大家好,又见面了,我是你们的朋友全栈君。



多重共线性是指在变量空间中,存在自变量可以近似地等于其他自变量的线性组合
如果将所有自变量用于线性回归或逻辑回归的建模,将导致模型系数不能准确表达自变量对Y的影响。
比如:如果X1和X2近似相等,则模型Y = X1 + X2 可能被拟合成Y = 3 X1 – X2,原来 X2 与 Y 正向相关被错误拟合成负相关,导致模型没法在业务上得到解释。
在评分卡建模中,可能将很多相关性很高的变量加入到建模自变量中,最终得到的模型如果用变量系数去解释自变量与目标变量的关系是不合适的。
相关矩阵是指由样本的相关系数组成的矩阵,自变量相关系数过大意味着存在共线性,同时会导致信息冗余,维度增加。
设置相关系数的阈值,当大于threshold时,删除IV值较小的变量。
VIF(variance inflation factors)VIF =1/(1-R^2) 式中,R^2是以xj为因变量时对其它自变量回归的复测定系数。
VIF越大,该变量与其他的变量的关系越高,多重共线性越严重。如果所有变量最大的VIF超过10,删除最大VIF的变量。
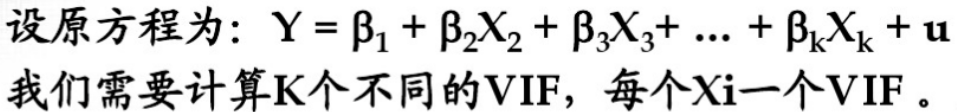

参考:
多重共线性:python中利用statsmodels计算VIF和相关系数消除共线性_ab1112221212的博客-CSDN博客
https://www.cnblogs.com/wqbin/p/11109650.html(可决系数)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141970.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
