大家好,又见面了,我是你们的朋友全栈君。
目录
前言
现在的社会是一个科技与信息高速发展的社会,人们之间的交流越来越密切,生活也越来越方便,大数据技术不知不觉地渗入人们生活的方方面面。人不仅生产大数据,同是也在使用大数据
阿里巴巴创办人马云在一次演讲中提到,未来的时代将不是IT时代 ,而是DT时候 DT就是 Data Technology,数据科技,表明了大数据对于阿里巴巴集团来说举足轻重。
有人把数据比喻为蕴藏能量的煤矿。大数据并不在“大”,而在于“有用”。价值含量、挖掘成本比数量更为重要。对于很多行业而言,如何利用这些大规模数据是赢得竟争的关键。
1.1 大数据概念及价值
大数据本身是一个比较抽象的概念,单从字面来看,它表示数据规模的庞大。但是仅仅数量上的庞大显然无法看出大数据这一概念和以往的“海量数据”(Massive Data)、“超大规模数据”(Very Large Data)等概念之间有何区别。针对大数据,目前存在多种不同的理解和定义。
麦肯锡在其报告《Big data: The next frontier for innovation, competition and productivity》中给出的大数据定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合。
维基百科对“大数据”的解读是:“大数据”(Big Data),或称巨量数据、海量数据、大资料,指的是所涉及的数据量规模巨大到无法通过人工,在合理时间内达到截取、管理、处理、并整理成为人类所能解读的信息。
百度百科对“大数据”的定义为:“大数据”(Big Data),或称巨量资料,指的是无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
研究机构Gartner认为,“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。从数据的类别上看,“大数据”指的是无法使用传统流程或工具处理或分析的信息。它定义了哪些超出正常处理范围和大小、迫使用户采用非传统处理方法的数据集。
按照美国国家标准与技术研究院(National Institute of Standards and Technology,NIST)发布的研究报告的定义,大数据是用来描述在我们网络的、数字的、遍布传感器的、信息驱动的世界中呈现出的数据泛滥的常用词语。大量数据资源为解决以前不可能解决的问题带来了可能性。
大数据代表着数据从量到质的变化过程,代表着数据作为一种资源在经济与社会实践中扮演越来越重要的角色,相关的技术、产业、应用、政策等环境会与之互相影响、互为促进。从技术角度来看,这种数据规模质变后带来新的问题,即数据从静态变为动态,从简单的多维度变成巨量维度,而且其种类日益丰富,超出当前分析方法与技术能够处理的范畴。这些数据的采集、分析、处理、存储和展现都涉及复杂的多模态高维计算过程,涉及异构媒体的统一语义描述、数据模型、大容量存储的建设,涉及多维度数据的特征关联与模拟展现。然而,大数据发展的最终目标还是挖掘其应用价值,没有价值或者没有发现其价值的大数据从某种意义上讲是一种冗余和负担。
1.1.1大数据的特征(特点)
(1)规模性(Volume)
随着信息化技术的高速发展,数据开始爆发性增长。大数据中的数据不再以几个GB或几个TB为单位来衡量,而是以 PB(1千个T)、EB(1百万个T)或ZB(10亿个T)为计量单位。
(2)多样性(Variety)
多样性主要体现在数据来源多、数据类型多和数据之间关联性强这三个方面。
①数据来源多,企业所面对的传统数据主要是交易数据,而互联网和物联网的发展,带来了诸如社交网站、传感器等多种来源的数据。
而由于数据来源于不同的应用系统和不同的设备,决定了大数据形式的多样性。大体可以分为三类:一是结构化数据,如财务系统数据、信息管理系统数据、医疗系统数据等,其特点是数据间因果关系强;二是非结构化的数据,如视频、图片、音频等,其特点是数据间没有因果关系;三是半结构化数据,如HTML文档、邮件、网页等,其特点是数据间的因果关系弱。
②数据类型多,并且以非结构化数据为主。传统的企业中,数据都是以表格的形式保存。而大数据中有70%-85%的数据是如图片、音频、视频、网络日志、链接信息等非结构化和半结构化的数据。
③数据之间关联性强,频繁交互,如游客在旅游途中上传的照片和日志,就与游客的位置、行程等信息有很强的关联性。
(3)高速性(Velocity)
这是大数据区分于传统数据挖掘最显著的特征。大数据与海量数据的重要区别在两方面:一方面,大数据的数据规模更大;另一方面,大数据对处理数据的响应速度有更严格的要求。实时分析而非批量分析,数据输入、处理与丢弃立刻见效,几乎无延迟。数据的增长速度和处理速度是大数据高速性的重要体现。
(4)价值性(Value)
尽管企业拥有大量数据,但是发挥价值的仅是其中非常小的部分。大数据背后潜藏的价值巨大。由于大数据中有价值的数据所占比例很小,而大数据真正的价值体现在从大量不相关的各种类型的数据中。挖掘出对未来趋势与模式预测分析有价值的数据,并通过机器学习方法、人工智能方法或数据挖掘方法深度分析,并运用于农业、金融、医疗等各个领域,以期创造更大的价值。
1.2 大数据数据源
大数据的来源,主要通过各种数据传感器、数据库、网站、移动App等产生大量的结构化和非结构化数据,互联网公司是天生的大数据公司,在搜索、社交、媒体、交易等各自核心业务领域,积累并持续产生海量数据.
