大家好,又见面了,我是你们的朋友全栈君。
在大家开始深度学习时,几乎所有的入门教程都会提到CUDA这个词。那么什么是CUDA?她和我们进行深度学习的环境部署等有什么关系?通过查阅资料,我整理了这份简洁版CUDA入门文档,希望能帮助大家用最快的时间尽可能清晰的了解这个深度学习赖以实现的基础概念。
本文在以下资料的基础上整理完成,感谢以下前辈提供的资料:
CUDA——“从入门到放弃”
我的CUDA学习之旅——启程
介绍一篇不错的CUDA入门博客 (该文引用的原链接失效,因此直接引用了此地址)
CUDA编程入门极简教程
显卡、GPU和CUDA简介
CPU、GPU
CPU
CPU(Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。
CPU与内部存储器(Memory)和输入/输出(I/O)设备合称为电子计算机三大核心部件。CPU主要包括运算器(算术逻辑运算单元,ALU,Arithmetic Logic Unit)、控制单元(CU, Control Unit)、寄存器(Register)、和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。简单来说就是:计算单元、控制单元和存储单元。CPU遵循的是冯诺依曼架构,其核心就是:存储程序,顺序执行。
因为CPU的架构中需要大量的空间去放置存储单元和控制单元,相比之下计算单元只占据了很小的一部分,所以它在大规模并行计算能力上极受限制,而更擅长于逻辑控制。
GPU
显卡(Video card,Graphics card)全称显示接口卡,又称显示适配器,是计算机最基本配置、最重要的配件之一。显卡是电脑进行数模信号转换的设备,承担输出显示图形的任务。具体来说,显卡接在电脑主板上,它将电脑的数字信号转换成模拟信号让显示器显示出来,同时显卡还是有图像处理能力,可协助CPU工作,提高整体的运行速度。在科学计算中,显卡被称为显示加速卡。
原始的显卡一般都是集成在主板上,只完成最基本的信号输出工作,并不用来处理数据。显卡也分为独立显卡和集成显卡。一般而言,同期推出的独立显卡的性能和速度要比集成显卡好、快。
| 类型 | 位置 | 内存 |
|---|---|---|
| 集成显卡 | 集成在主板上,不能随意更换 | 使用物理内存 |
| 独立显卡 | 作为一个独立的器件插在主板的AGP接口上的,可以随时更换升级 | 有自己的显存 |
随着显卡的迅速发展,GPU这个概念由NVIDIA公司于1999年提出。GPU是显卡上的一块芯片,就像CPU是主板上的一块芯片。集成显卡和独立显卡都是有GPU的。


CPU与GPU
在没有GPU之前,基本上所有的任务都是交给CPU来做的。有GPU之后,二者就进行了分工,CPU负责逻辑性强的事物处理和串行计算,GPU则专注于执行高度线程化的并行处理任务(大规模计算任务)。GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)。
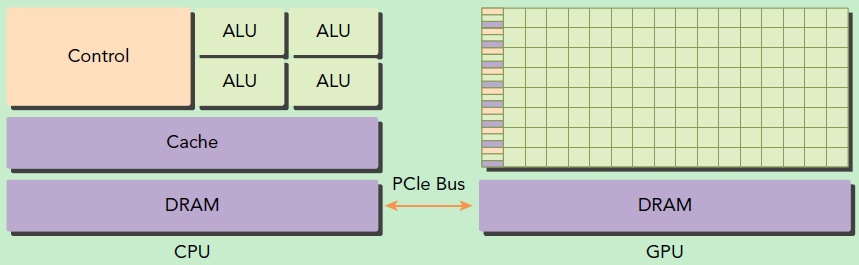
GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。因此,基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。GPU无论发展得多快,都只能是替CPU分担工作,而不是取代CPU。
GPU中有很多的运算器ALU和很少的缓存cache,缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为线程thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问DRAM。
CUDA编程模型基础
CUDA
2006年,NVIDIA公司发布了CUDA(Compute Unified Device Architecture),是一种新的操作GPU计算的硬件和软件架构,是建立在NVIDIA的GPUs上的一个通用并行计算平台和编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序,利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。它将GPU视作一个数据并行计算设备,而且无需把这些计算映射到图形API。操作系统的多任务机制可以同时管理CUDA访问GPU和图形程序的运行库,其计算特性支持利用CUDA直观地编写GPU核心程序。
