。
我们直接进入大家最喜爱的源码撑腰环节:
源码撑腰环节:
Android中的属性动画ValueAnimator类可以通过addListener(AnimatorListener listener)方法添加监听器,
那么常规写法如下:
ValueAnimator valueAnimator = ValueAnimator.ofInt(0,100);
valueAnimator.addListener(new Animator.AnimatorListener() {
@Override
public void onAnimationStart(Animator animation) {
}
@Override
public void onAnimationEnd(Animator animation) {
}
@Override
public void onAnimationCancel(Animator animation) {
}
@Override
public void onAnimationRepeat(Animator animation) {
}
});
valueAnimator.start();
有时候我们不想实现Animator.AnimatorListener接口的全部方法,我们只想监听onAnimationStart,我们会如下写:
ValueAnimator valueAnimator = ValueAnimator.ofInt(0,100);
valueAnimator.addListener(new AnimatorListenerAdapter() {
@Override
public void onAnimationStart(Animator animation) {
//xxxx具体实现
}
});
valueAnimator.start();
显然,这个AnimatorListenerAdapter类,就是一个接口适配器。
查看该Adapter类源码:
public abstract class AnimatorListenerAdapter implements Animator.AnimatorListener,
Animator.AnimatorPauseListener {
@Override
public void onAnimationCancel(Animator animation) {
}
@Override
public void onAnimationEnd(Animator animation) {
}
@Override
public void onAnimationRepeat(Animator animation) {
}
@Override
public void onAnimationStart(Animator animation) {
}
@Override
public void onAnimationPause(Animator animation) {
}
@Override
public void onAnimationResume(Animator animation) {
}
}
可见,它空实现了Animator.AnimatorListener类(src)的所有方法.
对应的src类:
public static interface AnimatorListener {
void onAnimationStart(Animator animation);
void onAnimationEnd(Animator animation);
void onAnimationCancel(Animator animation);
void onAnimationRepeat(Animator animation);
}
类图:
我们程序里的匿名内部类就是Listener1 2 这种具体实现类。
new AnimatorListenerAdapter() {
@Override
public void onAnimationStart(Animator animation) {
//xxxx具体实现
}
}
接口适配器模式很好理解,令我们的程序更加简洁明了。
五 总结
我个人理解,三种命名方式,是根据 src是以怎样的形式给到Adapter(在Adapter里的形式)来命名的。
类适配器,以类给到,在Adapter里,就是将src当做类,继承,
对象适配器,以对象给到,在Adapter里,将src作为一个对象,持有。
接口适配器,以接口给到,在Adapter里,将src作为一个接口,实现。
Adapter模式最大的作用还是将原本不兼容的接口融合在一起工作。
但是在实际开发中,实现起来不拘泥于本文介绍的三种经典形式,
例如Android中ListView、GridView的适配器Adapter,就不是以上三种经典形式之一,
我个人理解其属于对象适配器模式,一般日常使用中,我们都是在Adapter里持有datas,然后通过getView()/onCreateViewHolder()方法向ListView/RecyclerView提供View/ViewHolder。
Client是Lv Gv Rv ,它们是显示View的类。
所以dst(Target)是View。
一般来说我们有的src是数据datas,
即,我们希望:datas(src)->Adapter->View(dst)->Rv(Client)。
1.5.8适配器模式和代理模式的区别
1.简介
适配器模式:适配器模式(英语:adapter pattern)有时候也称包装样式或者包装。将一个类的接口转接成用户所期待的。一个适配使得因接口不兼容而不能在一起工作的类工作在一起,做法是将类别自己的接口包裹在一个已存在的类中。wiki
代理模式:代理模式的定义:为其他对象提供一种代理以控制对这个对象的访问。在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。wiki
2.困惑
设计模式总是通过增加层来进行解耦合,提高扩展性,但是如果我们没法从在这个抽象维度中看出,这个层真正的抽象含义,那么我们很难搞懂一个模式真正的内涵?我就有这个疑问,这两个东东都是增加了一层,但是这一层有什么区别?
3.理解
很明显,适配器模式是因为新旧接口不一致导致出现了客户端无法得到满足的问题,但是,由于旧的接口是不能被完全重构掉的,因为我们还想使用实现了这个接口的一些服务。那么为了使用以前实现旧接口的服务,我们就应该把新的接口转换成旧接口;实现这个转换的类就是抽象意义的转换器;
就比如在java中早期的枚举接口是Enumeration而后定义的枚举接口是Iterator;有很多旧的类实现了enumeration接口 暴露出了一些服务,但是这些服务我们现在想通过传入Iterator接口而不是Enumeration接口来调用,这时就需要一个适配器,那么client就能用这个服务了(服务端只想用Iterator或者只知道这个接口);
相比于适配器的应用场景,代理就不一样了,虽然代理也同样是增加了一层,但是,代理提供的接口和原本的接口是一样的,代理模式的作用是不把实现直接暴露给client,而是通过代理这个层,代理能够做一些处理;
1.5.9适配器模式和装饰器模式有什么区别
适配器模式将一个类的接口,转化成客户期望的另一个接口,适配器让原本接口不兼容的类可以合作无间。
装饰者模式:动态的将责任附加到对象上(因为利用组合而不是继承来实现,而组合是可以在运行时进行随机组合的)。若要扩展功能,装饰者提供了比继承更富有弹性的替代方案(同样地,通过组合可以很好的避免类暴涨,也规避了继承中的子类必须无条件继承父类所有属性的弊端)。
特点:
- 装饰者和被装饰者拥有相同的超类型(可能是抽象类也可能是接口)
- 可以用多个装饰类来包装一个对象,装饰类可以包装装饰类或被装饰对象
- 因为装饰者和被装饰者拥有相同的抽象类型,因此在任何需要原始对象(被包装)的场合,都可以用装饰过的对象来替代它。
- 装饰者可以在被装饰者的行为之前或之后,加上自己的附加行为,以达到特殊目的
- 因为对象可以在任何的时候被装饰,所以可以在运行时动态地、不限量地用你喜欢的装饰者来装饰对象
适配器模式主要是为了接口的转换,而装饰者模式关注的是通过组合来动态的为被装饰者注入新的功能或行为(即所谓的责任)。
适配器将一个对象包装起来以改变其接口;装饰者将一个对象包装起来以增强新的行为和责任;而外观将一群对象包装起来以简化其接口
1.5.10什么时候使用享元模式
享元模式通过共享对象来避免创建太多的对象。为了使用享元模式,你需要确保你的对象是不可变的,
这样你才能安全的共享。JDK 中 String 池、Integer 池以及 Long 池都是很好的使用了享元模式的例子。
1.5.11组合模式
组合模式(Composite Pattern),又叫部分整体模式,是用于把一组相似的对象当作一个单一的对象。组合模式依据树形结构来组合对象,用来表示部分以及整体层次。这种类型的设计模式属于结构型模式,它创建了对象组的树形结构。
这种模式创建了一个包含自己对象组的类。该类提供了修改相同对象组的方式。
我们通过下面的实例来演示组合模式的用法。实例演示了一个组织中员工的层次结构。
介绍
意图:将对象组合成树形结构以表示”部分-整体”的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
主要解决:它在我们树型结构的问题中,模糊了简单元素和复杂元素的概念,客户程序可以向处理简单元素一样来处理复杂元素,从而使得客户程序与复杂元素的内部结构解耦。
何时使用: 1、您想表示对象的部分-整体层次结构(树形结构)。 2、您希望用户忽略组合对象与单个对象的不同,用户将统一地使用组合结构中的所有对象。
如何解决:树枝和叶子实现统一接口,树枝内部组合该接口。
关键代码:树枝内部组合该接口,并且含有内部属性 List,里面放 Component。
应用实例: 1、算术表达式包括操作数、操作符和另一个操作数,其中,另一个操作符也可以是操作数、操作符和另一个操作数。 2、在 JAVA AWT 和 SWING 中,对于 Button 和 Checkbox 是树叶,Container 是树枝。
优点: 1、高层模块调用简单。 2、节点自由增加。
缺点:在使用组合模式时,其叶子和树枝的声明都是实现类,而不是接口,违反了依赖倒置原则。
使用场景:部分、整体场景,如树形菜单,文件、文件夹的管理。
1.5.12什么时候使用访问者模式
意图
表示一个作用于某对象结构中的各元素的操作。它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
适用性
- 一个对象结构包含很多类对象,它们有不同的接口,而你想对这些对象实施一些依赖于其具体类的操作。
- 需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而你想避免让这些操作“污染”这些对象的类。Visitor使得你可以将相关的操作集中起来定义在一个类中。当该对象结构被很多应用共享时,用Visitor模式让每个应用仅包含需要用到的操作。
- 定义对象结构的类很少改变,但经常需要在此结构上定义新的操作。改变对象结构类需要重定义对所有访问者的接口,这可能需要很大的代价。如果对象结构类经常改变,那么可能还是在这些类中定义这些操作较好。
总结一下,在这种地方你一定要考虑使用访问者模式:业务规则要求遍历多个不同的对象。这本身也是访问者模式出发点,迭代器模式只能访问同类或同接口的数据(当然了,如果你使用instanceof,那么能访问所有的数据,这没有争论),而访问者模式是对迭代器模式的扩充,
可以遍历不同的对象,然后执行不同的操作,也就是针对访问的对象不同,执行不同的操作。
优缺点
优点:
-
访问者模式使得易于增加新的操作 访问者使得增加依赖于复杂对象结构的构件的操作变得容易了。仅需增加一个新的访问者即可在一个对象结构上定义一个新的操作。相反, 如果每个功能都分散在多个类之上的话,定义新的操作时必须修改每一类。
-
访问者集中相关的操作而分离无关的操作 相关的行为不是分布在定义该对象结构的 各个类上,而是集中在一个访问者中。无关行为却被分别放在它们各自的访问者子类中。这 就既简化了这些元素的类,也简化了在这些访问者中定义的算法。所有与它的算法相关的数 据结构都可以被隐藏在访问者中。
缺点:
- 增加新的 ConcreteElement类很困难
Visitor模式使得难以增加新的 Element的子类。每 添加一个新的 ConcreteElement都要在 Vistor中添加一个新的抽象操作,并在每一个 ConcretVisitor类中实现相应的操作。有时可以在 Visitor中提供一个缺省的实现,这一实现可 以被大多数的 ConcreteVisitor继承,但这与其说是一个规律还不如说是一种例外。
所以在应用访问者模式时考虑关键的问题是系统的哪个部分会经常变化,是作用于对象结构上的算法呢还是构成该结构的各个对象的类。如果老是有新的 ConcretElement类加入进来的话, Vistor类层次将变得难以维护。在这种情况下,直接在构成该结构的类中定义这些操作可能更容易一些。如果 Element类层次是稳定的,而你不断地增加操作获修改算法,访问者模式可以帮助你管理这些改动。
- 破坏封装
访问者方法假定ConcreteElement接口的功能足够强,足以让访问者进行它 们的工作。结果是,该模式常常迫使你提供访问元素内部状态的公共操作,这可能会破坏它 的封装性。
1.5.13什么是模板方法模式?
算法执行的统一框架(step1、step2……、stepn)。
父类定义了实现步骤的框架,然后子类可以在不改变父类框架的基础上增加或者修改父类的一些方法。
2、如何实现模板方法模式
以银行柜台办理业务为例实现模板方法模式。
流程可分为,取号->排队->办理业务->销号。
BankBusiness.java
/**
-
银行业务抽象类(抽象基类,为所有子类提供一个算法框架)
*/public abstract class BankBusiness {
// final的模板方法,防止子类修改
final public void bankBusinessTemplate() {
// 调用各个流程方法
takeNo();
if (isSpecialUser()) {
queueUp();
}
handleBusiness();
destroyNo();
}// 取号
private void takeNo() {
System.out.println(“取号”);
}// 排队
private void queueUp() {
System.out.println(“排队”);
}// 办理业务(定义为protected,在子类中延迟实现,提供个性化操作)
protected abstract void handleBusiness();// 销号
private void destroyNo() {
System.out.println(“销号”);
}// 钩子方法,有效调控公用变化的流程
protected boolean isSpecialUser() {
return true;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
OpenNewCardBankBusiness.java
/** -
办理新卡业务
*/public class OpenNewCardBankBusiness extends BankBusiness {
@Override
protected void handleBusiness() {
System.out.println(“柜台业务,办新卡”);
}
}
1
2
3
4
5
6
7
8
9
10
11
destroyCardBankBusiness.java
/**
-
销卡业务
*/public class destroyCardBankBusiness extends BankBusiness {
@Override
protected void handleBusiness() {
System.out.println(“柜台业务,销卡”);
}
}
1
2
3
4
5
6
7
8
9
10
11
BankBusinessTest.java
/**
- 测试类
*/public class BankBusinessTest {
public static void main(String[] args) {
BankBusiness busi;
busi = new OpenNewCardBankBusiness();
busi.bankBusinessTemplate();
System.out.println();
busi = new destroyCardBankBusiness();
busi.bankBusinessTemplate();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
运行结果
取号
排队
柜台业务,办新卡
销号
取号
排队
柜台业务,销卡
销号
1
2
3
4
5
6
7
8
9
准备一个抽象类,将部分逻辑以具体方法的形式实现,然后声明一些抽象方法交由子类实现剩余逻辑,用钩子方法给予子类更大的灵活性。最后将方法汇总构成一个不可改变的模板方法。
3、模板方法模式的特点
优点
封装性好
复用性好
屏蔽细节
缺点:
每个不同的实现需要增加新类,类个数增多。
4、模板方法模式的适用场景
1.算法或操作逻辑相似的逻辑
2.重构时(把相同的代码抽取到父类中)
3.重要、复杂的算法,核心算法设计为模板算法
1.5.14 单例模式的双检锁是什么
关于单例模式,就不再详细叙述,想必大家都耳熟能详了,简单回顾下吧。以下是单例模式的一个例子:
public class DoubleCheckedLock {
private static DoubleCheckedLock instance;
public static DoubleCheckedLock getInstance() {
if (instance == null) {
instance=new DoubleCheckedLock();
}
return instance;
}
}
上述的例子,如果是在并发的情况下,就会遇到严重的问题。比如线程A在判断instance为空时,进入new操作,new操作还未完成时,此时线程B也运行到判断instance是否为NULL,那么可能就会造成线程A和线程B都在new,那就违背了单例模式的原本含义了。那么既然需要保证只有一个实例,我们是否可以通过synchronized关键字来解决呢?
public class DoubleCheckedLock
private static DoubleCheckedLock instance;
public static synchronized DoubleCheckedLock getInstance() {
if (instance == null) {
instance=new DoubleCheckedLock();
}
return instance;
}
}
不可否认,synchronized关键字是可以保证单例,但是程序的性能却不容乐观,原因在于getInstance()整个方法体都是同步的,这就限定了访问速度。其实我们需要的仅仅是在首次初始化对象的时候需要同步,对于之后的获取不需要同步锁。因此,可以做进一步的改进:
public class DoubleCheckedLock {
private static DoubleCheckedLock instance;
public static DoubleCheckedLock getInstance() {
if (instance == null) { //step1
synchronized (DoubleCheckedLock.class) { //step2
if(instance==null){ //step3
instance=new DoubleCheckedLock(); //step4
}
}
}
return instance;
}
}
这样我们将上锁的粒度降低到了仅仅是初始化实例的那部分,从而使代码即正确又保证了执行效率。这就是所谓的“双检锁”机制(顾名思义)。
双检锁机制的出现确实是解决了多线程并行中不会出现重复new对象,而且也实现了懒加载,但是很可惜,这样的写法在很多平台和优化编译器上是错误的,原因在于:instance=new DoubleCheckedLock()这行代码在不同编译器上的行为是无法预知的。一个优化编译器可以合法地如下实现 instance=new DoubleCheckedLock():
- 给新的实体instance分配内存;
- 调用DoubleCheckedLock的构造函数来初始化instance。
现在想象一下有线程A和B在调用DoubleCheckedLock,线程A先进入,在执行到步骤4的时候被踢出了cpu。然后线程B进入,B看到的是instance已经不是null了(内存已经分配),于是它开始放心地使用instance,但这个是错误的,因为A还没有来得及完成instance的初始化,而线程B就返回了未被初始化的instance实例。
当我们结合java虚拟机的类加载过程就会更好理解。对于JVM加载类过程,我还不是很熟悉,所以简要地介绍下:
jvm加载一个类大体分为三个步骤:
1)加载阶段:就是在硬盘上寻找java文件对应的class文件,并将class文件中的二进制数据加载到内存中,将其放在运行期数据区的方法区中去,然后在堆区创建一个java.lang.Class对象,用来封装在方法区内的数据结构;
2)连接阶段:这个阶段分为三个步骤,步骤一:验证,当然是验证这个class文件里面的二进制数据是否符合java规范;步骤二:准备,为该类的静态变量分配内存空间,并将变量赋一个默认值,比如int的默认值为0;步骤三:解析,这个阶段就不好解释了,将符号引用转化为直接引用,涉及到指针;
3)初始化阶段:当我们主动调用该类的时候,将该类的变量赋于正确的值(这里不要和第二阶段的准备混淆了),举个例子说明下两个区别,比如一个类里有private static int i = 5; 这个静态变量在”准备”阶段会被分配一个内存空间并且被赋予一个默认值0,当道到初始化阶段的时候会将这个变量赋予正确的值即5,了解了吧!
因此,双检锁对于基础类型(比如int)适用。因为基础类型没有调用构造函数这一步。那么对于双检锁中因编译器的优化无法保证执行顺序的问题,具体地说是在C++下是精简指令集(RISC)机器的编译器会重新排列编译器生成的汇编语言指令,从而使代码能够最佳运用RISC处理器的平行特性,因此有可能破坏双检锁模式。对于此问题,查阅了不少解决方案,主要有以下几种:
1)使用memory barrier,,关于merrory barrier的介绍,可参阅博文《Memory barrier》。
2)java中可考虑volatile关键字定义新的语意来解决这个问题,关于volatile关键字的使用,可见博文《volatile关键字》。
1.5.15 哪些设计模式可以增加系统的可扩展性:
工厂模式
抽象工厂模式
观察者模式:很方便增加观察者,方便系统扩展
模板方法模式:很方便的实现不稳定的扩展点,完成功能的重用
适配器模式:可以很方便地对适配其他接口
代理模式:可以很方便在原来功能的基础上增加功能或者逻辑
责任链模式:可以很方便得增加拦截器/过滤器实现对数据的处理,比如struts2的责任链
策略模式:通过新增策略从而改变原来的执行策略
1.5.16 享元模式 ***
1.6 排序
1.6.1 冒泡排序
public void bubbleSort(int[] arr) { //从小到大
int temp = 0;
for(int i = 0; i < arr.length -1; i++){ //控制趟数,到倒数第二个为止
for(int j = arr.length-1; j>i; j–){ //从最后一个值开始冒泡,将后面的小值与前面的大值进行交换,并且保证循环到前面已经排序完的索引为止
if(arr[j-1] > arr[j]){
temp = arr[j];
arr[j] = arr[j-1];
arr[j-1] = temp;
}
}
}
}
1.6.2 选择排序
public void selectionSort(int[] arr){
int temp = 0;
int k = 0; //存储最小值的索引
for(int i = 0; i<arr.lengrh - 1; i++){ //控制趟数,到倒数第二个为止
k = i;
for(int j = i; j<arr.length;j++){ //将第一个数默认为最小值,将其索引赋值给k,从k索引开始,将后面每个数与k索引对应的值比较,如果值小了,就将其索引赋值给k
if(arr[j] < arr[k]){
k = j;
}
}
//遍历完后,k就指向了最小的值,将其与i对应的值交换(也可 以先做个判断,判断k的索引是否有变化,无变化可以不交换)
temp = arr[k];
arr[k] = arr[i];
arr[i] = temp;
}
}
1.7 面向对象
1.7.1面向对象的理解
(1)概述:面向对象是相对于面向过程而言的,面向过程强调的是功能,面向对象强调的是将功能封装进对象,
强调具备功能的对象;
(2)思想特点:
A:是符合人们思考习惯的一种思想;
B:将复杂的事情简单化了;
C:将程序员从执行者变成了指挥者;
比如我要达到某种结果,我就寻找能帮我达到该结果的功能的对象,如我要洗衣服我就买洗衣机,
至于怎么洗我不管。
(3)特征:
封装:隐藏对象的属性和实现细节,仅对外提供公共访问方式
继承: 多个类中存在相同属性和行为时,将这些内容抽取到单独一个类中,那么多个类无需再定义
这些属性和行为,只要继承那个类即可。
多态: 一个对象在程序不同运行时刻代表的多种状态,父类或者接口的引用指向子类对象java的特性
封装:隐藏对象属性和实现细节;
继承:代码重用;
多态:运行时对象有多种状态;跨平台
1.7.2 面向对象的特点
各司其职: 对象应该保持其简单性
弱耦合性: 对象和对象间的联系应该尽量弱化
可重用性:
可扩展性:
1.7.3 反射,泛型项目中有没有使用
反射:虽然各类框架,底层技术都大量使用了反射,但是直接使用的并不多,除非自己封装一些方法,自己做框架的时候
泛型:也是底层肯定大量使用,写的工具类,对外的参数List Map等可以考虑使用泛型,避免一些类型不一致的编译错误
1.7.4 面向对象的设计原则
1、 开闭原则Open Close Principle
定义:一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
2、里氏代换原则(Liskov Substitution Principle)
定义1:如果对每一个类型为 T1的对象 o1,都有类型为 T2 的对象o2,使得以 T1定义的所有程序 P 在所有的对象 o1 都代换成 o2 时,程序 P 的行为没有发生变化,那么类型 T2 是类型 T1 的子类型。
定义2:子类型必须能够替换掉它们的父类型。
里氏替换原则通俗的来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能。它包含以下4层含义:
1.子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法。
2.子类中可以增加自己特有的方法。
3.当子类的方法重载父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松。
4.当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
3、依赖倒转原则(Dependence Inversion Principle)
定义:高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。即针对接 口编程,不要针对实现编程
依赖倒置原则的中心思想是面向接口编程,传递依赖关系有三种方式,接口传递,构造方法传递和setter方法传递
在实际编程中,我们一般需要做到如下3点:
低层模块尽量都要有抽象类或接口,或者两者都有。
变量的声明类型尽量是抽象类或接口。
使用继承时遵循里氏替换原则。
总之,依赖倒置原则就是要我们面向接口编程,理解了面向接口编程,也就理解了依赖倒置
4、接口隔离原则(Interface Segregation Principle)
接口隔离原则的含义是:建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少。也就是说,我们要为各个类建立专用的接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。
其一,单一职责原则原注重的是职责;而接口隔离原则注重对接口依赖的隔离。其二,单一职责原则主要是约束类,其次才是接口和方法,它针对的是程序中的实现和细节;而接口隔离原则主要约束接口接口,主要针对抽象,针对程序整体框架的构建。
采用接口隔离原则对接口进行约束时,要注意以下几点:
- 接口尽量小,但是要有限度。对接口进行细化可以提高程序设计灵活性是不挣的事实,但是如果过小,则会造成接口数量过多,使设计复杂化。所以一定要适度。
- 为依赖接口的类定制服务,只暴露给调用的类它需要的方法,它不需要的方法则隐藏起来。只有专注地为一个模块提供定制服务,才能建立最小的依赖关系。
- 提高内聚,减少对外交互。使接口用最少的方法去完成最多的事情。
运用接口隔离原则,一定要适度,接口设计的过大或过小都不好
5 、组合/聚合复用原则
就是说要尽量的使用合成和聚合,而不是继承关系达到复用的目的
该原则就是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分:新的对象通过向这些对象的委派达到复用已有功能的目的。
其实这里最终要的地方就是区分“has-a”和“is-a”的区别。相对于合成和聚合,
继承的缺点在于:父类的方法全部暴露给子类。父类如果发生变化,子类也得发生变化。聚合的复用的时候就对另外的类依赖的比较的少。。
合成/聚合复用
① 优点:
新对象存取成分对象的唯一方法是通过成分对象的接口;
这种复用是黑箱复用,因为成分对象的内部细节是新对象所看不见的;
这种复用支持包装;
这种复用所需的依赖较少;
每一个新的类可以将焦点集中在一个任务上;
这种复用可以在运行时动态进行,新对象可以使用合成/聚合关系将新的责任委派到合适的对象。
② 缺点:
通过这种方式复用建造的系统会有较多的对象需要管理。
继承复用
① 优点:
新的实现较为容易,因为基类的大部分功能可以通过继承关系自动进入派生类;
修改或扩展继承而来的实现较为容易。
② 缺点:
继承复用破坏包装,因为继承将基类的实现细节暴露给派生类,这种复用也称为白箱复用;
如果基类的实现发生改变,那么派生类的实现也不得不发生改变;
从基类继承而来的实现是静态的,不可能在运行时发生改变,不够灵活。
6 、迪米特法则
迪米特法则其根本思想,是强调了类之间的松耦合,类之间的耦合越弱,越有利于复用,一个处在弱耦合的类被修改,不会对有关系的类造成影响,也就是说,信息的隐藏促进了软件的复用。
迪米特法则又叫最少知道原则,最早是在1987年由美国Northeastern University的Ian Holland提出。通俗的来讲,就是一个类对自己依赖的类知道的越少越好。也就是说,对于被依赖的类来说,无论逻辑多么复杂,都尽量地的将逻辑封装在类的内部,对外除了提供的public方法,不对外泄漏任何信息。迪米特法则还有一个更简单的定义:只与直接的朋友通信。首先来解释一下什么是直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系,我们就说这两个对象之间是朋友关系。耦合的方式很多,依赖、关联、组合、聚合等。其中,我们称出现成员变量、方法参数、方法返回值中的类为直接的朋友,而出现在局部变量中的类则不是直接的朋友。也就是说,陌生的类最好不要作为局部变量的形式出现在类的内部。
一句话总结就是:一个对象应该对其他对象保持最少的了解。
7、单一职能原则
定义:不要存在多于一个导致类变更的原因。通俗的说,即一个类只负责一项职责,应该仅有一个引起它变化的原因
遵循单一职责原的优点有:
1.可以降低类的复杂度,一个类只负责一项职责,其逻辑肯定要比负责多项职责简单的多;
2.提高类的可读性,提高系统的可维护性;
3.变更引起的风险降低,变更是必然的,如果单一职责原则遵守的好,当修改一个功能时,可以显著降低对其他功能的影响。
需要说明的一点是单一职责原则不只是面向对象编程思想所特有的,只要是模块化的程序设计,都需要遵循这一重要原则
1.7.5 接口和抽象类的区别
抽象类可以有构造方法,接口中不能有构造方法
抽象类中可以有普通成员变量,接口中没有普通成员变量
抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的
抽象类中的抽象方法的访问类型可以是public,protected,但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型
抽象类中可以包含静态方法,接口中不能包含静态方法
抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static final类型,并且默认即为public static final类型
一个类可以实现多个接口,但只能继承一个抽象类。
下面接着再说说两者在应用上的区别:
接口关注的是功能,抽象类关注的抽象现实中事物
1.7.6 super什么时候使用
子类的构造函数中不是必须使用super,在构造函数中,如果第一行没有写super(),编译器会自动插入.但是如果父类没有不带参数的构造函数,或这个函数被私有化了(用private修饰).此时你必须加入对父类的实例化构造.而this就没有这个要求,因为它本身就进行实例化的构造.
如果父类的构造函数是无参的,那子类构造函数会在第一行默认调用super().
下面这种情况是必须调用super()的:
1 public class Father {
2 public String name;
3 public Father(String name) {
4 this.name = name;
5 }
6 }
7
8 class Son extends Father{
9 public Son(String name) {
10 super(name);
11 }
12 //必须调用,否则他会默认调用父类的无参构造函数,而父类的无参构造函数已经被有参的覆盖,所以找不到
1.7.7 说出几条 Java 中方法重载的最佳实践
下面有几条可以遵循的方法重载的最佳实践来避免造成自动装箱的混乱。
a)不要重载这样的方法:一个方法接收 int 参数,而另个方法接收 Integer 参数。
b)不要重载参数数量一致,而只是参数顺序不同的方法。
c)如果重载的方法参数个数多于 5 个,采用可变参数。
1.7.8 对象封装的原则是什么?
