大家好,又见面了,我是你们的朋友全栈君。
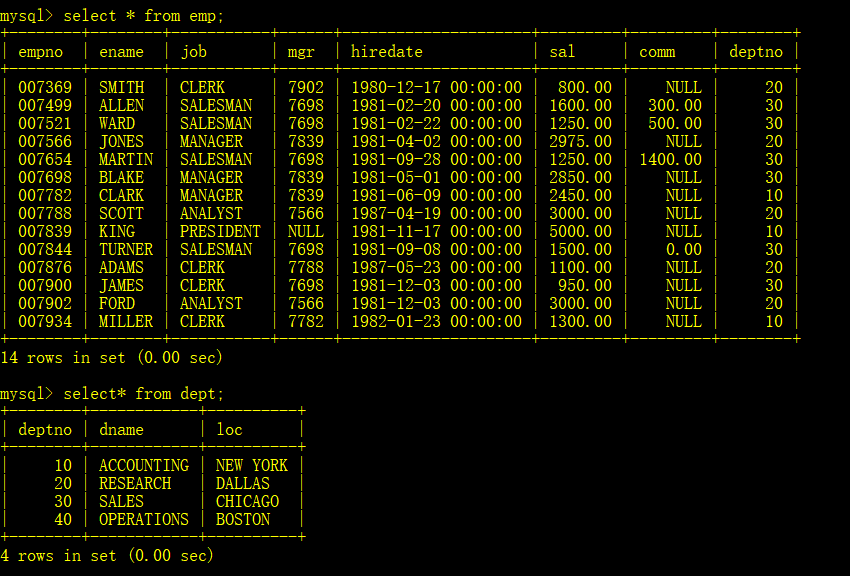
首先,为了方便说明问题,创建两个表emp(雇员信息)和dept(雇员部门信息),其数据如下:

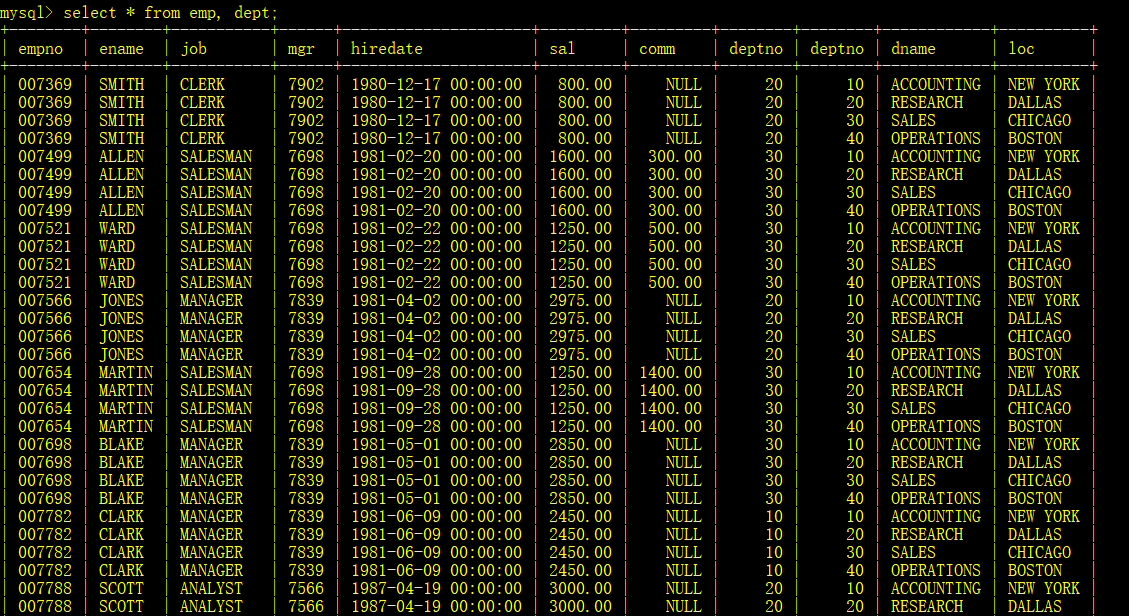
在之前的博客中,我们分享了单表查询的方法,但是在实际应用中,我们要查的数据很可能不在同一个表中,而是来自于不同的表。多表查询如果不加任何条件,得到的结果称为笛卡尔积。
例如,查找雇员名、雇员工资以及部门所在的名字。
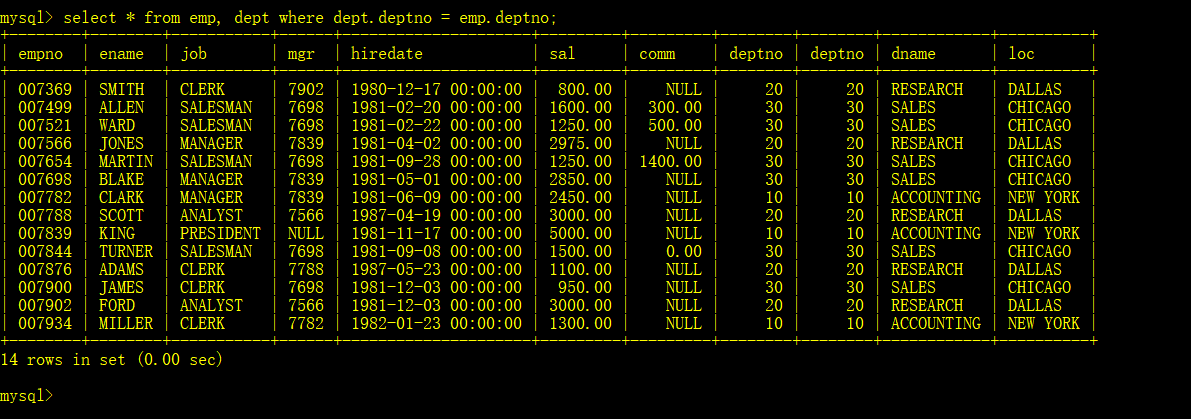
可以发现,结果是这样的,从第一个表中选出第一条记录,和第二个表中的所有所有记录进行组合,然后再从第一个表中取出第二条记录,和第二张表的所有记录进行组合,这样的结果是没有实际意义的。我们需要的是emp.deptno = dept.deptno字段的记录。
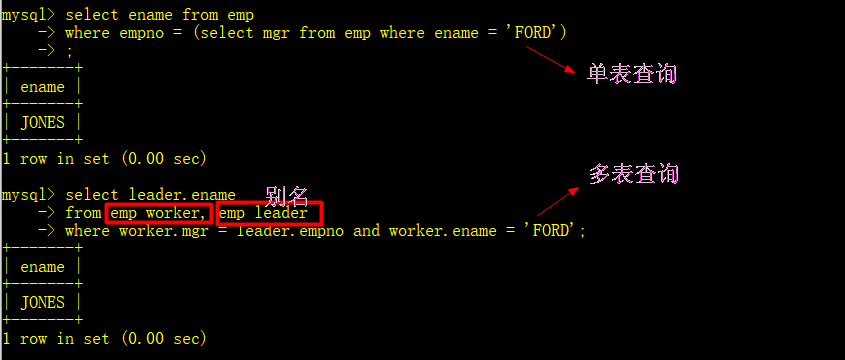
自连接
自连接是指在同一张表连接查询
- 显示员工FORD的上级领导的名字
