大家好,又见面了,我是你们的朋友全栈君。
前言
1.本文重点是了解OHEM算法以及它与hard negative mining的异同点,尽量用较少篇幅表达清楚论文算法,其他一些不影响理解算法的东西不做赘述
2.博客主要是学习记录,为了更好理解和方便以后查看,当然如果能为别人提供帮助就更好了,如果有不对的地方请指正(论文中的链接是我经过大量搜索,个人认为讲解最清楚的参考)
Hard Negatie Mining与OHEM(Online Hard Example Mining)
1.相同点:
二者都是难例挖掘,解决样本不平衡问题(简单样本多,在目标检测中也可以说是负样本多,因为基本大部分容易分类的样本都是负样本)
2.不同点:
1)从名字就可以看出前者只注重挖掘难负例,也就是标签是负样本但网络认为它是正样本(与gt的iou大,但是没到阈值那种难以区分的负样本);而后者是挖掘所有难分类样本,并且是online(R-CNN采用了错题集的办法进行挖掘,Fast R-CNN使用的是IoU阈值+随机采样的方法进行Hard Negative Mining,也就是都必须先结束一轮训练(参考);而OHEM是先根据loss大小选择留下的roi,然后再根据这些roi反向传播更新参数完成一轮训练)
2)前者可以说是一种指导方向,因为在不同的检测算法中(比如R-CNN、Fast R-CNN以及带anchor的one-stage算法SSD等)Hard Negatie Mining具体操作是不同的;而后是一个算法
OHEM
作者将OHEM用于Fast R-CNN进行试验
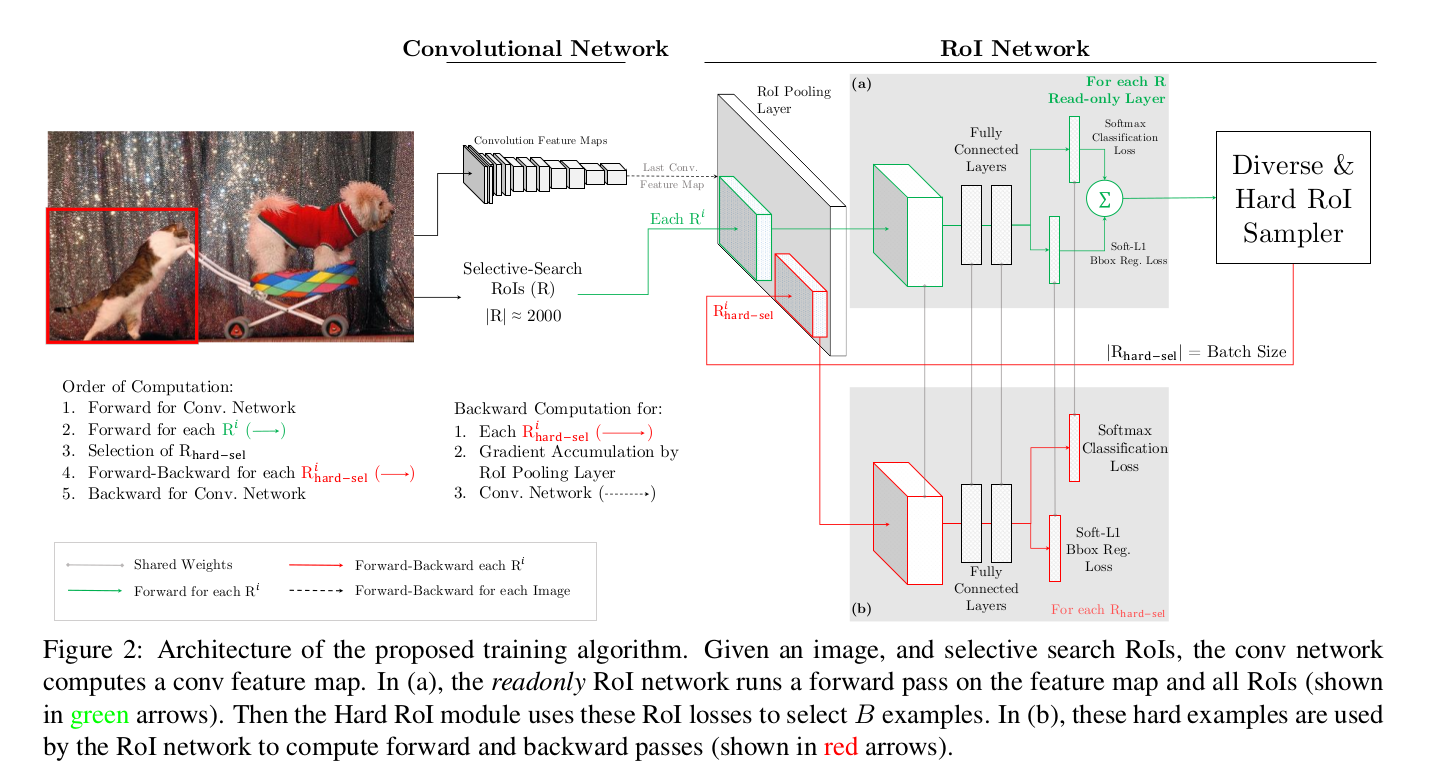

如图,框架只是比Fast R-CNN多出下面一块(b),(a)和(b)是参数相同的网络,(a)只进行前向传播,(b)可以进行反向传播,具体过程为:
1.每个roi通过(a)进行前向传播计算损失,然后根据损失大小进行排序,再通过nms筛选留下损失大的一些roi
2.再将留下的损失大的roi经过(b)进行反向传播以更新参数
3.同步(a)和(b)的参数
注:
1)分为(a)和(b)两个网络就是空间换时间,(b)不需要对所有的roi都进行反向传播,只对留下的损失大的反向传播,实验表明内存差不多而速度快很多
2)这里的nms是根据loss进行的(之前见过的都是根据置信度),阈值设为0.7,因为loss相近表明roi位置相近,没必要留下位置差不多的,所以进行nms
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139421.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
