大家好,又见面了,我是你们的朋友全栈君。
转自:https://blog.csdn.net/xs11222211/article/details/82931120#commentBox
本系列博客主要介绍使用Pytorch和TF进行分布式训练,本篇重点介绍相关理论,分析为什么要进行分布式训练。后续会从代码层面逐一介绍实际编程过程中如何实现分布式训练。
常见的训练方式
单机单卡(单GPU)
这种训练方式一般就是在自己笔记本上,穷学生专属。 : )
就是一台机器,上面一块GPU,最简单的训练方式。示例代码[2]:
#coding=utf-8
#单机单卡
#对于单机单卡,可以把参数和计算都定义再gpu上,不过如果参数模型比较大,显存不足等情况,就得放在cpu上
import tensorflow as tf with tf.device('/cpu:0'):#也可以放在gpu上
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
with tf.device('/gpu:0'):
addwb=w+b
mutwb=w*b
ini=tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(ini)
np1,np2=sess.run([addwb,mutwb])
print np1
print np2
12345678910111213141516171819
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
单机多卡(多GPU并行)
一台机器上可以配置4块GPU或者更多,如果我们在8块GPU上都跑一次BP算法计算出梯度,把所有GPU上计算出道梯度进行平均,然后更新参数。这样的话,以前一次BP只能喂1个batch的数据,现在就是8个batch。理论上来说,速度提升了8倍(除去GPU通信的时间等等)。这也是分布式训练提升速度的基本原理。
以前不理解,为什么这样就会收敛快!这种做法,其实就是单位时间内让模型多“过一些”数据。原因是这样的,梯度下降过程中,每个batch的梯度经常是相反的,也就是前后两次的更新方向相互抵消,导致优化过程中不断震荡,如果我用多块GPU,那么每次不同GPU计算出来的梯度就会取平均互相抵消,避免了这种情况的出现。示意图如下:

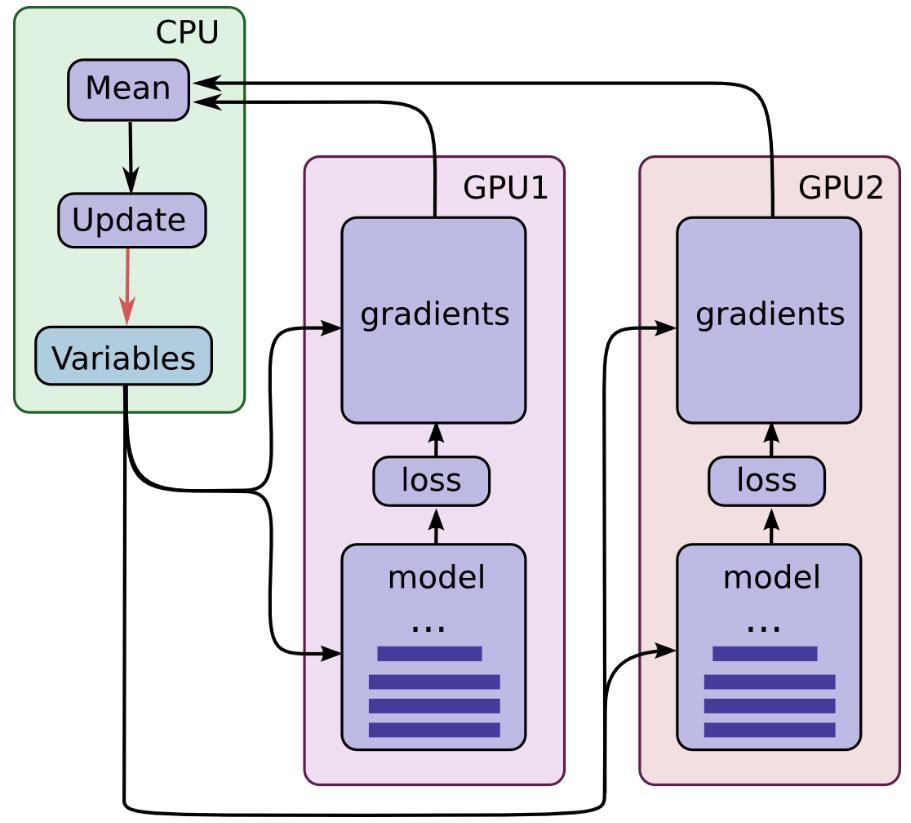
代码如下:
#coding=utf-8
#单机多卡:
#一般采用共享操作定义在cpu上,然后并行操作定义在各自的gpu上,比如对于深度学习来说,我们一把把参数定义、参数梯度更新统一放在cpu上
#各个gpu通过各自计算各自batch 数据的梯度值,然后统一传到cpu上,由cpu计算求取平均值,cpu更新参数。
