大家好,又见面了,我是你们的朋友全栈君。
论概率:从局部随机性到整体确定性
概率计算
概率计算三原则
所有概率问题,都基于三个计算法则:
- 排列: P n r = n ! ( n − r ) ! P^{r}_{n} = \frac{n!}{(n-r)!} Pnr=(n−r)!n!、组合: C n r = n ! r ! ( n − r ) ! C^{r}_{n} = \frac{n!}{r!(n-r)!} Cnr=r!(n−r)!n!
- 加法法则:如果事件 A 和 事件 B 相互排斥,而事件 A 有 p 种产生方式,事件 B 有 q 种产生方式,则事件 ” A 或 B ” 有 p + q 种产生方式。
- 乘法法则:如果事件 A 和 事件 B 相互独立,且事件 A 有 p 种产生方式,事件 B 有 q 种产生方式,则事件 ” A 与 B ” 有 p * q 种产生方式。
排列组合法则适用于结果有限,而且每种结果都是等可能性的情况。
如果说排列组合法则是针对单个随机事件的概率计算,加法法则针对的就是多个随机事件。
以两个随机事件为例,一个随机事件发生或者另一个随机事件发生的概率,也就是这两个随机事件发生其一的概率,等于两个随机事件各自发生概率的和。
三个随机事件,就是三个概率之和;四个随机事件,就是四个概率之和,这就是加法法则。
不过,加法法则也有个限定条件,就是这两个随机事件不能同时发生,我们也称之为 “互斥”。
和加法法则一样,乘法法则也是针对多个随机事件的概率计算。
以两个随机事件为例,加法法则是两个随机事件发生其一的概率,将两个随机事件各自发生的概率相加。而乘法法则是两个独立事件同时发生的概率,将两个随机事件各自发生的概率相乘就行了。
不过,乘法法则也有个限定条件,得是独立事件(如果随机事件之间没有任何关联,我们就可以说这些随机事件是相互独立的,它们之间就具备独立性)。
- 如果是独立事件,彼此互不影响,可以直接使用乘法法则。
- 如果是非独立事件,那就不能直接乘了,而是要对乘法法则做个变形。
加法原理和乘法原理最重要的区别是事件 A 和 事件 B 的关系,是 “或” 还是 “与”。
一些其他计算公式,在做题之前,全部写在草稿上:
- 独立事件: P ( A B ) = P ( A ) P ( B ) 、 P ( A ∣ B ) = P ( A ) P(AB)=P(A)P(B)、P( A| B)=P(A) P(AB)=P(A)P(B)、P(A∣B)=P(A)
- 减法公式: P ( A B ‾ ) = P ( A − B ) = P ( A ) − P ( A B ) P(A\overline{B})=P(A-B)=P(A)-P(AB) P(AB)=P(A−B)=P(A)−P(AB)、若 A ⊂ B A \subset B A⊂B,则 P ( B − A ) = P ( B ) − P ( A ) P(B-A)=P(B)-P(A) P(B−A)=P(B)−P(A)
- 加法公式: P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A B ) P(A \cup B)=P(A)+P(B)-P(AB) P(A∪B)=P(A)+P(B)−P(AB)
- 条件概率: P ( B ∣ A ) = P ( A B ) P ( A ) , P ( A B ) = P ( B ) P ( A ∣ B ) = P ( A ) P ( B ∣ A ) , P ( A 1 A 2 ⋅ ⋅ ⋅ A n ) = P ( A 1 P ( A 2 ∣ A 1 ) ) ⋅ ⋅ ⋅ P ( A n ∣ A 1 A 2 ⋅ ⋅ ⋅ A n − 1 ) P( B| A)=\frac{P(AB)}{P(A)},P(AB)=P(B)P(A|B)=P(A)P(B|A),P(A_{1}A_{2}···A_{n})=P(A_{1}P(A_{2}|A_{1}))···P(A_{n}|A_{1}A_{2}···A_{n-1}) P(B∣A)=P(A)P(AB),P(AB)=P(B)P(A∣B)=P(A)P(B∣A),P(A1A2⋅⋅⋅An)=P(A1P(A2∣A1))⋅⋅⋅P(An∣A1A2⋅⋅⋅An−1)
- 事件互斥: P ( A B ) = 0 P(AB)=0 P(AB)=0
- 事件对立: P ( A ‾ ) = 1 − P ( A ) P(\overline{A})=1-P(A) P(A)=1−P(A)
- 对偶原则: A ∪ B ‾ = A B ‾ 、 A ‾ B ‾ = A ∪ ‾ B \overline{A \cup B}=\overline{AB}、\overline{A} ~\overline{B}=A \overline{\cup} B A∪B=AB、A B=A∪B
写完后,对着找就可以了。
学概率论拼的不是数学,而是语文能力
正因为概率计算简单,所以概率论考试的时候,老师只能把题目描述得非常复杂。什么“或”“同时”“有放回”“无放回”,一字之差,结果就天壤之别。
大部分人不会做概率题,不是他不会计算,而是他没看明白题目。也许打败他的不是数学,而是语文。真正搞懂题目的意思,才是概率论考试的重点。
概率老师这么做是为啥呢?是为了故意把学生卡住,不让他毕业吗?当然不是。这其实是一种思维方式的训练。
让学生在复杂的题目中,寻找“或”,寻找“与”,辨析互斥,辨析独立,计算和分辨各种复杂的排列组合,从而学会把考卷上的题目翻译成一个概率问题。
要知道,我们在实际生活中遇到的概率问题,可远比加减乘除困难,甚至比考卷上设定的题目更难。现实中我们不会计算概率,往往就是因为不会把一个现实问题,准确地翻译成“对”的概率问题。
确切的说,学概率论拼的不是数学,而是语文能力。
比如,王家先后有两个孩子,已知老大是女孩,问另一个是男孩的概率是多少?
这很简单,老大的性别已经确定了,所以老二要么是男孩,要么是女孩,概率就是1/2嘛。
但是,只要改变条件里的一个词,把 “老大是女孩” 变成 “其中一个是女孩”,就改了一个词,这时候概率就变了。两个孩子,其中一个是女孩,就有 “女孩男孩、男孩女孩、女孩女孩” 三种情况,有男孩的情况有两种,所以另一个是男孩的概率马上就变大了,从 1 2 \frac{1}{2} 21 变成了 1 3 \frac{1}{3} 31。是不是很神奇?
概率计算四步法
我们对于什么的概率是多少的问题,概率计算四步法可以快速找到解题思路:
- 找到样本空间:把所有可能情况都排出来(树状图画出来)
- 找到目标事件:···的概率是多少(树状图中标记这部分)
- 确定结果概率:每个可能结果的概率(算出树状图每条边的概率)
- 计算事件概率:套用公式得出结果
条件概率:一切概率都是条件概率
所谓的条件概率,通俗来讲就是,如果一个随机事件的概率会因为某个条件而产生变化,那在这个条件发生的情况下,这个随机事件发生的概率就是条件概率。
其实严格来说,所有的概率问题都是基于条件的。
当我们说 “硬币正面朝上的概率是50%” 时,其实就隐含了很多条件。比如“这个硬币是公平的”、“抛硬币的手法没问题”、“空气密度不影响硬币的结果”、“气流不会对硬币产生干扰”等。
1994年,美国洛杉矶发生了一场恶性凶杀案,两名白人被杀,橄榄球明星辛普森杀妻事件。
辛普森有多次家暴前妻的记录,从家暴到杀人,是很有可能的。
而辛普森的律师天团,操纵条件,改变概率,以证明家暴和谋杀没有必然关系。
- P ( 丈 夫 谋 杀 ∣ 丈 夫 家 暴 ) P(丈夫谋杀|丈夫家暴) P(丈夫谋杀∣丈夫家暴):美国有 400 万被家暴的妻子,但只有 1432 名被丈夫谋杀,这个概率只有 1432 除以 400 万,比 1/2500 还低。所以,家暴证明不了辛普森谋杀。
您看,律师天团其实说的是,在家暴这个条件下,一个人谋杀妻子的概率并不会大大增加,所以不能判定辛普森有罪。
但是,律师天团故意忽略了一个条件 — 辛普森的妻子已经被杀害。
一旦 “前妻已经被杀害” 这个条件出现,问题就不再是 “在家暴的条件下,丈夫谋杀妻子的概率是多少” 了,而是变成了 “在丈夫家暴妻子,而且妻子已经死于谋杀的双重条件下,杀人凶手是丈夫的概率是多少”。
- P ( 丈 夫 谋 杀 ∣ 丈 夫 家 暴 且 妻 子 死 亡 ) P(丈夫谋杀|丈夫家暴且妻子死亡) P(丈夫谋杀∣丈夫家暴且妻子死亡)
如果有 100000 个被丈夫家暴过的妇女,那么其中大概有40个妇女最终会被丈夫谋杀(1/2500×100000=40)。
而根据美国联邦调查局于 1992 年发布的女性被谋杀的数据推算,每 100000 个被家暴的妇女中有 43 个会被谋杀。所以,有 3 个妇女被丈夫以外的人谋杀,其余 40 人都是被丈夫谋杀了。
条件概率的计算如下:
- 事件A:妻子被丈夫杀害
- 事件B:妻子被家暴且妻子死亡
则在妻子被家暴且被谋杀的双重条件下,妻子是被丈夫杀害的概率:
- P ( A │ B ) = P ( A B ) P ( B ) = ( 40 100000 ) / ( 40 + 3 100000 ) = 0.93 P(A│B)=\frac{P(AB)}{P(B)} =(\frac{40}{100000})/(\frac{40+3}{100000})=0.93 P(A│B)=P(B)P(AB)=(10000040)/(10000040+3)=0.93
相关性高达:93%,这个条件概率要远远高于 1 2500 \frac{1}{2500} 25001。
其实一切概率都是条件概率,那么,操纵条件,改变概率。
题目增益
某工厂有职工 400 人,其中男女职工各占一半,男女职工中技术优秀的分别为 20 人与 40 人,从中任选一名职工,已知选出来的是男职工,他技术优秀的概率是多少?