封装的作用大概有两个:
1 对象的数据封装特性彻底消除了传统结构方法中数据与操作分离所带来的种种问题,提高了程序的可复用性和可维护性,降低了程序员保持数据与操作内容的负担。
2 对象的数据封装特性还可以把对象的私有数据和公共数据分离开,保护了私有数据,减少了可能的模块间干扰,达到降低程序复杂性、提高可控性的目的。
通俗点说就是把一个对象下的属性概括起来,外部通过此对象来访问该对象下的属性,而开发人员可以通过控制属性的权限控制外部的访问权限,即可以控制哪些可以给外部访问哪些不行,可以起到很好的隐藏作用。
至于封装的原则主要是靠经验吧,只要尽力让封装的每个类里面的属性和方法独立,方便以后操作,减少耦合性就好了
1.7.9 多态的实现原理 **
靠的是父类或接口定义的引用变量可以指向子类或具体实现类的实例对象,而程序调用的方法在运行期才动态绑定,就是引用变量所指向的具体实例对象的方法,也就是内存里正在运行的那个对象的方法,而不是引用变量的类型中定义的方法。
1.7.10 类”的特性解释
1,封装性:把数据和行为结合起在一个包中,并对对象使用者隐藏数据的实现过程,一个对象中的数据叫他的实例字段(instance
field);
2,抽象性:
(1)往往用来表征对问题领域进行分析、设计中得出的抽象概念,是对一系列看上去不同,但是本质上相同的具体概念的抽象;
(2)抽象类是不完整的,它只能用作基类,在面向对象方法中,抽象类主要用来进行类型隐藏和充当全局变量的角色。
3,继承性:
(1)继承可以使得子类具有父类的各种属性和方法,而不需要再次编写相同的代码;
(2)在令子类继承父类的同时,可以重新定义某些属性,并重写某些方法,即覆盖父类的原有属性和方法,使其获得与父类不同的功能。
3,多态性:是指以适当频率在一个群体的某个特定遗传位点(基因序列或非基因序列)发生两种或两种以上变异的现象。
1.7.11 继承和组合之间有什么不同
组合和继承是面向对象中两种代码复用的方式。组合是指在新类里面创建原有类的对象,重复利用已有类的功能。继承是面向对象的主要特性之一,它允许设计人员根据其它类的实现来定义一个类的实现。
组合和继承都允许在新的类中设置子对象(subobject),只是组合是显式的,而继承则是隐式的。组合和继承存在着对应关系:组合中的整体类和继承中的子类对应,组合中的局部类和继承中的父类对应。
一:继承
继承是Is a 的关系,比如说Student继承Person,则说明Student is a Person。继承的优点是子类可以重写父类的方法来方便地实现对父类的扩展。
继承的缺点有以下几点:
1:父类的内部细节对子类是可见的。
2:子类从父类继承的方法在编译时就确定下来了,所以无法在运行期间改变从父类继承的方法的行为。
3:子类与父类是一种高耦合,违背了面向对象思想。
4 :继承关系最大的弱点是打破了封装,子类能够访问父类的实现细节,子类与父类之间紧密耦合,子类缺乏独立性,从而影响了子类的可维护性。
5:不支持动态继承。在运行时,子类无法选择不同的父类。
二:组合
1:不破坏封装,整体类与局部类之间松耦合,彼此相对独立。
2:具有较好的可扩展性。
3:支持动态组合。在运行时,整体对象可以选择不同类型的局部对象。
1.除非考虑使用多态,否则优先使用组合。
2.要实现类似”多重继承“的设计的时候,使用组合。
3.要考虑多态又要考虑实现“多重继承”的时候,使用组合+接口。
1.7.12 为什么类只能单继承,接口可以多继承
首先,类的多继承有哪些缺点那:
第一,如果一个类继承多个父类,如果父类中的方法名如果相同,那么就会产生歧义。
第二,如果父类中的方法同名,子类中没有覆盖,同样会产生上面的错误。
所以,java中就没有设计类的多继承。
但是接口就设计成多继承,是因为接口可以避免上述问题:
首先,接口中的只有抽象方法和静态常量。
对于一个类实现多个接口的情况和一个接口继承多个接口的情况,因为接口只有抽象方法,具体方法只能由实现接口的类实现(也是因为实现类一定会覆盖接口中的方法),在调用的时候始终只会调用实现类(也就是子类覆盖的方法)的方法(不存在歧义),因此不存在 多继承的第二个缺点;而又因为接口只有静态的常量,但是由于静态变量是在编译期决定调用关系的,即使存在一定的冲突也会在编译时提示出错;而引用静态变量一般直接使用类名或接口名,从而避免产生歧义,因此也不存在多继承的第一个缺点。
1.7.13 创建对象时构造器的调用顺序
复杂对象调用构造器的顺序应该遵循下面的原则:
1、调用基类[即父类]构造器。这个步骤会不断反复递归下去,首先是构造器这种层次结构的根,然后是下一层导出类[即子类],等等。直到最底层的导出类。[从最上层的meal一直递归到PortableLunch]
2、按声明顺序调用成员的初始化方法。[即上面的Bread,Cheese,Lettuce]
3、调用导出类构造器的主体[即Sandwich]
1.7.14 java中,什么是封装,继承,多态和抽象,好处与用法
1.封装
封装的概念:把对象的属性和方法结合成一个独立的整体,隐藏实现细节,并提供对外访问的接口。
封装的好处:
(1):隐藏实现细节。好比你买了台电视机,你只需要怎么使用,并不用了解其实现原理。
(2):安全性。比如你在程序中私有化了age属性,并提供了对外的get和set方法,当外界 使用set方
法为属性设值的时候 你可以在set方法里面做个if判断,把值设值在0-80岁,那样他就不能随意
赋值了。
(3):增加代码的复用性。
好比在工具类中封装的各种方法,你可以在任意地方重复调用,而不用再每处都去实现其细节。
(4):模块化。封装分为属性封装,方法封装,类封装,插件封装,模块封装,系统封装等等。
有利于程序的协助分工,互不干扰,方便了模块之间的相互组合与分解,也有利于代码的调试
和维护。比如人体由各个器官所组成,如果有个器官出现问题,你只要去对这个器官进行医治
就行了。
2.继承
继承的概念:从已知的一个类中派生出新的一个类,叫子类。子类实现了父类所有非私有化属性和方法,
并能根据自己的实际需求扩展出新的行为。
继承的好处:
(1):继承是传递的,容易在其基础上构造,建立和扩充出新的类。
(2):简化了人们对事物的认识和描述,能清晰体现相关类之间的层次结构关系。
(3):能减少数据和代码的冗余度。
(4):大大增加了代码的维护性。
3.多态
多态的概念:多个不同的对象对同一消息作出响应,同一消息根据不同的对象而采用各种不同的行为方法。
多态的好处:主要是利于扩展。直接上代码自己来体会。
4.抽象
抽象的概念:通过特定的实例抽取出共同的特征以后形成的概念的过程,它强调主要特征和忽略次要特征
1.7.15 抽象类是否可实现(implements)接口
接口可以继承接口。
抽象类可以实现(implements)接口。
抽象类是否可继承实体类,但前提是实体类必须有明确的构造函数。
1.7.16 对象创建过程
JVM会先去方法区下找有没有所创建对象的类存在,有就可以创建对象了,没有则把该类加载到方法区
在创建类的对象时,首先会先去堆内存中分配空间
当空间分配完后,加载对象中所有的非静态成员变量到该空间下
所有的非静态成员变量加载完成之后,对所有的非静态成员进行默认初始化
所有的非静态成员默认初始化完成之后,调用相应的构造方法到栈中
在栈中执行构造函数时,先执行隐式,再执行构造方法中书写的代码
执行顺序:静态代码库,构造代码块,构造方法
当整个构造方法全部执行完,此对象创建完成,并把堆内存中分配的空间地址赋给对象名(此时对象名就指向了该空间)
1.7.17 当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
https://www.cnblogs.com/lixiaolun/p/4311863.html
java中方法的参数传递机制
问:当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
答:是值传递。Java 编程语言只有值传递参数。当一个对象实例作为一个参数被传递到方法中时,参数的值就是该对象的引用一个副本。指向同一个对象,对象的内容可以在被调用的方法中改变,但对象的引用(不是引用的副本)是永远不会改变的。
Java参数,不管是原始类型还是引用类型,传递的都是副本(有另外一种说法是传值,但是说传副本更好理解吧,传值通常是相对传址而言)。
如果参数类型是原始类型,那么传过来的就是这个参数的一个副本,也就是这个原始参数的值,这个跟之前所谈的传值是一样的。如果在函数中改变了副本的值不会改变原始的值.
如果参数类型是引用类型,那么传过来的就是这个引用参数的副本,这个副本存放的是参数的地址。如果在函数中没有改变这个副本的地址,而是改变了地址中的 值,那么在函数内的改变会影响到传入的参数。如果在函数中改变了副本的地址,如new一个,那么副本就指向了一个新的地址,此时传入的参数还是指向原来的 地址,所以不会改变参数的值。
基本类型参数传递:不改变值
引用类型参数传递:改变值
无论是什么语言,要讨论参数传递方式,就得从内存模型说起,主要是我个人觉得从内存模型来说参数传递更为直观一些。闲言少叙,下面我们就通过内存模型的方式来讨论一下Java中的参数传递。
这里的内存模型涉及到两种类型的内存:栈内存(stack)和堆内存(heap)。基本类型作为参数传递时,传递的是这个值的拷贝。无论你怎么改变这个拷贝,原值是不会改变的。看下边的一段代码,然后结合内存模型来说明问题:
1
2
3
4
5
6
7
8
9
10
11
12 public class ParameterTransfer {
public static void main(String[] args) {
int num = 30;
System.out.println(“调用add方法前num=” + num);
add(num);
System.out.println(“调用add方法后num=” + num);
}
public static void add(int param) {
param = 100;
}
}
这段代码运行的结果如下:
1
2 调用add方法前num=30
调用add方法后num=30
程序运行的结果也说明这一点,无论你在add()方法中怎么改变参数param的值,原值num都不会改变。
下边通过内存模型来分析一下。
当执行了int num = 30;这句代码后,程序在栈内存中开辟了一块地址为AD8500的内存,里边放的值是30,内存模型如下图:
执行到add()方法时,程序在栈内存中又开辟了一块地址为AD8600的内存,将num的值30传递进来,此时这块内存里边放的值是30,执行param = 100;后,AD8600中的值变成了100。内存模型如下图:
地址AD8600中用于存放param的值,和存放num的内存没有任何关系,无论你怎么改变param的值,实际改变的是地址为AD8600的内存中的值,而AD8500中的值并未改变,所以num的值也就没有改变。
以上是基本类型参数的传递方式,下来我们讨论一下对象作为参数传递的方式。
先看下边的示例代码:
1
2
3
4
5
6
7
8
9
10
11
12 public class ParameterTransfer {
public static void main(String[] args) {
String[] array = new String[] {“huixin”};
System.out.println(“调用reset方法前array中的第0个元素的值是:” + array[0]);
reset(array);
System.out.println(“调用reset方法后array中的第0个元素的值是:” + array[0]);
}
public static void reset(String[] param) {
param[0] = "hello, world!";
}
}
运行的结果如下:
1
2 调用reset方法前array中的第0个元素的值是:huixin
调用reset方法后array中的第0个元素的值是:hello, world!
当对象作为参数传递时,传递的是对象的引用,也就是对象的地址。下边用内存模型图来说明。
当程序执行了String[] array = new String[] {“huixin”}后,程序在栈内存中开辟了一块地址编号为AD9500内存空间,用于存放array[0]的引用地址,里边放的值是堆内存中的一个地址,示例中的值为BE2500,可以理解为有一个指针指向了堆内存中的编号为BE2500的地址。堆内存中编号为BE2500的这个地址中存放的才是array[0]的值:huixin。
当程序进入reset方法后,将array的值,也就是对象的引用BE2500传了进来。这时,程序在栈内存中又开辟了一块编号为AD9600的内存空间,里边放的值是传递过来的值,即AD9600。可以理解为栈内存中的编号为AD9600的内存中有一个指针,也指向了堆内存中编号为BE2500的内存地址,如图所示:
这样一来,栈内存AD9500和AD9600(即array[0]和param的值)都指向了编号为BE2500的堆内存。
在reset方法中将param的值修改为hello, world!后,内存模型如下图所示:
改变对象param的值实际上是改变param这个栈内存所指向的堆内存中的值。param这个对象在栈内存中的地址是AD9600,里边存放的值是BE2500,所以堆内存BE2500中的值就变成了hello,world!。程序放回main方法之后,堆内存BE2500中的值仍然为hello,world!,main方法中array[0]的值时,从栈内存中找到array[0]的值是BE2500,然后去堆内存中找编号为BE2500的内存,里边的值是hello,world!。所以main方法中打印出来的值就变成了hello,world!
小结:
无论是基本类型作为参数传递,还是对象作为参数传递,实际上传递的都是值,只是值的的形式不用而已。第一个示例中用基本类型作为参数传递时,将栈内存中的值30传递到了add方法中。第二个示例中用对象作为参数传递时,将栈内存中的值BE2500传递到了reset方法中。当用对象作为参数传递时,真正的值是放在堆内存中的,传递的是栈内存中的值,而栈内存中存放的是堆内存的地址,所以传递的就是堆内存的地址。这就是它们的区别。
补充一下,在Java中,String是一个引用类型,但是在作为参数传递的时候表现出来的却是基本类型的特性,即在方法中改变了String类型的变量的值后,不会影响方法外的String变量的值。关于这个问题,可以参考如下两个地址:
http://freej.blog.51cto.com/235241/168676
http://dryr.blog.163.com/blog/static/58211013200802393317600/
我觉得是这两篇文章中提到的两个原因导致的,一个是String实际上操作的是char[],可以理解为String是char[]的包装类。二是给String变量重新赋值后,实际上没有改变这个变量的值,而是重新new了一个String对象,改变了新对象的值,所以原来的String变量的值并没有改变。
1.8 底层
1.8.1 操作系统中 heap (堆)和 stack (栈)的区别
概念:
堆栈是两种数据结构。堆栈都是一种数据项按序排列的数据结构,只能在一端(称为栈顶(top))对数据项进行插入和删除。在单片机应用中,堆栈是个特殊的存储区,主要功能是暂时存放数据和地址,通常用来保护断点和现场。要点:堆,队列优先,先进先出(FIFO—first in first out)。栈,先进后出(FILO—First-In/Last-Out)。
区别:1 ,空间分配区别
栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈;
stack空间有限
堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
heap常用new关键字来分配。 heap的空间是很大的自由区
2 ,缓存方式的区别
栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放;
堆是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。
所以调用这些对象的速度要相对来得低一些。
3,数据结构的区别
堆(数据结构):堆可以被看成是一棵树,如:堆排序;
栈(数据结构):一种先进后出的数据结构
Java中栈和堆的区别:
栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由new创建的对象和数组,在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。在堆中产生了一个数组或对象后,还可以在栈中定义一个特殊的变量,让栈中这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量。引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。
Java中变量在内存中的分配:
1、类变量(static修饰的变量):在程序加载时系统就为它在堆中开辟了内存,堆中的内存地址存放于栈以便于高速访问。静态变量的生命周期–一直持续到整个”系统”关闭。
2、实例变量:当你使用java关键字new的时候,系统在堆中开辟并不一定是连续的空间分配给变量(比如说类实例),然后根据零散的堆内存地址,通过哈希算法换算为一长串数字以表征这个变量在堆中的”物理位置”。 实例变量的生命周期–当实例变量的引用丢失后,将被GC(垃圾回收器)列入可回收“名单”中,但并不是马上就释放堆中内存。
3、局部变量:局部变量,由声明在某方法,或某代码段里(比如for循环),执行到它的时候在栈中开辟内存,当局部变量一但脱离作用域,内存立即释放。
1.8.2 数组和链表数据结构描述,各自的时间复杂度
1、存取方式上,数组可以顺序存取或者随机存取,而链表只能顺序存取;
2、存储位置上,数组逻辑上相邻的元素在物理存储位置上也相邻,而链表不一定;
3、存储空间上,链表由于带有指针域,存储密度不如数组大;
4、按序号查找时,数组可以随机访问,时间复杂度为O(1),而链表不支持随机访问,平均需要O(n);
5、按值查找时,若数组无序,数组和链表时间复杂度均为O(n),但是当数组有序时,可以采用折半查找将时间复杂度降为O(logn);
6、插入和删除时,数组平均需要移动n/2个元素,而链表只需修改指针即可;
7、空间分配方面:
数组在静态存储分配情形下,存储元素数量受限制,动态存储分配情形下,虽然存储空间可以扩充,但需要移动大量元素,导致操作效率降低,而且如果内存中没有更大块连续存储空间将导致分配失败;
链表存储的节点空间只在需要的时候申请分配,只要内存中有空间就可以分配,操作比较灵活高效;
1 数组
是最最基本的数据结构,很多语言都内置支持数组。数组是使用一块连续的内存空间保存数据,保存的数据的个数在分配内存的时候就是确定的:
图 1.1 包含 n 个数据的数组
访问数组中第 n 个数据的时间花费是 O(1) 但是要在数组中查找一个指定的数据则是 O(N)。当向数组中插入或者删除数据的时候,最好的情况是在数组的末尾进行操作,时间复杂度是O(1) ,但是最坏情况是插入或者删除第一个数据,时间复杂度是 O(N) 。在数组的任意位置插入或者删除数据的时候,后面的数据全部需要移动,移动的数据还是和数据个数有关所以总体的时间复杂度仍然是 O(N) 。
图 1.2 向数组中插入数据
2 链表
链表是在非连续的内存单元中保存数据,并且通过指针将各个内存单元链接在一起,最有一个节点的指针指向 NULL 。链表不需要提前分配固定大小存储空间,当需要存储数据的时候分配一块内存并将这块内存插入链表中。
在链表中查找第 n 个数据以及查找指定的数据的时间复杂度是 O(N) ,但是插入和删除数据的时间复杂度是 O(1) ,因为只需要调整指针就可以:
图 2.1 链表
图 2.2 向链表中插入一个数据
图 2.3 从链表中删除一个数据
向上面这样的链表结构在插入和删除的时候编程会比较困难,因为需要记住当前节点的前一个节点,这样才能完成插入和删除。为了简便通常使用带有头节点的链表:
图 2.4 带有头节点的单链表
上面的链表是单链表,此外还有双链表,就是节点中包含指向下一个节点的指针和指向上一个节点的指针:
图 2.5 双向链表
不带有头节点的双向链表在插入和删除数据的时候也不会出现单链表那样的问题。此外还有一种链表是循环链表,它是将双向链表的头尾相接:
图 2.6 双向循环链表
向循环双向链表和循环链表中插入或者从中删除数据只是多移动几个指针。
3 堆栈
栈: 是限定只能在表的一端进行插入和删除操作的线性表。
堆栈实现了一种后进先出的语义 (LIFO) 。可以使用数组或者是链表来实现它:
图 3.1 堆栈
对于堆栈中的数据的所有操作都是在栈的顶部完成的,只可以查看栈顶部的数据,只能够向栈的顶部压入数据,也只能从栈的顶部弹出数据。
4 队列
是限定只能在表的一端进行插入和在另一端进行删除操作的线性表;
队列实现了先入先出的语义 (FIFO) 。队列也可以使用数组和链表来实现:
图 4.1 队列
队列只允许在队尾添加数据,在队头删除数据。但是可以查看队头和队尾的数据。还有一种是双端队列,在两端都可以插入和删除:
图 4.2 双端队列
时间复杂度
数组每插入一个元素,考虑最坏的情况(即在第一个节点插入),则每个原先的元素都要往后移动一个位置;而链表插入一个元素,不需要移动原先的元素。所以说链表优于数组!
当需要一次性插入大量数据的时候,使用元素的时间复杂度每一次都是O(N),但是对于链表除了第一次是O(N),后面的插入都是O(1)。所以说在对插入和删除操作使用较多的 时候,链表优于数组。。{:1_1:}
5.列出它们的区别
一、规则不同
1. 队列:先进先出(First In First Out)FIFO
2. 栈:先进后出(First In Last Out )FILO
二、对插入和删除操作的限定不同
1. 队列:只能在表的一端进行插入,并在表的另一端进行删除;
2. 栈:只能在表的一端插入和删除。
三、遍历数据速度不同
1. 队列:基于地址指针进行遍历,而且可以从头部或者尾部进行遍历,但不能同时遍历,无需开辟空间,因为在遍历的过程中不影响数据结构,所以遍历速度要快;
2. 栈:只能从顶部取数据,也就是说最先进入栈底的,需要遍历整个栈才能取出来,而且在遍历数据的同时需要为数据开辟临时空间,保持数据在遍历前的一致性。
1.8.3 什么是Java虚拟机?为什么Java被称作是“平台无关的编程语言”
Java虚拟机是一个可以执行Java字节码的虚拟机进程。Java源文件被编译成能被Java虚拟机执行的字节码文件。是一个按照需求虚拟出来的机器.
Java是平台无关的语言是指用Java写的应用程序不用修改就可在不同的软硬件平台上运行。
平台无关有两种:源代码级和目标代码级。C和C++具有一定程度的源代码级平台无关,
表明用C或C++写的应用程序不用修改只需重新编译就可以在不同平台上运行。
Java主要靠Java虚拟机(JVM)在目标码级实现平台无关性。JVM是一种抽象机器,
它附着在具体操作系统之上,本身具有一套虚机器指令,并有自己的栈、寄存器组等。
但JVM通常是在软件上而不是在硬件上实现。
JVM是Java平台无关的基础,在JVM上,有一个Java解释器用来解释Java编译器编译后的程序。
Java编程人员在编写完软件后,通过Java编译器将Java源程序编译为JVM的字节代码。
任何一台机器只要配备了Java解释器,就可以运行这个程序,而不管这种字节码是在何种平台上生成的。
另外,Java采用的是基于IEEE标准的数据类型。通过JVM保证数据类型的一致性,也确保了Java的平台无关性。
1.8.4 JRE、JDK、JVM 及 JIT 之间有什么不同
java虚拟机(JVM):让java实现了跨平台
使用java编程语言的主要优势就是平台的独立性。你曾经想知道过java怎么实现平台的独立性吗?对,就是虚拟机,它抽象化了硬件设备,开发者和他们的程序的得以操作系统。虚拟机的职责就是处理和操作系统的交流。java不同的接口规范对任何平台都有良好的支持,因为jvm很好的实现了每个平台的规范。jvm可以理解伪代码字节码,在用户和操作系统之间建立了一层枢纽。
java运行时环境(JRE)
ava运行时环境是JVM的一个超集。JVM对于一个平台或者操作系统是明确的,而JRE确实一个一般的概念,他代表了完整的运行时环境。我们在jre文件夹中看到的所有的jar文件和可执行文件都会变成运行时的一部分。事实上,运行时JRE变成了JVM。所以对于一般情况时候使用JRE,对于明确的操作系统来说使用JVM。当你下载了JRE的时候,也就自动下载了JVM。
java开发工具箱(JDK)
java开发工具箱指的是编写一个java应用所需要的所有jar文件和可执行文件。事实上,JRE是JKD的一部分。如果你下载了JDK,你会看到一个名叫JRE的文件夹在里面。JDK中要被牢记的jar文件就是tools.jar,它包含了用于执行java文档的类还有用于类签名的jar包。
即时编译器(JIT)
即时编译器是种特殊的编译器,它通过有效的把字节码变成机器码来提高JVM的效率。
JIT这种功效很特殊,因为他把检测到的相似的字节码编译成单一运行的机器码,
从而节省了CPU的使用。这和其他的字节码编译器不同,
因为他是运行时(第一类执行的编译?),(从字节码到机器码)而不是在程序运行之前。
正是因为这些,动态编译这个词汇才和JIT有那么紧密的关系。
1.8.5 简单说说你了解的类加载器。是否实现过类加载器
A:类加载器的概述
负责将.class文件加载到内存中,并为之生成对应的Class对象。虽然我们不需要关心类加载机制,但是了解这个机制我们就能更好的理解程序的运行。
B:类加载器的分类
Bootstrap ClassLoader 根类加载器
Extension ClassLoader 扩展类加载器
Sysetm ClassLoader 系统类加载器
C:类加载器的作用
Bootstrap ClassLoader 根类加载器
也被称为引导类加载器,负责Java核心类的加载
比如System,String等。在JDK中JRE的lib目录下rt.jar文件中
Extension ClassLoader 扩展类加载器
负责JRE的扩展目录中jar包的加载。
在JDK中JRE的lib目录下ext目录
Sysetm ClassLoader 系统类加载器
负责在JVM启动时加载来自java命令的class文件,以及classpath环境变量所指定的jar包和类路径
1.8.6 内存溢出和栈溢出
1、 内存溢出的原因是什么?
内存溢出是由于没被引用的对象(垃圾)过多造成JVM没有及时回收,造成的内存溢出。如果出现这种现象可行代码排查:
一)是否App中的类中和引用变量过多使用了Static修饰 如public staitc Student s;在类中的属性中使用 static修饰的最好只用基本类型或字符串。如public static int i = 0; //public static String str;
二)是否App中使用了大量的递归或无限递归(递归中用到了大量的建新的对象)
三)是否App中使用了大量循环或死循环(循环中用到了大量的新建的对象)
四)检查App中是否使用了向数据库查询所有记录的方法。即一次性全部查询的方法,如果数据量超过10万多条了,就可能会造成内存溢出。所以在查询时应采用“分页查询”。
五)检查是否有数组,List,Map中存放的是对象的引用而不是对象,因为这些引用会让对应的对象不能被释放。会大量存储在内存中。
六)检查是否使用了“非字面量字符串进行+”的操作。因为String类的内容是不可变的,每次运行”+“就会产生新的对象,如果过多会造成新String对象过多,从而导致JVM没有及时回收而出现内存溢出。
如String s1 = “My name”;
String s2 = “is”;
String s3 = “xuwei”;
String str = s1 + s2 + s3 +…;这是会容易造成内存溢出的
但是String str = “My name” + ” is ” + ” xuwei” + ” nice ” + ” to ” + ” meet you”; //但是这种就不会造成内存溢出。因为这是”字面量字符串“,在运行”+“时就会在编译期间运行好。不会按照JVM来执行的。
在使用String,StringBuffer,StringBuilder时,如果是字面量字符串进行”+“时,应选用String性能更好;如果是String类进行”+”时,在不考虑线程安全时,应选用StringBuilder性能更好。
public class Test {
public void testHeap(){
for(;;){ //死循环一直创建对象,堆溢出
ArrayList list = new ArrayList (2000);
}
}
int num=1;
public void testStack(){ //无出口的递归调用,栈溢出
num++;
this.testStack();
}
public static void main(String[] args){
Test t = new Test ();
t.testHeap();
t.testStack();
}
}
七)使用 DDMS工具进行查找内存溢出的大概位置
2、栈溢出的原因
一)、是否有递归调用
二)、是否有大量循环或死循环
三)、全局变量是否过多
四)、 数组、List、map数据是否过大
五)使用DDMS工具进行查找大概出现栈溢出的位置
已有0 人发表留言,猛击->> 这里 <<-参与讨论
ITeye推荐
—软件人才免语言低担保 赴美带薪读研!—
相关 [java 内存 溢出] 推荐:
java 内存溢出 栈溢出的原因与排查方法
-
- 互联网 – ITeye博客
1、 内存溢出的原因是什么. 内存溢出是由于没被引用的对象(垃圾)过多造成JVM没有及时回收,造成的内存溢出. 如果出现这种现象可行代码排查:. 一)是否App中的类中和引用变量过多使用了Static修饰 如public staitc Student s;在类中的属性中使用 static修饰的最好只用基本类型或字符串. 如public static int i = 0; //public static String str;. 二)是否App中使用了大量的递归或无限递归(递归中用到了大量的建新的对象). 三)是否App中使用了大量循环或死循环(循环中用到了大量的新建的对象).
Java内存溢出问题的定位过程
- 互联网 – ITeye博客
-
- Java – 编程语言 – ITeye博客
相信通过写java程序讨生活的人对内存溢出并不陌生,如下文字的出现更是让人恼火:. 尤其当应用服务器(Java容器)出现上述情况更是让人有一种天塌下来的感觉. 好的编码实践可能会大大降低内存溢出的产生. 本文并不是写如何规避内存溢出,但是我还是要介绍一下如何能够尽量规避内存溢出:. 找几个资深程序猿(或者整个项目组讨论后)写一个Java编码规范,让项目组成员尽量遵守. 一目了然的代码更容易定位问题,当然也更能让人写出好的代码. 单元测试要覆盖所有分支与边界条件. 有句老话说常在河边站哪有不湿鞋(学名墨菲定律). 代码写完了,找资深程序猿扫扫代码没有坏处. 有条件的项目组要充分利用测试人员的能动性.
译文:解密Java内存溢出之持久代
- Java – 编程语言 – ITeye博客
-
-
研发管理 – ITeye博客
垃圾回收是Java程序员了解最少的一部分. 他们认为Java虚拟机接管了垃圾回收,因此没必要去担心内存的申请,分配等问题. 但是随着应用越来越复杂,垃圾回收也越来越复杂,一旦垃圾回收变的复杂,应用的性能将会大打折扣. 所以,Java程序员了解垃圾回收的机制并且知道怎样解决“内存溢出”问题会有很大的益处. 在Java中,有两个非常普遍的内存溢出问题. 一个是堆内存溢出,另一个是持久代内存溢出. Java对象是java 类的实例. 每当创建一个Java对象时,Java虚拟机都会创建该对象的内部引用并且保存在堆中. 如果一个类是第一次访问,那么它必须通过Java虚拟机加载进来.
