大家好,又见面了,我是你们的朋友全栈君。
目录
一、lxml
首先来了解一下lxml,很多常用的解析html的库都用到了lxml这个库,例如BeautifulSoup、pyquery。
下面我们介绍一下lxml关于html解析的3个Element。
1.1 _Element
1.1.1 _Element获取
from lxml import etree
text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first</a></li> <li class="item-1"><a href="link2.html">second</a></li> <li class="item-0"><a href="link3.html">third</a></li> </ul> </div> '''
# lxml.etree._Element
element = etree.HTML(text)
1.1.2 _Element常用方法
# 通过css选择器获取节点
cssselect(expr)
# 通过标签或者xpath语法获取第一个匹配
find(path)
# 通过标签或者xpath语法获取所有匹配
findall(path)
# 获取属性值
get(key)
# 获取所有属性
items()
# 获取所有属性名称
keys()
# 获取所有属性值
values()
# 获取子节点
getchildren()
# 获取父节点
getparent()
# 获取相邻的下一个节点
getnext()
# 获取相邻的上一个节点
getprevious()
# 迭代节点
iter(tag)
# 通过xpath表达式获取节点
xpath(path)
1.1.3 _Element示例
from lxml import etree
text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first</a></li> <li class="item-1"><a href="link2.html">second</a></li> <li class="item-0" rel="third"><a href="link3.html">third</a></li> </ul> </div> '''
element = etree.HTML(text)
# css选择器,获取class为item-0的li节点
lis = element.cssselect("li.item-0")
for li in lis:
# 获取class属性
print(li.get("class"))
# 获取属性名称和值,元组列表
print(li.items())
# 获取节点所有的属性名称
print(li.keys())
# 获取所有属性值
print(li.values())
print("--------------")
ass = element.cssselect("li a")
for a in ass:
# 获取文本节点
print(a.text)
print("--------------")
# 获取第一个li节点
li = element.find("li")
# 获取所有li节点
lis = element.find("li")
# 获取所有的a节点
lias = element.iter("a")
for lia in lias:
print(lia.get("href"))
textStr = element.itertext("a")
for ts in textStr:
print(ts)
xpath我们后面单独介绍。
1.2 _ElementTree
1.2.1 _ElementTree获取
from io import StringIO
from lxml import etree
text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first</a></li> <li class="item-1"><a href="link2.html">second</a></li> <li class="item-0"><a href="link3.html">third</a></li> </ul> </div> '''
parser = etree.HTMLParser()
# lxml.etree._ElementTree
elementTree = etree.parse(StringIO(text), parser)
# 可以直接从文件读取
# elementTree = etree.parse(r'F:\tmp\etree.html',parser)
1.2.2 _ElementTree常用方法
find(path)
findall(path)
iter(tag)
xpath(path)
_ElementTree方法和 _Element的同名方法使用基本一样。
有很多不同的是_ElementTree的find和findall方法只接受xpath表达式。
1.2.3 _ElementTree示例
from io import StringIO
from lxml import etree
text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first</a></li> <li class="item-1"><a href="link2.html">second</a></li> <li class="item-0"><a href="link3.html">third</a></li> </ul> </div> '''
parser = etree.HTMLParser()
elementTree = etree.parse(StringIO(text), parser)
lis = elementTree.iter("li")
for li in lis:
print(type(li))
