大家好,又见面了,我是你们的朋友全栈君。
转载请注明出处:坦GA
前端编译器:把*.java文件转变成*.class文件
后端运行期编译器(JIT编译器,Just In Time Compiler):把字节码转成机器码
静态提前编译器(AOT编译器,Ahead Of Time Compiler):把*.java编译成本地机器码
前端编译器:Sun的Javac、Eclipse JDT中的增量式编辑器(ECJ)
JIT编译器:HotSpot VM的C1、C2编译器
AOT编译器:GNU Compiler for the Java(GCJ)、Excelsior JET
Javac编译器
1.Javac的源码与调试
Javac的源码下载地址,在Myeclipse中新建项目Compiler_javac,把源码复制到项目中。
Javac的源码目录:

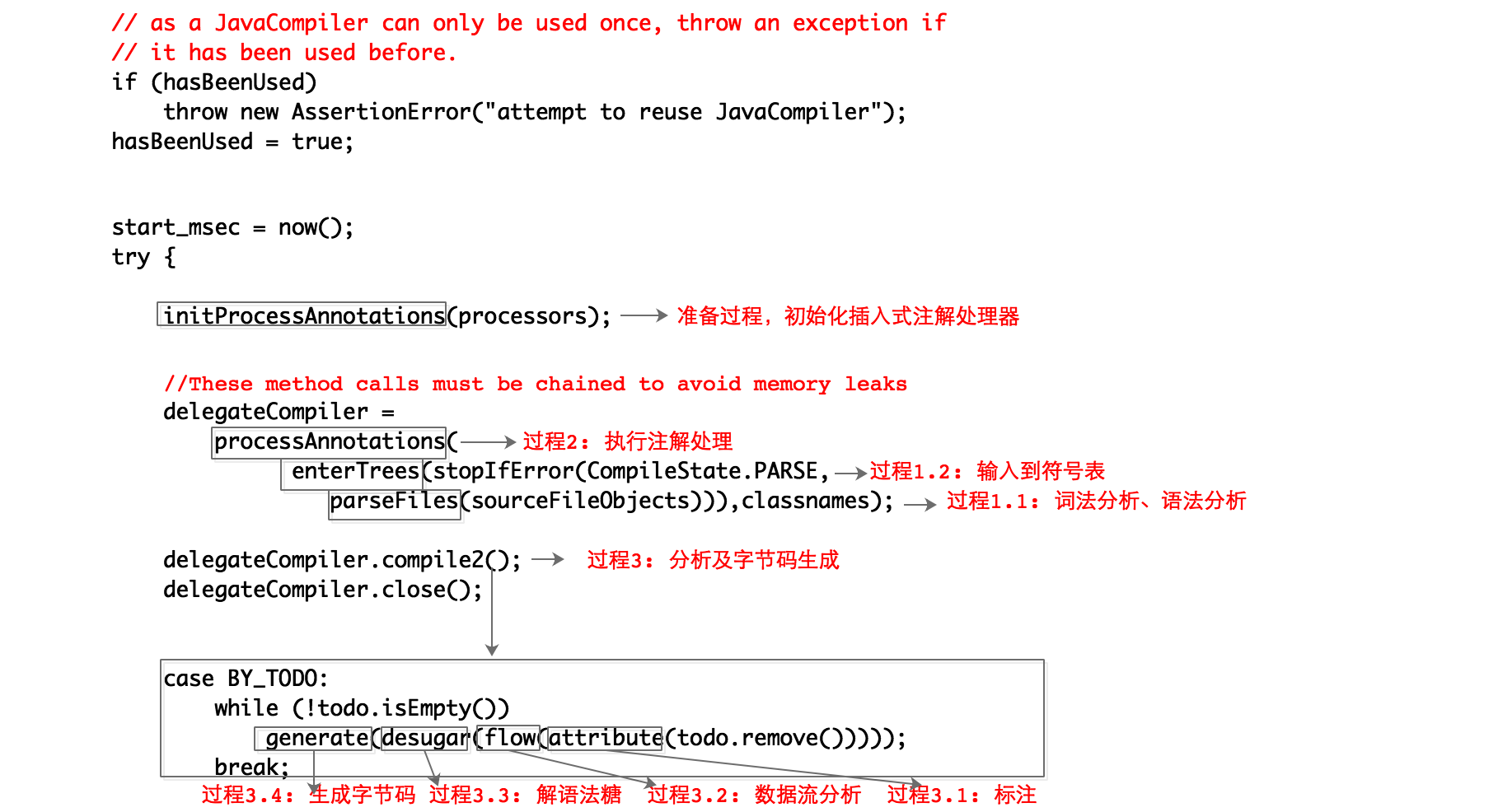
从Sun Javac的代码来看,编译过程大致可以分为3个过程:

Java编译动作的入口类为JavaCompiler,上述3个过程的代码逻辑集中在这个类的compile()和compile2()方法中。源代码如下:
2.解析与填充符号表
2.1词法分析、语法分析
词法分析:是将源代码的字符流转变为标记(Token)集合,单个字符是程序编写过程的最小元素,而标记则是编译过程的最小元素,关键字、变量名、字面量、运算符都可以看成标记。
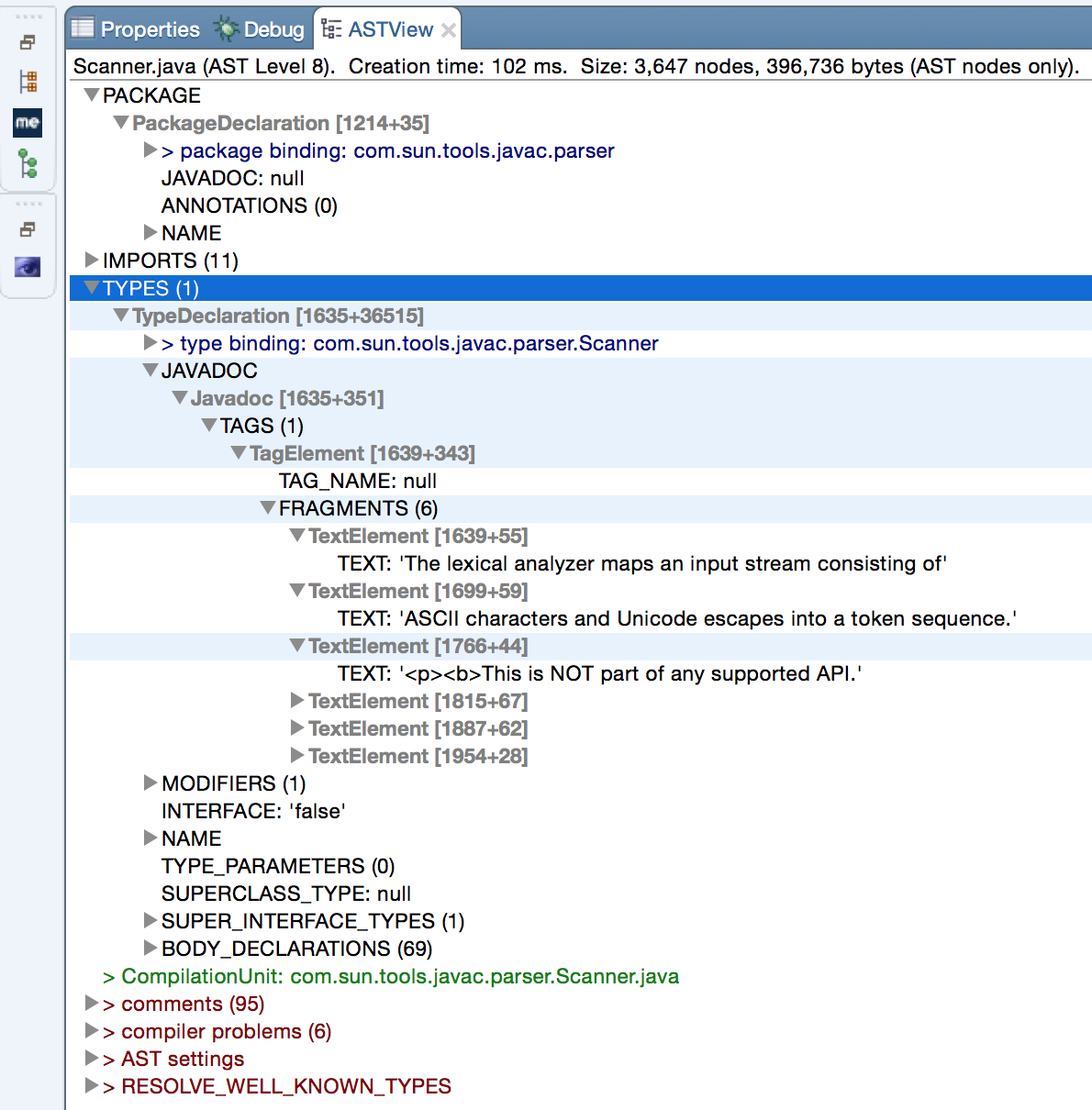
在Javac的源码中,词法分析过程由com.sun.tools.javac.parser.Scanner类实现。
语法分析:是根据Token序列构造抽象语法树的过程,抽象语法树(Abstract Syntax Tree,AST)是一种用来描述程序代码语法结构的树形表示方式,语法树的每一个节点都代表着程序代码中的语法结构(Construct),例如包、类型、修饰符、运算符、接口、返回值甚至代码注释都可以是一个语法结构。
在Javac的源码中,语法分析过程由com.sun.tools.javac.parser.Parser类实现。
这个阶段产生的抽象语法树由com.sun.tools.javac.tree.JCTree类表示,经过这个步骤之后,编译器就基本不会再对源码文件操作了,后续的操作都建立在抽象语法树之上。