答: P ( 技 术 优 秀 ∣ 男 职 工 ) = P ( 技 术 优 秀 男 职 工 ) P ( 男 职 工 ) = 20 200 = 1 10 P(技术优秀|男职工)=\frac{P(技术优秀男职工)}{P(男职工)}=\frac{20}{200}=\frac{1}{10} P(技术优秀∣男职工)=P(男职工)P(技术优秀男职工)=20020=101
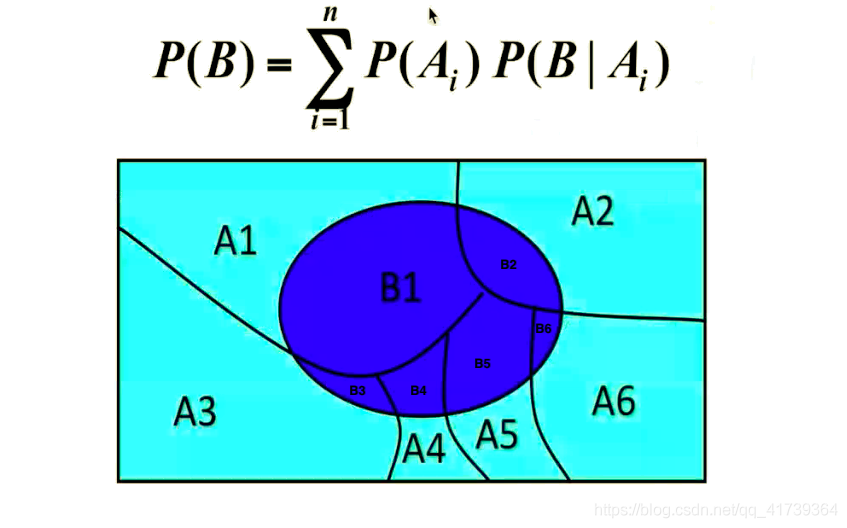
全概率公式
在较为复杂的时候,直接计算总体发生某事的概率 P ( B ) P(B) P(B) 不易,但 B B B 总是伴随着某个 A i A_{i} Ai 出现,适当的去构造这一组 A i A_{i} Ai。

题目增益

需要用到全概率公式的题目,是给出相似但没有关联的多个对象(如甲、乙),以及每个对象的具体数据(甲乙的产品分别占60%/40%,次品率是1%和2%),再把多个对象组合成一个整体(从中随机抽取一件),求总体发生某事的概率(问次品的概率)。
答: P ( 总 体 抽 一 件 是 次 品 ) = P ( 选 甲 ) ∗ P ( 选 甲 抽 一 件 是 次 品 ) + P ( 选 乙 ) ∗ P ( 选 乙 抽 一 件 是 次 品 ) P(总体抽一件是次品)=P(选甲)*P(选甲抽一件是次品)+P(选乙)*P(选乙抽一件是次品) P(总体抽一件是次品)=P(选甲)∗P(选甲抽一件是次品)+P(选乙)∗P(选乙抽一件是次品)
全概率公式:
-
文 字 表 达 : P ( 总 体 某 事 发 生 ) = P ( 选 对 象 一 ) ∗ P ( 选 对 象 一 该 事 发 生 ) + P ( 选 对 象 二 ) ∗ P ( 选 对 象 二 该 事 发 生 ) ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ 文字表达:P(总体某事发生)=P(选对象一)*P(选对象一该事发生)+P(选对象二)*P(选对象二该事发生)······ 文字表达:P(总体某事发生)=P(选对象一)∗P(选对象一该事发生)+P(选对象二)∗P(选对象二该事发生)⋅⋅⋅⋅⋅⋅
-
数 学 表 达 : P ( B ) = P ( A 1 ) P ( B ∣ A 1 ) + P ( A 2 ) P ( B ∣ A 2 ) + . . . + P ( A n ) P ( B ∣ A n ) 数学表达:P(B)=P(A_{1}) P(B|A_{1})+ P(A_{2}) P(B|A_{2})+ … + P(A_{n})P(B|A_{n}) 数学表达:P(B)=P(A1)P(B∣A1)+P(A2)P(B∣A2)+...+P(An)P(B∣An)
贝叶斯公式
条件概率: P ( B ∣ A ) = P ( A B ) P ( A ) P( B| A)=\frac{P(AB)}{P(A)} P(B∣A)=P(A)P(AB)
- P ( B ∣ A ) P(B|A) P(B∣A):条件概率,表示在 A 条件下 B 发生的概率
- P ( A B ) P(AB) P(AB):条件 A、事件 B 同时发生的概率
- P ( A ) P(A) P(A):条件 A 发生的概率
在文本中的两个词 A 和 B,前面的词就是后面的词的条件,比如 A 是中药,B 是人参,反过来也成立,A 是人参,B 是中药。
于是,就有一个想法:
- P ( B ∣ A ) = P ( A B ) P ( A ) P( B| A)=\frac{P(AB)}{P(A)} P(B∣A)=P(A)P(AB)
- P ( A ∣ B ) = P ( A B ) P ( B ) P( A| B)=\frac{P(AB)}{P(B)} P(A∣B)=P(B)P(AB)
我们把俩个式子都变形:
- P ( A B ) = P ( B ∣ A ) ∗ P ( A ) P(AB) = P(B|A)*P(A) P(AB)=P(B∣A)∗P(A)
- P ( A B ) = P ( A ∣ B ) ∗ P ( B ) P(AB) = P(A|B)*P(B) P(AB)=P(A∣B)∗P(B)
对比这个式子和前面的式子,我们发现它们都等于 P ( A , B ) P(A,B) P(A,B),因此两个等式的左边也必然相等。
于是,我们就可以得到一个重要的公式:
- P ( B ∣ A ) ∗ P ( A ) = P ( A ∣ B ) ∗ P ( B ) P(B|A)*P(A)=P(A|B)*P(B) P(B∣A)∗P(A)=P(A∣B)∗P(B)
在这个公式中,如果我们知道了其中三个因子,就能求出第四个。
通常来讲,两个条件概率 P ( A ) P(A) P(A) 和 P ( B ) P(B) P(B) 是容易求的。
另外两个条件概率,一个是 A 条件下 B 的概率,一个是 B 条件下 A 的概率,常常一个比较容易得到,另一个比较难得到。
另外两个条件概率,一个是 A 条件下 B 的概率,一个是 B 条件下 A 的概率,常常一个比较容易得到,另一个比较难得到。
所以,我们常常从容易得到的条件概率,推导出难得到的概率,这就是著名的贝叶斯公式:
- 贝叶斯公式: P ( A ∣ B ) = P ( B ∣ A ) ∗ P ( A ) P ( B ) P(A|B)=P(B|A)*\frac{P(A)}{P(B)} P(A∣B)=P(B∣A)∗P(B)P(A)
在这个公式中,我们假定 B 条件下 A 的条件概率比较难得到,我们放在了等式的左边,而 A 条件下 B 的条件概率容易得到,我们放在了等式的右边。
通过这种互换,可以把一个复杂的问题变成三个简单的问题。
这就是贝叶斯公式的本质。利用它,就解决了机器翻译的难题。
假定有一个英语句子 B,想要翻译成中文句子 A,那怎么翻译呢?