1.8.7 怎样通过 Java 程序来判断 JVM 是 32 位 还是 64 位
public class Java64 {
public static void main(String args[]){
String arch = System.getProperty(“sun.arch.data.model”);
System.out.println(“jdk的版本为:”+arch);
}
-
}
1、、
1.1、32位系统只能装 32位 jdk
1.2、64位系统,安装的 32位JDK 和 64位JDK 是不同的目录
1.2.1、32位的路径 类似:C:\Program Files (x86)\Java\jdk1.7.0_25
1.2.2、64位的路径 ???
2、命令:“java -d?? -version”
我的机子 Win7x64,安装的是 32位的JDK
2.1、“java -d32 -version”
C:\Users\33>java -d32 -version
java version “1.7.0_25”
Java™ SE Runtime Environment (build 1.7.0_25-b17)
Java HotSpot™ Client VM (build 23.25-b01, mixed mode, sharing)
C:\Users\33>
2.2、“java -d64 -version”
C:\Users\33>java -d64 -version
Error: This Java instance does not support a 64-bit JVM.
Please install the desired version.
C:\Users\33>
3、命令 “java -version”
如果是64位的JDK,输出的结果中 会带有 “64-Bit”字样
1.8.8 32 位 JVM 和 64 位 JVM 的最大堆内存分别是多数? 32 位和 64 位的 JVM,int 类型变量的长度是多数
理论上说上 32 位的 JVM 堆内存可以到达 2^32,即 4GB,但实际上会比这个小很多。不同操作系统之间不同,如 Windows 系统大约 1.5 GB,Solaris 大约 3GB。64 位 JVM允许指定最大的堆内存,理论上可以达到 2^64,这是一个非常大的数字,实际上你可以指定堆内存大小到 100GB。甚至有的 JVM,如 Azul,堆内存到 1000G 都是可能的。
java是被设计成和具体的硬件无关的。
因此,java的64位版本和32位版本的int都是32位的范围。
1.8.9 JVM自身会维护缓存吗,是不是在堆中进行对象分配,操作系统的堆还是JVM自己管理的堆?为什么?
答案:是的,JVM自身会管理缓存,它在堆中创建对象,然后在栈中引用这些对象。
1.8.10 JVM监控工具介绍jstack, jconsole, jinfo, jmap, jdb, jstat
一、jps
1、介绍
用来查看基于HotSpot JVM里面所有进程的具体状态, 包括进程ID,进程启动的路径等等。与unix上的ps类似,用来显示本地有权限的java进程,可以查看本地运行着几个java程序,并显示他们的进程号。使用jps时,不需要传递进程号做为参数。
Jps也可以显示远程系统上的JAVA进程,这需要远程服务上开启了jstat服务,以及RMI注及服务,不过常用都是对本对的JAVA进程的查看。
2、命令格式
jps [ options ] [ hostid ]
3、常用参数说明
-m 输出传递给main方法的参数,如果是内嵌的JVM则输出为null。
-l 输出应用程序主类的完整包名,或者是应用程序JAR文件的完整路径。
-v 输出传给JVM的参数。
二、jstat
1、介绍
Jstat是JDK自带的一个轻量级小工具。全称“Java Virtual Machine statistics monitoring tool”,它位于java的bin目录下,主要利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控。可见,Jstat是轻量级的、专门针对JVM的工具,非常适用。由于JVM内存设置较大,图中百分比变化不太明显一个极强的监视VM内存工具。可以用来监视VM内存内的各种堆和非堆的大小及其内存使用量。
jstat工具特别强大,有众多的可选项,详细查看堆内各个部分的使用量,以及加载类的数量。使用时,需加上查看进程的进程id,和所选参数。
它主要是用来显示GC及PermGen相关的信息,否则其中即使你会使用jstat这个命令,你也看不懂它的输出。
2、命令格式
jstat [ generalOption | outputOptions vmid [interval[s|ms] [count]] ]
3、参数说明
1)、generalOption:单个的常用的命令行选项,如-help, -options, 或 -version。
2)、outputOptions:一个或多个输出选项,由单个的statOption选项组件,可以-t, -h, and -J选项配合使用。
statOption:
-class Option
-compiler Option
-gc Option
-gccapacity Option
-gccause Option
-gcnew Option
-gcnewcapacity Option
-gcold Option
-gcoldcapacity Option
-gcpermcapacity Option
-gcutil Option
-printcompilation Option
注:其中最常用的就是-gcutil选项了,因为他能够给我们展示大致的GC信息。
Option:指的是vmid、显示间隔时间及间隔次数等
vmid — VM的进程号,即当前运行的java进程号
interval– 间隔时间,单位为秒或者毫秒
count — 打印次数,如果缺省则打印无数次
3)、jstat命令输出参数说明
S0 — Heap上的 Survivor space 0 区已使用空间的百分比
S0C:S0当前容量的大小
S0U:S0已经使用的大小
S1 — Heap上的 Survivor space 1 区已使用空间的百分比
S1C:S1当前容量的大小
S1U:S1已经使用的大小
E — Heap上的 Eden space 区已使用空间的百分比
EC:Eden space当前容量的大小
EU:Eden space已经使用的大小
O — Heap上的 Old space 区已使用空间的百分比
OC:Old space当前容量的大小
OU:Old space已经使用的大小
P — Perm space 区已使用空间的百分比
OC:Perm space当前容量的大小
OU:Perm space已经使用的大小
YGC — 从应用程序启动到采样时发生 Young GC 的次数
YGCT– 从应用程序启动到采样时 Young GC 所用的时间(单位秒)
FGC — 从应用程序启动到采样时发生 Full GC 的次数
FGCT– 从应用程序启动到采样时 Full GC 所用的时间(单位秒)
GCT — 从应用程序启动到采样时用于垃圾回收的总时间(单位秒),它的值等于YGC+FGC
注:由于该工具参数过多,不再进行给出测试结果。
三、jstack
1、介绍
jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息,如果是在64位机器上,需要指定选项”-J-d64″,Windows的jstack使用方式只支持以下的这种方式:
jstack [-l] pid
如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序的java stack和native stack的信息, 如果现在运行的java程序呈现hung的状态,jstack是非常有用的。
2、命令格式
jstack [ option ] pid
jstack [ option ] executable core
jstack [ option ] [server-id@]remote-hostname-or-IP
3、常用参数说明
1)、options:
executable Java executable from which the core dump was produced.
(可能是产生core dump的java可执行程序)
core 将被打印信息的core dump文件
remote-hostname-or-IP 远程debug服务的主机名或ip
server-id 唯一id,假如一台主机上多个远程debug服务
2)、基本参数:
-F当’jstack [-l] pid’没有相应的时候强制打印栈信息
-l长列表. 打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表.
-m打印java和native c/c++框架的所有栈信息.
-h | -help打印帮助信息
pid 需要被打印配置信息的java进程id,可以用jps查询.
四、jmap
1、介绍
打印出某个java进程(使用pid)内存内的,所有对象的情况(如:产生那些对象,及其数量)。
可以输出所有内存中对象的工具,甚至可以将VM 中的heap,以二进制输出成文本。使用方法 jmap -histo pid。如果连用SHELL jmap -histo pid>a.log可以将其保存到文本中去,在一段时间后,使用文本对比工具,可以对比出GC回收了哪些对象。jmap -dump:format=b,file=outfile 3024可以将3024进程的内存heap输出出来到outfile文件里,再配合MAT(内存分析工具(Memory Analysis Tool)或与jhat (Java Heap Analysis Tool)一起使用,能够以图像的形式直观的展示当前内存是否有问题。
64位机上使用需要使用如下方式:
jmap -J-d64 -heap pid
2、命令格式
SYNOPSIS
jmap [ option ] pid
jmap [ option ] executable core
jmap [ option ] [server-id@]remote-hostname-or-IP
3、参数说明
1)、options:
executable Java executable from which the core dump was produced.
(可能是产生core dump的java可执行程序)
core 将被打印信息的core dump文件
remote-hostname-or-IP 远程debug服务的主机名或ip
server-id 唯一id,假如一台主机上多个远程debug服务
2)、基本参数:
-dump:[live,]format=b,file= 使用hprof二进制形式,输出jvm的heap内容到文件=. live子选项是可选的,假如指定live选项,那么只输出活的对象到文件.
-finalizerinfo 打印正等候回收的对象的信息.
-heap 打印heap的概要信息,GC使用的算法,heap的配置及wise heap的使用情况.
-histo[:live] 打印每个class的实例数目,内存占用,类全名信息. VM的内部类名字开头会加上前缀”*”. 如果live子参数加上后,只统计活的对象数量.
-permstat 打印classload和jvm heap长久层的信息. 包含每个classloader的名字,活泼性,地址,父classloader和加载的class数量. 另外,内部String的数量和占用内存数也会打印出来.
-F 强迫.在pid没有相应的时候使用-dump或者-histo参数. 在这个模式下,live子参数无效.
-h | -help 打印辅助信息
-J 传递参数给jmap启动的jvm.
pid 需要被打印配相信息的java进程id,创业与打工的区别 – 博文预览,可以用jps查问.
注:平时该命令我是使用最多的。
五、jinfo
jinfo可以输出并修改运行时的java 进程的opts。用处比较简单,用于输出JAVA系统参数及命令行参数。
六、jconsole和jvisualvm
jconsole:一个java GUI监视工具,可以以图表化的形式显示各种数据。并可通过远程连接监视远程的服务器VM。用java写的GUI程序,用来监控VM,并可监控远程的VM,非常易用,而且功能非常强。命令行里打 jconsole,选则进程就可以了。
需要注意的就是在运行jconsole之前,必须要先设置环境变量DISPLAY,否则会报错误,Linux下设置环境变量如下:
export DISPLAY=:0.0
jvisualvm同jconsole都是一个基于图形化界面的、可以查看本地及远程的JAVA GUI监控工具,Jvisualvm同jconsole的使用方式一样,直接在命令行打入Jvisualvm即可启动,不过Jvisualvm相比,界面更美观一些,数据更实时。
七、Jhat
jhat用于对JAVA heap进行离线分析的工具,他可以对不同虚拟机中导出的heap信息文件进行分析,如LINUX上导出的文件可以拿到WINDOWS上进行分析,可以查找诸如内存方面的问题,不过jhat和MAT比较起来,就没有MAT那么直观了,MAT是以图形界面的方式展现结果。
八、Jdb
用来对core文件和正在运行的Java进程进行实时地调试,里面包含了丰富的命令帮助您进行调试,它的功能和Sun studio里面所带的dbx非常相似,但 jdb是专门用来针对Java应用程序的。现在应该说日常的开发中很少用到JDB了,因为现在的IDE已经帮我们封装好了,如使用ECLIPSE调用程序就是非常方便的,只要在非常特定的情况下可能会用到这个命令,如远程服务器的维护,没有IDE进行调试,那这个时候JDB应该可以帮上忙。
1.8.11 BlockingQueue
1.8.11.2 BlockingQueue是什么
答案:
1.BlockingQueue队列和平常队列一样都可以用来作为存储数据的容器,
但有时候在线程当中涉及到数据存储的时候就会出现问题,而BlockingQueue是空的话,
如果一个线程要从BlockingQueue里取数据的时候,该线程将会被阻断,并进入等待状态,
直到BlockingQueue里面有数据存入了后,就会唤醒线程进行数据的去除。
若BlockingQueue是满的,如果一个线程要将数据存入BlockQueue,该线程将会被阻断,并进入等待状态,
直到BlcokQueue里面的数据被取出有空间后,线程被唤醒后在将数据存入
2.BlockingQueue定义的常用方法详解:
1)add(anObject):把anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则报异常
2)offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则 返回false.
3)put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续.
4)poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null
5)take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到Blocking有新的对象被加入为止
3.BlockingQueue有四个具体的实现类,根据不同需求,选择不同的实现类
1)ArrayBlockingQueue:规定大小的BlockingQueue,其构造函数必须带一个int参数来指明其大小.其所含的对象是以FIFO(先入先出)顺序排序的.
2)LinkedBlockingQueue:大小不定的BlockingQueue,若其构造函数带一个规定大小的参数,生成的 BlockingQueue有大小限制,
若不带大小参数,所生成的BlockingQueue的大小由Integer.MAX_VALUE来决定.其所含 的对象是以FIFO(先入先出)顺序排序的
3)PriorityBlockingQueue:类似于LinkedBlockQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数的Comparator决定的顺序.
4)SynchronousQueue:特殊的BlockingQueue,对其的操作必须是放和取交替完成的.
4.LinkedBlockingQueue和ArrayBlockingQueue比较起来,它们背后所用的数据结构不一样,
导致 LinkedBlockingQueue的数据吞吐量要大于ArrayBlockingQueue,但在线程数量很大时其性能的可预见性低于 ArrayBlockingQueue.
1.8.11.2 简述 ConcurrentLinkedQueue LinkedBlockingQueue 的用处和不同之处。
1.由于LinkedBlockingQueue实现是线程安全的,实现了先进先出等特性,是作为生产者消费者的首选,LinkedBlockingQueue 可以指定容量,也可以不指定,不指定的话,默认最大是Integer.MAX_VALUE,其中主要用到put和take方法,put方法在队列满的时候会阻塞直到有队列成员被消费,take方法在队列空的时候会阻塞,直到有队列成员被放进来。
2.LinkedBlockingQueue是一个线程安全的阻塞队列,它实现了BlockingQueue接口,BlockingQueue接口继承自java.util.Queue接口,并在这个接口的基础上增加了take和put方法,这两个方法正是队列操作的阻塞版本。
3.ConcurrentLinkedQueue是无阻塞的队列,可伸缩性比BlockingQueue高。ConcurrentLinkedQueue是Queue的一个安全实现.Queue中元素按FIFO原则进行排序.采用CAS操作,来保证元素的一致性。
4.两个都是线程安全的
1.9接口和抽象类
1.9.1 abstract 类
1、抽象类不能被实例化,实例化的工作应该交由它的子类来完成,它只需要有一个引用即可。
2、抽象方法必须由子类来进行重写。
3、只要包含一个抽象方法的抽象类,该方法必须要定义成抽象类,不管是否还包含有其他方法。
4、抽象类中可以包含具体的方法,当然也可以不包含抽象方法。
5、子类中的抽象方法不能与父类的抽象方法同名。
6、abstract不能与final并列修饰同一个类。
7、abstract 不能与private、static、final或native并列修饰同一个方法。、
1.9.2 Interface
1、个Interface的方所有法访问权限自动被声明为public。确切的说只能为public,当然你可以显示的声明为protected、private,但是编译会出错!
2、接口中可以定义“成员变量”,或者说是不可变的常量,因为接口中的“成员变量”会自动变为为public static final。可以通过类命名直接访问:ImplementClass.name。
3、接口中不存在实现的方法。
4、实现接口的非抽象类必须要实现该接口的所有方法。抽象类可以不用实现。
5、不能使用new操作符实例化一个接口,但可以声明一个接口变量,该变量必须引用(refer to)一个实现该接口的类的对象。可以使用 instanceof 检查一个对象是否实现了某个特定的接口。例如:if(anObject instanceof Comparable){}。
6、在实现多接口的时候一定要避免方法名的重复。
1.9.3 接口和抽象类的区别
1、 抽象类在java语言中所表示的是一种继承关系,一个子类只能存在一个父类,但是可以存在多个接口。
2、 在抽象类中可以拥有自己的成员变量和非抽象类方法,但是接口中只能存在公开静态常量(不过一般都不在接口中定义成员数据),而且它的所有方法都是抽象的。
3、抽象类和接口所反映的设计理念是不同的,抽象类所代表的是“is-a”的关系,而接口所代表的是“like-a”的关系。
4、接口没有构造方法 动/静态代码块、
1.9.4 接口的好处
1 设计与实现分离
2 更自然的使用多态
3 更容易搭建程序框架
4 更容易更换实现 (开闭原则 对扩展开放 对修改关闭)
5 程序的耦合性降低
1.9.5 抽象类中是否可以有静态的main方法
抽象类中可以有静态的main方法,main方法都是静态的;
抽象类往往用来表征对问题领域进行分析、设计中得出的抽象概念,是对一系列看上去不同,但是本质上相同的具体概念的抽象。
通常在编程语句中用 abstract 修饰的类是抽象类。在C++中,含有纯虚拟函数的类称为抽象类,它不能生成对象;在java中,含有抽象方法的类称为抽象类,同样不能生成对象。
抽象类是不完整的,它只能用作基类。在面向对象方法中,抽象类主要用来进行类型隐藏和充当全局变量的角色。
1.9.6 接口是否可继承接口
可以
1.9.7 抽象类是否可实现(implements)接口
是
1.9.8 抽象类是否可继承具体类(concrete class)
抽象类是可以继承实体类,但前提是实体类必须有明确的构造函数
1.9.9 Comparator 与 Comparable 接口是干什么的?列出它们的区别
1,Comparable
Comparable 定义在 Person类的内部:
public class Persion implements Comparable {…比较Person的大小…},
因为已经实现了比较器,那么我们的Person现在是一个可以比较大小的对象了,它的比较功能和String完全一样,可以随时随地的拿来
比较大小,因为Person现在自身就是有大小之分的。Collections.sort(personList)可以得到正确的结果。
2,Comparator
Comparator 是定义在Person的外部的, 此时我们的Person类的结构不需要有任何变化,如
public class Person{ String name; int age },
然后我们另外定义一个比较器:
public PersonComparator implements Comparator() {…比较Person的大小…},
在PersonComparator里面实现了怎么比较两个Person的大小. 所以,用这种方法,当我们要对一个 personList进行排序的时候,
我们除了了要传递personList过去, 还需要把PersonComparator传递过去,因为怎么比较Person的大小是在PersonComparator
里面实现的, 如:
Collections.sort( personList , new PersonComparator() ).
2.0 final
2.0.1 final关键字有哪些用法
一、final修饰类:
被final修饰的类,是不可以被继承的,这样做的目的可以保证该类不被修改,Java的一些核心的API都是final类,例如String、Integer、Math等
代码举例:
二、final修饰方法:
子类不可以重写父类中被final修饰的方法
代码举例:
三、final修饰实例变量(类的属性,定义在类内,但是在类内的方法之外)
final修饰实例变量时必须初始化,且不可再修改
final修饰实例变量时必须初始化代码举例:
final修饰实例变量时必须初始化,且不可再修改代码举例:
四、final修饰局部变量(方法体内的变量)
final修饰局部变量时只能初始化(赋值)一次,但也可以不初始化
代码举例:
五、final修饰方法参数
final修饰方法参数时,是在调用方法传递参数时候初始化的
代码举例:
2.0.2 final、finally、finalize区别
final用于修饰类、成员变量和成员方法。
1、final修饰的类,不能被继承(String、StringBuilder、StringBuffer、Math,不可变类),其中所有的方法都不能被重写,所以不能同时用abstract和final修饰类(abstract修饰的类是抽象类,抽象类是用于被子类继承的,和final起相反的作用);
2、final修饰的方法不能被重写,但是子类可以用父类中final修饰的方法;
3、final修饰的成员变量是不可变的,如果成员变量是基本数据类型,初始化之后成员变量的值不能被改变,如果成员变量是引用类型,那么它只能指向初始化时指向的那个对象,不能再指向别的对象,但是对象当中的内容是允许改变的。
Final修饰的形参,不能在方法中对形参赋值
方法内声明的类或者方法内的匿名内部类,访问该方法内定义的变量,该变量必须要用final修饰。当内部类访问局部变量时,会扩大局部变量的作用域,如果局部变量不用 final 修饰,我们就可以在内部类中随意修改该局部变量值,而且是在该局部变量的作用域范围之外可以看到这些修改后的值,会出现安全问题。
finally通常和try catch搭配使用,保证不管有没有发生异常,资源都能够被释放(释放连接、关闭IO流)。
finalize是object类中的一个方法,子类可以重写finalize()方法实现对资源的回收。垃圾回收只负责回收内存,并不负责资源的回收,资源回收要由程序员完成,Java虚拟机在垃圾回收之前会先调用垃圾对象的finalize方法用于使对象释放资源(如关闭连接、关闭文件),之后才进行垃圾回收,这个方法一般不会显示的调用,在垃圾回收时垃圾回收器会主动调用。
2.0.3 能否在运行时向 static final 类型的赋值
在java中用final修饰符修饰的变量表示不可以被二次赋值,且系统不会给其赋默认值。
如果单纯只是final变量,可以在定义的时候就赋默认值,也可以在构造方法中赋默认值。
但是如果同时用final static 修饰变量,因为static变量属于类而不属于对象,且在调用构造方法之前static 变量就已经被系统给赋默认值。而相应的final static 变量就只能在定义的时候就初始化,否则既无法在构造方法中初始化,系统又不会赋默认值,相当于这个变量被定义出来是毫无用处的。 因此java中final static变量必须初始化。
2.0.4 一个类被声明为final类型,表示了什么意思
一般该类的设计者认为该类已经达到完美,完全没有必要再去修改它,用final关键字。
或者是该类的设计者由于种种原因不希望该类被继承,用final关键字修饰。
被final关键字修饰之后的类不能被继承,一般认为是完美的,或者被随意的继承可能导致隐蔽的错误。
java中的String类就是一个final类
2.0.5 如何构建不可变的类结构?关键点在哪里
创建不可变类,要实现下面几个步骤:
1.将类声明为final,所以它不能被继承
2.将所有的成员声明为私有的,这样就不允许直接访问这些成员
3.对变量不要提供setter方法
4.将所有可变的成员声明为final,这样只能对它们赋值一次
5.通过构造器初始化所有成员,进行深拷贝(deep copy)
6.在getter方法中,不要直接返回对象本身,而是克隆对象,并返回对象的拷贝
2.0.6 能创建一个包含可变对象的不可变对象吗
是的,我们是可以创建一个包含可变对象的不可变对象的,你只需要谨慎一点,不要共享可变对象的引用就可以了,如果需要变化时,就返回原对象的一个拷贝。最常见的例子就是对象中包含一个日期对象的引用
2.1 异常
2.1.1 throws, throw, try, catch, finally分别代表什么意义
throws是获取异常
throw是抛出异常
try是将会发生异常的语句括起来,从而进行异常的处理,
catch是如果有异常就会执行他里面的语句,
而finally不论是否有异常都会进行执行的语句。
throw和throws的详细区别如下:
throw是语句抛出一个异常。
语法:throw (异常对象);
throw e;
throws是方法可能抛出异常的声明。(用在声明方法时,表示该方法可能要抛出异常)
语法:(修饰符)(方法名)([参数列表])[throws(异常类)]{…}
public void doA(int a) throws Exception1,Exception3{…}
- 区别
throws是用来声明一个方法可能抛出的所有异常信息,而throw则是指抛出的一个具体的异常类型。此外throws是将异常声明但是不处理,而是将异常往上传,谁调用我就交给谁处理。
2.分别介绍
throws:用于声明异常,例如,如果一个方法里面不想有任何的异常处理,则在没有任何代码进行异常处理的时候,必须对这个方法进行声明有可能产生的所有异常(其实就是,不想自己处理,那就交给别人吧,告诉别人我会出现什么异常,报自己的错,让别人处理去吧)。
格式是:方法名(参数)throws 异常类1,异常类2,…
2.1.2 Java中的Error和Exception
Error和Exception的联系
继承结构:Error和Exception都是继承于Throwable,RuntimeException继承自Exception。
Error和RuntimeException及其子类称为未检查异常(Unchecked exception),其它异常成为受检查异常(Checked Exception)。
Error和Exception的区别
Error类一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢出等。如java.lang.StackOverFlowError和Java.lang.OutOfMemoryError。对于这类错误,Java编译器不去检查他们。对于这类错误的导致的应用程序中断,仅靠程序本身无法恢复和预防,遇到这样的错误,建议让程序终止。
Exception类表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常。
运行时异常和受检查的异常
Exception又分为运行时异常(Runtime Exception)和受检查的异常(Checked Exception )。
RuntimeException:其特点是Java编译器不去检查它,也就是说,当程序中可能出现这类异常时,即使没有用try……catch捕获,也没有用throws抛出,还是会编译通过,如除数为零的ArithmeticException、错误的类型转换、数组越界访问和试图访问空指针等。处理RuntimeException的原则是:如果出现RuntimeException,那么一定是程序员的错误。
受检查的异常(IOException等):这类异常如果没有try……catch也没有throws抛出,编译是通不过的。这类异常一般是外部错误,例如文件找不到、试图从文件尾后读取数据等,这并不是程序本身的错误,而是在应用环境中出现的外部错误。
throw 和 throws两个关键字有什么不同
throw 是用来抛出任意异常的,你可以抛出任意 Throwable,包括自定义的异常类对象;throws总是出现在一个函数头中,用来标明该成员函数可能抛出的各种异常。如果方法抛出了异常,那么调用这个方法的时候就需要处理这个异常。
try-catch-finally-return执行顺序
1、不管是否有异常产生,finally块中代码都会执行;
2、当try和catch中有return语句时,finally块仍然会执行;
3、finally是在return后面的表达式运算后执行的,所以函数返回值是在finally执行前确定的。无论finally中的代码怎么样,返回的值都不会改变,仍然是之前return语句中保存的值;
4、finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值。
2.1.3 NullPointerException 和 ArrayIndexOutOfBoundException 之间有什么相同之处
2.1.4 运行时异常
出现运行时异常后,系统会把异常一直往上层抛,一直遇到处理代码。如果没有处理块,到最上层,如果是多线程就由Thread.run()抛出,如果是单线程就被main()抛出。抛出之后,如果是线程,这个线程也就退出了。如果是主程序抛出的异常,那么这整个程序也就退出了。运行时异常是Exception的子类,也有一般异常的特点,是可以被Catch块处理的。只不过往往我们不对他处理罢了。也就是说,你如果不对运行时异常进行处理,那么出现运行时异常之后,要么是线程中止,要么是主程序终止。
如果不想终止,则必须扑捉所有的运行时异常,决不让这个处理线程退出。队列里面出现异常数据了,正常的处理应该是把异常数据舍弃,然后记录日志。不应该由于异常数据而影响下面对正常数据的处理。在这个场景这样处理可能是一个比较好的应用,但并不代表在所有的场景你都应该如此。如果在其它场景,遇到了一些错误,如果退出程序比较好,这时你就可以不太理会运行时异常,或者是通过对异常的处理显式的控制程序退出。异常处理的目标之一就是为了把程序从异常中恢复出来。
2.1.5 简述一个你最常见到的runtime exception(运行时异常)
ArithmeticException, 算术异常
ArrayStoreException, 将数组类型不兼容的值赋值给数组元素时抛出的异常
BufferOverflowException, 缓冲区溢出异常
BufferUnderflowException, 缓冲区下溢异常
CannotRedoException, 不能重复上一次操作异常
CannotUndoException, 不能撤销上一次操作异常
ClassCastException, 类型强制转换异常
ClassNotFoundException 类没找到时,抛出该异常
CMMException, CMM异常
ConcurrentModificationException, 对Vector、ArrayList在迭代的时候如果同时对其进行修改就会抛出异常
org.springframework.jdbc.CannotGetJdbcConnectionException 服务器端数据库连接不上时,抛出该异常
CannotGetJdbcConnectionException 网络没有连接或网络中断
DOMException, DOM异常
EOFException, 文件已结束异常
EmptyStackException, 空栈异常
FileNotFoundException, 文件未找到异常
IllegalArgumentException, 传递非法参数异常
IllegalMonitorStateException,
IllegalAccessException, 访问某类被拒绝时抛出的异常
IllegalPathStateException, 非法的路径声明异常
IllegalStateException, 非法声明异常
ImagingOpException, 成像操作异常
IndexOutOfBoundsException, 下标越界异常
IOException, 输入输出异常
NegativeArraySizeException, 数组负下标异常
NoSuchMethodException 在类中无法找到某一特定方法时,抛出该异常
NoSuchElementException, 方法未找到异常
NoSuchFieldException 类不包含指定名称的字段时产生的信号(bean中不存在这个属性)
NumberFormatException, 字符串转换为数字异常
NullPointerException, 空指针异常
ProfileDataException, 没有日志文件异常
ProviderException, 供应者异常
RasterFormatException, 平面格式异常
SecurityException, 违背安全原则异常
SQLException, 操作数据库异常
SystemException, 系统异常
UndeclaredThrowableException,
UnmodifiableSetException,
UnsupportedOperationException, 不支持的操作异常
2.1.6 什么情况下不会执行finally中的代码?