CUDA提供了对其它编程语言的支持,如C/C++,Python,Fortran等语言。只有安装CUDA才能够进行复杂的并行计算。主流的深度学习框架也都是基于CUDA进行GPU并行加速的,几乎无一例外。还有一个叫做cudnn,是针对深度卷积神经网络的加速库。
CUDA在软件方面组成有:一个CUDA库、一个应用程序编程接口(API)及其运行库(Runtime)、两个较高级别的通用数学库,即CUFFT和CUBLAS。CUDA改进了DRAM的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA提供了片上(on-chip)共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少DRAM的数据传送,更少的依赖DRAM的内存带宽。
编程模型
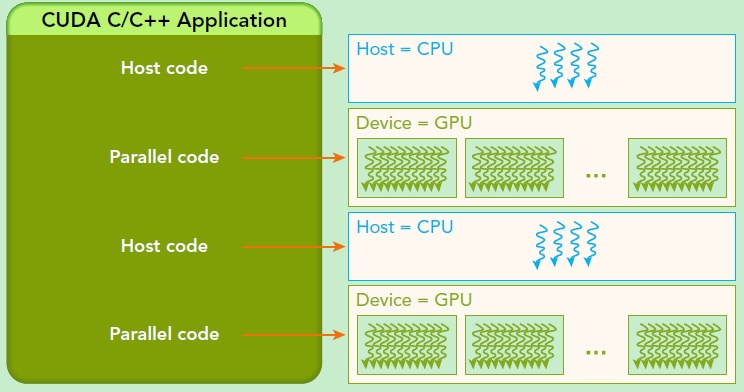
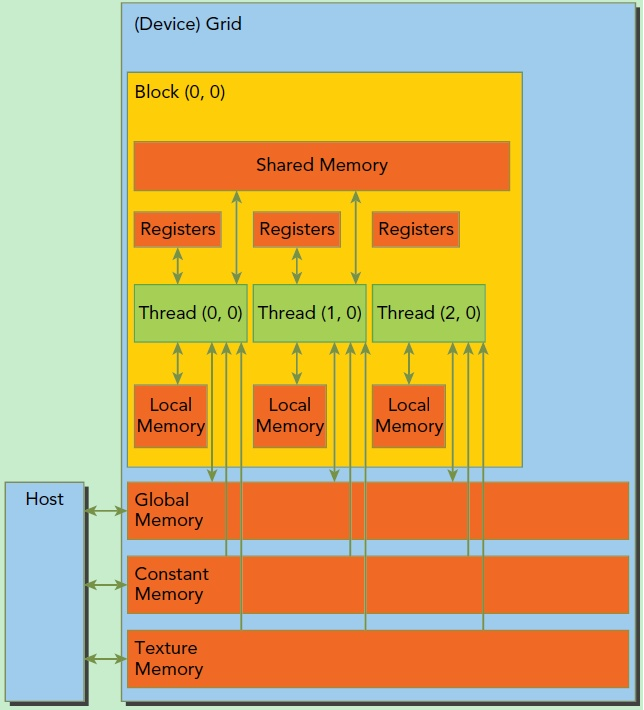
CUDA的架构中引入了主机端(host)和设备(device)的概念。CUDA程序中既包含host程序,又包含device程序。同时,host与device之间可以进行通信,这样它们之间可以进行数据拷贝。
主机(Host):将CPU及系统的内存(内存条)称为主机。
设备(Device):将GPU及GPU本身的显示内存称为设备。
动态随机存取存储器(DRAM):Dynamic Random Access Memory,最为常见的系统内存。DRAM只能将数据保持很短的时间。为了保持数据,DRAM使用电容存储,所以必须隔一段时间刷新(refresh)一次,如果存储单元没有被刷新,存储的信息就会丢失。(关机就会丢失数据)
典型的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
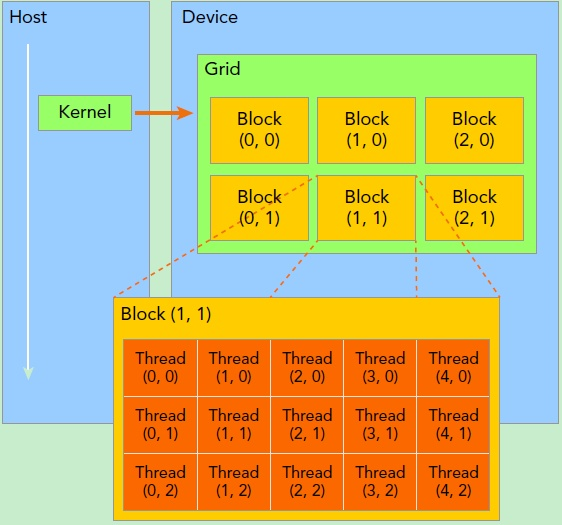
线程层次结构
核 kernel
CUDA执行流程中最重要的一个过程是调用CUDA的核函数来执行并行计算,kernel是CUDA中一个重要的概念。在CUDA程序构架中,主机端代码部分在CPU上执行,是普通的C代码;当遇到数据并行处理的部分,CUDA 就会将程序编译成GPU能执行的程序,并传送到GPU,这个程序在CUDA里称做核(kernel)。设备端代码部分在GPU上执行,此代码部分在kernel上编写(.cu文件)。kernel用__global__符号声明,在调用时需要用<<<grid, block>>>来指定kernel要执行及结构。
CUDA是通过函数类型限定词区别在host和device上的函数,主要的三个函数类型限定词如下:
- global:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
- device:在device上执行,单仅可以从device中调用,不可以和__global__同时用。
- host:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__同时使用,此时函数会在device和host都编译。
网格 grid
kernel在device上执行时,实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间。grid是线程结构的第一层次。
线程块 block
网格又可以分为很多线程块(block),一个block里面包含很多线程。各block是并行执行的,block间无法通信,也没有执行顺序。block的数量限制为不超过65535(硬件限制)。第二层次。
grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1。grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构。
CUDA中,每一个线程都要执行核函数,每一个线程需要kernel的两个内置坐标变量(blockIdx,threadIdx)来唯一标识,其中blockIdx指明线程所在grid中的位置,threaIdx指明线程所在block中的位置。它们都是dim3类型变量。
