大家好,又见面了,我是你们的朋友全栈君。
前言
上一篇blog介绍了Oracle中的单表查询和排序的相关技巧(http://blog.csdn.net/wlwlwlwl015/article/details/52083588),本篇blog继续介绍查询中用的最多的——多表查询的技巧与优化方式,下面依旧通过一次例子看一个最简单的多表查询。
多表查询
上一篇中提到了学生信息表的民族代码(mzdm_)这个字段通常应该关联字典表来查询其对应的汉字,实际上我们也是这么做的,首先简单看一下表结构,首先是字典表:

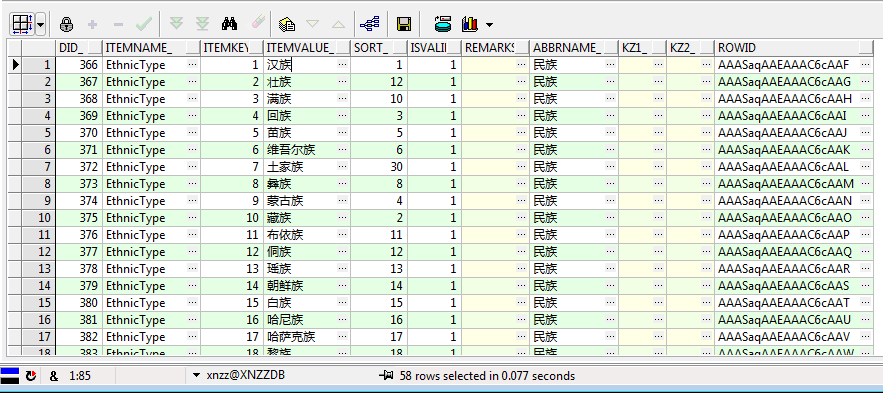
如上图,可以看到每个民族代码和名称都是由两个字段——“itemkey_”和“itemvalue_”以键值形式对应起来的,而学生信息表只存了民族代码字段(mzdm_),所以通过mzdm_和itemkey_相对应就能很好的查询出民族对应的汉字了,比如这样写:
select t1.*, t2.itemvalue_ mzmc_ from (select sid_, stuname_, mzdm_ from t_studentinfo) t1 left join (select itemkey_, itemvalue_ from t_dict where itemname_ = 'EthnicType') t2 on t1.mzdm_ = t2.itemkey_;
接下来查看一下运行结果:
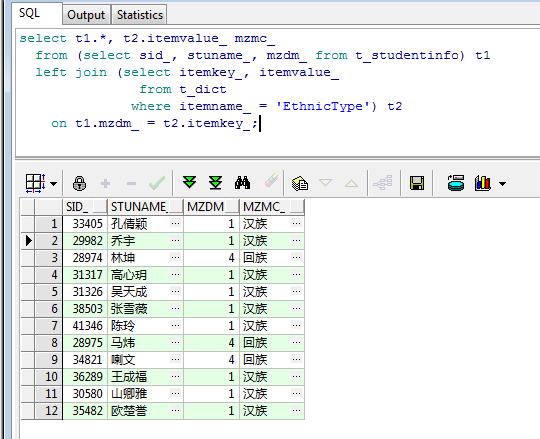
如上写法(左连接查询)是我在项目中运用最多的形式之一,暂不评论好坏与效率,总之查询结果是很好的展现出来了,接下来就具体研究一下多表查询的几种方式与区别。
UNION ALL
如题,这是我们第一个介绍的操作多表的方式就是UNION和UNION ALL,UNION和UNION ALL也是存在一定区别的,首先明确一点基本概念,UNION和UNION ALL是用来合并多个数据集的,例如将两个select语句的结果合并为一个整体:
select bmh_, stuname_, csrq_, mzdm_ from t_studentinfo where mzdm_ = 2 union all select bmh_, stuname_, csrq_, mzdm_ from t_studentinfo where mzdm_ = 5 查询结果如下:
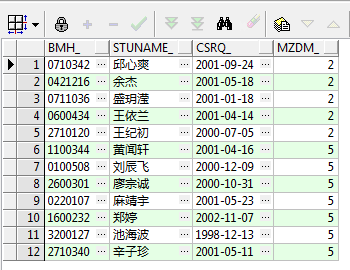
如上图所示,把mzdm_为2和5的结果集合并在了一起,那么接下来把UNION ALL换成UNION再看一下运行结果:
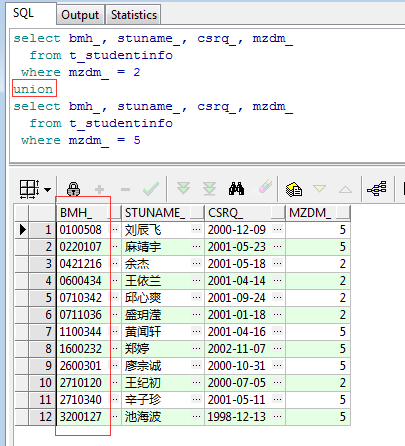
注意观察上图中的第一列BMH_不难发现,UNION进行了排序(默认规则排序,即按查询结果的首列进行排序),这就是它与UNION ALL的区别之一,再看一下下面这两个SQL和查询结果:
select bmh_, stuname_, csrq_, mzdm_ from t_studentinfo where mzdm_ in (2, 5) and csrq_ like '200%';
运行结果如下:
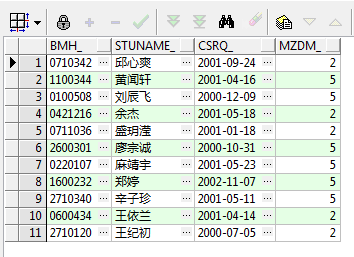
select bmh_, stuname_, csrq_, mzdm_ from t_studentinfo where mzdm_ in (2, 5) and csrq_ like '2001%';运行结果如下:
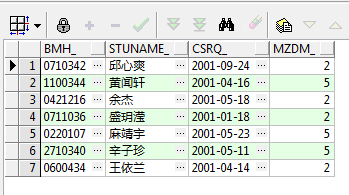
可以看到第二段查询结果肯定是包含在第一段查询结果之内的,那么它们进行UNION和UNION ALL又会有何区别呢?分别看一下,首先是UNION ALL:
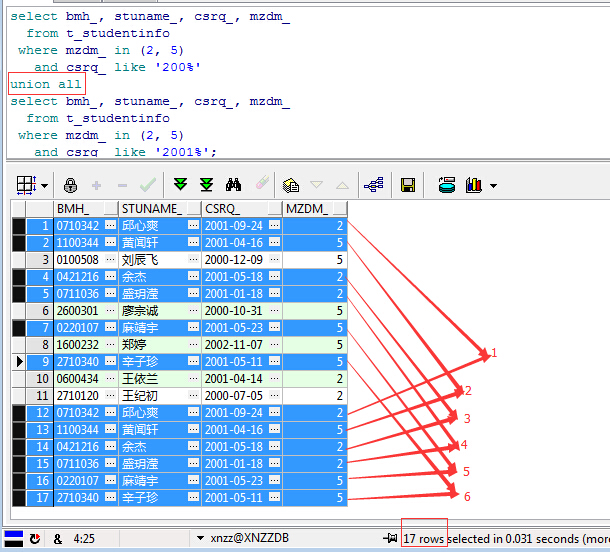
