大家好,又见面了,我是你们的朋友全栈君。
ResNet代码

本文主要搭建了ResNet18网络架构,每个block中包含两个Basicblock,每个Basicblock中包含两层,除去输入层和输出层外,一共有16层网络。而且每一个Basciblock之后进行一次跳跃连接。在此基础上,利用CIFAR10上的数据集大小举例,说明了ResNet网络中每层输出的大小变化。
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
# define structure
class BasicBlock(nn.Module):
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=in_planes, out_channels=planes, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=planes, out_channels=planes, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(planes)
)
if stride != 1 or in_planes != planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride),
nn.BatchNorm2d(planes)
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
# print(out.shape)
# print(self.shortcut(x).shape)
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_block, num_classes):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) # the first layer
self.layer1 = self._make_layer(block, 64, num_block[0], stride=1) # four layers 2-5
self.layer2 = self._make_layer(block, 128, num_block[1], stride=2) # four layers 6-9
self.layer3 = self._make_layer(block, 256, num_block[2], stride=2) # four layers 10-13
self.layer4 = self._make_layer(block, 512, num_block[3], stride=2) # four layers 14-17
self.fc = nn.Linear(512, num_classes) # the last layer
def _make_layer(self, block, planes, num_blocks, stride):
layers = []
for i in range(num_blocks):
if i == 0:
layers.append(block(self.in_planes, planes, stride))
else:
layers.append(block(planes, planes, 1))
self.in_planes = planes
return nn.Sequential(*layers)
def forward(self, x):
x = self.maxpool(self.relu(self.bn1(self.conv1(x))))
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = F.avg_pool2d(x, 4)
x = x.view(x.size(0), -1)
out = self.fc(x)
return out
Resnet18 = ResNet(BasicBlock, [2, 2, 2, 2], 10)
print(Resnet18)
运行结果
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
(1): BasicBlock(
(conv1): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(fc): Linear(in_features=512, out_features=10, bias=True)
)
Process finished with exit code 0
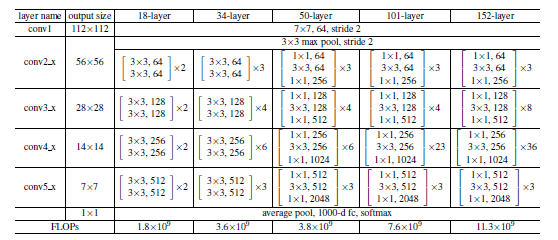
每层网络分析,以CIFAR10上的数据集为例说明
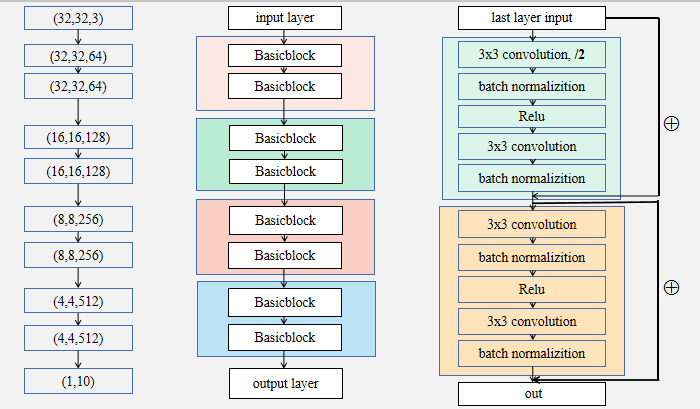
左:每一块之后的输出变化;中:网络结构;右:具体一个块,也就是两个Basicblock的结构。
ResNet18代码分析
上面的代码中主要有两个需要注意的地方
注意一:
每一个block中的第一个basicblock中的第一层卷积的in_channel是上一层层的out_channel。
所以在连接layers注意channel的改变,这个在下面的语句可以提现出来:
def _make_layer(self, block, planes, num_blocks, stride):
layers = []
for i in range(num_blocks):
if i == 0:
layers.append(block(self.in_planes, planes, stride))
else:
layers.append(block(planes, planes, 1))
self.in_planes = planes
return nn.Sequential(*layers)
注意二:
1、在跳跃连接时,上一basicblock的输出和当下basicblock的输出大小不一样,没办法进行加和运算。所以在shortcut时操作使得第2、3、4block的第一个basicblock的输出进行卷积操作:stride=2,使得输出结果缩小一半。
2、与此同时,通道数也是不一样的,也要进行卷积操作。这个在每一个block都要进行卷积操作,使得通道数一致。
if stride != 1 or in_planes != planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride),
nn.BatchNorm2d(planes)
)
else:
self.shortcut = nn.Sequential()
参考文献
【1】He K , Zhang X , Ren S , et al. Deep Residual Learning for Image Recognition[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE Computer Society, 2016.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141313.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