在Myeclipse中安装ASTView插件的下载地址:ASTView插件下载地址,安装插件后Window中Show View中选择ASTView。
抽象语法树结构视图如下:
2.2填充符号表
符号表(Symbol Table)是由一组符号地址和符号信息构成的表格,读者可以把它想象成哈希表中K-V值对的形式(实际上符号表不一定是哈希表实现,可以是有序符号表、树状符号表、栈结构符号表等)。
符号表中所登记的信息在编译的不同阶段都要用到。
1)在语义分析中:符号表所登记的内容将用于语义检查(如检查一个名字的使用和原先的说明是否一致)和产生中间代码。
2)在目标代码生成阶段:当对符号名进行地址分配时,符号表是地址分配的依据。
在Javac源码中,填充符号表的过程由com.sun.tools.javac.comp.Enter类实现,此过程的出口是一个待处理列表(To Do List),包含了每一个编译单元的抽象语法树的顶级节点,以及package-info.java(如果存在的话)的顶级节点。
3.注解处理器
JDK1.6提供了一组插入式注解处理器的标准API在编译期间对注解进行处理,我们可以把它看做是一组编译器的插件,在这些插件里面,可以读取、修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法树进行了修改,编译器将回到解析及填充符号表的过程重新处理,直到所有插入式注解处理器都没有再对语法树进行修改为止,每一次循环称为一个Round,也就是上面绿色图中回环的过程。
在Javac源码中,插入式注解处理器的初始化过程是在initProcessAnnotations()方法中完成的,而它的执行过程则是在processAnnotations()方法中完成的,这个方法判断是否还有新的注解处理器需要执行,如果有的话,通过com.sun.tools.javac.processing.JavacProcessingEnvironment类的doProcessing()方法生成一个新的JavaCompiler对象对编译的后续步骤进行处理。
4.语义分析与字节码生成
语法树能表示一个结构正确的源程序的抽象,但无法保证源代码是符号逻辑的。而语义分析的主要任务是对结构上正确的源程序进行上下文有关性质的审查,如进行类型审查。
语义分析包括两个步骤:
1)标注检查(attribute()方法)
2)数据及控制流分析(flow()方法)
4.1标记检查
检查的内容包括:变量使用前是否已被声明、变量与赋值之间的数据类型是否能够匹配等。
常量折叠:
int a = 1+2;这个插入式表达式(Infix Expression)的值已经在语法树上标注出来了(ConstantExpressValue:3)。
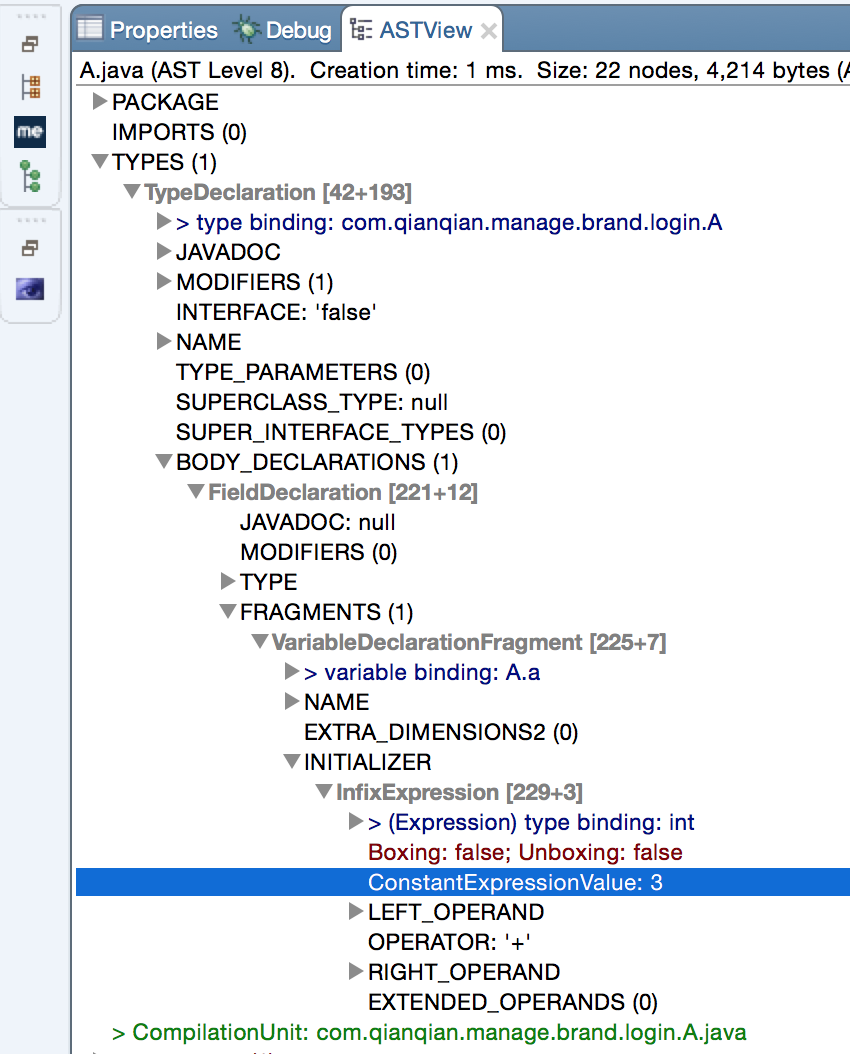
由于编译期间进行了常量折叠,所以在代码里面定义“a=1+2”比起直接定义“a=3”,并不会增加程序运行期哪怕仅仅一个CPU指令的运算量。
标注检查步骤在Javac源码中的实现类是com.sun.tools.javac.comp.Attr类和com.sun.tools.javac.comp.Check类。
4.2数据及控制流分析
数据及控制流分析是对程序上下文逻辑更进一步的验证,它可以检查:程序局部变量在使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受查异常都被正确处理了等。
编译时期的数据及控制流分析与类加载时的数据及控制流分析的目的基本上是一致的,但校验范围有所区别,有一些校验项只有在编译期或运行期才能进行。
局部变量与字段(实例变量、类变量)是有区别的,它在常量池中没有CONSTANT_Fieldref_info的符号引用,自然就没有访问标志(Access_Flags)的信息,甚至可能连名称都不会保留下来(取决于编译时的选项),自然在Class文件中不可能知道一个局部变量是不是声明为final了。因此,将局部变量声明为final,对运行期是没有影响的,变量的不变性仅仅由编译器在编译期间保障。
在Javac的源码中,数据及控制流分析的入口是flow()方法,具体操作由com.sun.tools.javac.comp.Flow类完成。
4.3解语法糖
语法糖(Syntactic Sugar),也称糖衣语法。指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。
Java中最常用的语法糖:泛型、变长参数、自动装箱/拆箱等,虚拟机运行时不支持这些语法,它们在编译阶段还原回简单的基础语法结构,这个过程称为解语法糖。