如上图,不难发现使用UNION ALL查询出了上面两个结果集的总和,包括6对重复数据+5条单独的数据总共17条,那么再看看UNION的结果:
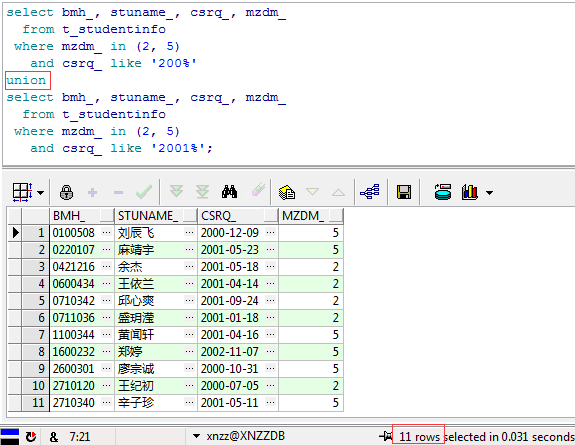
显而易见,和UNION ALL相比UNION帮我们自动剔除了6条重复结果,得到的是上面两个结果集的并集,同时并没有排序,这也就是UNION ALL与UNION的第二个区别了,最后简单总结一下UNION与UNION ALL的区别:
- UNION会自动去除多个结果集合中的重复结果,而UNION ALL则将所有的结果全部显示出来,不管是不是重复。
- UNION会对结果集进行默认规则的排序,而UNION ALL则不会进行任何排序。
所以效率方面很明显UNION ALL要高于UNION,因为它少去了排序和去重的工作。当然还有一点需要注意,UNION和UNION ALL也可以用来合并不同的两张表的结果集,但是字段类型和个数需要匹配,例如:
select sid_, stuname_, mzdm_ from t_studentinfo where sid_ = '33405' union all select did_, itemvalue_, itemkey_ from t_dict where did_ = '366' 查看一下运行结果:
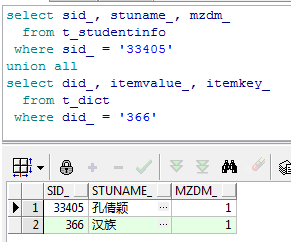
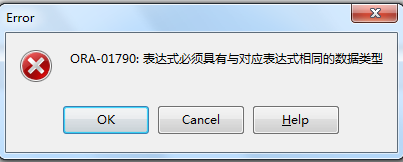
当数据配型不匹配或是列数不匹配时则会报错:
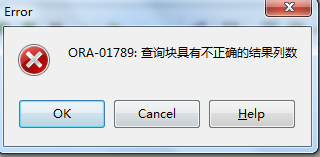
当列数不够时完全也可以用NULL来代替从而避免上图中的错误。最后再举个例子看一下UNION ALL在某些比较有意义的场景下的作用,首先创建一张临时表:
with test as
(select 'aaa' as name1, 'bbb' as name2 from dual union all select 'bbb' as name1, 'ccc' as name2 from dual union all select 'ccc' as name1, 'ddd' as name2 from dual union all select 'ddd' as name1, 'eee' as name2 from dual union all select 'eee' as name1, 'fff' as name2 from dual union all select 'fff' as name1, 'ggg' as name2 from dual) select * from test;
运行结果如下:
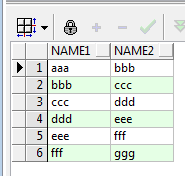
我们的需求也很简单,即:统计NAME1和NAME2中每个不同的值出现的次数。谈一下思路,首先统计NAME1每个值出现的次数,再统计NAME2每个值出现的次数,最后对上面两个结果集进行UNION ALL合并,最后再进行一次分组和排序即可:
with test as
(select 'aaa' as name1, 'bbb' as name2 from dual union all select 'bbb' as name1, 'ccc' as name2 from dual union all select 'ccc' as name1, 'ddd' as name2 from dual union all select 'ddd' as name1, 'eee' as name2 from dual union all select 'eee' as name1, 'fff' as name2 from dual union all select 'fff' as name1, 'ggg' as name2 from dual) select namex, sum(times) times from (select name1 namex, count(*) times from test group by name1 union all select name2 namex, count(*) times from test group by name2) group by namex order by namex;
