大家好,又见面了,我是你们的朋友全栈君。
1. 概述
论文名称:Training Region-based Object Detectors with Online Hard Example Mining
代码地址:OHEM
OHEM(online hard example miniing)算法的核心思想是: 根据输入样本的损失进行筛选,筛选出hard example,表示对分类和检测影响较大的样本,然后将筛选得到的这些样本应用在随机梯度下降中训练。
在实际操作中是将原来的一个ROI Network扩充为两个ROI Network,这两个ROI Network共享参数。其中前面一个ROI Network只有前向操作,主要用于计算损失;后面一个ROI Network包括前向和后向操作,以hard example作为输入,计算损失并回传梯度。
作者将该算法应用在Fast RCNN中,网络结构还是采用VGG16和VGG_CNN_M_1024,数据集主要采用VOC2007,VOC2012和COCO数据集。 算法优点:
1)对于数据的类别不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强;
2)随着数据集的增大,算法的提升更加明显(作者是通过在COCO数据集上做实验和VOC数据集做对比,因为前者的数据集更大,而且提升更明显,所以有这个结论);
算法的测试结果:在pascal VOC2007上的mAP为78.9%,在pascal VOC2012上的mAP为76.3%。注意,这些结果的得到包含了一些小tricks,比如multi-scale test(测试时候采用多尺度输入),bounding box的不断迭代回归。
需要注意的是,这个OHEM适合于batch size(images)较少,但每张image的examples很多的情况。
论文提及到可以用一种简单的方式来完成hard mining:在原有的Fast-RCNN里的loss layer里面对所有的props计算其loss,根据loss对其进行排序,(这里可以选用NMS),选出 K K K个hard examples(即props)。反向传播时,只对这 K K K个props的梯度/残差回传,而其他的props的梯度/残差设为 0 0 0即可。由于这样做,容易导致显存显著增加,迭代时间增加,这对显卡容量少的童鞋来说,简直是噩梦。
前面说到OHEM是在线的,为什么说是online?
论文的任务是region-based object detection,其examples是对props来说的,即使每次迭代的图像数为1,它的props还是会很多,即使hard mining后。
为什么要hard mining:
1)减少fg和bg的ratio,而且不需要人为设计这个ratio;
2)加速收敛,减少显存需要这些硬件的条件依赖;
3)hard mining已经证实了是一种booststrapping的方式, 尤其当数据集较大而且较难的时候;
4)eliminates several heuristics and hyperparameters in common use by automatically selecting hard examples, thus simplifying training。放宽了定义negative example的bg_lo threshold,即从[0.1, 0.5)变化到[0, 0.5)。取消了正负样本在mini-batch里的ratio(原Fast-RCNN的ratio为1:3)。
2. OHEM算法
如前所述,OHEM算法的核心是选择一些hard example作为训练的样本,那么什么样的样本是hard example呢?答案是:有多样性和高损失的样本。
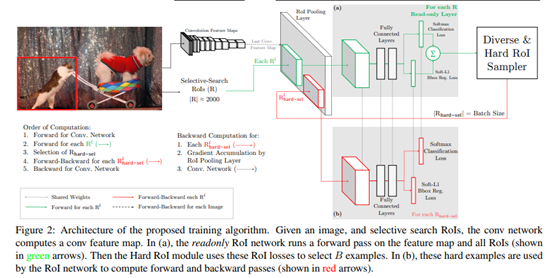

实际训练的时候,每个mini-batch包含 N N N个图像,共 ∣ R ∣ |R| ∣R∣个ROI,也就是每张图像包含 ∣ R ∣ / N |R|/N ∣R∣/N个ROI。经过hard ROI sampler筛选后得到 B B B个hard example。作者在文中采用 N = 2 , ∣ R ∣ = 4000 , B = 128 N=2,|R|=4000,B=128 N=2,∣R∣=4000,B=128。
另外关于正负样本的选择:当一个ROI和一个ground truth的IOU大于0.5,则为正样本;当一个ROI和所有ground truth的IOU的最大值小于0.5时为负样本。
3. OHEM实验
3.1 性能

从上表中可以看出加上OHEM明显提高了mAP。
3.2 总结:
总的来讲,OHEM算法通过选择hard example的方式来训练,不仅解决了正负样本类别不均衡问题,同时提高了算法准确率,算是一个不错的trick。可以联系另一篇博文:A-Fast-RCNN算法,也是类似的关于利用hard example来提高mAP,只不过那篇算法是生成hard example,而这篇算法是选择hard example。
4. OHEM在Caffe Faster R-CNN中的使用
添加的位置为生成roi-data之后,其结构见下图所示:
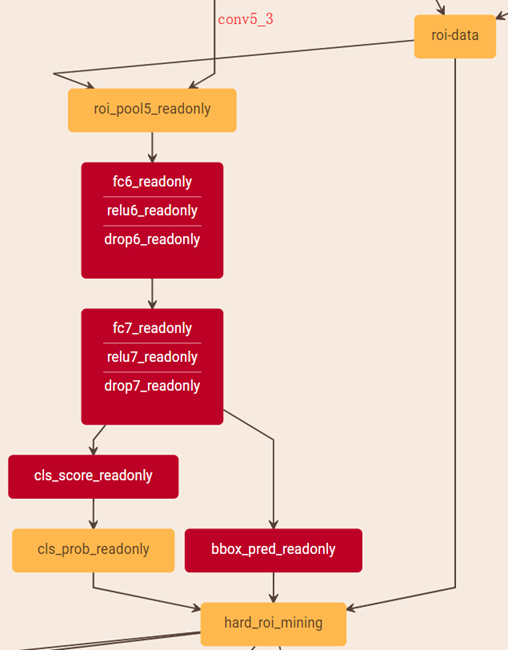