#具体的深度学习多卡训练代码,请参考:https://github.com/tensorflow/models/blob/master/inception/inception/inception_train.py
import tensorflow as tf with tf.device('/cpu:0'):
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
with tf.device('/gpu:0'):
addwb=w+b
with tf.device('/gpu:1'):
mutwb=w*b
ini=tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(ini)
while 1:
print sess.run([addwb,mutwb])
1234567891011121314151617181920212223
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
多机多卡(分布式)
多机多卡就是使用多个机器,每个机器上有很多GPU来训练。示意图和单机多卡一致,代码在后续博客讲解。
为什么要使用分布式训练
所谓分布式训练,就是使用很多台机器,每台机器上都有很多GPU,模型跑在这些不同电脑的不同GPU上以加快训练速度(这个训练速度表示收敛速度,但是使用分布式之后,收敛的值好不好,那就是另外一回事了)。
通常情况下,我们自己的笔记本是1块GPU,如果是一些台式机,可以有4块GPU。如果两台台式机,GPU数量则更多。GPU数量越多,模型训练越快,具体原先下面分析。
- 数据规模大,导致训练时间很长
在单机8卡情况下,对于MS COCO 115k 这个规模的数据集。训练resnet152模型需要40个小时。训练Open Image dataset v41,740k 数据集则需要40天[1]。
对于炼丹的同学们来说,需要不断的尝试参数,调模型,改结果,这种训练速度是无法接受的。因此就很有必要使用分布式训练了。
- 分布式可能带来一些精度上的提升
先回忆一下,我们为什么要用SGD来优化模型,随机梯度下降的“随机”是指每次从数据集里面随机抽取一个小的batch数据来进行计算误差,然后反向传播。我们之所以只选一个小的batch,一是因为通常来说这个小的batch梯度方向基本上可以代替整个数据集的梯度方向,二是因为GPU显存有限。实际情况下,有的时候小的batch梯度并不足够就代替整个数据集的梯度,也就是说,每次BP算法求出来的梯度方向并不完全一致。这样就会导致优化过程不断震荡,而使用分布式训练,即大一点的batch size,就可以很好的避免震荡。但最终精度的话,也只能说可能会更好!