除非在try块或者catch块中调用了退出虚拟机的方法(即System.exit(1);),否则不管在try块、catch块中执行怎样的代码,出现怎样的情况,异常处理的finally块总是会被执行的。不过,一般情况下,不要再finally块中使用return或throw等导致方法终止的语句,因为一旦使用,将会导致try块、catch块中的return、throw语句失效。
总结一下这个小问题:
当程序执行try块,catch块时遇到return语句或者throw语句,这两个语句都会导致该方法立即结束,所以系统并不会立即执行这两个语句,而是 去寻找该异常处理流程中的finally块,如果没有finally块,程序立即执行return语句或者throw语句,方法终止。如果有 finally块,系统立即开始执行finally块,只有当finally块执行完成后,系统才会再次跳回来执行try块、catch块里的 return或throw语句,如果finally块里也使用了return或throw等导致方法终止的语句,则finally块已经终止了方法,不用 再跳回去执行try块、catch块里的任何代码了。
综上:尽量避免在finally块里使用return或throw等导致方法终止的语句,否则可能出现一些很奇怪的情况!
使用throws抛出异常的思路是:当前方法不知道如何处理这种类型的异常,该异常应该由上一级调用者处理,如果main方法也不知道应该如何处理这种类型的异常,也可以使用使用throws声明抛出异常,该异常将交给JVM来处理。
JVM对异常的处理方法:打印异常跟踪栈的信息,并终止程序运行,所以有很多程序遇到异常后自动结束。
2.1.7 OOM
1, OutOfMemoryError异常
除了程序计数器外,虚拟机内存的其他几个运行时区域都有发生OutOfMemoryError(OOM)异常的可能,
Java Heap 溢出
一般的异常信息:java.lang.OutOfMemoryError:Java heap spacess
java堆用于存储对象实例,我们只要不断的创建对象,并且保证GC Roots到对象之间有可达路径来避免垃圾回收机制清除这些对象,就会在对象数量达到最大堆容量限制后产生内存溢出异常。
出现这种异常,一般手段是先通过内存映像分析工具(如Eclipse Memory Analyzer)对dump出来的堆转存快照进行分析,重点是确认内存中的对象是否是必要的,先分清是因为内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)。
如果是内存泄漏,可进一步通过工具查看泄漏对象到GC Roots的引用链。于是就能找到泄漏对象时通过怎样的路径与GC Roots相关联并导致垃圾收集器无法自动回收。
如果不存在泄漏,那就应该检查虚拟机的参数(-Xmx与-Xms)的设置是否适当。
2, 虚拟机栈和本地方法栈溢出
如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常。
如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常
这里需要注意当栈的大小越大可分配的线程数就越少。
3, 运行时常量池溢出
异常信息:java.lang.OutOfMemoryError:PermGen space
如果要向运行时常量池中添加内容,最简单的做法就是使用String.intern()这个Native方法。该方法的作用是:如果池中已经包含一个等于此String的字符串,则返回代表池中这个字符串的String对象;否则,将此String对象包含的字符串添加到常量池中,并且返回此String对象的引用。由于常量池分配在方法区内,我们可以通过-XX:PermSize和-XX:MaxPermSize限制方法区的大小,从而间接限制其中常量池的容量。
4, 方法区溢出
方法区用于存放Class的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。
异常信息:java.lang.OutOfMemoryError:PermGen space
方法区溢出也是一种常见的内存溢出异常,一个类如果要被垃圾收集器回收,判定条件是很苛刻的。在经常动态生成大量Class的应用中,要特别注意这点。
2.1.8 SOF
SOF (堆栈溢出 StackOverflow)
StackOverflowError 的定义:
当应用程序递归太深而发生堆栈溢出时,抛出该错误。
因为栈一般默认为1-2m,一旦出现死循环或者是大量的递归调用,在不断的压栈过程中,造成栈容量超过1m而导致溢出。
栈溢出的原因:
1
2
3
4
5
6
7
8 递归调用
大量循环或死循环
全局变量是否过多
数组、List、map数据过大
2.1.9 既然我们可以用RuntimeException来处理错误,那么你认为为什么Java中还存在检查型异常?
这是一个有争议的问题,在回答该问题时你应当小心。虽然他们肯定愿意听到你的观点,但其实他们最感兴
趣的还是有说服力的理由。我认为其中一个理由是,存在检查型异常是一个设计上的决定,受到了诸如C++等比
Java更早的编程语言设计经验的影响。绝大多数检查型异常位于java.io包内,这是合乎情理的,因为在你请求了
不存在的系统资源的时候,一段强壮的程序必须能够优雅的处理这种情况。通过把IOException声明为检查型异
常,Java 确保了你能够优雅的对异常进行处理。另一个可能的理由是,可以使用catch或finally来确保数量受限
的系统资源(比如文件描述符)在你使用后尽早得到释放。
2.2.0 空指针异常总结
1:NullPointerException由RuntimeException派生出来,是一个运行级别的异常。意思是说可能会在运行的时候才会被抛出,而且需要看这样的运行级别异常是否会导致你的业务逻辑中断。
2:空指针异常发生在对象为空,但是引用这个对象的方法。例如: String s = null; //对象s为空(null) int length = s.length();//发生空指针异常
3:一个变量是null,及只有其名,没有实值内容,也没分配内存,当你要去取他的长度,对他进行操作就会出现NullPointException,所以生命一个变量时最好给它分配好内存空间,给予赋值。
4:比如变量为空,而你没有去判断,就直接使用,就会出现NullPointException。写程序时严谨些,尽量避免了,例如在拿该变量与一个值比较时,要么先做好该异常的处理如: if (str == null) { System.out.println(“字符为空!”); } 当然也可以将这个值写在前面进行比较的,例如,判断一个String的实例s是否等于“a”,不要写成s.equals(“a”),这样写容易抛出NullPointerException,而写成”a”.equals(s)就可以避免这个问题。不过对变量先进行判空后再进行操作比较好
5:尽量避免返回null,方法的返回值不要定义成为一般的类型,而是用数组。这样如果想要返回null的时候,就返回一个没有元素的数组。就能避免许多不必要的NullPointerException,使用NullObject返回代替返回null确是一种不错的选择。
6:NullPointerException这个东西换一个角度来看,没准是好处也不一定。可以说,NullPointerException本身也是JAVA安全机制的一部分。有UNIX写C和C++的经验的可能都知道,空指针会导致什么问题:经常会导致程序的崩溃。 ? 而JAVA在这点进行了改善,JAVA为了保证程序的强壮,总是会对对象的引用进行检查。所以不再出险C/C++中的空指针错误,而仅仅是一个运行级别的异常-“NullPointerException”。从这点上说,算是JAVA的一个好处吧。 Josha Bloch倒是在《Effective Java》中说过返回数组的函数,如果没有返回值,优先返回零长度数组而不是返回null。 ? 不过使用NullObject返回代替返回null确是一种不错的选择。返回数组的方法同样可以返回null,因为数组在JAVA中已经发展为完备的对象了。如果是这样,INVOKER也是不可避免地检查NullPointerException。 初值不是你想决定是什么就是什么的。在很多情况下,你甚至无法断定对象的初值是什么才合适。所以这样的习惯并不见得就是很好的习惯。比如说你认为: String str = “”; 这样比较合理,但是为什么不是String str = “A”; 呢?在某些场合并不见得”“就是合理的初值。关键还是在建立publish方法的契约之上。如果你使用第三方的方法,你需要阅读其JAVADOC,知道其是否会返回null对象?是否会抛出checkedException,是否会抛出运行级别异常。如果是你自己publish方法,那么你需要在你的JAVADOC中说明你的方法的契约:满足什么条件才能调用此方法,调用之后会产生什么返回?是否会返回/何时返回null?是否抛出异常。在实现publish方法的时候,对于入口参数的检查也是非常关键的,因为调用者的行为是你无法期望的。 其实异常的处理是一个很有意思的话题,不仅仅只是NullPointerException。比如在DBC中有这么一个例子:你需要打开一个文件读,可能是C:\Data.txt,文件却没有找到,叫不叫异常?你如果需要打开另外一个文件,比如是C:\boot.ini,文件也没有找到,叫不叫异常?第一种情况不叫“异常”,因为C:\Data.txt没有找到应该是你能预计到的情况,那个文件可能存在,也可能不存在,这是需要你自己处理的。而第二种情况确叫做异常,因为正常情况下,C:\boot.ini应该被期望存在的,如果运行时丢失了这个文件,就是运行级别异常。在JDK中也有相应的例子,比如FileInputStream, BufferReader, StringTokenizer处理到达尾部的情况就是不一样的。 <<4.为什么说ResultSet作为处理结果不恰当呢?>> 把不相关的东西耦合在了一起。把JDBC query的结果集逻辑和自己需要的数据聚集的逻辑耦合在了一起。这样连抽象都无法做。现在俺们是从数据库中随机取结果,所以你使用了ResultSet,假设需求变化了,需要从文本文件源中取结果了,你的ResultSet接口成了什么?所以说更好的做法是抽象出数据获取的接口,而针对接口不同实现即可。 ? “单一职责”这点很关键,不需要耦合在一起的东西就不要耦合在一起。
7:我在写程序时,String uri=getSavePath()+getUploadFileName(); System.out.println(uri+“123345”);//这里可以输出结果的 String linkname=getUploadFileName(); String update=“update UserTable set uri=‘?’,linkname=‘?’,linkid=’?’where username=”+”‘“+username+”’”; DataBaseOperate dbo=new DataBaseOperate(); PreparedStatement ps=dbo.getConnection1().prepareStatement(update); ps.setString(1, uri); //这一行居然报出空指针异常呢? ps.setString(2, linkname); ps.setInt(3, i++); ps.executeUpdate(); 原来是加?号是为了可以自动给变量给值‘?’ 变成了字符常量了 …
2.2.1 catch块里别不写代码有什么问题
也就是说如果不在catch块里做异return或者throw的话,遇到异常程序是会继续走下去的,可能会造成严重错误。一般来说catch块里肯定要写一些其他的处理代码,但是最后一定是以return throw结尾的。
2.2.2 异常链
一 异常链简介
常常会在捕获一个异常后,再抛出另外一个异常,并且希望把异常原始信息保存下来,这被称为异常链。
在JDK1.4以前,程序员必须自己编写代码来保存原始异常信息。
在JDK1.4以后,所有的Throwable的子类在构造器中都可以接收一个cause对象作为参数。这个cause就用来表示原始异常,这样可以把原始异常传递给新的异常,使得即使在当前位置创建并抛出新的异常,你也能通过这个异常链跟踪到异常最初发生的位置。
二 异常链的应用
1 代码示例
[java] view plain copy
print?
public class SalException extends Exception
{
public SalException(){}
public SalException(String msg)
{
super(msg);
}
// 创建一个可以接受Throwable参数的构造器
public SalException(Throwable t)
{
super(t);
}
}
[java] view plain copy
print?
public class TestSalException {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
try
{
Calsal();
}
catch(SalException e)
{
e.printStackTrace();
}
}
public static void Calsal() throws SalException
{
try
{
int a;
a=8/0;
}
catch(Exception e)
{
throw new SalException(e);
}
}
}
2 运行结果
SalException: java.lang.ArithmeticException: / by zero
at TestSalException.Calsal(TestSalException.java:29)
at TestSalException.main(TestSalException.java:11)
Caused by: java.lang.ArithmeticException: / by zero
at TestSalException.Calsal(TestSalException.java:25)
… 1 more
2.2.3 你曾经自定义实现过异常吗?怎么写的?
很显然,我们绝大多数都写过自定义或者业务异常,像AccountNotFoundException。在面试过程中询问这个Java异常问题的主要原因是去发现你如何使用这个特性的。这可以更准确和精致的去处理异常,当然这也跟你选择checked 还是unchecked exception息息相关。通过为每一个特定的情况创建一个特定的异常,你就为调用者更好的处理异常提供了更好的选择。相比通用异常(general exception),我更倾向更为精确的异常。大量的创建自定义异常会增加项目class的个数,因此,在自定义异常和通用异常之间维持一个平衡是成功的关键。
2.2.4 UnsupportedOperationException是什么
ava.lang.UnsupportedOperationException 大致的意思是,你调用的关于的容器的操作是不被允许的。
注意【思想性的一些东西】:
1.这不是说没有该方法,如果没有该方法的话,在编译期间就可以识别。
2.有该方法,也就是说该方法受到了限制。
3.限制就类似于权限限制之类的东西。(类似于linux 中对于文件权限的管理)。如果list不能实现这种权限的限制,那么会存在一些安全性的问题。所以可以看出来,权限在大部分场合都是一个必备的成分。
4.不同的粒度上,相关的语言提供了不同控制权限的方式。
5.本质上,下面的错误案例,都可以归结为权限问题。
二、错误情况的举例1
Collections.unmodifiableList(*)引起的错误
下面这段代码会出现错误,抛出java.lang.UnsupportedOperationException.
Collections.unmodifiableList 起到了对list设置权限的目的。
private static void testReadOnly(){
//1.创建一个list。并且这个list的访问权限未进行设置。
List modifyList = new ArrayList<>();
//2.向其中插入相关的数据。【可行】
modifyList.add(“you”);
modifyList.add(“are”);
modifyList.add(“boy”);
//3.对list进行设置。使之可读。
modifyList = Collections.unmodifiableList(modifyList);
//4.在次插入,出现错误。
modifyList.add(“hello”);
}
解决办法
1.该只读的权限维护的是,修改list中引用的权限。
2.但是如果你如果不改引用,是可以通过引用来更改其所指向的对象的。
private static void testChangeReadOnly(){
1.创建2个list。并且这2个list的访问权限未进行设置。
List modifyList = new ArrayList<>();
List normalList= new LinkedList<>();
//2.向modifylist中插入元素。
modifyList.add(new StringBuilder(“you”));
modifyList.add(new StringBuilder(“are”));
modifyList.add(new StringBuilder(“boy”));
//3.设置可读权限
modifyList = Collections.unmodifiableList(modifyList);
//4.将只读的modifyList中的引用复制到normalList中。
normalList.addAll(modifyList);
//5.向normalList中插入数据。
normalList.add(new StringBuilder(“hello”));
System.out.println(normalList.toString());//[you, are, boy, hello]
//6.更改只读list中,引用所指向的对象的值。
System.out.println("更改之前 ----> " + modifyList.toString());//更改之前 ----> [you, are, boy]
//更改
modifyList.get(1).append("~~~~~");
System.out.println("更改之后 ----> " + modifyList.toString());//更改之后 ----> [you, are~~~~~, boy]
}
输出结果:
[you, are, boy, hello]
更改之前 —-> [you, are, boy]
更改之后 —-> [you, are~~~~~, boy]
1
2
3
三、错误情况的举例2
使用Arrays.asLisvt()后调用add,remove这些method时出现
原因:(摘自 :原文)
Arrays.asLisvt() 返回java.util.ArraysArrayList,而不是ArrayList。ArraysArrayList,而不是ArrayList。ArraysArrayList和ArrayList都是继承AbstractList,remove,add等method在AbstractList中是默认throw UnsupportedOperationException而且不作任何操作。ArrayList override这些method来对list进行操作,但是Arrays$ArrayList没有override remove(int),add(int)等,所以throw UnsupportedOperationException。
解决办法
和上面异常的处理一样,将引用操作转移到其他地方。
List list = Arrays.asList(fixArray[]);
List newList = new ArrayList(list);
2.2.5 finally代码块的执行情况
一、try里有return,finally怎么执行
finally块里的代码是在return之前执行的。
在异常处理中,无论是执行try还是catch,finally{}中的代码都会执行(除非特殊情况)。由于程序执行return就意味着结束对当前函数的调用并跳出这个函数体,因此任何语句要执行都只能在return前执行。
public class Test {
public static int testFinally() {
try {
return 1;
} catch (Exception ex) {
return 2;
} finally {
System.out.println(“execute finally”);
}
}
public static void main(String[] args) {
int result = testFinally();
System.out.println(result);
}
}
运行结果:
execute finally1
此外,如果try-catch-finally中都有return,那么finally块中的return将会覆盖别处的return语句,最终返回到调用者那里的是finally中return的值。
public class Test {
public static int testFinally() {
try {
return 1;
} catch (Exception ex) {
return 2;
} finally {
System.out.println(“execute finally”);
return 3;
}
}
public static void main(String[] args) {
int result = testFinally();
System.out.println(result);
}
}
运行结果:
execute finally3
return语句并不一定都是函数的出口,执行return时,只是把return后面的值复制了一份到返回值变量里去了。
此外,在try/catch中有return时,在finally块中改变基本类型的数据对返回值没有任何影响;而在finally中改变引用类型的数据会对返回结果有影响。
/**
- try/catch中有return,在finally{}中改变基本数据类型、引用类型对运行结果的影响
*/public class Test {
public static int testFinally1() {
int result1 = 1;
try {
return result1;
} catch (Exception ex) {
result1 = 2;
return result1;
} finally {
result1 = 3;
System.out.println(“execute testFinally1”);
}
}
public static StringBuffer testFinally2() {
StringBuffer result2 = new StringBuffer(“hello”);
try {
return result2;
} catch (Exception ex) {
return null;
} finally {
result2.append(“world”);
System.out.println(“execute testFinally2”);
}
}
public static void main(String[] args) {
int test1 = testFinally1();
System.out.println(test1);
StringBuffer test2 = testFinally2();
System.out.println(test2);
}
}
运行结果:
execute testFinally1
1
execute testFinally2
helloworld
程序在执行到return时会先将返回值存储在一个指定位置,其次去执行finally块,最会再return。
在finally块中改变基本类型的数据result1/引用类型数据result2的值,与java的值传递和引用传递相关。值传递中,形参和实参有着不同的存储单元,对形参的改变不会影响实参的值;引用传递中,传递的是对象的地址,形参和实参的对象指向同一块存储单元对形参的改变就会影响实参的值。
二、如果执行finally代码块之前方法返回了结果,或者JVM退出了,finally块中的代码还会执行吗//finally不会执行的情况
java程序中的finally块并不一定会被执行。
至少有两种情况finally语句是不会执行的。
(1)try语句没有被执行到。
即没有进入try代码块,对应的finally自然不会执行。
比如,在try语句之前return就返回了,这样finally不会执行;
或者在程序进入java之前就出现异常,会直接结束,也不会执行finally块。
(2)在try/catch块中有System.exit(0)来退出JVM。
System.exit(0)是终止JVM的,会强制退出程序,finally{}中的代码就不会被执行
2.2.7 既然我们可以用RuntimeException来处理错误,那么你认为为什么Java中还存在检查型异常?
这是一个有争议的问题,在回答该问题时你应当小心。虽然他们肯定愿意听到你的观点,但其实他们最感兴
趣的还是有说服力的理由。我认为其中一个理由是,存在检查型异常是一个设计上的决定,受到了诸如C++等比
Java更早的编程语言设计经验的影响。绝大多数检查型异常位于java.io包内,这是合乎情理的,因为在你请求了
不存在的系统资源的时候,一段强壮的程序必须能够优雅的处理这种情况。通过把IOException声明为检查型异
常,Java 确保了你能够优雅的对异常进行处理。另一个可能的理由是,可以使用catch或finally来确保数量受限
的系统资源(比如文件描述符)在你使用后尽早得到释放。
2.2.8
2.2.9
2.2.10
2.2 static
2.2.1 static class 与 non static class的区别
static class non static class
1、用static修饰的是内部类,此时这个
内部类变为静态内部类;对测试有用;
2、内部静态类不需要有指向外部类的引用;
3、静态类只能访问外部类的静态成员,不能访问外部类的非静态成员; 1、非静态内部类需要持有对外部类的引用;
2、非静态内部类能够访问外部类的静态和非静态成员;
3、一个非静态内部类不能脱离外部类实体被创建;
4、一个非静态内部类可以访问外部类的数据和方法;
2.2.2 static 关键字是什么意思?Java中是否可以覆盖(override)一个private或者是static的方法
Java中static方法不能被覆盖,因为方法覆盖是基于运行时动态绑定的,而static方法是编译时静态绑定的。static方法跟类的任何实例都不相关,所以概念上不适用。
java中也不可以覆盖private的方法,因为private修饰的变量和方法只能在当前类中使用,如果是其他的类继承当前类是不能访问到private变量或方法的,当然也不能覆盖。
2.2.3 main() 方法为什么必须是静态的?能不能声明 main() 方法为非静态
所有static成员都是在程序装载时初始化的,被分配在一块静态存储区域。
这个区域的成员一旦被分配,就不再改变地址啦。直到程序结束才释放。
main()就存储在这里。
尽管包含main()的类还没有被实例化,但是main()方法已经可以使用啦。
而且JVM将会自动调用这个方法。通过main()的调用,再实例化其他的对象,
也包括自己所在的类。
我们知道,在C/C++当中,这个main方法并不是属于某一个类的,它是一个全局的方法,所以当我们执行的时候,c++编译器很容易的就能找到这个main方法,然而当我们执行一个java程序的时候,因为java都是以类作为程序的组织单元,当我们要执行的时候,我们并不知道这个main方法会放到哪个类当中,也不知道是否是要产生类的一个对象,为了解决程序的运行问题,我们将这个main方法定义为static,这样的话,当我们在执行一个java代码的时候,我们在命令提示符中写:java Point(Point为一个类),解释器就会在Point这个类当中,去调用这个静态的main方法,而不需要产生Point这个类的对象,当我们加载Point这个类的时候,那么main方法也被加载了,作为我们java程序的一个入口。
2.2.4 是否可以从一个静态(static)方法内部发出对非静态(non-static)方法的调用
不可以,静态方法只能访问静态成员,因为非静态方法的调用要先创建对象,在调用静态方法时可能对象并没有被初始化
2.2.5 静态类型有什么特点
答案:1、随着类的加载而加载
也就是说:静态会随着类的消失而消失,说明他的生命周期最长
2、优先于对象存在
3、被所有对象所共享
4、可以直接被类名调用
2.2.6 静态变量在什么时候加载?编译期还是运行期?静态代码块加载的时机呢
当类加载器将类加载到JVM中的时候就会创建静态变量,这跟对象是否创建无关。静态变量加载的时候就会分配内存空间。静态代码块的代码只会在类第一次初始化的时候执行一次。一个类可以有多个静态代码块,它并不是类的成员,也没有返回值,并且不能直接调用。静态代码块不能包含this或者super,它们通常被用初始化静态变量。
2.2.7 成员方法是否可以访问静态变量?为什么静态方法不能访问成员变量
可以。static成员是在JVM的CLASSLOADER加载类的时候初始化的,而非static的成员是在创建对象,即new 操作的时候才初始化的;类加载的时候初始化static的成员,此时static 已经分配内存空间,所以可以访问;非static的成员还没有通过new创建对象而进行初始化,所以必然不可以访问。
简单点说:静态成员属于类,不需要生成对象就存在了.而非静态需要生成对象才产生,所以静态成员不能直接访问.
2.3 循环
2.3.1 switch switch 语句中的表达式可以是什么类型数据 switch 是否能作用在byte 上,是否能作用在long 上,是否能作用在String上
switch可作用于char byte short int
switch可作用于char byte short int对应的包装类
switch不可作用于long double float boolean,包括他们的包装类
switch中可以是字符串类型,String(jdk1.7之后才可以作用在string上)
switch中可以是枚举类型
2.3.2 while 循环和 do 循环有什么不同
do-while语句是一种后测试循环语句,即只有在循环体中的代码执行之后,才会测试出口条件。其实就是,代码在刚开始执行的时候,都是要先走一遍do循环体内的代码,然后在与while里面的条件进行判断,成立循环就一直继续下去,不成立就跳出循环。循环体内代码至少被执行一次。(肚子饿了,看到吃的先狂吃一顿,直到被发现了,就闭嘴停不吃了)
while语句是属于前测试循环语句,也就是说,在循环体内的代码被执行之前,就会对出口条件求值。其实就是先与while里面的条件进行判断,成立就走循环体内的代码,不成立就不走循环体内代码。循环体内的代码有可能永远不会执行。(肚子饿了,先问一下能不能吃东西,同意了就狂吃,直到不允许吃为止,不同意,就忍着忍着忍着不吃走了…)
2.4 数组
2.4.1 如何权衡是使用无序的数组还是有序的数组
2.4.2 怎么判断数组是 null 还是为空
2.4.3 怎么打印数组? 怎样打印数组中的重复元素
for(int i = 0;i<arr.length;i++){
for(int j = i+1;j<arr.length;j++){
if(arr[i] == arr[j]){
System.out.println(“有重负”);
break;
}
}
}
2.4.4 Array 和 ArrayList有什么区别?什么时候应该使用Array而不是ArrayList
不同点:Array 可以包含基本类型和对象类型,ArrayList 只能包含对象类型。
Array 大小是固定的,ArrayList 的大小是动态变化的。
ArrayList 提供了更多的方法和特性,比如:addAll(),removeAll(),iterator()等等。
对于基本类型数据,集合使用自动装箱来减少编码工作量。但是,当处理固定大小的基本数据类型的时候,这种方式相对比较慢。
2.4.5数组有没有length()这个方法? String有没有length()这个方法
2.5反射
2.5.1 什么是 Java 的反射机制
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;
对于任意一个对象,都能够调用它的任意一个方法和属性;
这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
要想解剖一个类,必须先要获取到该类的字节码文件对象。
而解剖使用的就是Class类中的方法,所以先要获取到每一个字节码文件对应的Class类型的对象。
2.5.2 获得类对象
第一种方式:通过类本身来获得对象
Java代码
Class classname =
this
.getClass();
第二种方式:通过子类的实例获取父类对象
Java代码
ClassName cn =
new
ClassName();
UserClass = cn.getClass();
Class SubUserClass = UserClass.getSuperclass();
第三种方式:通过类名加.class获取对象
Java代码
Class ForClass = ..ClassName.
class
;(类在包中的路径加.
class
)
第四种方式:通过类名的字符串获取对象
Java代码
Class ForName = Class.forName(
“..ClassName”
);
2.5.3 java反射机制提供了什么功能?
在运行时能够判断任意一个对象所属的类
在运行时判断任意一个类所具有的成员变量和方法
在运行时调用任一对象的方法、设置属性值
在运行时创建类对象
2.5.4 哪里用到反射机制?
jdbc中有一行代码:Class.forName(‘com.mysql.jdbc.Driver.class’).newInstance();那个时候只知道生成驱动对象实例,后来才知道,这就是反射,现在很多框架都用到反射机制,hibernate,struts都是用反射机制实现的。
2.5.5反射机制的优缺点?
