大家好,又见面了,我是你们的朋友全栈君。
之前文章目标检测API 已经介绍过API的基本使用,这里就不赘述了,直接上本次内容的代码了,添加的内容并不多。将测试的test.mp4原文件放到models-master\research\object_detection路径下,并创建一个detect_video.py文件,代码内容如下:
import os
import cv2
import time
import argparse
import multiprocessing
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt
import matplotlib
# Matplotlib chooses Xwindows backend by default.
matplotlib.use('Agg')
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
'''
视频目标追踪
'''
# Path to frozen detection graph. This is the actual model that is used for the object detection.
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
PATH_TO_CKPT = os.path.join(MODEL_NAME, 'frozen_inference_graph.pb')
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
def detect_objects(image_np, sess, detection_graph):
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
return image_np
#Load a frozen TF model
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
#import imageio
#imageio.plugins.ffmpeg.download()
# Import everything needed to edit/save/watch video clips
from moviepy.editor import VideoFileClip
from IPython.display import HTML
def process_image(image):
# NOTE: The output you return should be a color image (3 channel) for processing video below
# you should return the final output (image with lines are drawn on lanes)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
# 如果出现错误:ValueError: assignment destination is read-only,则将下面一行改为:
# image_process = detect_objects(np.array(image), sess, detection_graph)
image_process = detect_objects(image, sess, detection_graph)
return image_process
white_output = 'test_out.mp4'
clip1 = VideoFileClip("test.mp4").subclip(1,9)
white_clip = clip1.fl_image(process_image) #NOTE: this function expects color images!!s
white_clip.write_videofile(white_output, audio=False)
HTML("""
<video width="960" height="540" controls>
<source src="{0}">
</video>
""".format(white_output))
检测结果:

更新一个独立的检测现有视频脚本,这样可以方便在任意路径使用:
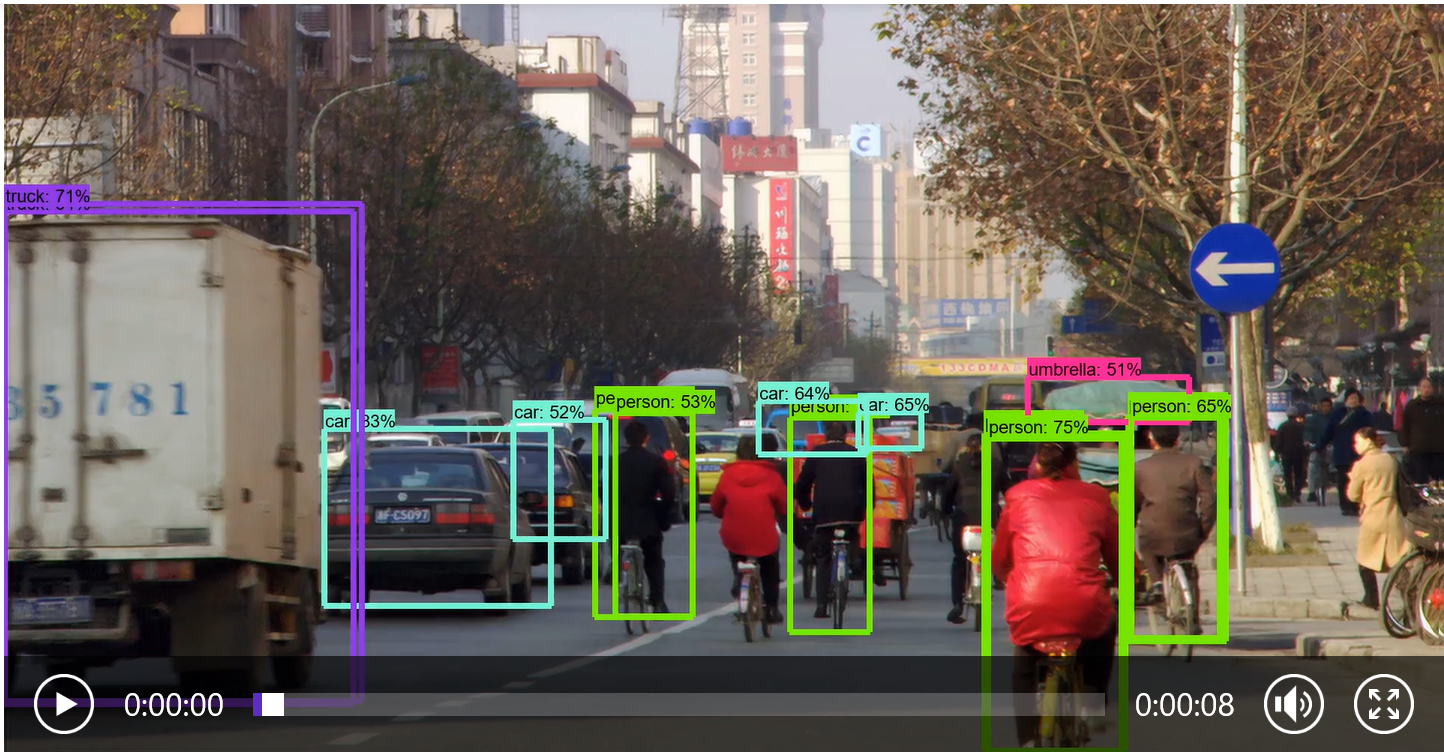
from moviepy.editor import VideoFileClip
from IPython.display import HTML
