大家好,又见面了,我是你们的朋友全栈君。
我家门前有两棵树,一棵是二叉树,另一棵也是二叉树。
遍历一棵二叉树常用的有四种方法,前序(PreOrder)、中序(InOrder)、后序(PastOrder)还有层序(LevelOrder)。
前中后序三种遍历方式都是以根节点相对于它的左右孩子的访问顺序定义的。例如根->左->右便是前序遍历,左->根->右便是中序遍历,左->右->根便是后序遍历。
而层序遍历是一层一层来遍历的。
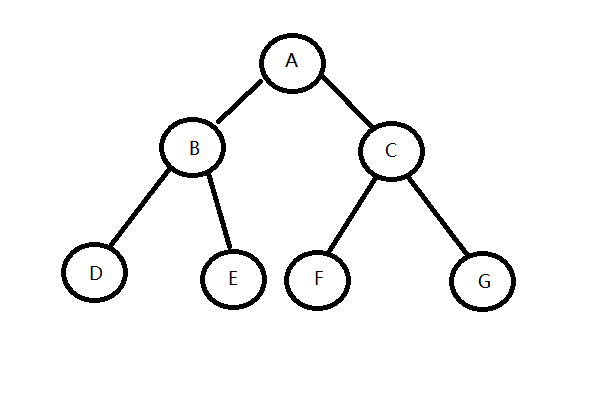
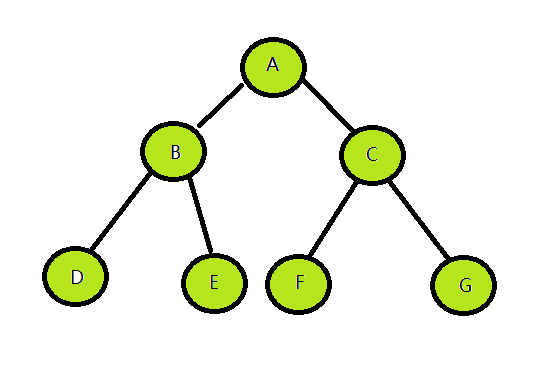
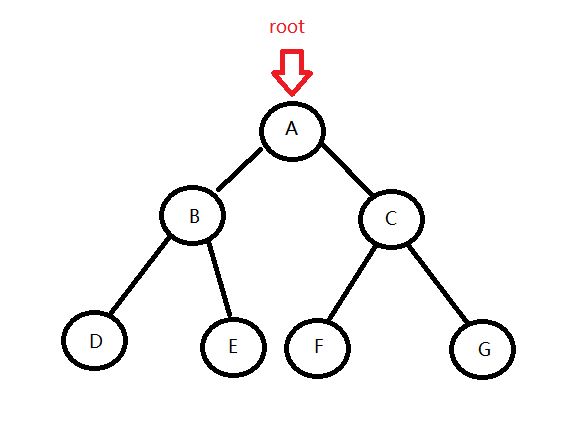
树的前中后序遍历是个递归的定义,在遍历到根节点的左/右子树时,也要遵循前/中/后序遍历的顺序,例如下面这棵树:

前序遍历:ABDECFG
中序遍历:DBEAFCG
后序遍历:DEBFGCA
层序遍历:ABCDEFG
树的结点结构体声明如下:
语言:C语言(为了省事用到了C++的栈,因为C语言要用栈的话要自己重新写一个出来,就偷了个懒)
编译器:VS
typedef char DataType;
typedef struct TreeNode{
DataType data;
struct TreeNode *left;
struct TreeNode *right;
}TreeNode;前序遍历(先序遍历)
对于一棵树的前序遍历,递归的写法是最简单的(写起来),就是将一个大的问题转化为几个小的子问题,直到子问题可以很容易求解,最后将子问题的解组合起来就是大问题的解。
前序访问的递归写法
先放代码,如果看完觉得不太清楚可以看看下面的详细步骤图解。
void PreOrder(const TreeNode *root)
{
if (root == NULL) //若结点为空
{
printf("# ");
return;
}
printf("%c ", root->data); //输出根节点的值
PreOrder(root->left); //前序访问左子树
