大家好,又见面了,我是你们的朋友全栈君。
事情的起源于一个面试,面试官让我说说数据库的隔离级别,以及他们各自对应着什么问题,这个还好说,说出来后他接着追问readcommited的原理,当时楞了一下,因为的确没接触过,虽然知道肯定是锁的作用,但不知道怎么说好,怎么着手,就直接说不清楚了。。。然后就凉了。。。下面记录一下吧!
所谓的数据库事务操作其实就是一组原子性的操作,要么全部操作成功,要么全部操作失败。
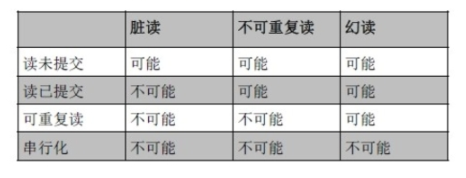
并行事务的四大问题:
1.更新丢失:和别的事务读到相同的东西,各自写,自己的写被覆盖了。(谁写的快谁的更新就丢失了)
2.脏读:读到别的事务未提交的数据。(万一回滚,数据就是脏的无效的了)
3.不可重复读:两次读之间有别的事务修改。
4.幻读:两次读之间有别的事务增删。
对应隔离级别
1.READ UNCOMMITTED:读未提交,不处理。
2.READ COMMITTED:读已提交,只读提交的数据,无脏读;
3.REPEATABLE READ:可重复读,加行锁,两次读之间不会有修改,无脏读无重复读;
4.SERIALIZABLE: 串行化,加表锁,全部串行,无所有问题。

1.READ UNCIMMITTED(未提交读)
事务还没提交,而别的事务可以看到他其中修改的数据的后果,也就是脏读。
2.READ COMMITTED(提交读)
首先大多数数据库系统的默认隔离级别是READ COMMITTED,这种隔离级别就是一个事务的开始,只能看到已经完成的事务的结果,正在执行的,是无法被其他事务看到的。这种级别会出现读取旧数据的现象
3.REPEATABLE READ(可重复读)
REPEATABLE READ解决了脏读的问题,该级别保证了每行的记录的结果是一致的,也就是上面说的读了旧数据的问题,但是却无法解决另一个问题,幻行,顾名思义就是突然蹦出来的行数据。指的就是某个事务在读取某个范围的数据,但是另一个事务又向这个范围的数据去插入数据,导致多次读取的时候,数据的行数不一致。
总结:虽然读取同一条数据可以保证一致性,但是却不能保证没有插入新的数据
4.SERIALIZABLE(可串行化)
SERIALIZABLE是最高的隔离级别,它通过强制事务串行执行(注意是串行),避免了前面的幻读情况,由于他大量加上锁,导致大量的请求超时,因此性能会比较低下,在需要数据一致性且并发量不需要那么大的时候才可能考虑这个隔离级别。
下面是各个隔离级别的原理:
READ_UNCOMMITED 的原理:
1,事务对当前被读取的数据不加锁;
2,事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级共享锁,直到事务结束才释放。
下面分别对应上面1,2产生的表现:
1,事务1读取某行记录时,事务2也能对这行记录进行读取、更新;当事务2对该记录进行更新时,事务1再次读取该记录,能读到事务2对该记录的修改版本,即使该修改尚未被提交。
2,事务1更新某行记录时,事务2不能对这行记录做更新,直到事务1结束。
READ_COMMITED 的原理:
1,事务对当前被读取的数据加 行级共享锁(当读到时才加锁),一旦读完该行,立即释放该行级共享锁;
2,事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级排他锁,直到事务结束才释放。
表现:
1,事务1读取某行记录时,事务2也能对这行记录进行读取、更新;当事务2对该记录进行更新时,事务1再次读取该记录,读到的只能是事务2对其更新前的版本,要不就是事务2提交后的版本。
2,事务1更新某行记录时,事务2不能对这行记录做更新,直到事务1结束。
REPEATABLE READ 的原理:
1,事务在读取某数据的瞬间(就是开始读取的瞬间),必须先对其加 行级共享锁,直到事务结束才释放;
2,事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级排他锁,直到事务结束才释放。
表现:
1,事务1读取某行记录时,事务2也能对这行记录进行读取、更新;当事务2对该记录进行更新时,事务1再次读取该记录,读到的仍然是第一次读取的那个版本。
2,事务1更新某行记录时,事务2不能对这行记录做更新,直到事务1结束。
SERIALIZABLE 的原理:
1,事务在读取数据时,必须先对其加 表级共享锁 ,直到事务结束才释放;
2,事务在更新数据时,必须先对其加 表级排他锁 ,直到事务结束才释放。
表现:
1,事务1正在读取A表中的记录时,则事务2也能读取A表,但不能对A表做更新、新增、删除,直到事务1结束。
2,事务1正在更新A表中的记录时,则事务2不能读取A表的任意记录,更不可能对A表做更新、新增、删除,直到事务1结束。
这里咋一看觉得能理解,但细想没有特别搞清,主要是这里面出现的几种锁,下面是数据库涉及和本文涉及到的锁的解释:
这里只针对MySQL,其他的可能有细微差别,但总体都是一个思想;
MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。比如,
MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking)。
InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。
所有的锁都是绑定在数据库的索引机制上的!!!
首先锁可以分为:
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
而除了粒度,锁根据模式分为:
共享锁(S):发生在数据查找之前,多个事务的共享锁之间可以共存
排他锁(X):发生在数据更新之前,排他锁是一个独占锁,与其他锁都不兼容
更新锁(U):发生在更新语句中,更新锁用来查找数据,当查找的数据不是要更新的数据时转化为S锁,当是要更新的数据时转化为X锁
意向锁:发生在较低粒度级别的资源获取之前,表示对该资源下低粒度的资源添加对应的锁,意向锁有分为:意向共享锁(IS) ,意向排他锁(IX),意向更新锁(IU),共享意向排他锁(SIX),共享意向更新锁(SIU),更新意向排他锁(UIX)
意向锁又分为
意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
共享锁/排他锁/更新锁一般作用在较低级别上,例如数据行或数据页,意向锁一般作用在较高的级别上,例如数据表或数据。锁是有层级结构的,若在数据行上持有排他锁的时候,则会在所在的数据页上持有意向排他锁. 在一个事务中,可能由于锁持有的时间太长或个数太多,出于节约资源的考虑,会造成锁升级;
我理解的就以最后一个SERIALIZABLE来说,开始时是设置的表级共享锁,分为表级别的而且是共享锁,表级别就是作用于整个表,不是行级别!而共享锁,则说明了其他事务也是共享锁的情况下可以共享这个表!虽然仅限于读,但这样也可能存在脏读等情况的存在,而如果换成表级排它锁,那么第一个事务在使用了这个锁之后,那其他事务连这个表的读的权限也没有,从根本上避免了各种可能的问题。
最后总结一下各个索引引擎的情况:
1.InnoDB(MySQL默认存储引擎 从版本5.5.5开始)
支持事务,行级锁,以及外键,拥有高并发处理能力。但是在创建索引和加载数据时,比MyISAM慢。默认的隔离级别是Repeatable Read(可重复读)
2.MyISAM
不支持事务和行级锁。所以速度很快,性能优秀。可以对整张表加锁,支持并发插入,支持全文索引。
3.MEMORY
支持Hash索引,内存表,Memory引擎将数据存储在内存中,表结构不是存储在内存中的,查询时不需要执行磁盘I/O操作,所以要比MyISAM和InnoDB快很多倍,但是数据库断电或是重启后,表中的数据将会丢失,表结构不会丢失。
先这样吧,如果散开说,那又要扯到各个索引引擎的实现原理,B树和B+树的区别了。。。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141303.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
