大家好,又见面了,我是你们的朋友全栈君。
文章目录
1-1 机器学习算法分类
一、基本分类:
①监督学习(Supervised learning)
数据集中的每个样本有相应的“正确答案”, 根据这些样本做出
预测, 分有两类: 回归问题和分类问题。
步骤1: 数据集的创建和分类
步骤2: 训练
步骤3: 验证
步骤4: 使用
( 1) 回归问题举例
例如: 预测房价, 根据样本集拟合出一条连续曲线。
( 2) 分类问题举例
例如: 根据肿瘤特征判断良性还是恶性,得到的是结果是“良性”或者“恶性”, 是离散的。
监督学习:从给定的训练数据集中学习出一个函数(模型参数), 当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标。训练集中的目标是由人标注的。
PCA和很多deep learning算法都属于无监督学习
②无监督学习
无监督学习:输入数据没有被标记,也没有确定的结果。样本数据类别未知, 需要根据样本间的相似性对样本集进行分类(聚类, clustering)试图使类内差距最小化,类间差距最大化。
实际应用中, 不少情况下无法预先知道样本的标签,也就是说没有训练样本对应的类别,因而只能从原先没有样本标签的样本集开始学习分器设计
| 有监督学习 | 无监督学习 | |
|---|---|---|
| 样本 | 必须要有训练集与测试样本。在训练集中找规律,而对测试样本使用这种规律。 | 没有训练集,只有一组数据,在该组数据集内寻找规律。 |
| 目标 | 方法是识别事物,识别的结果表现在给待识别数据加上了标签。 因此训练样本集必须由带标签的样本组成。 | 方法只有要分析的数据集的本身,预先没有什么标签。如果发现数据集呈现某种聚集性, 则可按自然的聚集性分类,但不予以某种预先分类标签对上号为目的。 |
③半监督学习
半监督学习: 即训练集同时包含有标记样本数据和未标记样本数据。
④强化学习
实质是: make decisions问题,即自动进行决策,并且可以做连续决策。
主要包含四个元素: agent, 环境状态, 行动, 奖励;
强化学习的目标就是获得最多的累计奖励。
小结:
监督学习:
In:有标签
Out:有反馈
目的:预测结果
案例:学认字
算法:分类(类别),回归(数字)
无监督学习:
In:无标签
Out:无反馈
目的:发现潜在结构
案例:自动聚类
算法:聚类,降维
半监督学习:
已知:训练样本Data和待分类的类别
未知:训练样本有无标签均可
应用:训练数据量过时,
监督学习效果不能满足需求,因此用来增强效果。
强化学习:
In:决策流程及激励系统
Out:一系列行动
目的:长期利益最大化,回报函数(只会提示你是否在朝着目标方向前进的延迟反映)
案例:学下棋
算法:马尔科夫决策,动态规划
2-1 KNN基本流程
一、概念:
KNN(K Near Neighbor):k个最近的邻居,即每个样本都可以用它最接近的k个邻居来代表。