OHEM中通过只读 ROI Network来选择困难样本,其中包含一个ROI pooling层,两个常规全连接层(fc6,fc7),一个分类得分的全连接层,一个回归的全连接层,一个算分类概率的softmax层。
##########################
## Readonly RoI Network ##
######### Start ##########
layer {
name: "roi_pool5_readonly"
type: "ROIPooling"
bottom: "conv5_3"
bottom: "rois"
top: "pool5_readonly"
propagate_down: false
propagate_down: false
roi_pooling_param {
pooled_w: 7
pooled_h: 7
spatial_scale: 0.0625 # 1/16
}
}
后面就是边界框分类和边界回归的全连接层:注意这里的propagate_down参数设为false ,也就是不回传梯度。还有一点需要注意的就是这些全连接层的参数初始化项,都是有名字的其实是实现了参数共享。
layer {
name: "fc6_readonly"
type: "InnerProduct"
bottom: "pool5_readonly"
top: "fc6_readonly"
propagate_down: false
param {
name: "fc6_w"
}
param {
name: "fc6_b"
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6_readonly"
type: "ReLU"
bottom: "fc6_readonly"
top: "fc6_readonly"
propagate_down: false
}
layer {
name: "drop6_readonly"
type: "Dropout"
bottom: "fc6_readonly"
top: "fc6_readonly"
propagate_down: false
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7_readonly"
type: "InnerProduct"
bottom: "fc6_readonly"
top: "fc7_readonly"
propagate_down: false
param {
name: "fc7_w"
}
param {
name: "fc7_b"
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7_readonly"
type: "ReLU"
bottom: "fc7_readonly"
top: "fc7_readonly"
propagate_down: false
}
layer {
name: "drop7_readonly"
type: "Dropout"
bottom: "fc7_readonly"
top: "fc7_readonly"
propagate_down: false
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "cls_score_readonly"
type: "InnerProduct"
bottom: "fc7_readonly"
top: "cls_score_readonly"
propagate_down: false
param {
name: "cls_score_w"
}
param {
name: "cls_score_b"
}
inner_product_param {
num_output: 6 #6
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "bbox_pred_readonly"
type: "InnerProduct"
bottom: "fc7_readonly"
top: "bbox_pred_readonly"
propagate_down: false
param {
name: "bbox_pred_w"
}
param {
name: "bbox_pred_b"
}
inner_product_param {
num_output: 24 #24
weight_filler {
type: "gaussian"
std: 0.001
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "cls_prob_readonly"
type: "Softmax"
bottom: "cls_score_readonly"
top: "cls_prob_readonly"
propagate_down: false
}
之后就将分类和边界框的结果送入到hard ROI mining层,其输入包括:分类概率的输出,回归的输出,最开始数据层的输出(rois,labels,targets和两个weights)
layer {
name: "hard_roi_mining"
type: "Python"
bottom: "cls_prob_readonly"
bottom: "bbox_pred_readonly"
bottom: "rois"
bottom: "labels"
bottom: "bbox_targets"
