大家好,又见面了,我是你们的朋友全栈君。
0.引言
针对类别变量进行oner-hot编码后的高维稀疏矩阵M,可以表示如下:
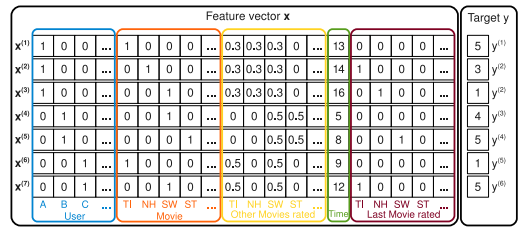

可以看出,经过One-Hot编码之后,大部分样本数据特征是比较稀疏的, One-Hot编码的另一个特点就是导致特征空间大。例如,电影品类有550维特征,一个categorical特征转换为550维数值特征,特征空间剧增。
同时通过观察大量的样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高。例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。换句话说,来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,而在“Thanksgiving”却不会有特别的消费行为。这种关联特征与label的正向相关性在实际问题中是普遍存在的,如“化妆品”类商品与“女”性,“球类运动配件”的商品与“男”性,“电影票”的商品与“电影”品类偏好等。因此,引入两个特征的组合是非常有意义的。
多项式模型是包含特征组合的最直观的模型。在多项式模型中,特征 和 的组合采用 表示,即和都非零时,组合特征 才有意义。从对比的角度,讨论二阶多项式模型。模型的表达式如下:
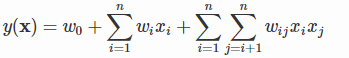
其中, 代表样本的特征数量,是第个特征的值, 是模型参数。从公式可以看出,组合特征的参数一共有 个,任意两个参数都是独立的。然而,在数据稀疏性普遍存在的实际应用场景中,二次项参数的训练是很困难的。其原因是,每个参数 的训练需要大量 和 都非零的样本;由于样本数据本来就比较稀疏,满足“和 都非零”的样本将会非常少。训练样本的不足,很容易导致参数 不准确,最终将严重影响模型的性能。
一、FM模型推导
1. 对于普通的线性模型,引入二次交叉项后:
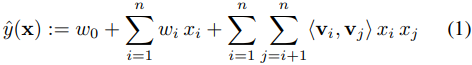
其中,,,,为隐向量的维度,则两个向量的内积满足:
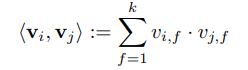
该模型需要学习的参数包括:
-
:模型整体的偏置;
-
:一阶线性权重;
-
和特征交互权重
针对等式(1)右端最后一项化简得:
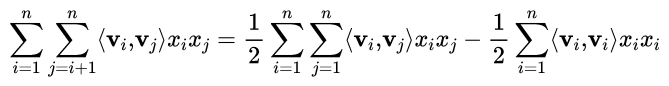
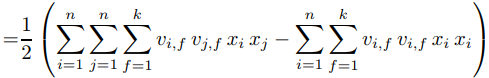
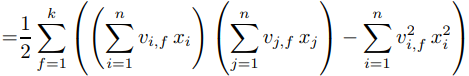
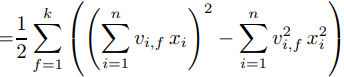
所以公式(1)可以化简为:

针对上式,利用SGD训练模型其参数的梯度下降表达式为:
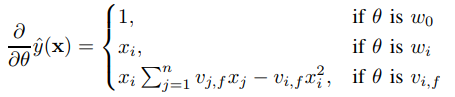
其中,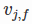 是隐向量 的第 个元素。由于 只与有关,而与 j 无关,在每次迭代过程中,只需计算一次所有 的 ,就能够方便地得到所有 的梯度。显然,计算所有 的 的复杂度是 O(kn);已知时,计算每个参数梯度的复杂度是 O(1);得到梯度后,更新每个参数的复杂度是 O(1);模型参数一共有 nk+n+1 个。因此,FM参数训练的复杂度也是 O(kn)。综上可知,FM可以在线性时间训练和预测,是一种非常高效的模型。
是隐向量 的第 个元素。由于 只与有关,而与 j 无关,在每次迭代过程中,只需计算一次所有 的 ,就能够方便地得到所有 的梯度。显然,计算所有 的 的复杂度是 O(kn);已知时,计算每个参数梯度的复杂度是 O(1);得到梯度后,更新每个参数的复杂度是 O(1);模型参数一共有 nk+n+1 个。因此,FM参数训练的复杂度也是 O(kn)。综上可知,FM可以在线性时间训练和预测,是一种非常高效的模型。
2. FM & SVM讨论
-
线性核SVM
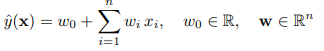
可以看出等价于时的FM。
-
多项式核 SVM
非线性映射函数:
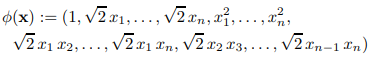
SVM的表达式为:
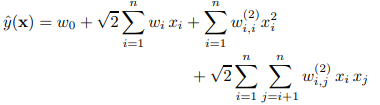
可以看出,SVM的二元特征交叉参数是独立的,而FM的二元特征交叉参数是两个维的向量、,交叉参数就不是独立的,而是相互影响的;
SUMMARY
-
对于大型稀疏矩阵,SVM无法估计高阶交互特征的参数,因为对于特征对
的参数必须有足够的非零样本即只要存在某一个特征则wij参数估计失败,因此在大型稀疏样本情况下,SVM表现很差,而FM对大型稀疏数据非常有用。 -
FM可以在原始形式下进行优化学习,而基于kernel的非线性SVM通常需要在对偶形式下进行;
-
FM的模型预测是与训练样本独立,而SVM则与部分训练样本有关,即支持向量;
FM参数初始化


