大家好,又见面了,我是你们的朋友全栈君。
基于DCNN的人脸特征点定位
原文地址:http://blog.csdn.net/hjimce/article/details/49955149
作者:hjimce
一、相关理论
本篇博文主要讲解2013年CVPR的一篇利用深度学习做人脸特征点定位的经典paper:《Deep Convolutional Network Cascade for Facial Point Detection》,论文的主页为:http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm 。网页提供了训练数据、测试demo,但是我却没有找到源码,所以只能自己写代码实现。这篇paper是利用深度学习搞人脸特征点定位的开山之作,想当年此算法曾经取得了state-of-art 的结果。后来face++发表的几篇paper的思想,都是在这篇paper的算法上进行扩展的。
如果之前没有学过类似DCNN的思想的话,那么会感觉相当难,至少我是这么觉得的。在之前学过的各种深度学习模型中,一般就只有一个CNN,可这篇paper是由十几个CNN组成的。我一看到文献中如下网络结构图片:

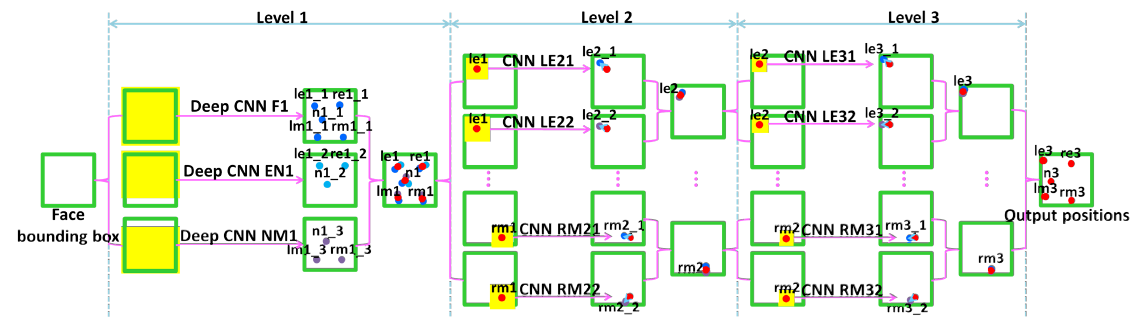
作为菜鸟的我,就已经晕了,然后在看一下文献的一些公式,我彻底没了耐性。因为我看外文paper,一般首先会直接看图、看公式,可这篇paper的图,一上来就把我吓到了。之前学过反卷积网络,FCN、R-CNN、FR-CNN、OverFeat、Siamese Network、NIN等等各种网络,感觉花个一两天的时间,总可以把算法想通。可是学了这篇paper之后,感觉难度完全不是一个等级的,因为初次接触这种DCNN,花了好几周的时间,才把源码实现出来,过程相当痛苦,好吧,还是不罗嗦了,这篇博文将仔细讲解paper算法的实现过程,领略不一样的CNN模型,也就是传说中的DCNN(这篇paper,后来人们又把这种多层次的CNN模型称之为DCNN)。接着我将先简单介绍,文章的主要思想。
1、RCNN回顾
paper的总思想是一种从粗到精的定位思想,如果你之前已经对R-CNN有所了解,我们就回忆一下现在的一些物体检测的大体算法思路,因为我觉得RCNN也是一种从粗定位,到精识别的过程,跟本篇paper的思想很相似,下面是RCNN的流程图(RCNN文献《Region-based Convolutional Networks for Accurate Object Detection and Segmentation》):
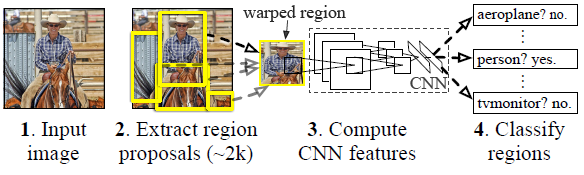
首先输入一张图片,然后RCNN的思路是:
(1)采用传统的方法,先把一张图片中各个可能的物体的bounding box分割出来
(2)把各个可能的裁剪出来的物体检测框,输入cnn,进行特征提取,最后进行物体分类识别
OK,算法的总体思路很简单。其实这也是一种从粗到精的思想,就是我们对输入的一整张图片先进行粗定位,先定位出物体的bounding box,也就是物体的大体的位置。然后进行裁剪(bouding box),这样我们裁剪出来的图片范围就变小了,外界背景因素的干扰就减小了,然后我们在把裁剪后的图片,作为CNN的输入,这样有利于提高精度。总之,假设你要用CNN做人脸识别,那么你就不应该把一整张图片,包括风景、背景、身体、头发这些背景因素都扔进CNN中,这样的精度会比较小。你应该是先用人脸检测器,把人脸部位的图片裁剪出来,送入CNN中,精度才会较高。OK,可能你觉得,我这边讲的话题有点废话,其实《Deep Convolutional Network Cascade for Facial Point Detection》这篇paper的思想就是这样,很简单的一个思想。
2、paper的思想