静态编译:在编译时确定类型,绑定对象,即通过
优点:
动态编译:运行时确定类型,绑定对象。动态编译最大限度的发挥了java的灵活性,体现了多态的应用,有利于降低类之间的耦合性。
缺点:
它的缺点是对性能有影响。使用反射基本上是一种解释操作,我们可以告诉JVM,我们希望做什么并且它满足我们的要求。这类操作总是慢于只直接执行相同的操作。
2.5.6 反射中 Class.forName 和 ClassLoader 区别
java中class.forName()和classLoader都可用来对类进行加载。
class.forName()前者除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块。
而classLoader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
Class.forName(name, initialize, loader)带参函数也可控制是否加载static块。并且只有调用了newInstance()方法采用调用构造函数,创建类的对象
2.5.7 反射和泛型在项目中有没有使用到
反射:虽然各类框架,底层技术都大量使用了反射,但是直接使用的并不多,除非自己封装一些方法,自己做框架的时候
泛型:也是底层肯定大量使用,写的工具类,对外的参数List Map等可以考虑使用泛型,避免一些类型不一致的编译错误
2.6 GC
2.6.1 析构函数(finalization)的目的是什么 finalize()方法什么时候被调用 什么是finalize()方法
析构finalization,比如你在调用了一些native的方法,可以要在finaliztion里去调用释放函数
2.6.2什么是垃圾回收
垃圾回收是Java中自动内存管理的另一种叫法。垃圾回收的目的是为程序保持尽可能多的可用堆(heap)。 JVM会删除堆上不再需要从堆引用的对象。
2.6.3用一个例子解释垃圾回收
比方说,下面这个方法就会从函数调用。
void method(){
Calendar calendar = new GregorianCalendar(2000,10,30);
System.out.println(calendar);
}
1
2
3
4
通过函数第一行代码中参考变量calendar,在堆上创建了GregorianCalendar类的一个对象。
函数结束执行后,引用变量calendar不再有效。因此,在方法中没有创建引用到对象。
JVM认识到这一点,会从堆中删除对象。这就是所谓的垃圾回收。
2.6.4什么时候运行垃圾回收
运行垃圾收集的可能情况是:
(1)堆可用内存不足
(2)CPU空闲
2.6.5垃圾回收的最佳做法
用编程的方式,我们可以要求(记住这只是一个请求——不是一个命令)JVM通过调用System.gc()方法来运行垃圾回收。
当内存已满,且堆上没有对象可用于垃圾回收时,JVM可能会抛出OutOfMemoryException。
对象在被垃圾回收从堆上删除之前,会运行finalize()方法。我们建议不要用finalize()方法写任何代码。
1、标记-清除算法:
首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。标记过程中 实际上即时上面说的finaLize()的过程。主要缺点一个是效率问题。另外一个是空间问题,标记清除后会产生大量不连续的内存碎片。
2、复制算法:
这种算法将可用内存按容量划分为大小相等的两块,每次只使用其中的一块,当这一块的内存用完了。就将还存活着的对象复制到另外一块上面,然后再把已经使用过的内存空间一次清理掉。
3、标记-整理算法:
复制收集算法在对象存活率较高时就要执行较多的复制操作,效率将会遍低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以对应被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
标记过程仍然与标记-清除算法一样,但是后续步骤不是直接将对可回收对象进行清理,而是让所有存活的对象都向领一端移动,然后直接清理掉端边界以外的内存。
4、分代收集算法:
当代商业虚拟机的垃圾收集都采用的是“分代收集算法” ,根据对象的存活周期的不同,将内存化为几块,一般是把java堆分为新生代和老年代。这样就可以根据各个年代的特点采用最合适的收集算法。
新生代选用复制算法,老年代使用标记-清理算法 或者 标记-整理算法。
2.6.6 GC是什么?为什么要有GC
GC是垃圾收集的意思,内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,Java提供的GC功能可以自动监测对象是否超过作用域从而达到自动回收内存的目的,Java语言没有提供释放已分配内存的显示操作方法。Java程序员不用担心内存管理,因为垃圾收集器会自动进行管理。要请求垃圾收集,可以调用下面的方法之一:
System.gc() 或Runtime.getRuntime().gc() 。
垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存。垃圾回收器通常是作为一个单独的低优先级的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清除和回收,程序员不能实时的调用垃圾回收器对某个对象或所有对象进行垃圾回收。回收机制有分代复制垃圾回收、标记垃圾回收、增量垃圾回收等方式。
补充:标准的Java进程既有栈又有堆。栈保存了原始型局部变量,堆保存了要创建的对象。Java平台对堆内存回收和再利用的基本算法被称为标记和清除,但是Java对其进行了改进,采用“分代式垃圾收集”。这种方法会跟Java对象的生命周期将堆内存划分为不同的区域,在垃圾收集过程中,可能会将对象移动到不同区域:
伊甸园(Eden):这是对象最初诞生的区域,并且对大多数对象来说,这里是它们唯一存在过的区域。
幸存者乐园(Survivor):从伊甸园幸存下来的对象会被挪到这里。
终身颐养园(Tenured):这是足够老的幸存对象的归宿。年轻代收集(Minor-GC)过程是不会触及这个地方的。当年轻代收集不能把对象放进终身颐养园时,就会触发一次完全收集(Major-GC),这里可能还会牵扯到压缩,以便为大对象腾出足够的空间。
与垃圾回收相关的JVM参数:
-Xms / -Xmx — 堆的初始大小 / 堆的最大大小
-Xmn — 堆中年轻代的大小
-XX:-DisableExplicitGC — 让System.gc()不产生任何作用
-XX:+PrintGCDetail — 打印GC的细节
-XX:+PrintGCDateStamps — 打印GC操作的时间戳
2.6.7 什么时候会导致垃圾回收
首先需要知道,GC又分为minor GC 和 Full Gc(也称为Major GC)。Java 堆内存分为新生代和老年代,新生代中又分为1个Eden区域 和两个 Survivor区域。
那么对于 Minor GC 的触发条件:大多数情况下,直接在 Eden 区中进行分配。如果 Eden区域没有足够的空间,那么就会发起一次 Minor GC;对于 Full GC(Major GC)的触发条件:也是如果老年代没有足够空间的话,那么就会进行一次 Full GC。
Ps:上面所说的只是一般情况下,实际上,需要考虑一个空间分配担保的问题:
在发生Minor GC之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象的总空间。如果大于则进行Minor GC,如果小于则看HandlePromotionFailure设置是否允许担保失败(不允许则直接Full GC)。如果允许,那么会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于则尝试Minor GC(如果尝试失败也会触发Full GC),如果小于则进行Full GC。
但是,具体到什么时刻执行,这个是由系统来进行决定,是无法预测的。
2.6.8 JVM怎么判断对象可以回收了?
我们知道,GC 主要处理的是对象的回收操作,那么什么时候会触发一个对象的回收的呢?
1,对象没有引用
2,作用域发生未捕获异常
3,程序在作用域正常执行完毕
4,程序执行了System.exit()
5,程序发生意外终止(被杀进程等)
其实,我们最容易想到的就是当对象没有引用的时候会将这个对象标记为可回收对象,那么现在就有一个问题,是不是这个对象被赋值为空以后就一定被标记为可回收对象了呢?
并不是这个对象被赋值为空之后就一定被标记为可回收,有可能会发生逃逸!
2.6.9 引用的分类
1, 强引用
只要引用存在,垃圾回收器永远不会回收
Objectobj = new Object();
// 可直接通过物镜取得对应的对象如obj.equels(NEWOBJECT());
而这样 obj对象对后面newObject的一个强引用,只有当obj这个引用被释放之后,对象才会被释放掉,这也是我们经常所用到的编码形式。
2、 软引用
非必须引用,内存溢出之前进行回收,可以通过以下代码实现
Objectobj = new Object();
SoftReferencesf = new SoftReference(obj);
obj =null;
sf.get();//有时候会返回null
这时候sf是对obj的一个软引用,通过sf.get()方法可以取到这个对象,当然,当这个对象被标记为需要回收的对象时,则返回null;
软引用主要用户实现类似缓存的功能,在内存足够的情况下直接通过软引用取值,无需从繁忙的真实来源查询数据,提升速度;当内存不足时,自动删除这部分缓存数据,从真正的来源查询这些数据。
3、 弱引用
第二次垃圾回收时回收,可以通过如下代码实现
Objectobj = new Object();
WeakReferencewf = new WeakReference(obj);
obj =null;
wf.get();//有时候会返回null
wf.isEnQueued();//返回是否被垃圾回收器标记为即将回收的垃圾
弱引用是在第二次垃圾回收时回收,短时间内通过弱引用取对应的数据,可以取到,当执行过第二次垃圾回收时,将返回null。
弱引用主要用于监控对象是否已经被垃圾回收器标记为即将回收的垃圾,可以通过弱引用的isEnQueued方法返回对象是否被垃圾回收器
4、 虚引用(幽灵/幻影引用)
垃圾回收时回收,无法通过引用取到对象值,可以通过如下代码实现
Objectobj = new Object();
PhantomReferencepf = new PhantomReference(obj);
obj=null;
pf.get();//永远返回null
pf.isEnQueued();//返回从内存中已经删除
虚引用是每次垃圾回收的时候都会被回收,通过虚引用的get方法永远获取到的数据为null,因此也被成为幽灵引用。
虚引用主要用于检测对象是否已经从内存中删除。
2.6.10 方法区也是会被回收的条件
但是方法区的回收条件非常苛刻,只有同时满足以下三个条件才会被回收!
1、所有实例被回收
2、加载该类的ClassLoader被回收
3、Class对象无法通过任何途径访问(包括反射)
2.6.11 如果对象的引用被置为null,垃圾收集器是否会立即释放对象占用的内存?
垃圾收集器不会立即释放对象占用的内存,在下一个垃圾回收周期中,这个对象将是可被回收的。
2.6.12 Minor GC 、Major GC、 与 Full GC
Minor GC
从年轻代空间(包括 Eden 和 Survivor 区域)回收内存被称为 Minor GC。
当 JVM 无法为一个新的对象分配空间时会触发 Minor GC,比如当 Eden 区满了。所以分配率越高,越频繁执行 Minor GC。
内存池被填满的时候,其中的内容全部会被复制,指针会从0开始跟踪空闲内存。Eden 和 Survivor 区进行了标记和复制操作,
取代了经典的标记、扫描、压缩、清理操作。所以 Eden 和 Survivor 区不存在内存碎片。写指针总是停留在所使用内存池的顶部。
执行 Minor GC 操作时,不会影响到永久代。从永久代到年轻代的引用被当成 GC roots,从年轻代到永久代的引用在标记阶段被直接忽略掉。
质疑常规的认知,所有的 Minor GC 都会触发“全世界的暂停(stop-the-world)”,停止应用程序的线程。对于大部分应用程序,停顿导致的延迟都是可以忽略不计的。
其中的真相就 是,大部分 Eden 区中的对象都能被认为是垃圾,永远也不会被复制到 Survivor 区或者老年代空间。如果正好相反,Eden 区大部分新生对象不符合 GC 条件,Minor GC 执行时暂停的时间将会长很多。
Major GC 是清理永久代。
Full GC 是清理整个堆空间—包括年轻代和永久代。
2.6.13 垃圾回收器可以马上回收内存吗?有什么办法主动通知虚拟机进行垃圾回收?
1、对于GC来说,当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。
通常,GC采用有向图的方式记录和管理堆(heap)中的所有对象。通过这种方式确定哪些对象是”可达的”,哪些对象是”不可达的”。当GC确定一些对象为”不可达”时,GC就有责任回收这些内存空间。
2、可以。程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。
2.6.14 System.gc(); 与Runtime.gc()的区别
(1) GC是垃圾收集的意思(Gabage Collection),内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,Java提供的GC功能可以自动监测对象是否超过作用域从而达到自动回收内存的目的,Java语言没有提供释放已分配内存的显示操作方法。
(2) 对于GC来说,当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。通常,GC采用有向图的方式记录和管理堆(heap)中的所有对象。通过这种方式确定哪些对象是”可达的”,哪些对象是”不可达的”。当GC确定一些对象为”不可达”时,GC就有责任回收这些内存空间。可以。程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。
(3) 垃圾回收是一种动态存储管理技术,它自动地释放不再被程序引用的对象,当一个对象不再被引用的时候,按照特定的垃圾收集算法来实现资源自动回收的功能。
(4) System.gc();就是呼叫java虚拟机的垃圾回收器运行回收内存的垃圾。
(5) 当不存在对一个对象的引用时,我们就假定不再需要那个对象,那个对象所占有的存储单元可以被收回,可通过System.gc()方法回收,但一般要把不再引用的对象标志为null为佳。
(6) 每个 Java 应用程序都有一个 Runtime 类实例,使应用程序能够与其运行的环境相连接。可以通过 getRuntime 方法获取当前运行时。 Runtime.getRuntime().gc();
(7) java.lang.System.gc()只是java.lang.Runtime.getRuntime().gc()的简写,两者的行为没有任何不同。
(8) 唯一的区别就是System.gc()写起来比Runtime.getRuntime().gc()简单点. 其实基本没什么机会用得到这个命令, 因为这个命令只是建议JVM安排GC运行, 还有可能完全被拒绝。 GC本身是会周期性的自动运行的,由JVM决定运行的时机,而且现在的版本有多种更智能的模式可以选择,还会根据运行的机器自动去做选择,就算真的有性能上的需求,也应该去对GC的运行机制进行微调,而不是通过使用这个命令来实现性能的优化
2.6.15 怎样回收垃圾
标记-清除(Mark-Sweep)算法
分为两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。
缺点:效率问题,标记和清除两个过程的效率都不高;空间问题,会产生很多碎片。
复制算法
将可用内存按容量划分为大小相等的两块,每次只用其中一块。当这一块用完了,就将还存活的对象复制到另外一块上面,然后把原始空间全部回收。高效、简单。
缺点:将内存缩小为原来的一半。
标记-整理(Mark-Compat)算法
标记过程与标记-清除算法过程一样,但后面不是简单的清除,而是让所有存活的对象都向一端移动,然后直接清除掉端边界以外的内存。
分代收集(Generational Collection)算法
新生代中,每次垃圾收集时都有大批对象死去,只有少量存活,就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集;
老年代中,其存活率较高、没有额外空间对它进行分配担保,就应该使用“标记-整理”或“标记-清理”算法进行回收。
2.6.16 GC收集器有哪些
Serial收集器
单线程收集器,表示在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。“Stop The World”.
ParNew收集器
实际就是Serial收集器的多线程版本。
并发(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态;
并行(Concurrent):指用户线程与垃圾收集线程同时执行,用户程序在继续运行,而垃圾收集程序运行于另一个CPU上。
Parallel Scavenge收集器
该收集器比较关注吞吐量(Throughout)(CPU用于用户代码的时间与CPU总消耗时间的比值),保证吞吐量在一个可控的范围内。
CMS(Concurrent Mark Sweep)收集器
CMS收集器是一种以获得最短停顿时间为目标的收集器。
G1(Garbage First)收集器
从JDK1.7 Update 14之后的HotSpot虚拟机正式提供了商用的G1收集器,与其他收集器相比,它具有如下优点:并行与并发;分代收集;空间整合;可预测的停顿等。
本部分主要分析了三种不同的垃圾回收算法:Mark-Sweep, Copy, Mark-Compact. 每种算法都有不同的优缺点,也有不同的适用范围。而JVM中对垃圾回收器并没有严格的要求,不同的收集器会结合多个算法进行垃圾回收。
2.6.17 垃圾回收器的基本原理
GC是垃圾收集的意思(Gabage Collection),内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,Java提供的GC功能可以自动监测对象是否超过作用域从而达到自动回收内存的目的,Java语言没有提供释放已分配内存的显示操作方法。
垃圾回收的优点和原理。并考虑2种回收机制
Java语言中一个显著的特点就是引入了垃圾回收机制,使c++程序员最头疼的内存管理的问题迎刃而解,它使得Java程序员在编写程序的时候不再需要考虑内存管理。由于有个垃圾回收机制,Java中的对象不再有”作用域”的概念,只有对象的引用才有”作用域”。垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存。垃圾回收器通常是作为一个单独的低级别的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清楚和回收,程序员不能实时的调用垃圾回收器对某个对象或所有对象进行垃圾回收。回收机制有分代复制垃圾回收和标记垃圾回收,增量垃圾回收。
对于GC来说,当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。
通常,GC采用有向图的方式记录和管理堆(heap)中的所有对象。通过这种方式确定哪些对象是”可达的”,哪些对象是”不可达的”。当GC确定一些对象为”不可达”时,GC就有责任回收这些内存空间。可以。程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。
2.6.18垃圾回收算法的实现原理
引用计数
引用计数存储对特定对象的所有引用数,也就是说,当应用程序创建引用以及引用超出范围时,JVM必须适当增减引用数。当某对象的引用数为0时,便可以进行垃圾收集。
·对象引用遍历
早期的JVM使用引用计数,现在大多数JVM采用对象引用遍历。对象引用遍历从一组对象开始,沿着整个对象图上的每条链接,递归确定可到达(reachable)的对象。如果某对象不能从这些根对象的一个(至少一个)到达,则将它作为垃圾收集。在对象遍历阶段,gc必须记住哪些对象可以到达,以便删除不可到达的对象,这称为标记(marking)对象。下一步,gc要删除不可到达的对象。删除时,有些gc只是简单的扫描堆栈,删除未标记的对象,并释放它们的内存以生成新的对象,这叫做清除(sweeping)。这种方法的问题在于内存会分成好多小段,而它们不足以用于新的对象,但是组合起来却很大。因此,许多gc可以重新组织内存中的对象,并进行压缩(compact),形成可利用的空间。为此,gc需要停止其他的活动。这种方法意味着所有与应用程序相关的工作停止,只有gc运行。结果,在响应期间增减了许多混杂请求。另外,更复杂的 gc不断增加或同时运行以减少或者清除应用程序的中断。有的gc使用单线程完成这项工作,有的则采用多线程以增加效率。
Java语言没有提供释放已分配内存的显示操作方法。
程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行
2.6.19 串行(serial)收集器和吞吐量(throughput)收集器的区别是什么?
吞吐量收集器使用并行版本的新生代垃圾收集器,它用于中等规模和大规模数据的应用程序。而串行收集器对大多数的小应用(在现代处理器上需要大概100M左右的内存)就足够了。
串行GC:整个扫描和复制过程均采用单线程的方式,相对于吞吐量GC来说简单;适合于单CPU、客户端级别。
吞吐量GC:采用多线程的方式来完成垃圾收集;适合于吞吐量要求较高的场合,比较适合中等和大规模的应用程序。
2.6.20 Serial,Parallel,CMS,G1四大GC收集器特点小结
1.Serial收集器
一个单线程的收集器,在进行垃圾收集时候,必须暂停其他所有的工作线程直到它收集结束。
特点:CPU利用率最高,停顿时间即用户等待时间比较长。
适用场景:小型应用
通过JVM参数-XX:+UseSerialGC可以使用串行垃圾回收器。
2.Parallel收集器
采用多线程来通过扫描并压缩堆
特点:停顿时间短,回收效率高,对吞吐量要求高。
适用场景:大型应用,科学计算,大规模数据采集等。
通过JVM参数 XX:+USeParNewGC 打开并发标记扫描垃圾回收器。
3.CMS收集器
采用“标记-清除”算法实现,使用多线程的算法去扫描堆,对发现未使用的对象进行回收。
(1)初始标记
(2)并发标记
(3)并发预处理
(4)重新标记
(5)并发清除
(6)并发重置
特点:响应时间优先,减少垃圾收集停顿时间
适应场景:服务器、电信领域等。
通过JVM参数 -XX:+UseConcMarkSweepGC设置
4.G1收集器
在G1中,堆被划分成 许多个连续的区域(region)。采用G1算法进行回收,吸收了CMS收集器特点。
特点:支持很大的堆,高吞吐量
–支持多CPU和垃圾回收线程
–在主线程暂停的情况下,使用并行收集
–在主线程运行的情况下,使用并发收集
实时目标:可配置在N毫秒内最多只占用M毫秒的时间进行垃圾回收
通过JVM参数 –XX:+UseG1GC 使用G1垃圾回收器
2.6.21 CMS垃圾回收器的工作过程
1.总体介绍:
CMS(Concurrent Mark-Sweep)是以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器。对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。在启动JVM参数加上-XX:+UseConcMarkSweepGC ,这个参数表示对于老年代的回收采用CMS。CMS采用的基础算法是:标记—清除。
2.CMS过程:
初始标记(STW initial mark)
并发标记(Concurrent marking)
并发预清理(Concurrent precleaning)
重新标记(STW remark)
并发清理(Concurrent sweeping)
并发重置(Concurrent reset)
初始标记 :在这个阶段,需要虚拟机停顿正在执行的任务,官方的叫法STW(Stop The Word)。这个过程从垃圾回收的”根对象”开始,只扫描到能够和”根对象”直接关联的对象,并作标记。所以这个过程虽然暂停了整个JVM,但是很快就完成了。
并发标记 :这个阶段紧随初始标记阶段,在初始标记的基础上继续向下追溯标记。并发标记阶段,应用程序的线程和并发标记的线程并发执行,所以用户不会感受到停顿。
并发预清理 :并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段”重新标记”的工作,因为下一个阶段会Stop The World。
重新标记 :这个阶段会暂停虚拟机,收集器线程扫描在CMS堆中剩余的对象。扫描从”跟对象”开始向下追溯,并处理对象关联。
并发清理 :清理垃圾对象,这个阶段收集器线程和应用程序线程并发执行。
并发重置 :这个阶段,重置CMS收集器的数据结构,等待下一次垃圾回收。
CSM执行过程:
3.CMS缺点
CMS回收器采用的基础算法是Mark-Sweep。所有CMS不会整理、压缩堆空间。这样就会有一个问题:经过CMS收集的堆会产生空间碎片。 CMS不对堆空间整理压缩节约了垃圾回收的停顿时间,但也带来的堆空间的浪费。为了解决堆空间浪费问题,CMS回收器不再采用简单的指针指向一块可用堆空 间来为下次对象分配使用。而是把一些未分配的空间汇总成一个列表,当JVM分配对象空间的时候,会搜索这个列表找到足够大的空间来hold住这个对象。
需要更多的CPU资源。从上面的图可以看到,为了让应用程序不停顿,CMS线程和应用程序线程并发执行,这样就需要有更多的CPU,单纯靠线程切 换是不靠谱的。并且,重新标记阶段,为空保证STW快速完成,也要用到更多的甚至所有的CPU资源。当然,多核多CPU也是未来的趋势!
CMS的另一个缺点是它需要更大的堆空间。因为CMS标记阶段应用程序的线程还是在执行的,那么就会有堆空间继续分配的情况,为了保证在CMS回 收完堆之前还有空间分配给正在运行的应用程序,必须预留一部分空间。也就是说,CMS不会在老年代满的时候才开始收集。相反,它会尝试更早的开始收集,已 避免上面提到的情况:在回收完成之前,堆没有足够空间分配!默认当老年代使用68%的时候,CMS就开始行动了。 – XX:CMSInitiatingOccupancyFraction =n 来设置这个阀值。
总得来说,CMS回收器减少了回收的停顿时间,但是降低了堆空间的利用率。
4.啥时候用CMS
如果你的应用程序对停顿比较敏感,并且在应用程序运行的时候可以提供更大的内存和更多的CPU(也就是硬件牛逼),那么使用CMS来收集会给你带来好处。还有,如果在JVM中,有相对较多存活时间较长的对象(老年代比较大)会更适合使用CMS。
2.6.22 内存申请、对象衰老过程
一、内存申请过程
JVM会试图为相关Java对象在Eden中初始化一块内存区域;
当Eden空间足够时,内存申请结束。否则到下一步;
JVM试图释放在Eden中所有不活跃的对象(minor collection),释放后若Eden空间仍然不足以放入新对象,则试图将部分Eden中活跃对象放入Survivor区;
Survivor区被用来作为Eden及old的中间交换区域,当OLD区空间足够时,Survivor区的对象会被移到Old区,否则会被保留在Survivor区;
当old区空间不够时,JVM会在old区进行major collection;
完全垃圾收集后,若Survivor及old区仍然无法存放从Eden复制过来的部分对象,导致JVM无法在Eden区为新对象创建内存区域,则出现”Out of memory错误”;
二、对象衰老过程
新创建的对象的内存都分配自eden。Minor collection的过程就是将eden和在用survivor space中的活对象copy到空闲survivor space中。对象在young generation里经历了一定次数(可以通过参数配置)的minor collection后,就会被移到old generation中,称为tenuring。
GC触发条件
GC类型 触发条件 触发时发生了什么 注意 查看方式
YGC eden空间不足 清空Eden+from survivor中所有no ref的对象占用的内存
将eden+from sur中所有存活的对象copy到to sur中
一些对象将晋升到old中:
to sur放不下的
存活次数超过turning threshold中的
重新计算tenuring threshold(serial parallel GC会触发此项)
重新调整Eden 和from的大小(parallel GC会触发此项) 全过程暂停应用
是否为多线程处理由具体的GC决定 jstat –gcutil
gc log
FGC old空间不足
perm空间不足
显示调用System.GC, RMI等的定时触发
YGC时的悲观策略
dump live的内存信息时(jmap –dump:live) 清空heap中no ref的对象
permgen中已经被卸载的classloader中加载的class信息
如配置了CollectGenOFirst,则先触发YGC(针对serial GC)
如配置了ScavengeBeforeFullGC,则先触发YGC(针对serial GC) 全过程暂停应用
是否为多线程处理由具体的GC决定
是否压缩需要看配置的具体GC jstat –gcutil
gc log
permanent generation空间不足会引发Full GC,仍然不够会引发PermGen Space错误。
2.6.23 JVM的永久代中会发生垃圾回收吗
JVM的永久代中会发生垃圾回收么?
垃圾回收不会发生在永久代,如果永久代满了或者是超过了临界值,会触发完全垃圾回收(Full GC)。如果你仔细查看垃圾收集器的输出信息,就会发现永久代也是被回收的。这就是为什么正确的永久代大小对避免Full GC是非常重要的原因。请参考下Java8:从永久代到元数据区
(译者注:Java8中已经移除了永久代,新加了一个叫做元数据区的native内存区)
2.6.24 jvm中一次完整的GC流程是怎样的,对象如何晋升到老年代,
GC流程图
对象晋升老生代一共有三个可能:
1.当对象达到成年,经历过15次GC(默认15次,可配置),对象就晋升为老生代
2.大的对象会直接在老生代创建
3.新生代跟幸存区内存不足时,对象可能晋升到老生代
2.7 正则表达式
2.7.1 什么是正则表达式?用途是什么?哪个包使用正则表达式来实现模式匹配
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
Java1.4起,Java核心API就引入了java.util.regex程序包,它包括两个类:Pattern和Matcher.
Pattern是对正则表达式进行编译,得到正则表达式的表现模式。
Matcher利用Pattern得到的表现模式进行模式匹配。
Pattern类的方法简述
方法 说明
static Pettern compile(String regex,int flag) 编译模式,参数regex表示输入的正则表达式,flag表示模式类型(Pattern.CASE_INSENSITIVE 表示不区分大小写)
Matcher matcher(CharSequence input) 获取匹配器,input时输入的待处理的字符串
static boolean matches(String regex, CharSequence input) 快速的匹配调用,直接根据输入的模式regex匹配input
String[] split(CharSequence input,int limit) 分隔字符串input,limit参数可以限制分隔的次数
Matcher类的方法简述
方法 说明
boolean find() 查找模式匹配
String group() 获得匹配
String group(int number) 获得第number个的匹配
可在Pattern类中查看所有通配符含义
符号 含义 实例
? 子模式0次或1次
- 子模式0次或多次
- 子模式1次或多次
{n} n个字符 [abcd]{3}
{n,} 至少n个字符 [abcd]{3,}
{n,m} n到m个字符 [abcd]{3,5}
. 任何单个字符
-
连字符 a-z
\s 空白(空格符,换行符,回车符等)
\S 非空白
\d 数字字符
\D 非数字字符
\w 单词字符 [0-9A-Za-z]
\W 非单词字符
\ 转义符 * 匹配*
^上尖括号符 []表示非,表示起始符 [abd],[0-9]+[a-z]*
$ 表示结束符 1-[a-z]+$
[] 字符列表中的任意一个 [abc]匹配abc中任意一个
() 子表达式 (abc)匹配abc
| 或,与()进行组合 (ab|cd|ef)
dws
x 字符x
\ 反斜线字符
n 带有八进制值0的字符n(0 <= n <= 7)
nn 带有八进制值0的字符nn(0 <= n <= 7)
mnn 带有八进制值0的字符mnn(0 <= m <= 3、0 <= n <= 7)
xhh 带有十六进制值 0x的字符hh
uhhhh 带有十六进制值 0x的字符hhhh
t 制表符 (‘u0009’)
n 新行(换行)符 (‘u000A’)
r 回车符 (‘u000D’)
f 换页符 (‘u000C’)
a 报警 (bell) 符 (‘u0007’)
e 转义符 (‘u001B’)
cx 对应于x的控制符
[abc] a、b或c(简单类)
[^abc] 任何字符,除了a、b或c(否定)
[a-zA-Z] a到z或A到Z,两头的字母包括在内(范围)
[a-d[m-p]] a到d或m到p:[a-dm-p](并集)
[a-z&&[def]] d、e或f(交集)
[a-z&&[^bc]] a到z,除了b和c:[ad-z](减去)
[a-z&&[^m-p]] a到z,而非m到p:[a-lq-z](减去)
. 任何字符(与行结束符可能匹配也可能不匹配)
d 数字:[0-9]
D 非数字:[^0-9]
s 空白字符:[ tnx0Bfr]
S 非空白字符:[^s]
w 单词字符:[a-zA-Z_0-9]
W 非单词字符:[^w]
p{Lower} 小写字母字符:[a-z]
p{Upper} 大写字母字符:[A-Z]
p{ASCII} 所有 ASCII:[x00-x7F]
p{Alpha} 字母字符:[p{Lower}p{Upper}]
p{Digit} 十进制数字:[0-9]
p{Alnum} 字母数字字符:[p{Alpha}p{Digit}]
p{Punct} 标点符号:!”#$%&'()+,-./:;<=>?@[]^_`{|}~
p{Graph} 可见字符:[p{Alnum}p{Punct}]
p{Print} 可打印字符:[p{Graph}x20]
p{Blank} 空格或制表符:[ t]
p{Cntrl} 控制字符:[x00-x1Fx7F]
p{XDigit} 十六进制数字:[0-9a-fA-F]
p{Space} 空白字符:[ tnx0Bfr]
p{javaLowerCase} 等效于 java.lang.Character.isLowerCase()
p{javaUpperCase} 等效于 java.lang.Character.isUpperCase()
p{javaWhitespace} 等效于 java.lang.Character.isWhitespace()
p{javaMirrored} 等效于 java.lang.Character.isMirrored()
p{InGreek} Greek 块(简单块)中的字符
p{Lu} 大写字母(简单类别)
p{Sc} 货币符号
P{InGreek} 所有字符,Greek 块中的除外(否定)
[p{L}&&[^p{Lu}]] 所有字母,大写字母除外(减去)
^ 行的开头
$ 行的结尾
b 单词边界
B 非单词边界
A 输入的开头
G 上一个匹配的结尾
Z 输入的结尾,仅用于最后的结束符(如果有的话)
z 输入的结尾
X? X,一次或一次也没有
X X,零次或多次
X+ X,一次或多次
X{n} X,恰好n次
X{n,} X,至少n次
X{n,m} X,至少n次,但是不超过m次
X?? X,一次或一次也没有
X*? X,零次或多次
X+? X,一次或多次
X{n}? X,恰好n次
X{n,}? X,至少n次
X{n,m}? X,至少n次,但是不超过m次
X?+ X,一次或一次也没有
X*+ X,零次或多次
X++ X,一次或多次
X{n}+ X,恰好n次
X{n,}+ X,至少n次
X{n,m}+ X,至少n次,但是不超过m次
XY X后跟Y
X|Y X或Y
(X) X,作为捕获组
n 任何匹配的nth捕获组
Nothing,但是引用以下字符
Q Nothing,但是引用所有字符,直到E
E Nothing,但是结束从Q开始的引用
(?:X) X,作为非捕获组
(?idmsux-idmsux) Nothing,但是将匹配标志idmsux on – off
(?idmsux-idmsux:X) X,作为带有给定标志idmsux on – off
(?=X) X,通过零宽度的正 lookahead
(?!X) X,通过零宽度的负 lookahead
(?<=X) X,通过零宽度的正 lookbehind
(?<!X) X,通过零宽度的负 lookbehind
(?>X) X,作为独立的非捕获组提供更强大的字符串处理能力,测试字符串内的模式,例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或身份证号码模式。即数据验证替换文本可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。
基于模式匹配从字符串中提取子字符串可以查找文档内或输入域内特定的文本。
在Java中使用正则表达式
正则表达式在字符串处理上有着强大的功能,sun在jdk1.4加入了对它的支持,jdk1.4中加入了java.util.regex包提供对正则表达式的支持。而且Java.lang.String类中的replaceAll和split函数也是调用的正则表达式来实现的。
正则表达式对字符串的操作主要包括:
1.字符串匹配
2.指定字符串替换
3.指定字符串查找
4.字符串分割
2.8 序列化
2.8.1 概念
序列化是将对象状态转换为可保持或传输的格式的过程。说明白点就是你可以用对象输出流输出到文件.如果不序列化输出的话.很可能会乱!