很多人将它想象成语言学问题,其实这是一个数学问题,或者更准确地说,是一个概率的问题。
假定英语句子 B 有很多种翻译方法 A1,A2,A3……AN,我们只要挑一种翻译 A,使得在已知英语句子 B 的条件下,A 的概率 P ( A ∣ B ) P(A|B) P(A∣B) 超过其它所有可能的句子的条件概率即可。
比如说,这句话有 10 种翻译方法,它们的条件概率分别是 0.1,0.5,0.01,0.02……你会发现第二种翻译方法 A2 的条件概率是 0.5,是最大的,因此就认为 B 应该被翻译成 A2,或者说 A = A2。
P ( A ∣ B ) P(A|B) P(A∣B) 这个概率该怎么计算呢?
这个条件概率的计算,就要用到贝叶斯公式了。我们将它展开成:
- P ( A ∣ B ) = P ( B ∣ A ) ∗ P ( A ) P ( B ) P(A|B)=P(B|A)*\frac{P(A)}{P(B)} P(A∣B)=P(B∣A)∗P(B)P(A)
P ( B ∣ A ) P(B|A) P(B∣A) 是给定中文的句子,对应的英文句子的概率,它可以通过一个马尔可夫模型计算出来。
P ( A ) P(A) P(A) 是所谓的语言模型,它计算的是哪个句子在语法上更合理,这个也可以通过一个马尔可夫模型计算。
P ( B ) P(B) P(B) 是一个常数,因为要翻译句子 B,它是个确定的事情,我们把它的概率想象成 1 就可以了(其实不是1)。
于是原来的一个无法直接计算的条件概率,经过贝叶斯公式,变成了三个可以计算的概率。
这样,就能够判断给定一个句子,任何翻译出来的中文句子的可能性,而后我们找出最大的那个即可。
因为条件概率在数学上条件和结果可以互换,通过这种互换,把一个复杂的问题变成三个简单的问题,这就是贝叶斯公式的本质,利用它,就解决了机器翻译的难题。
复盘一下,推导思路:从核心公式开始,
- P ( A , B ) = P ( B ∣ A ) ∗ P ( A ) P (A,B)=P (B|A)*P (A) P(A,B)=P(B∣A)∗P(A)
- P ( A , B ) = P ( A ∣ B ) ∗ P ( B ) P (A,B)=P (A|B)*P (B) P(A,B)=P(A∣B)∗P(B)
于是有:
- P ( B ∣ A ) ∗ P ( A ) = P ( A ∣ B ) ∗ P ( B ) P (B|A)*P (A)=P (A|B)*P (B) P(B∣A)∗P(A)=P(A∣B)∗P(B)
如何更容易地理解呢?答案是:「分步」,一步一步看。
- P ( A ) P (A) P(A):事件 A 发生的概率;
- P ( B ) P (B) P(B):事件 B 发生的概率;
- P ( A , B ) P (A,B) P(A,B):事件 A,B 同时发生的概率;
以上,都很容易理解。现在想一想:要让事件 A,B 同时发生我们可以如何实现?
我们可以「分步」完成这件事。而且,「分步」有两种不同方法,如下:
- ① 我们可以先让 A 发生,再在 A 发生的基础上让 B 发生;
- ② 我们可以先让 B 发生,再在 B 发生的基础上让 A 发生。
以上①、②两种「分步」途径都可以实现让事件 A,B 同时发生。
分步完成一件事总的概率等于每一步完成概率的乘积。
于是,上面两种途径就可以写成公式语言:
- ① A,B 同时发生 = A 发生 * A 已发生条件下 B 再发生;
- ② A,B 同时发生 = B 发生 * B 已发生条件下 A 再发生;
所以, P ( A , B ) = P ( A ) ∗ P ( B ∣ A ) = P ( B ) ∗ P ( A ∣ B ) P (A,B)=P (A)*P (B|A)=P (B)*P (A|B) P(A,B)=P(A)∗P(B∣A)=P(B)∗P(A∣B)
理解条件概率,可以从 “分步完成” 的角度思考,这样即使再推广到更多的事件,你也能够很快写出正确的公式。
比如,A,B,C 三个事件同时发生,我们依旧可以「分步」完成,一种分步方式是:
- 先让 A 发生,再在 A 发生的条件下让 B 发生,再在 A,B 都发生的条件下让 C 发生
由此可以轻松写出公式 P ( A , B , C ) = P ( A ) ∗ P ( B ∣ A ) ∗ P ( C ∣ A B ) P (A,B,C)=P (A)*P (B|A)*P (C|AB) P(A,B,C)=P(A)∗P(B∣A)∗P(C∣AB),思路你学会了吗?
题目增益

需要用到贝叶斯公式的题目,是给出相似但没有关联的多个对象(如甲、乙),以及每个对象的具体数据(如甲乙的产品分别占60%/40%,次品率是1%和2%),再把多个对象组合成一个整体(如从中随机抽取一件),在已知总体里某事发生的情况下(如发现是次品),求抽的东西源自某个对象的概率(如则该次品是甲生产的概率是)。
贝叶斯公式:
-
文 字 表 达 : P ( 抽 的 东 西 源 自 某 对 象 ∣ 总 体 某 事 发 生 ) = P ( 选 该 对 象 ) ∗ P ( 该 对 象 里 该 事 发 生 ) P ( 总 体 里 该 事 发 生 ) 文字表达:P(抽的东西源自某对象|总体某事发生)=\frac{P(选该对象)*P(该对象里该事发生)}{P(总体里该事发生)} 文字表达:P(抽的东西源自某对象∣总体某事发生)=P(总体里该事发生)P(选该对象)∗P(该对象里该事发生)
-
数 学 表 达 : P ( A ∣ B ) = P ( B ∣ A ) ∗ P ( A ) P ( B ) 数学表达:P(A|B)=\frac{P(B|A)*P(A)}{P(B)} 数学表达:P(A∣B)=P(B)P(B∣A)∗P(A)
随机变量
通俗地讲,随机变量就是一个随机的数,它是对任何的“随机的东西”做的量化。
把随机事件可能的结果抽象成一个数字,每个数字对应一个概率。这个随机变化的数字,就是随机变量。
随机的对象可以是任何东西–明天的天气可以是晴、阴、雨,扔硬币的结果可以是正面或者反面,这里本身都没有数字。
但是我们要借助概率论来研究它们,而概率论是数学的一部分,要用到数学语言,那么总是写 “明天是晴天的概率” 就很不方便,于是我们可以把晴、阴、雨贴上标签,叫做0、1、2,而后把明天的天气状况用一个字母X来表示,于是“明天下雨”就变成了“X=2”。
这样,这个原本没有数字的随机结果就变成了一个可能的取值为0、1、2的随机数,这就是随机变量。
期望和方差这两个描述随机事件的重要指标。
期望:对长期价值的数字化衡量
期望计算:先把每个结果各自发生的概率和带来的影响相乘,再把算出来的数相加。
数学期望本质上就是对事件长期价值的数字化衡量,或者说,每当要判断一件事的长期价值,数学期望就是一个指标。
注意,是长期价值。数学期望是把概率代表的长期价值变成了一个具体的数字,方便我们比较。
数学期望 = 成功的收益 × 成功的概率 – 失败的损失 × 失败的概率
如,一只股票现在 50 块,有40%的概率涨到 60 块,有30%的概率保持不变,还有30%的概率跌到 35 块。
- E ( X ) = ( 60 − 50 ) ∗ 40 % − ( 50 − 50 ) ∗ 30 % − ( 50 − 35 ) ∗ 30 % = − 0.5 E(X) =(60-50) * 40\% – (50-50)*30\%-(50-35)*30\% =-0.5 E(X)=(60−50)∗40%−(50−50)∗30%−(50−35)∗30%=−0.5
也就是说,虽然上涨的可能性比下跌的可能性更大,但整体上看,这只股票趋向于亏钱,不值得买。
在NBA这个世界最顶级的篮球联赛中,不少球队是照魔球理论建队的。比如说,火箭队的莫雷,在库里,已经开始了魔球计划。
魔球理论:打篮球?有三种得分方式。
篮下、中距离、三分球,假设你投中的概率分别是 55%、45%、35%。
那从长期来看,哪种进攻方式比较好?
