大家好,又见面了,我是你们的朋友全栈君。
The Google File System
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.125.789&rep=rep1&type=pdf
http://www.dbthink.com/?p=501, 中文翻译
Google牛人云集的地方, 但在设计系统时, 却非常务实, 没有采用什么复杂和时髦的算法和机制
设计大型系统, 最重要的就是, 简单和可靠, 复杂就意味着失控…
在设计GFS, 首先一个选择就是, 中心化或去中心化
Google选择了传统而保守的中心化策略, 而没有选择更漂亮的去中心化算法, 就是出于设计的简单性考虑
而去中心化的设计在很多方面都要复杂的多, 大家可以参考dynamo的设计
中心化设计, 好处就是简单, 可以把所有metadata都放到master, 所有的系统的控制, 恢复等都可以依赖master…
问题当然也是很明显的, 就是过于依赖master, 所以现在大家也在研究去中心化的设计, 可具有扩展性, 看上去也更美…
1. master负载过重问题
对于GFS, client的数量是huge的, 如果每次client的请求都要通过master, 所有数据都经过master得到, 可想而知, master的负载肯定overhead
所以Google的设计是, client尽可能少的访问master
a. 控制流和数据流分开, client只从master上获取metadata和控制request, 而直接去和chunkserver交换数据
b. client cache, 只有发现metadata变化了, 才需要从新连接master
2. master单点问题
首先master最重要的是metadata, google通过log来进行备份, log必须同时在本地和远程多处备份成功, 对metadata的修改才生效
为了防止log过大, recover的效率太低, 还会定期对metadata经行checkpoint, log和checkpoint都需要多replicas存储来保证不丢失
这样当master crash, 我们只需要新选择一个有完整log的server, 把master启动起来并recover metadata, 就ok了
并且还有只读的shadow masters, 当master down的时候还可以继续提供read服务
第二个问题就是数据一致性问题
一致性问题, 分布式系统必须要考虑一致性问题, GFS选择中心化, 所以在解决一致性问题上比较简单, 可以指定一个primary来协调和保证多replicas以相同的顺序经行更新(primary的指定使用lease机制来保证). 当更新中, 某些replica更新失败导致的不一致情况, 通过chunk版本来detect并由master来recover. 从而有效的解决各复本间内容不一致的问题.
但还有个问题没有解决, 当write比较大的时候, 会被拆分成多个更新请求, 而这儿无法保证这多个更新请求之间, 不被其他的并发写所干扰, 很有可能其他的并发写覆盖了之前的更新, 导致用户最终看到的结果和预期不一致. 所以除了consistent(所有replica一致), GFS还有defined的概念(用户最终看到的改动和他预想的一致, 即原子性, 因为并发写的情况下, client间会有干扰写)
怎么解决这个问题?
Google的答案很务实, GFS的特点就是支持批量append和顺序读
所以只有在append的情况下可以保证, defined, 而随机write, 无法保证.
为什么append可以保证defined?
因为GFS可以保证所有append操作的都是原子的, 有效的避免多个并发client从同一个offset开始write
而且append不会覆盖老数据, 所以用户总是可以在最终看到他写入的所有数据
Storm的作者在how to beat CAP中也是提出这样的模型, 数据不可变, 当不支持随机update操作时, 数据库的设计将被大大简化.
而去中心化的方案, 如dynamo, 一致性问题机制就比较复杂, 各个replica的更新顺序不一样, 需要通过时间向量来记录更新的因果关系, 并在产生冲突的时候, 需要client来最终仲裁.
其他问题的设计
A. chunk and metadata
在GFS中, chunk就是64M的linux file, 很简单
而metadata, 为了提高效率会加载在内存中, 其中namespaces and file-to-chunk mapping, 比较固定的, 不会经常变的, stored on the master’s local disk and replicated on remote machines
而对于chunk location, 则是在Master启动或chunk server加入的时候, 动态生成. 为什么这样做? 更简单, 更不容易出错
B. lease机制
这是基于中心化设计的机制, GFS通过这个机制保证所有replica的一致性
While control flows from the client to the primary and then to all secondaries, data is pushed linearly along a carefully picked chain of chunkservers in a pipelined fashion.
同时, 由于lease必须由master来赋予, 所以master可以借lease更好的实现控制, 比如, chunk的版本增加, snapshot hard copy
C. 数据delete和垃圾回收
When a file is deleted by the application, the master logs the deletion immediately just like other changes. However instead of reclaiming resources immediately, the file is just renamed to a hidden name that includes the deletion timestamp.
删除数据时, 不立刻删除, 而是把file改名, 后面在后台集中垃圾回收. 优点就是简单可靠, 防误删除, 缺点就是多占点空间.
实时删除数据, 对数据库的效率和逻辑复杂度影响比较大, 所以很多系统都采用这样的策略…
D. Snapshot的创建
Copy-on-write (sometimes referred to as “COW”) is an optimization strategy used in computer programming.
为了提高效率使用COW, master在收到某chunk的snapshot请求时, 会先取消该chunk的lease. 目的就是为了, 下次更新一定要经过master, 这样master才有机会做真正的copy.
E. 命名空间管理和lock
通过分析GFS的设计, 我想说的就是大道至简…
1. INTRODUCTION
We have designed and implemented the Google File System (GFS) to meet the rapidly growing demands of Google’s data processing needs.
GFS shares many of the same goals as previous distributed file systems such as performance, scalability, reliability, and availability.
However, its design has been driven by key observations of our application workloads and technological environment, both current and anticipated, that reflect a marked departure from some earlier file system design assumptions. We have reexamined traditional choices and explored radically different points in the design space.
为什么要设计GFS? 他和之前的分布式file system比, 需要面对新的需求, 新的目标
First, component failures are the norm rather than the exception.
The file system consists of hundreds or even thousands of storage machines built from inexpensive commodity parts and is accessed by a comparable number of client machines. The quantity and quality of the components virtually guarantee that some are not functional at any given time and some will not recover from their current failures. We have seen problems caused by application bugs, operating system bugs, human errors, and the failures of disks, memory, connectors, networking, and power supplies.
Therefore, constant monitoring, error detection, fault tolerance, and automatic recovery must be integral to the system.
Second, files are huge by traditional standards.
Multi-GB files are common. Each file typically contains many application objects such as web documents. When we are regularly working with fast growing data sets of many TBs comprising billions of objects, it is unwieldy to manage billions of approximately KB-sized files even when the file system could support it.
As a result, design assumptions and parameters such as I/O operation and blocksizes have to be revisited.
Third, most files are mutated by appending new data rather than overwriting existing data.
Random writes within a file are practically non-existent. Once written, the files are only read, and often only sequentially.
A variety of data share these characteristics. Some may constitute large repositories that data analysis programs scan through. Some may be data streams continuously generated by running applications. Given this access pattern on huge files, appending becomes the focus of performance optimization and atomicity guarantees, while caching data blocks in the client loses its appeal.
