大家好,又见面了,我是你们的朋友全栈君。
各种卷积的作用
Filter与kernel
filter是多个kernel的串联,每个kernel分配给输入的特定通道。filter总是比kernel大一维。
1. 常规卷积运算
整个过程可以用下图来概括。
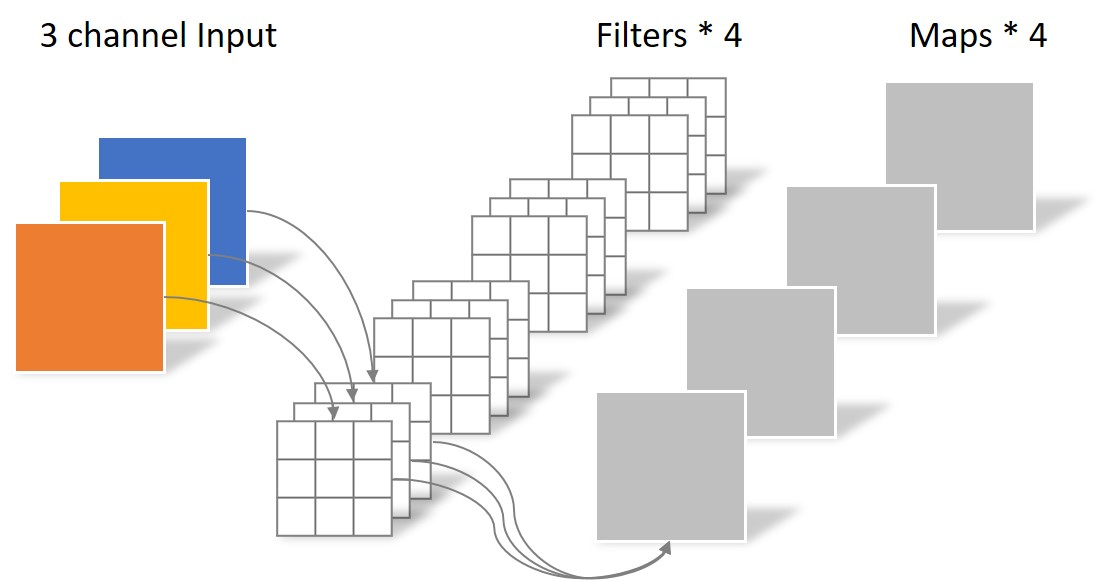

假设输入层为一个大小为64x64x3(Width=Height=64,Channel=3)的彩色图片。经过一个包含4个filter(每个filter有3个kernel,kernel_size=3×3)的卷积层,最终输出4个特征图(feature map),且尺寸与输入层相同。
因此卷积层的参数数量可以用如下公式来计算:
N_std = 3x3x3x4 = 108
2. Separable Convolution
Separable Convolution在Google的Xception[1]以及MobileNet[2]论文中均有描述。它的核心思想是将一个完整的卷积运算分解为两步进行,分别为Depthwise Convolution与Pointwise Convolution。
· Depthwise Convolution
同样是上述例子,一个大小为64×64像素、三通道彩色图片首先经过第一次卷积运算,不同之处在于此次的卷积完全是在二维平面内进行,且Filter的数量与上一层的Depth相同。所以一个三通道的图像经过运算后生成了3个Feature map,如下图所示。
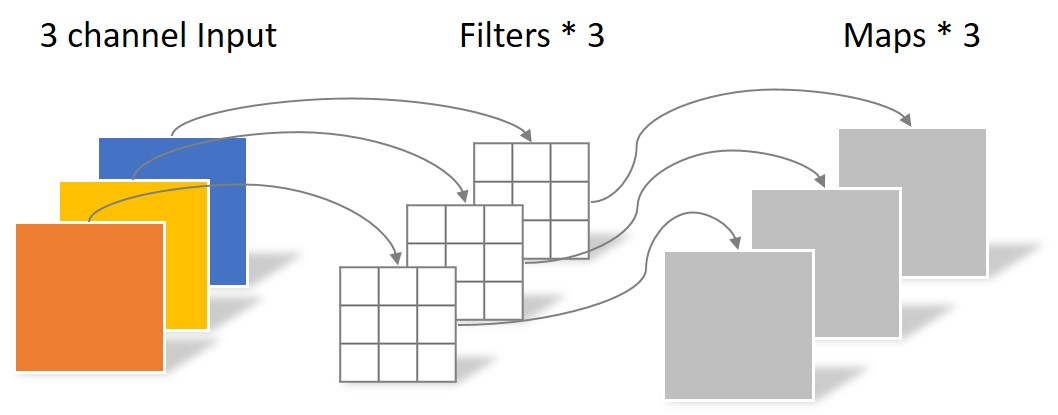
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
N_depthwise = 3 × 3 × 3 = 27
Depthwise Convolution完成后的Feature map数量与输入层的depth相同,但是这种运算对输入层的每个channel独立进行卷积运算后就结束了,没有有效的利用不同map在相同空间位置上的信息。因此需要增加另外一步操作来将这些map进行组合生成新的Feature map,即接下来的Pointwise Convolution。
·Pointwise Convolution