bottom: "bbox_inside_weights"
bottom: "bbox_outside_weights"
top: "rois_hard"
top: "labels_hard"
top: "bbox_targets_hard"
top: "bbox_inside_weights_hard"
top: "bbox_outside_weights_hard"
propagate_down: false
propagate_down: false
propagate_down: false
propagate_down: false
propagate_down: false
propagate_down: false
propagate_down: false
python_param {
module: "roi_data_layer.layer"
layer: "OHEMDataLayer"
param_str: "'num_classes': 6" #6
}
}
########## End ###########
## Readonly RoI Network ##
##########################
经过OHEM之后接的是另一个ROI Network,注意这里的ROI pooling层和前面那个只读ROI Network的ROI pooling层的主要区别在于输入变成了rois_hard,即挑选后的hard example。然后依然是两个常规的全连接层(fc6,fc7),一个分类全连接层和一个回归全连接层。
layer {
name: "roi_pool5"
type: "ROIPooling"
bottom: "conv5_3"
bottom: "rois_hard"
top: "pool5"
roi_pooling_param {
pooled_w: 7
pooled_h: 7
spatial_scale: 0.0625 # 1/16
}
}
之后的网络层就和原来的Faster R-CNN的预测头大致一样,这里就不一一展开,需要指出的是全连接参数 w w w和 b b b处需要处理,以实现共享。例如,fc6层其参数初始化与前面的readonly一致,不同之处就是需要回传梯度。
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
name: "fc6_w"
lr_mult: 1
}
param {
name: "fc6_b"
lr_mult: 2
}
inner_product_param {
num_output: 4096
}
}
5. Focal-Loss和OHEM
5.1 Focal-Loss的产生
Focal-Loss论文: Focal Loss for Dense Object Detection
Focal-Loss推导:推导
Focal-Loss代码:Focal-Loss
一般来说两阶段检测网络结果的准确度是好于一阶段的,那么是什么原因造成了一阶段检测网络的检测准确度比不上两阶段网络呢?文章的作者从损失的角度进行了改进。
首先,当bbox(由anchor加上偏移量得到)与ground truth间的IOU大于上门限时(一般是0.5),会认为该bbox属于positive example,如果IOU小于下门限就认为该bbox属于negative example。在一张输入image中,目标占的比例一般都远小于背景占的比例,所以两类example中以negative为主,这引发了两个问题:
1)negative example过多造成它的loss太大,以至于把positive的loss都淹没掉了,不利于目标的收敛;
2)大多negative example不在前景和背景的过渡区域上,分类很明确(这种易分类的negative称为easy negative),训练时对应的背景类score会很大,换个角度看就是单个example的loss很小,反向计算时梯度小。梯度小造成easy negative example对参数的收敛作用很有限,我们更需要loss大的对参数收敛影响也更大的example,即hard positive/negative example。
在Faster R-CNN网络中针对上面的上个问题,从如下方面解决:
1)会根据IOU的大小来调整positive和negative example的比例,比如设置成1:3,这样防止了negative过多的情况(同时防止了easy negative和hard negative),就解决了前面的第1个问题。所以Faster RCNN的准确率高;
2)会根据前景score的高低过滤出最有可能是前景的example (1K~2K个),因为依据的是前景概率的高低,就能把大量背景概率高的easy negative给过滤掉,这就解决了前面的第2个问题;
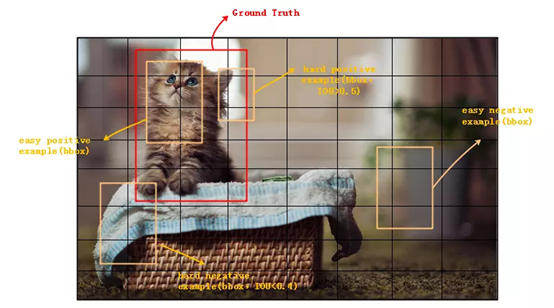
下图是hard positvie、hard negative、easy positive、easy negative四种example的示意图,明显easy negative占据了大多数。
5.2 Focal-Loss的思路
