大家好,又见面了,我是你们的朋友全栈君。
一,介绍
支持向量回归(SVR)是期望找到一条线,能让所有的点都尽量逼近这条线,从而对数据做出预测。
SVR的基本思路和SVM中是一样的,在ϵ−SVR需要解决如下的优化问题:

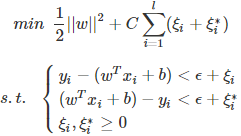
其回归图形如下:
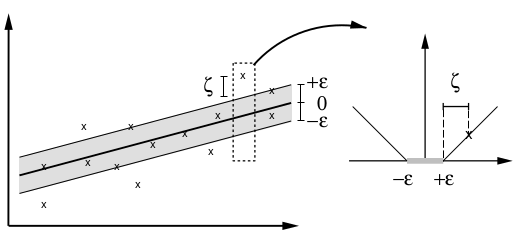
如上左图可知,在灰色区域,是正确回归的点。而还有一部分变量落在区域外,我们采用类似SVM中使用的方法,引入松弛因子,采取软边界的方法,如上右图。
二,拉格朗日对偶求解
类似与SVM,在SVR中,引入拉格朗日乘子,获得拉格朗日函数,再求解更加容易计算。拉格朗日函数如下:
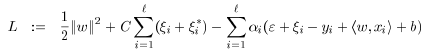
分别对w,b,,求导得:

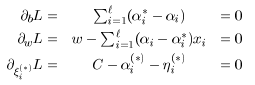
转化为对偶问题:
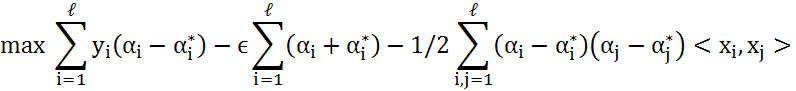
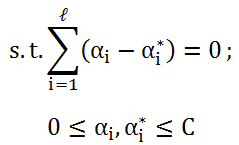
将w代入后获得:
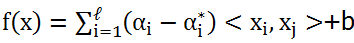
三,Python代码:
import numpy as np
from sklearn.svm import SVR
import matplotlib.pyplot as plt
# 随机产生样本点
X = np.sort(5 * np.random.rand(40, 1), axis=0) #产生40组数据,每组一个数据,axis=0决定按列排列,=1表示行排列
y = np.sin(X).ravel() #np.sin()输出的是列,和X对应,ravel表示转换成行
# 产生噪声
y[::5] += 3 * (0.5 - np.random.rand(8))
# SVC拟合
def svcrbfModel():
svr_rbf10 = SVR(kernel='rbf',C=100, gamma=10.0)
svr_rbf1 = SVR(kernel='rbf', C=100, gamma=0.1)
y_rbf10 = svr_rbf10.fit(X, y).predict(X)
y_rbf1 = svr_rbf1.fit(X, y).predict(X)
return y_rbf10,y_rbf1
#画图
def showPlot(y_rbf10,y_rbf1):
lw = 2 #line width
plt.scatter(X, y, color='darkorange', label='data')
plt.hold('on')
plt.plot(X, y_rbf10, color='navy', lw=lw, label='RBF gamma=10.0')
plt.plot(X, y_rbf1, color='c', lw=lw, label='RBF gamma=1.0')
plt.xlabel('data')
plt.ylabel('target')
plt.title('Support Vector Regression')
plt.legend()
plt.show()
if __name__ == '__main__':
y_rbf10, y_rbf1= svcrbfModel()
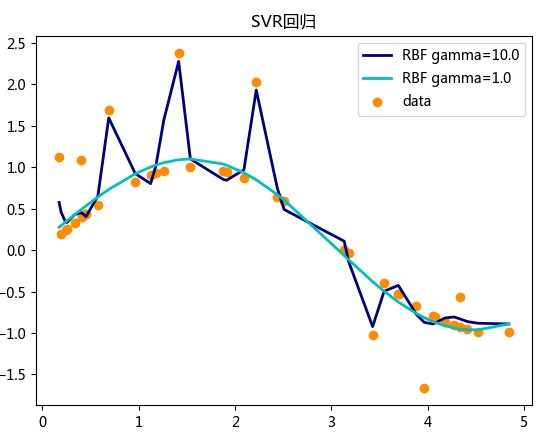
showPlot(y_rbf10,y_rbf1)产生如下结果:
sklearn.svm.SVR参数说明如下:
- C:惩罚项,float类型,可选参数,默认为1.0,C越大,即对分错样本的惩罚程度越大,因此在训练样本中准确率越高,但是泛化能力降低,也就是对测试数据的分类准确率降低。相反,减小C的话,容许训练样本中有一些误分类错误样本,泛化能力强。对于训练样本带有噪声的情况,一般采用后者,把训练样本集中错误分类的样本作为噪声。
- kernel:核函数类型,str类型,默认为’rbf’。可选参数为:
- ‘linear’:线性核函数
- ‘poly’:多项式核函数
- ‘rbf’:径像核函数/高斯核
- ‘sigmod’:sigmod核函数
- ‘precomputed’:核矩阵
- precomputed表示自己提前计算好核函数矩阵,这时候算法内部就不再用核函数去计算核矩阵,而是直接用你给的核矩阵,核矩阵需要为n*n的。
- degree:多项式核函数的阶数,int类型,可选参数,默认为3。这个参数只对多项式核函数有用,是指多项式核函数的阶数n,如果给的核函数参数是其他核函数,则会自动忽略该参数。
- gamma:核函数系数,float类型,可选参数,默认为auto。只对’rbf’ ,’poly’ ,’sigmod’有效。如果gamma为auto,代表其值为样本特征数的倒数,即1/n_features。
- coef0:核函数中的独立项,float类型,可选参数,默认为0.0。只有对’poly’ 和,’sigmod’核函数有用,是指其中的参数c。
- probability:是否启用概率估计,bool类型,可选参数,默认为False,这必须在调用fit()之前启用,并且会fit()方法速度变慢。
- shrinking:是否采用启发式收缩方式,bool类型,可选参数,默认为True。
- tol:svm停止训练的误差精度,float类型,可选参数,默认为1e^-3。
- cache_size:内存大小,float类型,可选参数,默认为200。指定训练所需要的内存,以MB为单位,默认为200MB。
- class_weight:类别权重,dict类型或str类型,可选参数,默认为None。给每个类别分别设置不同的惩罚参数C,如果没有给,则会给所有类别都给C=1,即前面参数指出的参数C。如果给定参数’balance’,则使用y的值自动调整与输入数据中的类频率成反比的权重。
- verbose:是否启用详细输出,bool类型,默认为False,此设置利用libsvm中的每个进程运行时设置,如果启用,可能无法在多线程上下文中正常工作。一般情况都设为False,不用管它。
- max_iter:最大迭代次数,int类型,默认为-1,表示不限制。
- decision_function_shape:决策函数类型,可选参数’ovo’和’ovr’,默认为’ovr’。’ovo’表示one vs one,’ovr’表示one vs rest。
- random_state:数据洗牌时的种子值,int类型,可选参数,默认为None。伪随机数发生器的种子,在混洗数据时用于概率估计。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140014.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
