大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
一、什么是ELK
ELK是Elasticsearch + Logstash + Kibana 这种架构的简写。这是一种日志分平台析的架构。从前我们用shell三剑客(grep, sed, awk)来分析日志, 虽然也能对付大多数场景,但当日志量大,分析频繁,并且使用者可能不会shell三剑客的情况下, 配置方便,使用简单,并且分析结果更加直观的工具(平台)就诞生了,它就是ELK。 ELK是开源的,并且社区活跃,用户众多。当然国内也有一些收费的,比较好用的日志分析平台,比如日志易(日志易的同事赶紧给我打钱,毕竟这广告打的好)。
二、ELK常见的几种架构
1 Elasticsearch + Logstash + Kibana
这是一种最简单的架构。这种架构,通过logstash收集日志,Elasticsearch分析日志,然后在Kibana(web界面)中展示。这种架构虽然是官网介绍里的方式,但是往往在生产中很少使用。
2 Elasticsearch + Logstash + filebeat + Kibana
与上一种架构相比,这种架构增加了一个filebeat模块。filebeat是一个轻量的日志收集代理,用来部署在客户端,优势是消耗非常少的资源(较logstash), 所以生产中,往往会采取这种架构方式,但是这种架构有一个缺点,当logstash出现故障, 会造成日志的丢失。
3 Elasticsearch + Logstash + filebeat + redis(也可以是其他中间件,比如kafka) + Kibana
这种架构是上面那个架构的完善版,通过增加中间件,来避免数据的丢失。当Logstash出现故障,日志还是存在中间件中,当Logstash再次启动,则会读取中间件中积压的日志。目前我司使用的就是这种架构,我个人也比较推荐这种方式。
架构图:
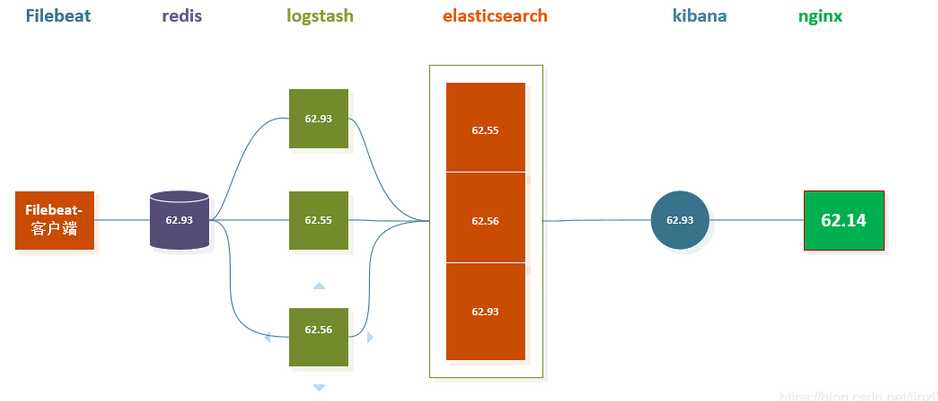

说明: logstash节点和elasticsearch节点可以根据日志量伸缩数量, filebeat部署在每台需要收集日志的服务器上。
首先准备安装包
传输到linux下找个目录存放
第一部分安装node和elasticsearch-head
作为web展示 所以首先安装nodejs 主要是利用npm
1安装wget
yum install -y wget
2.镜像淘宝下载node-v11
wget https://npm.taobao.org/mirrors/node/v11.0.0/node-v11.0.0.tar.gz
3.解压
tar -zxvf node-v11.0.0.tar.gz
4.进入node-v11
cd node-v11.0.0
5.安装编译环境
yum install -y gcc gcc-c++
6.启用配置
./configure
7.编译(会很慢,此处开启第二个会话窗口进行第二部分安装)
make
8.安装
make install
9.查看版本(看到此图说明成功)
node –v
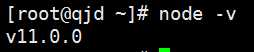
切换到安装软件的目录
10安装elasticsearch-head监控elasticsearch集群环境
没有unzip用yum下载安装一个
unzip –zxvf elasticsearch-head-master