- 篮下:2 x 55% + 0 x 45% = 1.1分
- 中距离:2 x 45% + 0 x 55% = 0.9分
- 三分球:3 x 35% + 0 x 65% = 1.05分
篮下进攻和三分球的数学期望比中距离都要高,所以尽可能多进攻篮下和投三分球,少投中距离,长期来看就是更有效率的选择。
我们过去这不到二十年间,NBA 比赛中最热门的 200 个投篮位置的演变。
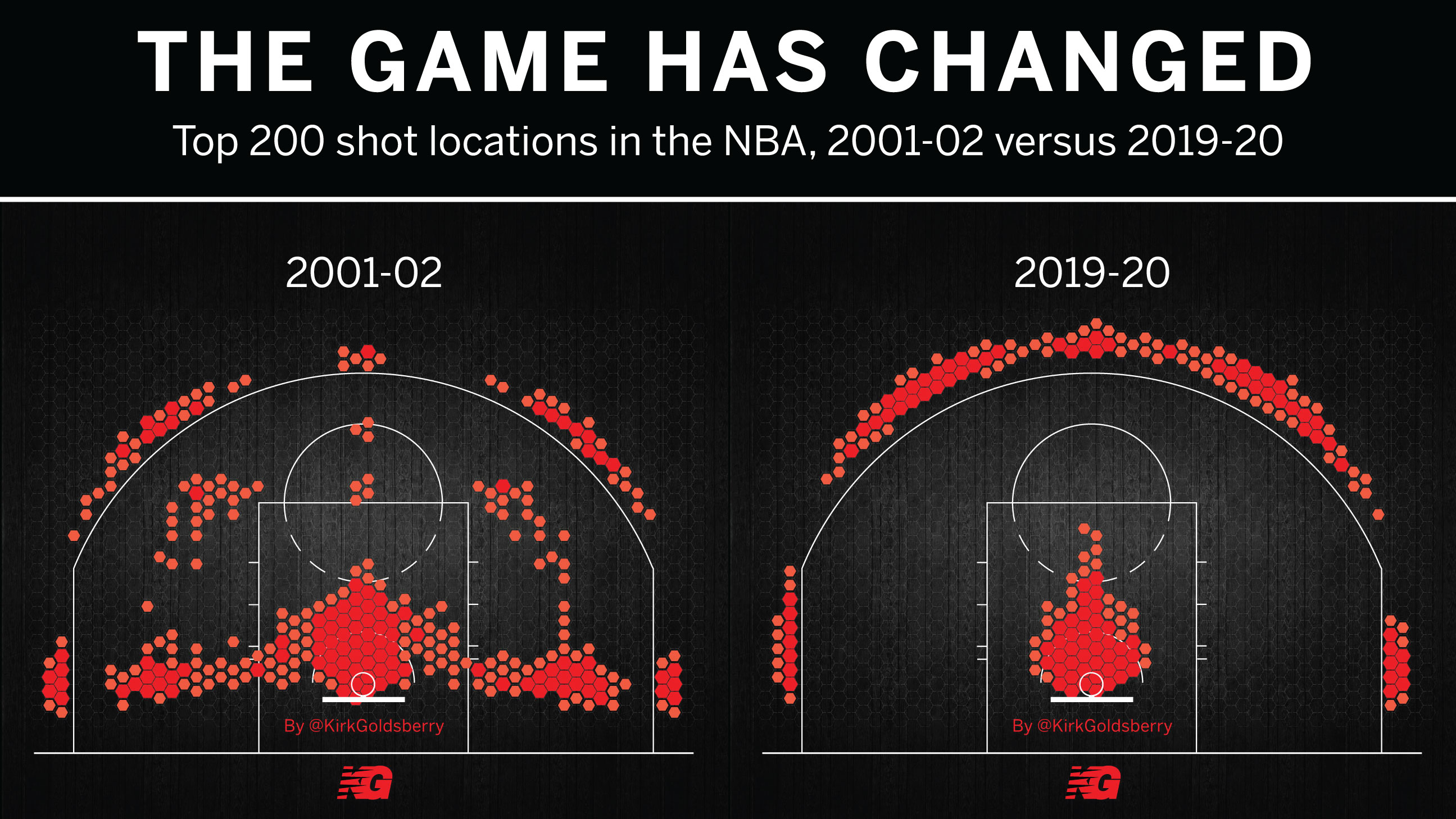
左边,2001-02 赛季的 NBA 比赛中你可以看到各个位置的投球。最热门的投篮位置是在篮下,然后是底线附近的中投,还有三分球,还有四十五度角和罚球点附近的中投。比赛在多点开花,因为球员可以在任意位置出手,怎么舒服怎么来。
十八年后,到了 2019-20 赛季,热门投篮点只剩下了篮下附近的区域和三分球。所有不正面面对篮筐的中投都消失了,这个打法是现在篮球的最优解。
二十年前,NBA 17% 的投篮是三分球。十年前是 22%。五年前是 28%……而 2021 年一月份,三分球占投篮总数的比例是 40%。
这可是 40% 啊。请注意这不是三分球占得分的比例,是占出手的比例:也就是说现在基本上你要说投篮,很大可能就是投三分。三分球现在是 NBA 的基础。
而且别忘了这拨球员还都是在三分球没有那么受重视的情况下成长起来的,我们完全可以预期下一拨球员会更擅长投三分。
球员培养方案:
- step-1:研究规则制定最佳策略
通常情况下,最佳当然是蓝下进攻,但随着外线体毛级规则的改变、特定底角、45度腰部三分战术的成熟、全体成员三分球命中率的提升等等,这些提高了三分战术的数学期望,所以最佳策略是三分球。
- step-2:用大数据和人工智能制定战术,训练时让大家习惯机器制定的最优战术。
这样培养出来的人,就有三分球史诗级命中率的库里。
当然三分战术也不是万能的,TA的数学期望还没有到碾压中距离,同时三分战术的兴起,也会改变外线防守强度,忽视中距离的方式,导致中距离命中率会提高,数学期望又会发生变化。
所以对个体来说,不同的球员,更“合理”的战术是根据自己的命中率。比如,林书豪……中距离投的就很欢,因为对他来说,篮下得分的数学期望不断下降(身体素质下降、联防规则、无禁区三秒),而中距离都快成他的主要阵地战得分手段了。
游戏平衡:对于游戏公司来说,怎么保证所谓的游戏平衡呢?换句话说,怎么做到不让某些职业特别强、某些职业特别弱呢?
这时候,他们使用的就是数学期望。把技能的伤害、防御、暴击率、格挡率等指标全部赋予一个具体的数,然后放在一起,计算出每个职业生存的数学期望,最后通过调整达到在数学期望上的平衡。
一些游戏会不断调整某些职业或某个英雄,比如这个太弱了,就增加10点攻击力;那个太强了,就减少100点生命值……其实,就是在调整它们的数学期望,争取达到长期的平衡状态。只有这样,才能提高游戏的公平性和可玩性。
投资期望:用数学期望来投资的几个注意事项,真金白银得出来的认知。
新股刚上市的时候,股价波动往往很大。咱们干脆假设,任何一只股票 IPO 第一周,股价都是或者上涨 80%,或者下跌 60%,可能性各占一半。
涨幅比跌幅大,机会啊,数学期望是正的,赚10%。
如果我每周都赚10%的话,一年下来利滚利,那就是1.1的52次方 —— 如果我投入了1万元,到年底我会有 142 万元。
我有1万元,于是,我每周一把钱全投进去买 IPO 的股票,周五再把股票全部卖掉,下周一再把钱全投进去。如果你也这么做,最有可能的结果是52个星期下来,你还剩下1.95元。
在50%的时间里,你的资金增长80%,在另外50%的时间里,你的资金下跌60%。你的资金要乘以1.8倍26次,乘以0.4倍26次,结果就是你平均每两周亏28%,一年后一万元就变成了1.95元。
我整个人都懵了,说好的 142 万呢?这 142 万元,就是市场的平均回报。但是这可不是你最有可能拿到的回报。
一群人做一件事取得的平均值,和一个人经历这件事很多很多次,是不一样的,这 142 万其实是一群人做一件事取得的平均值。
是无数个平行宇宙里的我平均下来能赚到 142 万,其中有的人比较幸运,遇到很多个周期都是增长80%,很少的周期是下跌60%。而那些不幸的人则是很多周期下跌60%,在很少的周期上涨80%。
把幸运者和不幸者都加在一起,取个平均数,结果就是每个人赚了142万元,但平均值,不是最可能的值(中位数)。
比如四个人连续玩了 2 周,最幸运的人拿走了大部分钱(连续 2 周涨 80%,32400 元),而大部分人拿到的是中位数 7200,最不幸的人只有 1600 元,亏是最可能的。
······
其实这个投资有俩种玩法,一个玩法是你每次只拿1块钱去玩,假设你有无限多个1块钱,你能够一直玩下去的话,那你长期看来的确是赚钱的。数学期望可以用,你平均每把赢0.1元。这是一个加法的关系,财富线性增长。
但是生活中真正的投资,一般不是这么一点一点地玩的。更常见的做法是你把自己所有能动用的资金都押在这个游戏上面,第一把游戏玩完之后,不管结果是多是少,把剩下的钱再次全部押上,这样不断地玩下去。
这种玩法,可就是乘法的关系了。那你最可能的结局是什么呢?是账户清零,财富指数清零。
我们要创造财富,就需要放弃部分安全感,应该冒险、要经历反脆弱,要在风险中成长 —— 但这种风险,主要是“波动性”,是不致命的。而另一方面,我们强烈反对冒 Game Over 的风险。
很多做心理学、社会学研究的人整天跟概率统计打交道,也未必知道这个概念,这就是“遍历性”。
比如说昨天晚上有100个人去一家赌场赌博,其中99个人赌完了都没事,只有一个人赌到输光了。那请问,这家赌场是不是一个危险的所在?答案似乎是并不危险的,毕竟输光率只有1%。
好。还是这家赌场,我们干脆假定去一次的输光率真的是1%。那请问,如果是同一个人,连续去了这家赌场 260 次,请问他输光的概率有多大?
