大家好,又见面了,我是你们的朋友全栈君。
目录
1、基本粒子群算法
假设在一个 D 维的目标搜索空间中,有 N 个粒子组成一个群落,其中第 i 个 粒子表示为一个 D 维的向量:
$$ X_i=(x_{i1},x_{i2}, \cdots ,x_{iD}), \quad i=1,2, \cdots ,N \quad \text {(1)} $$
第 i 个粒子的“飞行”速度也是一个 D 维的向量,记为:
$$ V_i=(v_{i1},v_{i2}, \cdots ,v_{iD}), \quad i=1,2, \cdots ,N \quad \text {(2)} $$
第 i 个粒子迄今为止搜索到的最优位置称为个体极值,记为:
$$ P_{best}=(p_{i1},p_{i2}, \cdots ,p_{iD}), \quad i=1,2, \cdots ,N \quad \text {(3)} $$
整个粒子群迄今为止搜索到的最优位置为全局极值,记为:
$$ g_{best} = (g_1, g_2, \cdots ,g_D) \quad \text {(4)} $$
在找到这两个最优值时,粒子根据如下的式(5)和式(6)来更新自己的速度和位置:
$$ v_{ij}(t+1) = v_{ij}(t) + c_1r_1(t)[p_{ij}(t) – x_{ij}(t)] + c_2r_2(t)[p_{gj}(t) – x_{ij}(t)] \quad \text {(5)} $$
$$ x_{ij}(t+1) = x_{ij}(t) + v_{ij}(t+1) \quad \text {(6)} $$
其中:\(c_1\)和\(c_2\)为学习因子,也称加速常数;\(r_1\)和\(r_2\)为[0, 1]范围内的均匀随机数,增加了粒子飞行的随机性;\(v_{ij}\)是粒子的速度,\(v_{ij} \in [-v_{max}, v_{max}], v_{max}\)是常数,由用户设定来限制粒子的速度。
式(5)右边由三部分组成:第一部分为“惯性”或“动量”部分,反映了粒子的运动“习惯”,代表粒子有维持自己先前速度的趋势;第二部分为“认知”部分,反映了粒子对自身历史经验的记忆或回忆,代表粒子有向自身历史最佳位置逼近的趋势;第三部分为“社会”部分,反映了粒子间协同合作与知识共享的 群体历史经验,代表粒子有向群体或邻域历史最佳位置逼近的趋势。
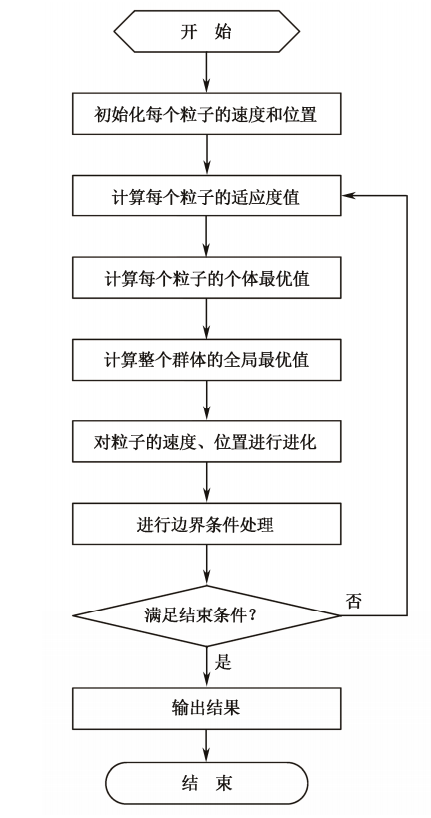
2、基本粒子群算法流程
粒子群算法基于“种群”和“进化”的概念,通过个体间的协作与竞争,实现复杂空间最优解的搜索,其流程如下:
(1)初始化粒子群,包括群体规模 \(N\),每个粒子的位置 \(x_i\) 和速度 \(v_i\)。
(2)计算每个粒子的适应度值 \(fit[i]\)。
(3)对每个粒子,用它的适应度值 \(fit[i]\) 和个体极值 \(p_{best}(i)\) 比较。如果 \(fit[i] > p_{best}(i)\),则用 \(fit[i]\)替换掉 \(p_{best}(i)\)。
(4)对每个粒子,用它的适应度值 \(fit[i]\) 和全局极值 \(g_{best}\) 比较。如果 \(fit[i] > g_{best}\) 则用 \(fit[i]\)替换掉 \(g_{best}\)。
(5)迭代更新粒子的速度 \(v_i\) 和位置 \(x_i\)。
(6)进行边界条件处理。
(7)判断算法终止条件是否满足:若是,则结束算法并输出优化结果;否则返回步骤(2)。
基本粒子群算法的算法流程图如下图所示:

3、关键参数说明