Batch Size对训练的影响
前面提到Batch size对模型精度会有一些影响,具体影响可以大致分析一下:
考虑极端情况,batch size = 1时,那么模型每次更新的梯度有当前数据决定,那么每次更新梯度方向不确定,模型很难收敛,但由于随机性大,也没那么容易陷入局部最优
如果batch size = total datasets呢,这个时候算出来的梯度就是整个数据集的梯度,如果学习速率合适(采用最速下降法),模型一次就收敛了。可能直接就掉到局部最优了。
下面是知乎上一位同学做的实验[1]:
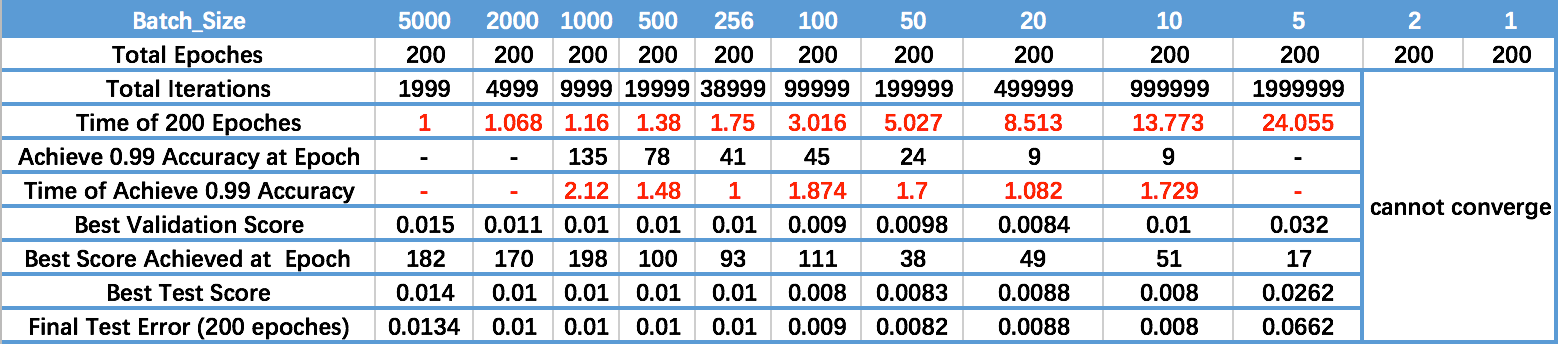
对表格每一行分析,可以知道:
- 从Time of 200 Epoches可以看出,batch size越大,训练到200个epoch的速度越快。即单位时间内,模型“看到的”数据越多
- 从Achieve 0.99 Accuracy at Epoch可以看出,batch size越大,实现同样的精度,模型需要的时间越久。这一点可以理解为,batch size越大,模型收敛越慢吗? 个人认为不可以,batch size越大,导致模型越容易陷入局部最优,即模型收敛后的最终精度下降。所以才导致看起来,实现同样精度,模型需要时间越久。
- 从Time of Achieve 0.99 Accuracy可以看出,batch size为256时,模型最快达到0.99精度。batch size过大,则导致模型精度上限下降,过小则不收敛。
- 从最后一行可以看出,小的batch size确实取得了较好的精度,但是训练速度堪忧。
总结,batch size对训练的影响:
- batch size 大点可以减少模型优化过程中的震荡问题
- 大的batch size可以提高矩阵乘法计算的并行度,提高内存利用率
- batch size过大,可能一定程度上导致模型收敛后的极限精度下降
