大家好,又见面了,我是你们的朋友全栈君。
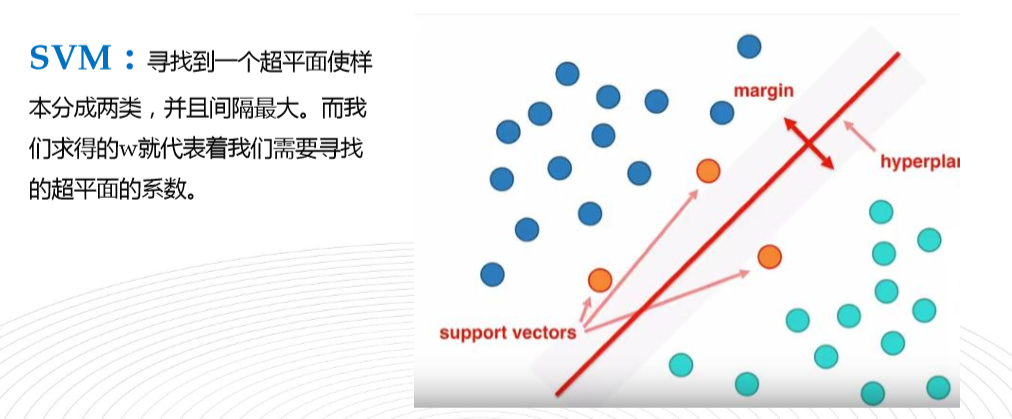
一,SVM(Support Vector Machine)支持向量机
a. SVM算法是介于简单算法和神经网络之间的最好的算法。
b. 只通过几个支持向量就确定了超平面,说明它不在乎细枝末节,所以不容易过拟合,但不能确保一定不会过拟合。可以处理复杂的非线性问题。
c. 高斯核函数
d. 缺点:计算量大

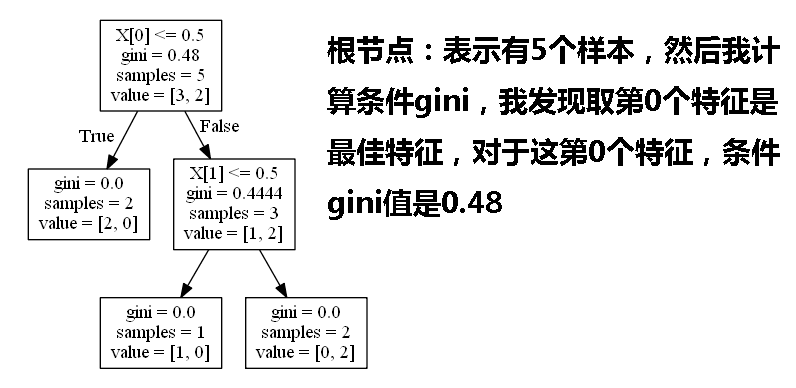
二,决策树(有监督算法,概率算法)
a. 只接受离散特征,属于分类决策树。
b. 条件熵的计算 H(Label |某个特征) 这个条件熵反映了在知道该特征时,标签的混乱程度,可以帮助我们选择特征,选择下一步的决策树的节点。
c. Gini和entropy的效果没有大的差别,在scikit learn中默认用Gini是因为Gini指数不需要求对数,计算量少。
d. 把熵用到了集合上,把集合看成随机变量。
e. 决策树:贪心算法,无法从全局的观点来观察决策树,从而难以调优。
f. 叶子节点上的最小样本数,太少,缺乏统计意义。从叶子节点的情况,可以看出决策树的质量,发现有问题也束手无策。
优点:可解释性强,可视化。缺点:容易过拟合(通过剪枝避免过拟合),很难调优,准确率不高
g. 二分类,正负样本数目相差是否悬殊,投票机制
h. 决策树算法可以看成是把多个逻辑回归算法集成起来。
三,随机森林(集成算法中最简单的,模型融合算法)
随机森林如何缓解决策树的过拟合问题,又能提高精度?