在粒子群优化算法中,控制参数的选择能够影响算法的性能和效率;如何选择合适的控制参数使算法性能最佳,是一个复杂的优化问题。在实际的优化问题中,通常根据使用者的经验来选取控制参数。粒子群算法的控制参数主要包括:粒子种群规模 \(N\),惯性权重 \(w\),加速常数 \(c_1\) 和 \(c_2\),最大速度 \(v_{max}\),停止准则,邻域结构的设定,边界条件处理策略等。
3.1 粒子种群规模 \(N\)
粒子种群大小的选择视具体问题而定,但是一般设置粒子数为 20~50。对于大部分的问题 10 个粒子,已经可以取得很好的结果;不过对于比较难的问题或者特定类型的问题,粒子的数量可以取到 100 或 200。另外,粒子数目越大,算法搜索的空间范围就越大,也就更容易发现全局最优解;当然,算法运行的时间也越长。
3.2 惯性权重 \(w\)
惯性权重 \(w\) 是标准粒子群算法中非常重要的控制参数,可以用来控制算法的开发和探索能力。惯性权重的大小表示了对粒子当前速度继承的多少。当惯性权重值较大时,全局寻优能力较强,局部寻优能力较弱;当惯性权重值较小时,全局寻优能力较弱,局部寻优能力较强。惯性权重的选择通常有固定权重和时变权重。固定权重就是选择常数作为惯性权重值,在进化过程中其值保持不变,一般取值为[0.8,1.2];时变权重则是设定某一变化区间,在进化过程中按照某种方式逐步减小惯性权重。时变权重的选择包括变化范围和递减率。固定的惯性权重可以使粒子保持相同的探索和开发能力,而时变权重可以使粒子在进化的不同阶段拥有不同的探索和开发能力。
3.3 加速常数 \(c_1\) 和 \(c_2\)
加速常数 \(c_1\) 和 \(c_2\) 分别调节向 \(p_{best}\) 和 \(g_{best}\) 方向飞行的最大步长,它们分别决定粒子个体经验和群体经验对粒子运行轨迹的影响,反映粒子群之间的信息交流。如果 \(c_1 = c_2 = 0\),则粒子将以当前的飞行速度飞到边界。此时,粒子仅能搜索有限的区域,所以难以找到最优解。如果 \(c_1 = 0\),则为“社会”模型,粒子缺乏认知能力,而只有群体经验,它的收敛速度较快,但容易陷入局部最优;如果 \(c_2 = 0\),则为“认知”模型,没有社会的共享信息,个体之间没有信息的交互,所以找到最优解的概率较小。一个规模为 \(D\) 的群体等价于运行了 \(N\) 个各行其是的粒子,因此一般设置 \(c_1 = c_2\)。这样,个体经验和群体经验就有了同样重要的影响力,使得最后的最优解更精确。
3.4 最大速度 \(v_{max}\)
粒子的速度在空间中的每一维上都有一个最大速度限制值 \(v_{dmax}\),用来对粒子的速度进行钳制,使速度控制在范围\([-v_{dmax},+v_{dmax}]\) 内,这决定问题空间搜索的力度,该值一般由用户自己设定。\(v_{max}\) 是一个非常重要的参数,如果该值太大,则粒子们也许会飞过优秀区域;而如果该值太小,则粒子们可能无法对局部最优区域以外的区域进行充分的探测。它们可能会陷入局部最优,而无法移动足够远的距离而跳出局部最优,达到空间中更佳的位置。研究者指出,设定 \(v_{max}\) 和调整惯性权重的作用是等效的,所以 \(v_{max}\) 一般用于对种群的初始化进行设定,即将 \(v_{max}\) 设定为每维变量的变化范围,而不再对最大速度进行细致的选择和调节。
3.5 停止准则
最大迭代次数、计算精度或最优解的最大停滞步数\(\Delta t\)(或可以接受的满意解)通常认为是停止准则,即算法的终止条件。根据具体的优化问题,停止准则的设定需同时兼顾算法的求解时间、优化质量和搜索效率等多方面性能。
3.6 邻域结构的设定