Fourth, co-designing the applications and the file system API benefits the overall system by increasing our flexibility. 应用程序和文件系统API的协同设计提高了整个系统的灵活性
For example, we have relaxed GFS’s consistency model to vastly simplify the file system without imposing an onerous burden on the applications. We have also introduced an atomic append operation so that multiple clients can append concurrently to a file without extra synchronization between them.
2. DESIGN OVERVIEW
2.1 Assumptions
In designing a file system for our needs, we have been guided by assumptions that offer both challenges and opportunities.
We alluded to some key observations earlier and now lay out our assumptions in more details.
设计GFS的需求和前提假设
• The system is built from many inexpensive commodity components that often fail. It must constantly monitor itself and detect, tolerate, and recover promptly from component failures on a routine basis.
• The system stores a modest number (适当数量) of large files. We expect a few million files, each typically 100 MB or larger in size. Multi-GB files are the common case and should be managed efficiently. Small files must be supported, but we need not optimize for them.
• The workloads primarily consist of two kinds of reads: large streaming reads and small random reads.
In large streaming reads, individual operations typically read hundreds of KBs, more commonly 1 MB or more. Successive operations from the same client often read through a contiguous region of a file. A small random read typically reads a few KBs at some arbitrary offset. Performance-conscious applications often batch and sort their small reads to advance steadily through the file rather than go back and forth. 把小规模的随机读取操作合并并排序,之后按顺序批量读取,这样就避免了在文件中前后来回的移动读取位置. GFS应用场景不是随机读, 而是海量的append和顺序读
• The workloads also have many large, sequential writes that append data to files. Typical operation sizes are similar to those for reads. Once written, files are seldom modified again. Small writes at arbitrary positions in a file are supported but do not have to be efficient. 许多大规模的、顺序的、数据追加方式的写操作.数据一旦被写入后,文件就很少会被修改.
• The system must efficiently implement well-defined semantics for multiple clients that concurrently append to the same file. Our files are often used as producerconsumer queues or for many-way merging. Hundreds of producers, running one per machine, will concurrently append to a file. Atomicity with minimal synchronization overhead is essential. The file may be read later, or a consumer may be reading through the file simultaneously. 高效的实现多客户端并行追加同一文件
• High sustained bandwidth is more important than low latency. Most of our target applications place a premium on processing data in bulk at a high rate, while few have stringent response time requirements for an individual read or write. 只需要保证总体上带宽的稳定和高速, 并不去苛求个别读写请求的绝对的响应时间
2.2 Interface
GFS provides a familiar file system interface, though it does not implement a standard API such as POSIX. Files are organized hierarchically in directories and identified by pathnames.
We support the usual operations to create, delete, open, close, read, and write files.
Moreover, GFS has snapshot and record append operations. Snapshot creates a copy of a file or a directory tree at low cost. Record append allows multiple clients to append data to the same file concurrently while guaranteeing the atomicity of each individual client’s append.
2.3 Architecture
A GFS cluster consists of a single master and multiple chunkservers and is accessed by multiple clients, as shown in Figure 1. Each of these is typically a commodity Linux machine running a user-level server process. 图中可以看出, 数据流和控制流分开的设计, 这样大大减轻了master的负担


Files are divided into fixed-size chunks. Each chunk is identified by an immutable and globally unique 64 bit chunk handle assigned by the master at the time of chunk creation.
Chunkservers store chunks on local disks as Linux files and read or write chunk data specified by a chunk handle and byte range.
For reliability, each chunk is replicated on multiple chunkservers. By default, we store three replicas, though users can designate different replication levels for different
regions of the file namespace.
The master maintains all file system metadata. This includes the namespace, access control information, the mapping from files to chunks, and the current locations of chunks.
The master also controls system-wide activities such as chunk lease management, garbage collection of orphaned chunks, and chunk migration between chunkservers.
The master periodically communicates with each chunkserver in HeartBeat messages to give it instructions and collect its state.
GFS client code linked into each application implements the file system API and communicates with the master and chunkservers to read or write data on behalf of the application.
Clients interact with the master for metadata operations, but all data-bearing communication goes directly to the chunkservers. We do not provide the POSIX API and therefore need not hook into the Linux vnode layer.
Neither the client nor the chunkserver caches file data.
Client caches offer little benefit because most applications stream through huge files or have working sets too large to be cached. Not having them simplifies the client and the overall system by eliminating cache coherence issues. (Clients do cache metadata, however.) 客户端只cache metadata, 而不去cache真正的数据, 因为大量的huge file的顺序读
Chunkservers need not cache file data because chunks are stored as local files and so Linux’s buffer cache already keeps frequently accessed data in memory.
2.4 Single Master
Having a single master vastly simplifies our design and enables the master to make sophisticated chunk placement and replication decisions using global knowledge.
However, we must minimize its involvement in reads and writes so that it does not become a bottleneck. Clients never read and write file data through the master. Instead, a client asks
the master which chunkservers it should contact. It caches this information for a limited time and interacts with the chunkservers directly for many subsequent operations.
Client和Master之间仅仅是获取metadata, 并且client还会对metadata做cache, 尽量减少对master节点的负担
Let us explain the interactions for a simple read with reference to Figure 1.
First, using the fixed chunk size, the client translates the file name and byte offset specified by the application into a chunk index within the file.
Then, it sends the master a request containing the file name and chunk index. The master replies with the corresponding chunk handle and locations of the replicas.
The client caches this information using the file name and chunk index as the key.
The client then sends a request to one of the replicas, most likely the closest one. The request specifies the chunk handle and a byte range within that chunk.
Further reads of the same chunk require no more client-master interaction until the cached information expires or the file is reopened.
2.5 Chunk Size
Chunk size is one of the key design parameters. We have chosen 64 MB, which is much larger than typical file system block sizes. Each chunk replica is stored as a plain Linux file on a chunkserver and is extended only as needed. Lazy space allocation avoids wasting space due to internal fragmentation, perhaps the greatest objection against such a large chunksize.
How does lazy space allocation avoid internal fragmentation in Google File System?
XFS makes use of lazy evaluation techniques for file allocation. When a file is written to the buffer cache, rather than allocating extents for the data, XFS simply reserves the appropriate number of file system blocks for the data held in memory. The actual block allocation occurs only when the data is finally flushed to disk. This improves the chance that the file will be written in a contiguous group of blocks, reducing fragmentation problems and increasing performance. Reference : http://en.wikipedia.org/wiki/XFS…
我个人的理解就是, block大了, 如果存的数据没有那么大, 就会浪费剩下的空间, 产生fragmentation, 这也是为什么传统的文件系统, block size设那么小的原因, 而GFS通过lazy space allocation解决了这个问题.
A large chunksize offers several important advantages. 为什么要采用large chunksize ?
First, it reduces clients’ need to interact with the master because reads and writes on the same chunk require only one initial request to the master for chunk location information. The reduction is especially significant for our workloads because applications mostly read and write large files sequentially. Even for small random reads, the client can comfortably cache all the chunk location information for a multi-TB working set.