print("---------")
firstLi = elementTree.find("//li")
print(type(firstLi))
print(firstLi.get("class"))
print("---------")
ass = elementTree.findall("//li/a")
for a in ass:
print(a.text)
1.3 HtmlElement
1.3.1 HtmlElement获取
import lxml.html
text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first</a></li> <li class="item-1"><a href="link2.html">second</a></li> <li class="item-0"><a href="link3.html">third</a> </ul> </div> '''
# lxml.html.HtmlElement
htmlElement = lxml.html.fromstring(text)
HtmlElement继承了etree.ElementBase和HtmlMixin,etree.ElementBase继承了_Element。
因为HtmlElement继承了_Element,所以_Element中介绍的方法,HtmlElement都可以使用。
HtmlElement还可以使用HtmlMixin中的方法。
1.3.2 HtmlMixin常用方法
# 通过类名获取节点
find_class(class_name)
# 通过id获取节点
get_element_by_id(id)
# 获取文本节点
text_content()
# 通过css选择器获取节点
cssselect(expr)
1.4 xpath
xpath功能非常强大,并且_Element、_ElementTree、HtmlElement都可以使用xpath表达式,所以最后介绍一下xpath。
| 表达式 | 描述 |
|---|---|
| / | 从根节点开始,绝对路径 |
| // | 从当前节点选取子孙节点,相对路径,不关心位置 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag=‘text’] | 选取所有具有指定元素并且文本内容是text节点 |
| expression | 表达式 | 描述 |
|---|---|---|
| ancestor | xpath(’./ancestor:: *’) | 选取当前节点的所有先辈节点 |
| ancestor-or-self | (’./ancestor-or-self:: *’) | 选取当前节点的所有先辈以及节点本身 |
| attribute | xpath(’./attribute:: *’) | 选取当前节点的所有属性 |
| child | xpath(’./child:: *’) | 返回当前节点的所有子节点 |
| descendant | xpath(’./descendant:: *’) | 返回当前节点的所有后代节点(子节点、孙节点) |
| following | xpath(’./following:: *’) | 选取文档中当前节点结束标签后的所有节点 |
| following-sibing | xpath(’./following-sibing:: *’) | 选取当前节点之后的兄弟节点 |
| parent | xpath(’./parent:: *’) | 选取当前节点的父节点 |
| preceding | xpath(’./preceding:: *’) | 选取文档中当前节点开始标签前的所有节点 |
| preceding-sibling | xpath(’./preceding-sibling:: *’) | 选取当前节点之前的兄弟节点 |
| self | xpath(’./self:: *’) | 选取当前节点 |
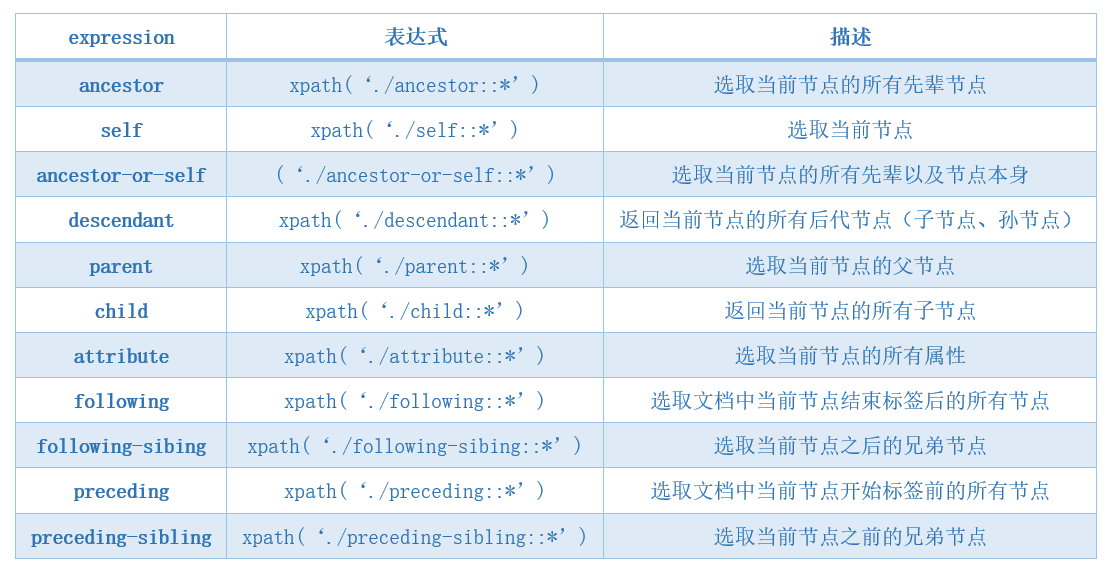
 很多时候我们可以通过浏览器获取xpath表达式:
很多时候我们可以通过浏览器获取xpath表达式:
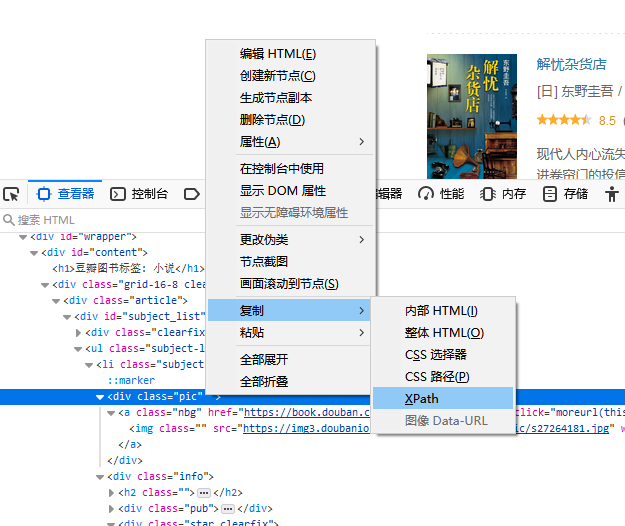
1.4.1 示例
from lxml.html.clean import Cleaner
from lxml import etree
text = ''' <div> <ul> <li class="item-0" rel="li1"><a href="link1.html">first</a></li> <li class="item-1" rel="li2"><a href="link2.html" rel="attrRel">second</a></li> <li class="item-0" rel="li3"><a href="link3.html" id="thirda">third</a> </ul> </div> '''
# 去除css、script
cleaner = Cleaner(style=True, scripts=True, page_structure=False, safe_attrs_only=False)
print(cleaner.clean_html(text))
# _Element
element = etree.HTML(text)
# 文本节点,特殊字符转义
print(element.xpath('//text()'))
# 文本节点,不转义
print(element.xpath('string()'))
# find、findall只能使用相对路径,以.//开头
print(element.findall('.//a[@rel]'))
print(element.find('.//a[@rel]'))