全局版本的粒子群算法将整个群体作为粒子的邻域,具有收敛速度快的优点,但有时算法会陷入局部最优。局部版本的粒子群算法将位置相近的个体作为粒子的邻域,收敛速度较慢,不易陷入局部最优值。实际应用中,可先采用全局粒子群算法寻找最优解的方向,即得到大致的结果,然后采用局部粒子群算法在最优点附近进行精细搜索。
3.7 边界条件处理策略
当某一维或若干维的位置或速度超过设定值时,采用边界条件处理策略可将粒子的位置限制在可行搜索空间内,这样能避免种群的膨胀与发散,也能避免粒子大范围地盲目搜索,从而提高了搜索效率。具体的方法有很多种,比如通过设置最大位置限制 \(x_{max}\) 和最大速度限制 \(v_{max}\),当超过最大位置或最大速度时,在范围内随机产生一个数值代替,或者将其设置为最大值,即边界吸收。
4、MATLAB仿真实例
4.1 粒子群算法求解n元函数极值
例1 计算函数 \(f(x)=\sum_{i=1}^n {
{x_i}^2} \quad (-20 \leq x_i \leq 20)\) 的最小值,其中个体 \(x\) 的维数 \(n = 10\)。这是一个简单的平方和函数,只有一个极小点 \(x = (0,0,…,0)\),理论最小值 \(f (0,0,…,0) = 0\)。
解:仿真过程如下:
(1)初始化群体粒子个数为 \(N = 100\),粒子维数为 \(D = 10\),最大迭代次数为 \(T = 200\),学习因子 \(c_1 = c_2 = 1.5\),惯性权重为 \(w = 0.8\),位置最大值为 \(X_{max} = 20\),位置最小值为 \(X_{min} = 20\),速度最大值为 \(V_{max} = 10\),速度最小值为 \(V_{min} = -10\)。
(2)初始化种群粒子位置 \(x\) 和速度 \(v\),粒子个体最优位置 \(p\) 和最优值 \(p_{best}\),以及粒子群全局最优位置 \(g\) 和最优值 \(g_{best}\)。
(3)更新位置 \(x\) 和速度值 \(v\),并进行边界条件处理,判断是否替换粒子个体最优位置 \(p\) 和最优值 \(p_{best}\)、粒子群全局最优位置 \(g\) 和最优值 \(g_{best}\)。
(4)判断是否满足终止条件:若满足,则结束搜索过程,输出优化值;若不满足,则继续进行迭代优化。
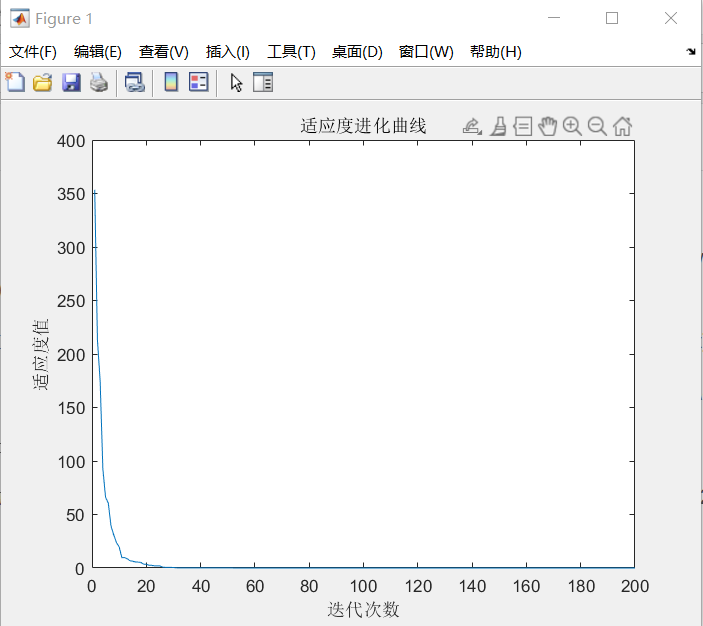
优化结束后,其适应度进化曲线如下图所示,优化后的结果为 \(x = [0.6325 \quad 0.1572 \quad 0.4814 \quad 0.1091 \quad 0.3154 \quad 0.2236 \quad 0.3991 \quad 0.5907 \quad 0.0221 \quad 0.1172]×10^{-4} \),函数 \(f(x)\) 的最小值为 \(1.34×10^{-8}\)。
粒子群算法求解n元函数极值问题MATLAB源程序
%%%%%%%%%%%%%%粒子群算法求函数极值%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%初始化%%%%%%%%%%%%%%%%%%%%%
clear all; %清除所有变量
close all; %清图
clc; %清屏
N = 100; %群体粒子个数
D = 10; %粒子维数
T = 200; %最大迭代次数
c1 = 1.5; %学习因子 1
c2 = 1.5; %学习因子 2
w = 0.8; %惯性权重
Xmax = 20; %位置最大值
Xmin = -20; %位置最小值
Vmax = 10; %速度最大值
Vmin = -10; %速度最小值