Second, since on a large chunk, a client is more likely to perform many operations on a given chunk, it can reduce network overhead by keeping a persistent TCP connection to the chunkserver over an extended period of time. chunk比较大, 所以client更有可能对一个chunk进行多次操作, 这样维持一个TCP, 比频繁在各个chunkserver之间切换connection要高效
Third, it reduces the size of the metadata stored on the master. This allows us to keep the metadata in memory, which in turn brings other advantages that we will discuss in Section 2.6.1.
On the other hand, a large chunk size, even with lazy space allocation, has its disadvantages.
A small file consists of a small number of chunks, perhaps just one. The chunkservers storing those chunks may become hot spots if many clients are accessing the same file.
In practice, hot spots have not been a major issue because our applications mostly read large multi-chunk files sequentially.
However, hot spots did develop when GFS was first used by a batch-queue system:
an executable was written to GFS as a single-chunk file and then started on hundreds of machines at the same time. The few chunkservers storing this executable were overloaded by hundreds of simultaneous requests. We fixed this problem by storing such executables with a higher replication factor and by making the batchqueue system stagger application start times. A potential longterm solution is to allow clients to read data from other clients in such situations.
large chunksize 的问题就是会导致热点问题, 如果在短时间某文件被大量的client server访问, 就会导致该chunkserver的overload
作者提到的解决办法, 就是增加复本数. longterm solution, 从其他client读数据, 这个有点复杂了…
chunksize的大小没有好坏之分, 只不过根据GFS的假设和面对的需求, 设大点更合适一些…
64MB – Much Larger than ordinary, why?
–Advantages
•Reduce client-master interaction
•Reduce network overhead
•Reduce the size of the metadata
–Disadvantages
•Internal fragmentation
–Solution: lazy space allocation
•Hot Spots – many clients accessing a 1-chunk file, e.g. executables
–Solution:
–Higher replication factor
–Stagger application start times
–Client-to-client communication
2.6 Metadata
The master stores three major types of metadata: the file and chunk namespaces, the mapping from files to chunks, and the locations of each chunk’s replicas.
All metadata is kept in the master’s memory.
The first two types (namespaces and file-to-chunk mapping) are also kept persistent by logging mutations to an operation log stored on the master’s local disk and replicated on remote machines. Using a log allows us to update the master state simply, reliably, and without risking inconsistencies in the event of a master crash.
The master does not store chunk location information persistently. Instead, it asks each chunkserver about its chunks at master startup and whenever a chunkserver joins the cluster.
Chunk location信息是在master startup的时候动态生成的, 而没有象其他metadata一样做磁盘上的persistent, 为什么? 2.6.2回答
2.6.1 In-Memory Data Structures
Since metadata is stored in memory, master operations are fast.
Furthermore, it is easy and efficient for the master to periodically scan through its entire state in the background.
This periodic scanning is used to implement chunk garbage collection, re-replication in the presence of chunkserver failures, and chunk migration to balance load and disk space usage across chunkservers. Sections 4.3 and 4.4 will discuss these activities further.
One potential concern for this memory-only approach is that the number of chunks and hence the capacity of the whole system is limited by how much memory the master has. This is not a serious limitation in practice.
The master maintains less than 64 bytes of metadata for each 64 MB chunk. Most chunks are full because most files contain many chunks, only the last of which may be partially filled.
Similarly, the file namespace data typically requires less then 64 bytes per file because it stores file names compactly using prefix compression.
If necessary to support even larger file systems, the cost of adding extra memory to the master is a small price to pay for the simplicity, reliability, performance, and flexibility we gain by storing the metadata in memory.
放内存里面, 好处就是效率高, 速度快…
缺点就是, 内容多了, 内存有放不下的风险…作者说在实际使用中这个问题不严重
2.6.2 Chunk Locations
The master does not keep a persistent record of which chunkservers have a replica of a given chunk. It simply polls chunkservers for that information at startup.
The master can keep itself up-to-date thereafter because it controls all chunk placement and monitors chunkserver status with regular HeartBeat messages.
We initially attempted to keep chunk location information persistently at the master, but we decided that it was much simpler to request the data from chunkservers at startup, and periodically thereafter. This eliminated the problem of keeping the master and chunkservers in sync as chunkservers join and leave the cluster, change names, fail, restart, and so on. In a cluster with hundreds of servers, these events happen all too often.
Another way to understand this design decision is to realize that a chunkserver has the final word over what chunks it does or does not have on its own disks. There is no point in trying to maintain a consistent view of this information on the master because errors on a chunkserver may cause chunks to vanish spontaneously (e.g., a disk may go bad and be disabled) or an operator may rename a chunkserver.
2.6.3 Operation Log
The operation log contains a historical record of critical metadata changes. It is central to GFS. Not only is it the only persistent record of metadata, but it also serves as a logical time line that defines the order of concurrent operations. Files and chunks, as well as their versions (see Section 4.5), are all uniquely and eternally identified by the logical times at which they were created.
为什么要operation log? 因为GFS默认是在不稳定的环境中, 而且metadata是存在memory中的, 如果master发生crash, 导致metadata数据丢失, 对系统会有很大影响.
所以增加log来记录metadata的change, 以便于发生问题时, 进行recovery.
这是个典型的设计, 在SSTable中也是使用类似的机制
Since the operation log is critical, we must store it reliably and not make changes visible to clients until metadata changes are made persistent.
Therefore, we replicate it on multiple remote machines and respond to a client operation only after flushing the corresponding log record to disk both locally and remotely.
The master batches several log records together before flushing thereby reducing the impact of flushing and replication on overall system throughput.
The master recovers its file system state by replaying the operation log.
To minimize startup time, we must keep the log small. The master checkpoints(snapshot) its state whenever the log grows beyond a certain size so that it can recover by loading the latest checkpoint from local disk and replaying only the limited number of log records after that.
The checkpoint is in a compact B-tree like form that can be directly mapped into memory and used for namespace lookup without extra parsing. This further speeds up recovery and improves availability. Because building a checkpoint can take a while, the master’s internal state is structured in such a way that a new checkpoint can be created without delaying incoming mutations.
Recovery needs only the latest complete checkpoint and subsequent log files. Older checkpoints and log files can be freely deleted, though we keep a few around to guard against catastrophes. A failure during checkpointing does not affect correctness because the recovery code detects and skips incomplete checkpoints.
优化策略, 防止log file过大, 定时做下checkpoint snapshot, 然后老的log就可以清除, 下次recover时, 可以基于最新的checkpoint进行recover.
2.7 Consistency Model
GFS has a relaxed consistency model that supports our highly distributed applications well but remains relatively simple and efficient to implement.
We now discuss GFS’s guarantees and what they mean to applications. We also highlight how GFS maintains these guarantees but leave the details to other parts of the paper.
2.7.1 Guarantees by GFS
File namespace mutations (e.g., file creation) are atomic.