PreOrder(root->right); //前序访问右子树
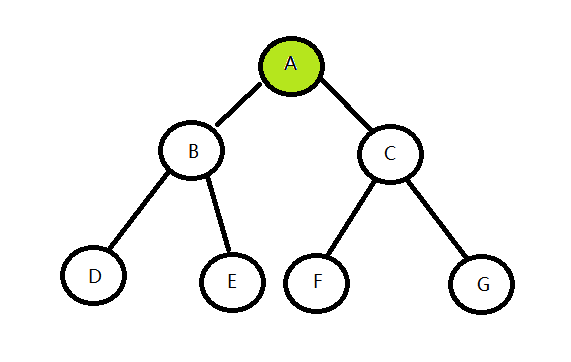
}比如说还是上面的这颗树:
- 访问根节点
- 访问左子树
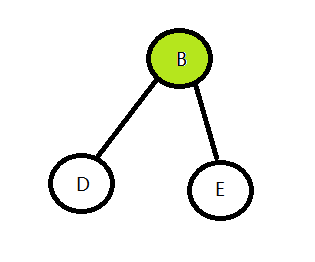
走到这里之后发现根节点的左孩子还是一棵子树,那就将访问这棵子树看作是遍历整颗树的一个子问题,遍历这棵子树的方法和遍历整颗树的方法是一样的。
然后继续访问它的左子树:
为了理解起来方便一点,我在这里加上了它的两个为空的左右孩子
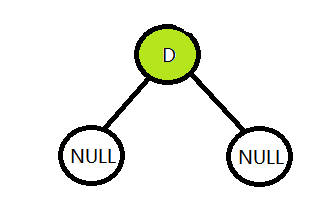
然后发现这(可能)还是一棵子树,就继续用这种方法来对待这颗子树,就是继续访问它的左子树:
发现这是一个空节点,那就直接返回,去访问它的右子树:
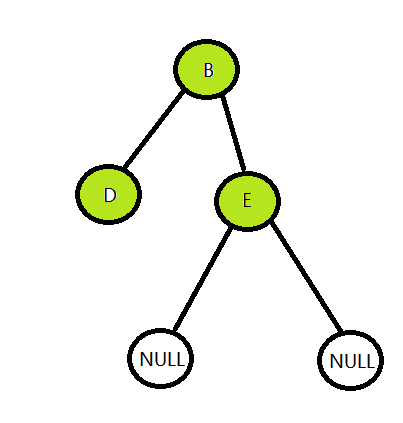
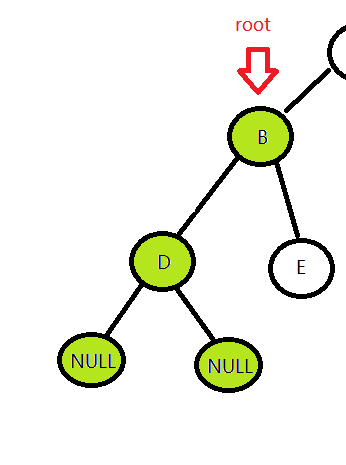
发现还是一个空节点,那么继续返回,这时候D和它的左右孩子结点都访问过了,继续返回,应该访问B的右子树了。
然后就和D结点一样的处理方法,->左孩子,发现是空,返回->右孩子,发现还是空,继续返回,发现这时候B的左右孩子都访问过了,继续返回。 - 访问右子树
然后和处理A的左子树的方法一样,最后访问到G结点的右子树时,发现是空,就返回,这时候树的所有节点都已经访问过了,所以可以一路返回到A结点的右子树完的地方,整个递归就结束了。
最后输出的前序访问序列便是:ABDECFG


前序访问的非递归写法
还是先上代码:
void PreOrderLoop(TreeNode *root)
{
std::stack<TreeNode *> s;
TreeNode *cur, *top;
cur = root;
while (cur != NULL || !s.empty())
{
while (cur != NULL)
{
printf("%c ", cur->data);
s.push(cur);
cur = cur->left;
}
top = s.top();
s.pop();