进入到解压后的目录中
npm install
npm run start
在浏览器url输入
http://ip:9100/
第二部分安装elasticsearch
1.安装jdk,elasticsearch是依赖javajdk的
2.解压tar -zxvf elasticsearch6.2.2
3.config/elasticsearch.yml 配置环境
cluster.name: es-app #集群名称,可以自行修改
node.name: es-1 #节点名称,自行修改
network.host: 192.168.235.133 #主机地址,这里写本机IP
http.port: 9200 #端口
(手动输入)
http.cors.enabled: true #设置跨域
http.cors.allow-origin: "*" #设置访问
4.vi /etc/security/limits.conf
扩大系统最大文件数 在文件末尾添加
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
5.解决虚拟内存太低,增加最大字节处理长度
修改vi /etc/sysctl.conf文件末尾追加
vm.max_map_count=655360
查看激活

6.自建用户并授权
useradd
passwd
修改root用户对sudoers文件的可写权限
chmod u+w /etc/sudoers
编辑:
vi /etc/sudoers
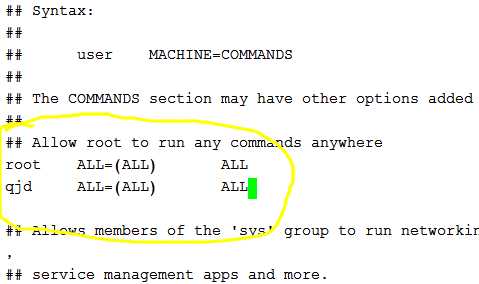
7进入到elasticsearch的bin目录
赋权
chown 用户名 -R 安装目录
切换到非root用户后
./elasticsearch 启动
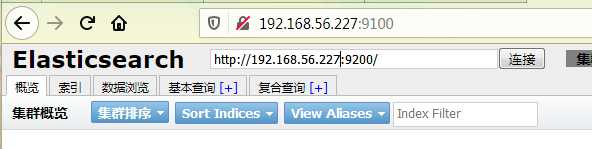
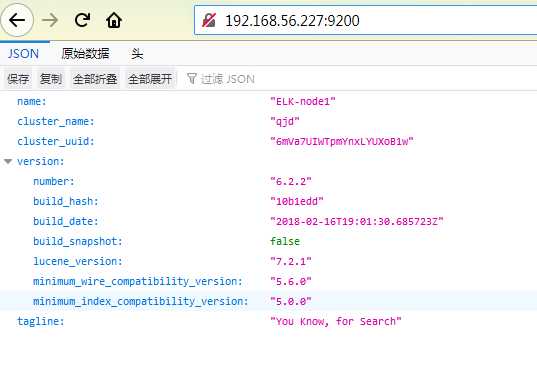
8之后在浏览器url输入
http://ip:9200/
出现此图证明成功
之后返回等待编译第一部分
第三部分kibana
1.解压缩安装kibana
tar -zxvf kibana-6.2.2-linux-x86_64.tar.gz
2.修改配置文件
在config下的kibana.yml
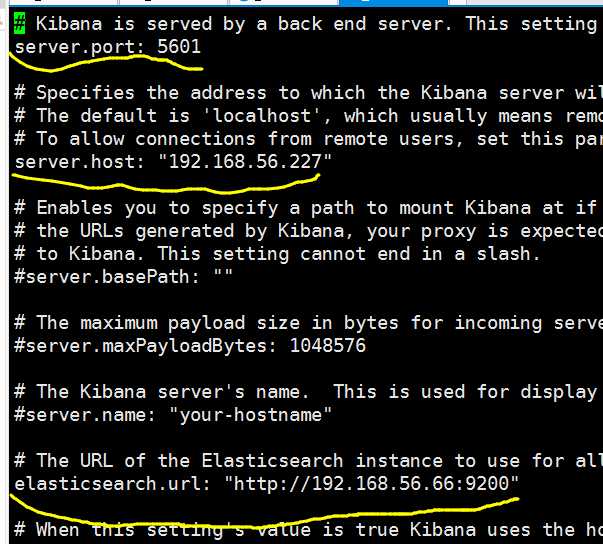
保存退出后
3.开启
cd 到bin目录下
./kibana
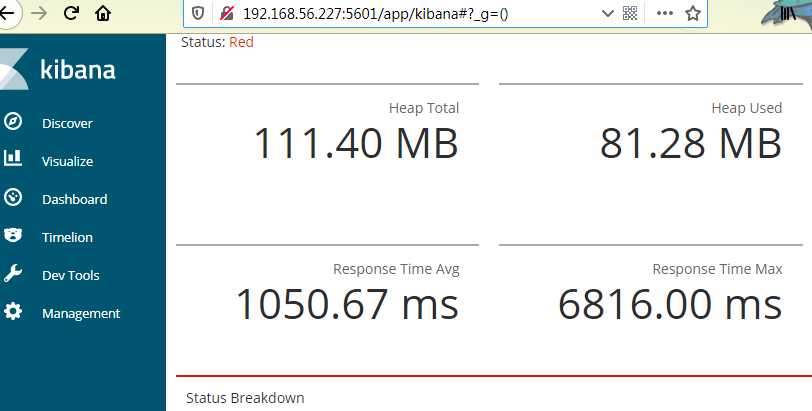
在浏览器url输入
http://192.168.56.227:5601
第四部分logstash
1解压缩
tar -zxvf logstash-6.2.2.tar.gz
2在logstash目录下
bin/logstash -e ‘input { stdin { } } output { stdout {} }’
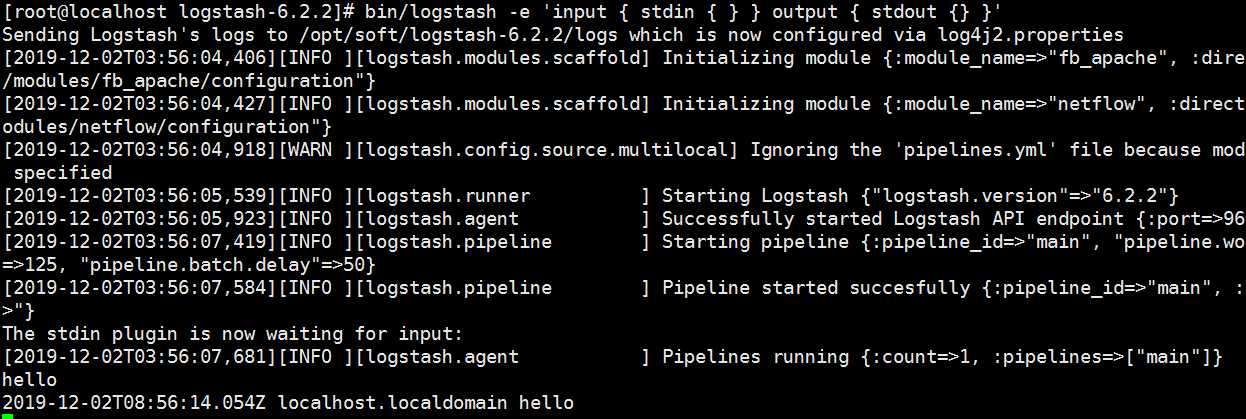 输入hello可以看到stdout输出的结果:hello
输入hello可以看到stdout输出的结果:hello
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/179551.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