They are handled exclusively by the master: namespace locking guarantees atomicity and correctness (Section 4.1); the master’s operation log defines a global total order of these operations (Section 2.6.3).
The state of a file region after a data mutation depends on the type of mutation, whether it succeeds or fails, and whether there are concurrent mutations. Table 1 summarizes the result.
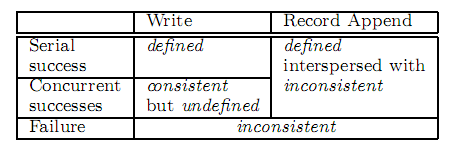
A file region is consistent if all clients will always see the same data, regardless of which replicas they read from.
A region is defined after a file data mutation if it is consistent and clients will see what the mutation writes in its entirety.
Defined的定义, 首先要一致, 而且改动能全部被client看到, 参考3.1的例子,比较好理解
Data mutations may be writes or record appends.
A write causes data to be written at an application-specified file offset.
A record append causes data (the “record”) to be appended atomically at least once even in the presence of concurrent mutations, but at an offset of GFS’s choosing (Section 3.3). (In contrast, a “regular” append is merely a write at an offset that the client believes to be the current end of file.) The offset is returned to the client and marks the beginning of a defined region that contains the record.
In addition, GFS may insert padding or record duplicates in between. They occupy regions considered to be inconsistent and are typically dwarfed by the amount of user data.
After a sequence of successful mutations, the mutated file region is guaranteed to be defined and contain the data written by the last mutation. (GFS确保被修改的文件region是已定义的,并且包含最后一次修改操作写入的数据), how to?
(a) applying mutations to a chunk in the same order on all its replicas (Section 3.1)
(b) using chunk version numbers to detect any replica that has become stale because it has missed mutations while its chunkserver was down (Section 4.5). Stale replicas will never be involved in a mutation or given to clients asking the master for chunk locations. They are garbage collected at the earliest opportunity.
Long after a successful mutation, component failures can of course still corrupt or destroy data. GFS identifies failed chunkservers by regular handshakes between master and all chunkservers and detects data corruption by checksumming (Section 5.2). Once a problem surfaces, the data is restored from valid replicas as soon as possible (Section 4.3). A chunk is lost irreversibly only if all its replicas are lost before GFS can react, typically within minutes. Even in this case, it becomes unavailable, not corrupted: applications receive clear errors rather than corrupt data.
2.7这部分比较难理解, 这部分应该放到后面去说, 我的理解是
File namespace的改动是原子的, 通过namespace locking来保证
File本身的改动后的状态取决于改动的类型, 接着给张表列出改动的类型
串行肯定没问题, 都是defined,
失败也没问题, 失败后必然会不一致, 因为某些replica没有更新成功, 某些成功
并行write, 一致但undefined, 为什么? 3.1解释了
最重要的是, GFS可以保证append操作达到Defined, interspersed with inconsistent (为什么interspersed with inconsistent ?参考3.3)
因为GFS设计的假设就是, 绝大部分的更新都是append, 所以后面写“经过了一系列的成功的修改操作之后,GFS确保被修改的文件region是已定义的”
2.7.2 Implications for Applications
GFS applications can accommodate the relaxed consistency model with a few simple techniques already needed for other purposes: relying on appends rather than overwrites, checkpointing, and writing self-validating, self-identifying records.
GFS采用简单的relaxed consistency model, application怎么样来应对relaxed consistency model带来的问题了?
最重要的是relying on appends, GFS的策略对append是可以达到defined, 而对于write只能达到consistent
Practically all our applications mutate files by appending rather than overwriting.
In one typical use, a writer generates a file from beginning to end. It atomically renames the file to a permanent name after writing all the data, or periodically checkpoints how much has been successfully written. Checkpoints may also include application-level checksums. Readers verify and process only the file region up to the last checkpoint, which is known to be in the defined state. Regardless of consistency and concurrency issues, this approach has served us well. Appending is far more efficient and more resilient to application failures than random writes. Checkpointing allows writers to restart incrementally and keeps readers from processing successfully written file data that is still incomplete from the application’s perspective.
In the other typical use, many writers concurrently append to a file for merged results or as a producer-consumer queue. Record append’s append-at-least-once semantics preserves each writer’s output. Readers deal with the occasional padding and duplicates(怎样处理interspersed with inconsistent ) as follows.
Each record prepared by the writer contains extra information like checksums so that its validity can be verified. A reader can identify and discard extra padding and record fragments using the checksums. If it cannot tolerate the occasional duplicates (e.g., if they would trigger non-idempotent operations), it can filter them out using unique identifiers in the records, which are often needed anyway to name corresponding application entities such as web documents. These functionalities for record I/O (except duplicate removal) are in library code shared by our applications and applicable to other file interface implementations at Google. With that, the same sequence of records, plus rare duplicates, is always delivered to the record reader.
3. SYSTEM INTERACTIONS
We designed the system to minimize the master’s involvement in all operations. With that background, we now describe how the client, master, and chunkservers interact to implement data mutations, atomic record append, and snapshot.
3.1 Leases (租约) and Mutation Order
A mutation is an operation that changes the contents or metadata of a chunk such as a write or an append operation. Each mutation is performed at all the chunk’s replicas.
为什么需要lease? 为了保证各replicas间consistent mutation order.
这个是分布式的根本问题, 保证了各个replicas的执行序列一致, 也就保证了状态的一致性, 对于去中心化的设计就需要考虑Paxos
为什么要保证mutation order? 上面说了确保被修改文件为defined
怎么样通过lease保证各replicas间consistent mutation order?
Master选定该chunk的primary replica, 并grant lease, 然后primary指定serial order for all mutations, 其他replicas都follow
The master grants a chunklease to one of the replicas, which we call the primary. The primary picks a serial order for all mutations to the chunk.
All replicas follow this order when applying mutations.
lease关键在于timeout time, 默认是60s. 如果chunk被更新, timeout时间会被延长
为什么不直接固定一个primary, 而要用lease机制?
我认为, 增加随机性, 防止某些server overhead, 一次lease有效期只有60s, 当然出于效率考虑, 防止master频繁set primary, 所以当有持续更新时, 可以申请延长timeout时间.
更主要的是, 在不稳定环境中, 防止primary crash, 因为primary只能有一个, 如果loss connection, 只需要登当前的lease过期, 就可以grant a new lease
The lease mechanism is designed to minimize management overhead at the master. A lease has an initial timeout of 60 seconds. However, as long as the chunk is being mutated, the primary can request and typically receive extensions from the master indefinitely. These extension requests and grants are piggybacked on the HeartBeat messages regularly exchanged between the master and all chunkservers. The master may sometimes try to revoke a lease before it expires (e.g., when the master wants to disable mutations on a file that is being renamed). Even if the master loses communication with a primary, it can safely grant a new lease to another replica after the old lease expires.
In Figure 2, we illustrate this process by following the control flow of a write through these numbered steps.