cur = top->right;
}
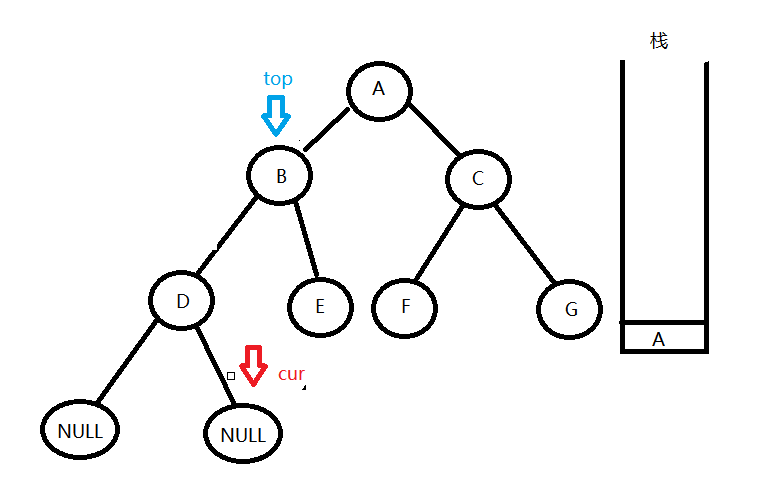
}非递归的写法比递归写法要麻烦一点,要用到栈来存储树的结点,在理解非递归方法的时候要重点理解栈中保存的元素的共同点是什么,在前序访问中,栈中元素都是自己和自己的左孩子都访问过了,而右孩子还没有访问到的节点,如果不太懂可以看下面的详细步骤图解。
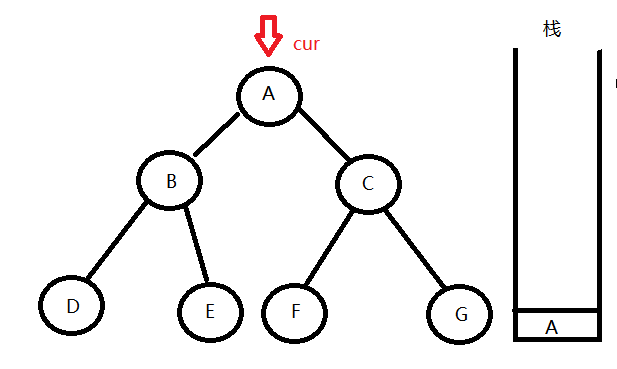
- 首先我们要用一个指针(cur)来指向当前访问的结点
发现这个节点不为空,就将它的数据输出,然后将这个节点的地址(图上的栈中写了节点的值是为了便于理解,实际上栈中保存的是节点地址)压栈。
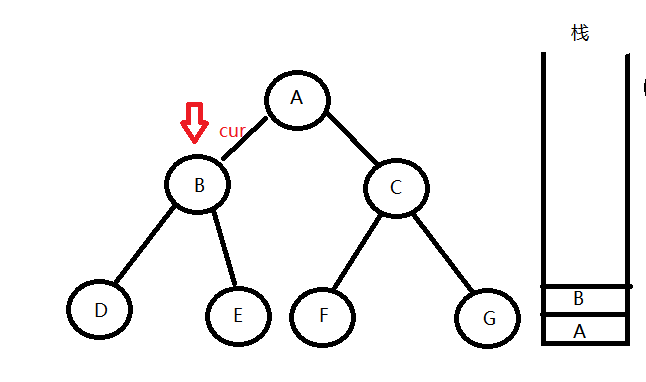
再去访问它的左子树,发现左孩子结点依旧不为空,继续输出并压栈。
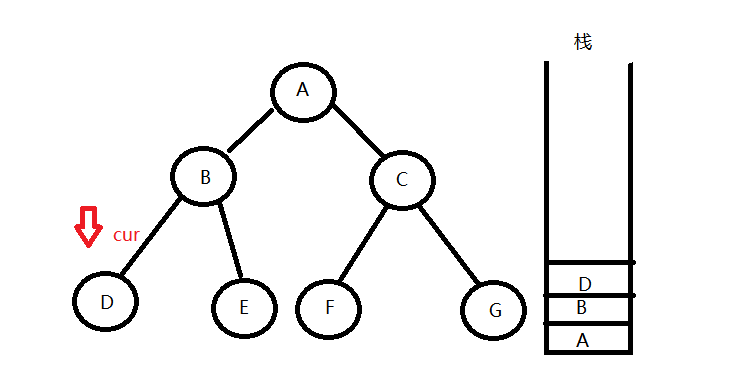
同理压栈D节点
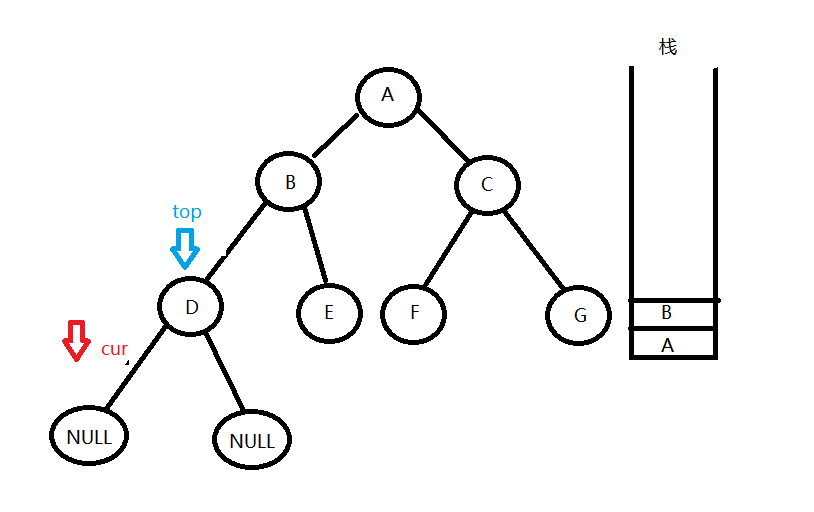
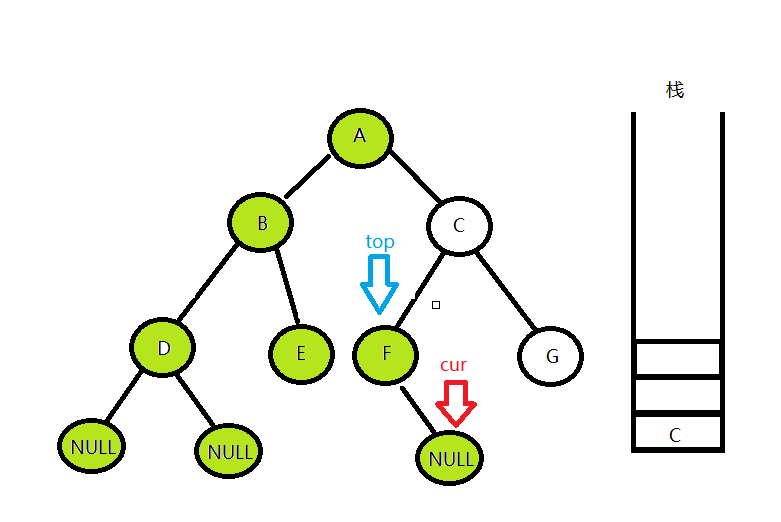
然后访问D的左孩子,发现为空,便从栈中拿出栈顶结点top,让cur = top->right,便访问到了D的右孩子。
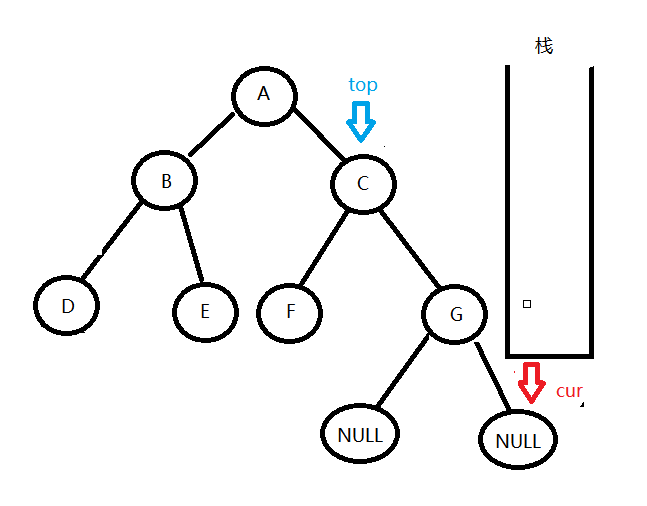
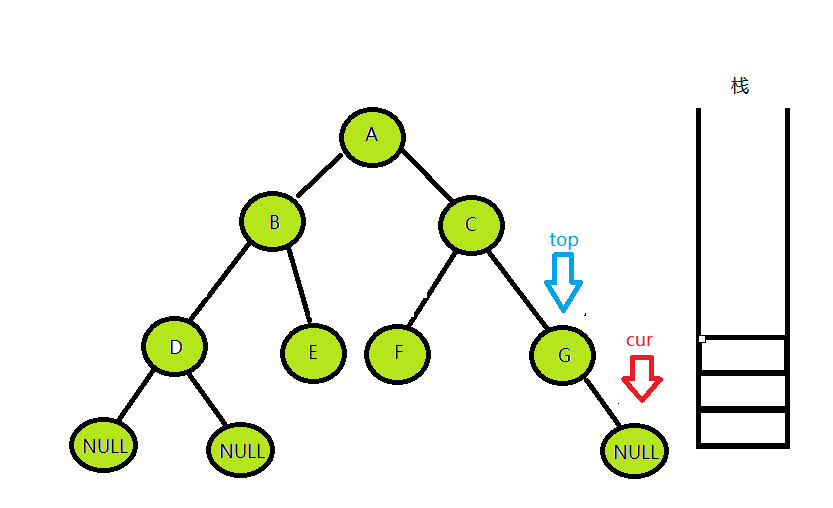
发现D的右孩子还是为空,这个看一下栈,发现栈不为空,说明还存在右孩子没被访问过的节点,就继续从栈中拿出栈顶结点top,让cur = top->right,便访问到了B的右孩子。
B的右孩子处理方法和D一样,然后再从栈中拿出A节点,去访问A的右孩子C,在访问到G节点的右孩子之后,发现当前节点cur为空,栈中也没有元素可以取出来了,这时候就代表整棵树都被访问过了,便结束循环。
最后输出的前序访问序列便是:ABDECFG

中序遍历
对于一棵树的中序遍历,和前序一样,可以分为递归遍历和非递归遍历,递归遍历是相对简单的,还是子问题思想,将一个大问题分解,直到可以解决,最后解决整个大问题。