答案是他肯定会输光。
这个道理就是空间上 —— 也就是同一时间一群人的集合 —— 的数学期望,和时间上 —— 也就是一个人连续去很多次 —— 的数学期望是不一样的。在数学上,这就叫“没有遍历性”。如果空间上和时间上的数学期望相同,就叫“有遍历性”。
第一个玩法有遍历性,但是赚钱速度太慢实际生活中没人感兴趣。
幸福取决于较多的小高潮,财富取决于极少的大高潮。
致富不取决于你判断对了多少次,而是取决于你在对的时候敢不敢下注,在错的时候能不能止损。也就是说,财富取决于单次的幅度,不取决于频率。
在局部看,你赢得多;但是往往一加总,从整体上看,你反而是输了。
比如喜欢打麻将的人,其实都知道这个规律。和很多次小牌,通常一场下来不能赢钱,和一次大牌,才能奠定赢钱的局面。
当你对一笔交易充满信心时,就要给对方致命一击。其实,这个时代的投资巨富,基本上都是这个路数。
第二个玩法更实际,但是没有遍历性,而对没有遍历性的系统来说,“数学期望” 没有太大意义,你随时都会死掉的,君子不立于危墙之下。
所以,长期投资最好是,只用年收入的10%,买成长性高、跑道长的投资标的,嗨,其实就是指数(大盘)呀。
生活中有大大小小的选择,如何清晰地计算它们的期望值呢?怎样能比较准确地判断出一个选择的“数学期望为正”?
没有简单通用的办法。数学期望是非常可贵的知识,有时候花多少人力物力做研究,就是为了得到一个数学期望。
对日常生活而言,要点在于我们很多情况下并不需要精确知道一件事的数学期望具体是多少,我们只要大概估计一下就可以做出很好的决策了。
数学期望 = 成功的收益 × 成功的概率 – 失败的损失 × 失败的概率
仅仅是看一眼这个公式,你就能得到有益的人生教训。
-
第一,好事儿不等于万无一失的事儿。一件事有失败的可能性不要紧,只要满足 1)数学期望是正的,2)哪怕失败了也可以承受,那就值得做。所有收益大的事儿都是有风险的,关键在于你能不能承受这个风险。
-
第二,有些事儿失败的损失几乎是零,那么即便这件事失败的概率很高,也值得一试。问问题就是这样的事儿。很可能对方不知道答案,但如果他知道,那可能就给你一个关键信息;而就算他不知道,你问一下也不损失什么。
-
第三,如果成功的收益很大,失败的损失也比较高的话,每一个更精确的概率判断都价值连城。那这时候就值得投入很多工夫调研了。最简单的调研就是问问过来的明白人 —— 问个问题你又损失不了什么。
方差:对风险的度量
假如我们在户外旅游时,遇到一条河:

假如您的身高是 1米8,河水平均深度 1米3,那我们是不是就可以直接走过去了呢?
看起来是安全的,但是下去遇到水中的深坑就淹死了。
所以我们还需要知道河水的深度范围,比如说1米3±0.2米,那么就是安全的,最深就是1米5,最浅是1米1。
当我们知道河的平均深度(均值/数学期望)后,再知道深度范围(方差)才能安全过河!
方差在不同场合有不同的意义:
- 河的深度中,方差大意味着河很深
- 运动场合中,方差大意味着发挥的不稳定
- 对于数据集,方差大意味着数据的比较离散
- 在概率论中,方差大意味着概率质量函数的分布比较分散,随机性高
- 金融领域,方差大意味着波动大,风险高
50年代之前,都知道金融市场有风险,但是对风险的认识特别地模糊,虽然知道它存在,但是你既不知道怎么衡量,也不知道怎么计算。
现代证劵投资行业的起点,就是对风险的度量,把投资收益看成一个随机变量,再用这个随机变量描述TA的收益(数学期望)和风险(方差、标准差、偏度、肥尾、协方差)。
只有期望是不够的,在你决定之前,肯定会考虑一个问题:风险。
- σ 2 = ∑ i = 1 n p i ( x i − x ‾ ) 2 n \sigma^{2}=\sum\limits_{i=1}^n\frac{p_{i}(x_{i}-\overline{x})^{2}}{n} σ2=i=1∑nnpi(xi−x)2
即,结果的值与平均值的差的平方的均值。
如,50%的机会赚 20 万元,另外50%的可能性是赔 10 万元,数学期望是 5万元。
- σ 2 = 50 % ( 200000 − 50000 ) 2 + 50 % ( − 50000 − 100000 ) 2 = 2.25 ∗ 1 0 10 \sigma^{2} = 50\% (200000 – 50000 )^2 + 50\% (-50000 – 100000)^2 = 2.25*10^{10} σ2=50%(200000−50000)2+50%(−50000−100000)2=2.25∗1010
方差描述的是,随机结果围绕数学期望的波动范围,数学期望的波动性有多大。
比如,我们知道俩只股票的数学期望是相同的,但其中一只 100% 赚 5000 元,另一只股票 50% 赚 2000 元,另外 50% 亏 1000 元。
既然数学期望一样,我们肯定选择波动性小的,越稳越好。
数学期望相同,并不代表两件事的价值就一样。随机结果的波动程度,同样对一件事的价值,对我们的决策影响巨大。
方差越大,说明这件事波动性越大。而风险,本质上指的就是波动性。所以,方差的本质,就是对风险的度量。一个随机事件的方差越大,可能的结果离期望值越远,就说明TA的风险越大。
比如,长期来看,股票的投资回报率,也就是数学期望更高,但为什么还是有很多人觉得股票是个坑,而愿意选择收益稳定的国债或者货币基金?其实就是考虑到了两者方差的不同。股票起伏不定,方差太大,风险太高;而国债或者货币基金很稳定,方差很小,风险也很小。
除了方差用来描述风险外,还有标准差、偏度、肥尾、协方差,简单介绍一下。
- 期望 E E E:均值
- 方差 σ 2 \sigma^{2} σ2:偏离均值的幅度,比如喜怒无常、容易激动的人,方差较大
- 标准差 σ \sigma σ:方差的平方根,比如计算身高,方差计算的单位是 米 2 米^{2} 米2,为了和平均身高比较,就开根号,换成 米 米 米
- 偏度:衡量风险的方向,往上还是往下、开心还是生气
- 肥尾:衡量极端情况的可能性
方差、偏度和肥尾这三个风险测度都是针对正态分布而言的。
离散型随机变量
连续型随机变量
导数
导数的基本公式:
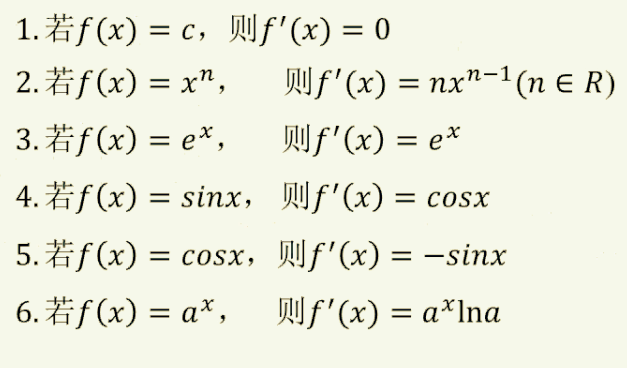
四则运算求导法则:
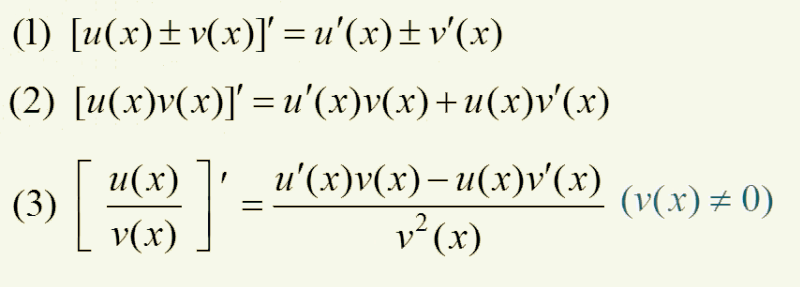
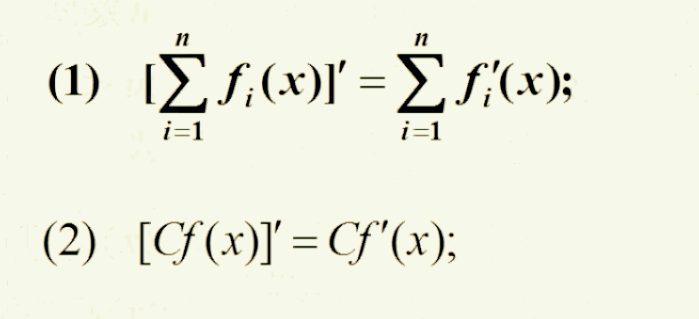
复合函数(多个函数嵌套)求导:

题目增益
求下列函数的导数:
-
y = 2 y=2 y=2
根据求导公式 1,2 是常数 c, f ′ ( x ) = 0 f ‘(x)=0 f′(x)=0
-
y = x 3 y=x^{3} y=x3
根据求导公式 2,3 是幂 n, f ′ ( x ) = 3 x 2 f ‘(x)=3x^{2} f′(x)=3x2
-
y = e x y=e^{x} y=ex