实现方式是实现java.io.Serializable接口.这个接口不需要实现任何具体方法.只要implements java.io.Serializable 就好了
java中的序列化机制能够将一个实例对象(只序列化对象的属性值,而不会去序列化什么所谓的方法。)的状态信息写入到一个字节流中使其可以通过socket进行传输、或者持久化到存储数库或文件系统中;然后在需要的时候通过字节流中的信息来重构一个相同的对象。
一般而言,要使得一个类可以序列化,只需简单实现java.io.Serializable接口即可。
2.8.2 分类
一.Java序列化的作用
有的时候我们想要把一个Java对象变成字节流的形式传出去,有的时候我们想要从一个字节流中恢复一个Java对象。例如,有的时候我们想要
把一个Java对象写入到硬盘或者传输到网路上面的其它计算机,这时我们就需要自己去通过java把相应的对象写成转换成字节流。对于这种通用
的操作,我们为什么不使用统一的格式呢?没错,这里就出现了java的序列化的概念。在Java的OutputStream类下面的子类ObjectOutput-
Stream类就有对应的WriteObject(Object object) 其中要求对应的object实现了java的序列化的接口。
为了更好的理解java序列化的应用,我举两个自己在开发项目中遇到的例子:
1)在使用tomcat开发JavaEE相关项目的时候,我们关闭tomcat后,相应的session中的对象就存储在了硬盘上,如果我们想要在tomcat重启的
时候能够从tomcat上面读取对应session中的内容,那么保存在session中的内容就必须实现相关的序列化操作。
2)如果我们使用的java对象要在分布式中使用或者在rmi远程调用的网络中使用的话,那么相关的对象必须实现java序列化接口。
亲爱的小伙伴,大概你已经了解了java序列化相关的作用,接下来们来看看如何实现java的序列化吧。~
二.实现java对象的序列化和反序列化。
Java对象的序列化有两种方式。
a.是相应的对象实现了序列化接口Serializable,这个使用的比较多,对于序列化接口Serializable接口是一个空的接口,它的主要作用就是
标识这个对象时可序列化的,jre对象在传输对象的时候会进行相关的封装。这里就不做过多的介绍了。
下面是一个实现序列化接口的Java序列化的例子:非常简单
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
public class Article implements java.io.Serializable {
private static final long serialVersionUID = 1L;
private Integer id;
private String title; //文章标题
private String content; // 文章内容
private String faceIcon;//表情图标
private Date postTime; //文章发表的时间
private String ipAddr; //用户的ip
private User author; //回复的用户
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getFaceIcon() {
return faceIcon;
}
public void setFaceIcon(String faceIcon) {
this.faceIcon = faceIcon;
}
public Date getPostTime() {
return postTime;
}
public void setPostTime(Date postTime) {
this.postTime = postTime;
}
public User getAuthor() {
return author;
}
public void setAuthor(User author) {
this.author = author;
}
public String getIpAddr() {
return ipAddr;
}
public void setIpAddr(String ipAddr) {
this.ipAddr = ipAddr;
}
}
b.实现序列化的第二种方式为实现接口Externalizable,Externlizable的部分源代码如下:
1
2
3
4
5
6
7
8 * @see java.io.ObjectInput
- @see java.io.Serializable
- @since JDK1.1
/
public interface Externalizable extends java.io.Serializable {
/*- The object implements the writeExternal method to save its contents
- by calling the methods of DataOutput for its primitive values or
没错,Externlizable接口继承了java的序列化接口,并增加了两个方法:
void writeExternal(ObjectOutput out) throws IOException;
void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
首先,我们在序列化对象的时候,由于这个类实现了Externalizable 接口,在writeExternal()方法里定义了哪些属性可以序列化,
哪些不可以序列化,所以,对象在经过这里就把规定能被序列化的序列化保存文件,不能序列化的不处理,然后在反序列的时候自动调
用readExternal()方法,根据序列顺序挨个读取进行反序列,并自动封装成对象返回,然后在测试类接收,就完成了反序列。
所以说Exterinable的是Serializable的一个扩展。
为了更好的理解相关内容,请看下面的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141 /**
-
测试实体类
-
@author 小浩
-
@创建日期 2015-3-12
*/
class Person implements Externalizable{
private static final long serialVersionUID = 1L;
String userName;
String password;
String age;public Person(String userName, String password, String age) {
super();
this.userName = userName;
this.password = password;
this.age = age;
}public Person() {
super();
}public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}/**
- 序列化操作的扩展类
*/
@Override
public void writeExternal(ObjectOutput out) throws IOException {
//增加一个新的对象
Date date=new Date();
out.writeObject(userName);
out.writeObject(password);
out.writeObject(date);
}
/**
- 反序列化的扩展类
*/
@Override
public void readExternal(ObjectInput in) throws IOException,
ClassNotFoundException {
//注意这里的接受顺序是有限制的哦,否则的话会出错的
// 例如上面先write的是A对象的话,那么下面先接受的也一定是A对象…
userName=(String) in.readObject();
password=(String) in.readObject();
SimpleDateFormat sdf=new SimpleDateFormat(“yyyy-MM-dd”);
Date date=(Date)in.readObject();
System.out.println(“反序列化后的日期为:”+sdf.format(date));
}
@Override
public String toString() {
//注意这里的年龄是不会被序列化的,所以在反序列化的时候是读取不到数据的
return “用户名:”+userName+“密 码:”+password+“年龄:”+age;
}
} - 序列化操作的扩展类
/**
-
序列化和反序列化的相关操作类
-
@author 小浩
-
@创建日期 2015-3-12
/
class Operate{
/*- 序列化方法
- @throws IOException
- @throws FileNotFoundException
*/
public void serializable(Person person) throws FileNotFoundException, IOException{
ObjectOutputStream outputStream=new ObjectOutputStream(new FileOutputStream(“a.txt”));
outputStream.writeObject(person);
}
/**
- 反序列化的方法
- @throws IOException
- @throws FileNotFoundException
- @throws ClassNotFoundException
*/
public Person deSerializable() throws FileNotFoundException, IOException, ClassNotFoundException{
ObjectInputStream ois=new ObjectInputStream(new FileInputStream(“a.txt”));
return (Person) ois.readObject();
}
}
/**
- 测试实体主类
- @author 小浩
- @创建日期 2015-3-12
*/
public class Test{
public static void main(String[] args) throws FileNotFoundException, IOException, ClassNotFoundException {
Operate operate=new Operate();
Person person=new Person(“小浩”,“123456”,“20”);
System.out.println(“为序列化之前的相关数据如下:\n”+person.toString());
operate.serializable(person);
Person newPerson=operate.deSerializable();
System.out.println(“——————————————————-”);
System.out.println(“序列化之后的相关数据如下:\n”+newPerson.toString());
}
}
首先,我们在序列化UserInfo对象的时候,由于这个类实现了Externalizable 接口,在writeExternal()方法里定义了哪些属性可
以序列化,哪些不可以序列化,所以,对象在经过这里就把规定能被序列化的序列化保存文件,不能序列化的不处理,然后在反序列
的时候自动调用readExternal()方法,根据序列顺序挨个读取进行反序列,并自动封装成对象返回,然后在测试类接收,就完成了反
序列。
***对于实现Java的序列化接口需要注意一下几点:
1.java中的序列化时transient变量(这个关键字的作用就是告知JAVA我不可以被序列化)和静态变量不会被序列
化(下面是一个测试的例子)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44 import java.io.*;
class Student1 implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private transient String password;
private static int count = 0;
public Student1(String name, String password) {
System.out.println("调用Student的带参的构造方法");
this.name = name;
this.password = password;
count++;
}
public String toString() {
return "人数: " + count + " 姓名: " + name + " 密码: " + password;
}
}
public class ObjectSerTest1 {
public static void main(String args[]) {
try {
FileOutputStream fos = new FileOutputStream(“test.obj”);
ObjectOutputStream oos = new ObjectOutputStream(fos);
Student1 s1 = new Student1(“张三”, “12345”);
Student1 s2 = new Student1(“王五”, “54321”);
oos.writeObject(s1);
oos.writeObject(s2);
oos.close();
FileInputStream fis = new FileInputStream(“test.obj”);
ObjectInputStream ois = new ObjectInputStream(fis);
Student1 s3 = (Student1) ois.readObject();
Student1 s4 = (Student1) ois.readObject();
System.out.println(s3);
System.out.println(s4);
ois.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e1) {
e1.printStackTrace();
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34 import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class Test{
public static void main(String args[]){
try {
FileInputStream fis = new FileInputStream("test.obj");
ObjectInputStream ois = new ObjectInputStream(fis);
Student1 s3 = (Student1) ois.readObject();
Student1 s4 = (Student1) ois.readObject();
System.out.println(s3);
System.out.println(s4);
ois.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e1) {
e1.printStackTrace();
}
}
}
2.也是最应该注意的,如果你先序列化对象A后序列化B,那么在反序列化的时候一定记着JAVA规定先读到的对象
是先被序列化的对象,不要先接收对象B,那样会报错.尤其在使用上面的Externalizable的时候一定要注意读取
的先后顺序。
3.实现序列化接口的对象并不强制声明唯一的serialVersionUID,是否声明serialVersionUID对于对象序列化的向
上向下的兼容性有很大的影响。我们来做个测试:
思路一
把User中的serialVersionUID去掉,序列化保存。反序列化的时候,增加或减少个字段,看是否成功。
Java代码
1
2
3
4
5
6
7
8
9
10
11 public class User implements Serializable{
private String name;
private int age;
private long phone;
private List friends;
…
}
保存到文件中:
1
2
3
4
5
6
7
8
9
10
11 Java代码
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream os = new ObjectOutputStream(bos);
os.writeObject(src);
os.flush();
os.close();
byte[] b = bos.toByteArray();
bos.close();
FileOutputStream fos = new FileOutputStream(dataFile);
fos.write(b);
fos.close();
增加或者减少字段后,从文件中读出来,反序列化:
1
2
3
4
5
6
7
8
9
10
11 Java代码
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream os = new ObjectOutputStream(bos);
os.writeObject(src);
os.flush();
os.close();
byte[] b = bos.toByteArray();
bos.close();
FileOutputStream fos = new FileOutputStream(dataFile);
fos.write(b);
fos.close();
结果:抛出异常信息
Java代码
1
2
3
4
5
6
7
8 Exception in thread “main” java.io.InvalidClassException: serialize.obj.UserVo; local class incompatible: stream classdesc serialVersionUID = 3305402508581390189, local class serialVersionUID = 7174371419787432394 at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:560)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1582)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1495)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1731)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1328)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:350)
at serialize.obj.ObjectSerialize.read(ObjectSerialize.java:74)
at serialize.obj.ObjectSerialize.main(ObjectSerialize.java:27)
思路二
eclipse指定生成一个serialVersionUID,序列化保存,修改字段后反序列化
略去代码
结果:反序列化成功
结论
如果没有明确指定serialVersionUID,序列化的时候会根据字段和特定的算法生成一个serialVersionUID,当属性有变化时这个id发生了变化,所以反序列化的时候
就会失败。抛出“本地classd的唯一id和流中class的唯一id不匹配”。
jdk文档关于serialVersionUID的描述:
写道
如果可序列化类未显式声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值,如“Java™ 对象序列化规范”中所述。不过,强烈建议 所有可序列化类都显式声明 serialVersionUID 值,原因是计算默认的 serialVersionUID 对类的详细信息具有较高的敏感性,根据编译器实现的不同可能千差万别,这样在反序列化过程中可能会导致意外的 InvalidClassException。因此,为保证 serialVersionUID 值跨不同 java 编译器实现的一致性,序列化类必须声明一个明确的 serialVersionUID 值。还强烈建议使用 private 修饰符显示声明 serialVersionUID(如果可能),原因是这种声明仅应用于直接声明类 – serialVersionUID 字段作为继承成员没有用处。数组类不能声明一个明确的 serialVersionUID,因此它们总是具有默认的计算值,但是数组类没有匹配 serialVersionUID 值的要求。
三.实现序列化的其它方式 (这是一个扩展内容,感兴趣的可以扩展一下)
1)是把对象包装成JSON字符串传输。
这里采用JSON格式同时使用采用Google的gson-2.2.2.jar 进行转义
2)采用谷歌的ProtoBuf
随着Google工具protoBuf的开源,protobuf也是个不错的选择。对JSON,Object Serialize(Java的序列化和反序列化),
ProtoBuf 做个对比。
定义一个通用的待传输的对象UserVo:
1
2
3
4
5
6
7
8 public class User
private static final long serialVersionUID = -5726374138698742258L;
{ private String name;
private int age;
private long phone;
private List friends;
…set和get方法
}
初始化User的实例src:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Java代码
User user1 = new UserVo();
user1 .setName(“user1 “);
user1 .setAge(30);
user1 .setPhone(13789126278L);
UserVo f1 = new UserVo();
f1.setName(“tmac”);
f1.setAge(32);
f1.setPhone(123L);
User user2 = new User();
user2 .setName(“user2 “);
user2 .setAge(29);
user2 .setPhone(123L);
List friends = new ArrayList();
friends.add(user1 );
friends.add(user2 );
user1 .setFriends(friends);
1.首先使用JOSN来实现序列化。
1
2 Java代码
Gson gson = new Gson();
String json = gson.toJson(src);
得到的字符串:
1
2
3 Js代码
{“name”:”user1 “,“age”:30,“phone”:123,“friends”:[{“name”:”user1 “,“age”:32,“phone”:123},{“name”:”user2 “,“age”:29,“phone”:123}]}
字节数为153
Json的优点:明文结构一目了然,可以跨语言,属性的增加减少对解析端影响较小。缺点:字节数过多,依赖于不同的第三方类库。
Object Serialize(Java的序列化和反序列化)
UserVo实现Serializalbe接口,提供唯一的版本号:
序列化方法:
Java代码
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream os = new ObjectOutputStream(bos);
os.writeObject(src);
os.flush();
os.close();
byte[] b = bos.toByteArray();
bos.close();
字节数是238
反序列化:
Java代码
ObjectInputStream ois = new ObjectInputStream(fis);
vo = (UserVo) ois.readObject();
ois.close();
fis.close();
Object Serializalbe 优点:java原生支持,不需要提供第三方的类库,使用比较简单。
缺点:无法跨语言,字节数占用比较大,某些情况下对于对象属性的变化比较敏感。
对象在进行序列化和反序列化的时候,必须实现Serializable接口,但并不强制声明唯一的serialVersionUID
是否声明serialVersionUID对于对象序列化的向上向下的兼容性有很大的影响。
Google ProtoBuf
protocol buffers 是google内部得一种传输协议,目前项目已经开源(http://code.google.com/p/protobuf/)。
它定义了一种紧凑得可扩展得二进制协议格式,适合网络传输,并且针对多个语言有不同得版本可供选择。
以protobuf-2.5.0rc1为例,准备工作:
下载源码,解压,编译,安装
Shell代码
tar zxvf protobuf-2.5.0rc1.tar.gz ./configure ./make ./make install
测试:
Shell代码
MacBook-Air:~ ming$ protoc –version libprotoc 2.5.0
安装成功!
进入源码得java目录,用mvn工具编译生成所需得jar包,protobuf-java-2.5.0rc1.jar
1、编写.proto文件,命名UserVo.proto
1
2
3
4
5
6
7
8
9
10
11
12 Text代码
package serialize;
option java_package = “serialize”;
option java_outer_classname=“UserVoProtos”;
message User{
optional string name = 1;
optional int32 age = 2;
optional int64 phone = 3;
repeated serialize.UserVo friends = 4;
}
2、在命令行利用protoc 工具生成builder类
Shell代码
protoc -IPATH=.proto文件所在得目录 –java_out=java文件的输出路径 .proto的名称
得到UserProtos类
3、编写序列化代码
1
2
3
4
5
6
7
8
9
10
11
12 Java代码
UserVoProtos.User.Builder builder = UserVoProtos.User.newBuilder();
builder.setName(“Yaoming”); builder.setAge(30);
builder.setPhone(13789878978L);
UserVoProtos.UserVo.Builder builder1 = UserVoProtos.UserVo.newBuilder();
builder1.setName(“tmac”); builder1.setAge(32); builder1.setPhone(138999898989L);
UserVoProtos.UserVo.Builder builder2 = UserVoProtos.UserVo.newBuilder();
builder2.setName(“liuwei”); builder2.setAge(29); builder2.setPhone(138999899989L);
builder.addFriends(builder1);
builder.addFriends(builder2);
UserVoProtos.UserVo vo = builder.build(); byte[] v = vo.toByteArray();
字节数53
反序列化
1
2
3 Java代码
UserVoProtos.UserVo uvo = UserVoProtos.UserVo.parseFrom(dstb);
System.out.println(uvo.getFriends(0).getName());
结果:tmac,反序列化成功
google protobuf 优点:字节数很小,适合网络传输节省io,跨语言 。
缺点:需要依赖于工具生成代码。
工作机制
proto文件是对数据的一个描述,包括字段名称,类型,字节中的位置。protoc工具读取proto文件生成对应builder代码的类库。protoc xxxxx –java_out=xxxxxx 生成java类库。builder类根据自己的算法把数据序列化成字节流,或者把字节流根据反射的原理反序列化成对象。官方的示例:https://developers.google.com/protocol-buffers/docs/javatutorial。
proto文件中的字段类型和java中的对应关系:
详见:https://developers.google.com/protocol-buffers/docs/proto
.proto Type java Type c++ Type
double double double
float float float
int32 int int32
int64 long int64
uint32 int uint32
unint64 long uint64
sint32 int int32
sint64 long int64
fixed32 int uint32
fixed64 long uint64
sfixed32 int int32
sfixed64 long int64
bool boolean bool
string String string
bytes byte string
字段属性的描述:
写道
required: a well-formed message must have exactly one of this field. optional: a well-formed message can have zero or one of this field (but not more than one). repeated: this field can be repeated any number of times (including zero) in a well-formed message. The order of the repeated values will be preserved.
protobuf 在序列化和反序列化的时候,是依赖于.proto文件生成的builder类完成,字段的变化如果不表现在.proto文件中就不会影响反序列化,比较适合字段变化的情况。
做个测试:把UserVo序列化到文件中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 Java代码
UserProtos.User vo = builder.build();
byte[] v = vo.toByteArray();
FileOutputStream fos = new FileOutputStream(dataFile);
fos.write(vo.toByteArray());
fos.close();
为User增加字段,对应的.proto文件:
Text代码
package serialize;
option java_package = “serialize”;
option java_outer_classname=“UserVoProtos”;
message User{
optional string name = 1;
optional int32 age = 2;
optional int64 phone = 3;
repeated serialize.UserVo friends = 4;
optional string address = 5; }
从文件中反序列化回来:
Java代码
FileInputStream fis = new FileInputStream(dataFile);
byte[] dstb = new byte[fis.available()];
for(int i=0;i<dstb.length;i++){ dstb[i] = (byte)fis.read(); }
fis.close(); UserProtos.User uvo = UserProtos.User.parseFrom(dstb);
System.out.println(uvo.getFriends(0).getName());
成功得到结果。
三种方式对比传输同样的数据,google protobuf只有53个字节是最少的。结论:
方式 优点 缺点
JSON 跨语言、格式清晰一目了然 字节数比较大,需要第三方类库
Object Serialize java原生方法不依赖外部类库 字节数比较大,不能跨语言
Google protobuf 跨语言、字节数比较少 编写.proto配置用protoc工具生成对应的代码
2.8.3. Serializable 与 Externalizable 的区别
1、Serializable序列化时不会调用默认的构造器,而Externalizable序列化时会调用默认构造器的!!!
2、Serializable:一个对象想要被序列化,那么它的类就要实现 此接口,这个对象的所有属性(包括private属性、包括其引用的对象)都可以被序列化和反序列化来保存、传递。
Externalizable:他是Serializable接口的子类,有时我们不希望序列化那么多,可以使用这个接口,这个接口的writeExternal()和readExternal()方法可以指定序列化哪些属性。
注意:
对象的序列化并不属于新的Reader和Writer层次结构的一部分,而是沿用老式的InputStream和OutputStream结构,在某些情况下,不得不混合使用两种类型的层次结构。
恢复了一个反序列化的对象后,如果想对其做更多的事情(对象.getClass().xxx),必须保证JVM能在本地类路径或者因特网的其他什么地方找到相关的.class文件。
恢复对象的默认构建器必须是public的,否则会抛异常。
由于Externalizable对象默认时不保存对象的任何字段,所以transient关键字只能伴随Serializable使用,虽然Externalizable对象中使用transient关键字也不报错,但不起任何作用。
2.8.4transient变量有什么特点
我们都知道一个对象只要实现了Serilizable接口,这个对象就可以被序列化,java的这种序列化模式为开发者提供了很多便利,我们可以不必关系具体序列化的过程,只要这个类实现了Serilizable接口,这个类的所有属性和方法都会自动序列化。
然而在实际开发过程中,我们常常会遇到这样的问题,这个类的有些属性需要序列化,而其他属性不需要被序列化,打个比方,如果一个用户有一些敏感信息(如密码,银行卡号等),为了安全起见,不希望在网络操作(主要涉及到序列化操作,本地序列化缓存也适用)中被传输,这些信息对应的变量就可以加上transient关键字。换句话说,这个字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。
1)一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问。
2)transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
3)被transient关键字修饰的变量不再能被序列化,一个静态变量不管是否被transient修饰,均不能被序列化。
2.9 包装类
2.9.1 int 和 Integer 哪个会占用更多的内存? int 和 Integer 有什么区别?parseInt()函数在什么时候使用到
Integer占用更多的内存.
int是一个基本数据类型,可以用来接收整数常量和变量.
Integer是一个引用数据类型,可以接收整数对象
将数值型字符转换为数字使用parseInt()
2.9.2 4:为什么128 == 128返回为False,而127 == 127会返回为True?
JDK1.5后就会自动装箱和拆箱
–地址值问题(如127的和128是否是同一地址值)
JVM会自动维护八种基本类型的常量池,int常量池中初始化-128~127的范围,所以当为Integer i=127时,在自动装箱过程中是取自常量池中的数值,而当Integer i=128时,128不在常量池范围内,所以在自动装箱过程中需new 128,所以地址不一样。
总结:这就归结于java对于Integer与int的自动装箱与拆箱的设计,是一种模式:叫享元模式(flyweight)
为了加大对简单数字的重利用,java定义:在自动装箱时对于值从–128到127之间的值,它们被装箱为Integer对象后,会存在内存中被重用,始终只存在一个对象
而如果超过了从–128到127之间的值,被装箱后的Integer对象并不会被重用,即相当于每次装箱时都新建一个 Integer对象(还是需要用equals来比较,已经重写);
以上的现象是由于使用了自动装箱所引起的,如果你没有使用自动装箱,而是跟一般类一样,用new来进行实例化,就会每次new就都一个新的对象;
3.0 泛型
3.0.1 泛型的作用
java 泛型是java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。
泛型(Generic type 或者 generics)是对 Java 语言的类型系统的一种扩展,以支持创建可以按类型进行参数化的类。可以把类型参数看作是使用参数化类型时指定的类型的一个占位符,就像方法的形式参数是运行时传递的值的占位符一样。
Java 语言中引入泛型是一个较大的功能增强。不仅语言、类型系统和编译器有了较大的变化,以支持泛型,而且类库也进行了大翻修,所以许多重要的类,比如集合框架,都已经成为泛型化的了。
这带来了很多好处:
1,类型安全。 泛型的主要目标是提高 Java 程序的类型安全。通过知道使用泛型定义的变量的类型限制,编译器可以在一个高得多的程度上验证类型假设。没有泛型,这些假设就只存在于程序员的头脑中(或者如果幸运的话,还存在于代码注释中)。
2,消除强制类型转换。 泛型的一个附带好处是,消除源代码中的许多强制类型转换。这使得代码更加可读,并且减少了出错机会。
3,潜在的性能收益。 泛型为较大的优化带来可能。在泛型的初始实现中,编译器将强制类型转换(没有泛型的话,程序员会指定这些强制类型转换)插入生成的字节码中。但是更多类型信息可用于编译器这一事实,为未来版本的 JVM 的优化带来可能。由于泛型的实现方式,支持泛型(几乎)不需要 JVM 或类文件更改。所有工作都在编译器中完成,编译器生成类似于没有泛型(和强制类型转换)时所写的代码,只是更能确保类型安全而已。
Java语言引入泛型的好处是安全简单。泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
泛型在使用中还有一些规则和限制:
1、泛型的类型参数只能是类类型(包括自定义类),不能是简单类型。
2、同一种泛型可以对应多个版本(因为参数类型是不确定的),不同版本的泛型类实例是不兼容的。
3、泛型的类型参数可以有多个。
4、泛型的参数类型可以使用extends语句,例如。习惯上成为“有界类型”。
5、泛型的参数类型还可以是通配符类型。例如Class<?> classType = Class.forName(Java.lang.String);
3.0.2 泛型的特点
java中的泛型只是在程序源码中存在,在编译后的字节码文件中,就已经替换为原来的原生类型(Raw Type,也成为裸类型),并且在相应的地方插入了强制转换代码,因此对于运行期的Java语言来讲,所有的泛型容器都是一样的,泛型技术实际上是Java的一颗语法糖,Java语言的泛型实际方法称为类型擦除,基于这种方法实现的泛型称为伪泛型。
3.1 volatile
3.1.1什么是volatile修饰符?
volatile关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,
比如:操作系统、硬件或者其他线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,
从而可以提供对特殊地址的稳定访问。
volatile 影响编译器编译的结果。volatile变量是随时可能发生变化的,与volatile变量有关的运算,不进行编译优化。如:
[cpp] view plain copy
1.volatile int i=10;
2.int j = i;
3.…
4.…
5.int k = i;
不优化的方式:编译器生成的可执行码会重新从i的地址读取数据放在k中
优化的方式:由于编译器发现两次从i读数据的代码之间的代码没有对i进行过操作,它会自动把上次读的数据放在k中。
也就是说:volatile 告诉编译器i是随时可能发生变化的,每次使用它的时候必须从i的地址中读取,因而编译器生成的可执行码会重新从i的地址读取数据放在k中。
而优化做法是,由于编译器发现两次从i读数据的代码之间的代码没有对i进行过操作,它会自动把上次读的数据放在k中。而不是重新从i里面读。这样以来,如果i是一个寄存器变量或者表示一个端口数据就容易出错,所以说volatile可以保证对特殊地址的稳定访问,不会出错。
3.1.2在何时使用volatile?
volatile:”易失变量“? ”编译时不做优化“、”直接存取原始内存地址“
一般说来,volatile用在如下的几个地方:
1、中断服务程序中修改的供其它程序检测的变量需要加volatile;
2、多任务环境下各任务间共享的标志应该加volatile;
3、存储器映射的硬件寄存器(如状态寄存器)通常也要加volatile说明,因为每次对它的读写都可能有不同意义
3.1.3 volatile 修饰符的有过什么实践
一种实践是用 volatile 修饰 long 和 double 变量,使其能按原子类型来读写。double 和 long 都是64位宽,因此对这两种类型的读是分为两部分的,第一次读取第一个 32 位,然后再读剩下的 32 位,这个过程不是原子的,但 Java 中 volatile 型的 long 或 double 变量的读写是原子的。volatile 修复符的另一个作用是提供内存屏障(memory barrier),例如在分布式框架中的应用。简单的说,就是当你写一个 volatile 变量之前,Java 内存模型会插入一个写屏障(write barrier),读一个 volatile 变量之前,会插入一个读屏障(read barrier)。意思就是说,在你写一个 volatile 域时,能保证任何线程都能看到你写的值,同时,在写之前,也能保证任何数值的更新对所有线程是可见的,因为内存屏障会将其他所有写的值更新到缓存
答:1,线程1执行doWork()的过程中,可能有另外的线程2调用了shutdown,所以boolean变量必须是volatile。
2,独立观察,定期 “发布” 观察结果供程序内部使用。【例如】假设有一种环境传感器能够感觉环境温度。一个后台线程可能会每隔几秒读取一次该传感器,并更新包含当前文档的 volatile 变量。然后,其他线程可以读取这个变量,从而随时能够看到最新的温度值。
3,线程安全的计数器,使用 synchronized 确保增量操作是原子的,并使用 volatile 保证当前结果的可见性。如果更新不频繁的话,该方法可实现更好的性能,因为读路径的开销仅仅涉及 volatile 读操作,这通常要优于一个无竞争的锁获取的开销。
4,单例双检锁
总结一下,可以分为5个:作为状态位发布;一次性安全发布;独立观察;volatile bean模式;开销较低的读写锁策略。
3.1.4为什么volatile不能保证原子性而Atomic可以?
http://www.cnblogs.com/Mainz/p/3556430.html
在上篇《非阻塞同步算法与CAS(Compare and Swap)无锁算法》中讲到在Java中long赋值不是原子操作,因为先写32位,再写后32位,分两步操作,而AtomicLong赋值是原子操作,为什么?为什么volatile能替代简单的锁,却不能保证原子性?这里面涉及volatile,是java中的一个我觉得这个词在Java规范中从未被解释清楚的神奇关键词,在Sun的JDK官方文档是这样形容volatile的:
The Java programming language provides a second mechanism, volatile fields, that is more convenient than locking for some purposes. A field may be declared volatile, in which case the Java Memory Model ensures that all threads see a consistent value for the variable.