中序遍历的递归写法
还是先上代码:
void InOrder(const TreeNode *root)
{
if (root == NULL) //判断节点是否为空
{
printf("# ");
return;
}
InOrder(root->left); //中序遍历左子树
printf("%c ", root->data); //访问节点值
InOrder(root->right); //中序遍历右子树
}
- 从根节点进入
- 发现根节点不为空,访问左子树
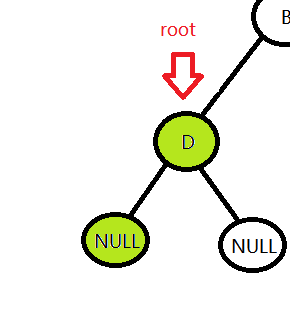
发现不为空,继续访问左子树
发现不为空,继续访问左子树
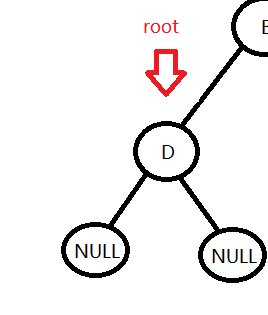
这时root为空了,就返回去访问它的根节点,刚才的访问只是路过,并没有真正地遍历节点的信息,在返回途中才是真正地遍历到了节点的信息。
访问到了D节点,下来要访问的是D的右孩子,因为D的左孩子已经访问过了。
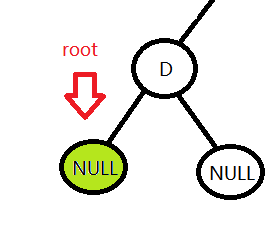
发现还是空,就返回,而它的根节点D也访问过了,那么就继续返回,该访问D节点的父节点B了。
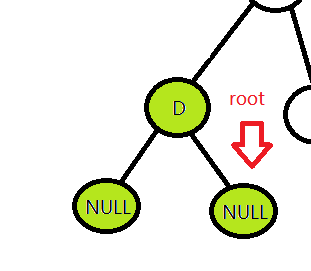
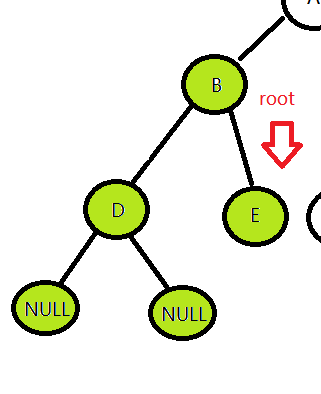
B访问过后下来要访问的是B的右孩子,因为是从B的左子树回来的路,B的左孩子已经访问过了。
然后和访问D一样,->左孩子,为空,返回访问根节点E,->右孩子,为空(这部分就不画了,和D节点的访问是一样的),最后返回,B已经访问过了,就继续返回,至此,整颗树的左子树访问完了。
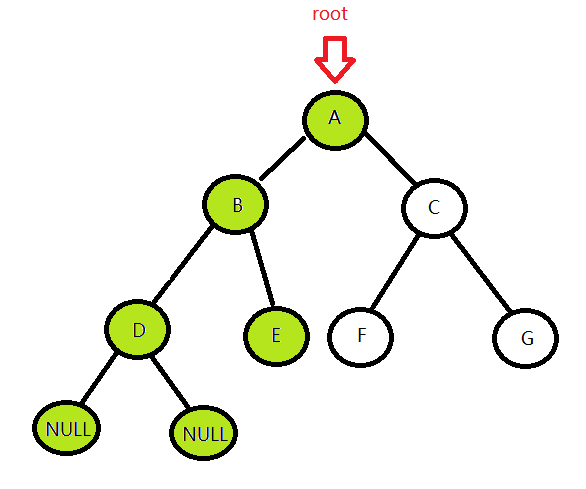
3. 访问B的根节点A
4. 遍历A的右子树
遍历右子树的过程和左子树一样,还是左->根->右的中序遍历下去,直到遍历到G的右孩子,发现为空,就返回,因为右子树都遍历过了,所以可以一直返回到root为A节点的那一层递归,整个遍历结束。