子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。
单行子查询:子查询的查询结果只有一行
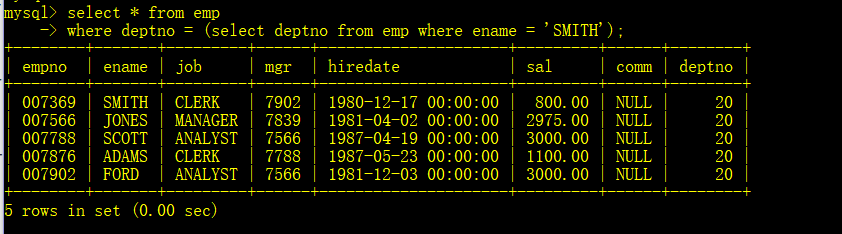
- 显示和SMITH同一部门的员工
多行子查询(in ,all, any):返回多条记录的子查询
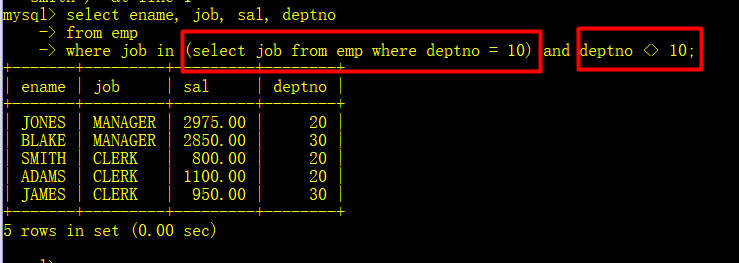
- 查询和10好部门的工作相同的官员的名字、工作、工资、部门号,但是不包括10号自己的信息
- 显示工资比部门编号为30的所有员工的工资高的员工的姓名、工资和部门号
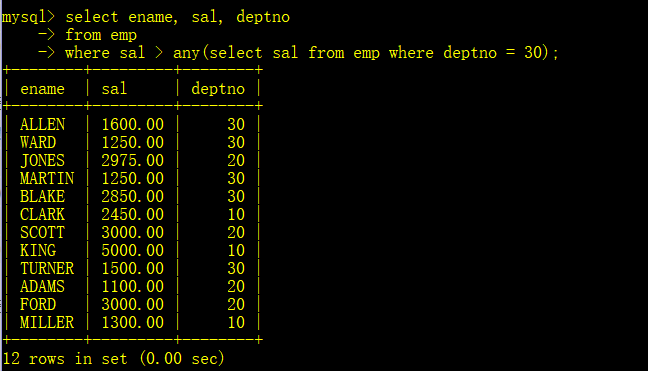
- 显示工资比部门编号为30的任意员工的工资高的员工的姓名、工资和部门号

多列子查询:查询返回多个列数据的子查询语句
- 查询和SMITH的部门和岗位完全相同的雇员,不含SMITH本人

from子句中使用子查询
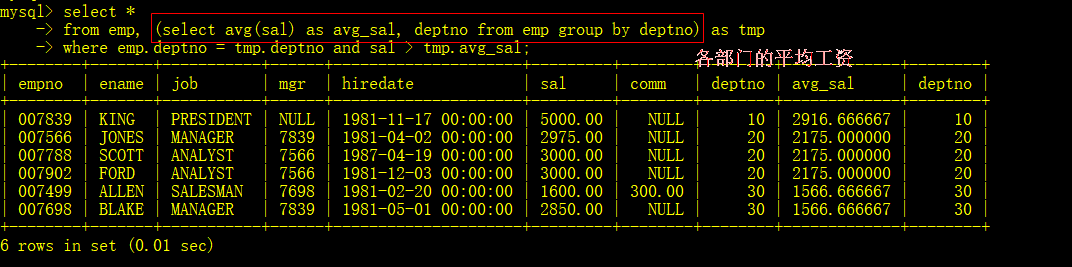
- 显示高于自己部门的平均工资的员工信息