一个线程在block中的全局ID,必须还要知道block的组织结构,这是通过线程的内置变量blockDim来获得。它获取block各个维度的大小。对于一个2-dim的block(D_x,D_y),线程 (x,y) 的ID值为(x+y∗D_x),如果是3-dim的block (D_x,D_y,D_z),线程(x,y,z)的ID值为(x+y∗D_x+z∗D_x∗D_y) 。另外线程还有内置变量gridDim,用于获得grid各个维度的大小。
每个block有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。
每个thread有自己的私有本地内存(Local Memory)。此外,所有的线程都可以访问全局内存(Global Memory),还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)。
线程 thread
一个CUDA的并行程序会被以许多个threads来执行。数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
线程束 warp
GPU执行程序时的调度单位,SM的基本执行单元。目前在CUDA架构中,warp是一个包含32个线程的集合,这个线程集合被“编织在一起”并且“步调一致”的形式执行。同一个warp中的每个线程都将以不同数据资源执行相同的指令,这就是所谓 SIMT架构(Single-Instruction, Multiple-Thread,单指令多线程)。
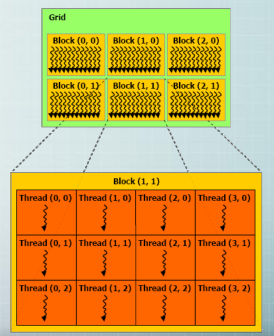
CUDA的内存模型
SP:最基本的处理单元,streaming processor,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
SM:GPU硬件的一个核心组件是流式多处理器(Streaming Multiprocessor)。SM的核心组件包括CUDA核心、共享内存、寄存器等。SM可以并发地执行数百个线程。一个block上的线程是放在同一个流式多处理器(SM)上的,因而,一个SM的有限存储器资源制约了每个block的线程数量。在早期的NVIDIA 架构中,一个block最多可以包含 512个线程,而在后期出现的一些设备中则最多可支持1024个线程。一个kernel可由多个大小相同的block同时执行,因而线程总数应等于每个块的线程数乘以块的数量。
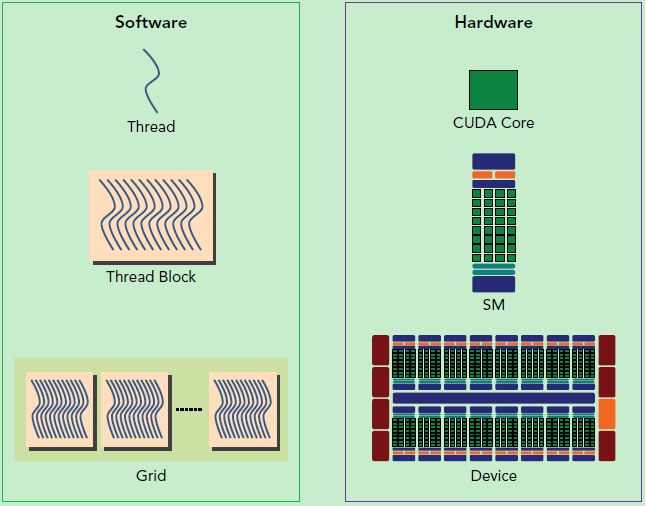
一个kernel实际会启动很多线程,这些线程是逻辑上并行的,但是网格和线程块只是逻辑划分,SM才是执行的物理层,在物理层并不一定同时并发。原因如下:
- 当一个kernel被执行时,它的gird中的block被分配到SM上,一个block只能在一个SM上被调度。SM一般可以调度多个block,这要看SM本身的能力。有可能一个kernel的各个block被分配至多个SM上,所以grid只是逻辑层,SM才是执行的物理层。
- 当block被划分到某个SM上时,它将进一步划分为多个wraps。SM采用的是SIMT,基本的执行单元是wraps,一个wrap包含32个线程,这些线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。所以尽管wraps中的线程同时从同一程序地址执行,但是可能具有不同的行为,比如遇到了分支结构,一些线程可能进入这个分支,但是另外一些有可能不执行,它们只能死等,因为GPU规定warp中所有线程在同一周期执行相同的指令,线程束分化会导致性能下降。
综上,SM要为每个block分配shared memory,而也要为每个warp中的线程分配独立的寄存器。所以SM的配置会影响其所支持的线程块和线程束并发数量。所以kernel的grid和block的配置不同,性能会出现差异。还有,由于SM的基本执行单元是包含32个线程的warp,所以block大小一般要设置为32的倍数。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139657.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