# 获取包含rel属性的a节点
print(element.xpath('//a[@rel]'))
# 获取ul元素下的第一个li节点,注意是列表,因为ul可能有多个
print(element.xpath("//ul/li[1]"))
# 获取ul元素下rel属性为li2的li节点
print(element.xpath("//ul/li[@rel='li2']"))
# 获取ul元素下的倒数第2个节点
print(element.xpath("//ul/li[last()-1]"))
# 获取ul元素下的前2个li节点
print(element.xpath("//ul/li[position()<3]"))
# 获取li元素下的所有a节点
for a in element.xpath("//li/a"):
print(a.text)
print(a.get("href"))
# 获取父节点,列表,因为可能匹配多个a
print(element.xpath('//a[@href="link2.html"]/parent::*'))
# 获取的是文本节点对象列表
print(element.xpath('//li[@class="item-1"]/a/text()'))
print("---------------")
# 获取a的href属性
print(element.xpath('//li/a/@href'))
# 获取所有li子孙节点的href属性
print(element.xpath('//li//@href'))
1.5 xpath示例
from lxml import etree
text = ''' <li class="subject-item"> <div class="pic"> <a class="nbg" href="https://book.douban.com/subject/25862578/"> <img class="" src="https://img3.doubanio.com/view/subject/m/public/s27264181.jpg" width="90"> </a> </div> <div class="info"> <h2 class=""><a href="https://book.douban.com/subject/25862578/" title="解忧杂货店">解忧杂货店</a></h2> <div class="pub">[日] 东野圭吾 / 李盈春 / 南海出版公司 / 2014-5 / 39.50元</div> <div class="star clearfix"> <span class="allstar45"></span> <span class="rating_nums">8.5</span> <span class="pl"> (537322人评价) </span> </div> <p>现代人内心流失的东西,这家杂货店能帮你找回——僻静的街道旁有一家杂货店,只要写下烦恼投进卷帘门的投信口,第二天就会在店后的牛奶箱里得到回答。因男友身患绝... </p> </div> </li> '''
element = etree.HTML(text)
# 查找符合xpath(//li/div/a)的节点
aeles = element.xpath("//li/div/a")
for aele in aeles:
# 获取href属性
print(aele.get("href"))
# 查找img标签,并且获取src属性
print(aele.find("img").get("src"))
# 返回列表的原因是:虽然我们只取了第一个a节点,但是上级xpath(//li/div[@class='info']/h2)可能匹配多个
for a in element.xpath("//li/div[@class='info']/h2/a[1]"):
print(a.get("href"))
print(a.text)
# print(a.get("title"))
# 指定div的class属性
for pu in element.xpath("//li/div[@class='info']/div[@class='pub']"):
print(pu.text)
# 使用到contains函数和or运算符
spans = element.xpath("//li/div[@class='info']/div[@class='star clearfix']/span[contains(@class,'rating_nums') or "
"contains(@class,'pl')]")
for span in spans:
print(span.text.strip())
for content in element.xpath("//li/div[@class='info']/p"):
print(content.text)
# 如果确定只有一个或者只需要第一个可以使用find,注意find使用xpath为参数的时候使用相对路径(.//开头)
print(element.find(".//li/div[@class='info']/p").text)
二、pyquery
2.1 构造PyQuery
从字符串:
from pyquery import PyQuery as pq
html = ''
with open(r"F:\tmp\db.html", "r", encoding='utf-8') as f:
html = f.read()
doc = pq(html)
从URL:
from pyquery import PyQuery as pq
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0'
}
doc = pq('https://book.douban.com/tag/小说', headers=headers)
从文件:
from pyquery import PyQuery as pq