1. The client asks the master which chunkserver holds the current lease for the chunk and the locations of the other replicas. If no one has a lease, the master grants one to a replica it chooses (not shown).
2. The master replies with the identity of the primary and the locations of the other (secondary) replicas. The client caches this data for future mutations. It needs to contact the master again only when the primary becomes unreachable or replies that it no longer holds a lease.
3. The client pushes the data to all the replicas.
A client can do so in any order. Each chunkserver will store the data in an internal LRU buffer cache until the data is used or aged out.
By decoupling the data flow from the control flow, we can improve performance by scheduling the expensive data flow based on the network topology regardless of which chunkserver is the primary.
4. Once all the replicas have acknowledged receiving the data, the client sends a write request to the primary.
The request identifies the data pushed earlier to all of the replicas. The primary assigns consecutive serial numbers to all the mutations it receives, possibly from multiple clients, which provides the necessary serialization. It applies the mutation to its own local state in serial number order.
5. The primary forwards the write request to all secondary replicas.
Each secondary replica applies mutations in the same serial number order assigned by the primary.
6. The secondaries all reply to the primary indicating that they have completed the operation.
7. The primary replies to the client.
Any errors encountered at any of the replicas are reported to the client.
In case of errors, the write may have succeeded at the primary and an arbitrary subset of the secondary replicas. (If it had failed at the primary, it would not have been assigned a serial number and forwarded.) The client request is considered to have failed, and the modified region is left in an inconsistent state.
Our client code handles such errors by retrying the failed mutation. It will make a few attempts at steps (3) through (7) before falling back to a retry from the beginning of the write.
这一系列步骤, 就是为了保证更新的多replicas一致性(defined), 失败的情况一定是某些replicas没有存成功, 这样就会导致不一致, 所以client code必须handle error, retry去维护一致性.
If a write by the application is large or straddles a chunk boundary, GFS client code breaks it down into multiple write operations.
They all follow the control flow described above but may be interleaved with and overwritten by concurrent operations from other clients.
Therefore, the shared file region may end up containing fragments from different clients, although the replicas will be identical because the individual operations are completed successfully in the same order on all replicas. This leaves the file region in consistent but undefined state as noted in Section 2.7.
对于large write , 超越了chunk的边界, GFS client会把这个更新拆分为多个更新, 应该是每个chunk的改动为一个子更新
在并发的环境下, 这多个子更新很可能会被其他clients的更新操作interleave(交叉隔开)和overwritten, 所以这样更新的数据根据GFS的机制, 还是可以保持一致性的, 但无法保证defined, 因为更新的数据很可能被其他client操作覆盖, 导致最终你无法从结果上看到这部分更新, 这就解释了2.7中说的并发write, 一致但undefined的case
3.2 Data Flow
We decouple the flow of data from the flow of control to use the network efficiently.
While control flows from the client to the primary and then to all secondaries, data is pushed linearly along a carefully picked chain of chunkservers in a pipelined fashion.
Our goals are to fully utilize each machine’s network bandwidth, avoid network bottlenecks and high-latency links, and minimize the latency to push through all the data.
为什么这种carefully picked chain的结构比其他topology (e.g., tree)更高效?
To fully utilize each machine’s network bandwidth, the data is pushed linearly along a chain of chunkservers rather than distributed in some other topology (e.g., tree). Thus, each machine’s full outbound bandwidth is used to transfer the data as fast as possible rather than divided among multiple recipients.
To avoid network bottlenecks and high-latency links (e.g., inter-switch links are often both) as much as possible, each machine forwards the data to the “closest” machine in the network topology that has not received it.
Finally, we minimize latency by pipelining the data transfer over TCP connections. Once a chunkserver receives some data, it starts forwarding immediately. Pipelining is especially helpful to us because we use a switched network with full-duplex links. Sending the data immediately does not reduce the receive rate. Without networkc ongestion, the ideal elapsed time for transferring B bytes to R replicas is B/T + RL where T is the network throughput and L is latency to transfer bytes between two machines. Our network links are typically 100 Mbps (T), and L is far below 1 ms. Therefore, 1 MB can ideally be distributed in about 80 ms.
3.3 Atomic Record Appends
GFS provides an atomic append operation called record append.
In a traditional write, the client specifies the offset at which data is to be written. Concurrent writes to the same region are not serializable: the region may end up containing data fragments from multiple clients.
In a record append, however, the client specifies only the data. GFS appends it to the file at least once atomically (i.e., as one continuous sequence of bytes) at an offset of GFS’s choosing and returns that offset to the client. This is similar to writing to a file opened in O_APPEND mode in Unix without the race conditions when multiple writers do so concurrently.
Record append保证每次写都自动将offset设为end(所谓的GFS’s choosing ), 再开始写. 并保证对文件的一次append是原子的.
这样就可以简单的保证多clients的并发写, 避免多个client从相同的offset并发写, 导致数据被互相overwrite.
Record append is a kind of mutation and follows the control flow in Section 3.1 with only a little extra logic at the primary.
The client pushes the data to all replicas of the last chunk of the file, Then it sends its request to the primary.
The primary checks to see if appending the record to the current chunk would cause the chunk to exceed the maximum size (64 MB).
- If so, it pads the chunk to the maximum size, tells secondaries to do the same, and replies to the client indicating that the operation should be retried on the next chunk. (Record append is restricted to be at most one-fourth of the maximum chunk size to keep worstcase fragmentation at an acceptable level.)
- If the record fits within the maximum size, which is the common case, the primary appends the data to its replica, tells the secondaries to write the data at the exact offset where it has, and
finally replies success to the client. - If a record append fails at any replica, the client retries the operation.
As a result, replicas of the same chunk may contain different data possibly including duplicates of the same record in whole or in part.
Append在exceed和fail的时候分别需要需要一些特殊的处理, 分别会产生padding数据和duplicate record
为什么在exceed时候, 采取padding的策略? 如果象large write那样, 分别append部分数据到现有chunk, 和新chunk, 可能无法保证append的原子性.
GFS does not guarantee that all replicas are bytewise identical. It only guarantees that the data is written at least once as an atomic unit. 怎么去理解这个property?
This property follows readily from the simple observation that for the operation to report success, the data must have been written at the same offset on all replicas of some chunk. Furthermore,
after this, all replicas are at least as long as the end of record and therefore any future record will be assigned a higher offset or a different chunk even if a different replica later becomes the primary. In terms of our consistency guarantees, the regions in which successful record append operations have written their data are defined (hence consistent), whereas intervening regions are inconsistent (hence undefined). Our applications can deal with inconsistent regions as we discussed in Section 2.7.2.
3.4 Snapshot
The snapshot operation makes a copy of a file or a directory tree (the “source”) almost instantaneously, while minimizing any interruptions of ongoing mutations.
Our users use it to quickly create branch copies of huge data sets (and often copies of those copies, recursively), or to checkpoint the current state before experimenting with changes that
can later be committed or rolled backeasily .