运行结果如下:
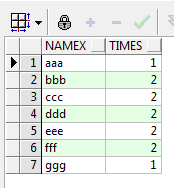
OK,很好的完成了查询,那么关于UNION和UNION ALL暂且介绍到这里。
是否使用JOIN
如题,blog开头写的那个例子是使用LEFT JOIN完成两张表的关联查询的,那么另外也可以不用JOIN而通过WHERE条件来完成以达到相同的效果:
select t1.sid_, t1.stuname_, t1.mzdm_, t2.itemvalue_ mzmc_ from t_studentinfo t1, t_dict t2 where t1.mzdm_ = t2.itemkey_ and t2.itemname_ = 'EthnicType';运行效果如下:
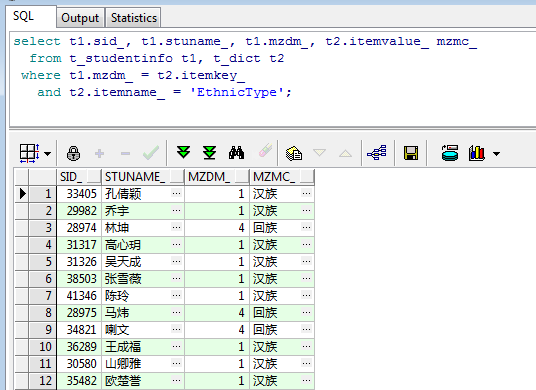
回头看一下blog开头的SQL和运行效果,可以发现和上图一模一样,那使用哪一种更合适呢?JOIN的写法是SQL-92的标准,多表关联时候使用JOIN方式进行关联查询可以更清楚的看到各表之间的联系,也方便维护SQL,所以还是不建议上面使用WHERE的查询方式,而是应该使用JOIN的写法。
IN和EXISTS
如题,这也是在查询中经常用到的,尤其是IN关键字,在项目中使用的相当频繁,经常会有通过for循环和StringBuffer来拼接IN语句的写法,那么接下来就仔细看一下IN和EXISTS的使用场景以及效率问题,依旧通过举例说明,比如这个需求,查询所有汉族学生的成绩:
explain plan for select *
from t_studentscore
where bmh_ in (select bmh_ from t_studentinfo where mzdm_ = 1);select * from table(dbms_xplan.display());观察一下执行计划:
1 Plan hash value: 902966761
2
3 ————————————————————————————-
4 | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
5 ————————————————————————————-
6 | 0 | SELECT STATEMENT | | 535 | 37985 | 240 (1)| 00:00:03 |
7 |* 1 | HASH JOIN | | 535 | 37985 | 240 (1)| 00:00:03 |
8 |* 2 | TABLE ACCESS FULL| T_STUDENTINFO | 535 | 5885 | 207 (1)| 00:00:03 |
9 | 3 | TABLE ACCESS FULL| T_STUDENTSCORE | 11642 | 682K| 32 (0)| 00:00:01 |
10 ————————————————————————————-
11
12 Predicate Information (identified by operation id):
13 —————————————————
14
15 1 – access(“BMH_”=SYS_OP_C2C(“BMH_”))
16 2 – filter(“MZDM_”=1)
同理,将IN换成EXISTS再来看一下SQL和执行计划:
explain plan for select * from t_studentscore ts where exists (select 1 from t_studentinfo where mzdm_ = 1 and bmh_ = ts.bmh_);select * from table(dbms_xplan.display());观察一下执行计划:
1 Plan hash value: 3857445149
2
3 —————————————————————————————
4 | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
5 —————————————————————————————
6 | 0 | SELECT STATEMENT | | 1 | 71 | 240 (1)| 00:00:03 |
7 |* 1 | HASH JOIN RIGHT SEMI| | 1 | 71 | 240 (1)| 00:00:03 |
8 |* 2 | TABLE ACCESS FULL | T_STUDENTINFO | 535 | 5885 | 207 (1)| 00:00:03 |
9 | 3 | TABLE ACCESS FULL | T_STUDENTSCORE | 11642 | 682K| 32 (0)| 00:00:01 |
10 —————————————————————————————
11
12 Predicate Information (identified by operation id):
13 —————————————————
14
15 1 – access(“TS”.”BMH_”=SYS_OP_C2C(“BMH_”))
16 2 – filter(“MZDM_”=1)
如上所示,尽管IN的写法用了HASH JOIN(哈希连接)而EXISTS的写法用了HASH JOIN RIGHT SEMI(哈希右半连接),但它们的执行计划却没有区别,效率都是一样的,这是因为数据量不大,所以有一点结论就是在简单查询中,IN和EXISTS是等价的。还有一点需要明确,在早期的版本中仿佛有这样的规则:
- 子查询结果集小,用IN。
- 外表小,子查询表大,用EXISTS。
这两个说法在Oracle11g中已经是完全错误的了!在Oracle8i中这样也许还经常是正确的,但Oracle 9i CBO就已经优化了IN和EXISTS的区别,Oracle优化器有个查询转换器,很多SQL虽然写法不同,但是Oracle优化器会根据既定规则进行查询重写,重写为优化器觉得效率最高的SQL,所以可能SQL写法不同,但是执行计划却是完全一样的,所以还有个结论就是:关于IN和EXISTS哪种更高效应该及时查看PLAN,而不是记固定的结论,至少在目前的Oracle版本中是这样的。
INNER LEFT RIGHT FULL JOIN
如题,很常用的几种连接方式,下面就分别看一下它们之间的区别。
INNER JOIN
首先是内连接(INNER JOIN),顾名思义,INNER JOIN返回的是两表相匹配的数据,依旧以blog开头的例子改写为INNER JOIN:
select t1.sid_, t1.stuname_, t1.mzdm_, t2.itemvalue_ mzmc_ from t_studentinfo t1 inner join t_dict t2 on t1.mzdm_ = t2.itemkey_ where t2.itemname_ = 'EthnicType';
运行结果如下:
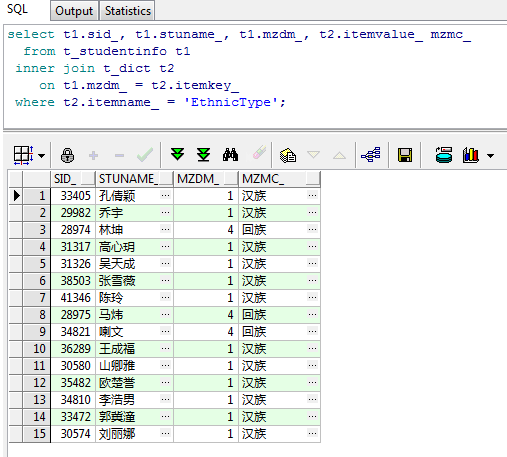
可以看到和上面的结果依旧是完全一样,但这个例子没有说明INNER JOIN的特点,所以就再重新创建两张表说明一下问题,这次用比较经典的学生表班级表来进行测试:
create table T_TEST_STU ( sid INTEGER, stuname VARCHAR2(20), clsid INTEGER ) tablespace USERS pctfree 10 initrans 1 maxtrans 255 storage ( initial 64K next 1M minextents 1 maxextents unlimited );create table T_TEST_CLS ( cid INTEGER, cname VARCHAR2(20) ) tablespace USERS pctfree 10 initrans 1 maxtrans 255 storage ( initial 64K next 1M minextents 1 maxextents unlimited );
表创建好后插入测试数据:
insert into T_TEST_STU (SID, STUNAME, CLSID) values (1, '张三', 1);
insert into T_TEST_STU (SID, STUNAME, CLSID) values (2, '李四', 1);
insert into T_TEST_STU (SID, STUNAME, CLSID) values (3, '小明', 2);
insert into T_TEST_STU (SID, STUNAME, CLSID) values (4, '小李', 3);
insert into T_TEST_CLS (CID, CNAME) values (1, '三年级1班');
insert into T_TEST_CLS (CID, CNAME) values (5, '三年级5班');如上所示,可以看到非常简单,学生表插入了4条数据,班级表插入了1条数据,用学生表的clsid来关联班级表的cid查询一下班级名称,下面看一下使用INNER JOIN的查询语句:
select t1.sid, t1.stuname, t2.cname from t_test_stu t1 inner join t_test_cls t2 on t1.clsid = t2.cid;
运行后可以看到查询结果:
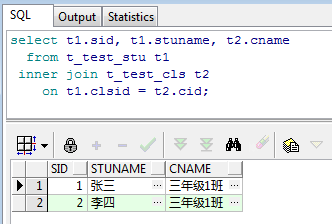
如上所示,很好的验证了INNER JOIN的概念,即返回两表均匹配的数据,由于班级表只有1条1班的数据和1条5班的数据,而学生表仅有两名1班的学生并且没有任何5班的学生,所以自然只能返回两条。
LEFT JOIN
如题,LEFT JOIN是以左表为主表,返回左表的全部数据,右表只返回相匹配的数据,将上面的SQL改为LEFT JOIN看一下:
select t1.sid, t1.stuname, t2.cname from t_test_stu t1 left join t_test_cls t2 on t1.clsid = t2.cid;
看一下运行结果:
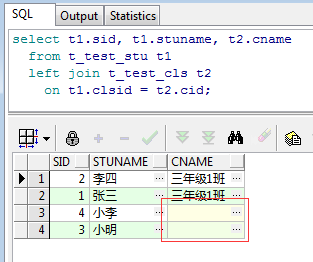
如上图所示,也非常简单,因为右表(班级表)并没有2班和3班的数据,所以班级名称不会显示。
RIGHT JOIN
如题,RIGHT JOIN和LEFT JOIN是相反的,以右表数据为主表,左表仅返回相匹配的数据,同理将上面的SQL改写为RIGHT JOIN的形式:
select t1.sid, t1.stuname, t2.cname from t_test_stu t1 right join t_test_cls t2 on t1.clsid = t2.cid;
运行结果如下:
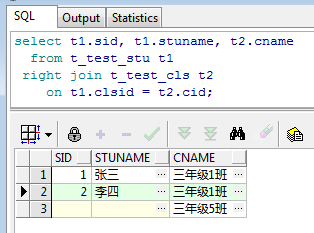
如上图,由于是以班级表为主表进行关联,所以匹配到1班的2名学生以及5班的数据。
FULL JOIN
如题,顾名思义,FULL JOIN就是不管左右两边是否匹配,一次性显示出所有的查询结果,相当于LEFT JOIN和RIGHT JOIN结果的并集,依旧将上面的SQL改写为FULL JOIN并查看结果:
select t1.sid, t1.stuname, t2.cname from t_test_stu t1 full join t_test_cls t2 on t1.clsid = t2.cid;