- batch size过大,可能会有微小的精度损失
分布式训练实现方式
数据并行
把数据进行拆分,比如有4块GPU,batch size=1024,那么每块GPU就是256个数据。分别在每块GPU都跑BP算法,然后进行参数更新。
模型并行
把模型拆分成多个部分,对于很大的网络结构在如此,一般没必要。
混合并行
两者兼用,组内模型并行,组外数据并行[3]
多GPU训练的参数更新方式
多GPU训练情况下,包括单机多卡,多机多卡情况。其参数更新方式有两种:
-
同步更新
每块GPU分别运行反向传播求出梯度,然后对梯度进行平均,更新参数。
缺点:每次参数更新,都要等待所有GPU梯度都计算完毕。此外,需要有一个中心节点汇总梯度,并进行参数更新,这也会影响训练速度。
-
异步更新
每块GPU各自进行反向传播,计算出梯度,各自对模型进行更新(不进行梯度平均)
缺点:各个GPU梯度更新不同步,可能导致梯度已更新,然而某个GPU的梯度还是上一时刻的梯度,导致优化过程不稳定。
总之,各个GPU算力差不多时,推荐使用同步模式,否则使用异步模式
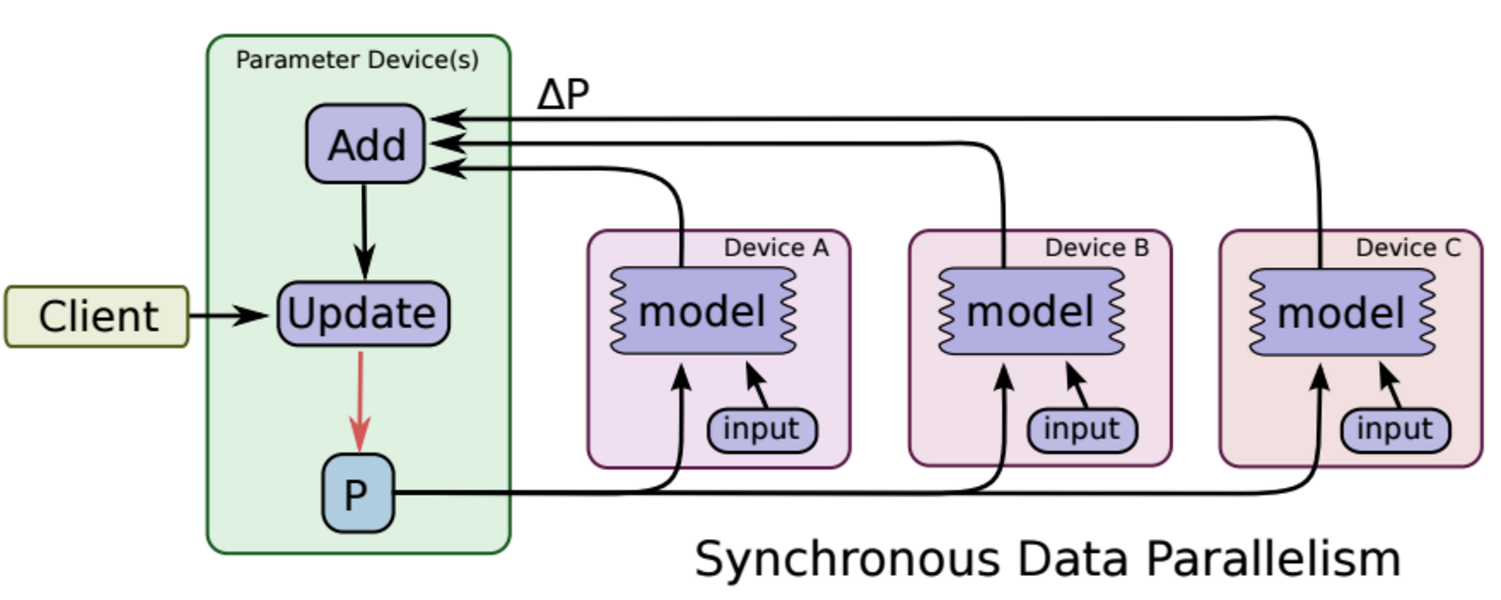
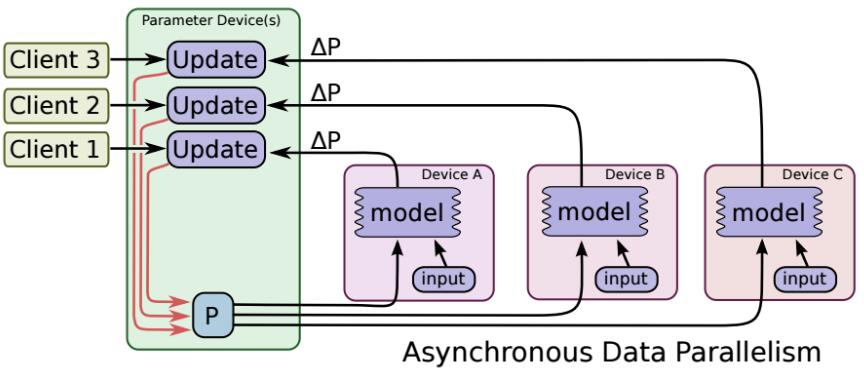
总结
- 分布式训练有一点点精度损失
- 可以在前期改模型,调算法过程采用分布式训练,后期模型成熟了可以采用单GPU的小batch size训练。(不过从mnist那一点点的精度差距来看,根本没必要为了这一点点差距去做调参)
</div>转载于:https://www.cnblogs.com/leebxo/p/11081492.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106756.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
