大家好,又见面了,我是你们的朋友全栈君。
目标是宅男女神的美女图片板块下的秀人板块, 页面上全部是该网站收录的美女图片分类, 大概浏览了一下, 发现各个杂志社的图片(妹子) 质量最高, 其中以秀人为首, 所以决定爬取所有秀人板块下的图片.
目标网页截图


该网页这里显示只有5页, 后面的页面在点击下一页后出现.
为了过审还是打码了, 本来都是穿着衣服的正经妹妹, 兄弟们可别误会了~
首先利用Chrome抓包
第一步先利用抓包工具来判断我们要爬取的网站是动态数据还是静态数据.
这里可以清楚的看到,当我们发起请求之后, 所有我们需要的东西都已经加载并缓存好了, 并没有什么反爬措施, 这一步分析后,我们可以直接写代码,看看我们分析的对不对.

from lxml import etree
import os
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
}
response = requests.get('目标网址', headers=headers)
# 这里直接拿会全部是乱码, encoding成utf-8显示正常
response.encoding = 'utf-8'
page_text = response.text
print(page_text)

发现确实是我们需要的网页信息, 现在就可以对页面进行分析, 用xpath拿到我们想要的数据
发现我们每个妹妹都在li标签里, 并且需要拼接的url和title也可以在li标签里找到.
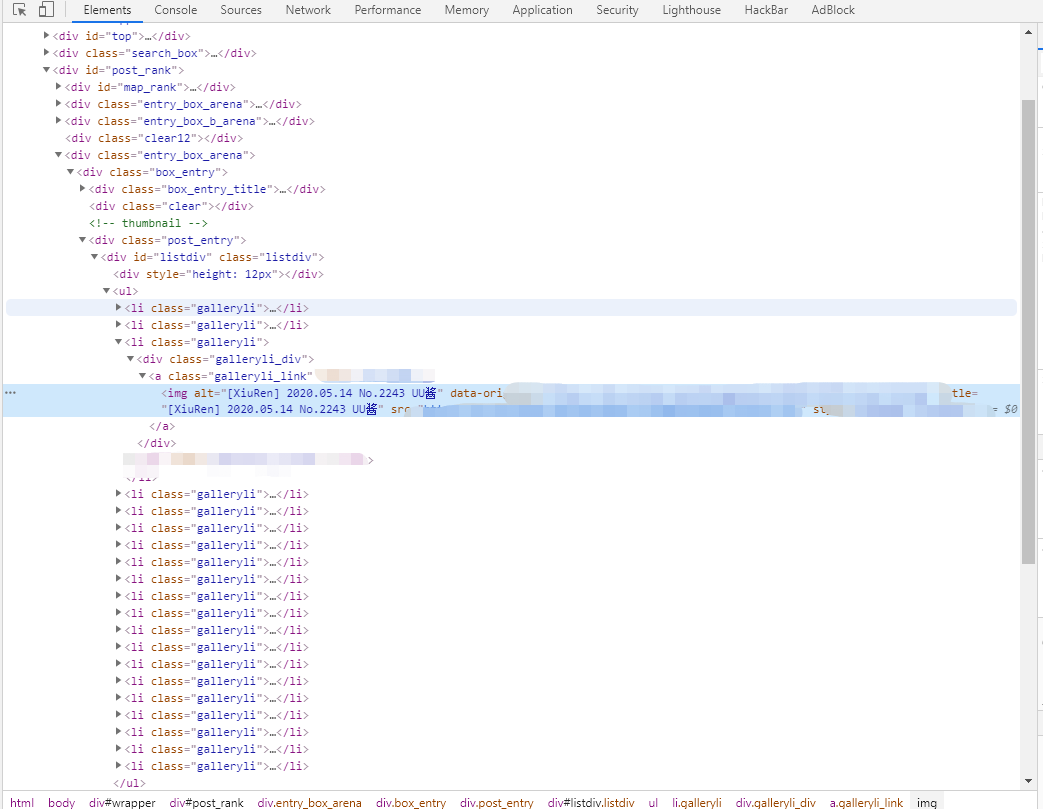
from lxml import etree
import os
import requests