a. Random Forest, 本质上是多个算法平等的聚集在一起。每个单个的决策树,都是随机生成的训练集(行),随机生成的特征集(列),来进行训练而得到的。
b. 随机性的引入使得随机森林不容易陷入过拟合,具有很好的抗噪能力,有效的缓解了单棵决策树的过拟合问题。
c. 每一颗决策树训练样本是随机的有样本的放回抽样。
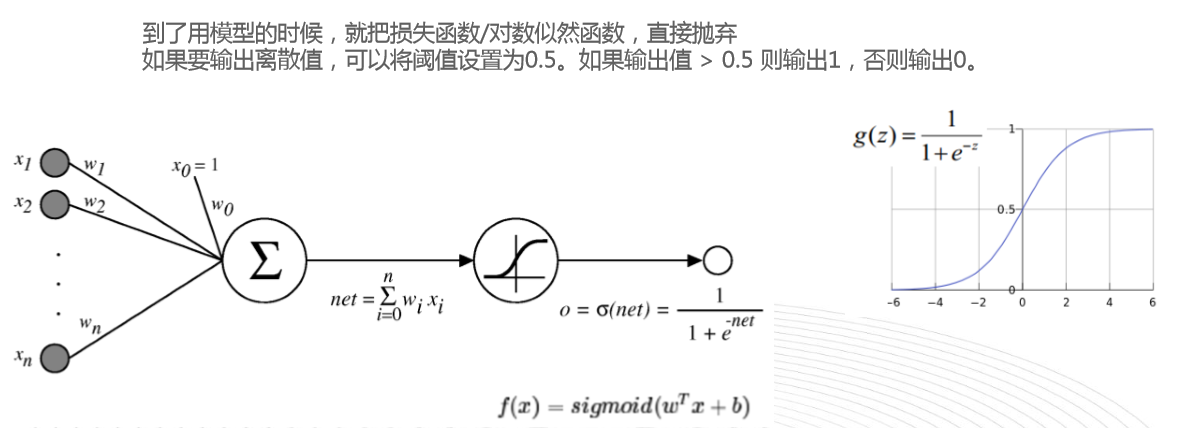
四,逻辑回归(线性算法)
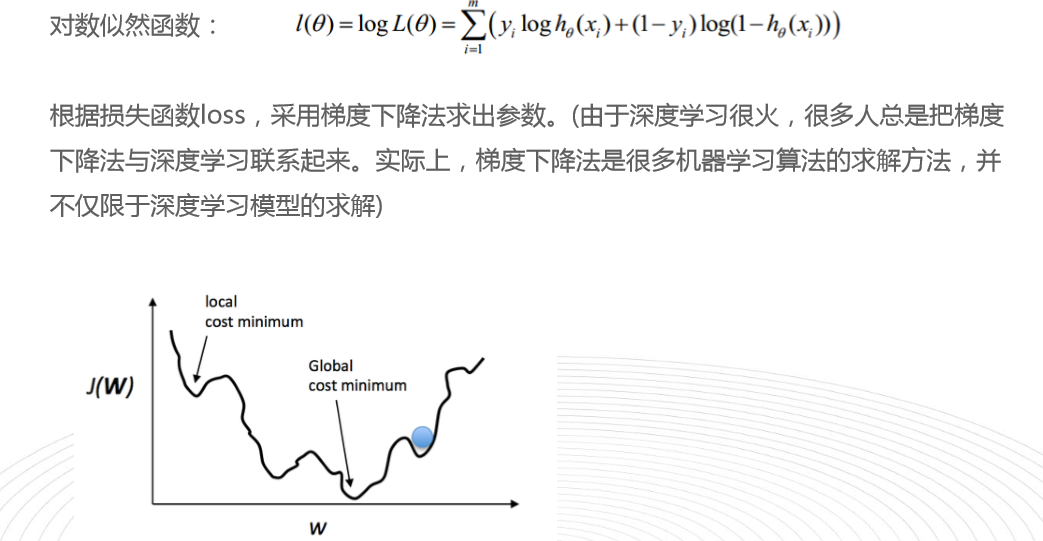
它是广义线性模型GLM的一种,可以看成是一个最简单的神经网络,损失函数是一个对数似然函数,损失函数的值越大越好。(梯度上升法)
a. 多次训练,多次测试,目的是看逻辑回归这个算法适不适合这个应用场景。




五,朴素贝叶斯
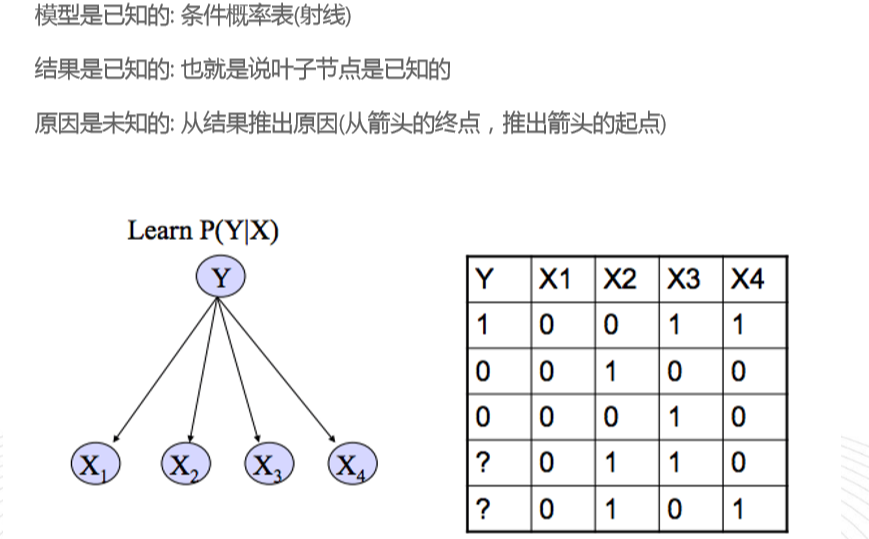
应用场景:源于推理的需要,例如:通过商品的描述(特征X)来推理商品的类别(Y)。
“朴素”:特征与特征之间是独立的,互不干扰。如果特征比较多时,往往独立性的条件不重要(互相抵消),可以用朴素贝叶斯。
训练的时候:得出条件概率表
推理的时候:比较条件概率的大小
特点:训练容易,推理难
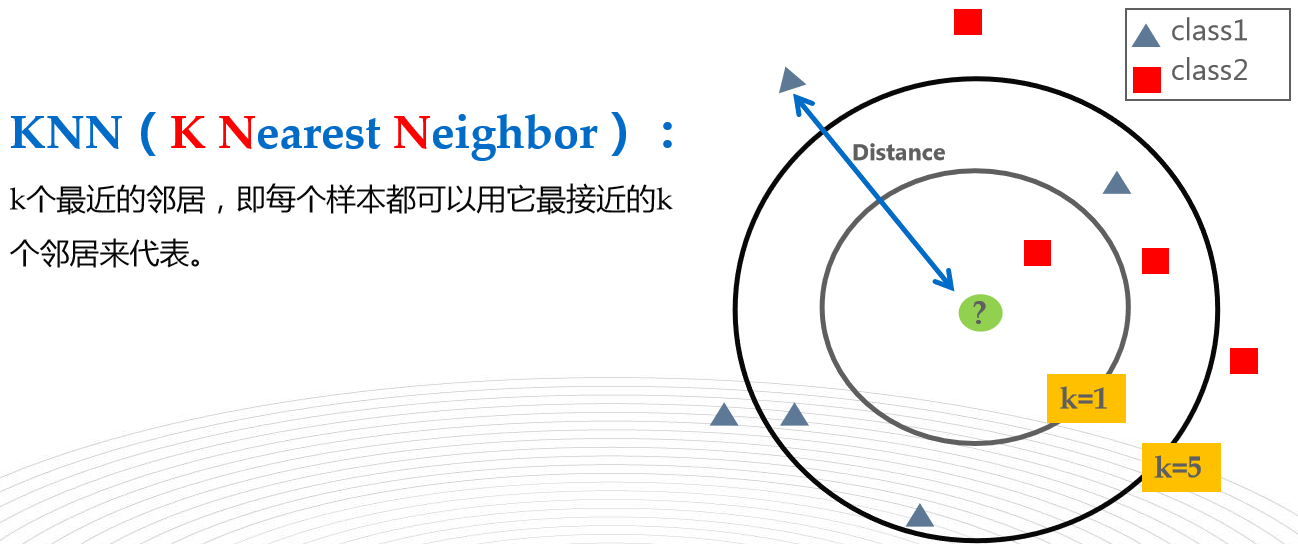
六,KNN(K Nearest Neighbor) K近邻(有监督算法,分类算法)