Like AFS [5], we use standard copy-on-write techniques to implement snapshots.
Copy-on-write (sometimes referred to as “COW“) is an optimization strategy used in computer programming. The fundamental idea is that if multiple callers ask for resources which are initially indistinguishable, they can all be given pointers to the same resource. This state of affairs can be maintained until a caller tries to modify its “copy” of the resource, at which point a separate (private) copy is made for that caller to prevent its changes from becoming visible to everyone else. All of this happens transparently to the callers. The primary advantage is that if no caller ever makes any modifications, no private copy need ever be created.
对于大部分copy需求, 其实需要的只是浅copy, COW技术确实是个很好的优化方法.
When the master receives a snapshot request,
first revokes any outstanding leases on the chunks in the files it is about to snapshot. This ensures that any subsequent writes to these chunks will require an interaction with the master to find the lease holder. This will give the master an opportunity to create a new copy of the chunk first. 之所以要取消lease, 是因为第一次write, master必须要创建真正的copy chunk, 所以第一次write必须让master知道
After the leases have been revoked or have expired, the master logs the operation to disk. It then applies this log record to its in-memory state by duplicating the metadata for the source file or directory tree. The newly created snapshot files point to the same chunks as the source files. COW高效在于不用copy正真的data, 只需要拷贝引用, 这儿就是copy metadata
The first time a client wants to write to a chunk C after the snapshot operation, it sends a request to the master to find the current lease holder.
The master notices that the reference count for chunk C is greater than one. 因为原metadata和snapshot的metadata都指向该chunk, 所以reference count>1
It defers replying to the client request and instead picks a new chunk handle C’. It then asks each chunkserver that has a current replica of C to create a new chunk called C’. By creating the new chunk on the same chunkservers as the original, we ensure that the data can be copied locally, not over the network(our disks are about three times as fast as our 100 Mb Ethernet links).
From this point, request handling is no different from that for any chunk: the master grants one of the replicas a lease on the new chunk C’ and replies to the client, which can write the chunk normally, not knowing that it has just been created from an existing chunk.
这样的结果就是, snapshot指向C, 而真正的指向 new chunk C’
4. MASTER OPERATION
The master executes all namespace operations. In addition, it manages chunk replicas throughout the system: it makes placement decisions, creates new chunks and hence replicas, and coordinates various system-wide activities to keep chunks fully replicated, to balance load across all the chunkservers, and to reclaim unused storage. We now discuss each of these topics.
4.1 Namespace Management and Locking
Many master operations can take a long time: for example, a snapshot operation has to revoke chunkserver leases on all chunks covered by the snapshot. We do not want to delay other master operations while they are running. Therefore, we allow multiple operations to be active and use locks over regions of the namespace to ensure proper serialization.
Unlike many traditional file systems, GFS does not have a per-directory data structure that lists all the files in that directory. Nor does it support aliases for the same file or directory (i.e, hard or symbolic links in Unix terms).
GFS logically represents its namespace as a lookup table mapping full pathnames to metadata. With prefix compression, this table can be efficiently represented in memory. Each node in the namespace tree (either an absolute file name or an absolute directory name) has an associated read-write lock.
Each master operation acquires a set of locks before it runs.
Typically, if it involves /d1/d2/…/dn/leaf, it will acquire read-locks on the directory names /d1, /d1/d2, …, /d1/d2/…/dn, and either a read lock or a write lock on the full pathname /d1/d2/…/dn/leaf. Note that leaf may be a file or directory depending on the operation.
We now illustrate how this locking mechanism can prevent a file /home/user/foo from being created while /home/user is being snapshotted to /save/user.
The snapshot operation acquires read locks on /home and /save, and write locks on /home/user and /save/user.
The file creation acquires read locks on /home and /home/user, and a write lockon /home/user/foo.
The two operations will be serialized properly because they try to obtain conflicting locks on /home/user.
One nice property of this locking scheme is that it allows concurrent mutations in the same directory.
For example, multiple file creations can be executed concurrently in the same directory: each acquires a read lock on the directory name and a write lock on the file name. The read lock on the directory name suffices to prevent the directory from being deleted, renamed, or snapshotted. The write locks on file names serialize attempts to create a file with the same name twice.
Since the namespace can have many nodes, read-write lock objects are allocated lazily and deleted once they are not in use. Also, locks are acquired in a consistent total order to prevent deadlock: they are first ordered by level in the namespace tree and lexicographically within the same level.
作为文件系统, 命名空间都是类似, 目录, 子目录, 文件, GFS的不同是, 没有维护目录和目录下文件的关系, 为什么? 用不到? 浪费空间? 还是通过前缀判断?
所以, namespace 就是full path和metadata的mapping, 并且full path可以简单的prefix compression, 并存储到memory中
然后GFS需要支持多文件并发更新, 这个必须通过lock. 通过给每个节点增加read-write lock
可以同时更新不同的文件, 创建不同的文件, 但是同一文件的更新必须是原子的
4.2 Replica Placement
A GFS cluster is highly distributed at more levels than one. It typically has hundreds of chunkservers spread across many machine racks. These chunkservers in turn may be accessed from hundreds of clients from the same or different racks. Communication between two machines on different racks may cross one or more network switches. Additionally, bandwidth into or out of a rack may be less than the aggregate bandwidth of all the machines within the rack.
Multi-level distribution presents a unique challenge to distribute data for scalability, reliability, and availability.
The chunk replica placement policy serves two purposes: maximize data reliability and availability, and maximize network bandwidth utilization.
For both, it is not enough to spread replicas across machines, which only guards against disk or machine failures and fully utilizes each machine’s networkbandwidth.
We must also spread chunk replicas across racks. This ensures that some replicas of a chunk will survive and remain available even if an entire rack is damaged or offline (for example, due to failure of a shared resource like a network switch or power circuit). It also means that traffic, especially reads, for a chunk can exploit the aggregate bandwidth of multiple racks. On the other hand, write traffic has to flow through multiple racks, a tradeoff we make willingly.
4.3 Creation, Re-replication, Rebalancing
Chunk replicas are created for three reasons: chunkcreation, re-replication, and rebalancing.
When the master creates a chunk, it chooses where to place the initially empty replicas.
It considers several factors,
- We want to place new replicas on chunkservers with below-average disk space utilization. Over time this will equalize disk utilization across chunkservers.
- We want to limit the number of “recent” creations on each chunkserver. Although creation itself is cheap, it reliably predicts imminent heavy write traffic because chunks are created when demanded by writes, and in our append-once-read-many workload they typically become practically read-only once they have been completely written.
- As discussed above, we want to spread replicas of a chunk across racks.
The master re-replicates a chunk as soon as the number of available replicas falls below a user-specified goal.
This could happen for various reasons:
- a chunkserver becomes unavailable
- it reports that its replica may be corrupted
- one of its disks is disabled because of errors
- the replication goal is increased.
Each chunk that needs to be re-replicated is prioritized based on several factors.