在Javac的源码中,解语法糖的过程由desugar()方法触发,在com.sun.tools.javac.comp.TransTypes类和com.sun.tools.javac.comp.Lower类中完成。
4.4字节码生成
字节码生成是Javac编译过程的最后一个阶段,在Javac源码里面由com.sun.tools.javac.jvm.Gen类来完成。
字节码生成阶段不仅仅是把前面各个步骤所生成的信息(语法树、符号表)转化成字节码写到磁盘中,编译器还进行了少量的代码添加和转换工作。
实例构造器<init>()方法和类构造器<clinit>()方法就是在这个阶段添加到语法树之中的(注意,这里的实例构造器并不是指默认构造函数,如果用户代码中没有提供任何构造函数,那编译器将会添加一个没有参数的、访问性(public、protected、private)与当前类一致的默认构造函数,这个工作在填充符号表阶段就已经完成),这两个构造器的产生过程实际上是一个代码收敛的过程,编译器会把语句块(对于实例构造器而言是“{}”块,对于类构造器而言是“static{}”块)、变量初始化(实例变量和类变量)、调用父类的实例构造器(仅仅是实例构造器,<clinit>()方法中无须调用父类的<clinit>()方法,虚拟机会自动保证父类构造器的执行,但在<clinit>()方法中经常会生成调用java.lang.Object的<init>()方法的代码)等操作收敛到<init>()和<clinit>方法之中,并且保证一定是按先执行父类的实例构造器,然后初始化变量,最后执行语句块的顺序进行,上面所述的动作由Gen.normalizeDefs()方法来实现。
除了生成构造器以外,还有其它的一些代码替换工作用于优化程序的实现逻辑,如把字符串的加操作替换为StringBuffer或StringBuilder的append()操作等。
完成了对语法树的遍历和调整之后,就会把填充了所有所需信息的符号表交给com.tools.javac.jvm.ClassWriter类,由这个类的writeClass()方法输出字节码,生成最终的Class文件,到此为止整个编译过程宣告结束。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140990.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