import tensorflow as tf
import cv2 as cv
import time
#Load a frozen TF model
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile('./frozen_inference_graph.pb', 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
def detect_objects(image, sess, detection_graph):
height = image.shape[0]
width = image.shape[1]
channel = image.shape[2]
start_time = time.time()
# Run the model
out = sess.run([sess.graph.get_tensor_by_name('num_detections:0'),
sess.graph.get_tensor_by_name('detection_scores:0'),
sess.graph.get_tensor_by_name('detection_boxes:0'),
sess.graph.get_tensor_by_name('detection_classes:0')],
feed_dict={'image_tensor:0': image.reshape(1, height, width, channel)})
end_time = time.time()
runtime = end_time - start_time
print('run time:%f' % (runtime * 1000) + 'ms')
# Visualize detected bounding boxes.
num_detections = int(out[0][0])
# Iterate through the number of checked out rectangular boxes on the picture
for i in range(num_detections):
classId = int(out[3][0][i])
score = float(out[1][0][i])
bbox = [float(v) for v in out[2][0][i]]
if score > 0.8: # 这里的阈值自行修改即可
#print(score)
x = bbox[1] * width
y = bbox[0] * height
right = bbox[3] * width
bottom = bbox[2] * height
# Draw rectangular box
font = cv.FONT_HERSHEY_SIMPLEX # Use default fonts
cv.rectangle(image, (int(x), int(y)), (int(right), int(bottom)), (0, 0, 255), thickness=2)
cv.putText(image, '{}:'.format(classId) + str(('%.3f' % score)), (int(x), int(y - 9)), font, 0.6,
(0, 0, 255), 1)
return image
def process_image(image):
# NOTE: The output you return should be a color image (3 channel) for processing video below
# you should return the final output (image with lines are drawn on lanes)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
image_process = detect_objects(image, sess, detection_graph)
return image_process
white_output = 'test_out.mp4'
# 使用 VideoFileClip 函数从视频中抓取图片,subclip(1,9)代表识别视频中1-9s这一时间段
clip1 = VideoFileClip("test.mp4").subclip(1,9)
# 用fl_image函数将原图片替换为修改后的图片,用于传递物体识别的每张抓取图片
white_clip = clip1.fl_image(process_image) #NOTE: this function expects color images!!