# 该网站没什么反爬手段, 直接用最简单的header反而效果好
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
}
response = requests.get('目标网址', headers=headers)
# 这里直接拿会全部是乱码, encoding成utf-8显示正常
response.encoding = 'utf-8'
page_text = response.text
print(page_text)
tree = etree.HTML(page_text) #
li_list = tree.xpath("//div[@id='listdiv']//li")
for li in li_list:
img_list = []
img_dict = {
}
task_list = []
# 拼接每个妹妹的url, 并给每个妹妹创建一个文件夹
box_url = host + li.xpath('.//div[2]/a/@href')[0]
file_name = li.xpath('.//div[2]/a/text()')[0]
if not os.path.exists('./' + file_name):
os.mkdir(file_name)
详情页分析
现在主页面的信息我们都已经拿到了, 下一步就是进入每一个妹妹详情页面, 去下载图片
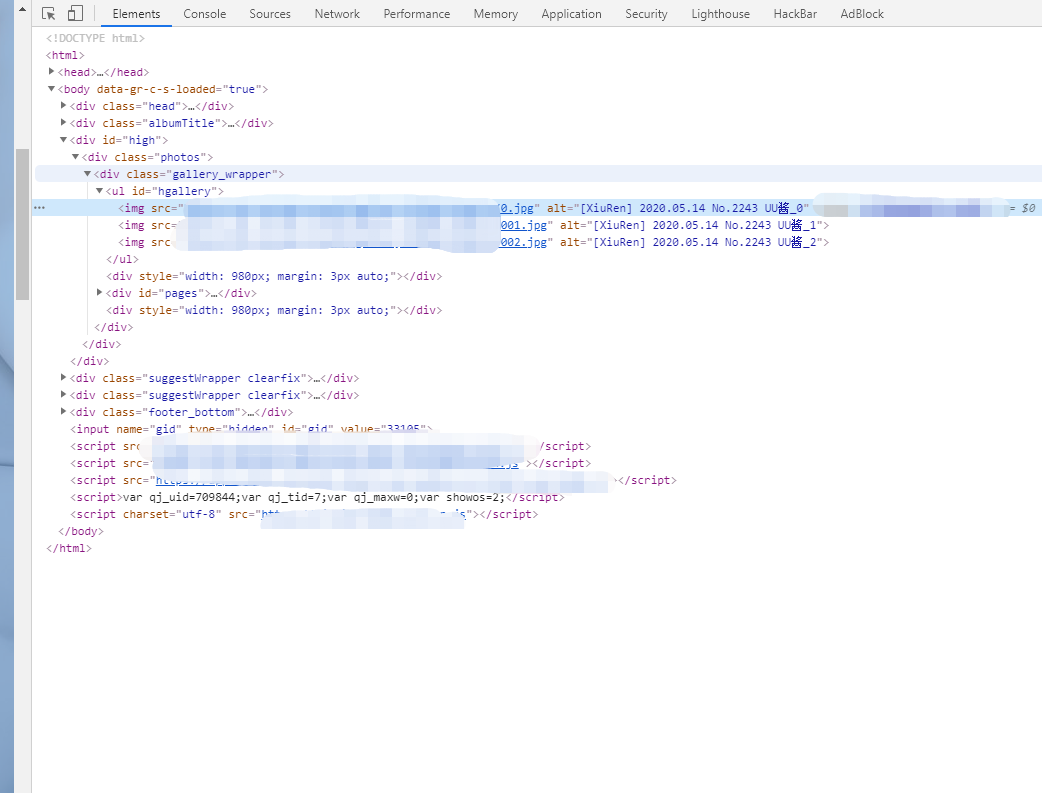
对详情页面分析, 发现每一页都会有三张图片, 并且下面需要翻页, 经测试如果翻到最后一页再点下一页会跳转到第一页, 这里找发现在第一页会显示每个妹妹图集里有多少张图

用xpath拿出来, 用正则把数字提取出来.到这一步我们的页面分析已经结束了, 直接上代码, 因为这么写下载速度很慢, 所以代码有几个版本, 包括线性的和协程的来对比和优化.