图 1
回到本篇文章的主题,特征点定位。以上面的图片为例,假设我们要定位出上面的5个人脸特征点,从粗定位到精定位的过程如下(下面我先用最简单的理解方式,讲解粗到精的定位过程,先不根据paper的算法进行讲解,等明白了粗定精的定位过程,我们再结合paper的算法进行细讲):
(1) level1。首先我们要做的第一步,把人脸图片裁剪出来,而不是直接把上面的一整张图片,扔到CNN中,因为上面图片包含的范围太大了,我们需要使得输入CNN的图片范围越小越好,比如裁剪成下面的图片,然后输入CNN中(我们只需要保证要定位的5个特征点包含在里面就可以了):

图 2
因此网络的第一层次CNN模型,我们的目标就是要定位出包含这5个特征点的最小包围盒,缩小搜索范围(paper没有这一层,它所采用的算法是直接采用人脸检测器,但是如果采用cnn,先定位出5个特征点的bounding box 精度会比直接采用人脸检测器,定位精度来的高,这个可以从后面face++发表的paper:《Extensive Facial Landmark Localization with Coarse-to-fine Convolutional Network Cascade》中看到,这篇我以后会在另外一篇博文中讲解,这边只是为了方便理解)
本层次CNN模型的输入:原始图片(图1)
本层次CNN模型的输出:包含五个特征点的bonding box,预测出bounding box后,把它裁剪出来,得到图2
(2) level2。接着我们采用CNN,粗定位出这五个特征点,如下图所示(换了一张示例图片,将就一下):

图 3
上面示例图中,蓝色的点是正确的点;然后红色的点是,我们采用本层次网络CNN模型,预测定位出来的特征点。可以看到红色的点和正确的蓝色点,之间还是有很大的误差,这就是所谓的粗定位,只能大体的搜索到各个点的位置,精度还有待提高。这一层次,又称之为网络特征点的初始定位层,很粗糙的一个定位。然后根据我们cnn的粗定位点,也就是红色的点,作为中心,进行裁剪出一个小的矩形区域,进一步缩小搜索范围:

鼻子

左右嘴角

左右眼睛
图 4
本层次CNN模型输入:包含五个特征点的bounding box图片(也就是图 2)
本层次CNN模型输出:预测出五个特征点的初始位置,得到图3的红色特征点位置,预测出来以后,进行裁剪,把各个特征点的一个小区域范围中的图片裁剪出来,得到图4
(3) level3。这一层又称之位精定位。
因此接着我们就要分别设计5个CNN模型,用于分别输入上面的5个特征点所对应的图片区域了,然后用于分别定位,找到蓝色正确点的坐标。通过图4的裁剪,我们的搜索的范围一下子小了很多,就只有小小的一个范围而已了。这边需要注意,各个部位的CNN模型参数是不共享的,也就是各自独立工作,5个CNN用于分别定位5个点。每个CNN的输出是两个神经元(因为一个CNN,只定位1个特征点,一个特征点,包含了(x,y)两维)。声明:这一层次的网络,文献不仅仅包含了5个CNN,它是用了10个CNN,每个特征点有两个CNN训练预测,然后进行平均,我们这里可以先忽略这一点,影响不大。
本层次CNN模型输入:各个特征点,对应裁剪出来的图片区域,如图4
本层次CNN模型输出:各个特征点的精定位位置。
OK,到了这里,基本讲完了,从粗定位到精定位的思想了,如果看不懂,就得结合文献,反复的读了,因为只有懂了这个思想,才能进行下一步。
二、网络架构
上面只是对从粗到精的思想,大体的思路进行了讲解,但是具体我们要怎么实现,代码要怎么实现,各个网络是如何训练的?因此接着我要讲的就是细节、代码实现问题,上面讲解从粗到精的思想的时候,我为了方便理解,所以有的一些细节也没有根据文献的讲。这一部分,我们将根据文献的一步一步,每个细节,网络结构进行讲解。首先我们先再次看一下网络的结构图:
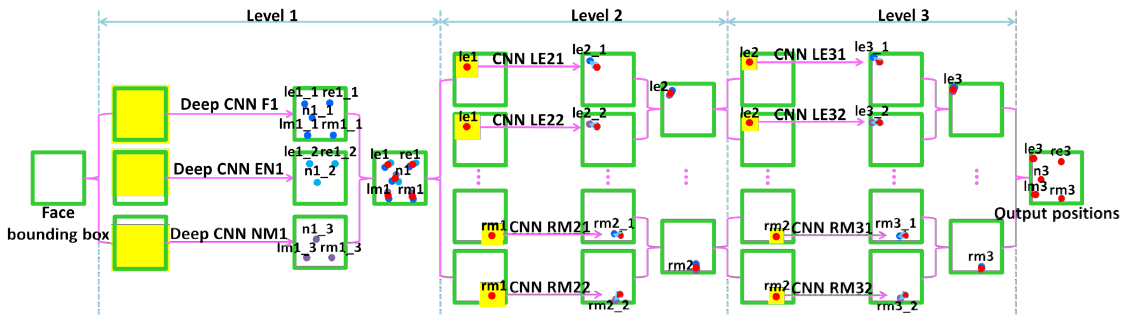
这篇papar的DCNN,总体上分成三大部分,分别是:level 1、level 2、level 3。每个level 里面,包含着好几个CNN模型,我们将一步一步剖析这个网络结构。在最开始的时候,首先,我们利用人脸检测器,裁剪出人脸图片,具体的人脸检测器的就是用我们传统的方法,比如haar特征。然后把我们裁剪出来的人脸图片,作为level 1的输入。下面开始分层次讲解各个level 的具体细节(在此不要纠结level 这个词怎么翻译,如果非要理解这个词,可以用“等级”,leve 1表示最粗糙的等级,然后level 2表示精等级,level 3表示更精的等级)。
1、level 1网络架构
网络的输入:我们通过人脸检测器,裁剪出face bounding box,然后把它转换成灰度图像,最后缩放到39*39大小的图片,这个39*39的图片,将作为我们level 1的输入。在网络的第一层次上,由三个卷积神经网络组成,这三个卷积神经网络分别命名为:F1(网络的输入为一整张人脸图片),EN1(输入图片包含了眼睛和鼻子)、NM1(包含了鼻子和嘴巴区域)。这三个卷积网络区别在于输入的图片区域不同:
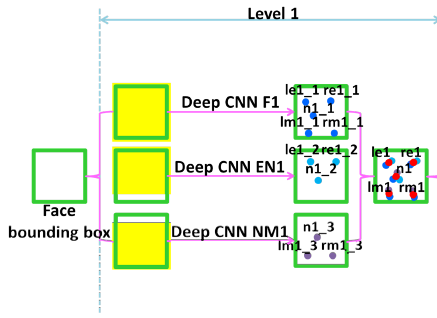
第一层次网络
A、F1结构
F1的输入为整个人脸图片(39*39的大小),输出为我们所要预测的五个特征点。F1的网络结构如下:
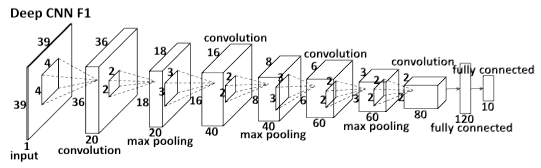
F1的网络结构图
输入一张人脸图片大小为39*39,然后通过卷积神经网络,输出一个10维的特征向量(5个特征点)。F1的结构,第一个层特征图选择20,第二次卷积特征图个数选择40,然后接着是60、80。具体各层的参数可以参考下面表格:
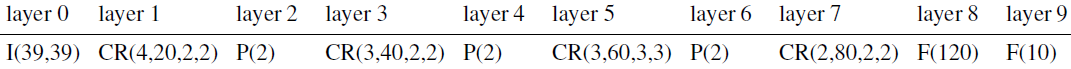
F1网络参数
I(39,39)表示输入图片大小为39*39,P(2)应该表示池化为stride大小为2。具体的各层参数我就不再详解,因为这个不是重点,而且即便是你没有根据paper的结构进行设计,对精度的影响也不大(只要你设计的网络合理,不要出现过拟合、欠拟合都OK)
B、EN1、NM1的网络结构
这两个CNN和F1基本相同,不过输入图片的大小不同,输出神经元的个数也不相同。
EN1用于定位:左眼+右眼+鼻子 三个特征点,因此自然而然,网络设计的时候,输出层的神经元个数就是6。然后输入的图片,是我们根据比例裁剪的,我们把39*39图片的上半部分裁剪出来,裁剪出31*39大小的图片,当然裁剪大小比例这个是一个经验裁剪,我们只要保证裁剪的区域包含了眼睛和鼻子区域就好了。
NM1用于定位:左嘴角+右嘴角+鼻子 三个特征点。同样的,网络的输出就是6个神经元,输入部分,从人脸的底部往上裁剪,也是裁剪出31*39的图片,只要裁剪出来的区域,只包含嘴巴和鼻子,就OK了。具体这两个CNN的各层相关参数,如下表格中的S1行所示(S0是F1,S1是EN1、NM1):