最后输出的中序访问序列为:DBEAFCG
非递归写法
中序访问的非递归写法和前序一样,都要用到一个栈来辅助存储,不一样的地方在于前序访问时,栈中保存的元素是右子树还没有被访问到的节点的地址,而中序访问时栈中保存的元素是节点自身和它的右子树都没有被访问到的节点地址。
先上代码:
void InOrderLoop(TreeNode *root)
{
std::stack<TreeNode *> s;
TreeNode *cur;
cur = root;
while (cur != NULL || !s.empty())
{
while (cur != NULL)
{
s.push(cur);
cur = cur->left;
}
cur = s.top();
s.pop();
printf("%c ", cur->data);
cur = cur->right;
}
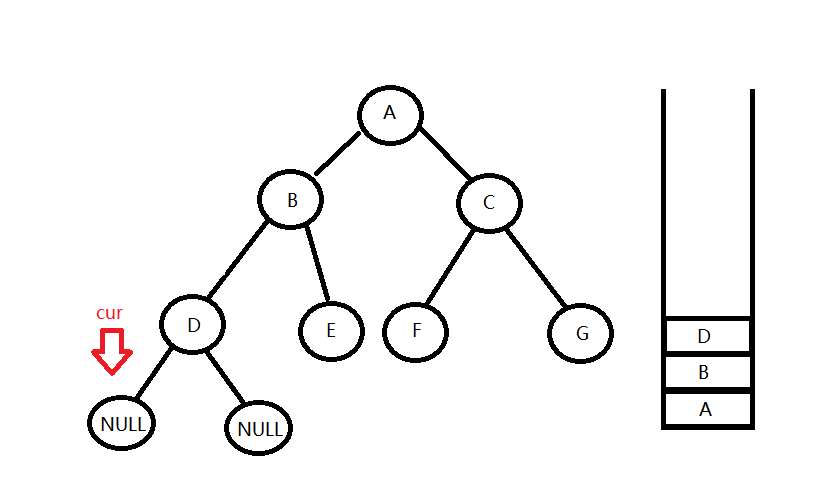
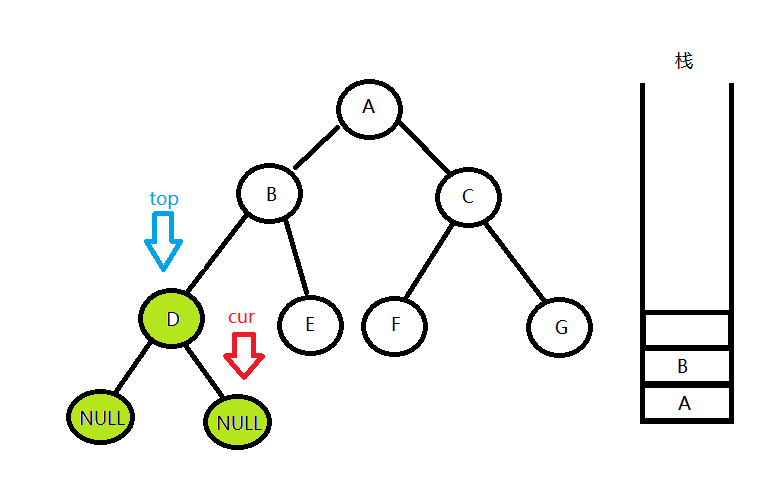
}- cur指针一路沿着最左边往下访问,路过的节点全部压栈,直到遇到空节点
- 从栈中取出栈顶节点top,输出栈顶结点的值并使cur = top->right,从第一步开始去遍历top的右子树。
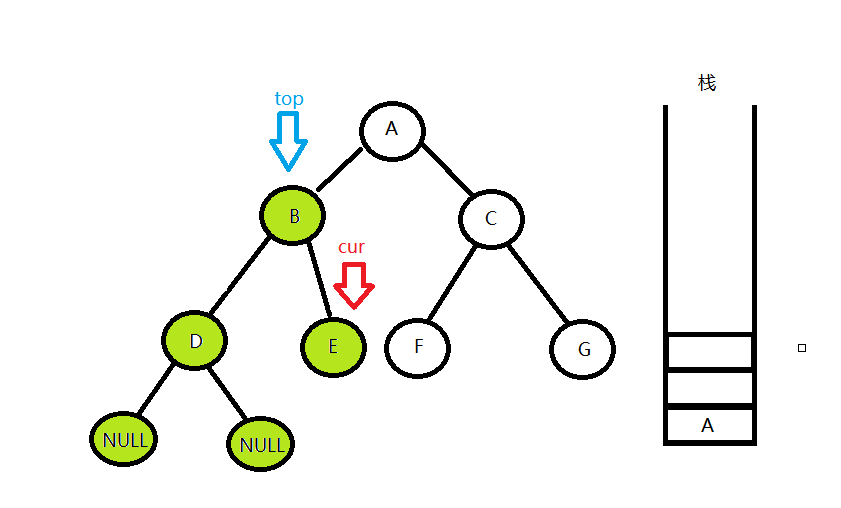
遍历完之后,cur走到了D节点的右孩子,发现cur 为空,但栈中还有元素,就重复第二步
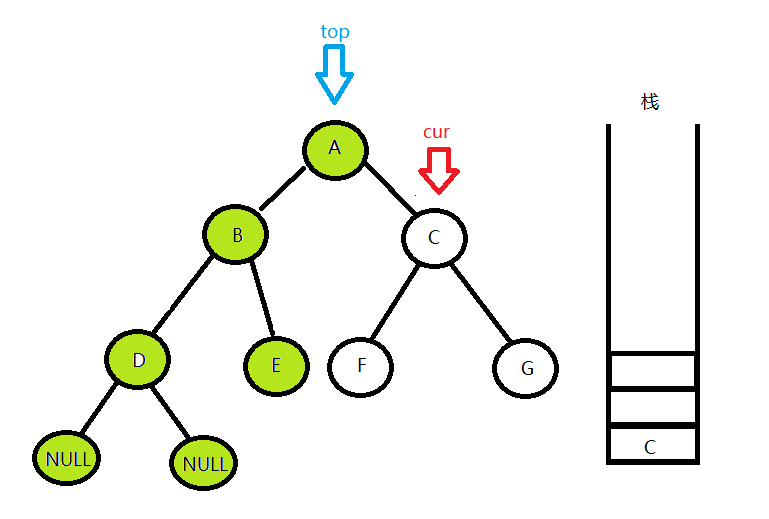
这时候,cur走到了E节点的右孩子,发现cur 为空,但栈中还有元素,就继续重复第二步,之后cur = top->right,cur指针继续去遍历A节点的右子树,从第一步开始
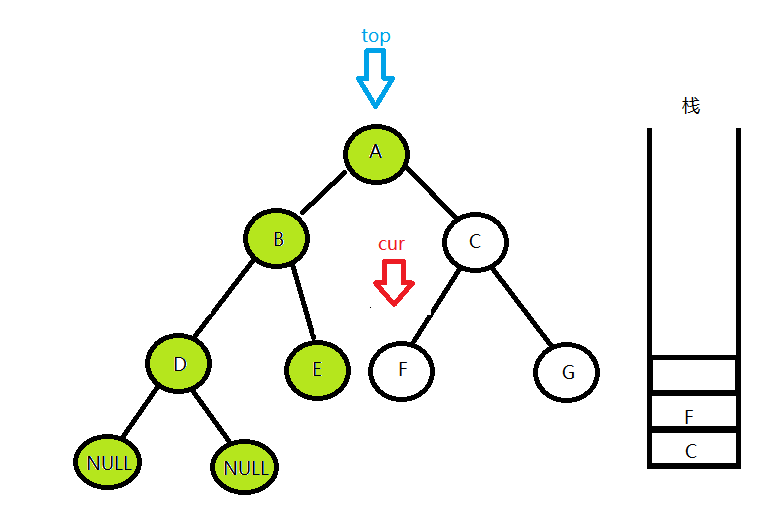
访问到F的左孩子节点发现是空,这时候栈中还有元素,就重复第二步
照这个规则依次访问下去,最后会访问到G节点的右孩子,这时候cur为空,栈也空了,就代表所有节点已经遍历完了,就结束循环,遍历完成。