根据求导公式 3, f ′ ( x ) = e x f ‘(x)=e^{x} f′(x)=ex
-
y = 4 x 3 + 6 x 2 − 3 y=4x^{3}+6x^{2}-3 y=4x3+6x2−3
根据求导公式 1、2, f ′ ( x ) = 4 ∗ 3 x 2 + 6 ∗ 2 x 1 − 0 = 12 x 2 + 12 x f ‘(x)=4*3x^{2}+6*2x^{1}-0=12x^{2}+12x f′(x)=4∗3x2+6∗2x1−0=12x2+12x
-
f ( x ) = 3 x 4 − e x − 1 f(x)=3x^{4}-e^{x}-1 f(x)=3x4−ex−1,求 f ′ ( x ) 、 f ′ ( 0 ) f ‘(x)、f ‘(0) f′(x)、f′(0)
根据求导公式 1、2、3, f ′ ( x ) = 12 x 3 − e x f ‘(x)=12x^{3}-e^{x} f′(x)=12x3−ex
代入 0 得, f ′ ( 0 ) = 12 ∗ 0 3 − e 0 = 0 − 1 = − 1 f ‘(0)=12*0^{3}-e^{0}=0-1=-1 f′(0)=12∗03−e0=0−1=−1
复合函数(多个函数嵌套)求导:
-
y = ( x − 2 ) 3 y=(x-2)^{3} y=(x−2)3
将上式子拆分为俩个函数: 外 函 数 y = z 3 , 内 函 数 z = x − 2 外函数~y = z^{3},内函数~z=x-2 外函数 y=z3,内函数 z=x−2
先求外面函数的导数,再求里面的函数的导数: y ′ = ( z 3 ) ′ ∗ ( x − 2 ) ′ y’=(z^{3})’*(x-2)’ y′=(z3)′∗(x−2)′
求导结果: ( z 3 ) ′ = 3 z 2 、 x ′ = 1 ∗ x 1 − 1 = 1 、 2 ′ = 0 (z^{3})’=3z^{2}、x’=1*x^{1-1}=1、2’=0 (z3)′=3z2、x′=1∗x1−1=1、2′=0
等于: y ′ = 3 z 2 y’=3z^{2} y′=3z2
将 z = x − 2 z=x-2 z=x−2 代入: y ′ = 3 ( x − 2 ) 2 y’=3(x-2)^{2} y′=3(x−2)2
不定积分
以上是原函数 —> 求导过程,如果反过来,导数 —> 原函数过程,称为积分。
基本积分公式:
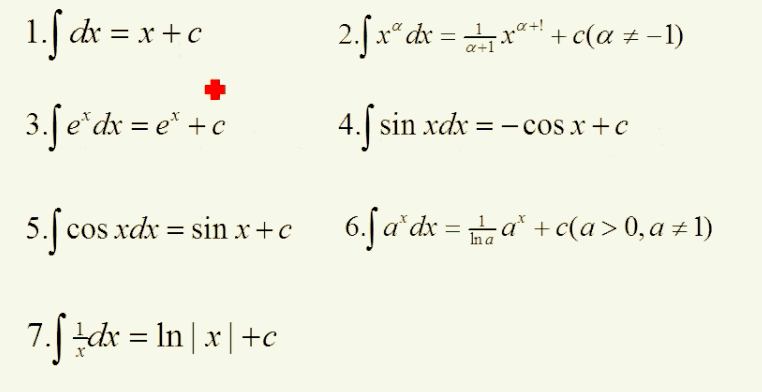
不定积分的性质:

题目增益
-
∫ 2 x d x \int 2xdx ∫2xdx
根据基本积分公式 1 可得: ( x 2 ) ′ = 2 x (x^{2})’=2x (x2)′=2x,所以 x 2 x^{2} x2 是 2 x 2x 2x 的一个原函数, ∫ 2 x d x = x 2 + C \int 2xdx=x^{2}+C ∫2xdx=x2+C
-
∫ x 2 d x \int x^{2}dx ∫x2dx
根据不定积分性质 2 可得: 2 ∫ x 2 d x 2\int x^{2}dx 2∫x2dx
根据基本积分公式 2 可得: 2 ∗ 1 3 x 3 = 2 3 x 3 2*\frac{1}{3}x^{3}=\frac{2}{3}x^{3} 2∗31x3=32x3
-
∫ ( 2 x 2 + 3 x ) d x \int (2x^{2}+3x)dx ∫(2x2+3x)dx
根据不定积分性质 3 可得: ∫ 2 x 2 d x + ∫ 3 x d x \int 2x^{2}dx+\int3xdx ∫2x2dx+∫3xdx
其他计算步骤,如上式。
定积分
定积分在不定积分上,多了一个积分区间。
- 不定积分: ∫ 2 x d x \int 2xdx ∫2xdx
- 定积分: ∫ a b 2 x d x \int^{b}_{a} 2xdx ∫ab2xdx
定积分计算过程:
- 先计算出不定积分
- 再把 a 、 b a、b a、b 代入
比如计算: ∫ x 2 d x \int x^{2}dx ∫x2dx
-
根据不定积分性质 2 可得: 2 ∫ x 2 d x 2\int x^{2}dx 2∫x2dx
-
根据基本积分公式 2 可得: 2 ∗ 1 3 x 3 = 2 3 x 3 2*\frac{1}{3}x^{3}=\frac{2}{3}x^{3} 2∗31x3=32x3
代入 a 、 b a、b a、b, 2 3 ∗ 3 2 − 2 3 ∗ 1 3 \frac{2}{3}*3^{2}-\frac{2}{3}*1^{3} 32∗32−32∗13。
概率分布
概率分布,是指用于表述随机变量取值的概率规律。
比如地震,要研究地震的强度,地震的级别就是一个随机变量,1到8级,每个震级都是随机变量的一个结果。
根据频率法,我们就能知道不同级别的地震发生的概率了。1级地震的概率多大、2级地震的概率多大……一直到8级地震的概率多大,全都一清二楚。
把随机变量所有的结果和它对应的概率全部统计出来后,我们就有了一个东西——概率分布,或者说整体的确定性。
面对一个无法解释的现象,专家会先假设它服从某个概率分布模型,再去验证假设。
比如对于股市这个问题,过去的经济学家发现:股票的波动情况和抛硬币一样,连续两天都涨或连续两天都跌的可能性差不多都是50%(随机),挺服从正态分布的。
于是,他们就用正态分布来模拟股市,并根据这个模型的数学特征,比如数学期望、方差、极端情况出现的可能性等,来构建整个金融体系的风险系统。
最后,人们拿模型的预测和现实中股市的涨跌情况做个对比,发现变化挺一致的。所以人们就认为,股市的变化服从正态分布这个模型。
但是很快,这个结论就出问题了。金融危机爆发的时候,市场完全不遵循正态分布的规律。在正态分布的模型中,几十亿年才会出现一次的极端情况,会在一天内反复出现。
这时候,人们终于明白——用正态分布来评估股市的风险,可能压根就是错的。换句话说,我们可能从一开始就选错了模型。
模型选错了怎么办呢?当然是重新选择新模型。
在研究过极端情况后,金融分析师就发现,用正态分布描述金融资产的风险不对,也许肥尾的柯西分布更有效。
正态分布是钟形曲线,柯西分布也是钟形的,差别只在尾部的高低上。
具体来说,现在大概有几十种分布,我们学习每个分布最重要的学习性质,拥有一种、几种不同的性质。
比如正态分布的稳定性、幂律分布的无标度,指数分布的无记忆等等。
再使用数据,看看这个分布是否可以符合现实的数据情况。如果吻合,就先假设这件事儿服从这个分布,再不断验证。
伯努利分布:二选一
凡是二选一的随机现象,都可用伯努利分布来描述,如抛硬币,是正是反。
假设抛一次硬币,得到正面概率为 p,反面概率为 1-p。
- p ( k ) = p k ( 1 − p ) 1 − k , k = 1 p(k)=p^{k}(1-p)^{1-k},k=1 p(k)=pk(1−p)1−k,k=1
扔十次硬币,真的会有五次朝上?
