大家好,又见面了,我是你们的朋友全栈君。
文章目录
表的生成参考《
3. SQL–数据库基础查询操作》。
前几节所总结的查询,都是基于单张表格进行的,如果单张表格的信息不足以达到查询的目的,就需要将他们组合到一起形成多张表格。
1. 表的加法
表的加法,就是将两张表的记录进行合并,使用UNION 或者UNION ALL。
首先我们新建一张表,执行如下代码,新建course1表格:
DROP TABLE IF EXISTS `course1`;
CREATE TABLE `course1` (
`课程号` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`课程名称` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`教师号` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
PRIMARY KEY (`课程号`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
-- ----------------------------
-- Records of course
-- ----------------------------
INSERT INTO `course1` VALUES ('0001', '语文', '0002');
INSERT INTO `course1` VALUES ('0004', '计算机', '0001');
INSERT INTO `course1` VALUES ('0005', '数据库', '0003');
对于如下图两张表格:
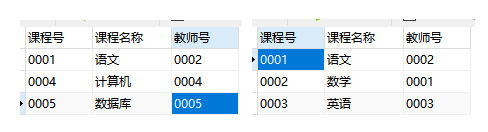

其中,左边是course1,右边是course。
1.1 UNION 去重合并
通过如下代码执行UNION加法:
SELECT 课程号,课程名称
FROM course
UNION
SELECT 课程号,课程名称
FROM course1;
得到结果如图所示:
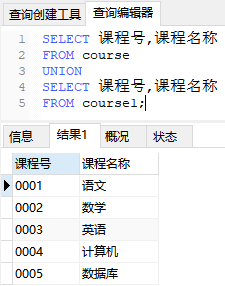
其中,可以发现两张表中相同的语文(这里的相同指的是所查课程号和课程名称两列完全相同),自动完成了去重操作。
1.2 UNION ALL 简单合并
通过如下代码执行UNION ALL :
SELECT 课程号,课程名称
FROM course
UNION ALL
SELECT 课程号,课程名称
FROM course1;
结果如下图:
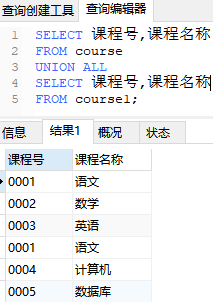
可以看到,UNION ALL 只是简单加法,并不去重。
1.3 注意事项
- UNION 和 UNION ALL的区别主要在于去重
- 去重的标准是所查内容列相同,算作重复。
- 使用UNION 和 UNION ALL 必须保证两个子查询,列的字段名和顺序以及数据类型一致。
2. 表的联结 JOIN
关系数据库中,本质上就是表与表之间能够有关系,才能够使用二维表表达几乎所有的数据。
联结:通过表与表之间的关系,将表合并到一起的操作。
我们数据库中,如下四张表的关系通过某一列联结到一起,如下图所示:
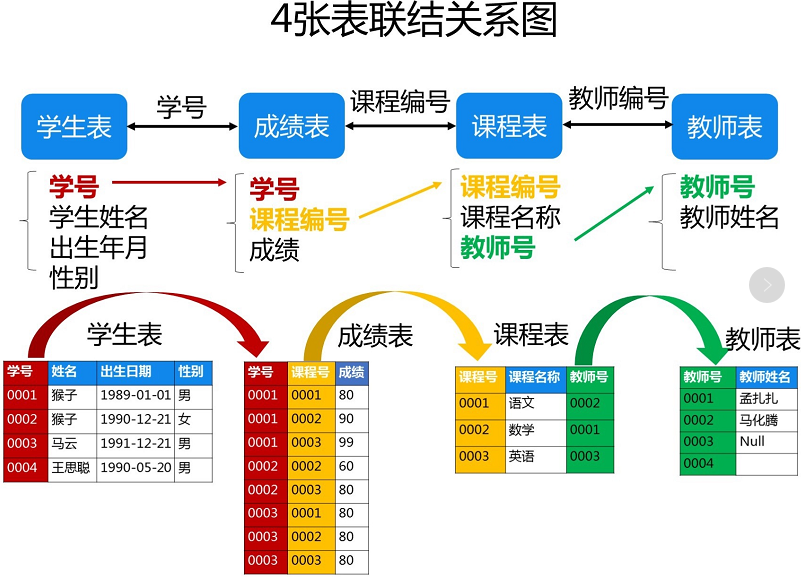
其中可以清晰的看到表与表之间是通过哪些列产生的关系,我们在分析问题的时候,往往需要画出各表的关系图,方便我们清晰的分析思路。
2.1 交叉联结 CROSS JOIN
交叉联结也叫做笛卡尔积,英文命名为CROSS JOIN。
交叉联结就是将表1中的所有M行,分别与表2中的N行进行组合,生成新的行,然后合并到一起的过程。因此交叉联结会产生M*N个记录。
如下图所示:
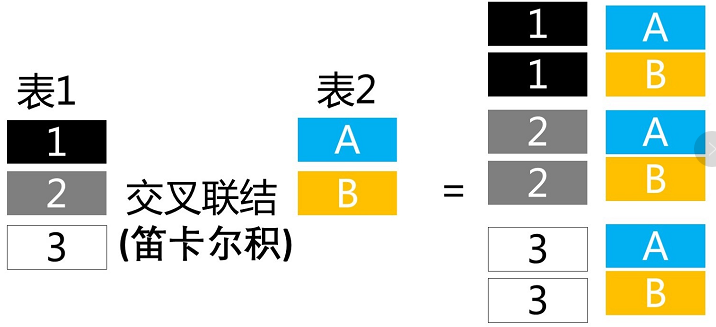
注意,由于交叉联结会产生很多记录,所以并不常用;但是交叉联结是后边所有联结的基础,需要理解。
2.2 内联结 INNER JOIN
内联结,本质上是找到两张表中对应关系的交集,取出来然后进行交叉联结。
如下代码:
SELECT a.学号,a.姓名,b.课程号 --- 最终选出几列
FROM student AS a INNER JOIN score AS b ----分别缩写,通过INNER JOIN 联结
ON a.学号 = b.学号; --- 以学号列进行联结
如下图是内联结的操作流程:
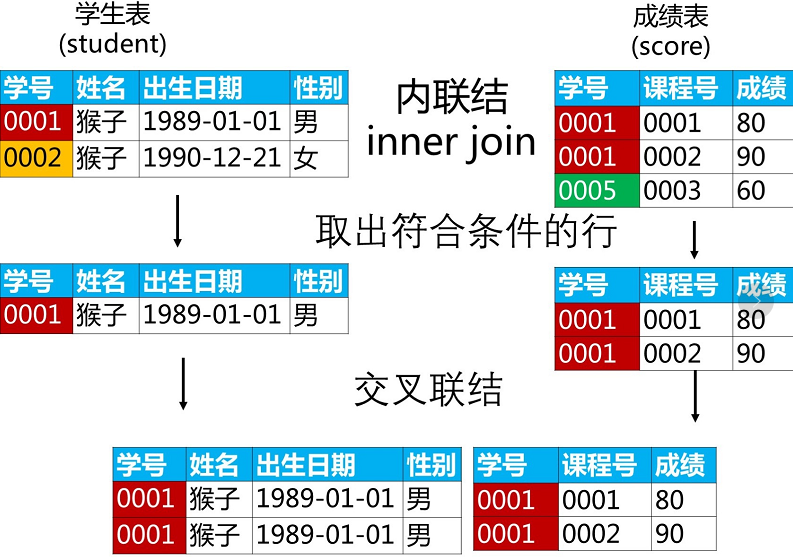
其中,并没有选取的过程,只是做了后边两两步,选取最后一步很简单,这里就不画了。
2.3 左联结 LEFT JOIN
左联结是将左边表中的数据全部保留,然后将右边表中与左表相交的数据取出,针对相交数据进行笛卡尔积合成表。
左联结看起来就是将左表数据全部保留,然后左右表相交数据进行交叉联结,没有的数据用NULL 填充,得到最终结果。
代码如下:
SELECT a.学号,a.姓名,b.课程号 --- 最终选出几列
FROM student AS a LEFT JOIN score AS b ----分别缩写,通过INNER JOIN 联结
ON a.学号 = b.学号; --- 以学号列进行联结
执行过程如下:
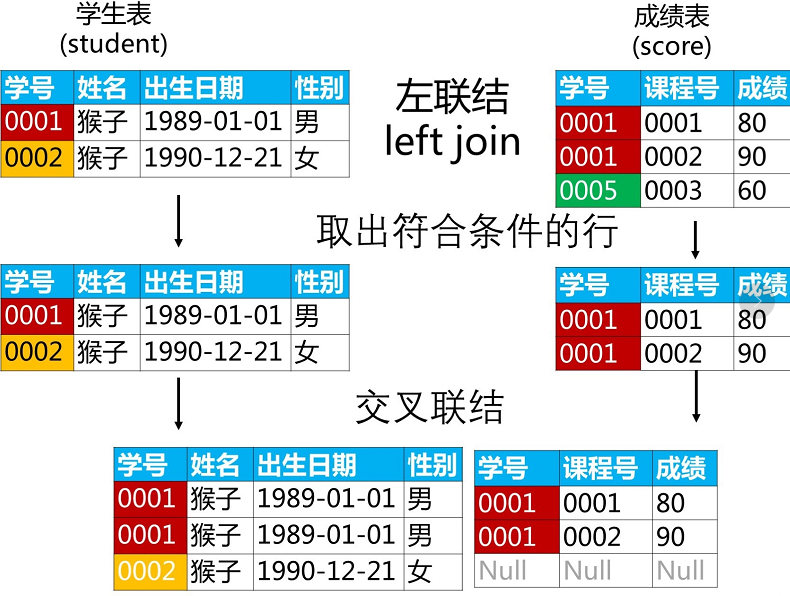
其中,同样缺少筛选列,不要介意,图只是表达了关键过程。
2.4 右联结 RIGHT JOIN
右联结和左联结没有什么区别,仅仅是右表数据全部保留,然后对交叉数据进行笛卡尔积,没有的数据用NULL 填充,合并成最终结果。
代码如下:
SELECT a.学号,a.姓名,b.课程号 --- 最终选出几列
FROM student AS a RIGHT JOIN score AS b ----分别缩写,通过INNER JOIN 联结
ON a.学号 = b.学号; --- 以学号列进行联结
执行过程如下:
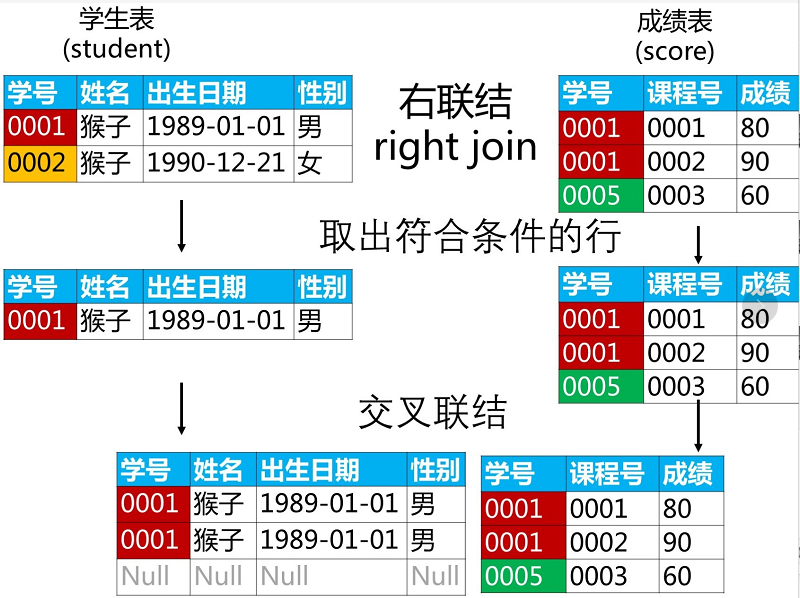
2.5 全联结 FULL JOIN
全联结保留左右表中所有数据,然后对交集数据做笛卡尔积,合成结果。
过程如图所示:
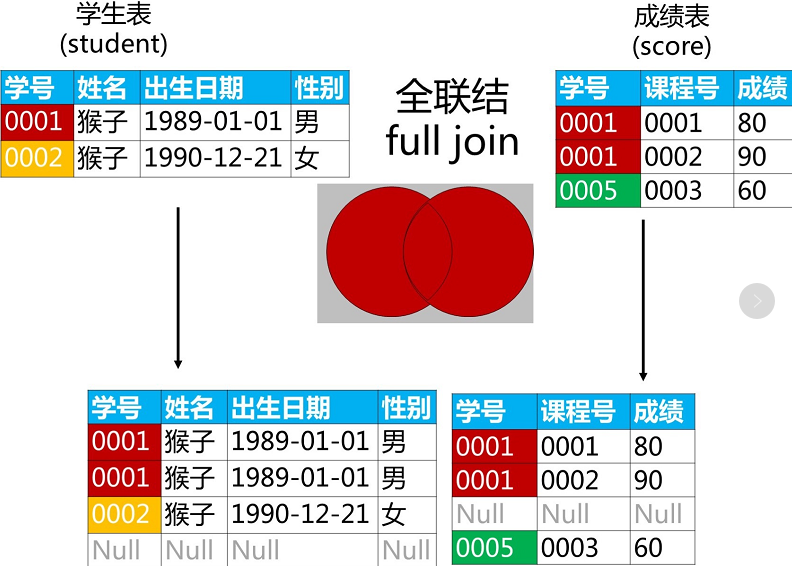
MYSQL并不支持全联结,可以通过左右联结加UNION 来实现:
参考《Mysql不支持FULL JOIN怎么办?》
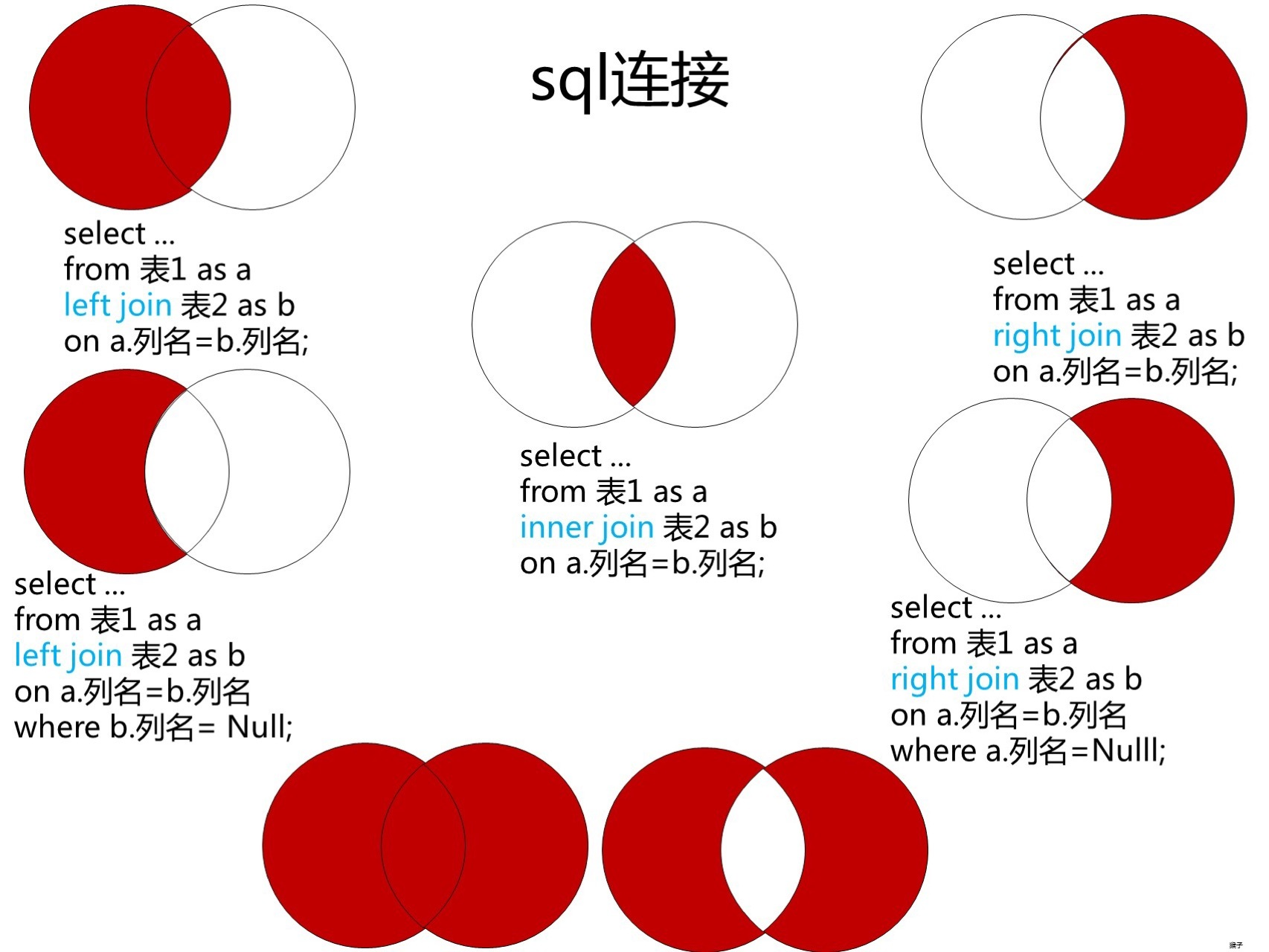
2.6 小结
如图所有联结的小结:
3. 联结的应用
3.1 案例1
问题查询所有学生的学号,姓名,选课数,总成绩?