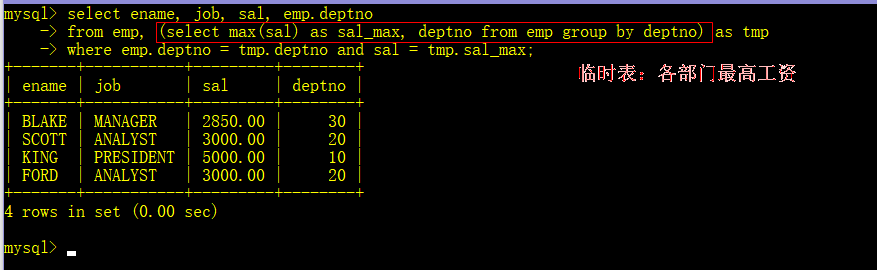
- 查找每个部门工资最高的人的ename, job, sal
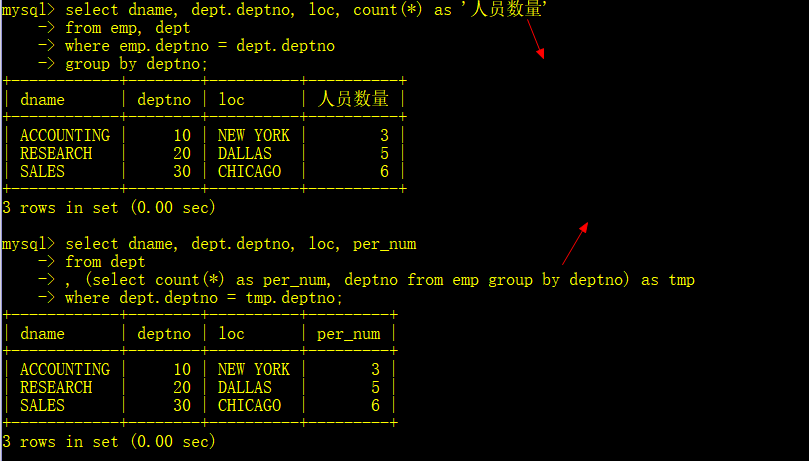
3.显示每个部门的信息(部门名、编号、地址)和人员数量
这里有两种方法可以使用,但是经验证,当数据非常多的时候from子查询的效率是高于多表查询的。
删除表中的重复记录
已知一个表tt中有重复的数据
- 创建一张空表tmp_tt,空表的结构与表tt的结构相同;
create table tmp_tt like tt; - 将tt表进行distinct,将数据导入空表中;
insert into tmp_tt select distinct * from tt; - 删除原表tt
drop table tt; - 将tmp_tt改名为tt
alter table tmp_tt rename tt;
合并查询
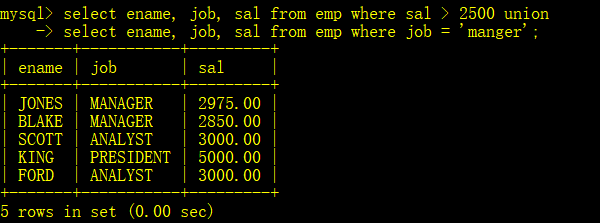
在实际应用中,为了合并多个select的执行结果,可以使用union,union all集合操作符
