大家好,又见面了,我是你们的朋友全栈君。
Mysql模糊查询正常情况下在数据量小的时候,速度还是可以的,但是不容易看出查询的效率,在数据量达到百万级,千万级的甚至亿级时 mysql查询的效率是很关键的,也是很重要的。
一、一般情况下 like 模糊查询的写法:前后模糊匹配


这个SQL语句,如果用explain解释的话,我们很容易就能发觉它是没有走索引搜索,而是对全表进行了扫描,这显然是很慢的,还有卡库的可能。
如果将上面的SQL语句改成下面的写法:
就是把‘keyword’前面的%去掉了,这样的写法用explain解释看到,SQL语句使用了索引,这样就可以大大的提高查询的效率。

有时候,我们在做模糊查询的时候,并非要想查询的关键词都在开头,所以如果不是特别的要求,”keywork%”并不合适所有的模糊查询。
二、模糊查询高效的方法:
1、LOCATE(’substr’,str,pos)方法
解释:返回 substr 在 str 中第一次出现的位置,如果 substr 在 str 中不存在,返回值为 0 。如果pos存在,返回 substr 在 str 第pos个位置后第一次出现的位置,如果 substr 在 str 中不存在,返回值为0。

实例:

备注:keyword是要搜索的内容,business为被匹配的字段,查询出所有存在keyword的数据
2、POSITION(‘substr’ IN `field`)方法
其实我们就可以把这个方法当做是locate()方法的别名,因为它和locate()方法的作用是一样的。
实例:

3、INSTR(`str`,’substr’)方法
格式:

实例:
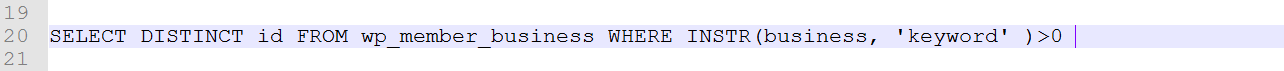
除了上述的方法外,还有一个函数FIND_IN_SET,这个方法比较特殊,他所查询的必须要是以“,”分隔开。
4、FIND_IN_SET(str1,str2):
返回str2中str1所在的位置索引,其中str2必须以”,”分割开。
格式:

实例:


发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/139114.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