最近邻 (k-Nearest Neighbors, KNN) 算法是一种分类算法, 1968年由 Cover和 Hart 提出, 应用场景有字符识别、 文本分类、 图像识别等领域。
该算法的思想是: 一个样本与数据集中的k个样本最相似, 如果这k个样本中的大多数属于某一个类别, 则该样本也属于这个类别。
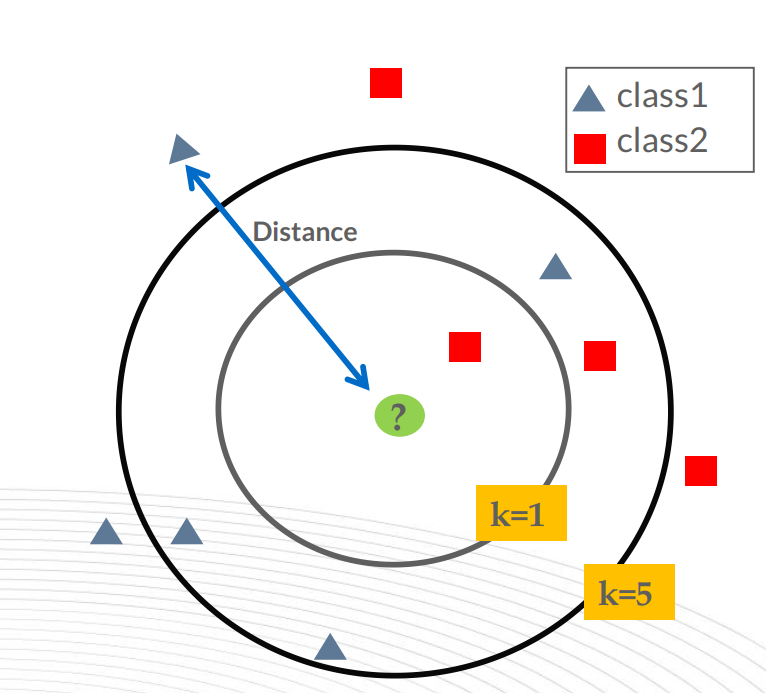
二、距离度量
在选择两个实例相似性时,一般使用的欧式距离
Lp距离定义:
L p ( x i , x j ) = ( ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ p ) 1 p L_p(x_i, x_j) = \left( \sum_{l=1}^{n} | x_i^{(l)} – x_j^{(l)} |^p \right)^{\frac{1}{p}} Lp(xi,xj)=(l=1∑n∣xi(l)−xj(l)∣p)p1
其中 x i ∈ R n , x j ∈ R n x_i \in \mathbf{R}^n,x_j \in \mathbf{R}^n xi∈Rn,xj∈Rn, 其中L∞定义为:
L ∞ ( x i , x j ) = max l ∣ x i ( l ) − x j ( l ) ∣ L_\infty(x_i, x_j) = \max_l|x_i^{(l)} – x_j^{(l)}| L∞(xi,xj)=lmax∣xi(l)−xj(l)∣
其中p是一个变参数。
当p=1时,就是曼哈顿距离(对应L1范数)
曼哈顿距离对应L1-范数,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。例如在平面上,坐标(x1, y1)的点P1与坐标(x2, y2)的点P2的曼哈顿距离为: ∣ x 1 − x 2 ∣ + ∣ y 1 − y 2 ∣ |x_1-x_2|+|y_1-y_2| ∣x1−x2∣+∣y1−y2∣,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
曼哈顿距离:
L 1 = ∑ k = 1 n ∣ x 1 k − x 2 k ∣ L_1=\sum_{k=1}^n|x_{1k}-x_{2k}| L1=k=1∑n∣x1k−x2k∣
L1范数表示为:
L 1 定 义 为 ∣ x ∣ = ∑ i = 1 n ∣ x i ∣ , 其 中 x = [ x 1 x 2 ⋮ x n ] ∈ R n L_1定义为|x| = \sum_{i=1}^n| x_i|,其中x = \left[ \begin{matrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{matrix} \right] \in \mathbf{R}^n L1定义为∣x∣=i=1∑n∣xi∣,其中x=⎣⎢⎢⎢⎡x1x2⋮xn⎦⎥⎥⎥⎤∈Rn
当p=2时,就是欧氏距离(对应L2范数)
