大家好,又见面了,我是你们的朋友全栈君。
Python 根据AIC准则定义向前逐步回归进行变量筛选(二)
AIC简介
AIC即赤池值,是衡量模型拟合优良性和模型复杂性的一种标准,在建立多元线性回归模型时,变量过多,且有不显著的变量时,可以使用AIC准则结合逐步回归进行变量筛选。AICD数学表达式如下:
A I C = 2 p + n ( l o g ( S S E / n ) ) AIC=2p+n(log(SSE/n)) AIC=2p+n(log(SSE/n))
其中, p p p是进入模型当中的自变量个数, n n n为样本量, S S E SSE SSE是残差平方和,在 n n n固定的情况下, p p p越小, A I C AIC AIC越小, S S E SSE SSE越小, A I C AIC AIC越小,而 p p p越小代表着模型越简洁, S S E SSE SSE越小代表着模型越精准,即拟合度越好,综上所诉, A I C AIC AIC越小,即模型就越简洁和精准。
逐步回归
逐步回归分为三种,分别是向前逐步回归,向后逐步回归,逐步回归。向前逐步回归的特点是将自变量一个一个当如模型中,每当放入一个变量时,都利用相应的检验准则检验,当加入的变量不能使得模型变得更优良时,变量将会被剔除,如此不断迭代,直到没有适合的新变量加入为止。向后逐步回归的特点是,将所有变量都放入模型之后,一个一个的剔除变量,将某一变量拿出模型而使得模型更优良时,将会剔除此变量。如此反复迭代,直到没有合适的变量剔除为止。逐步回归则是结合了以上的向前和向后逐步回归的特点。
继上一篇的代码
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_california_housing as fch #加载加利福尼亚房屋价值数据
#加载线性回归需要的模块和库
import statsmodels.api as sm #最小二乘
from statsmodels.formula.api import ols #加载ols模型
data=fch() #导入数据
house_data=pd.DataFrame(data.data) #将自变量转换成dataframe格式,便于查看
house_data.columns=data.feature_names #命名自变量
house_data.loc[:,"value"]=data.target #合并自变量,因变量数据
house_data.shape #查看数据量
house_data.head(10) #查看前10行数据
#分训练集测试集
import random
random.seed(123) #设立随机数种子
a=random.sample(range(len(house_data)),round(len(house_data)*0.3))
house_test=[]
for i in a:
house_test.append(house_data.iloc[i])
house_test=pd.DataFrame(house_test)
house_train=house_data.drop(a)
定义向前逐步回归函数
#定义向前逐步回归函数
def forward_select(data,target):
variate=set(data.columns) #将字段名转换成字典类型
variate.remove(target) #去掉因变量的字段名
selected=[]
current_score,best_new_score=float('inf'),float('inf') #目前的分数和最好分数初始值都为无穷大(因为AIC越小越好)
#循环筛选变量
while variate:
aic_with_variate=[]
for candidate in variate: #逐个遍历自变量
formula="{}~{}".format(target,"+".join(selected+[candidate])) #将自变量名连接起来
aic=ols(formula=formula,data=data).fit().aic #利用ols训练模型得出aic值
aic_with_variate.append((aic,candidate)) #将第每一次的aic值放进空列表
aic_with_variate.sort(reverse=True) #降序排序aic值
best_new_score,best_candidate=aic_with_variate.pop() #最好的aic值等于删除列表的最后一个值,以及最好的自变量等于列表最后一个自变量
if current_score>best_new_score: #如果目前的aic值大于最好的aic值
variate.remove(best_candidate) #移除加进来的变量名,即第二次循环时,不考虑此自变量了
selected.append(best_candidate) #将此自变量作为加进模型中的自变量
current_score=best_new_score #最新的分数等于最好的分数
print("aic is {},continuing!".format(current_score)) #输出最小的aic值
else:
print("for selection over!")
break
formula="{}~{}".format(target,"+".join(selected)) #最终的模型式子
print("final formula is {}".format(formula))
model=ols(formula=formula,data=data).fit()
return(model)
利用向前逐步回归筛选变量
forward_select(data=house_train,target="value")
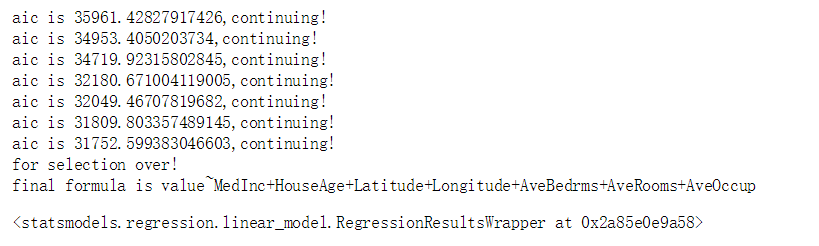

最终保留了7个自变量,其实只是剔除了一个自变量,将这七个自变量放进模型里再运行一遍,查看模型结果
lm_1=ols("value~MedInc+HouseAge+Latitude+Longitude+AveBedrms+AveRooms+AveOccup",data=house_train).fit()
lm_1.summary()
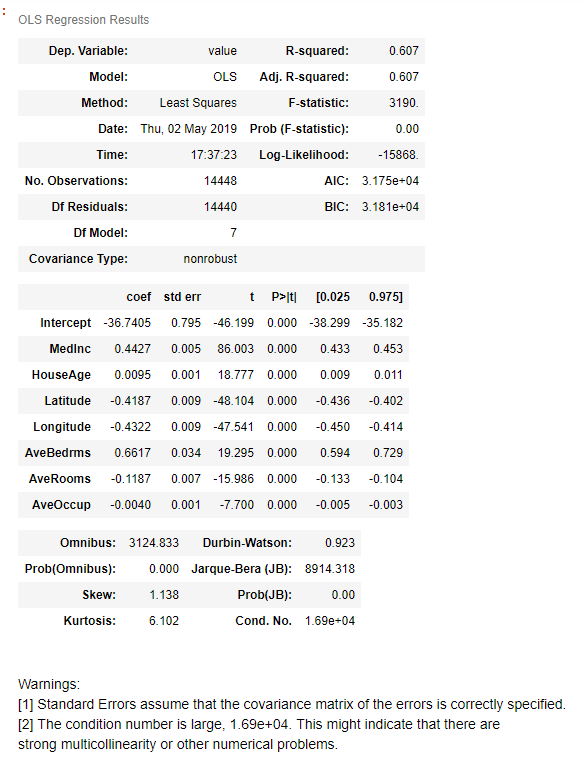
由以上结果可以看出,其实模型的R方几乎没有变化。
本篇文章主要是想讲述如何利用statsmodels和AIC准则定义向前逐步回归函数筛选自变量,在日后遇到比较多自变量的时候,方便进行自变量筛选。
参考文献
常国珍,赵仁乾,张秋剑.Python数据科学技术详解于商业实战[M]. 北京:中国人民大学出版社,2018.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/142215.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