EN1\NM1网络参数
那么F1、EN1、NM1三个网络是怎么连接在一起的?我们通过平均的方法,把重复预测的特征点进行位置平均。比如我们的鼻子点,三个网络都可以预测到位置,那么我们就把这三个网络预测出来的鼻子点,三个点相加,然后除以3,就可以得到平均位置了。再如,右眼睛,我们F1、EN1这两个网络有预测,我们就把这两个网络预测到的右眼睛点相加在一起,然后除以2,就得到平均位置了。
那么为什么要搞得这么复杂了,为什么要用三个网络进行分别预测,然后进行平均呢?其实这个就像Alexnet一样,采用平均预测的方法,可以提高网络的稳定性,提高精度,如果你之前已经学过Alexnet,就会明白作者为什么要用平均预测。总之”平均“,可以提高网络的稳定性、防止预测特征点的位置偏差过大,提高精度。
OK,我们大体知道了level 1由三个CNN组成,三个CNN分别预测各自所需要的特征点,然后进行位置平均。这三个CNN都包含了9层(如上面的表格所示),算是一个深度网络。level 1因为是粗定位,输入的图片区域比较大,特征提取难度比较大,所以我们设计这一层级网络的时候,需要保证网络的深度,用于提取复杂的特征(原理解释请自己查看paper)。突然感觉讲到这边,有点累了,好漫长的算法,感觉才讲了一半左右,坚持……
2、level 2 网络架构
A、level 2的输入
经过了level 1 我们大体可以知道了,各个特征点的位置,接着我们要减小搜索范围,我们以第一层级预测到的特征点,以这五个预测特征点为中心,然后用一个较小的bbox,把这五个特征点的小区域范围内的图片裁剪出来,如下图所示:
鼻子
左右嘴角
左右眼睛
level 2 输入
上图中,红色的点就是我们用level 1 预测出来的位置,然后在进行裁剪(上面图,我是自己手动随便裁剪的,因为比较懒,所以就随便做了一个示意图,我们程序裁剪的时候,是以预测点为中心点,裁剪出一个矩形框)。OK,既然是裁剪,那么我们要裁剪多大?这个可以从下面表格参数中知道,level 2采用的是S2行,我们只需要看S2那一行参数就可以了:

我们裁剪的时候,是以level 1的特征点为中心,裁剪出小区域范围的图片。
B、网络总体结构
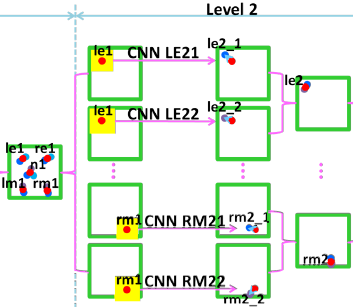
level 2 组成
本层次的网络CNN个数可就多了,level 2 由10个CNN组成,每个CNN网络层数、每层的相关参数,如上面的表格中S2那一行所示。总之就是leve 2 和level 3的结构都是用了S2那一行的参数,每个CNN包含6层。
哎,看到上面level 2的10个CNN,估计会有点晕,其实很简单,且听我细细道来:这10个CNN,分别用于预测5个特征点,每个特征点用了两个CNN,然后两个CNN对预测的结果进行平均。我们以左眼特征点为例,我们用表格S2行的参数设计出了LE21、LE22,我们在训练的时候,训练了两个模型,这两个CNN都是用于预测左眼特征点,然后我们使用的时候,就直接用这两个CNN预测到的特征点,做位置平均。总之一句话就是:还是平均,跟level 1一样,也是用多个CNN进行位置平均。
3、level 3网络架构
level 3是在level 2得到预测点位置的基础上,重新进行裁剪。我们知道由level 2的网络,我们可以进一步得到那5个特征点的位置(离正确的点越近了),然后我们利用level 2的预测位置,重新进行裁剪。然后在重新进行预测,level 3的总体结构如下:
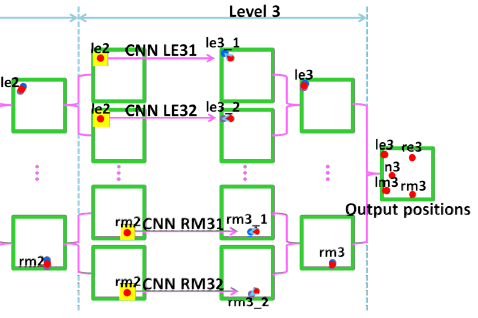
与level 2结构相同,也是由10个CNN组成,每两个CNN预测1个特征点。那么level 3和level 2的区别在哪里呢?首先我们的裁剪区域发生了变化,我们也可以让level 3的裁剪图片大小再变得更小一些。
三、网络训练
测试误差评价标准公式如下:
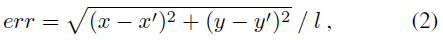
其中l是人脸框的长度。
其它细节:
1、采用local shared weights 有助于level 1的精度提高
2、采用abs+tanh 激活,可以提高网络性能:
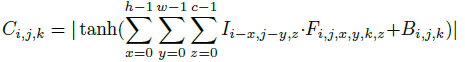
OK,终于解放了,讲解完毕,对于人脸特征点的定位,出了从粗到精的定位方法,后面还有一些paper采用的是mutil-task方法,好像很不错的样子,以后在慢慢学习。
参考文献:
1、《Deep Convolutional Network Cascade for Facial Point Detection》
2、《Extensive Facial Landmark Localization with Coarse-to-fine Convolutional Network Cascade》
3、《Face Alignment at 3000 FPS via Regressing Local Binary Features》
4、《Face Alignment by Explicit Shape Regression》
**********************作者:hjimce 时间:2015.11.1 联系QQ:1393852684 地址:http://blog.csdn.net/hjimce 原创文章,版权所有,转载请保留本行信息(不允许删除)********************
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139818.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