Focal-Loss先解决了样本不平衡的问题,即在交叉熵损失(CE Loss,Cross Entropy Loss )上加权重,当class为1的时候,乘以权重 α t \alpha_t αt,当class为0的时候,乘以权重 1 − α t 1-\alpha_t 1−αt,这是最基本的解决样本不平衡的方法,也就是在loss计算时乘以权重。注意下面公式中 α t \alpha_t αt有个下角标 t t t,也就是说 α \alpha α针对不同类别,值并不一样
C E ( p t ) = − α t l o g ( p t ) CE(p_t)=-\alpha_t log(p_t) CE(pt)=−αtlog(pt)
尝试通过添加权重解决样本不平衡问题之后,接下就是分配loss的问题了。Focal-Loss中在CE前加了一个 ( 1 − p t ) γ (1-p_t)^\gamma (1−pt)γ系数用于处理loss的分类问题。也就是说,如果你的准确率越高, γ \gamma γ次方的值越小,整个loss的值也就越小。也就是说, γ \gamma γ次方就是用来衰减的,准确率越高的样本衰减越多,越低的衰减的越少,这样整个loss就是由准确率较低的样本主导了。对于onestage的网络,loss由负样本主导,但这些负样本大多是准确率很高的,经过focal loss后就变成了正负样本共同主导,或者说是概率低的主导。这一点和OHEM很像,OHEM是让loss大的进行训练。
F L ( p t ) = − ( 1 − p t ) γ l o g ( p t ) FL(p_t)=-(1-p_t)^{\gamma}log(p_t) FL(pt)=−(1−pt)γlog(pt)
最后总的公式是两者结合:
F L ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) FL(p_t)=-\alpha_t(1-p_t)^{\gamma}log(p_t) FL(pt)=−αt(1−pt)γlog(pt)
6 Focal-Loss与OHEM的思考
6.1 Focal-Loss与OHEM的关系
OHEM是只取3:1的负样本去计算loss,之外的负样本权重置零,而focal loss取了所有负样本,根据难度给了不同的权重。
focal loss相比OHEM的提升点在于,3:1的比例比较粗暴,那些有些难度的负样本可能游离于3:1之外。之前实验中曾经调整过OHEM这个比例,发现是有好处的,现在可以试试focal loss了。
paper中单独做了一个实验,就是直接在CE上加权重,得到的结果是alpha=0.75的时候效果最好,也就是说,正样本的权重为0.75,负样本的权重为0.25,正样本的权重大于负样本,因为本身就是正样本个数远少于负样本。加了 γ \gamma γ次方后,alpha取0.25的时候效果最好,也就是说,正样本的权重为0.25,负样本的权重为0.75,这个时候反而负样本的权重在增加,按道理来说,负样本个数这么多,应该占loss主导,这说明 γ \gamma γ次方已经把负样本整体的loss衰减到需要加权重的地步。
paper中 α = 0.25 \alpha=0.25 α=0.25, γ = 2 \gamma=2 γ=2效果最好。
6.2 为什么说这些方法像Boosting
上面自己做的总结是有问题的,自己认为SSD中正负样本严重失衡(1:1000),Focal-Loss是在解决SSD的样本不平衡问题。但是实际上,SSD训练的时候通过hard mining选负样本,实现了正负样本1:3。
Focal-Loss主旨是:SSD按照OHEM选出了loss较大的,但忽略了那些loss较小的easy的负样本,虽然这些easy负样本loss很小,但数量多,加起来的loss较大,对最终loss有一定贡献。作者想把这些loss较小的也融入到loss计算中。但如果直接计算所有的loss,loss会被那些easy的负样本主导,因为数量太多,加起来的loss就大了。也就是说,作者是想融入一些easy example,希望他们能有助于训练,但又不希望他们主导loss。这个时候就用了公式进行衰减那些easy example,让他们对loss做贡献,但又不至于主导loss,并且通过balanced cross entropy平衡类别。
对于two stage来说,rpn阶段是保持的1:1的正负样本比例,但rpn阶段也是有大量的负样本,这个阶段类似于SSD。按道理来说,实现应该是把所有的rpn的anchor都拿来训练使用focal-loss,但我做的时候还是用的512个正负样本,其实这个实验稍稍有点不正确,但性能上依旧能将mAP值提升1.5个点。对于一般物体检测fast阶段,提取的roi实际上只有2000个,并且负样本一般不会太多,不会像SSD那样1:1000,所以王乃岩觉得这个阶段使用focal显然是没有太大意义的。但有个特殊的地方,小物体,我自己做小物体的时候,选512个roi(faster原版的代码应该是128),很多图片正样本只有几个,但负样本几百个,这个时候其实也可以考虑使用Focal-Loss.
7. 参考
- OHEM算法及Caffe代码详解
- focal loss和ohem
- 目标检测 | OHEM
- 对抗网络之目标检测应用:A-Fast-RCNN
- Focal Loss for Dense Object Detection解读
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139215.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