意思就是说,如果一个变量加了volatile关键字,就会告诉编译器和JVM的内存模型:这个变量是对所有线程共享的、可见的,每次jvm都会读取最新写入的值并使其最新值在所有CPU可见。volatile似乎是有时候可以代替简单的锁,似乎加了volatile关键字就省掉了锁。但又说volatile不能保证原子性(java程序员很熟悉这句话:volatile仅仅用来保证该变量对所有线程的可见性,但不保证原子性)。这不是互相矛盾吗?
不要将volatile用在getAndOperate场合,仅仅set或者get的场景是适合volatile的
不要将volatile用在getAndOperate场合(这种场合不原子,需要再加锁),仅仅set或者get的场景是适合volatile的。
volatile没有原子性举例:AtomicInteger自增
例如你让一个volatile的integer自增(i++),其实要分成3步:1)读取volatile变量值到local; 2)增加变量的值;3)把local的值写回,让其它的线程可见。这3步的jvm指令为:
?
1
2
3
4 mov 0xc(%r10),%r8d ; Load
inc %r8d ; Increment
mov %r8d,0xc(%r10) ; Store
lock addl $0x0,(%rsp) ; StoreLoad Barrier
注意最后一步是内存屏障。
什么是内存屏障(Memory Barrier)?
内存屏障(memory barrier)是一个CPU指令。基本上,它是这样一条指令: a) 确保一些特定操作执行的顺序; b) 影响一些数据的可见性(可能是某些指令执行后的结果)。编译器和CPU可以在保证输出结果一样的情况下对指令重排序,使性能得到优化。插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行。内存屏障另一个作用是强制更新一次不同CPU的缓存。例如,一个写屏障会把这个屏障前写入的数据刷新到缓存,这样任何试图读取该数据的线程将得到最新值,而不用考虑到底是被哪个cpu核心或者哪颗CPU执行的。
内存屏障(memory barrier)和volatile什么关系?上面的虚拟机指令里面有提到,如果你的字段是volatile,Java内存模型将在写操作后插入一个写屏障指令,在读操作前插入一个读屏障指令。这意味着如果你对一个volatile字段进行写操作,你必须知道:1、一旦你完成写入,任何访问这个字段的线程将会得到最新的值。2、在你写入前,会保证所有之前发生的事已经发生,并且任何更新过的数据值也是可见的,因为内存屏障会把之前的写入值都刷新到缓存。
volatile为什么没有原子性?
明白了内存屏障(memory barrier)这个CPU指令,回到前面的JVM指令:从Load到store到内存屏障,一共4步,其中最后一步jvm让这个最新的变量的值在所有线程可见,也就是最后一步让所有的CPU内核都获得了最新的值,但中间的几步(从Load到Store)是不安全的,中间如果其他的CPU修改了值将会丢失。下面的测试代码可以实际测试voaltile的自增没有原子性:
-
View Code?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40 private static volatile long _longVal = 0;private static class LoopVolatile implements Runnable {
public void run() {
long val = 0;
while (val < 10000000L) {
_longVal++;
val++;
}
}
}private static class LoopVolatile2 implements Runnable {
public void run() {
long val = 0;
while (val < 10000000L) {
_longVal++;
val++;
}
}
}private void testVolatile(){
Thread t1 = new Thread(new LoopVolatile());
t1.start();Thread t2 = new Thread(new LoopVolatile2()); t2.start(); while (t1.isAlive() || t2.isAlive()) { } System.out.println("final val is: " + _longVal);}
Output:————-
final val is: 11223828
final val is: 17567127
final val is: 12912109
volatile没有原子性举例:singleton单例模式实现
这是一段线程不安全的singleton(单例模式)实现,尽管使用了volatile:
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14 public class wrongsingleton {
private static volatile wrongsingleton _instance = null;
private wrongsingleton() {}
public static wrongsingleton getInstance() {
if (_instance == null) {
_instance = new wrongsingleton();
}
return _instance;
}
}
下面的测试代码可以测试出是线程不安全的:
-
View Code?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33 public class wrongsingleton {
private static volatile wrongsingleton _instance = null;private wrongsingleton() {}
public static wrongsingleton getInstance() {
if (_instance == null) { _instance = new wrongsingleton(); System.out.println("--initialized once."); } return _instance;}
}
private static void testInit(){
Thread t1 = new Thread(new LoopInit());
Thread t2 = new Thread(new LoopInit2());
Thread t3 = new Thread(new LoopInit());
Thread t4 = new Thread(new LoopInit2());
t1.start();
t2.start();
t3.start();
t4.start();
while (t1.isAlive() || t2.isAlive() || t3.isAlive()|| t4.isAlive()) {
}
}
输出:有时输出”–initialized once.”一次,有时输出好几次
原因自然和上面的例子是一样的。因为volatile保证变量对线程的可见性,但不保证原子性。
附:正确线程安全的单例模式写法:
?
1
2
3
4
5
6
7
8
9 @ThreadSafe
public class SafeLazyInitialization {
private static Resource resource;
public synchronized static Resource getInstance() {
if (resource == null)
resource = new Resource();
return resource;
}
}
另外一种写法:
?
1
2
3
4
5 @ThreadSafe
public class EagerInitialization {
private static Resource resource = new Resource();
public static Resource getResource() { return resource; }
}
延迟初始化的写法:
?
1
2
3
4
5
6
7
8
9 @ThreadSafe
public class ResourceFactory {
private static class ResourceHolder {
public static Resource resource = new Resource();
}
public static Resource getResource() {
return ResourceHolder.resource ;
}
}
二次检查锁定/Double Checked Locking的写法(反模式)
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 public class SingletonDemo {
private static volatile SingletonDemo instance = null;//注意需要volatile
private SingletonDemo() { }
public static SingletonDemo getInstance() {
if (instance == null) { //二次检查,比直接用独占锁效率高
synchronized (SingletonDemo .class){
if (instance == null) {
instance = new SingletonDemo ();
}
}
}
return instance;
}
}
为什么AtomicXXX具有原子性和可见性?
就拿AtomicLong来说,它既解决了上述的volatile的原子性没有保证的问题,又具有可见性。它是如何做到的?当然就是上文《非阻塞同步算法与CAS(Compare and Swap)无锁算法》提到的CAS(比较并交换)指令。 其实AtomicLong的源码里也用到了volatile,但只是用来读取或写入,见源码:
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 public class AtomicLong extends Number implements java.io.Serializable {
private volatile long value;
/**
* Creates a new AtomicLong with the given initial value.
*
* @param initialValue the initial value
*/
public AtomicLong(long initialValue) {
value = initialValue;
}
/**
* Creates a new AtomicLong with initial value {@code 0}.
*/
public AtomicLong() {
}
其CAS源码核心代码为:
?
1
2
3
4
5
6
7
8
9 int compare_and_swap (int* reg, int oldval, int newval)
{
ATOMIC();
int old_reg_val = *reg;
if (old_reg_val == oldval)
*reg = newval;
END_ATOMIC();
return old_reg_val;
}
虚拟机指令为:
?
1
2
3
4 mov 0xc(%r11),%eax ; Load
mov %eax,%r8d
inc %r8d ; Increment
lock cmpxchg %r8d,0xc(%r11) ; Compare and exchange
因为CAS是基于乐观锁的,也就是说当写入的时候,如果寄存器旧值已经不等于现值,说明有其他CPU在修改,那就继续尝试。所以这就保证了操作的原子性。
3.1.5 java中能创建 volatile 数组吗?
能,Java 中可以创建 volatile 类型数组,不过只是一个指向数组的引用,而不是整个数组。我的意思是,如果改变引用指向的数组,将会受到 volatile 的保护,但是如果多个线程同时改变数组的元素,volatile 标示符就不能起到之前的保护作用了。
3.1.6volatile 能使得一个非原子操作变成原子操作吗?
一个典型的例子是在类中有一个 long 类型的成员变量。如果你知道该成员变量会被多个线程访问,如计数器、价格等,你最好是将其设置为 volatile。为什么?因为 Java 中读取 long 类型变量不是原子的,需要分成两步,如果一个线程正在修改该 long 变量的值,另一个线程可能只能看到该值的一半(前 32 位)。但是对一个 volatile 型的 long 或 double 变量的读写是原子。
3.1.7 volatile 类型变量提供什么保证?
volatile 变量提供顺序和可见性保证,例如,JVM 或者 JIT为了获得更好的性能会对语句重排序,但是 volatile 类型变量即使在没有同步块的情况下赋值也不会与其他语句重排序。 volatile 提供 happens-before 的保证,确保一个线程的修改能对其他线程是可见的。某些情况下,volatile 还能提供原子性,如读 64 位数据类型,像 long 和 double 都不是原子的,但 volatile 类型的 double 和 long 就是原子的。
3.1.8 volatile 变量是什么?volatile 变量和 atomic 变量有什么不同
答:1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
[java] view plain copy
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;
这个代码能够把线程中断,但是也有可能会导致无法中断线程。每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。但是用volatile修饰之后就变得不一样了:第一:使用volatile关键字会强制将修改的值立即写入主存;第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。那么线程1读取到的就是最新的正确的值。
happens-before规则中的volatile变量规则,但是要注意,线程1对变量进行读取操作之后,被阻塞了的话,并没有对inc值进行修改。然后虽然volatile能保证线程2对变量inc的值读取是从内存中读取的,但是线程1没有进行修改,所以线程2根本就不会看到修改的值。自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。
3.1.9
3.2 IO
3.2.1 IO 和 NIO的区别,NIO优点
概述
Java NIO提供了与标准IO不同的IO工作方式:
Channels and Buffers(通道和缓冲区):标准的IO基于字节流和字符流进行操作的,而NIO是基于通道(Channel)和缓冲区(Buffer)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。
Asynchronous IO(异步IO):Java NIO可以让你异步的使用IO,例如:当线程从通道读取数据到缓冲区时,线程还是可以进行其他事情。当数据被写入到缓冲区时,线程可以继续处理它。从缓冲区写入通道也类似。
Selectors(选择器):Java NIO引入了选择器的概念,选择器用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个的线程可以监听多个数据通道。
使用场景
NIO
优势在于一个线程管理多个通道;但是数据的处理将会变得复杂;
如果需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据,采用这种;
传统的IO
适用于一个线程管理一个通道的情况;因为其中的流数据的读取是阻塞的;
如果需要管理同时打开不太多的连接,这些连接会发送大量的数据;
NIO vs IO区别
NIO vs IO之间的理念上面的区别(NIO将阻塞交给了后台线程执行)
IO是面向流的,NIO是面向缓冲区的
oJava IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方;
oNIO则能前后移动流中的数据,因为是面向缓冲区的
IO流是阻塞的,NIO流是不阻塞的
oJava IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了
oJava NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。NIO可让您只使用一个(或几个)单线程管理多个通道(网络连接或文件),但付出的代价是解析数据可能会比从一个阻塞流中读取数据更复杂。
o非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
选择器
oJava NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
Java NIO 由以下几个核心部分组成:
Channels
Buffers
Selectors
基本上,所有的 IO 在NIO 中都从一个Channel 开始。Channel 有点象流。 数据可以从Channel读到Buffer中,也可以从Buffer 写到Channel中。这里有个图示:
Channel
Channel的实现: (涵盖了UDP 和 TCP 网络IO,以及文件IO)
FileChannel
DatagramChannel
SocketChannel
ServerSocketChannel
读数据:
int bytesRead = inChannel.read(buf);
写数据:
int bytesWritten = inChannel.write(buf);
还有部分的使用,如配置Channel为阻塞或者非阻塞模式,以及如何注册到Selector上面去,参考Selector部分;
Buffer
Buffer实现: (byte, char、short, int, long, float, double )
ByteBuffer
CharBuffer
DoubleBuffer
FloatBuffer
IntBuffer
LongBuffer
ShortBuffer
Buffer使用
读数据
flip()方法
o将Buffer从写模式切换到读模式
o调用flip()方法会将position设回0,并将limit设置成之前position的值。
obuf.flip();
(char) buf.get()
o读取数据
Buffer.rewind()
o将position设回0,所以你可以重读Buffer中的所有数据
olimit保持不变,仍然表示能从Buffer中读取多少个元素(byte、char等)
Buffer.mark()方法,可以标记Buffer中的一个特定position。之后可以通过调用
Buffer.reset()方法,恢复到Buffer.mark()标记时的position
一旦读完了所有的数据,就需要清空缓冲区,让它可以再次被写入。
clear()方法会:
o清空整个缓冲区。
oposition将被设回0,limit被设置成 capacity的值
compact()方法:
o只会清除已经读过的数据;任何未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面。
o将position设到最后一个未读元素正后面,limit被设置成 capacity的值
写数据
buf.put(127);
Buffer的三个属性
capacity:含义与模式无关;Buffer的一个固定的大小值;Buffer满了需要将其清空才能再写;
oByteBuffer.allocate(48);该buffer的capacity为48byte
oCharBuffer.allocate(1024);该buffer的capacity为1024个char
position:含义取决于Buffer处在读模式还是写模式(初始值为0,写或者读操作的当前位置)
o写数据时,初始的position值为0;其值最大可为capacity-1
o将Buffer从写模式切换到读模式,position会被重置为0
limit:含义取决于Buffer处在读模式还是写模式(写limit=capacity;读limit等于最多可以读取到的数据)
o写模式下,limit等于Buffer的capacity
o切换Buffer到读模式时, limit表示你最多能读到多少数据;
Selector
概述
Selector允许单线程处理多个 Channel。如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用Selector就会很方便。例如,在一个聊天服务器中。
要使用Selector,得向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件的例子有如新连接进来,数据接收等。
使用
1.创建:Selector selector = Selector.open();
2.注册通道:
ochannel.configureBlocking(false);
//与Selector一起使用时,Channel必须处于非阻塞模式
//这意味着不能将FileChannel与Selector一起使用,因为FileChannel不能切换到非阻塞模式(而套接字通道都可以)
oSelectionKey key = channel.register(selector, Selectionkey.OP_READ);
//第二个参数表明Selector监听Channel时对什么事件感兴趣
//SelectionKey.OP_CONNECT SelectionKey.OP_ACCEPT SelectionKey.OP_READ SelectionKey.OP_WRITE
//可以用或操作符将多个兴趣组合一起
oSelectionKey
包含了interest集合 、ready集合 、Channel 、Selector 、附加的对象(可选)
int interestSet = key.interestOps();可以进行类似interestSet & SelectionKey.OP_CONNECT的判断
3.使用:
oselect():阻塞到至少有一个通道在你注册的事件上就绪了
oselectNow():不会阻塞,不管什么通道就绪都立刻返回
oselectedKeys():访问“已选择键集(selected key set)”中的就绪通道
oclose():使用完selector需要用其close()方法会关闭该Selector,且使注册到该Selector上的所有SelectionKey实例无效
1.Set selectedKeys = selector.selectedKeys();
2.Iterator keyIterator = selectedKeys.iterator();
3.while(keyIterator.hasNext()) {
4. SelectionKey key = keyIterator.next();
5. if(key.isAcceptable()) {
6. // a connection was accepted by a ServerSocketChannel.
7. } else if (key.isConnectable()) {
8. // a connection was established with a remote server.
9. } else if (key.isReadable()) {
10. // a channel is ready for reading
11. } else if (key.isWritable()) {
12. // a channel is ready for writing
13. }
14. keyIterator.remove();//注意这里必须手动remove;表明该selectkey我已经处理过了;
15.}
Java测试关键代码
1.RandomAccessFile aFile = new RandomAccessFile(“data/nio-data.txt”, “rw”);
2.FileChannel inChannel = aFile.getChannel(); //从一个InputStream outputstream中获取channel
3.
4.//create buffer with capacity of 48 bytes
5.ByteBuffer buf = ByteBuffer.allocate(48);
6.
7.int bytesRead = inChannel.read(buf); //read into buffer.
8.while (bytesRead != -1) {
9.
10. buf.flip(); //make buffer ready for read
11.
12. while(buf.hasRemaining()){
13. System.out.print((char) buf.get()); // read 1 byte at a time
14. }
15.
16. buf.clear(); //make buffer ready for writing
17. bytesRead = inChannel.read(buf);
18.}
19.aFile.close();
文件通道
1.RandomAccessFile aFile = new RandomAccessFile(“data/nio-data.txt”, “rw”);
2.FileChannel inChannel = aFile.getChannel();
读数据
1.ByteBuffer buf = ByteBuffer.allocate(48);
2.int bytesRead = inChannel.read(buf);
写数据
1.String newData = “New String to write to file…” + System.currentTimeMillis();
2.ByteBuffer buf = ByteBuffer.allocate(48);
3.buf.clear();
4.buf.put(newData.getBytes());
5.buf.flip();
6.while(buf.hasRemaining()) {
7. channel.write(buf);
8.}
Socket 通道
1.SocketChannel socketChannel = SocketChannel.open();
2.socketChannel.connect(new InetSocketAddress(“http://jenkov.com”, 80));
读数据
1.ByteBuffer buf = ByteBuffer.allocate(48);
2.int bytesRead = socketChannel.read(buf);
写数据
1.String newData = “New String to write to file…” + System.currentTimeMillis();
2.ByteBuffer buf = ByteBuffer.allocate(48);
3.buf.clear();
4.buf.put(newData.getBytes());
5.buf.flip();
6.while(buf.hasRemaining()) {
7. socketChannel.write(buf);
8.}
ServerSocket 通道
1.ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
2.serverSocketChannel.socket().bind(new InetSocketAddress(9999));
3.while(true){
4. SocketChannel socketChannel =
5. serverSocketChannel.accept();
6. //do something with socketChannel…
7.}
Datagram 通道(channel的读写操作与前面的有差异)
1.DatagramChannel channel = DatagramChannel.open();
2.channel.socket().bind(new InetSocketAddress(9999));
读数据
1.ByteBuffer buf = ByteBuffer.allocate(48);
2.buf.clear();
3.channel.receive(buf);
4.//receive()方法会将接收到的数据包内容复制到指定的Buffer. 如果Buffer容不下收到的数据,多出的数据将被丢弃。
写数据
1.String newData = “New String to write to file…” + System.currentTimeMillis();
2.ByteBuffer buf = ByteBuffer.allocate(48);
3.buf.clear();
4.buf.put(newData.getBytes());
5.buf.flip();
6.int bytesSent = channel.send(buf, new InetSocketAddress(“jenkov.com”, 80));
3.2.2 直接缓冲区与非直接缓冲器有什么区别?
BufferedOutputStream与任何一个OutputStream相同,除了用一个另外的flush( ) 方法来保证数据缓冲器被写入到实际的输出设备。因为BufferedOutputStream是通过减小系统写数据的时间而提高性能的,可以调用flush( )方法生成缓冲器中待写的数据。
3.2.3 PrintStream、BufferedWriter、PrintWriter的比较?
PrintStream类的输出功能非常强大,通常如果需要输出文本内容,都应该将输出流包装成PrintStream后进行输出。它还提供其他两项功能。与其他输出流不同,PrintStream 永远不会抛出 IOException;而是,异常情况仅设置可通过 checkError 方法测试的内部标志。另外,为了自动刷新,可以创建一个 PrintStream
BufferedWriter:将文本写入字符输出流,缓冲各个字符从而提供单个字符,数组和字符串的高效写入。通过write()方法可以将获取到的字符输出,然后通过newLine()进行换行操作。BufferedWriter中的字符流必须通过调用flush方法才能将其刷出去。并且BufferedWriter只能对字符流进行操作。如果要对字节流操作,则使用BufferedInputStream。
PrintWriter的println方法自动添加换行,不会抛异常,若关心异常,需要调用checkError方法看是否有异常发生,PrintWriter构造方法可指定参数,实现自动刷新缓存(autoflush);
3.2.4 JDK 为每种类型的流提供了一些抽象类以供继承,分别是哪些类
java中有几种类型的流?JDK为每种类型的流提供了一些抽象类以供继承,请说出他们分别是哪些类?
Java中的流分为两种,一种是字节流,另一种是字符流,分别由四个抽象类来表示(每种流包括输入和输出两种所以一共四个):InputStream,OutputStream,Reader,Writer。Java中其他多种多样变化的流均是由它们派生出来的.
字符流和字节流是根据处理数据的不同来区分的。字节流按照8位传输,字节流是最基本的,所有文件的储存是都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘。
1.字节流可用于任何类型的对象,包括二进制对象,而字符流只能处理字符或者字符串;
2. 字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以。
读文本的时候用字符流,例如txt文件。读非文本文件的时候用字节流,例如mp3。理论上任何文件都能够用字节流读取,但当读取的是文本数据时,为了能还原成文本你必须再经过一个转换的工序,相对来说字符流就省了这个麻烦,可以有方法直接读取。
字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节, 操作字节和字节数组。所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的,所以它对多国语言支持性比较好!
1.字节流:继承于InputStream \ OutputStream。
OutputStream提供的方法:
void write(int b):写入一个字节的数据
void write(byte[] buffer):将数组buffer的数据写入流
void write(byte[] buffer,int offset,int len):从buffer[offset]开始,写入len个字节的数据
void flush():强制将buffer内的数据写入流
void close():关闭流
InputStream提供的方法:
int read():读出一个字节的数据,如果已达文件的末端,返回值为-1
int read(byte[] buffer):读出buffer大小的数据,返回值为实际所读出的字节数
int read(byte[] buffer,int offset,int len)
int available():返回流内可供读取的字节数目
long skip(long n):跳过n个字节的数据,返回值为实际所跳过的数据数
void close():关闭流
2.字符流,继承于InputStreamReader \ OutputStreamWriter。
字符流的类:1),BufferedReader是一种过滤器(filter)(extends FilterReader)。过滤
器用来将流的数据加以处理再输出。构造函数为:
BufferedReader(Reader in):生成一个缓冲的字符输入流,in为一个读取器
BufferedReader(Reader in,int size):生成一个缓冲的字符输入流,并指定缓冲区的大小为size
public class IOStreamDemo { public void samples() throws IOException { //1. 这是从键盘读入一行数据,返回的是一个字符串 BufferedReader stdin =new BufferedReader(new InputStreamReader(System.in)); System.out.print(“Enter a line:”); System.out.println(stdin.readLine());
//2. 这是从文件中逐行读入数据
BufferedReader in = new BufferedReader(new FileReader(“IOStreamDemo.java”)); String s, s2 = new String(); while((s = in.readLine())!= null) s2 += s + “\n”; in.close();
//3. 这是从一个字符串中逐个读入字节 StringReader in1 = new StringReader(s2); int c; while((c = in1.read()) != -1) System.out.print((char)c);
//4. 这是将一个字符串写入文件 try { BufferedReader in2 = new BufferedReader(new StringReader(s2)); PrintWriter out1 = new PrintWriter(new BufferedWriter(new FileWriter(“IODemo.out”))); int lineCount = 1; while((s = in2.readLine()) != null ) out1.println(lineCount++ + “: ” + s); out1.close(); } catch(EOFException e) { System.err.println(“End of stream”); } } }
对于上面的例子,需要说明的有以下几点:
- InputStreamReader是InputStream和Reader之间的桥梁,由于System.in是字节流,需要用它来包装之后变为字符流供给BufferedReader使用。
- PrintWriter out1 = new PrintWriter(new BufferedWriter(new FileWriter(“IODemo.out”)));
这句话体现了Java输入输出系统的一个特点,为了达到某个目的,需要包装好几层。首先,输出目的地是文件IODemo.out,所以最内层包装的是FileWriter,建立一个输出文件流,接下来,我们希望这个流是缓冲的,所以用BufferedWriter来包装它以达到目的,最后,我们需要格式化输出结果,于是将PrintWriter包在最外层。
Java流有着另一个重要的用途,那就是利用对象流对对象进行序列化。
在一个程序运行的时候,其中的变量数据是保存在内存中的,一旦程序结束这些数据将不会被保存,一种解决的办法是将数据写入文件,而Java中提供了一种机制,它可以将程序中的对象写入文件,之后再从文件中把对象读出来重新建立。这就是所谓的对象序列化。Java中引入它主要是为了RMI(Remote Method Invocation)和Java Bean所用,不过在平时应用中,它也是很有用的一种技术。
3.2.5 Java中以指定编码方式读取字符流
Java中可以以指定的编码方式读取字符流,比如utf-8,utf-16,utf-32和gbk等,也可以自己制定解码算法。
这里涉及的一个class就是InputStreamReader,它用于在字节流上建立字符流。
构造方式有:
public InputStreamReader(InputStream in)
public InputStreamReader(InputStream in,String enc)
public InputStreamReader(InputStream in,CharsetDecoder dec)
public InputStreamReader(InputStream in,Charset charset)
3.3 克隆
https://blog.csdn.net/w410589502/article/details/54985987
3.3.1 为什么要克隆
在java中,复制一个变量很容易
int a = 5; int b = a;
不仅仅是int类型,其它七种原始数据类型(boolean,char,byte,short,float,double.long)同样适用于该类情况。
但是如果我们需要复制一个对象,使用变量的”=”符号复制就不正确了,除了在函数传值的时候是”引用传递”,在任何用”=”向对象变量赋值的时候都是”引用传递”。
克隆的对象可能包含一些已经修改过的属性,而new出来的对象的属性都还是初始化时候的值,所以当需要一个新的对象来保存当前对象的“状态”就靠clone方法了。
所以我们需要能够实现对于输入的实参进行了一份拷贝,若方法参数为基本类型,则在栈内存中开辟新的空间,所有的方法体内部的操作都是针对这个拷贝的操作,并不会影响原来输入实参的值 。若方法参数为引用类型,该拷贝与输入实参指向了同一个对象,方法体内部对于对象的操作,都是针对的同一个对象。
3.3.2 如何实现克隆
两种不同的克隆方法,浅克隆(ShallowClone)和深克隆(DeepClone)。
在Java语言中,数据类型分为值类型(基本数据类型)和引用类型,值类型包括int、double、byte、boolean、char等简单数据类型,引用类型包括类、接口、数组等复杂类型。浅克隆和深克隆的主要区别在于是否支持引用类型的成员变量的复制。
有两种方式:
1). 实现Cloneable接口并重写Object类中的clone()方法;
2). 实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆;
3.3.3 深拷贝和浅拷贝区别 (深克隆和浅克隆)
浅克隆
在浅克隆中,如果原型对象的成员变量是值类型,将复制一份给克隆对象;如果原型对象的成员变量是引用类型,则将引用对象的地址复制一份给克隆对象,也就是说原型对象和克隆对象的成员变量指向相同的内存地址。
在Java语言中,通过覆盖Object类的clone()方法可以实现浅克隆。
深克隆
在深克隆中,无论原型对象的成员变量是值类型还是引用类型,都将复制一份给克隆对象,深克隆将原型对象的所有引用对象也复制一份给克隆对象。
简单来说,在深克隆中,除了对象本身被复制外,对象所包含的所有成员变量也将复制。
在Java语言中,如果需要实现深克隆,可以通过覆盖Object类的clone()方法实现,也可以通过序列化(Serialization)等方式来实现。
如果引用类型里面还包含很多引用类型,或者内层引用类型的类里面又包含引用类型,使用clone方法就会很麻烦。这时我们可以用序列化的方式来实现对象的深克隆。
序列化就是将对象写到流的过程,写到流中的对象是原有对象的一个拷贝,而原对象仍然存在于内存中。通过序列化实现的拷贝不仅可以复制对象本身,而且可以复制其引用的成员对象,因此通过序列化将对象写到一个流中,再从流里将其读出来,可以实现深克隆。需要注意的是能够实现序列化的对象其类必须实现Serializable接口,否则无法实现序列化操作。
参考文章:
3.4 方法
3.4.1 构造器能被重写吗
Constructor(构造器)不能被继承,所以不能被override(重写),但是可以被overloading(重载)。
3.4.2 abstract 的 method是否可同时是 static,是否可同时是 native,是否可同时是synchronized
都不可以,因为abstract申明的方法是要求子类去实现的,abstract只是告诉你有这样一个接口,你要去实现,至于你的具体实现可以是native和synchronized,也可以不是,抽象方法是不关心这些事的,所以写这两个是没有意义的。然后,static方法是不会被覆盖的,而abstract方法正是要子类去覆盖它,所以也是没有意义的。所以,总的来说,就是java语法不允许你这样做,事实上,也没有意义这样做。
abstract需要重载,static为类方法,没有重载一说 abstract为没有实现的方法,native为本机实现的方法,自相矛盾 abstract方法没有实现,也不可能实际调用抽象方法,没有必要synchronized修饰,当然子类可以根据需要同步该方法.所以 都不能。
3.4.3 Java支持哪种参数传递类型
:Java 应用程序有且仅有的一种参数传递机制,即按值传递。
对象是按引用传递的;
Java 应用程序有且仅有的一种参数传递机制,即按值传递;
按值传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的一个副本;
按引用传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的内存地址,而不是值的副本。
3.4.4 一个对象被当作参数传递到一个方法,是值传递还是引用传递
是值传递。Java编程语言中只有由值传递参数的。当一个对象实例作为一个参数被传递到方法中时,参数的值就是该对象的引用。对象的内容可以在被调用的方法中改变,但对象的引用是永远不会改变的。
3.4.5当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递
:是值传递。Java编程语言只有值传递参数。当一个对象实例作为一个参数被传递到方法中时,参数的值就是该对象的引用一个副本。指向同一个对象,对象的内容可以在被调用的方法中改变,但对象的引用(不是引用的副本)是永远不会改变的。
在 Java应用程序中永远不会传递对象,而只传递对象引用。因此是按引用传递对象。但重要的是要区分参数是如何传递的,这才是该节选的意图。Java应用程序按引用传递对象这一事实并不意味着 Java 应用程序按引用传递参数。参数可以是对象引用,而 Java应用程序是按值传递对象引用的。
Java应用程序中的变量可以为以下两种类型之一:引用类型或基本类型。当作为参数传递给一个方法时,处理这两种类型的方式是相同的。两种类型都是按值传递的;没有一种按引用传递。
按值传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的一个副本。因此,如果函数修改了该参数,仅改变副本,而原始值保持不变。按引用传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的内存地址,而不是值的副本。因此,如果函数修改了该参数的值,调用代码中的原始值也随之改变。如果函数修改了该参数的地址,调用代码中的原始值不会改变.