线性翻页下载图片
from lxml import etree
import os
import requests
# 该网站没什么反爬手段, 直接用最简单的header反而效果好
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
}
host = '目标网站host'
response = requests.get('目标网址', headers=headers)
# 这里直接拿会全部是乱码, encoding成utf-8显示正常
response.encoding = 'utf-8'
page_text = response.text
print(page_text)
tree = etree.HTML(page_text) #
li_list = tree.xpath("//div[@id='listdiv']//li")
for li in li_list:
img_list = []
img_dict = {
}
task_list = []
# 拼接每个妹妹的url, 并给每个妹妹创建一个文件夹
box_url = host + li.xpath('.//div[2]/a/@href')[0]
file_name = li.xpath('.//div[2]/a/text()')[0]
if not os.path.exists('./' + file_name):
os.mkdir(file_name)
# 这里进入详情页
page_detail = requests.get(url=box_url, headers=headers).text
detail_tree = etree.HTML(page_detail)
# 拿到一个图集中有多少图片的信息
NumbersOfImage = int(re.findall('(\d+)', (detail_tree.xpath('//*[@id="dinfo"]/span/text()')[0]))[0])
# 下载图片(如果图片列表里不到最大图片数量就一直翻页下载)
while len(img_list) != NumbersOfImage:
# 因为每页三张, 用一个for loop解析下载
for i in detail_tree.xpath('//*[@id="hgallery"]/img'):
img_dict = {
}
img_dict['title'] = './' + file_name + '/' + i.xpath('./@alt')[0] + '.jpg'
img_dict['src'] = i.xpath('./@src')[0]
# 利用requests content下载到二进制数据, 并保存
bytes_img = requests.get(url=img_dict['src'], headers=headers).content
with open(img_dict['title'], 'wb') as fp:
fp.write(bytes_img)
img_list.append(img_dict)
print(img_dict['title'], "下载完成", img_dict['src'])
# 翻页部分, 利用xpath拿到下一页标签中的url 与host进行拼接,形成下一页的url
next_page = host + detail_tree.xpath('//*[@id="pages"]/a[last()]/@href')[0]
new_page_detail = requests.get(url=next_page, headers=headers).text
new_page_detail_tree = etree.HTML(new_page_detail)
detail_tree = new_page_detail_tree
print(next_page)
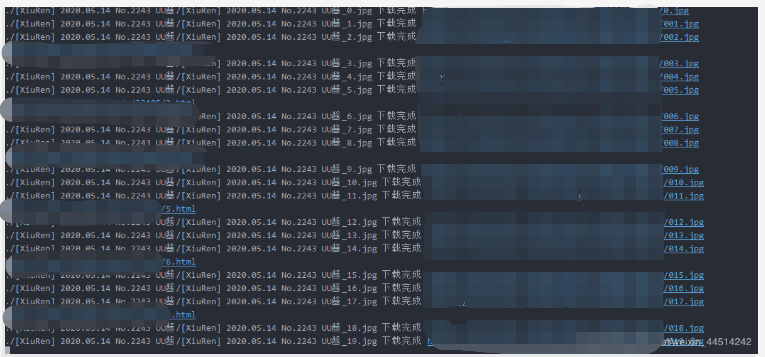
这里拿到了我们想要的结果, 每页下载图片, 然后翻页, 但是这么下载的速度实在是太慢了, 一个妹妹的全部图集一张一张的下载完, 全站的图片不知道哪年才能拿到

这里这个妹妹图片只有35张耗时17秒, 大部分妹妹的图集都超过70张, 所以现在想办法用asyncio协程来优化一下下载速度
第一次优化
from lxml import etree
import os
import requests
import re
import time
import asyncio
import aiohttp
# 协成下载
# asyncio不支持requests, 所以这里要用到aiohttp来下载, 和requests用法相似
sem = asyncio.Semaphore(20)
async def down_load(path, url):
with(await sem):
async with aiohttp.ClientSession() as sess:
async with await sess.get(url=url, headers=headers) as response:
img_bytes = await response.read()
with open(path, 'wb') as img:
img.write(img_bytes)
print(path, " 下载成功 ", url)
# 该网站没什么反爬手段, 直接用最简单的header反而效果好
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
}
host = '目标网站host'
response = requests.get('目标网站', headers=headers)
# 这里直接拿会全部是乱码, encoding成utf-8显示正常
response.encoding = 'utf-8'
page_text = response.text
tree = etree.HTML(page_text) #
li_list = tree.xpath("//div[@id='listdiv']//li")
for li in li_list:
img_list = []
img_dict = {
}
task_list = []
# 拼接每个妹妹的url, 并给每个妹妹创建一个文件夹
box_url = host + li.xpath('.//div[2]/a/@href')[0]
file_name = li.xpath('.//div[2]/a/text()')[0]
if not os.path.exists('./' + file_name):
os.mkdir(file_name)
# 这里进入详情页
page_detail = requests.get(url=box_url, headers=headers).text
detail_tree = etree.HTML(page_detail)
# 拿到一个图集中有多少图片的信息
NumbersOfImage = int(re.findall('(\d+)', (detail_tree.xpath('//*[@id="dinfo"]/span/text()')[0]))[0])
# 下载图片(如果图片列表里不到最大图片数量就一直翻页下载)
while len(img_list) != NumbersOfImage:
# 因为每页三张, 用一个for loop解析下载
for i in detail_tree.xpath('//*[@id="hgallery"]/img'):
img_dict = {
'title': './' + file_name + '/' + i.xpath('./@alt')[0] + '.jpg', 'src': i.xpath('./@src')[0]}
# 利用requests content下载到二进制数据, 并保存
# bytes_img = requests.get(url=img_dict['src'], headers=headers).content
# with open(img_dict['title'], 'wb') as fp:
# fp.write(bytes_img)
img_list.append(img_dict)
# 翻页部分, 利用xpath拿到下一页标签中的url 与host进行拼接,形成下一页的url
next_page = host + detail_tree.xpath('//*[@id="pages"]/a[last()]/@href')[0]
new_page_detail = requests.get(url=next_page, headers=headers).text
new_page_detail_tree = etree.HTML(new_page_detail)
detail_tree = new_page_detail_tree
print(next_page)
# 建立协程任务
loop = asyncio.get_event_loop()
for img_url in img_list:
c = down_load(img_url['title'], img_url['src'])
task = asyncio.ensure_future(c)
# task.add_done_callback(parse)
task_list.append(task)
loop.run_until_complete(asyncio.wait(task_list))
print("单个妹妹图集耗时: ", time.time() - start)
exit()

这里发现如果用协成来下载的话, 速度比之前快很多, 变成了4秒钟左右, 但是翻页等操作还是线性的,还是会占用大块的时间, 现在想办法把对一个页面里所有妹妹的图集请求变成协成的, 最终代码如下
最终版本
import requests
import time
import asyncio
import aiohttp
from lxml import etree
import re