- One is how far it is from its replication goal. For example, we give higher priority to a chunk that has lost two replicas than to a chunk that has lost only one.
- In addition, we prefer to first re-replicate chunks for live files as opposed to chunks that belong to recently deleted files (see Section 4.4).
- Finally, to minimize the impact of failures on running applications, we boost the priority of any chunk that is blocking client progress.
To keep cloning traffic from overwhelming client traffic, the master limits the numbers of active clone operations both for the cluster and for each chunkserver. Additionally, each chunkserver limits the amount of bandwidth it spends on each clone operation by throttling its read requests to the source chunkserver.
Finally, the master rebalances replicas periodically:
It examines the current replica distribution and moves replicas for better disks pace and load balancing.
Also through this process, the master gradually fills up a new chunkserver rather than instantly swamps it with new chunks and the heavy write traffic that comes with them. The placement criteria for the new replica are similar to those discussed above. In addition, the master must also choose which existing replica to remove. In general, it prefers to remove those on chunkservers with below-average free space so as to equalize disk space usage.
4.4 Garbage Collection
After a file is deleted, GFS does not immediately reclaim the available physical storage. It does so only lazily during regular garbage collection at both the file and chunk levels. We find that this approach makes the system much simpler and more reliable.
4.4.1 Mechanism
When a file is deleted by the application, the master logs the deletion immediately just like other changes. However instead of reclaiming resources immediately, the file is just renamed to a hidden name that includes the deletion timestamp.
During the master’s regular scan of the file system namespace, it removes any such hidden files if they have existed for more than three days (the interval is configurable).
Until then, the file can still be read under the new, special name and can be undeleted by renaming it back to normal.
When the hidden file is removed from the namespace, its in memory metadata is erased. This effectively severs its links to all its chunks.
In a similar regular scan of the chunk namespace, the master identifies orphaned chunks (i.e., those not reachable from any file) and erases the metadata for those chunks. In a HeartBeat message regularly exchanged with the master, each chunkserver reports a subset of the chunks it has, and the master replies with the identity of all chunks that are no longer present in the master’s metadata. The chunkserver is free to delete its replicas of such chunks.
4.4.2 Discussion
Although distributed garbage collection is a hard problem that demands complicated solutions in the context of programming languages, it is quite simple in our case.
We can easily identify all references to chunks: they are in the fileto-chunk mappings maintained exclusively by the master.
We can also easily identify all the chunk replicas: they are Linux files under designated directories on each chunkserver.
Any such replica not known to the master is “garbage.”
The garbage collection approach to storage reclamation offers several advantages over eager deletion.
- First, it is simple and reliable in a large-scale distributed system where component failures are common. Chunk creation may succeed on some chunkservers but not others, leaving replicas that the master does not know exist. Replica deletion messages may be lost, and the master has to remember to resend them across failures, both its own and the chunkserver’s.
Garbage collection provides a uniform and dependable way to clean up any replicas not known to be useful. - Second, it merges storage reclamation into the regular background activities of the master, such as the regular scans of namespaces and handshakes with chunkservers. Thus, it is done
in batches and the cost is amortized. Moreover, it is done only when the master is relatively free. The master can respond more promptly to client requests that demand timely attention. - Third, the delay in reclaiming storage provides a safety net against accidental, irreversible deletion.
In our experience, the main disadvantage is that the delay sometimes hinders user effort to fine tune usage when storage is tight.
Applications that repeatedly create and delete temporary files may not be able to reuse the storage right away. We address these issues by expediting storage reclamation if a deleted file is explicitly deleted again. We also allow users to apply different replication and reclamation policies to different parts of the namespace. For example, users can specify that all the chunks in the files within some directory tree are to be stored without replication, and any deleted files are immediately and irrevocably removed from the file system state.
其实GFS的垃圾回收, 机制非常简单, 最大的优点就是简单, 可靠, 尤其在不稳定分布式环境中, 缺点就是当存储空间比较紧张的时候, 有点浪费空间.
4.5 Stale Replica Detection
Chunk replicas may become stale if a chunkserver fails and misses mutations to the chunk while it is down.
For each chunk, the master maintains a chunk version number to distinguish between up-to-date and stale replicas.
Whenever the master grants a new lease on a chunk, it increases the chunk version number and informs the up-to-date replicas. The master and these replicas all record the new version number in their persistent state.
为什么是grant lease的时候增加chunk版本, 而不是在每个chunk更新时都增加chunk版本? 我的理解, chunk更新不一定需要通过master, 而grant lease必须通过master
This occurs before any client is notified and therefore before it can start writing to the chunk. If another replica is currently unavailable, its chunk version number will not be advanced. The master will detect that this chunkserver has a stale replica when the chunkserver restarts and reports its set of chunks and their associated version numbers. If the master sees a version number greater than the one in its records, the master assumes that it failed when granting the lease and so takes the higher version to be up-to-date.
The master removes stale replicas in its regular garbage collection.
Before that, it effectively considers a stale replica not to exist at all when it replies to client requests for chunk information.
As another safeguard, the master includes the chunk version number when it informs clients which chunkserver holds a lease on a chunk or when it instructs a chunkserver to read the chunk from another chunkserver in a cloning operation. The client or the chunkserver verifies the version number when it performs the operation so that it is always accessing up-to-date data.
为了确保client不要读到stale数据, master会把最新的版本信息也附带返回给client, 这样client去chunkserver读数据的时候, 可以再进行verify.
5. FAULT TOLERANCE AND DIAGNOSIS
One of our greatest challenges in designing the system is dealing with frequent component failures.
The quality and quantity of components together make these problems more the norm than the exception: we cannot completely trust the machines, nor can we completely trust the disks. Component failures can result in an unavailable system or, worse, corrupted data. We discuss how we meet these challenges and the tools we have built into the system to diagnose problems when they inevitably occur.
5.1 High Availability
Among hundreds of servers in a GFS cluster, some are bound to be unavailable at any given time. We keep the overall system highly available with two simple yet effective strategies: fast recovery and replication.
5.1.1 Fast Recovery, 可以在秒级别的快速重启
Both the master and the chunkserver are designed to restore their state and start in seconds no matter how they terminated.
In fact, we do not distinguish between normal and abnormal termination; servers are routinely shut down just by killing the process.
Clients and other servers experience a minor hiccup as they time out on their outstanding requests, reconnect to the restarted server, and retry. Section 6.2.2 reports observed startup times.
5.1.2 Chunk Replication, 通过多replicas来保证数据的高可用性
As discussed earlier, each chunk is replicated on multiple chunkservers on different racks.
Users can specify different replication levels for different parts of the file namespace. The default is three.
The master clones existing replicas as needed to keep each chunk fully replicated as chunkservers go offline or detect corrupted replicas through checksum verification (see Section 5.2).
Although replication has served us well, we are exploring other forms of cross-server redundancy such as parity or erasure codes for our increasing readonly storage requirements. We expect that it is challenging but manageable to implement these more complicated redundancy schemes in our very loosely coupled system because our traffic is dominated by appends and reads rather than small random writes.