最后输出的中序访问序列为:DBEAFCG
后序遍历
后序遍历还是分递归版本和非递归版本,后序遍历的递归版本和前序中序很相似,就是输出根节点值的时机不同,而后序遍历的非递归版本则要比前序和中序的要难一些,因为在返回根节点时要分从左子树返回和右子树返回两种情况,从左子树返回时不输出,从右子树返回时才需要输出根节点的值。
递归写法
先上代码:
void PostOrder(TreeNode *root)
{
if (root == NULL)
{
printf("# ");
return;
}
PostOrder(root->left);
PostOrder(root->right);
printf("%c ", root->data);
}后序遍历的递归版本和前中序非常相似,就是输出根节点值的时机不同,详细图解这里就不画了,可以联系前中序的递归版本来理解。
后序遍历的非递归写法
后序遍历的非递归同样要借助一个栈来保存元素,栈中保存的元素是它的右子树和自身都没有被遍历到的节点,与中序遍历不同的是先访问右子树,在回来的时候再输出根节点的值。需要多一个last指针指向上一次访问到的节点,用来确认是从根节点的左子树返回的还是从右子树返回的。
先上代码:
void PostOrderLoop(TreeNode *root)
{
std::stack<TreeNode *> s;
TreeNode *cur, *top, *last = NULL;
cur = root;
while (cur != NULL || !s.empty())
{
while (cur != NULL)
{
s.push(cur);
cur = cur->left;
}
top = s.top();
if (top->right == NULL || top->right == last){
s.pop();
printf("%c ", top->data);
last = top;
}
else {
cur = top->right;
}
}
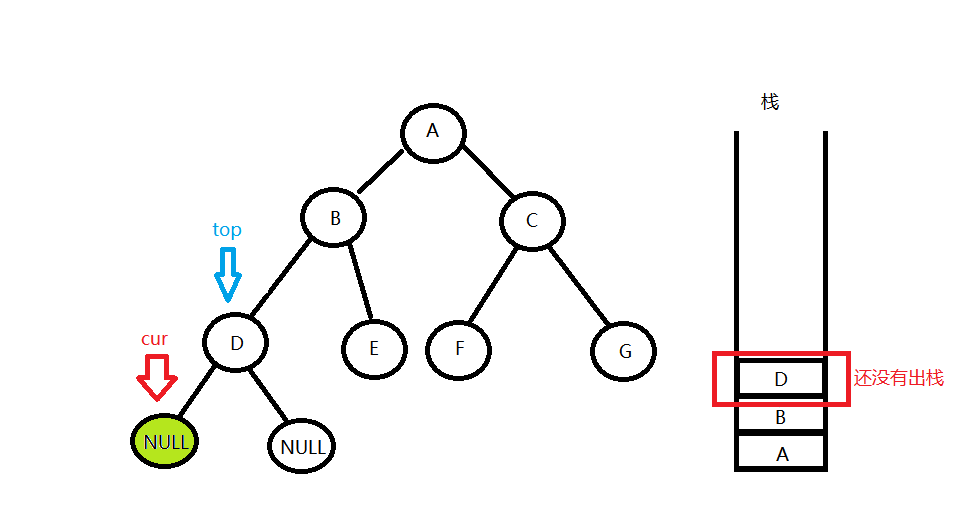
}- 还是沿着左子树一路往下走,将路过的节点都压栈,直到走到空节点。