Pointwise Convolution的运算与常规卷积运算非常相似,不同之处在于卷积核的尺寸为 1×1×M(1×1 Convolution),M为上一层的depth。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个Filter就有几个Feature map。如下图所示。
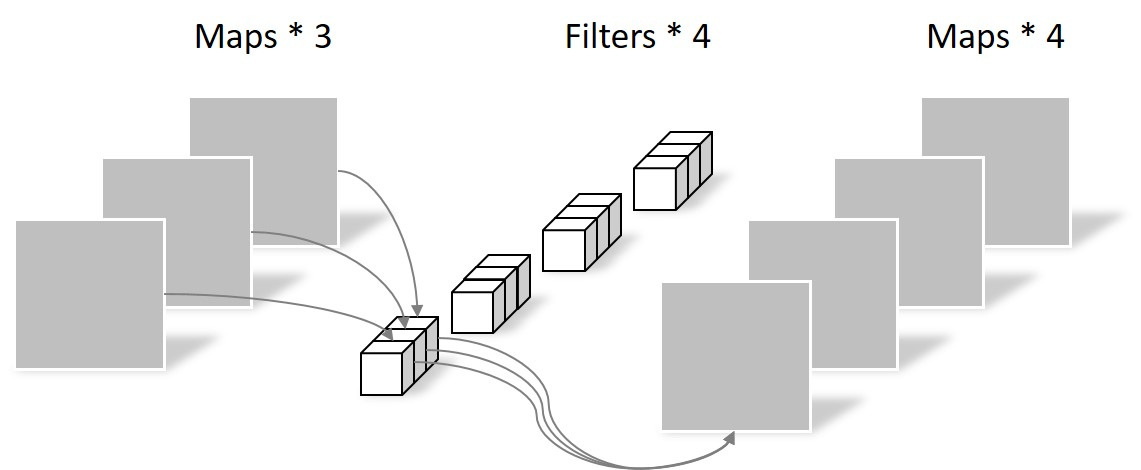
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同。
参数对比
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
1×1卷积的特点
- 对通道数进行升维和降维(跨通道信息整合),实现多个特征图的线性组合,同时保持了原有的特征图大小;
- 相比于其他尺寸的卷积核,可以极大地降低运算复杂度。
扩张/空洞(Dilated/Atrous)卷积
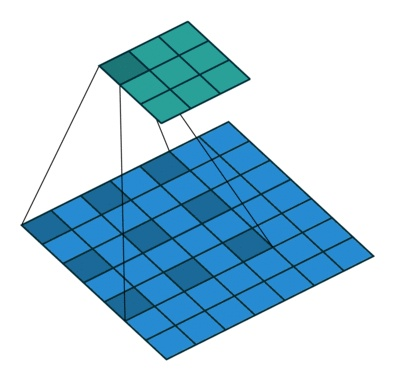
如你在以上所有卷积层中所见,无一例外,它们将一起处理所有相邻值。但是,有时跳过某些输入值可能更好,这就是为什么引入扩张卷积(也称为空洞卷积)的原因。这样的修改允许kernel在不增加参数数量的情况下增加其感受野。
显然,可以从上面的动画中注意到,kernel能够使用与之前相同的9个参数来处理更广阔的邻域。这也意味着由于无法处理细粒度的信息(因为它跳过某些值)而导致信息丢失。但是,在某些应用中,总体效果是正面的。
https://www.cnblogs.com/yibeimingyue/p/11964515.html
https://yinguobing.com/separable-convolution/#fn2
Xception: Deep Learning with Depthwise Separable Convolutions, François Chollet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140412.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