doc = pq(filename=r"F:\tmp\db.html")
从文件有一个问题就是不能指定文件编码,所以一般都是自己读取文件,然后从字符串构造。
2.2 选择器
pyquery最强大的地方就在于,它可以像jQuery使用css选择器一样获取节点。
常用的一些选择器:
id选择器(#id)
类选择器(.class)
属性选择器(a[href=“xxx”])
伪类选择器(:first :last :even :odd :eq :lt :gt :checked :selected)
前面我们已经知道怎样构造一个PyQuery,上面我们有知道了怎么通过选择器获取节点,下面我们通过一个小示例来具体了解一下。
from pyquery import PyQuery as pq
html = ''' <!DOCTYPE html> <html> <head> <title>pyquery</title> </head> <body> <ul id="container"> <li class="li1">li1</li> <li class="li2">li2</li> <li class="li3" data-type='3'>li3</li> </ul> </body> </html> '''
doc = pq(html)
# id选择器,outerHtml输出整体的html
print(doc("#container").outerHtml())
print("----------")
# 类选择器
print(doc(".li1").outerHtml())
print("----------")
# 伪类选择器
# 选择第2个li节点,并通过text获取该li节点的值
print(doc('li:nth-child(2)').text())
# 获取第1个li节点
print(doc('li:first-child').text())
# 获取最后一个li节点,并通过attr获取该节点的data-type属性值
print(doc('li:last-child').attr("data-type"))
print(doc("li:contains('li3')").attr("data-type"))
print("----------")
# 属性选择器
# 选择li的data-type的属性值为3的节点
print(doc("li[data-type='3']").outerHtml())
首先我们通过html字符串构造了一个PyQuery对象,然后就可以通过选择器愉快的获取我们想要的节点了。
注意:上面的text方法是获取节点的文本,attr是获取节点的属性,非常常用
这里就补贴输出代码了,如果感兴趣可以自己动手尝试一下,看一下输出。
2.3 查找与过滤节点
很多时候,我们并不能直接通过选择器一步到位的获取到我们需要的节点,所以我们需要另外一些查找、过滤、遍历节点的方法,例如:find、filter、eq、not_、items、each等,下面我们还是通过一个小例子来介绍一下这些方法。
from pyquery import PyQuery as pq
html = ''' <!DOCTYPE html> <html> <head> <title>pyquery</title> </head> <body> <ul id="container"> <li class="li1">li1</li> <li class="li2">li2</li> <li class="li3" data-type='3'>li3</li> </ul> </body> </html> '''
doc = pq(html)
# find的语法和直接使用选择器一样
print("---find:")
print(doc.find("li").show())
# 输出li的个数
print(doc.find("li").size())
# filter过滤得到满足条件的
print("---filter:")
print(doc.find("li").filter(".li3").show())
# eq选择第n个,下标从0开始
print("---eq:")
print(doc.find("li").eq(1).show())
# not_排除满足条件的节点
print("---not_:")
print(doc.find("li").not_("li[data-type='3']").show())
lis = doc.find("li")
# 输出PyQuery
print(type(lis))
# each输出的类型是lxml.etree._Element
print("---each:")
lis.each(lambda i, e: print(type(e)))
print("---for:")
for li in lis:
print(type(li))
# items获取到的类型才是PyQuery
print("---items:")
for li in lis.items():
print(type(li))
这些方法还是比较基础的,看代码中的注释就能知道是什么意思了,如果有疑问,可以自己动手调试一下。
注意lis是PyQuery类型,PyQuery的each是lxml.etree._Element类型,items才是PyQuery
这意味着使用for\each循环不能使用PyQuery的find、filter、text、attr这些方法。
需要使用lxml.etree._Element的方法。
四、总结
本文只是简单的介绍了一下通过pyquery、lxml解析获取html数据,pyquery还可以操作数据,例如设置属性,添加节点等,甘兴趣的可以自己通过下面的参考链接获取。
五、参考
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/136659.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