- union操作符用于取得两个结果的并集,并再自动去掉重复行
查找工资大于2500和职位Manger的人
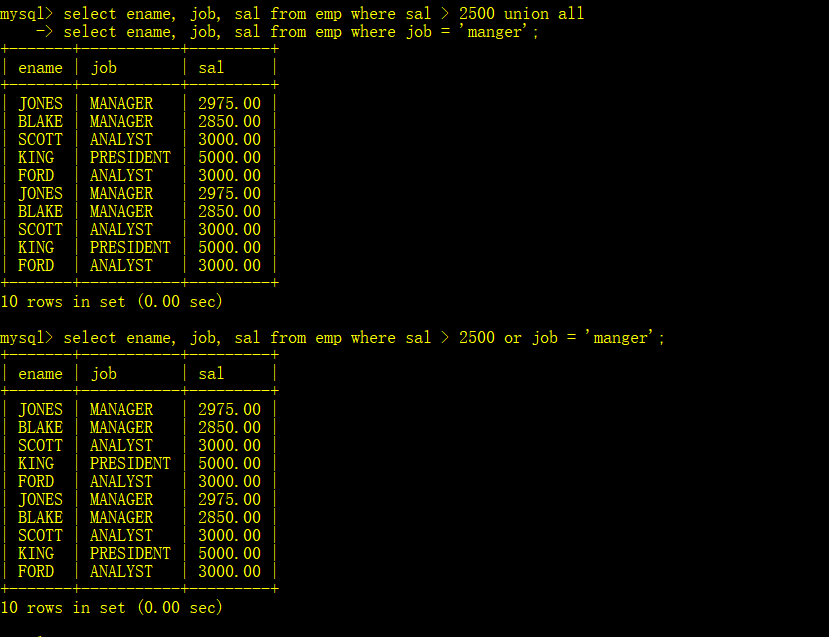
2. union all 与union类似,但是不会自动去重
例如:与or类似
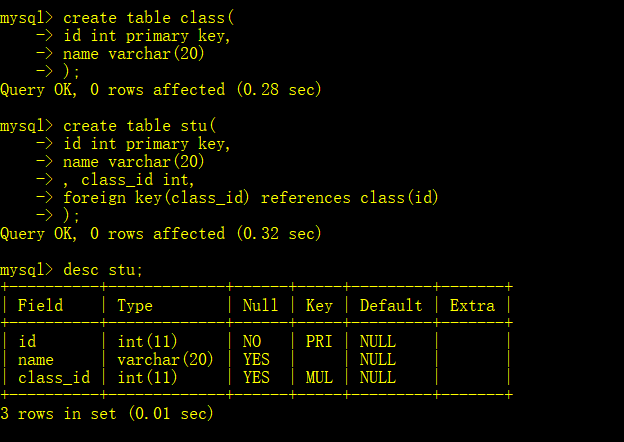
外键
外键定义主表和从表的关系,外键约束主要是定义在从表上,主表必须是有主键或者唯一键。当定义外键后,要求外键列数据必须在主表列存在或者为NULL。
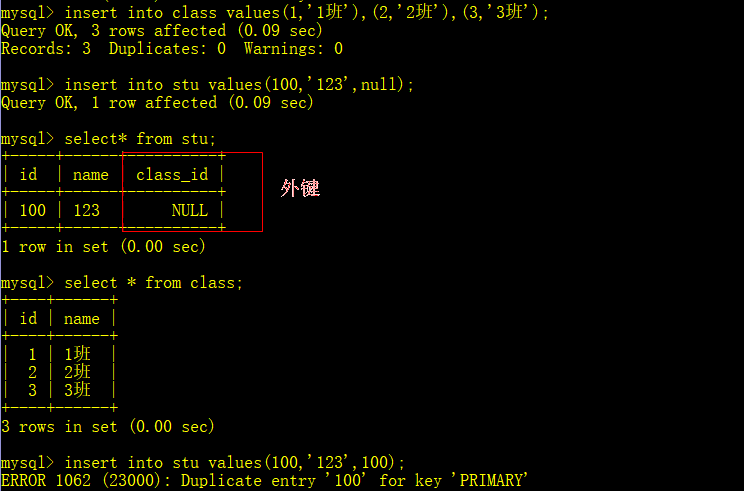
例如:创建一个主表class,从表stu
由上图,我们可以知道主键不能为null,但是外键可以为null,同时不能存在外键有的数据而主表中不存在。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/138356.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