例如:百度公司 阿里巴巴 腾讯公司
此外还有一些行业大数据,如电信、金融与保险、电力与石化、制造业、医疗、教育和交通运输等行业大数据。
数据从哪里来是我们评价大数据应用的重要指标,如果一个应用没有可靠的数据来源,再好、再高超的数据分析技术都是无本之木
1.3 大数据技术应用场景
大数据无处不在,大数据应用于各个行业,包括金融、汽车、餐饮、电信、能源、体能和娱乐等在内的社会各行各业都已经融入了大数据的印迹。
制造业,利用工业大数据提升制造业水平,包括产品故障诊断与预测、分析工艺流程、改进生产工艺,优化生产过程能耗、工业供应链分析与优化、生产计划与排程。
电商行业,零售行业可以利用大数据技术进行精准营销。
金融行业,大数据金融行业主要应用于,精准营销、风险管控、决策支持、效率提升、产品设计中发挥重大作用。
交通领域:通过交通数据分析,合理的规则出行道路,其次可以通过大数据分析人流高峰,调控信息灯,提高运行能力。
教育领域:可以收集学生的学习数据,优化教学过程,从而达到个性化教学;还可以通过数据分析优化学习方法,更好的提高成绩
汽车行业,利用大数据和物联网技术的无人驾驶汽车,在不远的未来将走入我们的日常生活。
互联网行业,借助于大数据技术,可以分析客户行为,进行商品推荐和针对性广告投放。
电信行业,利用大数据技术实现客户离网分析,及时掌握客户离网倾向,出台客户挽留措施。
能源行业,随着智能电网的发展,电力公司可以掌握海量的用户用电信息,利用大数据技术分析用户用电模式,可以改进电网运行,合理设计电力需求响应系统,确保电网运行安全。
物流行业,利用大数据优化物流网络,提高物流效率,降低物流成本。
城市管理,可以利用大数据实现智能交通、环保监测、城市规划和智能安防。
生物医学,大数据可以帮助我们实现流行病预测、智慧医疗、健康管理,同时还可以帮助我们解读
DNA,了解更多的生命奥秘。
体育娱乐,大数据可以帮助我们训练球队,决定投拍哪种题财的影视作品,以及预测比赛结果。
安全领域,政府可以利用大数据技术构建起强大的国家安全保障体系,企业可以利用大数据抵御网络攻击,警察可以借助大数据来预防犯罪。
个人生活, 大数据还可以应用于个人生活,利用与每个人相关联的“个人大数据”,分析个人生活行为习惯,为其提供更加周到的个性化服务。
大数据的价值,远远不止于此,大数据对各行各业的渗透,大大推动了社会生产和生活,未来必将产生重大而深远的影响。
1.4 大数据处理流程及技术
大数据处理流程,主要包括数据收集、数据预处理、数据存储、数据处理与分析、数据展示/数据可视化等环节,每一个数据处理环节都会对大数据质量产生影响.