最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于欧几里得空间中。n维空间中两个点x1(x11,x12,…,x1n)与 x2(x21,x22,…,x2n)间的欧氏距离
欧氏距离:
d 12 = ∑ k = 1 n ( x 1 − x 2 ) 2 d_{12}=\sqrt{\sum_{k=1}^n(x_1-x_2)^2} d12=k=1∑n(x1−x2)2
L2范数:
L 2 定 义 为 ∣ x ∣ = ∑ i = 1 n x i 2 , 其 中 x = [ x 1 x 2 ⋮ x n ] ∈ R n L_2定义为|x| = \sqrt{ \sum_{i=1}^n x_i^2 },其中x = \left[ \begin{matrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{matrix} \right] \in \mathbf{R}^n L2定义为∣x∣=i=1∑nxi2,其中x=⎣⎢⎢⎢⎡x1x2⋮xn⎦⎥⎥⎥⎤∈Rn
当p→∞时,就是切比雪夫距离
二维平面两点a(x1,y1)与b(x2,y2)间的切比雪夫距离:
d 12 = m a x ( ∣ x 1 − x 2 ∣ , ∣ y 1 − y 2 ∣ ) d_{12}=max(|x_1-x_2|,|y_1-y_2|) d12=max(∣x1−x2∣,∣y1−y2∣)
n维空间点a(x11,x12,…,x1n)与b(x21,x22,…,x2n)的切比雪夫距离:
d 12 = m a x ( ∣ x 1 i − x 2 i ∣ ) d_{12}=max(|x_{1i}-x_{2i}|) d12=max(∣x1i−x2i∣)
三、k值选择
如果选择较小的K值,就相当于用较小的邻域中的训练实例进行预测,学习的近似误差会减小,只有与输入实例较近的训练实例才会对预测结果起作用,单缺点是学习的估计误差会增大,预测结果会对近邻的实例点分成敏感。如果邻近的实例点恰巧是噪声,预测就会出错。换句话说,K值减小就意味着整体模型变复杂,分的不清楚,就容易发生过拟合。
如果选择较大K值,就相当于用较大邻域中的训练实例进行预测,其优点是可以减少学习的估计误差,但近似误差会增大,也就是对输入实例预测不准确,K值得增大就意味着整体模型变的简单
**近似误差:**可以理解为对现有训练集的训练误差。
**估计误差:**可以理解为对测试集的测试误差。
近似误差关注训练集,如果k值小了会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较大偏差的预测。模型本身不是最接近最佳模型。
估计误差关注测试集,估计误差小了说明对未知数据的预测能力好。模型本身最接近最佳模型。
在应用中,K值一般取一个比较小的数值,通常采用交叉验证法来选取最优的K值。
流程:
1) 计算已知类别数据集中的点与当前点之间的距离
2) 按距离递增次序排序