- 翻译成大白话
每个学生,选课数目和总成绩统计分析。 - 分步骤
(1) 从学生表和成绩表做左联结,保留所有学生数据
(2) 按照学号分组(姓名可能有重复,所以按学号),求课程号计数
(3) 按照学号分组,求总成绩。 - 翻译成SQL
如下图:

代码实现如下:
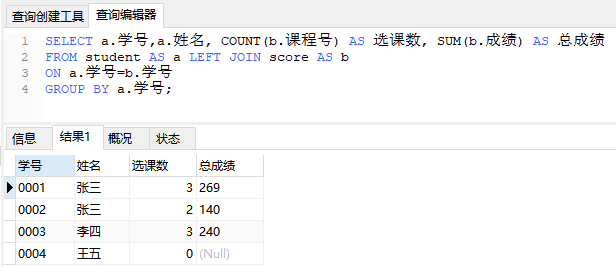
SELECT a.学号,a.姓名, COUNT(b.课程号) AS 选课数, SUM(b.成绩) AS 总成绩
FROM student AS a LEFT JOIN score AS b
ON a.学号=b.学号
GROUP BY a.学号;
查询结果如下图所示,注意指定是那个表的哪个列, a. 还是b.:
3.2 案例2
查询平均成绩大于85分的所有学生的学号,姓名,平均成绩?
- 翻译成大白话
求每个学生的平均成绩,选出大于85分的。 - 分步骤
(1) 按学号,联结学生表和成绩表
(2) 按学号分组,求平均成绩。
(3) 选出平均成绩大于85分的。 - SQL实现
代码如下:
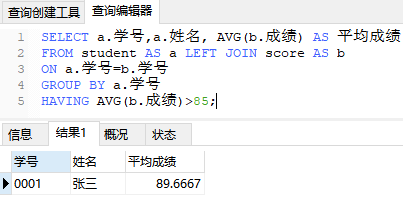
SELECT a.学号,a.姓名, AVG(b.成绩) AS 平均成绩
FROM student AS a LEFT JOIN score AS b
ON a.学号=b.学号
GROUP BY a.学号
HAVING AVG(b.成绩)>85;
查询结果如下:
3.3 案例3
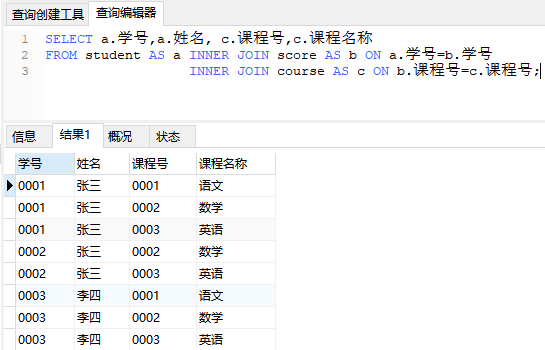
查询学生的选课情况,学号,姓名,课程号,课程名称?
显然对于该问题,2张表不够表达,需要对三张表进行联结。
如下图:

代码如下:
SELECT a.学号,a.姓名, c.课程号,c.课程名称