可以看出:常数项和一次项初始化为零,二次项按照均值为0,方差为0.01的正态分布初始化。
FM数据格式

-
For classification(binary/multiclass), <label> is an integer indicating the class label.
-
For regression, <label> is the target value which can be any real number.
-
Labels in the test file are only used to calculate accuracy or errors. If they are unknown, you can just fill the first column with any number.
二、FFM
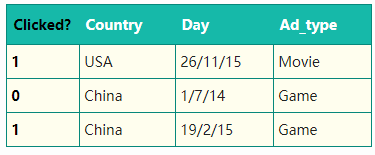
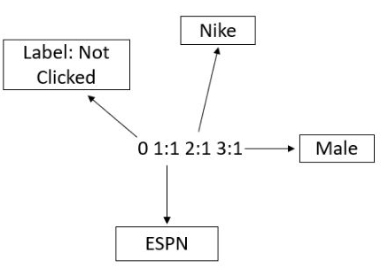
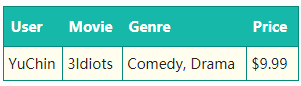
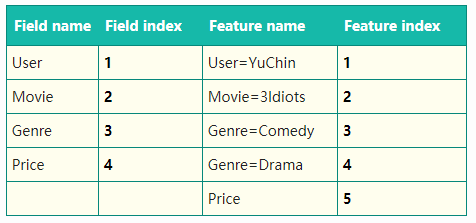
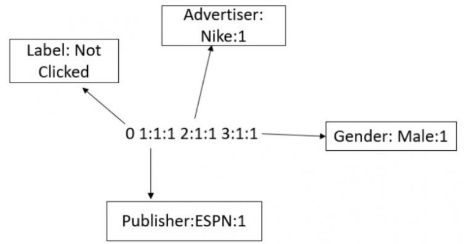
“Clicked?“是label,Country、Day、Ad_type是特征。由于三种特征都是categorical类型的,需要经过独热编码(One-Hot Encoding)转换成数值型特征。

FFM(Field-aware Factorization Machine)最初的概念来自Yu-Chin Juan(阮毓钦,毕业于中国台湾大学,现在美国Criteo工作)与其比赛队员,是他们借鉴了来自Michael Jahrer的论文中的field概念提出了FM的升级版模型。
通过引入field的概念,FFM把相同性质的特征归于同一个field。以上面的广告分类为例,“Day=26/11/15”、“Day=1/7/14”、“Day=19/2/15”这三个特征都是代表日期的,可以放到同一个field中。同理,商品的末级品类编码生成了550个特征,这550个特征都是说明商品所属的品类,因此它们也可以放到同一个field中。简单来说,
同一个
cat
egorical特征经过One-Hot编码生成的数值特征都可以放到同一个field,包括用户性别、职业、品类偏好等。在FFM中,每一维特征
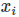 ,针对其它特征的每一种
,针对其它特征的每一种
field f
j,都会学习一个隐向量
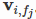 。因此,隐向量不仅与特征相关,也与field相关。也就是说,“Day=26/11/15”这个特征与“Country”特征和“Ad_type”特征进行关联的时候使用不同的隐向量,这与“Country”和“Ad_type”的内在差异相符,也是FFM中“field-aware”的由来。
。因此,隐向量不仅与特征相关,也与field相关。也就是说,“Day=26/11/15”这个特征与“Country”特征和“Ad_type”特征进行关联的时候使用不同的隐向量,这与“Country”和“Ad_type”的内在差异相符,也是FFM中“field-aware”的由来。
n个特征属于
f个field,那么FFM的二次项有 nf个隐向量。而在FM模型中,每一维特征的隐向量只有一个。FM可以看作FFM的特例,是把所有特征都归属到一个field时的FFM模型。根据FFM的field敏感特性,可以导出其模型方程。
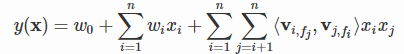
j个特征所属的field。如果隐向量的长度为
k,那么FFM的二次参数有 nfk 个,远多于FM模型的
nk个。此外,由于隐向量与field相关,
FFM二次项并不能够化简,其预测复杂度是 O(
kn
2
)。

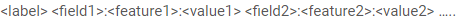
-
样本归一化。FFM默认是进行样本数据的归一化,即 pa.normpa.norm 为真;若此参数设置为假,很容易造成数据inf溢出,进而引起梯度计算的nan错误。因此,样本层面的数据是推荐进行归一化的。
-
特征归一化。CTR/CVR模型采用了多种类型的源特征,包括数值型和categorical类型等。但是,categorical类编码后的特征取值只有0或1,较大的数值型特征会造成样本归一化后categorical类生成特征的值非常小,没有区分性。例如,一条用户-商品记录,用户为“男”性,商品的销量是5000个(假设其它特征的值为零),那么归一化后特征“sex=male”(性别为男)的值略小于0.0002,而“volume”(销量)的值近似为1。特征“sex=male”在这个样本中的作用几乎可以忽略不计,这是相当不合理的。因此,将源数值型特征的值归一化到 [0,1]是非常必要的。
-
省略零值特征。从FFM模型的表达式可以看出,零值特征对模型完全没有贡献。包含零值特征的一次项和组合项均为零,对于训练模型参数或者目标值预估是没有作用的。因此,可以省去零值特征,提高FFM模型训练和预测的速度,这也是稀疏样本采用FFM的显著优势。
https://github.com/kangzhang0709/tensorflow-DeepFM
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/136696.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