当传递给函数的参数不是引用时,传递的都是该值的一个副本(按值传递)。区别在于引用。在 C++中当传递给函数的参数是引用时,您传递的就是这个引用,或者内存地址(按引用传递)。在 Java应用程序中,当对象引用是传递给方法的一个参数时,您传递的是该引用的一个副本(按值传递),而不是引用本身。
Java 应用程序按值传递参数(引用类型或基本类型),其实都是传递他们的一份拷贝.而不是数据本身.(不是像 C++中那样对原始值进行操作。)
3.4.6 我们能否重载main()方法 https://www.jb51.net/article/78360.htm
可以,我们可以重载main()方法。一个Java类可以有任意数量的main()方法。
为了运行java类,类的main()方法应该有例如“public static void main(String[] args)”的声明。如果你对此声明做任何修改,编译也是可以成功的。但是,运行不了Java程序。你会得到运行时错误,因为找不到main方法。
main方法能被完美重载,但是在JVM中有特殊能力的只有public static void main.
3.4.7 .我们能否声明main()方法为private或protected,或者不用访问修饰符?
不能,main()方法必须public。你不能定义main()方法为private和protected,也不能不用访问修饰符。
这是为了能让JVM访问main()方法。如果你不定义main()方法为public,虽然编译也会成功,但你会得到运行时错误,因为找不到main方法。
3.5 网络编程
3.5.1传输层常见编程协议有哪些?并说出各自的特点
TCP,UDP,SPX,NetBIOS,NetBEUI
☆ SPX:顺序包交换协议,是Novell NetWare网络的传输层协议。
☆ TCP:传输控制协议,是TCP/IP参考模型的传输层协议。
UDP : UDP协议全称是用户数据报协议,在网络中它与TCP协议一样用于处理数据包,是一种无连接的协议。在OSI模型中,在第四层——传输层,处于IP协议的上一层
UDP的主要特点
(1) UDP是无连接的,即发送数据之前不需要建立连接,因此减少了开销和发送数据之前的时延。
(2) UDP使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的连接状态表。
4) UDP没有拥塞控制,因此网络出现的拥塞不会使源主机的发送速率降低。很多的实时应用(如IP电话、实时视频会议等)要去源主机以恒定的速率发送数据,并且允许在网络发生拥塞时丢失一些数据,但却不允许数据有太多的时延。UDP正好符合这种要求。
(5) UDP支持一对一、一对多、多对一和多对多的交互通信。
(6) UDP的首部开销小,只有8个字节,比TCP的20个字节的首部要短。
3.5.2 TCP和UDP通信有什么区别 如何分别用java实现?
TCP是面向连接,UDP面向非连接,
TCP建立连接时需要传说的三次握手,服务端与客户端需要确认对方身份而已,建立好连接后,就开始传递消息,直到有一方断开连接位置。 就好比两个人打电话,要先通了才能说话。
UDP只是数据报发送,它的优点速度快,并非要向TCP那样麻烦建立,它只负责将信息发出,但是并不确保信息的准确完整性等,就好比发短信,短信是出去了,但是中间是否有问题,是否对方手机能收到就不管了。
在java中想要实现上述两种协议通信,可采用socket建立连接,socket可以理解为码头,其实是套接字,这里简单说下,就好比两个城市运输货物,通过码头走货一样。
3.5.3 Socket 工作在 TCP/IP 协议栈是哪一层
socket的实现部分, 就是系统协议栈部分, 应该包含了 网络层 (ip), 传输层(tcp/udp)等等。
用socket写程序的人, 就要看用socket那部分了。 如果你直接用ip层, rawsocket, 假如你自己写个tcp协议, 那你应该做的就是传输层。
如果你是用tcp/udp等协议, 做网络应用, 那应该是应用层。
其实如果按osi的模型来分。 每个从事软件或者硬件开发的人, 都应该能找到自己工作在那一层。
3.6 内部类
3.6.1 内部类分为几种
Java中的内部类共分为四种:
静态内部类static inner class (also called nested class)
成员内部类member inner class
局部内部类local inner class
匿名内部类anonymous inner class
静态内部类Static Inner Class
最简单的内部类形式。
类定义时加上static关键字。
不能和外部类有相同的名字。
被编译成一个完全独立的.class文件,名称为OuterClass$InnerClass.class的形式。
只可以访问外部类的静态成员和静态方法,包括了私有的静态成员和方法。
生成静态内部类对象的方式为:
OuterClass.InnerClass inner = new OuterClass.InnerClass();
示例代码:
package com.learnjava.innerclass;
class StaticInner
{
private static int a = 4;
// 静态内部类
public static class Inner
{
public void test()
{
// 静态内部类可以访问外部类的静态成员
// 并且它只能访问静态的
System.out.println(a);
}
}
}
public class StaticInnerClassTest
{
public static void main(String[] args)
{
StaticInner.Inner inner = new StaticInner.Inner();
inner.test();
}
}
成员内部类 Member Inner Class
成员内部类也是定义在另一个类中,但是定义时不用static修饰。
成员内部类和静态内部类可以类比为非静态的成员变量和静态的成员变量。
成员内部类就像一个实例变量。
它可以访问它的外部类的所有成员变量和方法,不管是静态的还是非静态的都可以。
在外部类里面创建成员内部类的实例:
this.new Innerclass();
在外部类之外创建内部类的实例:
(new Outerclass()).new Innerclass();
在内部类里访问外部类的成员:
Outerclass.this.member
示例代码:
package com.learnjava.innerclass;
class MemberInner
{
private int d = 1;
private int a = 2;
// 定义一个成员内部类
public class Inner2
{
private int a = 8;
public void doSomething()
{
// 直接访问外部类对象
System.out.println(d);
System.out.println(a);// 直接访问a,则访问的是内部类里的a
// 如何访问到外部类里的a呢?
System.out.println(MemberInner.this.a);
}
}
}
public class MemberInnerClassTest
{
public static void main(String[] args)
{
// 创建成员内部类的对象
// 需要先创建外部类的实例
MemberInner.Inner2 inner = new MemberInner().new Inner2();
inner.doSomething();
}
}
方法内部类 Local Inner Class
class Out {
private int age = 12;
public void Print(final int x) {
class In {
public void inPrint() {
System.out.println(x);
System.out.println(age);
}
}
new In().inPrint();
}
}
public class Demo {
public static void main(String[] args) {
Out out = new Out();
out.Print(3);
}
}
运行结果:
3
12
在上面的代码中,我们将内部类移到了外部类的方法中,然后在外部类的方法中再生成一个内部类对象去调用内部类方法
如果此时我们需要往外部类的方法中传入参数,那么外部类的方法形参必须使用final定义
至于final在这里并没有特殊含义,只是一种表示形式而已
匿名内部类Anonymous Inner Class
匿名内部类就是没有名字的局部内部类,不使用关键字class, extends, implements, 没有构造方法。
匿名内部类隐式地继承了一个父类或者实现了一个接口。
匿名内部类使用得比较多,通常是作为一个方法参数。
生成的.class文件中,匿名类会生成OuterClass$1.class文件,数字根据是第几个匿名类而类推。
示例代码:
package com.learnjava.innerclass;
import java.util.Date;
public class AnonymouseInnerClass
{
@SuppressWarnings(“deprecation”)
public String getDate(Date date)
{
return date.toLocaleString();
}
public static void main(String[] args)
{
AnonymouseInnerClass test = new AnonymouseInnerClass();
// 打印日期:
String str = test.getDate(new Date());
System.out.println(str);
System.out.println(“—————-”);
// 使用匿名内部类
String str2 = test.getDate(new Date()
{
});// 使用了花括号,但是不填入内容,执行结果和上面的完全一致
// 生成了一个继承了Date类的子类的对象
System.out.println(str2);
System.out.println(“—————-”);
// 使用匿名内部类,并且重写父类中的方法
String str3 = test.getDate(new Date()
{
// 重写父类中的方法
@Override
@Deprecated
public String toLocaleString()
{
return “Hello: ” + super.toLocaleString();
}
});
System.out.println(str3);
}
}
3.6.2 内部类可以引用它的包含类(外部类)的成员吗
如果不是静态内部类,完全可以。那没有什么限制!
在静态内部类下,不可以访问外部类的普通成员变量,而只能访问外部类中的静态成员,
3.6.3请说一下 Java 中为什么要引入内部类?还有匿名内部类
java内部类有什么好处?为什么需要内部类?
首先举一个简单的例子,如果你想实现一个接口,但是这个接口中的一个方法和你构想的这个类中的一个方法的名称,参数相同,你应该怎么办?这时候,你 可以建一个内部类实现这个接口。由于内部类对外部类的所有内容都是可访问的,所以这样做可以完成所有你直接实现这个接口的功能。
不过你可能要质疑,更改一下方法的不就行了吗?
的确,以此作为设计内部类的理由,实在没有说服力。
真正的原因是这样的,java中的内部类和接口加在一起,可以的解决常被C++程序员抱怨java中存在的一个问题——没有多继承。实际上,C++的多继承设计起来很复杂,而java通过内部类加上接口,可以很好的实现多继承的效果。
java内部类总结
(1) 在方法间定义的非静态内部类:
● 外围类和内部类可互相访问自己的私有成员。
● 内部类中不能定义静态成员变量。
在外部类作用范围之外向要创建内部类对象必须先创建其外部类对象
(2) 在方法间定义的静态内部类:
● 只能访问外部类的静态成员。
静态内部类没有了指向外部的引用
(3) 在方法中定义的局部内部类:
● 该内部类没有任何的访问控制权限
● 外围类看不见方法中的局部内部类的,但是局部内部类可以访问外围类的任何成员。
● 方法体中可以访问局部内部类,但是访问语句必须在定义局部内部类之后。
● 局部内部类只能访问方法体中的常量,即用final修饰的成员。
(4) 在方法中定义的匿名内部类:
● 没有构造器,取而代之的是将构造器参数传递给超类构造器
当你只需要创建一个类的对象而且用不上它的名字时,使用匿名内部类可以使代码看上去简洁清楚。
3.6.4匿名内部类是否可以继承其它类?是否可以实现接口
回答:匿名内部类在实现时必须借助一个借口或者一个抽象类或者一个普通类来构造,从这过层次上讲匿名内部类是实现了接口或者继承了类,但是不能通过extends或implement关键词来继承类或实现接口。
匿名内部类即没有名字的内部类。当我们只需要用某一个类一次时,且该类从意义上需要实现某个类或某个接口,这个特殊的扩展类就以匿名内部类来展现。
一般的用途:
1、覆盖某个超类的方法,并且该扩展类只在本类内用一次。
2、继承抽象类,并实例化其抽象方法,并且该扩展类只在本类内用一次。
3、实现接口,实例化其方法,并且该扩展类只在本类内用一次。
3.7 锁
3.7.1 synchronized的三种应用方式
synchronized关键字最主要有以下3种应用方式,下面分别介绍
修饰实例方法,作用于当前实例加锁,进入同步代码前要获得当前实例的锁
修饰静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁
修饰代码块,指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
任何一个对象都一个Monitor与之关联,当且一个Monitor被持有后,它将处于锁定状态。Synchronized在JVM里的实现都是基于进入和退出Monitor对象来实现方法同步和代码块同步,虽然具体实现细节不一样,但是都可以通过成对的MonitorEnter和MonitorExit指令来实现。MonitorEnter指令插入在同步代码块的开始位置,当代码执行到该指令时,将会尝试获取该对象Monitor的所有权,即尝试获得该对象的锁,而monitorExit指令则插入在方法结束处和异常处,JVM保证每个MonitorEnter必须有对应的MonitorExit。
3.7.2 synchronized 的原理是什么
每个对象有一个监视器锁(monitor)。当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
1、如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
2、如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
3.如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
执行monitorexit的线程必须是objectref所对应的monitor的所有者。
指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个 monitor 的所有权。
通过这两段描述,我们应该能很清楚的看出Synchronized的实现原理,Synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象,这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
3.7.3 什么场景下可以使用 volatile 替换 synchronized
java在编写多线程程序时,为了保证线程安全,需要对数据同步,经常用到两种同步方式就是Synchronized和重入锁ReentrantLock。
相似点:
这两种同步方式有很多相似之处,它们都是加锁方式同步,而且都是阻塞式的同步,也就是说当如果一个线程获得了对象锁,进入了同步块,其他访问该同步块的线程都必须阻塞在同步块外面等待,而进行线程阻塞和唤醒的代价是比较高的(操作系统需要在用户态与内核态之间来回切换,代价很高,不过可以通过对锁优化进行改善)。
区别:
这两种方式最大区别就是对于Synchronized来说,它是java语言的关键字,是原生语法层面的互斥,需要jvm实现。而ReentrantLock它是JDK 1.5之后提供的API层面的互斥锁,需要lock()和unlock()方法配合try/finally语句块来完成。
1.Synchronized
Synchronized进过编译,会在同步块的前后分别形成monitorenter和monitorexit这个两个字节码指令。在执行monitorenter指令时,首先要尝试获取对象锁。如果这个对象没被锁定,或者当前线程已经拥有了那个对象锁,把锁的计算器加1,相应的,在执行monitorexit指令时会将锁计算器就减1,当计算器为0时,锁就被释放了。如果获取对象锁失败,那当前线程就要阻塞,直到对象锁被另一个线程释放为止。
public class SynDemo{
public static void main(String[] arg){
Runnable t1=new MyThread();
new Thread(t1,"t1").start();
new Thread(t1,"t2").start();
}
}
class MyThread implements Runnable {
@Override
public void run() {
synchronized (this) {
for(int i=0;i<10;i++)
System.out.println(Thread.currentThread().getName()+“:”+i);
}
}
}
查看字节码指令:
2.ReentrantLock
由于ReentrantLock是java.util.concurrent包下提供的一套互斥锁,相比Synchronized,ReentrantLock类提供了一些高级功能,主要有以下3项:
1.等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于Synchronized来说可以避免出现死锁的情况。
2.公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁非公平锁,ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性能不是很好。
3.锁绑定多个条件,一个ReentrantLock对象可以同时绑定对个对象。
ReentrantLock的用法如下:
public class SynDemo{
public static void main(String[] arg){
Runnable t1=new MyThread();
new Thread(t1,“t1”).start();
new Thread(t1,“t2”).start();
}
}
class MyThread implements Runnable {
private Lock lock=new ReentrantLock();
public void run() {
lock.lock();
try{
for(int i=0;i<5;i++)
System.out.println(Thread.currentThread().getName()+":"+i);
}finally{
lock.unlock();
}
}
}
.
对ReentrantLock的源码分析这有一篇很好的文章http://www.blogjava.net/zhanglongsr/articles/356782.html
3.7.4现在有T1、T2、T3三个线程,怎样保证T2在T1执行完后执行,T3在T2执行完后执行?使用Join
public class TestJoin
{
public static void main(String[] args)
{
Thread t1 = new MyThread(“线程1”);
Thread t2 = new MyThread(“线程2”);
Thread t3 = new MyThread(“线程3”);
try
{
//t1先启动 t1.start();
t1.join();
//t2 t2.start();
t2.join();
//t3 t3.start();
t3.join();
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
}
class MyThread extend Thread{
public MyThread(String name){
setName(name);
}
@Override
public void run()
{
for (int i = 0; i < 5; i++)
{
System.out.println(Thread.currentThread().getName()+”: “+i);
try
{
Thread.sleep(100);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
}
}
还有一种方式,在t3开始前join t2,在t2开始前join t1
public class TestJoin2
{
public static void main(String[] args)
{
final Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("t1");
}
});
final Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
try {
//引用t1线程,等待t1线程执行完 t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t2");
}
});
Thread t3 = new Thread(new Runnable() {
@Override
public void run() {
try {
//引用t2线程,等待t2线程执行完 t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t3");
}
});
t3.start();
t2.start();
t1.start();
}
}
3.7.5如果同步块内的线程抛出异常会发生什么?
这个问题坑了很多Java程序员,若你能想到锁是否释放这条线索来回答还有点希望答对。无论你的同步块是正常还是异常退出的,里面的线程都会释放锁,所以对比锁接口我更喜欢同步块,因为它不用我花费精力去释放锁,该功能可以在finally block里释放锁实现。
3.7.6 当一个线程进入一个对象的一个synchronized方法后,其它线程是否可进入此对象的其它方法?
分两种情况
1):进入此对象的非同步方法
答案:可以
2):进入此对象的同步方法
答案:不可以
第一种情况原代码
/**
*/
package thread;
/**
-
@author Administrator
*/
public class TestClass {
/**
* @param args
*/
public static void main(String[] args) {
TestClass tc = new TestClass();
Thread1 t1 = tc.new Thread1(tc);
t1.start();
Thread2 t2 = tc.new Thread2(tc);
t2.start();
}
class Thread1 extends Thread{
TestClass tc = null;
public Thread1(TestClass tc) {
this.tc = tc;
}
@Override
public void run() {
tc.method1();
}
}
class Thread2 extends Thread{
TestClass tc = null;
public Thread2(TestClass tc) {
this.tc = tc;
}
@Override
public void run() {
// TODO Auto-generated method stub
tc.method2();
}
}
public synchronized void method1(){
System.out.println("method1");
try {
Thread.sleep(1000*10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void method2(){
System.out.println("method2");
}
}
第二种情况原代码
/**
*/
package thread;
/**
-
@author Administrator
*/
public class TestClass {
/**
* @param args
*/
public static void main(String[] args) {
TestClass tc = new TestClass();
Thread1 t1 = tc.new Thread1(tc);
t1.start();
Thread2 t2 = tc.new Thread2(tc);
t2.start();
}
class Thread1 extends Thread{
TestClass tc = null;
public Thread1(TestClass tc) {
this.tc = tc;
}
@Override
public void run() {
tc.method1();
}
}
class Thread2 extends Thread{
TestClass tc = null;
public Thread2(TestClass tc) {
this.tc = tc;
}
@Override
public void run() {
// TODO Auto-generated method stub
tc.method2();
}
}
public synchronized void method1(){
System.out.println("method1");
try {
Thread.sleep(1000*10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public synchronized void method2(){
System.out.println("method2");
}
}
3.7.7使用 synchronized 修饰静态方法和非静态方法有什么区别
synchronized在静态方法上表示调用前要获得类的锁,而在非静态方法上表示调用此方法前要获得对象的锁。
public class StaticSynDemo {
private static String a=“test”;
//等同于方法print2
public synchronized void print1(String b){ //调用前要取得StaticSynDemo实例化后对象的锁
System.out.println(b+a);
}
public void print2(String b){
synchronized (this) {//取得StaticSynDemo实例化后对象的锁
System.out.println(b+a);
}
}
//等同于方法print4
public synchronized static void print3(String b){//调用前要取得StaticSynDemo.class类的锁
System.out.println(b+a);
}
public static void print4(String b){
synchronized (StaticSynDemo.class) { //取得StaticSynDemo.class类的锁
System.out.println(b+a);
}
}
}
3.7.8Java Concurrency API 中 的 Lock 接口是什么?对比同步它有什么优势
Lock接口比同步方法和同步块提供了更具扩展性的锁操作。他们允许更灵活的结构,可以具有完全不同的性质,并且可以支持多个相关类的条件对象。
它的优势有:
可以使锁更公平
可以使线程在等待锁的时候响应中断
可以让线程尝试获取锁,并在无法获取锁的时候立即返回或者等待一段时间
可以在不同的范围,以不同的顺序获取和释放锁
3.7.9 Java中的ReadWriteLock是什么?
一般而言,读写锁是用来提升并发程序性能的锁分离技术的成果。Java中的ReadWriteLock是Java 5 中新增的一个接口,一个ReadWriteLock维护一对关联的锁,一个用于只读操作一个用于写。在没有写线程的情况下一个读锁可能会同时被多个读线程 持有。写锁是独占的,你可以使用JDK中的ReentrantReadWriteLock来实现这个规则,它最多支持65535个写锁和65535个读 锁。
3.7.10 Java的锁机制有什么用?简述Hibernate的悲观锁和乐观锁机制
有些业务逻辑在执行过程中要求对数据进行排他性的访问,于是需要通过一些机制保证在此过程中数据被锁住不会被外界修改,这就是所谓的锁机制。
Hibernate支持悲观锁和乐观锁两种锁机制。悲观锁,顾名思义悲观的认为在数据处理过程中极有可能存在修改数据的并发事务(包括本系统的其他事务或来自外部系统的事务),于是将处理的数据设置为锁定状态。悲观锁必须依赖数据库本身的锁机制才能真正保证数据访问的排他性。乐观锁,顾名思义,对并发事务持乐观态度(认为对数据的并发操作不会经常性的发生),通过更加宽松的锁机制来解决由于悲观锁排他性的数据访问对系统性能造成的严重影响。最常见的乐观锁是通过数据版本标识来实现的,读取数据时获得数据的版本号,更新数据时将此版本号加1,然后和数据库表对应记录的当前版本号进行比较,如果提交的数据版本号大于数据库中此记录的当前版本号则更新数据,否则认为是过期数据无法更新。Hibernate中通过Session的get()和load()方法从数据库中加载对象时可以通过参数指定使用悲观锁;而乐观锁可以通过给实体类加整型的版本字段再通过XML或@Version注解进行配置。
提示:使用乐观锁会增加了一个版本字段,很明显这需要额外的空间来存储这个版本字段,浪费了空间,但是乐观锁会让系统具有更好的并发性,这是对时间的节省。因此乐观锁也是典型的空间换时间的策略。
3.7.11 死锁是怎么导致的,如果解决呢
产生死锁的四个必要条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之
一不满足,就不会发生死锁。
死锁的解除与预防:
理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和
解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确
定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态
的情况下占用资源。因此,对资源的分配要给予合理的规划
3.8 算法
3.8.1 冒泡和选择排序
冒泡排序
public void bubbleSort(int[] arr) { //从小到大
int temp = 0;
for(int i = 0; i < arr.length -1; i++){ //控制趟数,到倒数第二个为止
for(int j = arr.length-1; j>i; j–){ //从最后一个值开始冒泡,将后面的小值与前面的大值进行交换,并且保证循环到前面已经排序完的索引为止
if(arr[j-1] > arr[j]){
temp = arr[j];
arr[j] = arr[j-1];
arr[j-1] = temp;
}
}
}
}
选择排序:
public void selectionSort(int[] arr){
int temp = 0;
int k = 0; //存储最小值的索引
for(int i = 0; i<arr.lengrh – 1; i++){ //控制趟数,到倒数第二个为止
k = i;
for(int j = i; j<arr.length;j++){ //将第一个数默认为最小值,将其索引赋值给k,从k索引开始,将后面每个数与k索引对应的值比较,如果值小了,就将其索引赋值给k
if(arr[j] < arr[k]){
k = j;
}
}
//遍历完后,k就指向了最小的值,将其与i对应的值交换(也可 以先做个判断,判断k的索引是否有变化,无变化可以不交换)
temp = arr[k];
arr[k] = arr[i];
arr[i] = temp;
}
}
3.8.2 利用算法写出一个非0整数的阶乘
Public int getFactorialSum(int n){
if(n1||n0){
return 1;
}else{
return getFactorialSum (n-1)*n;
}
}
3.9 cookie
3.9.1二、cookie的大小,一个站点可以存储多少个cookie
3.10 java跨平台
简单讲一下java的跨平台原理
由于各操作系统(windows,liunx等)支持的指令集,不是完全一致的。就会让我们的程序在不同的操作系统上要执行不同程序代码。Java开发了适用于不同操作系统及位数的java虚拟机来屏蔽个系统之间的差异,提供统一的接口。对于我们java开发者而言,你只需要在不同的系统上安装对应的不同java虚拟机、这时你的java程序只要遵循java规范,就可以在所有的操作系统上面运行java程序了。
Java通过不同的系统、不同版本、不同位数的java虚拟机(jvm),来屏蔽不同的系统指令集差异而对外体统统一的接口(java API),对于我们普通的java开发者而言,只需要按照接口开发即可。如果我系统需要部署到不同的环境时,只需在系统上面按照对应版本的虚拟机即可。
二 Web部分
2.1 jsp9大内置对象
答案:
不需要创建,就可以在 <%= %>和<% %> 直接使用。 由tomcat创建
1、request – HttpServletRequest 客户端请求 包括从get/post请求传递过来的参数
请求对象,可以用于获得客户机的信息,也可以作为域对象来使用,使用request保存的数据在一次请求范围内有效
2、response – HttpServletResponse 网页传回客户端的反映 是响应对象,代表的是从服务器向浏览器响应数据.
3、out – javax.servlet.jsp.jspWriter 传送响应的输出流 JSPWriter是用于向页面输出内容的对象
4、session – HttpSession 与请求关联的会话
代表的是一次会话,可以用于保存用户的私有的信息,也可以作为域对象使用,使用session保存的数据在一次会话范围有效
5、application – ServletContext 代码片段的运行环境
代表整个应用范围,使用这个对象保存的数据在整个web应用中都有效
6、page – Object 相当于this,代表当前页面 jsp网页本身 (JSP被翻译成Servlet的对象的引用.)
7、config – ServletConfig 代码片段配置对象 指的是ServletConfig用于JSP翻译成Servlet后 获得Servlet的配置的对象.
8、exception –
-
0-9 ↩︎
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/143211.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