5.1.3 Master Replication, master本身也需要通过log和checkpoint来多replicas备份
The master state is replicated for reliability. Its operation log and checkpoints are replicated on multiple machines.
A mutation to the state is considered committed only after its log record has been flushed to disk locally and on all master replicas.
For simplicity, one master process remains in charge of all mutations as well as background activities such as garbage collection that change the system internally.
When it fails, it can restart almost instantly. If its machine or disk fails, monitoring infrastructure outside GFS starts a new master process elsewhere with the replicated operation log.
Clients use only the canonical name of the master (e.g. gfs-test), which is a DNS alias that can be changed if the master is relocated to another machine.
Moreover, “shadow” masters provide read-only access to the file system even when the primary master is down.
They are shadows, not mirrors, in that they may lag the primary slightly, typically fractions of a second. They enhance read availability for files that are not being actively mutated or applications that do not mind getting slightly stale results. In fact, since file content is read from chunkservers, applications do not observe stale file content. What could be stale within short windows is file metadata, like directory contents or access control information.
To keep itself informed, a shadow master reads a replica of the growing operation log and applies the same sequence of changes to its data structures exactly as the primary does.
Like the primary, it polls chunkservers at startup (and infrequently thereafter) to locate chunk replicas and exchanges frequent handshake messages with them to monitor their status. It depends on the primary master only for replica location updates resulting from the primary’s decisions to create and delete replicas.
5.2 Data Integrity
Each chunkserver uses checksumming to detect corruption of stored data.
Given that a GFS cluster often has thousands of disks on hundreds of machines, it regularly experiences disk failures that cause data corruption or loss on both the read and write paths.
We can recover from corruption using other chunk replicas, but it would be impractical to detect corruption by comparing replicas across chunkservers. Moreover, divergent replicas may be legal: the semantics of GFS mutations, in particular atomic record append as discussed earlier, does not guarantee identical replicas. Therefore, each chunkserver must independently verify the integrity of its own copy by maintaining checksums.
A chunk is broken up into 64 KB blocks. Each has a corresponding 32 bit checksum. Like other metadata, checksums are kept in memory and stored persistently with logging, separate from user data. For reads, the chunkserver verifies the checksum of data blocks that overlap the read range before returning any data to the requester, whether a client or another chunkserver.
Therefore chunkservers will not propagate corruptions to other machines. If a block does not match the recorded checksum, the chunkserver returns an error to the requestor and reports the mismatch to the master. In response, the requestor will read from other replicas, while the master will clone the chunkfrom another replica. After a valid new replica is in place, the master instructs the chunkserver that reported the mismatch to delete its replica.
通过校验和来保证数据的一致性, 并且每个chunkserver独立的验证本地chunk的一致性(出于效率考虑).
每次当client来读数据的时候, chunkserver都会验证该数据的一致性, 如果数据不一致, 返回错误信息, 让client去其他replica读取, 并且会通知master, master会通过其他replica来recover.
Checksumming has little effect on read performance for several reasons.
Since most of our reads span at least a few blocks, we need to read and checksum only a relatively small amount of extra data for verification.
GFS client code further reduces this overhead by trying to align reads at checksum block boundaries.
Moreover, checksum lookups and comparison on the chunkserver are done without any I/O, and checksum calculation can often be overlapped with I/Os.
Checksum computation is heavily optimized for writes that append to the end of a chunk(as opposed to writes that overwrite existing data) because they are dominant in our workloads. We just incrementally update the checksum for the last partial checksum block, and compute new checksums for any brand new checksum blocks filled by the append. Even if the last partial checksum block is already corrupted and we fail to detect it now, the new checksum value will not match the stored data, and the corruption will be detected as usual when the block is next read.
In contrast, if a write overwrites an existing range of the chunk, we must read and verify the first and last blocks of the range being overwritten, then perform the write, and finally compute and record the new checksums. If we do not verify the first and last blocks before overwriting them partially, the new checksums may hide corruption that exists in the regions not being overwritten.
During idle periods, chunkservers can scan and verify the contents of inactive chunks, 前面说了, chunkserver在读的时候check checksumming, 那么对于inactive chunk, 就没有机会被check
This allows us to detect corruption in chunks that are rarely read. Once the corruption is detected, the master can create a new uncorrupted replica and delete the corrupted replica. This prevents an inactive but corrupted chunk replica from fooling the master into thinking that it has enough valid replicas of a chunk.
5.3 Diagnostic Tools
Extensive and detailed diagnostic logging has helped immeasurably in problem isolation, debugging, and performance analysis, while incurring only a minimal cost.
Without logs, it is hard to understand transient, non-repeatable interactions between machines. GFS servers generate diagnostic logs that record many significant events (such as chunkservers going up and down) and all RPC requests and replies. These diagnostic logs can be freely deleted without affecting the correctness of the system. However, we try to keep these logs around as far as space permits.
The RPC logs include the exact requests and responses sent on the wire, except for the file data being read or written.
By matching requests with replies and collating RPC records on different machines, we can reconstruct the entire interaction history to diagnose a problem. The logs also serve as traces for load testing and performance analysis.
The performance impact of logging is minimal (and far outweighed by the benefits) because these logs are written sequentially and asynchronously. The most recent events are also kept in memory and available for continuous online monitoring.
9. CONCLUSIONS
The Google File System demonstrates the qualities essential for supporting large-scale data processing workloads on commodity hardware.
While some design decisions are specific to our unique setting, many may apply to data processing tasks of a similar magnitude and cost consciousness.
We started by reexamining traditional file system assumptions in light of our current and anticipated application workloads and technological environment.
Our observations have led to radically different points in the design space.
We treat component failures as the norm rather than the exception, optimize for huge files that are mostly appended to (perhaps concurrently) and then read (usually sequentially), and both extend and relax the standard file system interface to improve the overall system.
Our system provides fault tolerance by constant monitoring, replicating crucial data, and fast and automatic recovery.
Chunk replication allows us to tolerate chunkserver failures. The frequency of these failures motivated a novel online repair mechanism that regularly and transparently repairs the damage and compensates for lost replicas as soon as possible. Additionally, we use checksumming to detect data corruption at the disk or IDE subsystem level, which becomes all too common given the number of disks in the system.
Our design delivers high aggregate throughput to many concurrent readers and writers performing a variety of tasks.
We achieve this by separating file system control, which passes through the master, from data transfer, which passes directly between chunkservers and clients. Master involvement in common operations is minimized by a large chunk size and by chunkleases, which delegates authority to primary replicas in data mutations. This makes possible a simple, centralized master that does not become a bottleneck.
We believe that improvements in our networking stack will lift the current limitation on the write throughput seen by an individual client.
GFS has successfully met our storage needs and is widely used within Google as the storage platform for research and development as well as production data processing. It is an important tool that enables us to continue to innovate and attack problems on the scale of the entire web.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/137973.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