经过频率法 + 伯努利试验,发现它的规律性其实和我们直觉想象的不一样,我们知道抛硬币正反两面朝上的概率各一半,但你现在去抛十次硬币,真的有5次正面朝上么?
其实这种可能性只有 1 4 \frac{1}{4} 41 左右,显然和大多数人直觉的 1 2 \frac{1}{2} 21 完全不同了。
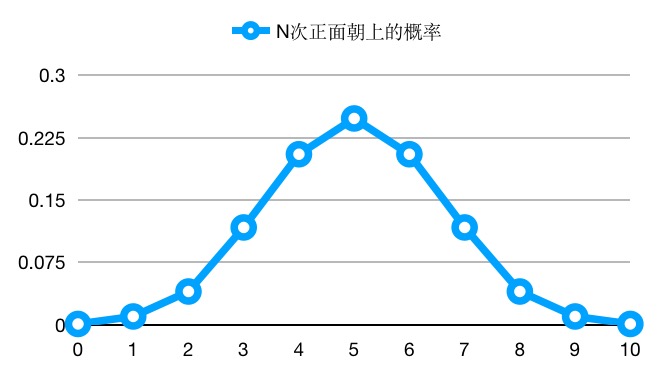
我们知道这是因为局部的随机性,试验次数太少。
随着抛硬币的次数越来越多,正面朝上的概率明显地向 50% 靠近。
其实,计算机模拟的结果也是这样:
- 抛 10 枚硬币,正面朝上的比例范围是 20%~90%;
- 抛 100 枚,比例范围就缩小了,变为了 40%~60%;
- 抛 1000 枚,比例范围就缩小到 46.2%~53.7%。
如何找到这个误差呢?
在数学上我们不能用“曲线比较鼓”,或者“比较平”之类不严格的语言来描述一种规律。我们需要用两个非常准确的概念来定量描述“鼓”和“平”的差别。
这第一个概念就是数学期望,也就是 N*p,因为概率是 p 的事件进行 N 次试验后,平均发生的次数,也是最可能发生的次数。
接下来,我们再用方差这个概念来描述曲线的“鼓”与“平”。
方差在这里其实是对误差的一种度量,既然是误差,就要有可对比的基点,在概率中,这个基准点就是数学期望,如,做 10 次抛硬币的试验,平均就是 5 次正面朝上,5 就是基点。
如果我们做 10 次试验只出现 4 次正面朝上的情况,就有了误差,误差是1。如果 9 次正面朝上,那么误差就大了,就是 4。
接下来我们就把各种误差,和产生那些误差的可能性一起考虑,做一个加权平均,算出来的“误差”就是平方差。
之所以使用 “平方” 这个词,是因为计算方差这种误差时用到了平方,为了进一步方便误差和平均值的比较,我们通常会对方差开根号一次,这样得到的结果被称为标准差。
试验的次数越多,方差和标准差越小,概率的分布越往平均值 N*p 的位置集中。显然,在这种情况下,你用 A 发生的次数,除以试验次数N,当作 A 发生的概率,就比较准确。
反之,试验的次数越少,概率分布的曲线就越平,也就是说 A 发生多少次的可能性都存在,这时你用 A 发生的次数,除以试验次数 N,当作 A 发生的概率,误差可能会很大。
有了标准差的概念,我们就能定量分析理想和现实的差距了。
什么是理想呢?
- 我们进行 N 次伯努利试验,每一次事件 A 发生的概率为 p,N次下来发生了 N*p 次,这就是理想。
那么什么是现实呢?
- 由于标准差的影响,使得实际发生的次数严重偏离 N*p,这就是现实。
很多人喜欢赌小概率事件,觉得它成本低,大不了多来几次,其实由于误差的作用,要确保小概率事件发生,成本要比确保大概率事件的发生高得多。
关于概率论和统计学的规律,还有很多和大家直觉不相符的地方,现在介绍的伯努利试验就是如此。
伯努利试验是单次随机试验,只有 “成功(1)“或”失败(0)” 这两种结果,其概率分布称为伯努利分布,是最简单的离散型概率分布。
在生活中,很多人觉得某件事有 1 N \frac{1}{N} N1 发生的概率,只要他做 N 次,就会有一次发生,这只是理想。
事实上,越是小概率事件,理想和现实的差距越大。比如说一件事发生的概率为1%,虽然进行 100 次试验后它的数学期望值达到了1,但是这时它的标准差大约也是1,也就是说误差大约是100%,因此试了 100 次下来,可能一次也没有成功。
假设中奖概率是 1 100 \frac{1}{100} 1001,如果你想确保获得一次成功怎么办呢?你大约要做 260 次左右的试验,而不是 100 次。
造成试验结果和理论值不一致的原因,是试验次数太少,统计的规律性被试验的随机性掩盖了。
越是小概率事件,你如果想确保它发生,需要试验的次数比理想的次数越要多得多。
比如买彩票这种事情。你中奖的概率是 1 10000000 \frac{1}{1000 0000} 100000001,你如果要想确保成功一次,恐怕要买 2600 万次彩票。你即使中一回大奖,花的钱要远比获得的多得多 — 所以说,彩票,穷人税。
只是当我们买彩票时,思想意识集中在中奖是可能的这一点上,而不是中奖概率是 0.00001% 上,但是,请相信数学。
n 重伯努利试验:n 次二选一
n 重伯努利试验,单次伯努利试验重复 n 次。
- p ( k ) = C n k p k ( 1 − p ) n − k , k = 0 , 1 , 2 , ⋅ ⋅ ⋅ , n p(k)=C^{k}_{n}p^{k}(1-p)^{n-k},k=0,1, 2, ···,n p(k)=Cnkpk(1−p)n−k,k=0,1,2,⋅⋅⋅,n
二项分布:n 重伯努利试验,出现 k 次是
对于 n 重伯努利试验,如果每次得到正面的概率是 p,设随机变量: X = 得 到 正 面 的 概 率 X=得到正面的概率 X=得到正面的概率。
- 二项分布: p ( X = k ) = C n k p k ( 1 − p ) n − k , k = 0 , 1 , 2 , ⋅ ⋅ ⋅ , n p(X=k)=C^{k}_{n}p^{k}(1-p)^{n-k},k=0,1, 2, ···,n p(X=k)=Cnkpk(1−p)n−k,k=0,1,2,⋅⋅⋅,n
以上随机变量 X 的二项分布,简写为 X − B ( n , p ) X-B(n,~p) X−B(n, p)。
完整描述是,在 n 重伯努利试验中,设成功发生的次数为 X,则 X − B ( n , p ) X-B(n,~p) X−B(n, p)。
当 n = 1 时,对应的就是伯努利分布。
- 伯努利分布: p ( X = k ) = C n k p k ( 1 − p ) n − k , k = 0 , 1 p(X=k)=C^{k}_{n}p^{k}(1-p)^{n-k},k=0,1 p(X=k)=Cnkpk(1−p)n−k,k=0,1
伯努利分布也可以记作: B ( 1 , p ) B(1,~p) B(1, p)。
题目增益。
问:某新药有效率为 0.95,有 10 人服用,问至少 8 人治愈的概率是多少?