3) 选取与当前点距离最小的k个点
4) 统计前k个点所在的类别出现的频率
5) 返回前k个点出现频率最高的类别作为当前点的预测分类
优点:
1、简单有效
2、重新训练代价低
3、算法复杂度低
4、适合类域交叉样本
5、适用大样本自动分类
缺点:
1、惰性学习
2、类别分类不标准化
3、输出可解释性不强
4、不均衡性
5、计算量较大
例子如下图:
距离越近,就越相似,属于这一类的可能性就越大
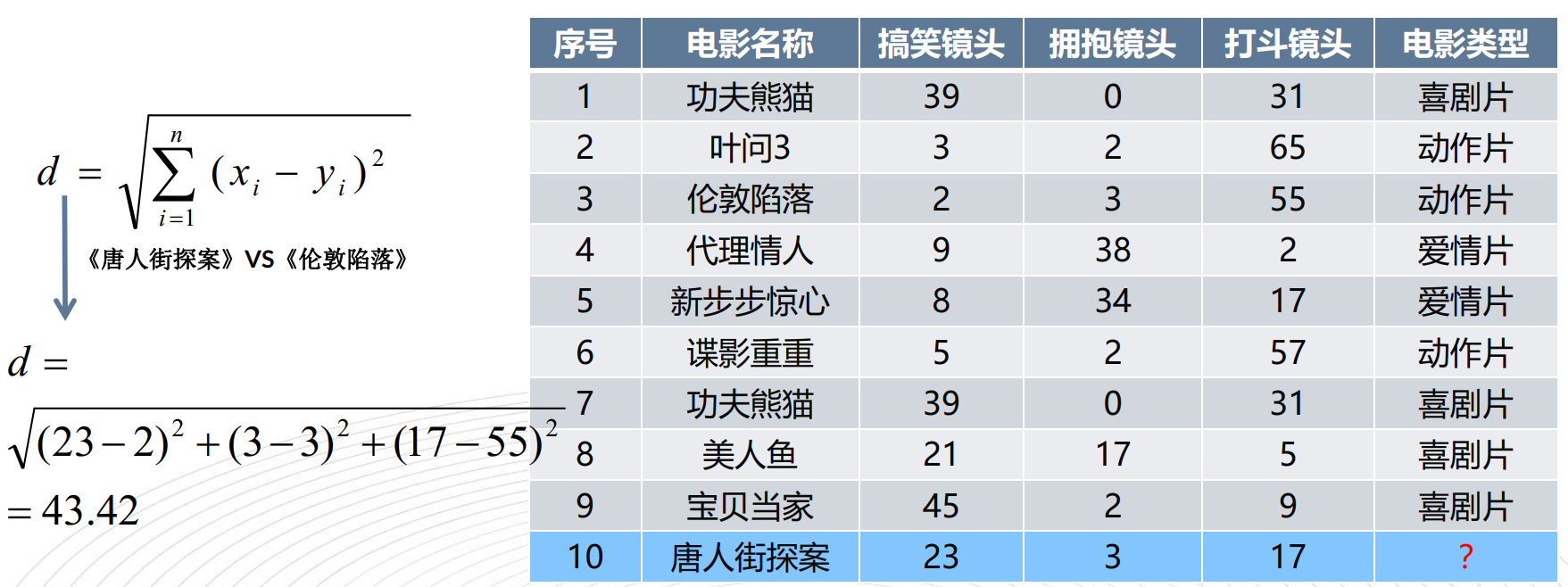
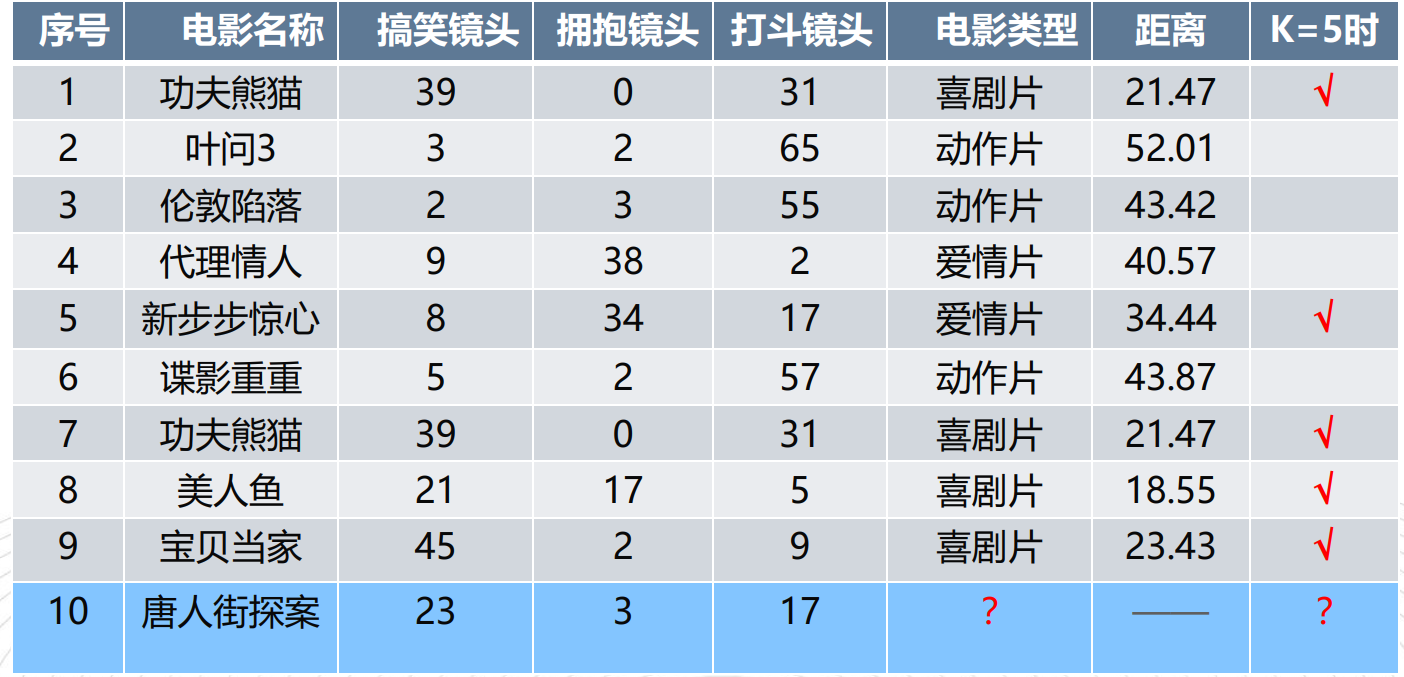
import math
movie_data = {"宝贝当家": [45, 2, 9, "喜剧片"],
"美人鱼": [21, 17, 5, "喜剧片"],
"澳门风云3": [54, 9, 11, "喜剧片"],
"功夫熊猫3": [39, 0, 31, "喜剧片"],
"谍影重重": [5, 2, 57, "动作片"],
"叶问3": [3, 2, 65, "动作片"],
"伦敦陷落": [2, 3, 55, "动作片"],
"我的特工爷爷": [6, 4, 21, "动作片"],
"奔爱": [7, 46, 4, "爱情片"],
"夜孔雀": [9, 39, 8, "爱情片"],
"代理情人": [9, 38, 2, "爱情片"],
"新步步惊心": [8, 34, 17, "爱情片"]}
# 测试样本 唐人街探案": [23, 3, 17, "?片"]
#下面为求与数据集中所有数据的距离代码:
x = [23, 3, 17]
KNN = []
for key, v in movie_data.items():
d = math.sqrt((x[0] - v[0]) ** 2 + (x[1] - v[1]) ** 2 + (x[2] - v[2]) ** 2)
KNN.append([key, round(d, 2)])
# 输出所用电影到 唐人街探案的距离
print(KNN)
#按照距离大小进行递增排序
KNN.sort(key=lambda dis: dis[1])
#选取距离最小的k个样本,这里取k=5;
KNN=KNN[:5]
print(KNN)
#确定前k个样本所在类别出现的频率,并输出出现频率最高的类别
labels = {"喜剧片":0,"动作片":0,"爱情片":0}
for s in KNN:
label = movie_data[s[0]]
labels[label[3]] += 1
labels =sorted(labels.items(),key=lambda l: l[1],reverse=True)
print(labels,labels[0][0],sep='\n')
代码和例子来自:https://blog.csdn.net/saltriver/article/details/52502253
2-2 K值的选择
一、近似误差与估计误差:
近似误差:对现有训练集的训练误差,关注训练集,如果近似误差过小可能会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较大偏差的预测。模型本身不是最接近最佳模型。
估计误差:可以理解为对测试集的测试误差,关注测试集,估计误差小说明对未知数据的预测能力好,模型本身最接近最佳模型。
二、K值确定标准:
K值过小:k值小,特征空间被划分为更多子空间(模型的项越多),整体模型变复杂,容易发生过拟合,k值越小,选择的范围就比较小,训练的时候命中率较高,近似误差小,而用test的时候就容易出错,估计误差大,容易过拟合。
K值=N:无论输入实例是什么,都将简单的预测他属于训练实例中最多的类。
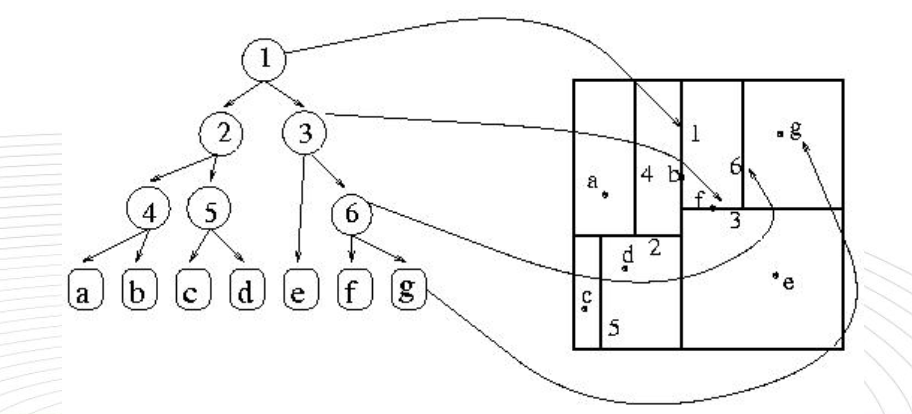
2-3 kd树
一、原理:
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。 kd树是是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。 利用kd树可以省去对大部分数据点的搜索, 从而减少搜索的计算量。
一个三维k-d树。 第一次划分(红色)把根节点(白色)划分成两个节点,然后它们分别再次被划分(绿色) 为两个子节点。最后这四个子节点的每一个都被划分(蓝色) 为两个子节点。 因为没有更进一步的划分, 最后得到的八个节点称为叶子节点
类比“二分查找”: 给出一组数据: [9 1 4 7 2 5 0 3 8], 要查找8。如果挨个查找(线性扫描),那么将会把数据集都遍历一遍。而如果排一下序那数据集就变成了: [0 1 2 3 4 5 6 7 8 9], 按前一种方式我们进行了很多没有必要的查找, 现在如果我们以5为分界点, 那么数据集就被划分为了左右两个“簇” [0 1 2 3 4]和[6 7 8 9]。
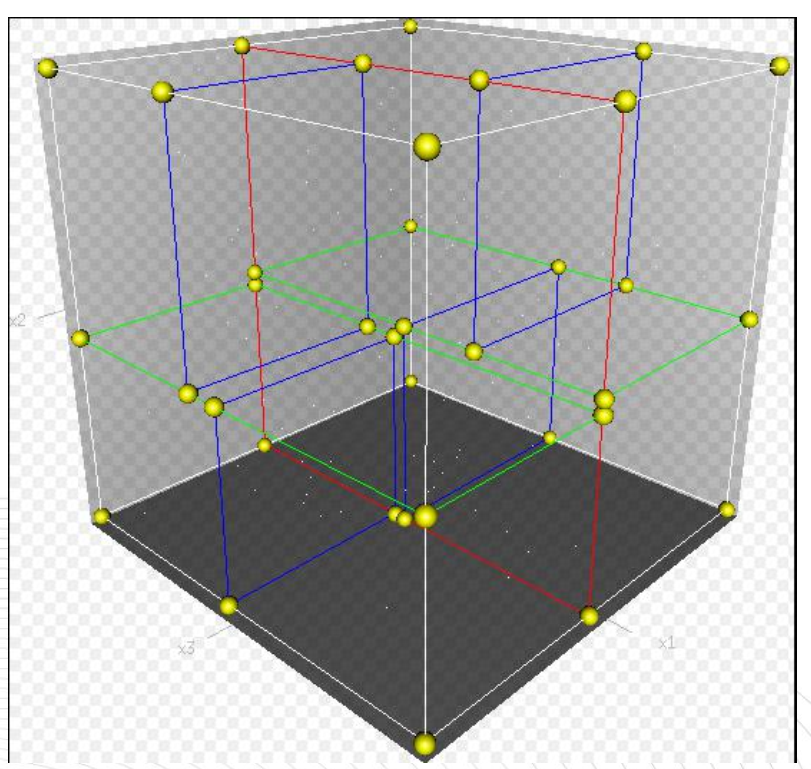
因此, 根本久没有必要进入第一个簇,可以直接进入第二个簇进行查找。把二分查找中的数据点换成k维数据点, 这样的划分就变成了用超平面对k维空间的划分。空间划分就是对数据点进行分类, “挨得近”的数据点就在一个空间里面。
二、构造方法:
第一个问题简单的解决方法可以是选择随机选择某一维或按顺序选择,但是更好的方法应该是在数据比较分散的那一维进行划分(分散的程度可以根据方差来衡量)。好的划分方法可以使构建的树比较平衡, 可以每次选择中位数来进行划分, 这样问题2也得到了解决。
代码实现:
# -*- coding: utf-8 -*-
#from operator import itemgetter
import sys
reload(sys)
sys.setdefaultencoding('utf8')
# kd-tree每个结点中主要包含的数据结构如下
class KdNode(object):