FROM student AS a INNER JOIN score AS b ON a.学号=b.学号
INNER JOIN course AS c ON b.课程号=c.课程号;
执行结果如下:
4. case 表达式
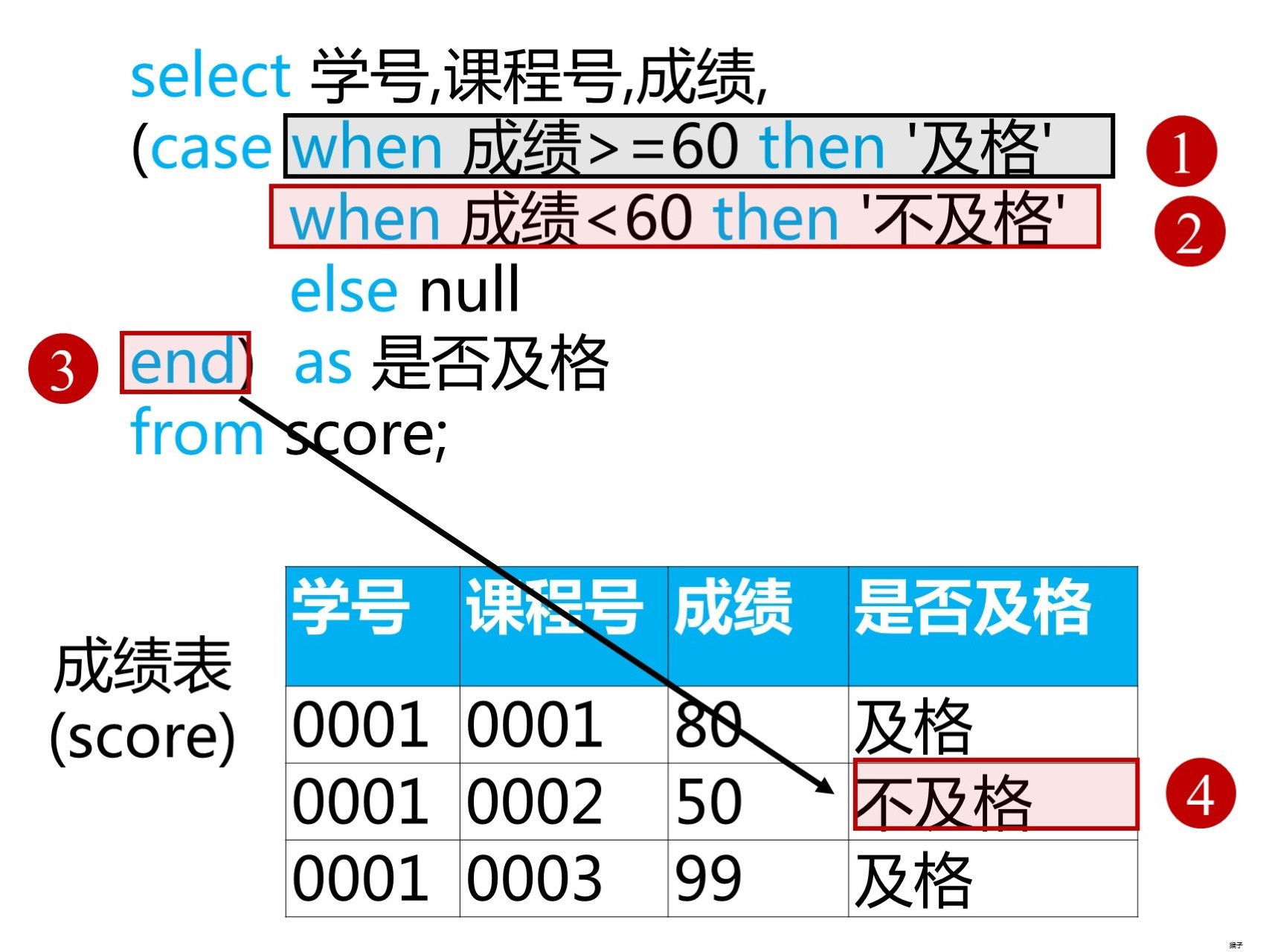
case表达式本质上判断条件,与JAVA语句中的swicth case 执行过程一样,满足则执行,不满足则继续查找,直到结束。
4.1 案例1
成绩表中,添加一列,表示及格还是不及格,CASE WHEN THEN 类似于添加一个常量列的操作。
代码如下:
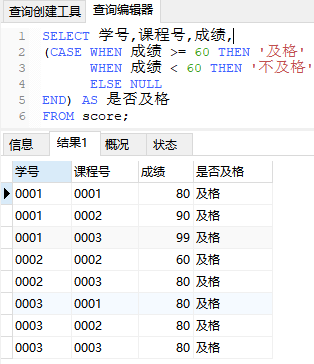
SELECT 学号,课程号,成绩,
(CASE WHEN 成绩 >= 60 THEN '及格'
WHEN 成绩 < 60 THEN '不及格'
ELSE NULL ---相当于default
END) AS 是否及格
FROM score;
执行过程如图:
查询结果如下图:
4.2 案例2
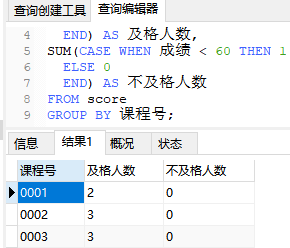
查询每门课程 及格人数和不及格人数:
代码如下:
SELECT 课程号,
SUM(CASE WHEN 成绩 >= 60 THEN 1
ELSE 0
END) AS 及格人数,
SUM(CASE WHEN 成绩 < 60 THEN 1
ELSE 0
END) AS 不及格人数
FROM score
GROUP BY 课程号;
查询结果如下图:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139481.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