答:设 X 为 10 人中被治愈人数,如 X − B ( 10 , 0.95 ) X-B(10,~0.95) X−B(10, 0.95)。
所求概率为: P ( X > = 8 ) = P ( X = 8 ) + P ( X = 9 ) + P ( X = 10 ) P(X>=8)=P(X=8)+P(X=9)+P(X=10) P(X>=8)=P(X=8)+P(X=9)+P(X=10)。
- P ( X = 8 ) = C 10 8 0.9 5 8 ( 1 − 0.95 ) 2 P(X=8)=C^{8}_{10}0.95^{8}(1-0.95)^{2} P(X=8)=C1080.958(1−0.95)2
- P ( X = 9 ) = C 10 9 0.9 5 9 ( 1 − 0.95 ) 1 P(X=9)=C^{9}_{10}0.95^{9}(1-0.95)^{1} P(X=9)=C1090.959(1−0.95)1
- P ( X = 10 ) = C 10 10 0.9 5 10 ( 1 − 0.95 ) 0 P(X=10)=C^{10}_{10}0.95^{10}(1-0.95)^{0} P(X=10)=C10100.9510(1−0.95)0
柏松分布:二项分布的极限
在一类特殊的伯努利试验里,随机事件 A 发生的概率通常很小(五十年一遇),但是试验的次数 n 很大,比如发生车祸的情况便是如此,这种分布被称为泊松分布。
在 n 重伯努利试验中,事件 A 在一次试验中出现的概率为 p,如果当 n − > ∞ , n p − > λ ( λ 是 不 为 0 的 常 数 ) n->∞,np->\lambda(\lambda是不为0的常数) n−>∞,np−>λ(λ是不为0的常数),则当 n 很大,p 很小时,有近似公式:
- C n k p k ( 1 − p ) n − k ≈ λ k k ! e − λ , λ = n p C^{k}_{n}p^{k}(1-p)^{n-k}\approx\frac{\lambda^{k}}{k!}e^{-\lambda},\lambda=np Cnkpk(1−p)n−k≈k!λke−λ,λ=np
具体什么时候可以用柏松分布计算呢?
- n ∗ p = λ , λ > 0 , 常 数 n*p = \lambda,~\lambda>0,~常数 n∗p=λ, λ>0, 常数
当二项分布的 n 很大而 p 很小时,泊松分布可作为二项分布的近似,其中 λ 为 np。
通常当 n ≧ 20,p ≦ 0.05 时,就可以用泊松公式近似得计算。
······
泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生次数,不是求解整体发生率,而是求发生次数的概率。
假如您是包子店老板,生意兴隆,但令人发愁的地方是,应该准备多少个馒头才能既不太浪费又可以多买一些呢?
如果您的包子店事业已经比较稳定了,您不会太担心顾客流量的波动。这种情况,就是正态分布。
只要您知道顾客人数符合正态分布,数学期望和标准差就都可以用平时的流量数据统计出来,有了期望和标准差您就可以大致估算各种事件发生的概率。
老板您统计了一周每日卖出的馒头:

数 学 期 望 = 3 + 7 + 4 + 6 + 5 5 = 5 数学期望 = \frac{3+7+4+6+5}{5}=5 数学期望=53+7+4+6+5=5
如果按照期望准备馒头,从统计来看,只能满足 60% 的天数够卖,这肯定不够。
那在某一段时间内,这个随机事件发生的次数的概率分布是什么呢?比如,每天供应 6个、7个、8个、9个 的概率。
求发生次数的概率,泊松分布就是专门解决这类问题的,把 k = 6、7、8、9、···、n 分别计算。
如果每天卖 5 个,那有 40% 的时间没有供应
如果每天卖 6 个,那有 25% 的时间没有供应
如果每天卖 7 个,那有 14% 的时间没有供应
如果每天卖 8 个,那有 7% 的时间没有供应
如果是理想情况,应该是保证每天的包子都是充足的,但这样一定会造成很大的浪费(可能一半不止),所以,我觉得 80%-90% 的时间供应就很合理,所以可选每天供应 8 个(93%的时间都有,但浪费又不会太多)。
… …
数学性质一:泊松分布是正态分布的一种微观视角,数据越多柏松分布越像正态分布。
数学性质二:泊松分布的间隔是无记忆性的。
十年一遇( 1 10 \frac{1}{10} 101),五十年一遇( 1 50 \frac{1}{50} 501),并不代表他们十年五十年才发生一次,他们很可能发生好几次。
就按 “接下来50年” 来计算吧,这时候lambda取值为1。
- K=0,就是接下来的50年,1次都不发生的概率是多少?代入公式一算,答案是37%。
- K=1,就是接下来的50年,发生1次的概率是多少?代入公式一算,答案也是37%。
- K=2,就是接下来的50年,发生2次的概率。代入公式一算,答案是18%。
发生一次的概率37%,一次不发生的概率也是37%,发生2次的概率18%,
而好玩的是,如果中国划成300个不相关的区域,那么在未来一年中中国发生百年一遇的事情的概率是95%,几乎可以说中国每年都有可能遇到一次百年一遇的事儿。所以你在电视里看到今年这儿遇到一个百年一遇的洪水,明年那儿,遇到一个百年一遇的暴雨之类的事情,不用惊讶,百年一遇的事儿每年都会遇到。
这背后就是泊松分布。
物理学家要研究放射性物质的半衰期。可是,绝大多数物质衰变期极长,长到我们没法直接测量。比如铋 209 原子的半衰期是1.9×10的19次方年,如果你盯着一个铋原子,想看到它衰变,可能看到宇宙毁灭都够呛。这时候数据太少了,连一个完整的衰变周期都观测不到。怎么办呢?
我们可以假设衰变是服从正态分布的吗?当然可以。但是,连一个完整的衰变周期都看不全,怎么去验证这个假设呢?
用泊松分布解决。
找一堆铋 209 原子,统计一下在几个确定的时间间隔中,这堆原子有多少个发生了衰变。只要这个数字服从泊松分布,反过来就证明铋 209 原子的衰变服从正态分布,就可以用正态分布直接计算。
在泊松分布之前,概率和统计是两个不同的学科。概率研究未发生的随机事件,统计描述已发生的现实。换句话说,那会儿只有描述统计,没有推断统计。泊松分布开启了推断统计的大门,第一次把概率和统计连接在一起。
离散分布
很多离散分布,都是从伯努利分布中推出的:

指数分布
正态分布
数字特征、极限定理
协方差、相关系数
不相关、相互独立时的期望、方差
切比雪夫不等式
期望、方差称为概率分布的 数 字 特 征 \color{Salmon}{数字特征} 数字特征,它们把复杂的概率分布浓缩为一个实数,使得我们可以快速把握概率分布的特征。
现实中还存在这种情况,只知道数字特征而不知道概率分布,那么能否通过数字特征尝试概率分布呢?
如果不考虑精确程度的话,确实可以还原一部分。
- 切比雪夫不等式: P ( ∣ X − μ ∣ ≥ k ) ≤ σ 2 k 2 P(|X-\mu|\geq k)\leq\frac{\sigma^{2}}{k^{2}} P(∣X−μ∣≥k)≤k2σ2
根据官方数据,中国人均收入为 51350 元,收入标准差 44000 元,那么年入超过百万的人会超过10%吗?
- ∣ X − 51350 ∣ ≥ 100 , 0000 − 51350 |X-51350 |\geq100,0000-51350 ∣X−51350∣≥100,0000−51350
- P ( ∣ X − 51350 ∣ ≥ 948650 ) ≤ 4400 0 2 94865 0 2 ≈ 0.22 % P(|X-51350 |\geq948650)\leq\frac{44000^{2}}{948650^{2}}\approx0.22\% P(∣X−51350∣≥948650)≤9486502440002≈0.22%
千分之二左右。
大数定律
中心极限定理
数理统计
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138904.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