%%%%%%%%%%%初始化种群个体(限定位置和速度)%%%%%%%%%%%%%
x = rand(N,D) * (Xmax-Xmin)+Xmin;
v = rand(N,D) * (Vmax-Vmin)+Vmin;
%%%%%%%%%%%初始化个体最优位置和最优值%%%%%%%%%%%%%%%
p = x;
pbest = ones(N,1);
for i = 1:N
pbest(i) = func1(x(i,:));
end
%%%%%%%%%%%%%%初始化全局最优位置和最优值%%%%%%%%%%%%
g = ones(1,D);
gbest = inf;
for i = 1:N
if(pbest(i) < gbest)
g = p(i,:);
gbest = pbest(i);
end
end
gb = ones(1,T);
%%%%%%%%按照公式依次迭代直到满足精度或者迭代次数%%%%%%%%%
for i = 1:T
for j = 1:N
%%%%%%%%%%更新个体最优位置和最优值%%%%%%%%%%%%
if (func1(x(j,:)) < pbest(j))
p(j,:) = x(j,:);
pbest(j) = func1(x(j,:));
end
%%%%%%%%%%%更新全局最优位置和最优值%%%%%%%%%%%
if(pbest(j) < gbest)
g = p(j,:);
gbest = pbest(j);
end
%%%%%%%%%%%%%更新位置和速度值%%%%%%%%%%%%%
v(j,:) = w*v(j,:)+c1*rand*(p(j,:)-x(j,:))...
+c2*rand*(g-x(j,:));
x(j,:) = x(j,:)+v(j,:);
%%%%%%%%%%%%%%边界条件处理%%%%%%%%%%%%%%%
for ii = 1:D
if (v(j,ii) > Vmax) | (v(j,ii) < Vmin)
v(j,ii) = rand * (Vmax-Vmin)+Vmin;
end
if (x(j,ii) > Xmax) | (x(j,ii) < Xmin)
x(j,ii) = rand * (Xmax-Xmin)+Xmin;
end
end
end
%%%%%%%%%%%%%%记录历代全局最优值%%%%%%%%%%%%%
gb(i) = gbest;
end
g; %最优个体
gb(end); %最优值
figure
plot(gb)
xlabel('迭代次数');
ylabel('适应度值');
title('适应度进化曲线')
%%%%%%%%%%%%%%%%%%适应度函数%%%%%%%%%%%%%%%%
function result = func1(x)
summ = sum(x.^2);
result = summ;
end4.2 粒子群算法求解二元函数的极值
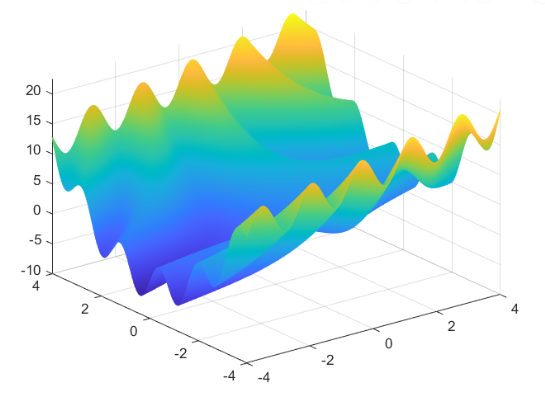
例2 求函数 \(f(x,y) = 3cos(xy) + x + y^2\) 的最小值,其中 \(x\) 的取值范围为\([-4,4]\),\(y\) 的取值范围为\([-4,4]\)。这是一个有多个局部极值的函数,其函数值图形如下图所示。
解:仿真过程如下:
(1)初始化群体粒子个数为 \(N = 100\),粒子维数为 \(D = 2\),最大迭代次数为 \(T = 200\),学习因子 \(c_1 = c_2 = 1.5\),惯性权重最大值为 \(W_{max} = 0.8\),惯性权重最小值为 \(W_{min} = 0.4\),位置最大值为 \(X_{max} = 4\),位置最小值为 \(X_{min} = -4\),速度最大值为 \(V_{max} = 1\),速度最大值为 \(V_{min} = -1\)。