def __init__(self, dom_elt, split, left, right):
self.dom_elt = dom_elt # k维向量节点(k维空间中的一个样本点)
self.split = split # 整数(进行分割维度的序号)
self.left = left # 该结点分割超平面左子空间构成的kd-tree
self.right = right # 该结点分割超平面右子空间构成的kd-tree
class KdTree(object):
def __init__(self, data):
k = len(data[0]) # 数据维度
def CreateNode(split, data_set): # 按第split维划分数据集exset创建KdNode
if not data_set: # 数据集为空
return None
# key参数的值为一个函数,此函数只有一个参数且返回一个值用来进行比较
# operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为需要获取的数据在对象中的序号
#data_set.sort(key=itemgetter(split)) # 按要进行分割的那一维数据排序
data_set.sort(key=lambda x: x[split])
split_pos = len(data_set) // 2 # //为Python中的整数除法
median = data_set[split_pos] # 中位数分割点
split_next = (split + 1) % k # cycle coordinates
# 递归的创建kd树
return KdNode(median, split,
CreateNode(split_next, data_set[:split_pos]), # 创建左子树
CreateNode(split_next, data_set[split_pos + 1:])) # 创建右子树
self.root = CreateNode(0, data) # 从第0维分量开始构建kd树,返回根节点
# KDTree的前序遍历
def preorder(root):
print root.dom_elt
if root.left: # 节点不为空
preorder(root.left)
if root.right:
preorder(root.right)
if __name__ == "__main__":
data = [[2,3],[5,4],[9,6],[4,7],[8,1],[7,2]]
kd = KdTree(data)
preorder(kd.root)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140243.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