K表示K个邻居,不表示距离,因为需要求所有邻居的距离,所以效率低下。
优点:可以用来填充缺失值,可以处理非线性问题
调优方法:K值的选择,k值太小,容易过拟合
应用:样本数少,特征个数较少,kNN更适合处理一些分类规则相对复杂的问题,在推荐系统大量使用
KNN算法和贝叶斯算法有某种神秘的联系,用贝叶斯算法估算KNN的误差。
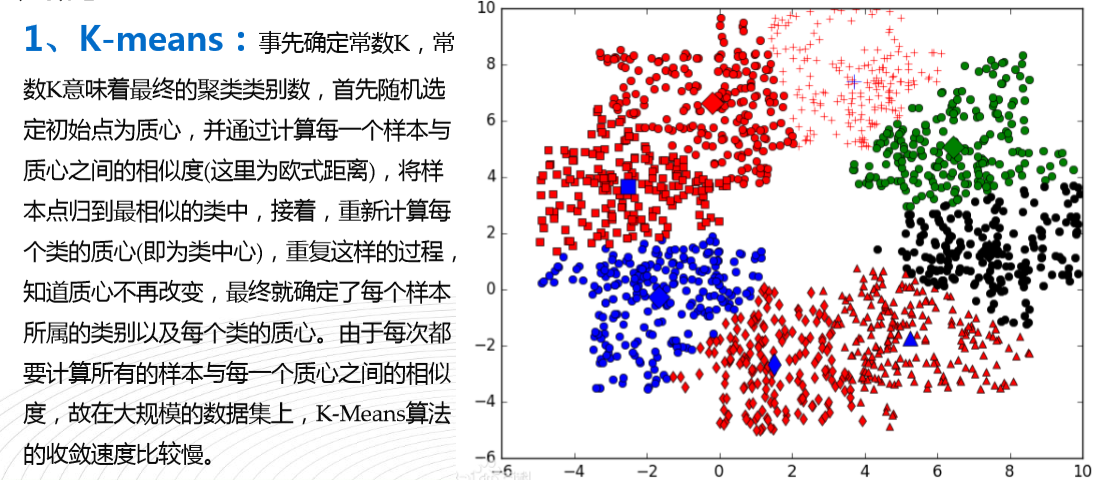
七,K-means K均值(无监督算法,聚类算法,随机算法)
a. 最常用的无监督算法
b. 计算距离方法:欧式距离,曼哈顿距离
c. 应用:去除孤立点,离群点(只针对度量算法);可以离散化
d. 最常用归一化预处理方法
f. k-means设置超参数k时,只需要设置最大的k值。
g. k-means算法最终肯定会得到稳定的k个中心点,可以用EM(Expectation Maximum)算法解释
h. k-means算法k个随机初始值怎么选? 多选几次,比较,找出最好的那个
i. 调优的方法:1. bi-kmeans 方法(依次“补刀”)
j. 调优的方法:2. 层次聚类(逐步聚拢法)k=5 找到5个中心点,把中心点喂给k-means。初始中心点不同,收敛的结果也可能不一致。
k. 聚类效果怎么判断?用SSE误差平方和指标判断,SSE越小越好,也就是肘部法则的拐点处。也可以用轮廓系数法判断,值越大,表示聚类效果越好,簇与簇之间距离越远越好,簇内越紧越好。
l. k-means算法最大弱点:只能处理球形的簇(理论)
八,Adaboost(集成算法之一)
九,马尔可夫
a. 马尔可夫线没有箭头,马尔可夫模型允许有环路。
b. affinity亲和力关系,energy(A,B,C),发现A,B,C之间有某种规律性东西,但不一定是概率,但是可以表示ABC之间的一种亲和力。
c. potential = e1*e2*e3*en potential函数一般来说不是概率
d. 归一化 -> 概率分布probability
e. 贝叶斯模型与马尔可夫模型:任何一个贝叶斯模型对应于唯一的一个马尔可夫模型,而任意一个马尔可夫模型,可以对应于多个贝叶斯模型。
f. 贝叶斯模型类似于象棋,等级分明;马尔可夫模型类似于围棋,人人平等。
g. 马尔可夫模型(Markov Model)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域。
十,EM算法
EM算法是概率图算法的一个简单
附录:

模型是已知的:条件概率表(射线)已知( P(Xi|C1) P ( X i | C 1 ) ),类别的概率是已知的( P(C1) P ( C 1 ) )

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/136631.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