(2)初始化种群粒子位置 \(x\) 和速度 \(v\),粒子个体最优位置 \(p\) 和最优值 \(p_{best}\),粒子群全局最优位置 \(g\) 和最优值 \(g_{best}\)。
(3)计算动态惯性权重值 \(w\),更新位置 \(x\) 和速度值 \(v\),并进行边界条件处理,判断是否替换粒子个体最优位置 \(p\) 和最优值 \(p_{best}\),以及粒子群全局最优位置 \(g\) 和最优值 \(g_{best}\)。
(4)判断是否满足终止条件:若满足,则结束搜索过程,输出优化值;若不满足,则继续进行迭代优化。
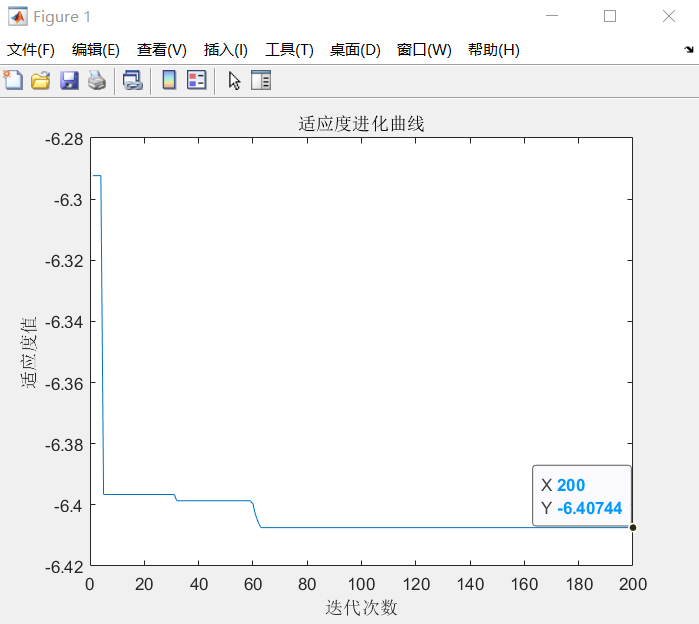
优化结束后,其适应度进化曲线如下图所示。优化后的结果为:在 \(x=4.4395,y = 5\) 时,函数 \(f(x)\) 取得最小值\(-6.407\)。
粒子群算法求解二元函数极值问题MATLAB源程序
%%%%%%%%%%%%%%粒子群算法求函数极值%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%初始化%%%%%%%%%%%%%%%%%%%
clear all; %清除所有变量
close all; %清图
clc; %清屏
N = 100; %群体粒子个数
D = 2; %粒子维数
T = 200; %最大迭代次数
c1 = 1.5; %学习因子 1
c2 = 1.5; %学习因子 2
Wmax = 0.8; %惯性权重最大值
Wmin = 0.4; %惯性权重最小值
Xmax = 4; %位置最大值
Xmin = -4; %位置最小值
Vmax = 1; %速度最大值
Vmin = -1; %速度最小值
%%%%%%%%%%%%初始化种群个体(限定位置和速度)%%%%%%%%%%%%
x = rand(N,D) * (Xmax-Xmin)+Xmin;
v = rand(N,D) * (Vmax-Vmin)+Vmin;
%%%%%%%%%%%%%初始化个体最优位置和最优值%%%%%%%%%%%%%
p = x;
pbest = ones(N,1);
for i = 1:N
pbest(i) = func2(x(i,:));
end
%%%%%%%%%%%%%初始化全局最优位置和最优值%%%%%%%%%%%%
g = ones(1,D);
gbest = inf;
for i = 1:N
if(pbest(i) < gbest)
g = p(i,:);
gbest = pbest(i);
end
end
gb = ones(1,T);
%%%%%%%%%按照公式依次迭代直到满足精度或者迭代次数%%%%%%%%
for i = 1:T
for j = 1:N
%%%%%%%%%更新个体最优位置和最优值%%%%%%%%%%%%%
if (func2(x(j,:)) < pbest(j))
p(j,:) = x(j,:);
pbest(j) = func2(x(j,:));
end
%%%%%%%%%%更新全局最优位置和最优值%%%%%%%%%%%%
if(pbest(j) < gbest)
g = p(j,:);
gbest = pbest(j);
end
%%%%%%%%%%%计算动态惯性权重值%%%%%%%%%%%%%%%
w = Wmax-(Wmax-Wmin)*i/T;
%%%%%%%%%%%%更新位置和速度值%%%%%%%%%%%%%%%
v(j,:) = w*v(j,:)+c1*rand*(p(j,:)-x(j,:))...