- 然后从栈中看一下栈顶元素(只看一眼,用top指针记下,先不出栈),如果top节点没有右子树,或者last等于top的右孩子,说明top的右子树不存在或者遍历过了,就输出top节点的值,并将栈顶元素pop掉(出栈),反之则是从左子树回到根节点的,接下来要去右子树。
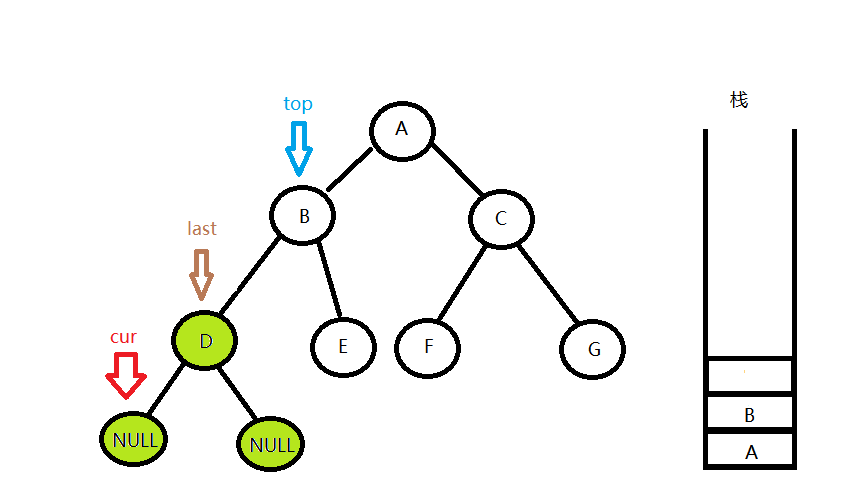
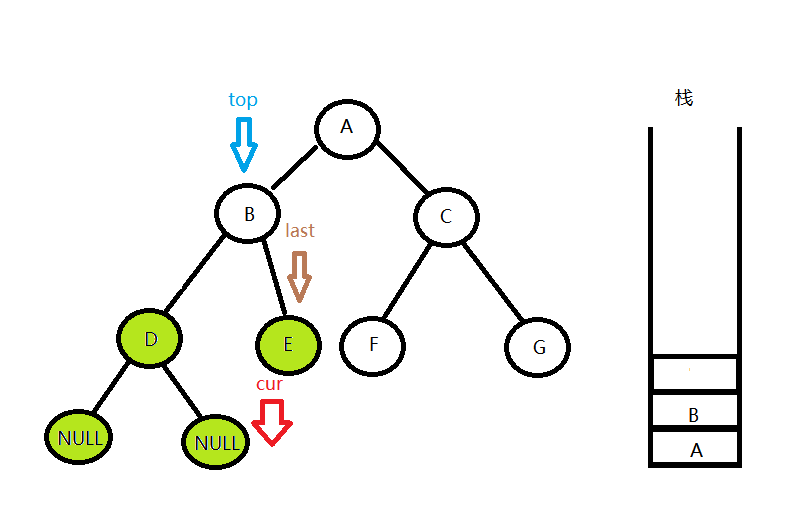
如图,top的右孩子为空,说明右子树不存在,就可以输出top的值并pop掉栈顶了,这时候用last指针记下top指向的节点,代表上一次处理的节点。(这一过程cur始终没有动,一直指向空)
继续从栈顶看一个元素记为top,然后发现top的右孩子不为空,而且last也不等于top->right,就使cur = top->right,回到第一步,用同样的方法来处理top的右子树,下一次回来的时候,last指针指向的是E节点。
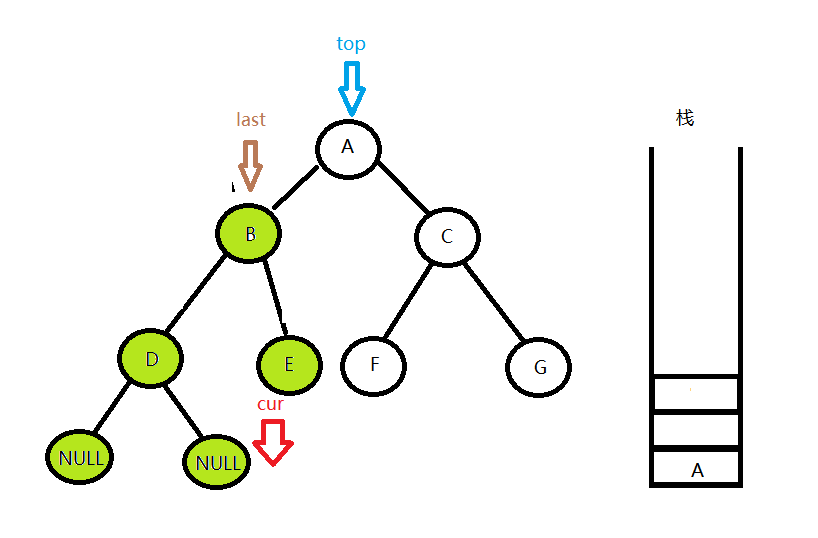
这时候发现top的右孩子不为空,但是last等于top->right,说明top的右子树遍历完成,下一步就要输出top的值并且将这个节点出栈,下一次再从栈中看一个栈顶元素A即为top。
这时候再比较,发现top的right不为空,而且last也不等于top->right,说明top有右子树并且还没有遍历过,就让cur = top->right,回到第一步用同样的方法来遍历A的右子树。
到最后,cur访问到了G的左孩子,而top也一路出栈到了A节点,发现cur为空,并且栈中也为空,这时候便代表整个树已经遍历完成,结束循环。

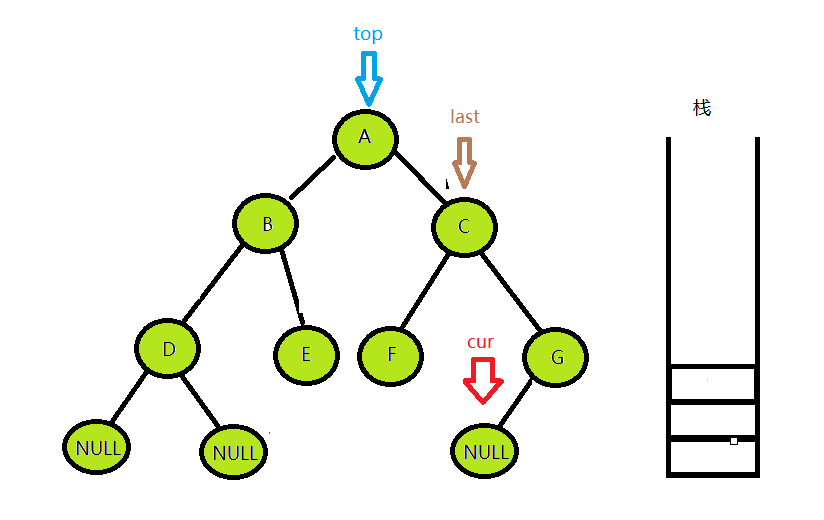
最后输出的中序访问序列为:DEBFGCA
层序遍历
层序遍历是比较接近人的思维方式的一种遍历方法,将二叉树的每一层分别遍历,直到最后的叶子节点被全部遍历完,这里要用到的辅助数据结构是队列,队列具有先进先出的性质。
上代码:
void LevelOrder(TreeNode *root)
{