# 修改的剪辑图像被组合成为一个新的视频
white_clip.write_videofile(white_output, audio=False)
HTML("""
<video width="960" height="540" controls>
<source src="{0}">
</video>
""".format(white_output))
上面的对现有的视频中目标进行检测的,那么怎样实时的对现实生活中的目标进行检测呢?这个其实也很简单,我们来创建一个object_detection_tutorial_video.py 文件,具体的代码如下:
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
import matplotlib
import cv2
# Matplotlib chooses Xwindows backend by default.
matplotlib.use('Agg')
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
from utils import label_map_util
from utils import visualization_utils as vis_util
'''
检测视频中的目标
'''
cap = cv2.VideoCapture(0) #打开摄像头
##################### Download Model
# What model to download.
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90
# Download model if not already downloaded
if not os.path.exists(PATH_TO_CKPT):
print('Downloading model... (This may take over 5 minutes)')
opener = urllib.request.URLopener()
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
print('Extracting...')
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
else:
print('Model already downloaded.')
##################### Load a (frozen) Tensorflow model into memory.
print('Loading model...')
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
##################### Loading label map
print('Loading label map...')
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
##################### Helper code
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
##################### Detection ###########
print('Detecting...')
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
# print(TEST_IMAGE_PATH)
# image = Image.open(TEST_IMAGE_PATH)
# image_np = load_image_into_numpy_array(image)
while True:
ret, image_np = cap.read() #从摄像头中获取每一帧图像
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Print the results of a detection.
print(scores)
print(classes)
print(category_index)
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
cv2.imshow('object detection', cv2.resize(image_np, (800, 600)))
#cv2.waitKey(0)
if cv2.waitKey(25) & 0xFF == ord('q'):
cv2.destroyAllWindows()
break
代码中只是添加了摄像头来获取每一帧图像,处理方式和静态的图片差不多,这里就不多说了。这里就不上测试的结果了,大家课可以实际的跑一下程序即可看到结果。
更新 2020.05.04
更新一个单独运行的实时获取摄像头进行检测脚本:
import argparse
import tensorflow as tf
import numpy as np
import time
import cv2 as cv
'''
video det
use:
python Video.py \
--model=xxx.pb \
--threshold=0.65
'''
# os.environ['CUDA_VISIBLE_DEVICES'] = "0"
parser = argparse.ArgumentParser('TensorFlow')
parser.add_argument('--model', required=True, help='pb file')
parser.add_argument('--threshold', type=float, required=True, help='Detection threshold')
args = parser.parse_args()
# open camera
cap = cv.VideoCapture(0)
if not cap.isOpened():
print("cannot open camera")
exit()
# Read the graph.
with tf.gfile.FastGFile(args.model, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
config.gpu_options.allow_growth = True
with tf.Session(config=config) as sess:
# Restore session
sess.graph.as_default()
tf.import_graph_def(graph_def, name='')
while True:
ret, image_np = cap.read()
if not ret:
print("Cant't receive frame. Exiting....")
break
height = image_np.shape[0]
width = image_np.shape[1]
channel = image_np.shape[2]
image_np_expanded = np.expand_dims(image_np, axis=0)
start_time = time.time()
# Run the model
out = sess.run([sess.graph.get_tensor_by_name('num_detections:0'),
sess.graph.get_tensor_by_name('detection_scores:0'),
sess.graph.get_tensor_by_name('detection_boxes:0'),
sess.graph.get_tensor_by_name('detection_classes:0')],
feed_dict={'image_tensor:0': image_np_expanded})
end_time = time.time()
runtime = end_time - start_time
print('run time:%f' % (runtime * 1000) + 'ms')
# Visualize detected bounding boxes.
num_detections = int(out[0][0])
for i in range(num_detections):
classId = int(out[3][0][i])
score = float(out[1][0][i])
bbox = [float(v) for v in out[2][0][i]]
if score > args.threshold:
x = bbox[1] * width
y = bbox[0] * height
right = bbox[3] * width
bottom = bbox[2] * height
# draw boxes
font = cv.FONT_HERSHEY_SIMPLEX
cv.rectangle(image_np, (int(x), int(y)), (int(right), int(bottom)), (0, 0, 255), thickness=2)
cv.putText(image_np, '{}:'.format(classId) + str(('%.3f' % score)), (int(x), int(y - 9)), font, 0.6,
(0, 0, 255), 1)
cv.imshow('object detection', cv.resize(image_np, (800, 600)))
if cv.waitKey(1) == ord('q'):
break
cap.release()
cv.destroyAllWindows()
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132180.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