+c2*rand*(g-x(j,:));
x(j,:) = x(j,:)+v(j,:);
%%%%%%%%%%%%%%边界条件处理%%%%%%%%%%%%%%%
for ii = 1:D
if (v(j,ii) > Vmax) | (v(j,ii) < Vmin)
v(j,ii) = rand * (Vmax-Vmin)+Vmin;
end
if (x(j,ii) > Xmax) | (x(j,ii) < Xmin)
x(j,ii) = rand * (Xmax-Xmin)+Xmin;
end
end
end
%%%%%%%%%%%%%%记录历代全局最优值%%%%%%%%%%%%%%
gb(i) = gbest;
end
g; %最优个体
gb(end); %最优值
figure
plot(gb)
xlabel('迭代次数');
ylabel('适应度值');
title('适应度进化曲线')
%%%%%%%%%%%%%%%%%%适应度函数%%%%%%%%%%%%%%%%%
function value = func2(x)
value = 3*cos(x(1)*x(2))+x(1)+x(2)^2;
end5、粒子群算法的特点
粒子群算法本质是一种随机搜索算法,它是一种新兴的智能优化技术。该算法能以较大概率收敛于全局最优解。实践证明,它适合在动态、多目标优化环境中寻优,与传统优化算法相比,具有较快的计算速度和更好的全局搜索能力。
(1)粒子群算法是基于群智能理论的优化算法,通过群体中粒子间的合作与竞争产生的群体智能指导优化搜索。与其他算法相比,粒子群算法是一种高效的并行搜索算法。
(2)粒子群算法与遗传算法都是随机初始化种群,使用适应值来评价个体的优劣程度和进行一定的随机搜索。但粒子群算法根据自己的速度来决定搜索,没有遗传算法的交叉与变异。与进化算法相比,粒子群算法保留了基于种群的全局搜索策略,但是其采用的速度位移模型操作简单,避免了复杂的遗传操作。
(3)由于每个粒子在算法结束时仍保持其个体极值,即粒子群算法除了可以找到问题的最优解外,还会得到若干较好的次优解,因此将粒子群算法用于调度和决策问题可以给出多种有意义的方案。
(4)粒子群算法特有的记忆使其可以动态地跟踪当前搜索情况并调整其搜索策略。另外,粒子群算法对种群的大小不敏感,即使种群数目下降时,性能下降也不是很大。
6、其他种类的粒子群算法
6.1 标准粒子群算法
引入研究粒子群算法经常用到的两个概念:一是“探索”,指粒子在一定程度上离开原先的搜索轨迹,向新的方向进行搜索,体现了一种向未知区域开拓的能力,类似于全局搜索;二是“开发”,指粒子在一定程度上继续在原先的搜索轨迹上进行更细一步的搜索,主要指对探索过程中所搜索到的区域进行更进一步的搜索。探索是偏离原来的寻优轨迹去寻找一个更好的解,探索能力是一个算法的全局搜索能力。开发是利用一个好的解,继续原来的寻优轨迹去搜索更好的解,它是算法的局部搜索能力。如何确定局部搜索能力和全局搜索能力的比例,对一个问题的求解过程很重要。1998 年,Y. H. Shi 提出了带有惯性权重的改进粒子群算法,由于该算法能够保证较好的收敛效果,所以被默认为标准粒子群算法。其进化过程为:
$$ v_{ij}(t+1) = w \cdot v_{ij}(t) + c_1r_1(t)[p_{ij}(t) – x_{ij}(t)] + c_2r_2(t)[p_{gj}(t) – x_{ij}(t)] \quad \text {(7)} $$
$$ x_{ij}(t+1) = x_{ij}(t) + v_{ij}(t+1) \quad \text {(8)} $$
在式(7)中,第一部分表示粒子先前的速度,用于保证算法的全局收敛性能;第二部分、第三部分则使算法具有局部收敛能力。可以看出,式(7)中惯性权重 w 表示在多大程度上保留原来的速度:w 较大,则全局收敛能力较强,局部收敛能力较弱;w 较小,则局部收敛能力较强,全局收敛能力较弱。