std::queue<TreeNode *> q;
TreeNode *front;
if (root == NULL)return;
q.push(root);
while (!q.empty())
{
front = q.front();
q.pop();
if (front->left)
q.push(front->left);
if (front->right)
q.push(front->right);
printf("%c ", front->data);
}
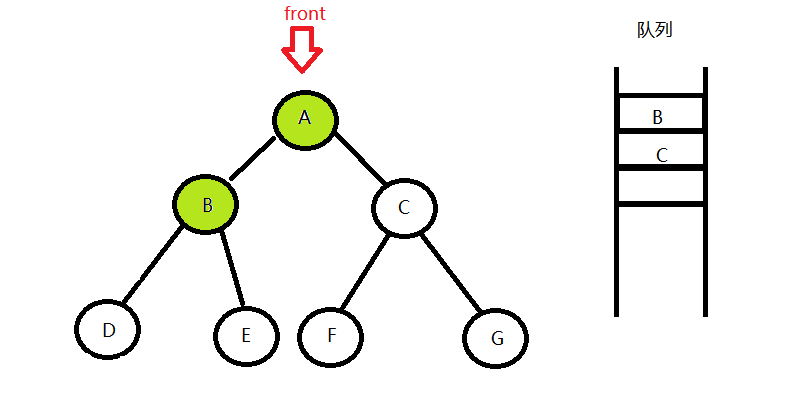
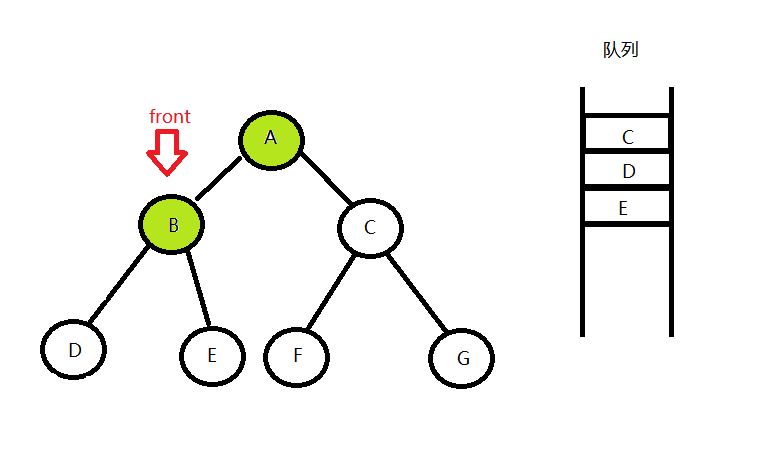
}层序遍历的思路是,创建一个队列,先将根节点(A)入队,然后用front指针将根节点记下来,再将根节点出队,接下来看front节点(也就是刚才的根节点)有没有左孩子或右孩子,如果有,先左(B)后右(C)入队,最后输出front节点的值,只要队列还不为空,就说明还没有遍历完,就进行下一次循环,这时的队头元素(front)则为刚才入队的左孩子(B),然后front出队,再把它的左右孩子拉进来(如果有),因为队列的先进先出性质,B的左右孩子DE是排在C后面的,然后输出B,下一次循环将会拉人C的左右孩子FG,最后因为FG没有左右孩子,一直出队,没有入队元素,队列迟早会变为空,当队列为空时,整颗树就层序遍历完成了,结束循环。
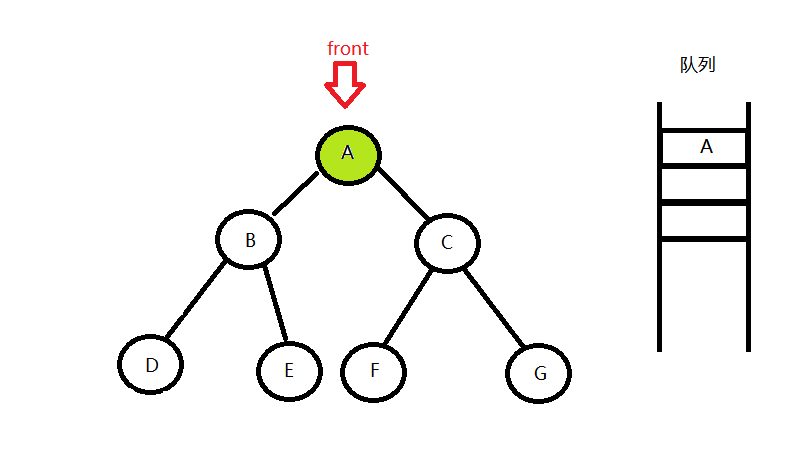
- 根节点入队,并用front指针标记
- 队头出队,并将左右孩子拉进队列
重复1,2
- 直到队列为空
这时候便代表整个树遍历完成,结束循环。
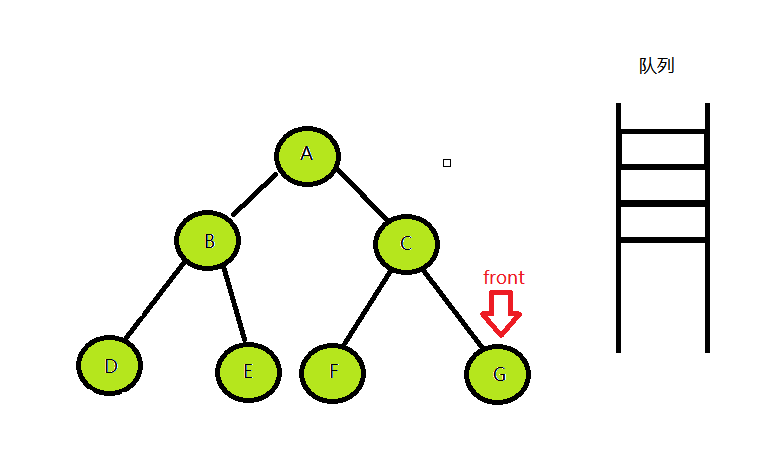
最后输出的层序访问序列为:ABCDEF
编辑于2018-8-27 16:55:37
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/143189.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