import os
host = '目标网站host'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
sem = asyncio.Semaphore(20)
async def RealDownLoad(img_url, filename):
with(await sem):
async with aiohttp.ClientSession() as sess:
for url in img_url:
async with await sess.get(url=url['url'], headers=headers) as response:
img_bytes = await response.read()
with open('./'+filename + '/' + url['path'], 'wb') as img:
img.write(img_bytes)
print(url)
async def DownLoad(page_url, filename):
img_url = []
for page in page_url:
async with aiohttp.ClientSession() as sess:
async with await sess.get(url=page, headers=headers) as response:
page_detail = await response.text()
detail_tree = etree.HTML(page_detail)
for i in detail_tree.xpath('//*[@id="hgallery"]/img'):
img = {
'url': i.xpath('./@src')[0], 'path': i.xpath('./@alt')[0] + '.jpg'}
img_url.append(img)
return await RealDownLoad(img_url, filename)
async def GetInDetailPage(boxes):
page_url = []
for i in range(15):
page_url.append(boxes['url'] + str(i) + ".html")
return await DownLoad(page_url, boxes['file_name'])
async def main():
tasks = []
url = '目标网站'
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
page_text = response.text
box_url_list = []
box_task_list = []
tree = etree.HTML(page_text)
li_list = tree.xpath("//div[@id='listdiv']//li")
for li in li_list:
box = {
}
box_url = host + li.xpath('.//div[2]/a/@href')[0]
file_name = li.xpath('.//div[2]/a/text()')[0]
if not os.path.exists('./' + file_name):
os.mkdir(file_name)
box['url'] = box_url
box['file_name'] = file_name
box_url_list.append(box)
for boxes in box_url_list:
c = GetInDetailPage(boxes)
tasks.append(asyncio.ensure_future(c))
await asyncio.wait(tasks)
loop = asyncio.get_event_loop()
start = time.time()
loop.run_until_complete(main())
print("用时: ", time.time()-start)
exit()
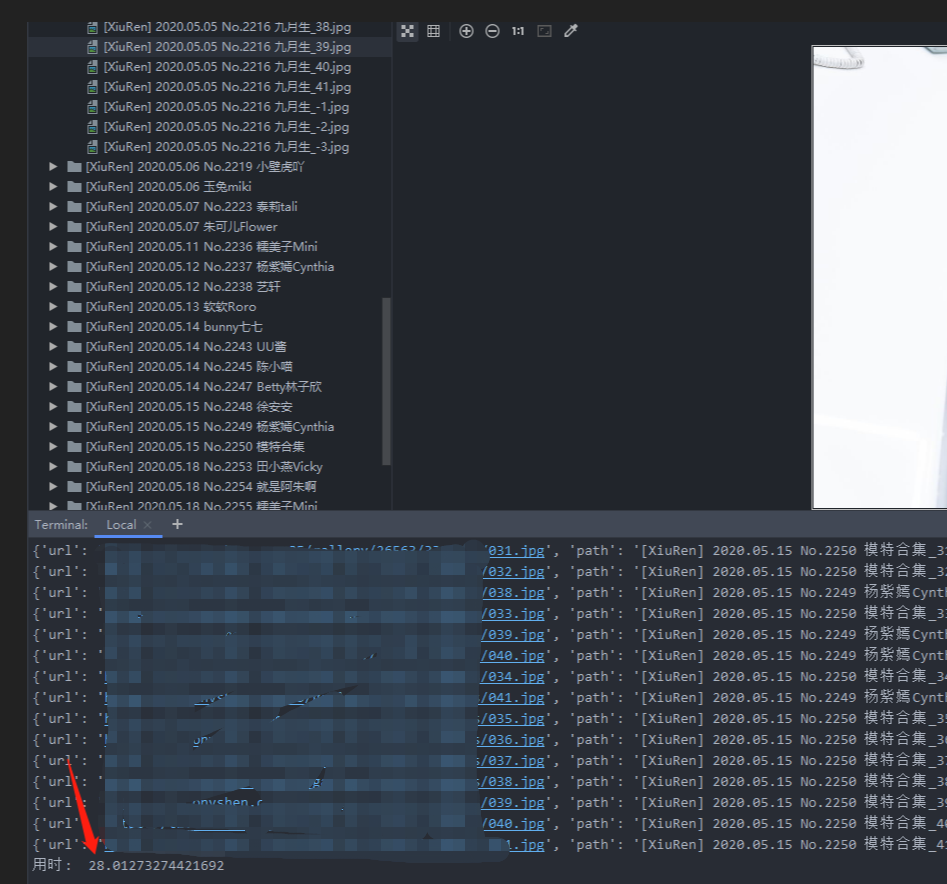
最终版本下载了目标页面宅男女神->美女图片->秀人网 下所有妹妹的图集(20个图集), 总用时不到30秒钟.
这段代码是只爬了”目标网址”的第一页, 没加翻页的函数, 有想法的朋友可以自己加一个翻页的方法.
其实这样类型的爬虫用scrapy框架中的crawl spider是最好的, 想看的朋友可以给我留言.
总结
写的不是很好, 包括对asyncio库的运用, 整体代码的封装等等, 后面还会持续更新爬虫方面的实例, 希望能给也在学习爬虫相关知识的朋友一点点启发, 喜欢的朋友也请点个赞吧,谢谢!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/136799.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