当 w = 1 时,式(7)与式(5)完全一样,表明带惯性权重的粒子群算法是基本粒子群算法的扩展。实验结果表明:w 在 0.8~1.2 之间时,粒子群算法有更快的收敛速度;而当 w > 1.2 时,算法则容易陷入局部极值。
另外,在搜索过程中可以对 w 进行动态调整:在算法开始时,可给 w 赋予较大正值,随着搜索的进行,可以线性地使 w 逐渐减小,这样可以保证在算法开始时,各粒子能够以较大的速度步长在全局范围内探测到较好的区域;而在搜索后期,较小的 w 值则保证粒子能够在极值点周围做精细的搜索,从而使算法有较大的概率向全局最优解位置收敛。对 w 进行调整,可以权衡全局搜索和局部搜索能力。目前,采用较多的动态惯性权重值是 Shi 提出的线性递减权值策略,其表达式如下:
$$ w = w_{max} – \frac {(w_{max} – w_{min}) \cdot t} {T_{max}} \quad \text {(9)} $$
其中,\(T_{max}\) 表示最大进化代数;\(w_{min}\) 表示最小惯性权重;\(w_{max}\) 表示最大惯性权重;\(t\) 表示当前迭代次数。在大多数的应用中 \(w_{max} = 0.9,w_{min} = 0.4\)。
6.2 压缩因子粒子群算法
Clerc 提出利用约束因子来控制系统行为的最终收敛,该方法可以有效搜索不同的区域,并且能得到高质量的解。压缩因子法的速度更新公式为:
$$ v_{ij}(t+1) = \lambda \cdot v_{ij}(t) + c_1r_1(t)[p_{ij}(t) – x_{ij}(t)] + c_2r_2(t)[p_{gj}(t) – x_{ij}(t)] \quad \text {(10)} $$
$$ \lambda = \frac {2} {\mid 2 – \varphi – \sqrt{(\varphi ^2 – 4 \varphi )} \mid} \quad \text {(11)} $$
$$ \varphi = c_1 + c_2 \quad \text {(12)} $$
其中,\(\lambda\) 为压缩因子。实验结果表明,与使用惯性权重的粒子群优化算法相比,使用具有约束因子的粒子群算法具有更快的收敛速度。
6.3 离散粒子群算法
基本的粒子群算法是在连续域中搜索函数极值的有力工具。继基本粒子群算法之后,Kennedy 和 Eberhart 又提出了一种离散二进制版的粒子群算法。在此离散粒子群方法中,将离散问题空间映射到连续粒子运动空间,并适当修改粒子群算法来求解,在计算上仍保留经典粒子群算法速度-位置更新运算规则。粒子在状态空间的取值和变化只限于 0 和 1 两个值,而速度的每一维 \(v_{ij}\) 代表位置每一位 \(x_{ij}\) 取值为 1 的可能性。因此,在连续粒子群中的 \(v_{ij}\) 更新公式依然保持不变,但是 \(p_{best}\) 和 \(g_{best}\) 只在 \([0,1]\) 内取值。其位置更新等式表示如下:
$$ s(v_{ij}) = \frac {1} {1 + e^{-v_{ij}}} \quad \text {(13)} $$
$$ x_{ij} = \begin{cases} 1, & \text {r < s(v_{ij})} \\ 0, & \text{其他} \end{cases} \quad \text {(14)} $$
式中,\(r\) 是从 \(U(0,1)\)分布中产生的随机数。
往期相关博客:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139462.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