运行结果如下:
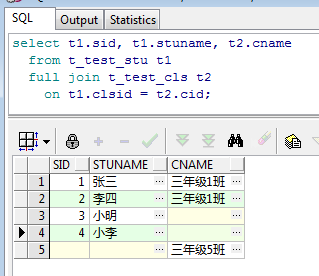
到这里这4种JOIN查询方式就已经简要的介绍完毕,单从概念上来将还是很好理解和区分的。
自关联
如题,这是一个使用场景比较特殊的关联方式,个人感觉如果数据库合理设计的话不会出现这种需求吧,既然提到了就举例说明一下,依旧以上面的测试学生表为例,现在需要添加一个字段:
alter table T_TEST_STU add leader INTEGER;假设有如下需求,每个学生都有一个直属leader,负责检查作业,老师为了避免作弊行为不会指定两个人相互检查,而是依次错开,比如学生A检查学生B,学生B检查学生C,所以我们的表数据可以这样来描述这个问题:
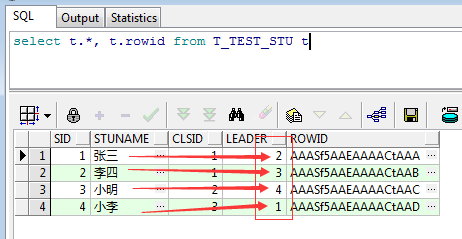
如上图,张三的LEADER是李四,李四的LEADER是小明,小明的LEADER是小李,而小李的LEADER又是张三,那么问题来了,该如何查询得到每个学生的LEADER的姓名呢?没错,这里就用到了自关联查询,简单的讲就是把同一张表查两遍并进行关联,用视图来说明获取更清晰,所以首先创建两个视图:
CREATE OR REPLACE VIEW V_STU as select * from T_TEST_STU;
CREATE OR REPLACE VIEW V_LEADER as select * from T_TEST_STU;接下来就通过自关联查询:
select v1.SID, v1.STUNAME, v1.CLSID, v1.LEADER, v2.STUNAME leader
from V_STU v1
left join V_LEADER v2
on v1.LEADER = v2.SID
order by v1.SID运行结果如下:

如上图所示,这样就通过自关联很好的查询出了每个学生对应的LEADER的姓名。
NOT IN和NOT EXISTS
如题,我们现在有一张学生信息表和一张录取结果表,例如我们想知道有哪些学生没被录取,即学生表有数据但录取表却没有该学生的数据,这时就可以用到NOT IN或NOT EXISTS,依旧结合执行计划看一看这种方式的差异:
explain plan for
select * from t_studentinfo where bmh_ not in (select bmh_ from t_lq);select * from table(dbms_xplan.display());观察一下执行计划:
1 Plan hash value: 4115710565
2
3 —————————————————————————————–
4 | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
5 —————————————————————————————–
6 | 0 | SELECT STATEMENT | | 119 | 52003 | 551 (1)| 00:00:07 |
7 |* 1 | HASH JOIN RIGHT ANTI NA| | 119 | 52003 | 551 (1)| 00:00:07 |
8 | 2 | TABLE ACCESS FULL | T_LQ | 11643 | 93144 | 343 (1)| 00:00:05 |
9 | 3 | TABLE ACCESS FULL | T_STUDENTINFO | 11772 | 4931K| 207 (1)| 00:00:03 |
10 —————————————————————————————–
11
12 Predicate Information (identified by operation id):
13 —————————————————
14
15 1 – access(“BMH_”=”BMH_”)
接下来将SQL转换为NOT EXISTS再看一下执行计划:
explain plan for
select * from t_studentinfo t1 where not exists (select null from t_lq t2 where t1.bmh_ = t2.bmh_);
select * from table(dbms_xplan.display());执行结果如下:
1 Plan hash value: 270337792
2
3 ————————————————————————————–
4 | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
5 ————————————————————————————–
6 | 0 | SELECT STATEMENT | | 119 | 52003 | 551 (1)| 00:00:07 |
7 |* 1 | HASH JOIN RIGHT ANTI| | 119 | 52003 | 551 (1)| 00:00:07 |
8 | 2 | TABLE ACCESS FULL | T_LQ | 11643 | 93144 | 343 (1)| 00:00:05 |
9 | 3 | TABLE ACCESS FULL | T_STUDENTINFO | 11772 | 4931K| 207 (1)| 00:00:03 |
10 ————————————————————————————–
11
12 Predicate Information (identified by operation id):
13 —————————————————
14
15 1 – access(“T1”.”BMH_”=”T2”.”BMH_”)
如上所示,两个PLAN都应用了HASH JOIN RIGHT ANTI,所以它们的效率是一样的,所以在Oracle11g中关于NOT IN和NOT EXISTS也没有绝对的效率优劣,依旧是要通过PLAN来判断和测试哪种更高效。
多表查询时的空值处理
如题,假设有以下需求,我需要查询一下性别不为男的学生的录取分数,但在这之前我首先给学生表添加一条报名号(bmh_)为null的学生数据,如下所示:

接下来写查询语句,这里刻意用一下NOT IN关键字而不是IN关键字:
select bmh_, stuname_, lqfs_ from t_lq where bmh_ not in (select bmh_ from t_studentinfo where sextype_ = 1) 运行结果如下图所示:
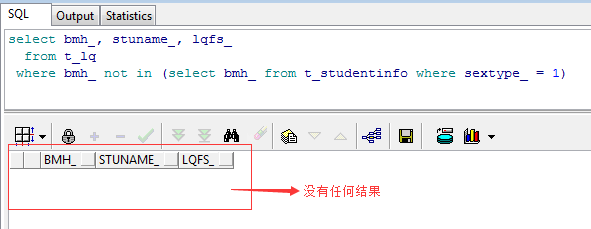
我们惊奇的发现没有任何数据被查出来,这就是因为NOT IN后的子查询中的5000+结果中仅仅有一条存在NULL值,所以这个查询整体就不会显示任何结果,有点一只老鼠毁了一锅汤的感觉,这也正是Oracle的特性之一,即:如果NOT IN关键字后的子查询包含空值,则整体查询都会返回空,所以这类查询务必要加非NULL判断条件,即:
select bmh_, stuname_, lqfs_ from t_lq where bmh_ not in (select bmh_ from t_studentinfo where sextype_ = 1 and bmh_ is not null);
这次再看一下运行结果:
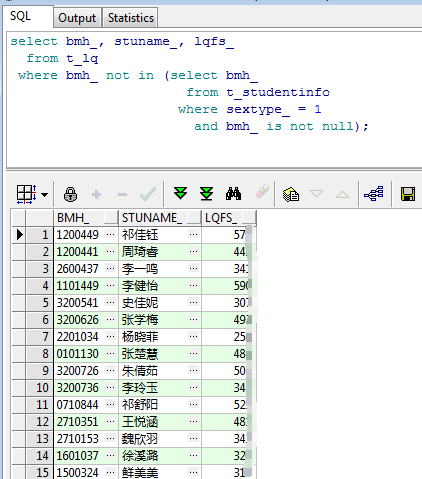
如上图所示,这次就很好的查询出了我们需要的结果。
总结
简单记录一下Oracle多表查询中的各种模式以及个人认为值得注意的一些点和优化方式,希望对读到的同学有所帮助和提高,The End。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141003.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