通常一个好的大数据产品要有以下特征:
- 大量的数据规模;
- 快速的数据处理能力;
- 精确的数据分析与预测能力;
-
优秀的可视化图表以及简练易懂的结果解释
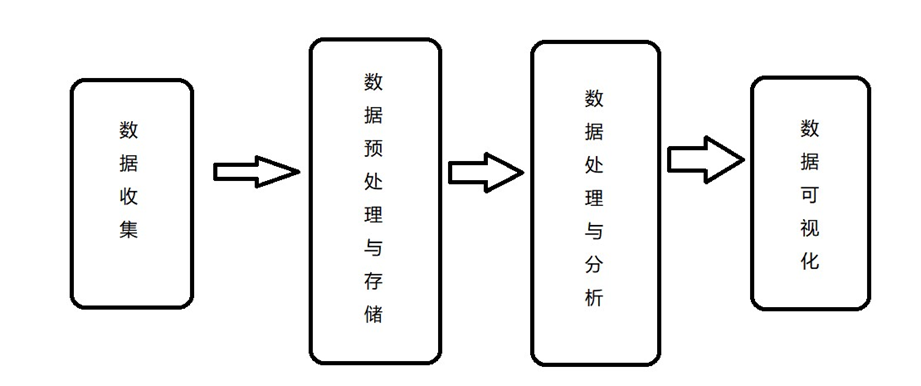

收集数据
大数据的采集指利用多个数据库来接收发自客户端(Web、App、或者传感器形式等)的数据,并且用户可以通过这些数据库来进行简单和处理工作,另外大数据的采集不是抽样,而是要求数据尽可能的完整和全面,尽量保证每一个数据的准确有用。
对于Web数据,多采用网络爬虫方式进行收集,这需要对爬虫软件进行时间设置以保障收集到的数据具有时效性,数据采集技术方式有:
Sqoop
日志采集工具(Flume、Kafka)等
数据预处理与存储
因为通过数据源收集的数据比较原始,价值密度低,所以会对收集的数据进行很多次清洗,将重复、无用、噪声、缺失和冲突的数据筛选掉。
大数据的预处理环节包括:
数据清理
主要就是初步对数据进行,不一致检测、噪声数据识别、数据过滤、修正等,进一步提高数据的准确性、真实性、可用性等
数据集成
就是将多个数据源的数据进行集成,从而形成集中、统一的数据库
数据归约
是指在不损害分析结果准确性的前提下,通过维归约、数量归约、数据抽样等技术,提高大数据存储的价值性
数据转换处理
通过转换实现数据统一、这一过程有利于提升大数据的一致性和可用性
大数据存储主要是利用分布式文件系统、数据仓库、关系数据库、NoSql数据库、云数据库等实现对结构化、半结构化、非结构化海量数据的存储和管理
数据处理与分析
数据处理
大数据处理模型有:
MapReduce分布式计算框架
是一个批处理的分布式计算框架,可对海量数据进行并行分析与处理,它适合对各种结构化、非结构化数据的处理。
Spark分布式内存计算系统
可有效减少数据读写和移动的开销,提高大数据处理性能。
Storm分布式流计算系统
对数据流进行实时处理,以保障大数据的时效性和价值性
大数据类型和存储形式决定了其所采用的数据处理系统,而数据处理系统的性能与优劣直接影响大数据质量的价值性、可用性、时效性、准确性。
数据分析
大数据分析技术主要包括已有数据的分布式统计分析技术和未知数据的分布式挖掘、深度学习技术。
分布式统计分析技术可由数据处理技术完成,分布式挖掘和深度学习技术则在大数据分析阶段完成
注意:
数据分析是大数据处理与应用的关键环节,它决定了大数据集合的价值性和可用性。
数据可视化与应用环节
数据可视化是指将大数据分析与预测结果以计算机图形或图像的直观方式显示给用户的过程,并可与用户进行交互式处理。
大数据应用是指将经过分析处理后挖掘得到的大数据结果应用于管理决策、战略规划等的过程,它是对大数据分析结果的检验与验证,大数据应用过程直接体现了大数据分析处理结果的价值性和可用性
1.5 大数据与云计算的关系
云计算: 是分布式计算的一种,指的是通过网络“云”将巨大的数据计算处理程序分解成无数个小程序,然后,通过多部服务器组成的系统进行处理和分析这些小程序得到结果并返回给用户
大数据与云计算的关系就像一枚硬币的正反面一样密不可分。大数据必然无法用单台的计算机进行处理,必须采用分布式计算架构。它的特色在于对海量数据的挖掘,但它必须依托云计算的分布式处理、分布式数据库、云存储和虚拟化技术
大数据是云计算非常重要的应用场景,而云计算则为大数据的处理和数据挖掘提供了最佳的技术解决方案
他俩之间的关系你可以这样来理解,云计算技术就是一个容器,大数据正是存放在这个容器中的水,大数据是要依靠云计算技术来进行存储和计算的。
1.6 大数据与人工智能的关系
人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等两者联系:
一方面,人工智能需要数据来建立其智能,特别是机器学习。
例如,机器学习图像识别应用程序可以查看数以万计的飞机图像,以了解飞机的构成,以便将来能够识别出它们。人工智能应用的数据越多,其获得的结果就越准确。在过去,人工智能由于处理器速度慢、数据量小而不能很好地工作。今天,大数据为人工智能提供了海量的数据,使得人工智能技术有了长足的发展,甚至可以说,没有大数据就没有人工智能。另一方面,大数据技术为人工智能提供了强大的存储能力和计算能力。
在过去,人工智能算法都是依赖于单机的存储和单机的算法,而在大数据时代,面对海量的数据,传统的单机存储和单机算法都已经无能为力,建立在集群技术之上的大数据技术(主要是分布式存储和分布式计算),可以为人工智能提供强大的存储能力和计算能力。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138633.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
