大家好,又见面了,我是你们的朋友全栈君。
为了提高神经网络的性能,是应该增加宽度呢?还是应该增加深度呢?增加宽度和增加深度各有什么样的效果呢?
本文对论文《Wide & Deep Learning for Recommender Systems Heng-Tze》中关于宽度模型和深度模型的对比实验进行介绍。
推荐系统
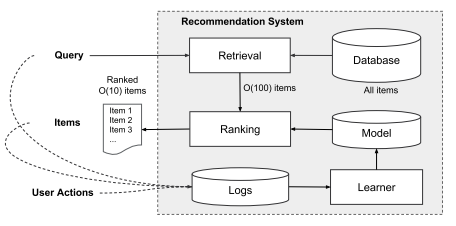
本论文基于推荐系统,推荐系统的运作如图。以APP推荐为例,首先用户在查询入口输入关键字,系统自动将Database中的items对关键字进行匹配,从而Retrieval一定的items,这些items将根据之前使用用户的各种行为数据logs学习到的model进行Ranking,从而将用户更可能下载的APP排在前面。

模型介绍
这里的模型,是针对上图中的Model模型。作者提及在推荐系统中最重要的两个特性是Memorize和generalize。Memorize的过程就是根据以往用户的数据训练模型的过程,类似training;generalize就是使用model对新的输入数据进行预测。
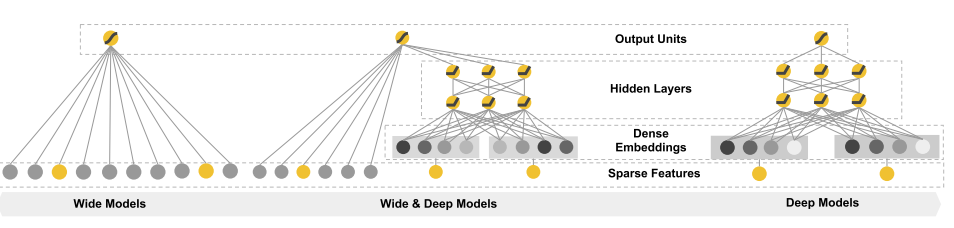
作者对比了三种模型,如下图,分别是宽度模型(wide models),深宽结合模型(wide&deep models)深度模型(deep models)。对于各模型的特点理解,故名思意,不做更多解释。
实验过程与实验结果
作者进行了3周的实时在线实验。对于对照组,作者随机选择1%的用户,并提供由之前版本的排名模型生成的推荐建议,这是一种高度优化的仅限广泛的逻辑回归模型,具有丰富的跨产品特征转换。对于实验组,1%的用户会收到由Wide&Deep models生成的建议,并使用相同的功能集进行训练。如表1所示,Wide&Deep models相对于对照组,应用程序商店主登陆页面上的应用程序获取率提高了3.9%(统计上显着)。结果也与另一个1%组进行比较,仅使用具有相同特征和神经网络结构的模型的深部,并且Wide&Deep models在仅deep models之上具有+ 1%的增益(具有统计显着性)。

除了在线实验,作者器操作员特征曲线下面积(AUC)。 虽然Wide&Deep的离线AUC略高,但对在线流量的影响更为显着。 一个可能的原因是离线数据集中的印象和标签是固定的,而在线系统可以通过将概括与记忆相结合来产生新的探索性建议,并从新的用户响应中学习。
实验总结
记忆和概括对于推荐系统都很重要。 宽线性模型可以使用跨产品特征转换有效地记忆稀疏特征交互,而深度神经网络可以通过低维嵌入来生成以前看不见的特征交互。作者介绍了Wide&Deep学习框架,以结合两种模型的优势。 作者在Google Play的推荐系统上制作并评估了该框架,Google Play是一个大规模的商业应用商店。 在线实验结果表明,Wide&Deep models在仅wide和仅deep models上的应用程序获取方面取得了显着改进。
通俗地讲:
1.wide models能够从训练数据中学习到重要的特征,对训练数据达到高度拟合。但是更换数据后,数据特征改变,wide models的预测能力就会下降,所以说,wide models的泛化能力不够;
2.deep models能够从训练数据中挖掘出更抽象的特征,这使得它具有很好的泛化能力,但是对单组数据来说,它的拟合能力比不上wide models;
3.wide&deep models的结构类似于卷积神经网络中将不同级别的特征层信息进行融合使用,既有低级纹理信息又有高级语义信息;
4.第一条和第二条还可以这样说,wide models容易过拟合,deep models不易过拟合。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/143597.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
